 ELMER: 高效強大的非自回歸預訓練文本生成模型
ELMER: 高效強大的非自回歸預訓練文本生成模型
本文介紹了小組發表于EMNLP 2022的非自回歸預訓練文本生成模型ELMER,在生成質量與生成效率方面相比于之前的研究具有很大優勢。

一、背景
自從GPT-2的出現,預訓練語言模型在許多文本生成任務上都取得了顯著的效果。這些預訓練語言模型大都采用自回歸的方式從左到右依次生成單詞,這一范式的主要局限在于文本生成的過程難以并行化,因此帶來較大的生成延遲,這也限制了自回歸模型在許多實時線上應用的廣泛部署(例如搜索引擎的查詢重寫、在線聊天機器人等)。并且,由于訓練過程與生成過程存在差異,自回歸生成模型容易出現曝光偏差等問題。因此,在這一背景下,許多研究者開始關注非自回歸生成范式——所有文本中的單詞同時且獨立地并行生成。
與自回歸模型相比,非自回歸模型的生成過程具有并行化、高效率、低延遲等優勢,但與此同時,所有單詞獨立生成的模式使得非自回歸模型難以學習單詞間依賴關系,導致生成文本質量下降等問題。已有研究提出迭代生成優化、隱變量建模文本映射等方法,但仍然難以生成復雜的文本。受到早期退出技術(early exit)啟發,我們提出一個高效強大的非自回歸預訓練文本生成模型——ELMER,通過在不同層生成不同單詞的方式顯式建模單詞間依賴關系,從而提升并行生成的效果。
二、形式化定義
文本生成的目標是建模輸入文本與輸出文本 之間的條件概率 。目前常用的三種生成范式為:自回歸、非自回歸和半非自回歸范式。
自回歸生成自回歸生成模型基于從左到右的方式生成輸出文本:
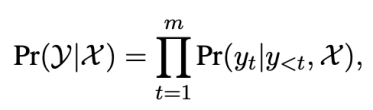
每個單詞都依賴于輸入文本與之前生成的單詞。自回歸生成模型只建模了前向的單詞依賴關系,依次生成的結構也使得自回歸模型難以并行化。目前大部分預訓練生成模型均采用自回歸方式,包括GPT-2,BART,T5等模型。
非自回歸生成非自回歸生成模型同時預測所有位置的單詞,不考慮前向與后向的單詞依賴關系:
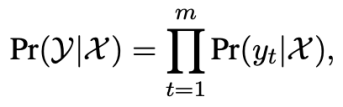
每個單詞的生成只依賴于輸入文本,這一獨立生成假設使得非自回歸模型易于并行化,大大提高了文本生成速度。由于不考慮單詞依賴,非自回歸模型的生成效果往往不如自回歸模型。
半非自回歸生成半非自回歸生成模型介于自回歸與非自回歸生成之間:
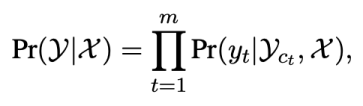
每個單詞的生成依賴于輸入文本和部分可見上下文,其中采用不同方式平衡生成質量與生成效率。
三、模型
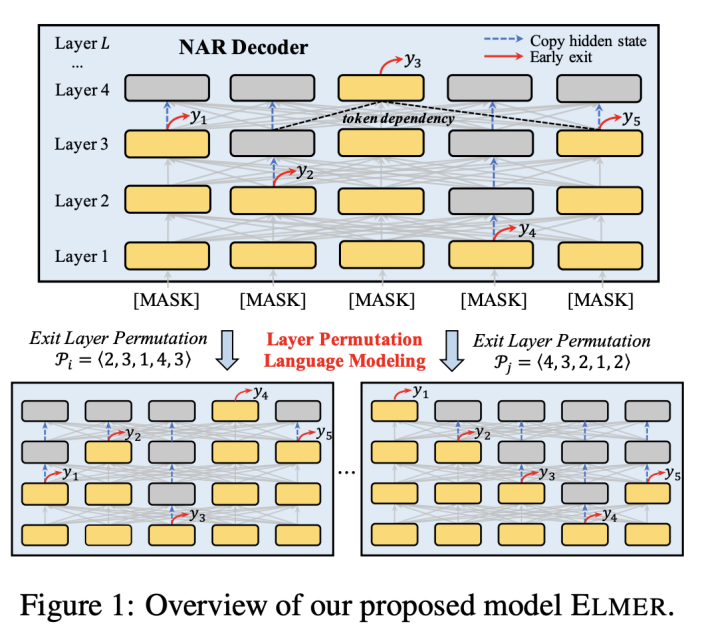
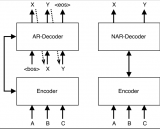
