 羅列一些在不同操作系統中比較常見的文件系統
羅列一些在不同操作系統中比較常見的文件系統
當提到文件系統時,大部分人都很陌生。但實際上我們幾乎每天都會使用它。比如,大家打開 Windows、macOS 或者 Linux,不管是用資源管理器還是 Finder,都是在和文件系統打交道。
如果大家曾經手動安裝過操作系統,一定會記得在第一次安裝時需要格式化磁盤,格式化時就需要為磁盤選擇使用哪個文件系統。
維基百科上的關于文件系統[1]的定義是:
In computing, file system is a method and data structure that the operating system uses to control how data is stored and retrieved.
簡而言之,文件系統的任務是管理存儲介質(例如磁盤、SSD、CD、磁帶等)上的數據。
在文件系統中最基礎的概念就是文件和目錄,所有的數據都會對應一個文件,通過目錄以樹形結構來管理和組織這些數據。
基于文件和目錄的組織結構,可以進行一些更高級的配置,比如給文件配置權限、統計文件的大小、修改時間、限制文件系統的容量上限等。
以下羅列了一些在不同操作系統中比較常見的文件系統:
? Linux:ext4、XFS、Btrfs
? Windows:NTFS、FAT32
? macOS:APFS、HFS+
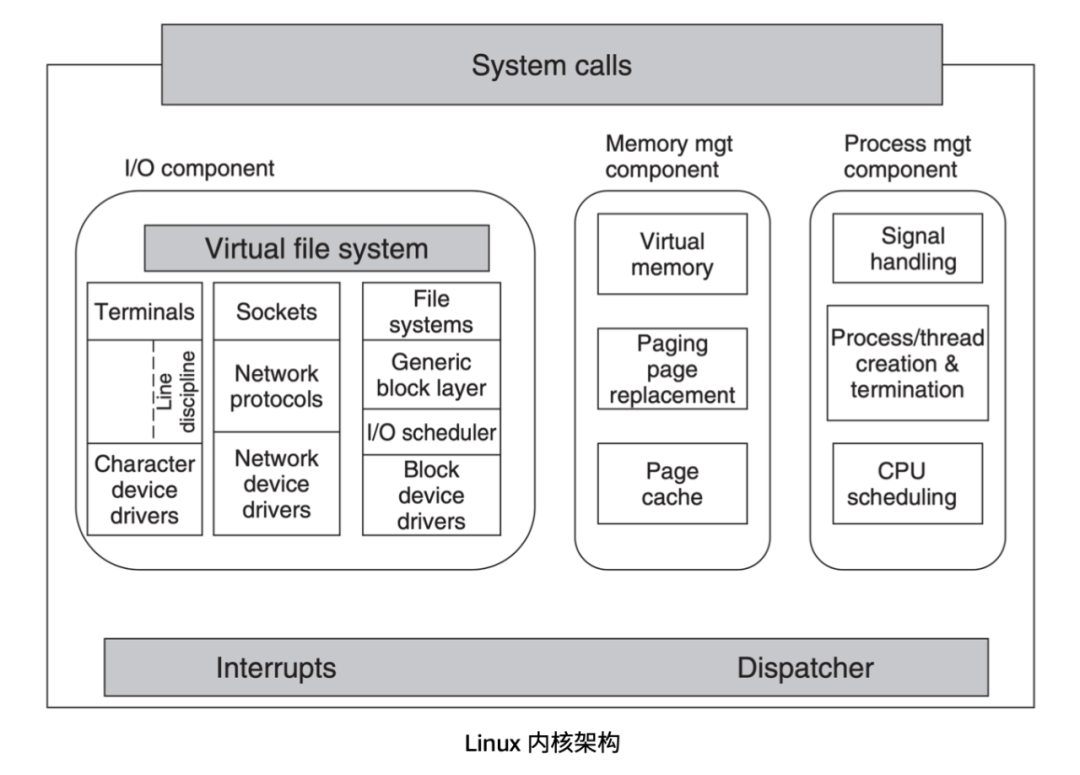
(圖片來源:《Modern Operating Systems》10.2.5 小節)
上圖是 Linux 內核的架構,左邊 Virtual file system 區域,也就是虛擬文件系統簡稱 VFS。它的作用是為了幫助 Linux 去適配不同的文件系統而設計的,VFS 提供了通用的文件系統接口,不同的文件系統實現需要去適配這些接口。
日常使用 Linux 的時候,所有的系統調用請求都會先到達 VFS,然后才會由 VFS 向下請求實際使用的文件系統。
文件系統的設計者需要遵守 VFS 的接口協議來設計文件系統,接口是共享的,但是文件系統具體實現是不同的,每個文件系統都可以有自己的實現方式。文件系統再往下是存儲介質,會根據不同的存儲介質再去組織存儲的數據形式。
