


排序算法是《數據結構與算法》中最基本的算法之一。
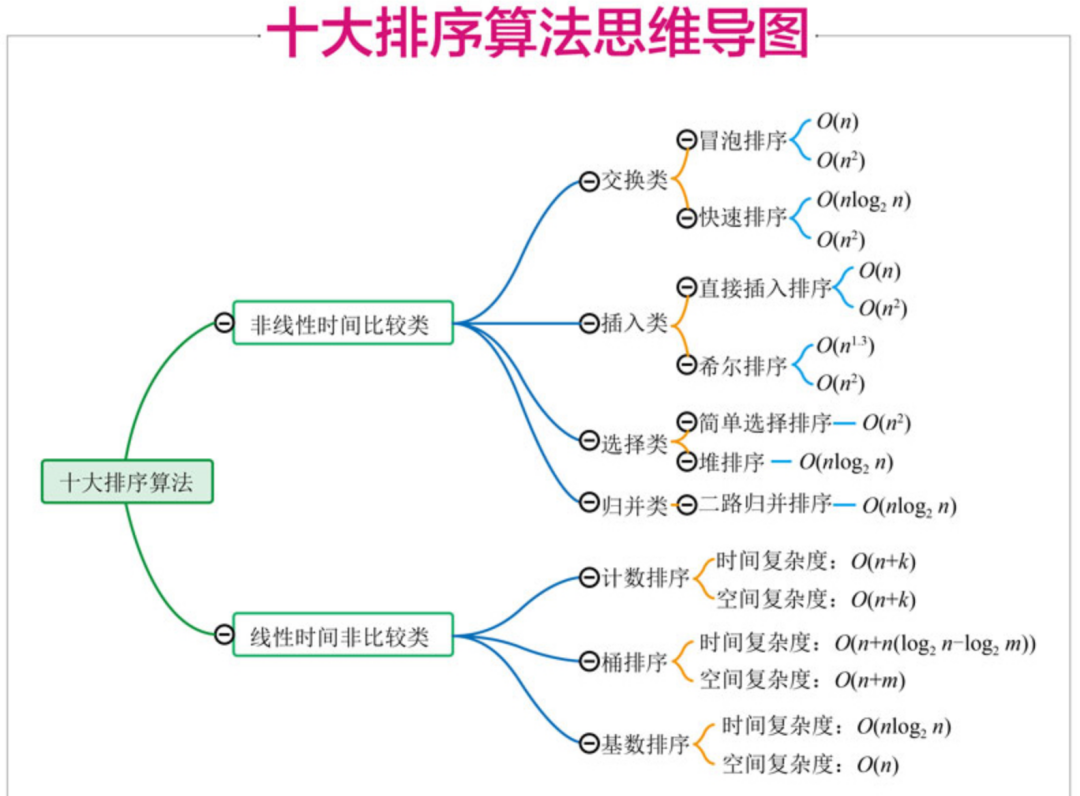
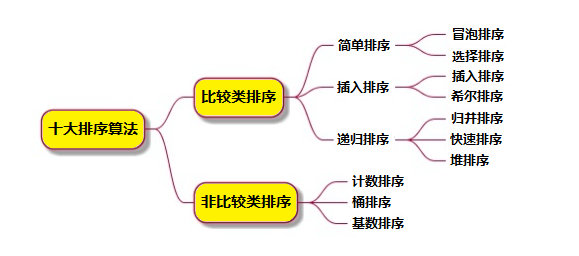
排序算法可以分為內部排序和外部排序,內部排序是數據記錄在內存中進行排序,而外部排序是因排序的數據很大,一次不能容納全部的排序記錄,在排序過程中需要訪問外存。常見的內部排序算法有:插入排序、希爾排序、選擇排序、冒泡排序、歸并排序、快速排序、堆排序、基數排序等。用一張圖概括:
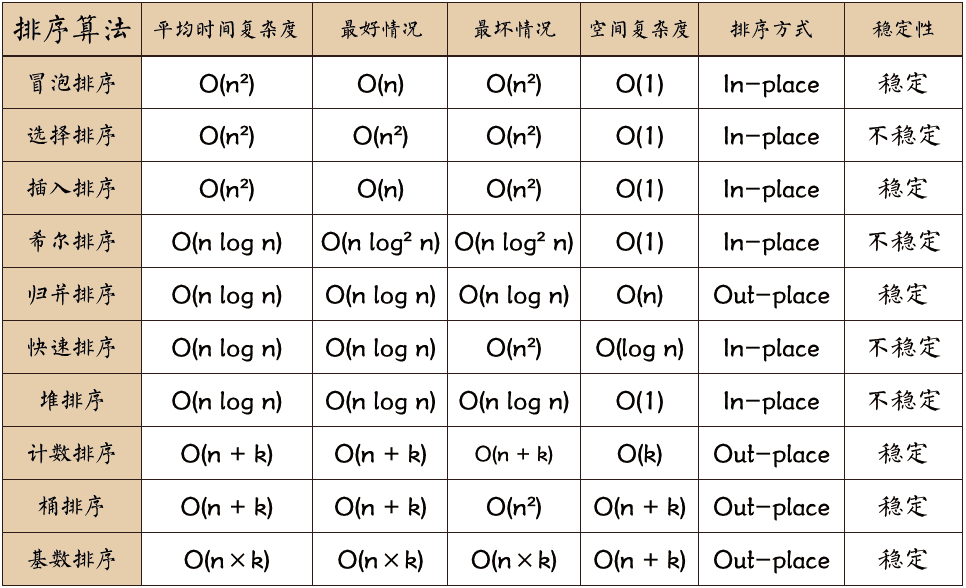
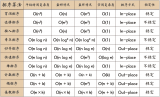
關于時間復雜度
- 平方階 (O(n2)) 排序 各類簡單排序:直接插入、直接選擇和冒泡排序。
- 線性對數階 (O(nlog2n)) 排序 快速排序、堆排序和歸并排序;
- O(n1+§)) 排序,§ 是介于 0 和 1 之間的常數。希爾排序
- 線性階 (O(n)) 排序 基數排序,此外還有桶、箱排序。
關于穩(wěn)定性
- 排序后 2 個相等鍵值的順序和排序之前它們的順序相同
- 穩(wěn)定的排序算法:冒泡排序、插入排序、歸并排序和基數排序。
- 不是穩(wěn)定的排序算法:選擇排序、快速排序、希爾排序、堆排序。
名詞解釋
- n:數據規(guī)模
- k:“桶”的個數
- In-place:占用常數內存,不占用額外內存
- Out-place:占用額外內存
1、冒泡排序
冒泡排序(Bubble Sort)也是一種簡單直觀的排序算法。它重復地走訪過要排序的數列,一次比較兩個元素,如果他們的順序錯誤就把他們交換過來。走訪數列的工作是重復地進行直到沒有再需要交換,也就是說該數列已經排序完成。這個算法的名字由來是因為越小的元素會經由交換慢慢“浮”到數列的頂端。
作為最簡單的排序算法之一,冒泡排序給我的感覺就像 Abandon 在單詞書里出現的感覺一樣,每次都在第一頁第一位,所以最熟悉。冒泡排序還有一種優(yōu)化算法,就是立一個 flag,當在一趟序列遍歷中元素沒有發(fā)生交換,則證明該序列已經有序。但這種改進對于提升性能來說并沒有什么太大作用。
(1)算法步驟
- 比較相鄰的元素。如果第一個比第二個大,就交換他們兩個。
- 對每一對相鄰元素作同樣的工作,從開始第一對到結尾的最后一對。這步做完后,最后的元素會是最大的數。
- 針對所有的元素重復以上的步驟,除了最后一個。
- 持續(xù)每次對越來越少的元素重復上面的步驟,直到沒有任何一對數字需要比較。
(2)動圖演示
(3)Python 代碼
defbubbleSort(arr):
