 改進Hinton的Dropout:可以用來減輕欠擬合了
改進Hinton的Dropout:可以用來減輕欠擬合了
深度學習三巨頭之一 Geoffrey Hinton 在 2012 年提出的 dropout 主要用來解決過擬合問題,但近日的一項工作表明,dropout 能做的事情不止于此。
2012 年,Hinton 等人在其論文《Improving neural networks by preventing co-adaptation of feature detectors》中提出了 dropout。同年,AlexNet 的出現開啟了深度學習的新紀元。AlexNet 使用 dropout 顯著降低了過擬合,并對其在 ILSVRC 2012 競賽中的勝利起到了關鍵作用。可以這么說,如果沒有 dropout,我們目前在深度學習領域看到的進展可能會被推遲數年。
自 dropout 推出以后,它被廣泛用作正則化器,降低神經網絡中的過擬合。dropout 使用概率 p 停用每個神經元,防止不同的特征相互適應。應用 dropout 之后,訓練損失通常增加,而測試誤差減少,從而縮小模型的泛化差距。深度學習的發展不斷引入新的技術和架構,但 dropout 依然存在。它在最新的 AI 成果中繼續發揮作用,比如 AlphaFold 蛋白質預測、DALL-E 2 圖像生成等,展現出了通用性和有效性。