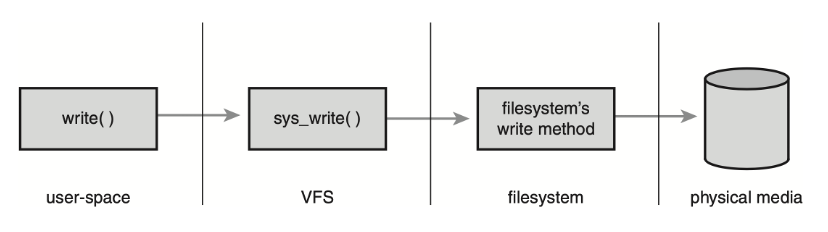
一次寫操作的請求流程 (圖片來源:《Linux Kernel Development》第 13 章 Filesystem Abstraction Layer)
上圖是一次寫操作的請求流程,在 Linux 里寫文件,其實就是一次write()系統調用。當你調用write()操作請求的時候,它會先到達 VFS,再由 VFS 去調用文件系統,最后再由文件系統去把實際的數據寫到本地的存儲介質。
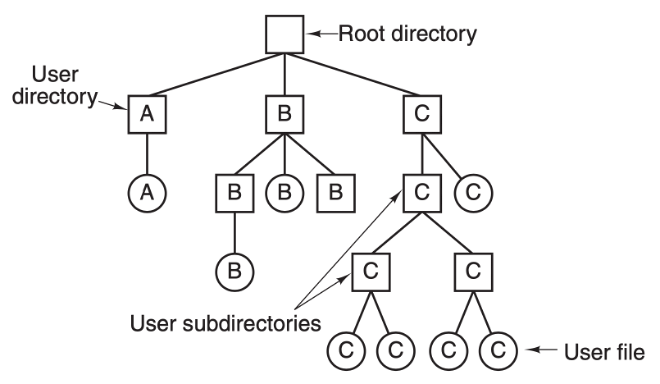
目錄樹(圖片來源:《Modern Operating Systems》4.2.2 小節)
上圖是一個目錄樹的結構,在文件系統里面,所有數據的組織形式都是這樣一棵樹的結構,從最上面的根節點往下,有不同的目錄和不同的文件。
這顆樹的深度是不確定的,相當于目錄的深度是不確定的,是由每個用戶來決定的,樹的葉子節點就是每一個文件。
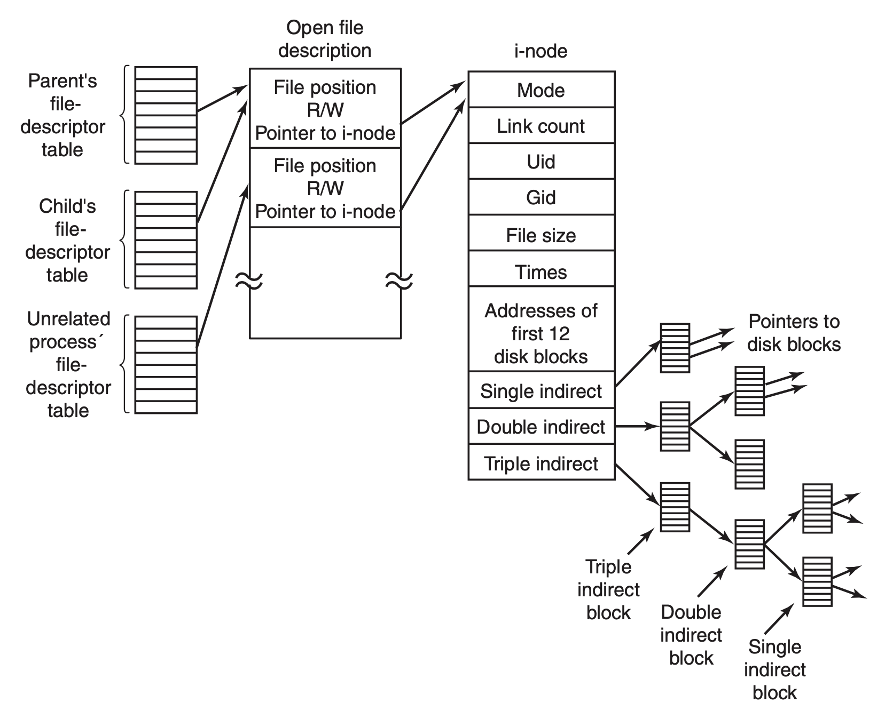
文件描述符與 inode
(圖片來源:《Modern Operating Systems》10.6.3 小節)
最右邊的 inode 就是每個文件系統內部的數據結構。這個 inode 有可能是一個目錄,也有可能是一個普通的文件。Inode 里面會包含關于文件的一些元信息,比如創建時間、創建者、屬于哪個組以及權限信息、文件大小等。此外每個 inode 里面還會有一些指針或者索引指向實際物理存儲介質上的數據塊。
以上就是實際去訪問一個單機文件系統時,可能會涉及到的一些數據結構和流程。作為一個引子,讓大家對于文件系統有一個比較直觀的認識。
分布式文件系統架構設計
單機的文件系統已經能夠滿足我們大部分使用場景的需求,管理很多日常需要存儲的數據。但是隨著時代的發展以及數據的爆發增長,對于數據存儲的需求也是在不斷的增長,分布式文件系統應運而生。
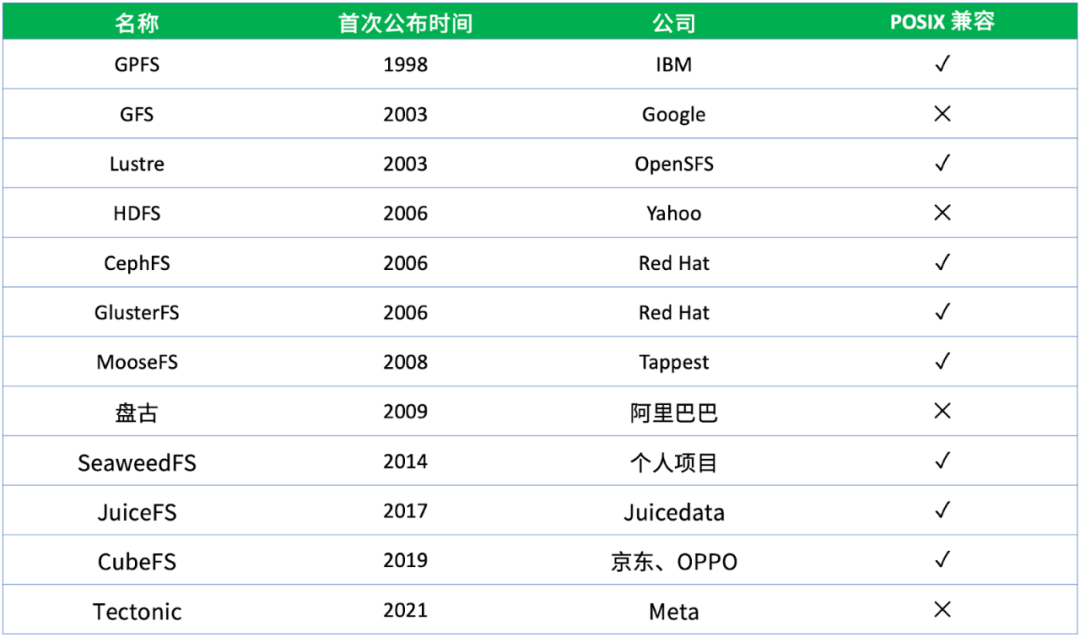