foriinrange(1,len(arr)):
forjinrange(0,len(arr)-i):
ifarr[j]>arr[j+1]:
arr[j],arr[j+1]=arr[j+1],arr[j]
returnarr
2、選擇排序
選擇排序是一種簡單直觀的排序算法,無論什么數據進去都是 O(n2) 的時間復雜度。所以用到它的時候,數據規(guī)模越小越好。唯一的好處可能就是不占用額外的內存空間了吧。
(1)算法步驟
- 首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置
- 再從剩余未排序元素中繼續(xù)尋找最小(大)元素,然后放到已排序序列的末尾。
- 重復第二步,直到所有元素均排序完畢。
(2)動圖演示
(3)Python 代碼
defselectionSort(arr):
foriinrange(len(arr)-1):
#記錄最小數的索引
minIndex=i
forjinrange(i+1,len(arr)):
ifarr[j]#i不是最小數時,將i和最小數進行交換
ifi!=minIndex:
arr[i],arr[minIndex]=arr[minIndex],arr[i]
returnarr
3、插入排序
插入排序的代碼實現雖然沒有冒泡排序和選擇排序那么簡單粗暴,但它的原理應該是最容易理解的了,因為只要打過撲克牌的人都應該能夠秒懂。插入排序是一種最簡單直觀的排序算法,它的工作原理是通過構建有序序列,對于未排序數據,在已排序序列中從后向前掃描,找到相應位置并插入。
插入排序和冒泡排序一樣,也有一種優(yōu)化算法,叫做拆半插入。
(1)算法步驟
-
將第一待排序序列第一個元素看做一個有序序列,把第二個元素到最后一個元素當成是未排序序列。
-
從頭到尾依次掃描未排序序列,將掃描到的每個元素插入有序序列的適當位置。(如果待插入的元素與有序序列中的某個元素相等,則將待插入元素插入到相等元素的后面。)
(2)動圖演示
(3)Python 代碼
definsertionSort(arr):
foriinrange(len(arr)):
preIndex=i-1
current=arr[i]
whilepreIndex>=0andarr[preIndex]>current:
arr[preIndex+1]=arr[preIndex]
preIndex-=1
arr[preIndex+1]=current
returnarr
4、希爾排序
希爾排序,也稱遞減增量排序算法,是插入排序的一種更高效的改進版本。但希爾排序是非穩(wěn)定排序算法。
希爾排序是基于插入排序的以下兩點性質而提出改進方法的:
- 插入排序在對幾乎已經排好序的數據操作時,效率高,即可以達到線性排序的效率;
- 但插入排序一般來說是低效的,因為插入排序每次只能將數據移動一位;
希爾排序的基本思想是:先將整個待排序的記錄序列分割成為若干子序列分別進行直接插入排序,待整個序列中的記錄“基本有序”時,再對全體記錄進行依次直接插入排序。
(1)算法步驟
- 選擇一個增量序列 t1,t2,……,tk,其中 ti > tj, tk = 1;
- 按增量序列個數 k,對序列進行 k 趟排序;
- 每趟排序,根據對應的增量 ti,將待排序列分割成若干長度為 m 的子序列,分別對各子表進行直接插入排序。僅增量因子為 1 時,整個序列作為一個表來處理,表長度即為整個序列的長度。
(2)Python 代碼
defshellSort(arr):
importmath
gap=1
while(gap3):
gap=gap*3+1
whilegap>0:
foriinrange(gap,len(arr)):
temp=arr[i]
j=i-gap
whilej>=0andarr[j]>temp:
arr[j+gap]=arr[j]
j-=gap
arr[j+gap]=temp
gap=math.floor(gap/3)
returnarr
5、歸并排序
歸并排序(Merge sort)是建立在歸并操作上的一種有效的排序算法。該算法是采用分治法(Divide and Conquer)的一個非常典型的應用。
作為一種典型的分而治之思想的算法應用,歸并排序的實現由兩種方法:
- 自上而下的遞歸(所有遞歸的方法都可以用迭代重寫,所以就有了第 2 種方法);
- 自下而上的迭代;
和選擇排序一樣,歸并排序的性能不受輸入數據的影響,但表現比選擇排序好的多,因為始終都是 O(nlogn) 的時間復雜度。代價是需要額外的內存空間。
(1)算法步驟
-
申請空間,使其大小為兩個已經排序序列之和,該空間用來存放合并后的序列;
-
設定兩個指針,最初位置分別為兩個已經排序序列的起始位置;
-
比較兩個指針所指向的元素,選擇相對小的元素放入到合并空間,并移動指針到下一位置;
-
重復步驟 3 直到某一指針達到序列尾;
-
將另一序列剩下的所有元素直接復制到合并序列尾。
(2)動圖演示
(3)Python 代碼
defmergeSort(arr):
importmath
if(len(arr)<2):
returnarr
middle=math.floor(len(arr)/2)
left,right=arr[0:middle],arr[middle:]
returnmerge(mergeSort(left),mergeSort(right))
defmerge(left,right):