盡管 dropout 持續流行,但多年來其強度(以drop rate p 表示)一直在下降。最初的 dropout 工作中使用了 0.5 的默認drop rate。然而近年來常常采用較低的drop rate,比如 0.1,相關示例可見訓練 BERT 和 ViT。這一趨勢的主要動力是可用訓練數據的爆炸式增長,使得過擬合越來越困難。加之其他因素,我們可能很快會遇到更多欠擬合而非過擬合問題。
近日在一篇論文《Dropout Reduces Underfitting》中,Meta AI、加州大學伯克利分校等機構的研究者展示了如何使用 dropout 來解決欠擬合問題。

論文標題:
Dropout Reduces Underfitting
論文鏈接:
https://arxiv.org/abs/2303.01500
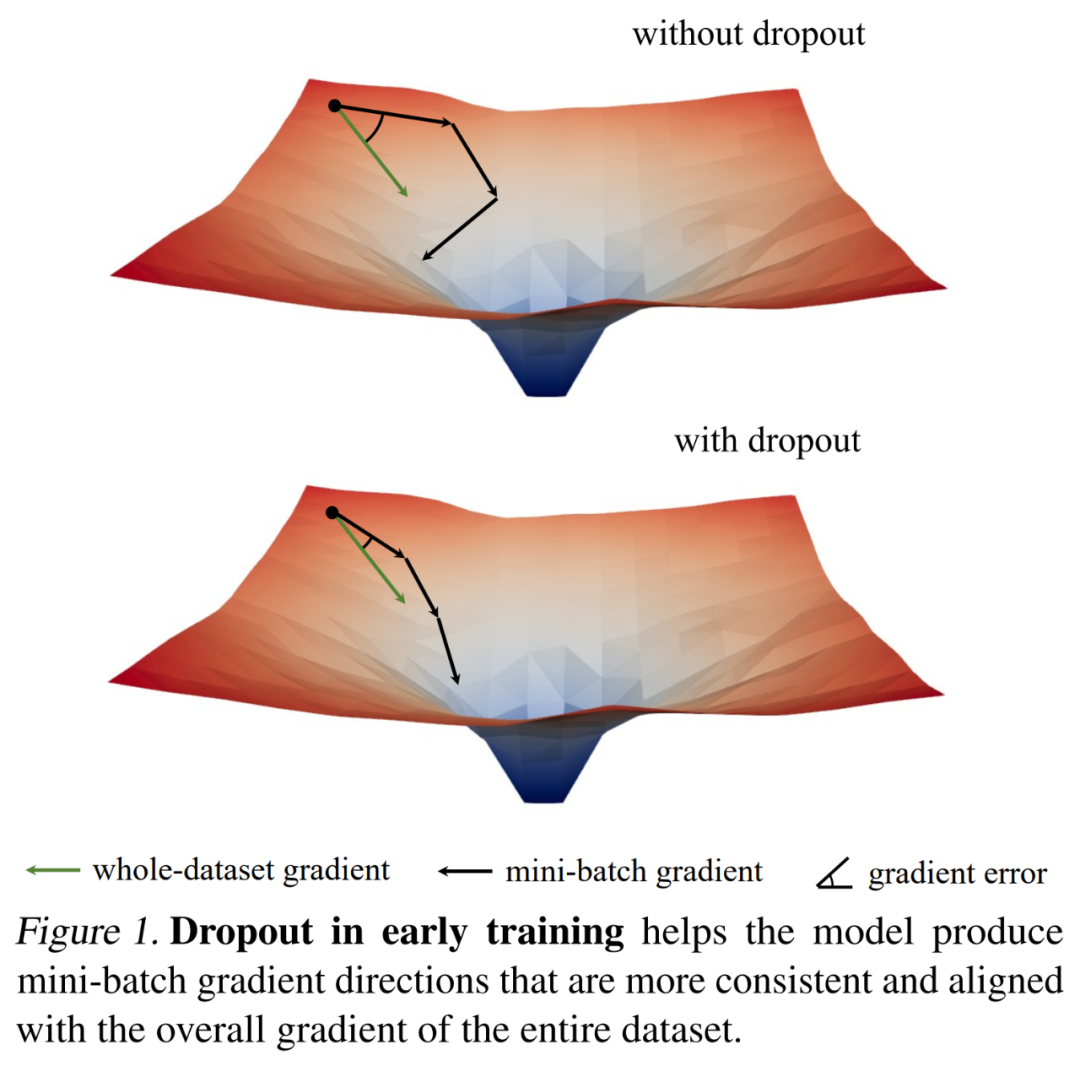
他們首先通過對梯度范數的有趣觀察來研究 dropout 的訓練動態,然后得出了一個關鍵的實證發現:在訓練初始階段,dropout 降低小批量的梯度方差,并允許模型在更一致的方向上更新。這些方向也更與整個數據集的梯度方向保持一致,具體如下圖 1 所示。
因此,模型可以更有效地優化整個訓練集的訓練損失,而不會受到個別小批量的影響。換句話說,dropout 抵消了隨機梯度下降(SGD)并防止訓練早期采樣小批量的隨機性所造成的過度正則化。
