") 一種基于直接法的動(dòng)態(tài)稠密SLAM方案
一種基于直接法的動(dòng)態(tài)稠密SLAM方案
0. 引言
基于特征點(diǎn)法的視覺(jué)SLAM系統(tǒng)很難應(yīng)用于稠密建圖,且容易丟失動(dòng)態(tài)對(duì)象。而基于直接法的SLAM系統(tǒng)會(huì)跟蹤圖像幀之間的所有像素,因此在動(dòng)態(tài)稠密建圖方面可以取得更完整、魯棒和準(zhǔn)確的結(jié)果。本文將帶大家精讀2022 CVPR的論文:"基于學(xué)習(xí)視覺(jué)里程計(jì)的動(dòng)態(tài)稠密RGB-D SLAM"。該論文提出了一種基于直接法的動(dòng)態(tài)稠密SLAM方案,重要的是,算法已經(jīng)開源。
1. 論文信息
摘要
我們提出了一種基于學(xué)習(xí)的視覺(jué)里程計(jì)(TartanVO)的稠密動(dòng)態(tài)RGB-D SLAM系統(tǒng)。TartanVO與其他直接法而非特征點(diǎn)法一樣,通過(guò)稠密光流來(lái)估計(jì)相機(jī)姿態(tài)。而稠密光流僅適用于靜態(tài)場(chǎng)景,且不考慮動(dòng)態(tài)對(duì)象。同時(shí)由于顏色不變性假設(shè),光流不能區(qū)分動(dòng)態(tài)和靜態(tài)像素。
因此,為了通過(guò)直接法重建靜態(tài)地圖,我們提出的系統(tǒng)通過(guò)利用光流輸出來(lái)解決動(dòng)態(tài)/靜態(tài)分割,并且僅將靜態(tài)點(diǎn)融合到地圖中。此外,我們重新渲染輸入幀,以便移除動(dòng)態(tài)像素,并迭代地將它們傳遞回視覺(jué)里程計(jì),以改進(jìn)姿態(tài)估計(jì)。
3. 算法分析
圖1所示是作者提出的具有基于學(xué)習(xí)的視覺(jué)里程計(jì)的動(dòng)態(tài)稠密RGB-D SLAM的頂層架構(gòu),其輸出的地圖是沒(méi)有動(dòng)態(tài)對(duì)象的稠密全局地圖。 算法的主要思想是從兩個(gè)連續(xù)的RGB圖像中估計(jì)光流,并將其傳遞到視覺(jué)里程計(jì)中,以通過(guò)匹配點(diǎn)作為直接法來(lái)預(yù)測(cè)相機(jī)運(yùn)動(dòng)。然后通過(guò)利用光流來(lái)執(zhí)行動(dòng)態(tài)分割,經(jīng)過(guò)多次迭代后,移除動(dòng)態(tài)像素,這樣僅具有靜態(tài)像素的RGB-D圖像就被融合到全局地圖中。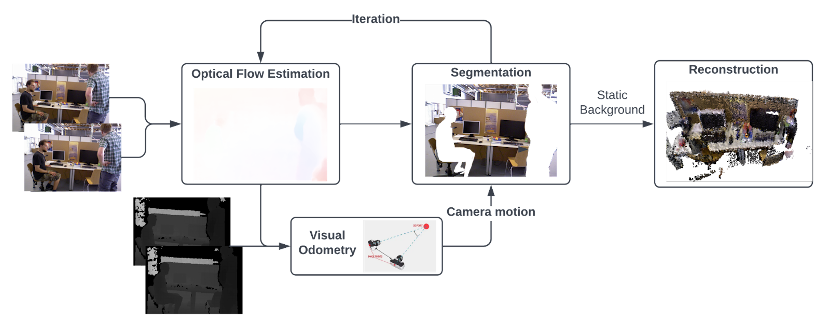