result=[]
whileleftandright:
ifleft[0]<=?right[0]:
result.append(left.pop(0));
else:
result.append(right.pop(0));
whileleft:
result.append(left.pop(0));
whileright:
result.append(right.pop(0));
returnresult
6、快速排序
快速排序是由東尼·霍爾所發(fā)展的一種排序算法。在平均狀況下,排序 n 個項目要 Ο(nlogn) 次比較。在最壞狀況下則需要 Ο(n2) 次比較,但這種狀況并不常見。事實上,快速排序通常明顯比其他 Ο(nlogn) 算法更快,因為它的內部循環(huán)(inner loop)可以在大部分的架構上很有效率地被實現出來。
快速排序使用分治法(Divide and conquer)策略來把一個串行(list)分為兩個子串行(sub-lists)。
快速排序又是一種分而治之思想在排序算法上的典型應用。本質上來看,快速排序應該算是在冒泡排序基礎上的遞歸分治法。
快速排序的名字起的是簡單粗暴,因為一聽到這個名字你就知道它存在的意義,就是快,而且效率高!它是處理大數據最快的排序算法之一了。雖然 Worst Case 的時間復雜度達到了 O(n2),但是人家就是優(yōu)秀,在大多數情況下都比平均時間復雜度為 O(n logn) 的排序算法表現要更好,可是這是為什么呢,我也不知道。好在我的強迫癥又犯了,查了 N 多資料終于在《算法藝術與信息學競賽》上找到了滿意的答案:
快速排序的最壞運行情況是 O(n2),比如說順序數列的快排。但它的平攤期望時間是 O(nlogn),且 O(nlogn) 記號中隱含的常數因子很小,比復雜度穩(wěn)定等于 O(nlogn) 的歸并排序要小很多。所以,對絕大多數順序性較弱的隨機數列而言,快速排序總是優(yōu)于歸并排序。
(1)算法步驟
① 從數列中挑出一個元素,稱為 “基準”(pivot);
② 重新排序數列,所有元素比基準值小的擺放在基準前面,所有元素比基準值大的擺在基準的后面(相同的數可以到任一邊)。在這個分區(qū)退出之后,該基準就處于數列的中間位置。這個稱為分區(qū)(partition)操作;
③ 遞歸地(recursive)把小于基準值元素的子數列和大于基準值元素的子數列排序;
遞歸的最底部情形,是數列的大小是零或一,也就是永遠都已經被排序好了。雖然一直遞歸下去,但是這個算法總會退出,因為在每次的迭代(iteration)中,它至少會把一個元素擺到它最后的位置去。
(2)動圖演示
(3)Python 代碼