基于這一發現,研究者提出了 early dropout(即 dropout 僅在訓練早期使用),來幫助欠擬合模型更好地擬合。與無 dropout 和標準 dropout 相比,early dropout 降低了最終的訓練損失。相反,對于已經使用標準 dropout 的模型,研究者建議在早期訓練 epoch 階段移除 dropout 以降低過擬合。他們將這一方法稱為 late dropout,并證明它可以提升大模型的泛化準確率。下圖 2 比較了標準 dropout、early 和 late dropout。

研究者在圖像分類和下游任務上使用不同的模型來評估 early dropout 和 late dropout,結果顯示二者始終比標準 dropout 和無 dropout 產生了更好的效果。他們希望自己的研究發現可以為 dropout 和過擬合提供新穎的見解,并激發人們進一步開發神經網絡正則化器。
分析與驗證
在提出 early dropout 和 late dropout 之前,該研究探討了是否可以使用 dropout 作為減少欠擬合的工具。該研究使用其提出的工具和指標對 dropout 的訓練動態進行了詳細分析,并比較了 ImageNet 上兩個 ViT-T/16 的訓練過程(Deng et al., 2009):一個沒有 dropout 作為基線;另一個在整個訓練過程中有 0.1 的 dropout 率。
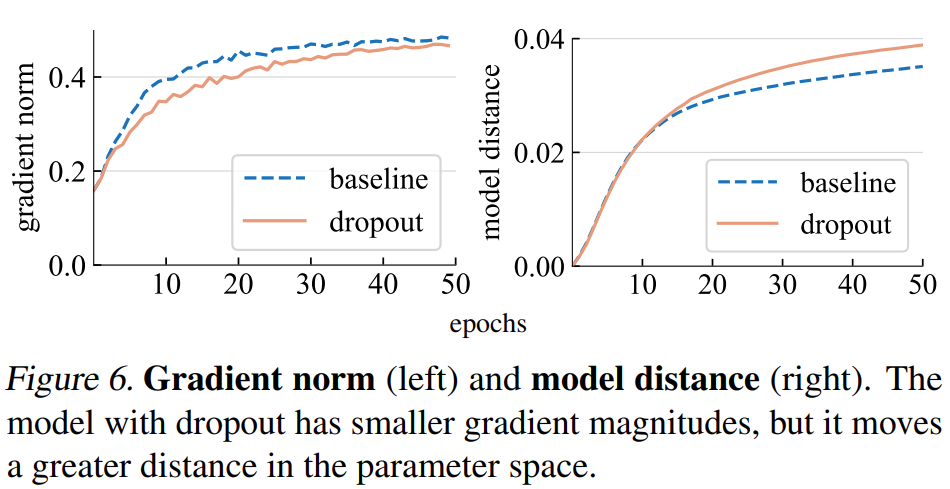
梯度范數(norm)。該研究首先分析了 dropout 對梯度 g 強度的影響。如下圖 6(左)所示,dropout 模型產生范數較小的梯度,表明它在每次梯度更新時采用較小的步長(step)。