圖1 基于學(xué)習(xí)的視覺(jué)里程計(jì)的動(dòng)態(tài)稠密RGB-D SLAM頂層架構(gòu)
3.1 分割算法
為了利用來(lái)自TartanVO的光流輸出來(lái)分類動(dòng)態(tài)/靜態(tài)像素,作者提出了兩種分割方法:一種是使用2D場(chǎng)景流作為光流和相機(jī)運(yùn)動(dòng)之間的差值。另一種是提取一幀中的像素到它們匹配的核線的幾何距離。圖2和圖3所示分別為兩種方法的算法原理。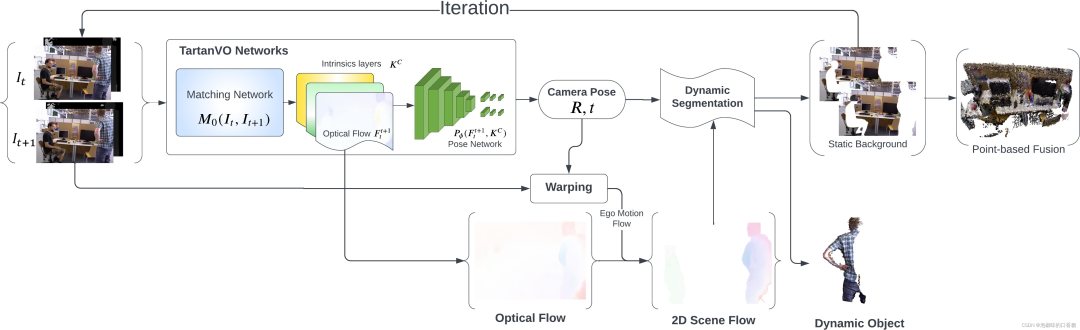
圖2 使用基于2D場(chǎng)景流的分割的稠密RGB-D SLAM架構(gòu)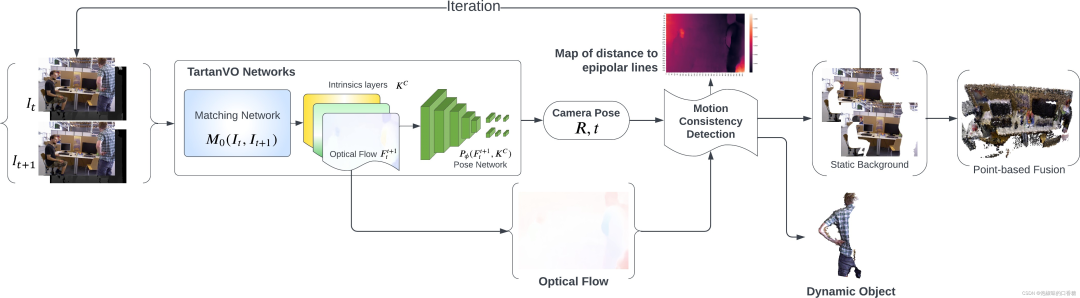
圖3 基于運(yùn)動(dòng)一致性檢測(cè)的稠密RGB-D SLAM架構(gòu)
在圖2中,作者首先使用來(lái)自TartanVO的匹配網(wǎng)絡(luò)從兩個(gè)連續(xù)的RGB圖像中估計(jì)光流,隨后使用姿態(tài)網(wǎng)絡(luò)來(lái)預(yù)測(cè)相機(jī)運(yùn)動(dòng)。然后通過(guò)從光流中減去相機(jī)自身運(yùn)動(dòng)來(lái)獲得2D場(chǎng)景流,并通過(guò)對(duì)2D場(chǎng)景流進(jìn)行閾值處理來(lái)執(zhí)行動(dòng)態(tài)分割。 同時(shí),靜態(tài)背景被前饋到網(wǎng)絡(luò),以實(shí)現(xiàn)相機(jī)運(yùn)動(dòng)的迭代更新。
經(jīng)過(guò)幾次迭代后,動(dòng)態(tài)像素被移除,僅具有靜態(tài)像素的RGB-D圖像被傳遞到基于點(diǎn)的融合中進(jìn)行重建。圖4所示為使用2D場(chǎng)景流進(jìn)行動(dòng)態(tài)像素分割的原理。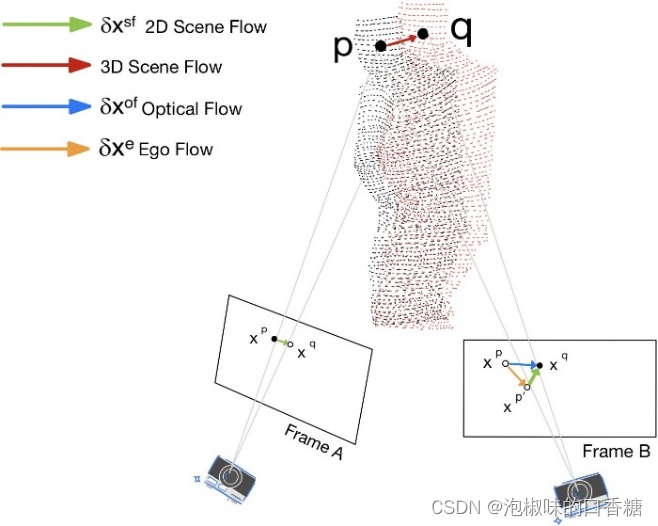