defquickSort(arr,left=None,right=None):
left=0ifnotisinstance(left,(int,float))elseleft
right=len(arr)-1ifnotisinstance(right,(int,float))elseright
ifleft-1)
quickSort(arr,partitionIndex+1,right)
returnarr
defpartition(arr,left,right):
pivot=left
index=pivot+1
i=index
whilei<=?right:
????????ifarr[i]1
i+=1
swap(arr,pivot,index-1)
returnindex-1
defswap(arr,i,j):
arr[i],arr[j]=arr[j],arr[i]
7、堆排序
堆排序(Heapsort)是指利用堆這種數據結構所設計的一種排序算法。堆積是一個近似完全二叉樹的結構,并同時滿足堆積的性質:即子結點的鍵值或索引總是小于(或者大于)它的父節(jié)點。堆排序可以說是一種利用堆的概念來排序的選擇排序。分為兩種方法:
- 大頂堆:每個節(jié)點的值都大于或等于其子節(jié)點的值,在堆排序算法中用于升序排列;
- 小頂堆:每個節(jié)點的值都小于或等于其子節(jié)點的值,在堆排序算法中用于降序排列;
堆排序的平均時間復雜度為 Ο(nlogn)。
(1)算法步驟
- 創(chuàng)建一個堆 H[0……n-1];
- 把堆首(最大值)和堆尾互換;
- 把堆的尺寸縮小 1,并調用 shift_down(0),目的是把新的數組頂端數據調整到相應位置;
- 重復步驟 2,直到堆的尺寸為 1。
(2)動圖演示

(3)Python 代碼
defbuildMaxHeap(arr):
importmath
foriinrange(math.floor(len(arr)/2),-1,-1):
heapify(arr,i)
defheapify(arr,i):
left=2*i+1
right=2*i+2
largest=i
ifleftandarr[left]>arr[largest]:
largest=left
ifrightandarr[right]>arr[largest]:
largest=right
iflargest!=i:
swap(arr,i,largest)
heapify(arr,largest)
defswap(arr,i,j):
arr[i],arr[j]=arr[j],arr[i]
defheapSort(arr):
globalarrLen