模型距離。由于梯度步長更小,我們期望 dropout 模型相對于其初始點移動的距離比基線模型更小。如下圖 6(右)所示,該研究繪制了每個模型與其隨機初始化的距離。然而,令人驚訝的是,dropout 模型實際上比基線模型移動了更大的距離,這與該研究最初基于梯度范數的預期相反。
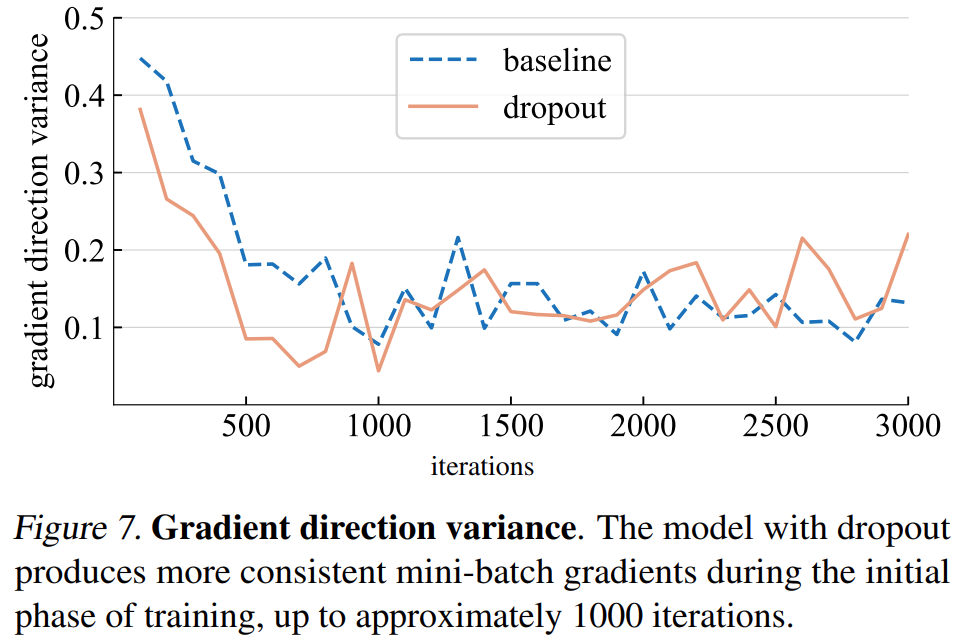
梯度方向方差。該研究首先假設 dropout 模型在小批量中產生更一致的梯度方向。下圖 7 所示的方差與假設基本一致。直到一定的迭代次數(大約 1000 次)以后,dropout 模型和基線模型的梯度方差都在一個較低的水平波動。
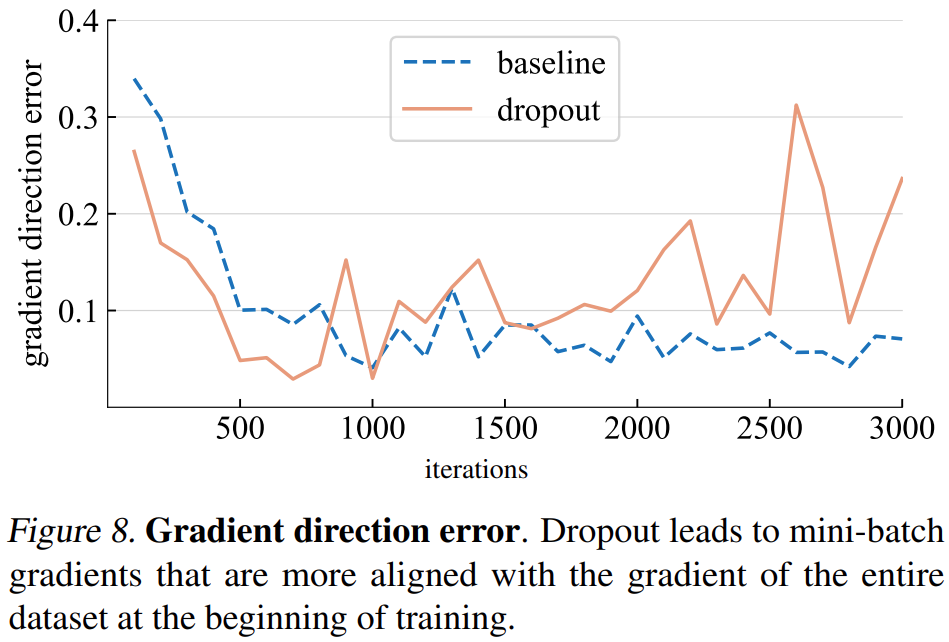
梯度方向誤差。然而,正確的梯度方向應該是什么?為了擬合訓練數據,基本目標是最小化整個訓練集的損失,而不僅僅是任何一個小批量的損失。該研究在整個訓練集上計算給定模型的梯度,其中 dropout 設置為推理模式以捕獲完整模型的梯度。梯度方向誤差如下圖 8 所示。
基于上述分析,該研究發現盡早使用 dropout 可以潛在地提高模型對訓練數據的擬合能力。而是否需要更好地擬合訓練數據取決于模型是處于欠擬合還是過擬合狀態,這可能很難精確定義。該研究使用如下標準:
1. 如果一個模型在標準 dropout 下泛化得更好,則認為它處于過擬合狀態;
2. 如果模型在沒有 dropout 的情況下表現更好,則認為它處于欠擬合狀態。