上面列了一些大家相對比較熟悉或者使用比較多的分布式文件系統,這里面有開源的文件系統,也有公司內部使用的閉源產品。從這張圖可以看到一個非常集中的時間點,2000 年左右有一大批的分布式系統誕生,這些分布式文件系統至今在我們日常工作中或多或少還是會接觸到。在 2000 年之前也有各種各樣的共享存儲、并行文件系統、分布式文件系統,但基本上都是基于一些專用的且比較昂貴的硬件來構建的。
自 2003 年 Google 的 GFS(Google File System)論文公開發表以來,很大程度上影響了后面一大批分布式系統的設計理念和思想。GFS 證明了我們可以用相對廉價的通用計算機,來組建一個足夠強大、可擴展、可靠的分布式存儲,完全基于軟件來定義一個文件系統,而不需要依賴很多專有或者高昂的硬件資源,才能去搭建一套分布式存儲系統。
因此 GFS 很大程度上降低了分布文件系統的使用門檻,所以在后續的各個分布式文件系統上都可以或多或少看到 GFS 的影子。比如雅虎開源的 HDFS 它基本上就是按照 GFS 這篇論文來實現的,HDFS 也是目前大數據領域使用最廣泛的存儲系統。
上圖第四列的「POSIX 兼容」表示這個分布式文件系統對 POSIX 標準的兼容性。POSIX(Portable Operating System Interface)是用于規范操作系統實現的一組標準,其中就包含與文件系統有關的標準。所謂 POSIX 兼容,就是滿足這個標準里面定義的一個文件系統應該具備的所有特征,而不是只具備個別,比如 GFS,它雖然是一個開創性的分布式文件系統,但其實它并不是 POSIX 兼容的文件系統。
Google 當時在設計 GFS 時做了很多取舍,它舍棄掉了很多傳統單機文件系統的特性,保留了對于當時 Google 搜索引擎場景需要的一些分布式存儲的需求。所以嚴格上來說,GFS 并不是一個 POSIX 兼容的文件系統,但是它給了大家一個啟發,還可以這樣設計分布式文件系統。
接下來我會著重以幾個相對有代表性的分布式文件系統架構為例,給大家介紹一下,如果要設計一個分布式文件系統,大概會需要哪些組件以及可能會遇到的一些問題。
GFS
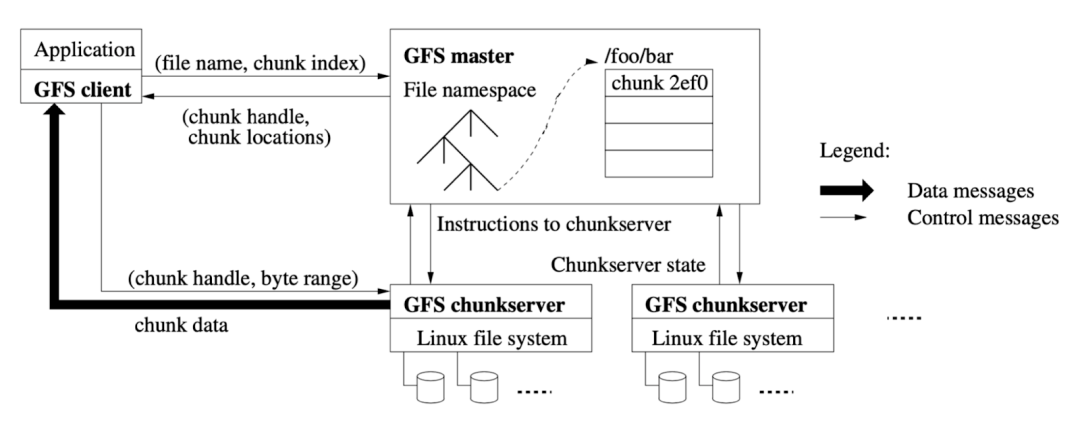
(圖片來源:The Google File System 論文)