arrLen=len(arr)
buildMaxHeap(arr)
foriinrange(len(arr)-1,0,-1):
swap(arr,0,i)
arrLen-=1
heapify(arr,0)
returnarr
8、計數排序
計數排序的核心在于將輸入的數據值轉化為鍵存儲在額外開辟的數組空間中。作為一種線性時間復雜度的排序,計數排序要求輸入的數據必須是有確定范圍的整數。
(1)動圖演示
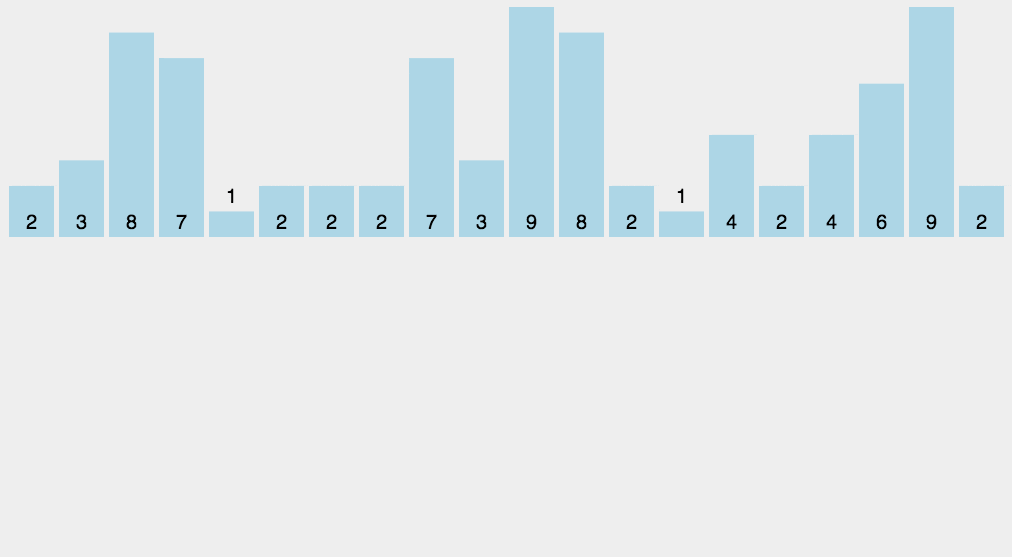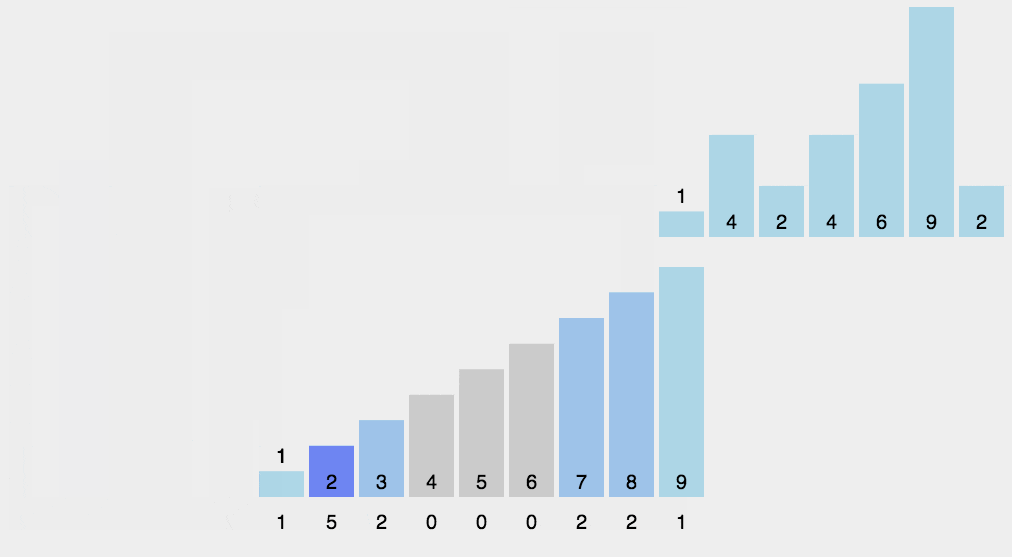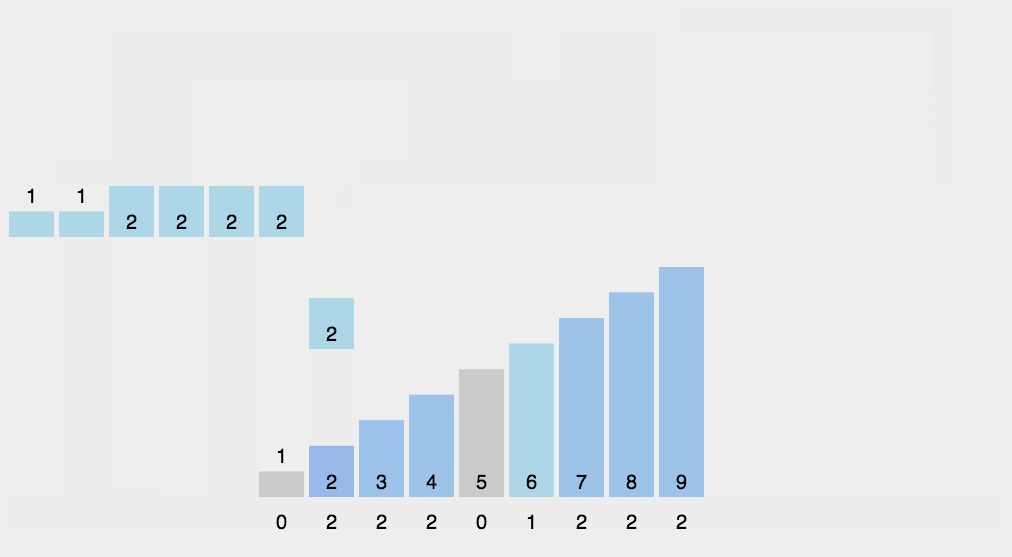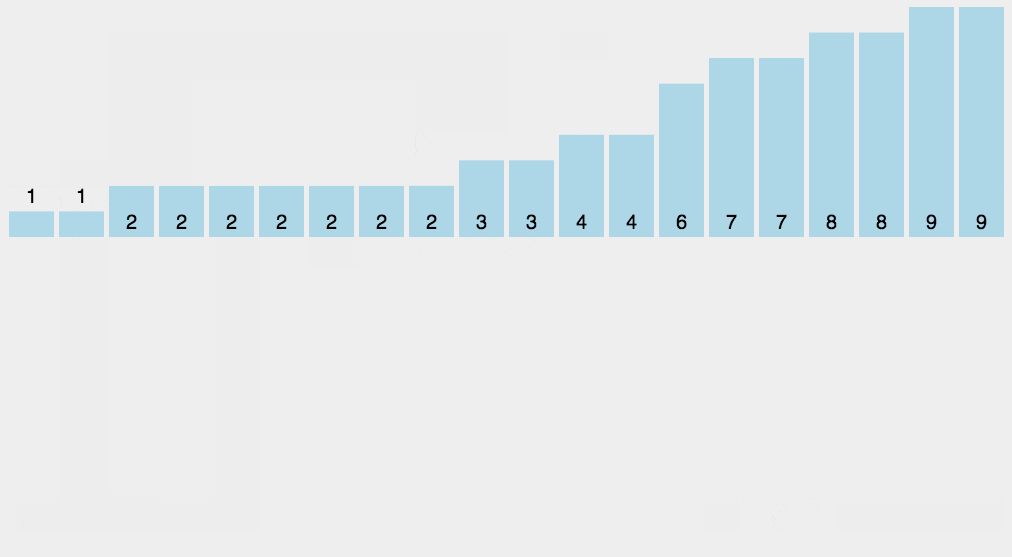
(2)Python 代碼
defcountingSort(arr,maxValue):
bucketLen=maxValue+1
bucket=[0]*bucketLen
sortedIndex=0
arrLen=len(arr)
foriinrange(arrLen):
ifnotbucket[arr[i]]:
bucket[arr[i]]=0
bucket[arr[i]]+=1
forjinrange(bucketLen):
whilebucket[j]>0:
arr[sortedIndex]=j
sortedIndex+=1
bucket[j]-=1
returnarr
9、桶排序
桶排序是計數排序的升級版。它利用了函數的映射關系,高效與否的關鍵就在于這個映射函數的確定。為了使桶排序更加高效,我們需要做到這兩點:
- 在額外空間充足的情況下,盡量增大桶的數量
- 使用的映射函數能夠將輸入的 N 個數據均勻的分配到 K 個桶中
同時,對于桶中元素的排序,選擇何種比較排序算法對于性能的影響至關重要。
什么時候最快
當輸入的數據可以均勻的分配到每一個桶中。
什么時候最慢
當輸入的數據被分配到了同一個桶中。
Python 代碼
defbucket_sort(s):
"""桶排序"""
min_num=min(s)
max_num=max(s)
#桶的大小
bucket_range=(max_num-min_num)/len(s)
#桶數組
count_list=[[]foriinrange(len(s)+1)]
#向桶數組填數
foriins:
count_list[int((i-min_num)//bucket_range)].append(i)
s.clear()
#回填,這里桶內部排序直接調用了sorted
foriincount_list:
forjinsorted(i):