模型所處的狀態不僅取決于模型架構,還取決于所使用的數據集和其他訓練參數。
然后,該研究提出了 early dropout 和 late dropout 兩種方法:
early dropout:在默認設置下,欠擬合狀態下的模型不使用 dropout。為了提高其適應訓練數據的能力,該研究提出 early dropout:在某個迭代之前使用 dropout,然后在其余的訓練過程中禁用 dropout。該研究實驗表明,early dropout 減少了最終的訓練損失并提高了準確性。
late dropout:過擬合模型的訓練設置中已經包含了標準的 dropout。在訓練的早期階段,dropout 可能會無意中造成過擬合,這是不可取的。為了減少過擬合,該研究提出 late dropout:在某個迭代之前不使用 dropout,而是在其余的訓練中使用 dropout。
該研究提出的方法在概念和實現上都很簡單,如圖 2 所示。實現時需要兩個超參數:1) 在打開或關閉 dropout 之前等待的 epoch 數;2)drop rate p,類似于標準的 dropout rate。該研究表明,這兩種超參數可以保證所提方法的穩健性。
實驗及結果
研究者在具有 1000 個類和 1.2M 張訓練圖像的 ImageNet-1K 分類數據集上進行了實證評估,并報告了 top-1 驗證準確率。
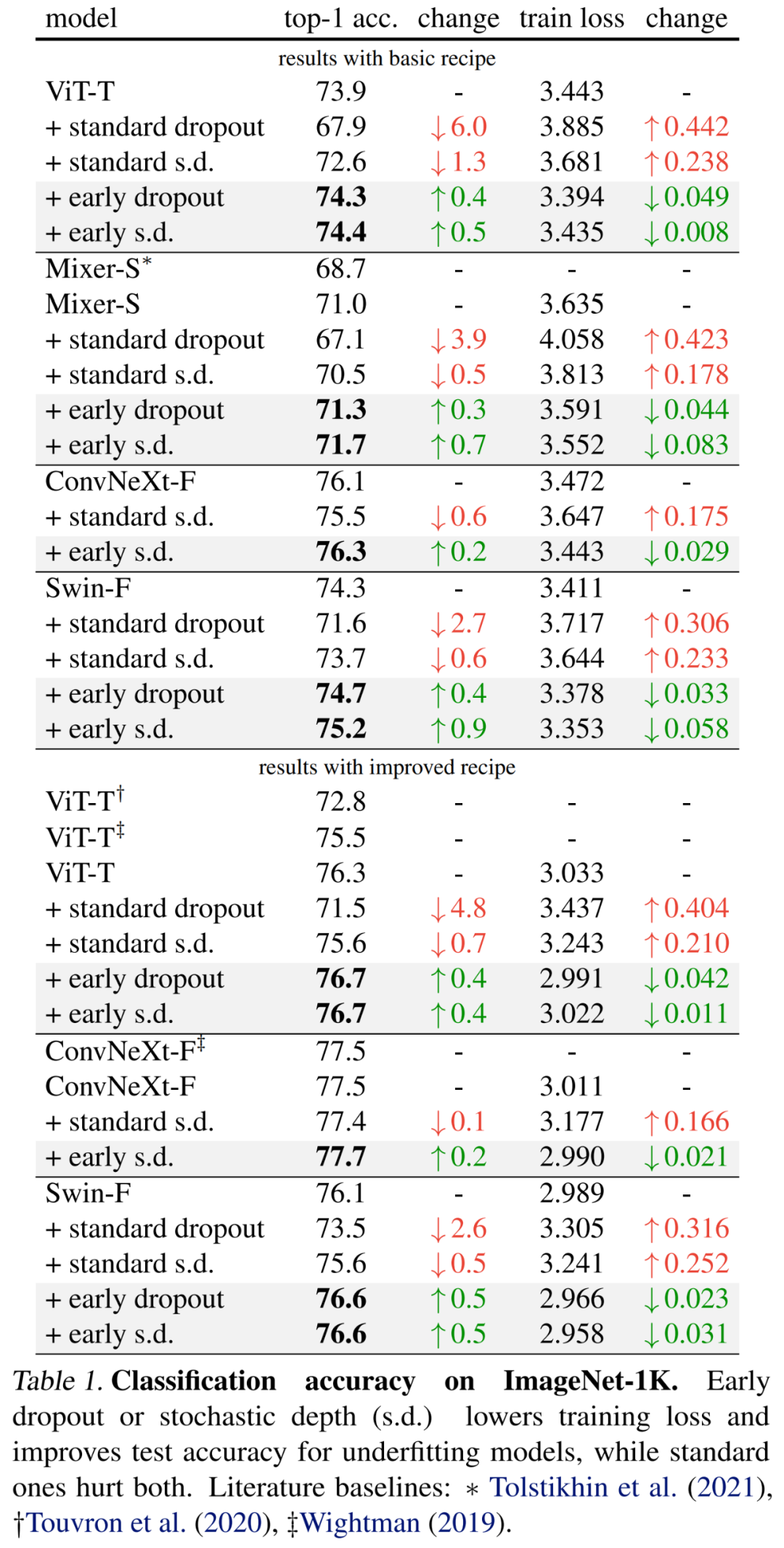