ELMER模型架構如圖1所示。基于早期退出機制(early exit),在不同層生成的單詞可以建立雙向的單詞依賴關系。為了預訓練ELMER,我們提出了一個用于非自回歸生成廣泛建模單詞依賴的預訓練任務——Layer Permutation Language Modeling。
基于早期退出的Transformer非自回歸生成
ELMER采用Transformer架構,不同的是我們將解碼器中的掩碼多頭注意力替換為與編碼器一致的雙向多頭注意力用于非自回歸生成。特別地,對于數據,輸入文本由編碼器編碼為隱狀態,然后,我們將一段完全由“[MASK]”單詞組成的序列作為解碼器輸入,生成目標文本。對于每一個“[MASK]”單詞,經過層解碼器得到:
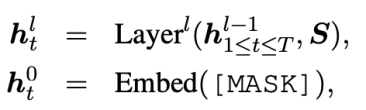
最后,第個單詞由最后一層表示計算得到:

之前的非自回歸模型需要額外模塊預測輸出文本的長度,但是,我們通過生成終止單詞“[EOS]”動態地確定生成文本的長度,即最終的文本為首單詞至第一個終止單詞。
一般的Transformer模型都在最后一層生成單詞,使用早期退出技術,單詞以足夠的置信度在低層被生成,那么高層單詞的生成可以依賴已生成的低層單詞,從而在非自回歸生成過程中建模雙向的單詞依賴關系。特別地,我們在Transformer每一層插入“off-ramp”,其使用每一層隱狀態表示預測單詞如下:
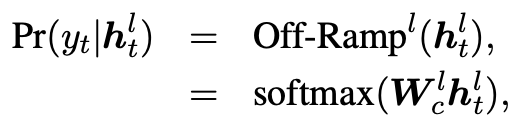
這些“off-ramp”可以獨立或者共享參數。與之前的早期退出研究聚焦于句子級別不同,我們的方法關注單詞級別的退出。在訓練過程中,如果一個單詞已經以足夠的置信度在第層生成,那么隱狀態將不會在高層中進行更新,我們的模型將直接拷貝至高層。
Layer Permutation預訓練
為了在預訓練中學習多樣化的單詞依賴關系,我們提出基于早退技術的預訓練目標——Layer Permutation Language Modeling (LPLM),對每個單詞的退出層進行排列組合。對于長度為的序列,每個單詞可以在層的任意一層退出,因此,這一序列所有單詞的退出層共有種排列組合。如果模型的參數對于所有組合是共享的,那么每個單詞都可以學習到來自所有位置的單詞的依賴關系。形式化地,令表示長度為的序列的所有可能的退出層組合,對于任意一個組合,基于LPLM的非自回歸文本生成概率可以表示為:
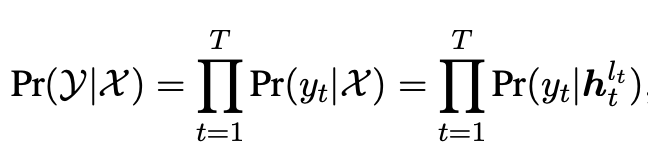
其中模型在解碼器第層退出,使用隱狀態預測第個單詞。
在預訓練過程中,對于語料中的每一條文本,我們只采樣中退出層組合計算生成概率。傳統的早期退出方法需要計算閾值來估計退出層,這對于大規模預訓練來說是不方便的,而我們提出的LPLM預訓練目標自然而然地避免了對退出層的估計。遵循BART模型的預訓練模式,我們將打亂的文本輸入模型并采用基于LPLM的非自回歸生成方式還原文本,我們主要采用sentence shuffling和text infilling兩種打亂方式。