首先還是以提到最多的 GFS 為例,雖然它在 2003 年就公布了,但它的設計我認為至今也是不過時的,有很多值得借鑒的地方。GFS 的主要組件可以分為三塊,最左邊的 GFS client 也就是它的客戶端,然后就是中間的 GFS master 也就是它的元數據節點,最下面兩塊是 GFS chunkserver 就是數據實際存儲的節點,master 和 chunkserver 之間是通過網絡來通信,所以說它是一個分布式的文件系統。Chunkserver 可以隨著數據量的增長不斷地橫向擴展。
其中 GFS 最核心的兩塊就是 master 和 chunkserver。我們要實現一個文件系統,不管是單機還是分布式,都需要去維護文件目錄、屬性、權限、鏈接等信息,這些信息是一個文件系統的元數據,這些元數據信息需要在中心節點 master 里面去保存。Master 也包含一個樹狀結構的元數據設計。
當要存儲實際的應用數據時,最終會落到每一個 chunkserver 節點上,然后 chunkserver 會依賴本地操作系統的文件系統再去存儲這些文件。
Chunkserver 和 master、client 之間互相會有連接,比如說 client 端發起一個請求的時候,需要先從 master 獲取到當前文件的元數據信息,再去和 chunkserver 通信,然后再去獲取實際的數據。在 GFS 里面所有的文件都是分塊(chunk)存儲,比如一個 1GB 的大文件,GFS 會按照一個固定的大小(64MB)對這個文件進行分塊,分塊了之后會分布到不同的 chunkserver 上,所以當你讀同一個文件時其實有可能會涉及到和不同的 chunkserver 通信。
同時每個文件的 chunk 會有多個副本來保證數據的可靠性,比如某一個 chunkserver 掛了或者它的磁盤壞了,整個數據的安全性還是有保障的,可以通過副本的機制來幫助你保證數據的可靠性。這是一個很經典的分布式文件系統設計,現在再去看很多開源的分布式系統實現都或多或少有 GFS 的影子。