具體結果首先如下表 1(上部)所示,early dropout 持續提升測試準確率,降低訓練損失,表明早期階段的 dropout 有助于模型更好地擬合數據。研究者還展示了使用 drop rate 為 0.1 時與標準 dropout、隨機深度(s.d.)的比較結果,這兩者都對模型具有負面影響。
此外,研究者將訓練 epoch 增加一倍并減少 mixup 和 cutmix 強度,從而改進了這些小模型的方法。下表 1(底部)的結果表明,基線準確率顯著提升,有時甚至大大超越了以往工作的結果。
為了評估 late dropout,研究者選擇了更大的模型,即分別具有 59M 和 86M 參數的 ViT-B 和 Mixer-B,使用了基礎的訓練方法。
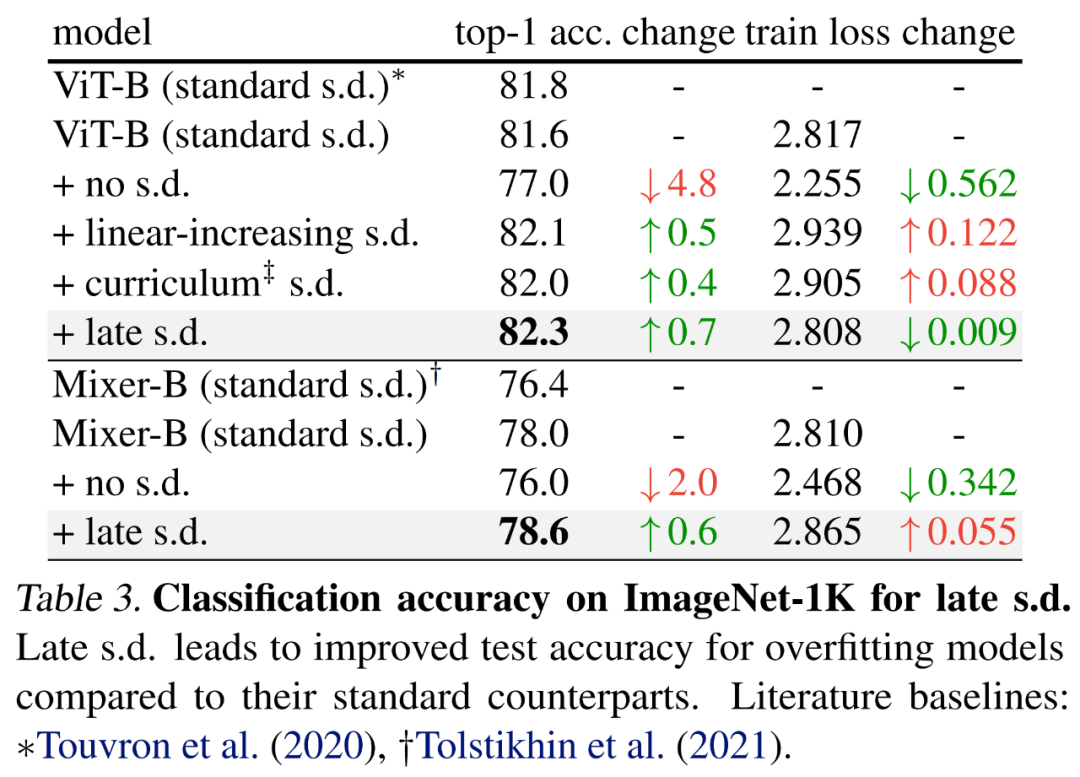
結果如下表 3 所示,與標準 s.d. 相比,late s.d. 提升了測試準確率。這一提升是在保持 ViT-B 或增加 Mixer-B 訓練損失的同時實現的,表明 late s.d. 有效降低了過擬合。
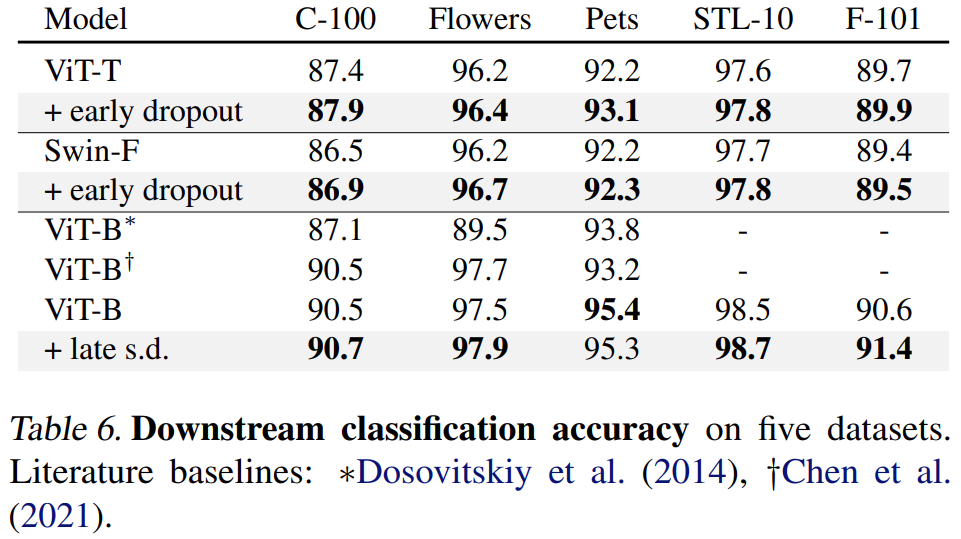
最后,研究者在下游任務上對預訓練 ImageNet-1K 模型進行微調,并對它們進行評估。下游任務包括 COCO 目標檢測與分割、ADE20K 語義分割以及在 C-100 等五個數據集上的下游分類。目標是在微調階段不使用 early dropout 或 late dropout 的情況下評估學得的表示。