圖4 圖像平面中投影的2D場(chǎng)景流
在圖3中,作者首先使用來(lái)自TartanVO的匹配網(wǎng)絡(luò)從兩個(gè)連續(xù)的RGB圖像中估計(jì)光流,隨后使用姿態(tài)網(wǎng)絡(luò)來(lái)預(yù)測(cè)相機(jī)運(yùn)動(dòng)。 然后計(jì)算從第二幀中的像素到它們的對(duì)應(yīng)核線的距離,其中核線使用光流從匹配像素中導(dǎo)出。
最后通過(guò)距離閾值化來(lái)執(zhí)行動(dòng)態(tài)分割。經(jīng)過(guò)幾次迭代后,動(dòng)態(tài)像素被移除,僅具有靜態(tài)像素的RGB-D圖像被傳遞到基于點(diǎn)的融合中進(jìn)行重建。
圖3所示的動(dòng)態(tài)稠密框架基于的思想是:如果場(chǎng)景中沒(méi)有動(dòng)態(tài)物體,那么第二幀圖像中的每個(gè)像素應(yīng)該在其第一幀圖像匹配像素的核線上。 在這種情況下,可以使用給定的相機(jī)位姿、光流和內(nèi)在特性進(jìn)行分割,而不是將第一幀圖像直接投影到第二幀。這種方法也被作者稱為"運(yùn)動(dòng)一致性"檢測(cè)。
圖5所示是運(yùn)動(dòng)一致性的細(xì)節(jié)檢測(cè)原理。該算法首先獲得匹配的像素對(duì),即每對(duì)圖像中的像素直接施加光流矢量到第一幀上,并計(jì)算具有匹配像素對(duì)的基礎(chǔ)矩陣。 然后,再計(jì)算每個(gè)像素的對(duì)應(yīng)核線基本矩陣和像素的位置。當(dāng)?shù)诙衅ヅ湎袼嘏c它的核線大于閾值時(shí),它被分類作為動(dòng)態(tài)像素。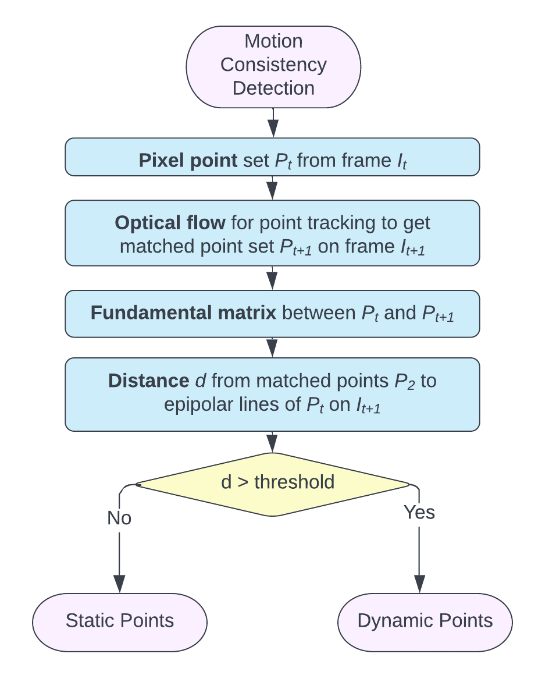
圖5 運(yùn)動(dòng)一致性檢測(cè)的算法原理
3.2 迭代和融合
在RGB-D圖像中僅剩下靜態(tài)像素后,作者迭代地將其傳遞回TartanVO進(jìn)行改進(jìn)光流估計(jì),從而獲得更精確的相機(jī)姿態(tài)。理想情況下,通過(guò)足夠的迭代,分割掩模將移除與動(dòng)態(tài)對(duì)象相關(guān)聯(lián)的所有像素,并且僅在圖像中留下靜態(tài)背景。 同時(shí)作者發(fā)現(xiàn),即使使用粗糙的掩模,仍然可以提高TartanVO的ATE。另外,如果粗掩模允許一些動(dòng)態(tài)像素進(jìn)入最終重建,那么它們將很快從地圖中移除。