這里不得不提一下,GFS 的下一代產品: Colossus。由于 GFS 的架構設計存在明顯的擴展性問題,所以 Google 內部基于 GFS 繼續研發了 Colossus。Colossus 不僅為谷歌內部各種產品提供存儲能力,還作為谷歌云服務的存儲底座開放給公眾使用。Colossus 在設計上增強了存儲的可擴展性,提高了可用性,以處理大規模增長的數據需求。下面即將介紹的 Tectonic 也是對標 Colossus 的存儲系統。篇幅關系,這篇博客不再展開介紹 Colossus,有興趣的朋友可以閱讀官方博客[2]。
Tectonic
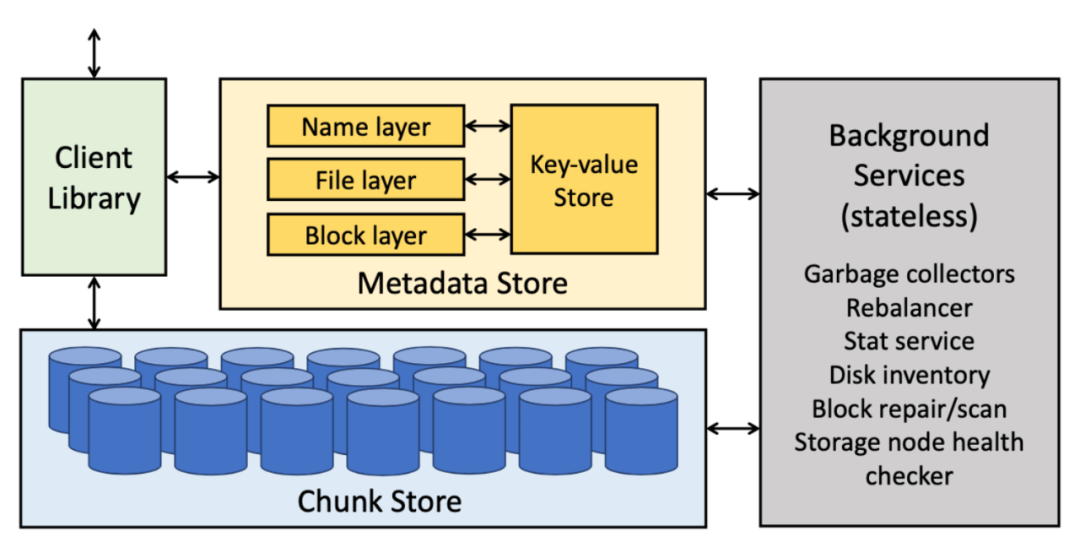
(圖片來源:Facebook’s Tectonic Filesystem: Efficiency from Exascale 論文)
Tectonic 是 Meta(Facebook)內部目前最大的一個分布式文件系統。Tectonic 項目大概在 2014 年就開始做了(之前被叫做 Warm Storage),但直到 2021 年才公開發表論文來介紹整個分布式文件系統的架構設計。
在研發 Tectonic 之前,Meta 公司內部主要使用 HDFS、Haystack 和 f4 來存儲數據,HDFS 用在數倉場景(受限于單集群的存儲容量,部署了數十個集群),Haystack 和 f4 用在非結構化數據存儲場景。Tectonic 的定位即是在一個集群里滿足這 3 種存儲支撐的業務場景需求。和 GFS 一樣,Tectonic 也主要由三部分構成,分別是 Client Library、Metadata Store 和 Chunk Store。
Tectonic 比較創新的點在于它在 Metadata 這一層做了分層處理,以及存算分離的架構設計。從架構圖可以看到 Metadata 分了三層:Name layer、File layer 和 Block layer。
傳統分布式文件系統會把所有的元數據都看作同一類數據,不會把它們顯式區分。在 Tectonic 的設計中,Name layer 是與文件的名字或者目錄結構有關的元數據,File layer 是跟當前文件本身的一些屬性相關的數據,Block layer 是每一個數據塊在 Chunk Store 位置的元數據。
Tectonic 之所以要做這樣一個分層的設計是因為它是一個非常大規模的分布式文件系統,特別是在 Meta 這樣的量級下(EB 級數據)。在這種規模下,對于 Metadata Store 的負載能力以及擴展性有著非常高的要求。