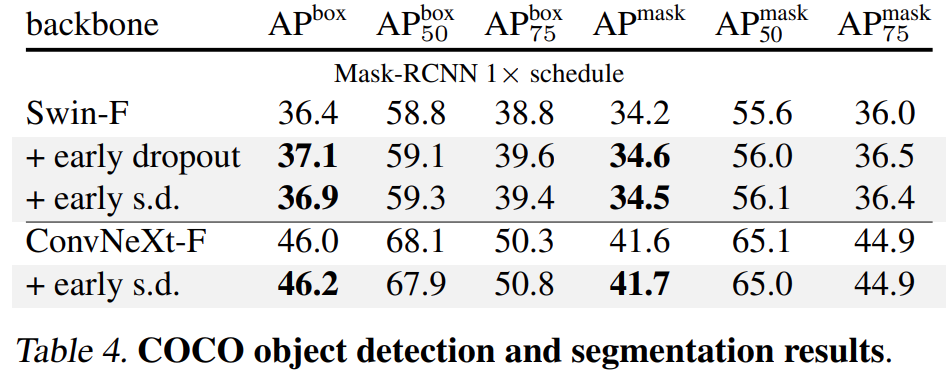
結果如下表 4、5 和 6 所示,首先當在 COCO 上進行微調時,使用 early dropout 或 s.d. 進行預訓練的模型始終保持優勢。
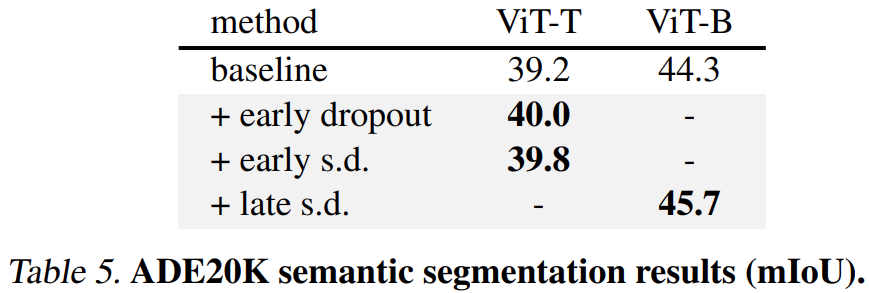
其次對于 ADE20K 語義分割任務而言,使用本文方法進行預訓練的模型優于基準模型。
最后是下游分類任務,本文方法在大多數分類任務上提升了泛化性能。
審核編輯 :李倩
-
模型
+關注
關注
1文章
3229瀏覽量
48810 -
數據集
+關注
關注
4文章
1208瀏覽量
24689 -
深度學習
+關注
關注
73文章
5500瀏覽量
121113
原文標題:改進Hinton的Dropout:可以用來減輕欠擬合了
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
欠壓保護電路的少許改進方案
機器學習基礎知識 包括評估問題,理解過擬合、欠擬合以及解決問題的技巧
深度學習中過擬合/欠擬合的問題及解決方案
MP3不僅是用來聽的,也可以用來玩的
基于動態dropout的改進堆疊自動編碼機方法
Python編程一般可以用來做什么
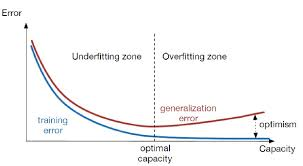
深度學習中過擬合、欠擬合問題及解決方案
cbb電容可以用來阻容降壓嗎






 工商網監
工商網監
評論