經(jīng)過(guò)固定次數(shù)的迭代后,將去除了大多數(shù)動(dòng)態(tài)像素的細(xì)化圖像對(duì)與其對(duì)應(yīng)的深度對(duì)一起進(jìn)行融合。數(shù)據(jù)融合首先將輸入深度圖中的每個(gè)點(diǎn)與全局圖中的點(diǎn)集投影關(guān)聯(lián),使用的方法是將深度圖渲染為索引圖。 如果找到相應(yīng)的點(diǎn),則使用加權(quán)平均將最可靠的點(diǎn)與新點(diǎn)估計(jì)合并。
如果沒(méi)有找到可靠的對(duì)應(yīng)點(diǎn),則估計(jì)的新點(diǎn)作為不穩(wěn)定點(diǎn)被添加到全局圖中。
隨著時(shí)間的推移,清理全局地圖,以去除由于可見(jiàn)性和時(shí)間約束導(dǎo)致的異常值,這也確保了來(lái)自分割的假陽(yáng)性點(diǎn)將隨著時(shí)間的推移而被丟棄。因?yàn)樽髡呃贸砻艿墓饬鞑⒃诿總€(gè)像素上分割圖像而不進(jìn)行下采樣,所以算法可以重建稠密的RGB-D全局圖。
4. 實(shí)驗(yàn)
作者使用TUM數(shù)據(jù)集中的freiburg3行走xyz序列,圖6和圖7所示為使用2D場(chǎng)景流的分割結(jié)果。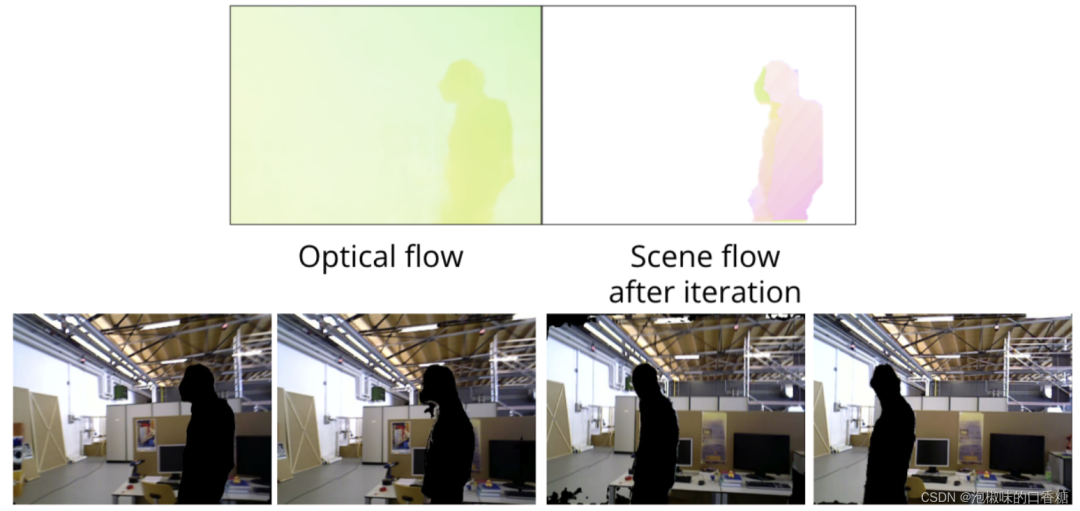
圖6 基于2D場(chǎng)景流動(dòng)態(tài)分割向左移動(dòng)的對(duì)象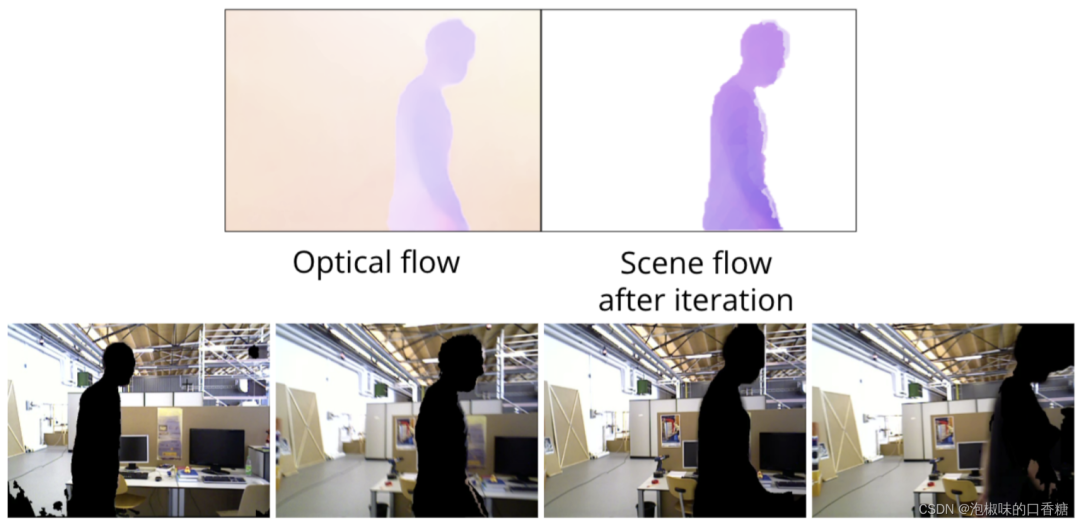
圖7 基于2D場(chǎng)景流動(dòng)態(tài)分割向右移動(dòng)的對(duì)象
隨后,作者迭代地將重新渲染的圖像對(duì)傳遞回TartanVO。作者認(rèn)為這一操作將改進(jìn)光流估計(jì),并且獲得更精確的相機(jī)姿態(tài),如圖8所示是實(shí)驗(yàn)結(jié)果。其中左圖是使用原始TartanVO的絕對(duì)軌跡誤差,右圖是使用改進(jìn)TartanVO的絕對(duì)軌跡誤差。實(shí)驗(yàn)結(jié)果顯示,如果有足夠的迭代,分割過(guò)程將移除動(dòng)態(tài)物體中的大多數(shù)像素,并且僅保留靜態(tài)背景。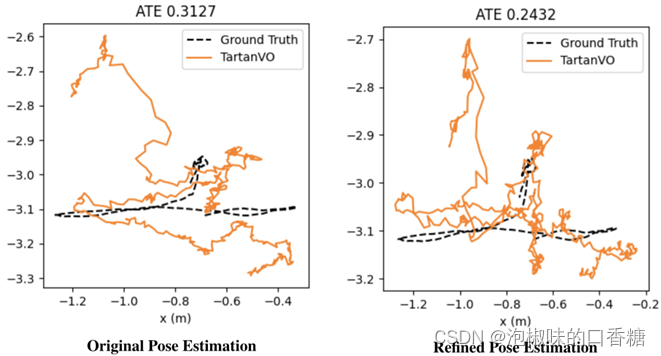