s.append(j)
if__name__==__main__:
a=[3.2,6,8,4,2,6,7,3]
bucket_sort(a)
print(a)#[2,3,3.2,4,6,6,7,8]
10、基數排序
基數排序是一種非比較型整數排序算法,其原理是將整數按位數切割成不同的數字,然后按每個位數分別比較。由于整數也可以表達字符串(比如名字或日期)和特定格式的浮點數,所以基數排序也不是只能使用于整數。
基數排序 vs 計數排序 vs 桶排序
基數排序有兩種方法:
這三種排序算法都利用了桶的概念,但對桶的使用方法上有明顯差異:
- 基數排序:根據鍵值的每位數字來分配桶;
- 計數排序:每個桶只存儲單一鍵值;
- 桶排序:每個桶存儲一定范圍的數值;
動圖演示

Python 代碼
defRadixSort(list):
i=0#初始為個位排序
n=1#最小的位數置為1(包含0)
max_num=max(list)#得到帶排序數組中最大數
whilemax_num>10**n:#得到最大數是幾位數
n+=1
whilei#用字典構建桶
forxinrange(10):
bucket.setdefault(x,[])#將每個桶置空
forxinlist:#對每一位進行排序
radix=int((x/(10**i))%10)#得到每位的基數
bucket[radix].append(x)#將對應的數組元素加入到相#應位基數的桶中
j=0
forkinrange(10):
iflen(bucket[k])!=0:#若桶不為空
foryinbucket[k]:#將該桶中每個元素
list[j]=y#放回到數組中
j+=1
i+=1
returnlist
審核編輯 :李倩
-
算法
+關注
關注
23文章
4713瀏覽量
95532 -
python
+關注
關注
56文章
4828瀏覽量
86993
原文標題:用Python實現十大經典排序算法(附動圖)
文章出處:【微信號:AndroidPush,微信公眾號:Android編程精選】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
動圖展示C語言十大經典排序算法
C語言實現十大經典排序算法
數據挖掘十大經典算法,你都知道哪些!
【免費領取】運放十大經典電路(視頻21集)
數據挖掘十大經典算法,你都知道哪些!
十大經典排序算法動畫與解析
NI獲選第八屆浦東總部經濟十大經典樣本,持續(xù)助力中國科技創(chuàng)新和產業(yè)發(fā)展
動圖演示C語言10大經典排序算法(含代碼)
機器學習的基本流程和十大算法





 工商網監(jiān)
工商網監(jiān)

評論