第二點創新在于元數據的存算分離設計,前面提到這三個 layer 其實是無狀態的,可以根據業務負載去橫向擴展。但是上圖中的 Key-value Store 是一個有狀態的存儲,layer 和 Key-value Store 之間通過網絡通信。
Key-value Store 并不完全是 Tectonic 自己研發的,而是用了 Meta 內部一個叫做 ZippyDB 的分布式 KV 存儲來支持元數據的存儲。ZippyDB 是基于 RocksDB 以及 Paxos 共識算法來實現的一個分布式 KV 存儲。Tectonic 依賴 ZippyDB 的 KV 存儲以及它提供的事務來保證整個文件系統元信息的一致性和原子性。
這里的事務功能是非常重要的一點,如果要實現一個大規模的分布式文件系統,勢必要把 Metadata Store 做橫向擴展。橫向擴展之后就涉及數據分片,但是在文件系統里面有一個非常重要的語義是強一致性,比如重命名一個目錄,目錄里面會涉及到很多的子目錄,這個時候要怎么去高效地重命名目錄以及保證重命名過程中的一致性,是分布式文件系統設計中是一個非常重要的點,也是業界普遍認為的難點。
Tectonic 的實現方案就是依賴底層的 ZippyDB 的事務特性來保證當僅涉及單個分片的元數據時,文件系統操作一定是事務性以及強一致性的。但由于 ZippyDB 不支持跨分片的事務,因此在處理跨目錄的元數據請求(比如將文件從一個目錄移動到另一個目錄)時 Tectonic 無法保證原子性。
在 Chunk Store 層 Tectonic 也有創新,上文提到 GFS 是通過多副本的方式來保證數據的可靠性和安全性。多副本最大的弊端在于它的存儲成本,比如說你可能只存了1TB 的數據,但是傳統來說會保留三個副本,那么至少需要 3TB 的空間來存儲,這樣使得存儲成本成倍增長。
對于小數量級的文件系統可能還好,但是對于像 Meta 這種 EB 級的文件系統,三副本的設計機制會帶來非常高昂的成本,所以他們在 Chunk Store 層使用 EC(Erasure Code)也就是糾刪碼的方式去實現。通過這種方式可以只用大概 1.2~1.5 倍的冗余空間,就能夠保證整個集群數據的可靠性和安全性,相比三副本的冗余機制節省了很大的存儲成本。Tectonic 的 EC 設計細到可以針對每一個 chunk 進行配置,是非常靈活的。