圖8 原始TartanVO和回環(huán)優(yōu)化的軌跡誤差對(duì)比結(jié)果
圖9所示是在TUM整個(gè)freiburg3行走xyz序列上的重建結(jié)果,結(jié)果顯示動(dòng)態(tài)對(duì)象(兩個(gè)移動(dòng)的人)已經(jīng)從場(chǎng)景中移除,只有靜態(tài)背景存儲(chǔ)在全局地圖中。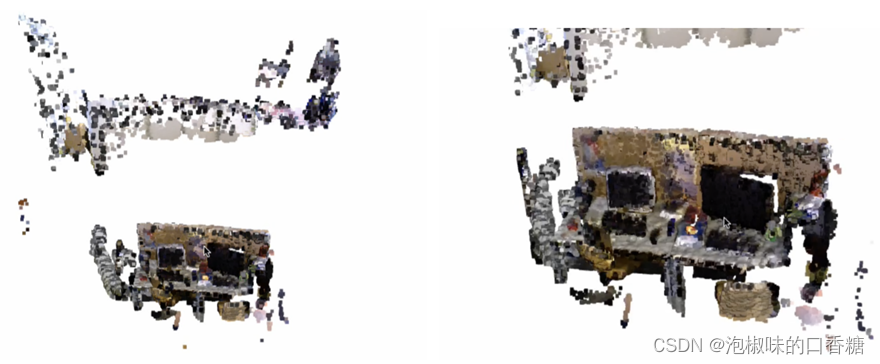
圖9 基于點(diǎn)融合的三維重建結(jié)果
此外,為了進(jìn)行不同方法的對(duì)比,作者首先嘗試掩蔽原始圖像以濾除對(duì)應(yīng)于3D中的動(dòng)態(tài)點(diǎn)的像素,然后,在此之上嘗試用在先前圖像中找到的匹配靜態(tài)像素來(lái)修補(bǔ)空缺,但降低了精度。與產(chǎn)生0.1248的ATE的TartanVO方法相比,原始掩蔽方法產(chǎn)生了更理想的光流,而修補(bǔ)方法產(chǎn)生因?yàn)楫a(chǎn)生過(guò)多的偽像而阻礙了光流的計(jì)算。如圖10所示是對(duì)比結(jié)果。
圖10 tartan VO的三種輸入類型對(duì)比
5.結(jié)論
在2022 CVPR論文"Dynamic Dense RGB-D SLAM using Learning-based Visual Odometry"中,作者提出了一種全新的動(dòng)態(tài)稠密RGB-D SLAM框架,它是一種基于學(xué)習(xí)視覺(jué)里程計(jì)的方法,用于重建動(dòng)態(tài)運(yùn)動(dòng)物體干擾下的靜態(tài)地圖。重要的是,算法已經(jīng)開源,讀者可在開源代碼的基礎(chǔ)上進(jìn)行二次開發(fā)。
此外,作者也提到了基于該論文的幾個(gè)重要的研究方向:
(1) 引入自適應(yīng)閾值機(jī)制,通過(guò)利用流、姿態(tài)和地圖等來(lái)為分割提供更一致的閾值。
(2) 在預(yù)訓(xùn)練的基于學(xué)習(xí)的視覺(jué)里程計(jì)中,使用對(duì)相機(jī)姿態(tài)和光流的BA來(lái)補(bǔ)償大范圍運(yùn)動(dòng)感知。