下游微調
經過預訓練的非自回歸生成模型ELMER可以微調至下游各種文本生成任務。在微調階段,可以使用小規模的任務數據集為每個生成單詞估計其退出層。在論文中,我們主要考慮兩種早期退出方式:hard early exit與soft early exit。
1)Hard Early Exit:這是一種最簡單直接的早期退出方式。通過設置閾值并計算退出置信度決定模型是否在某層退出結束生成。我們使用生成概率分布的熵來量化單詞生成的退出置信度,如下式:
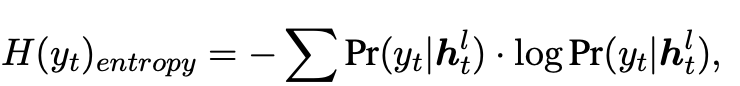
模型生成概率分布的熵越低,意味著生成單詞的退出置信度越高。因此,當熵低于事先設定的閾值時,模型將在此層退出并生成單詞。
2)Soft Early Exit:上述方法對于每個單詞只退出一次并生成,因此會發生錯誤生成的情況。而soft方法則在每一層都計算單詞生成概率,并將中間層生成的單詞傳遞至下一層繼續進行計算。特別地,在位置解碼器的第層,我們使用第層的off-ramp計算生成單詞:
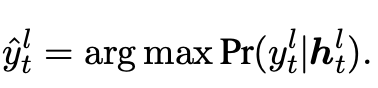
然后,我們將預測單詞的向量與當前層的隱狀態拼接,經過一個線性層傳遞至下一層作為新的表示:

與hard方法相比,soft方法在每層預測單詞,并將預測結果傳遞至下一次預測,因此可以起到修正預測的作用。
四、實驗
1)預訓練設置
我們收集了16G的數據(包括Wikipedia和BookCorpus)作為預訓練語料。ELMER采用6層的編碼器與解碼器,隱藏層維度為768,與大部分自回歸(例如BART)與非自回歸(BANG)預訓練生成模型的base版本一致。我們使用2e-4的學習率從頭開始訓練模型,批大小為4096。我們采用BART模型的詞表,在預訓練過程中共享所有層的off-ramp參數,預訓練語料中的每條序列采樣10種退出層組合進行訓練。相關代碼與模型已開源至https://github.com/RUCAIBox/ELMER.
2)微調數據集
我們微調ELMER至三種文本生成任務與數據集:XSUM為摘要任務數據集,SQuAD v1.1為問題生成任務數據集,PersonaChat為對話生成任務數據集。
3)基準模型
實驗中設置三類基準模型作為對比:1)自回歸生成模型:Transformer,MASS,BART和ProphetNet;2)非自回歸生成模型:NAT,iNAT,CMLM,LevT和BANG;3)半非自回歸生成模型:InsT,iNAT,CMLM,LevT和BANG。
4)評測指標
我們從effectiveness與efficiency兩個方面評測模型效果。我們使用ROUGE,BLEU,METEOR和Distinct來評測模型生成文本的effectiveness;設置生成批大小為1并計算每條樣本的生成時間來評測模型生成文本的efficiency。