同時 Tectonic 也支持多副本的方式,取決于上層業務需要什么樣的存儲形式。EC 不需要特別大的的空間就可以保證整體數據的可靠性,但是 EC 的缺點在于當數據損壞或丟失時重建數據的成本很高,需要額外消耗更多計算和 IO 資源。
通過論文我們得知目前 Meta 最大的 Tectonic 集群大概有四千臺存儲節點,總的容量大概有 1590PB,有 100 億的文件量,這個文件量對于分布式文件系統來說,也是一個比較大的規模。在實踐中,百億級基本上可以滿足目前絕大部分的使用場景。
 (圖片來源:Facebook’s Tectonic Filesystem: Efficiency from Exascale 論文)
(圖片來源:Facebook’s Tectonic Filesystem: Efficiency from Exascale 論文)
再來看一下 Tectonic 中 layer 的設計,Name、File、Block 這三個 layer 實際對應到底層的 KV 存儲里的數據結構如上圖所示。比如說 Name layer 這一層是以目錄 ID 作為 key 進行分片,File layer 是通過文件 ID 進行分片,Block layer 是通過塊 ID 進行分片。
Tectonic 把分布式文件系統的元數據抽象成了一個簡單的 KV 模型,這樣可以非常好的去做橫向擴展以及負載均衡,可以有效防止數據訪問的熱點問題。
JuiceFS
JuiceFS 誕生于 2017 年,比 GFS 和 Tectonic 都要晚,相比前兩個系統的誕生年代,外部環境已經發生了翻天覆地的變化。
首先硬件資源已經有了突飛猛進的發展,作為對比,當年 Google 機房的網絡帶寬只有 100Mbps(數據來源:The Google File System 論文),而現在 AWS 上機器的網絡帶寬已經能達到 100Gbps,是當年的 1000 倍!
其次云計算已經進入了主流市場,不管是公有云、私有云還是混合云,企業都已經邁入了「云時代」。而云時代為企業的基礎設施架構帶來了全新挑戰,傳統基于 IDC 環境設計的基礎設施一旦想要上云,可能都會面臨種種問題。如何最大程度上發揮云計算的優勢是基礎設施更好融入云環境的必要條件,固守陳規只會事倍功半。