(3) 使用動(dòng)態(tài)感知迭代最近點(diǎn)(ICP)算法來(lái)代替TartanVO中的姿態(tài)網(wǎng)絡(luò)。
(4) 在更多樣化的數(shù)據(jù)集上進(jìn)行測(cè)試和迭代,以提供更好的魯棒性。
審核編輯:劉清
-
RGB
+關(guān)注
關(guān)注
4文章
798瀏覽量
58462 -
SLAM
+關(guān)注
關(guān)注
23文章
423瀏覽量
31823 -
ATE
+關(guān)注
關(guān)注
5文章
124瀏覽量
26622 -
ICP
+關(guān)注
關(guān)注
0文章
70瀏覽量
12778
原文標(biāo)題:基于學(xué)習(xí)視覺(jué)里程計(jì)的動(dòng)態(tài)稠密RGB-D SLAM
文章出處:【微信號(hào):3D視覺(jué)工坊,微信公眾號(hào):3D視覺(jué)工坊】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
從基本原理到應(yīng)用的SLAM技術(shù)深度解析
SLAM技術(shù)的應(yīng)用及發(fā)展現(xiàn)狀
視覺(jué)SLAM特征點(diǎn)法與直接法對(duì)比分析
求一種基于嵌入式系統(tǒng)和Internet的FPGA動(dòng)態(tài)配置方案
一種基于動(dòng)態(tài)口令和動(dòng)態(tài)ID的遠(yuǎn)程認(rèn)證方案
一種適用于動(dòng)態(tài)場(chǎng)景的SLAM方法

一種基于RBPF的、優(yōu)化的激光SLAM算法

基于增強(qiáng)動(dòng)態(tài)稠密軌跡特征的視頻布料材質(zhì)識(shí)別
基于增強(qiáng)動(dòng)態(tài)稠密軌跡特征的布料材質(zhì)識(shí)別技術(shù)
一種快速的激光視覺(jué)慣導(dǎo)融合的slam系統(tǒng)
關(guān)于視覺(jué)SLAM直接法的介紹
3D重建的SLAM方案算法解析

一種適用于動(dòng)態(tài)環(huán)境的實(shí)時(shí)視覺(jué)SLAM系統(tǒng)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論