5)實驗結果
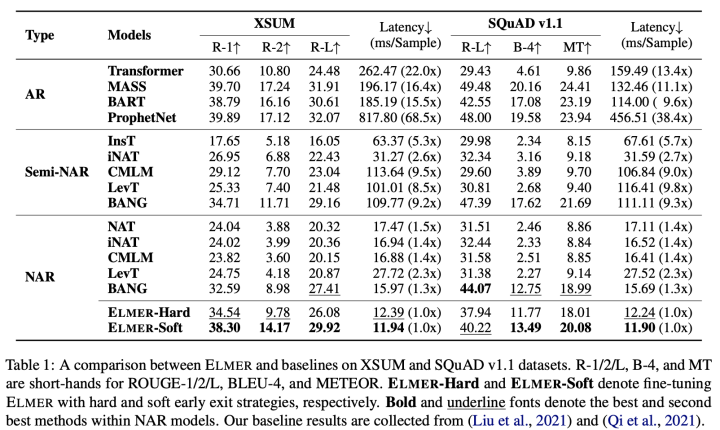
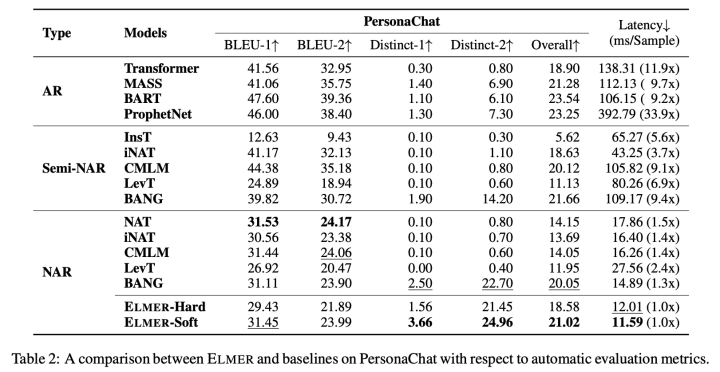
表1與表2展示了在三個任務和數據集上的實驗結果。我們的ELMER-soft方法超越了大部分非自回歸與半非自回歸生成模型,展示出我們的模型在生成文本上的有效性。相比于基準模型,我們的模型采用早期退出技術,可以在并行生成過程中建模單詞間依賴關系,保證了生成文本的質量。
除此以外,ELMER取得了與自回歸預訓練模型相似的結果,并超越了非預訓練的Transformer模型,進一步縮小了非自回歸生成模型與自回歸生成模型在生成質量上的差距。對于對話任務,雖然ELMER在ROUGE,BLEU等指標不如NAT等模型,但非常重要的Distinct指標卻表現很好,說明我們方法能夠生成較為多樣的文本。
最后,在生成文本的效率上,ELMER的生成效率相比自回歸模型具有非常大的優勢,對比其他非自回歸模型如LevT也具有更快的生成速度。
五、結論
我們提出了一個高效強大的非自回歸預訓練文本生成模型ELMER,通過引入單詞級別的早期退出機制,模型可以在并行生成文本的過程中顯式建模前后單詞依賴關系。更重要的,我們提出了一個新的預訓練目標——Layer Permutation Language Modeling,對序列中每個單詞的退出層進行排列組合。最后,在摘要、問題生成與對話三個任務上的實驗結果表明,我們的ELMER模型無論是生成質量還是生成效率都具有極大優勢。
審核編輯 :李倩
-
模型
+關注
關注
1文章
3226瀏覽量
48807 -
語言模型
+關注
關注
0文章
520瀏覽量
10268 -
聊天機器人
+關注
關注
0文章
339瀏覽量
12304
原文標題:EMNLP 2022 | ELMER: 高效強大的非自回歸預訓練文本生成模型
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【大語言模型:原理與工程實踐】揭開大語言模型的面紗
【大語言模型:原理與工程實踐】大語言模型的預訓練
如何構建文本生成器?如何實現馬爾可夫鏈以實現更快的預測模型
基于生成器的圖像分類對抗樣本生成模型

文本生成任務中引入編輯方法的文本生成

受控文本生成模型的一般架構及故事生成任務等方面的具體應用
利用對比前綴控制文本生成以及長文本生成的動態內容規劃
基于VQVAE的長文本生成 利用離散code來建模文本篇章結構的方法
預訓練數據大小對于預訓練模型的影響
一種非自回歸的預訓練方法
從原理到代碼理解語言模型訓練和推理,通俗易懂,快速修煉LLM
大語言模型的預訓練
榮聯科技集團再度入選信通院《高質量數字化轉型產品及服務全景圖》






 工商網監
工商網監
評論