同時,GFS 和 Tectonic 都是僅服務公司內部業務的系統,雖然規模很大,但需求相對單一。而 JuiceFS 定位于服務廣大外部用戶、滿足多樣化場景的需求,因而在架構設計上與這兩個文件系統也大有不同。
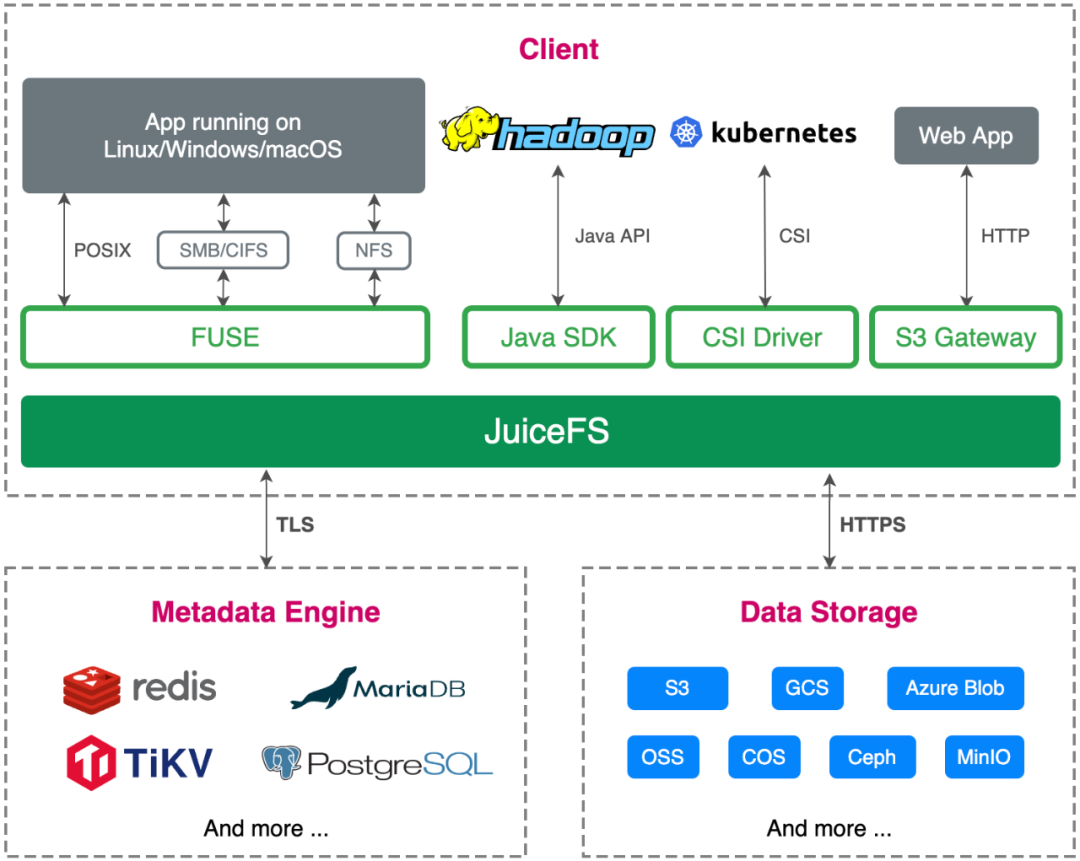
基于這些變化和差異,我們再來看看 JuiceFS 的架構。同樣的,JuiceFS 也是由 3 部分組成:元數據引擎、數據存儲和客戶端。雖然大體框架上類似,但其實每一部分的設計 JuiceFS 都有著一些不太一樣的地方。
首先是數據存儲這部分,相比 GFS 和 Tectonic 使用自研的數據存儲服務,JuiceFS 在架構設計上順應了云原生時代的特點,直接使用對象存儲作為數據存儲。前面看到 Tectonic 為了存儲 EB 級的數據用了 4000 多臺服務器,可想而知,如此大規模存儲集群的運維成本也必然不小。對于普通用戶來說,對象存儲的好處是開箱即用、容量彈性,運維復雜度陡然下降。對象存儲也支持 Tectonic 中使用的 EC 特性,因此存儲成本相比一些多副本的分布式文件系統也能降低不少。
但是對象存儲的缺點也很明顯,例如不支持修改對象、元數據性能差、無法保證強一致性、隨機讀性能差等。這些問題都被 JuiceFS 設計的獨立元數據引擎,Chunk、Slice、Block 三層數據架構設計,以及多級緩存解決了。
其次是元數據引擎,JuiceFS 可使用一些開源數據庫作為元數據的底層存儲。這一點和 Tectonic 很像,但 JuiceFS 更進了一步,不僅支持分布式 KV,還支持 Redis、關系型數據庫等存儲引擎,讓用戶可以靈活地根據自己的使用場景選擇最適合的方案,這是基于 JuiceFS 定位為一款通用型文件系統所做出的架構設計。使用開源數據庫的另一個好處是這些數據庫在公有云上通常都有全托管服務,因此對于用戶來說運維成本幾乎為零。
前面提到 Tectonic 為了保證元數據的強一致性選擇了 ZippyDB 這個支持事務的 KV 存儲,但 Tectonic 也只能保證單分片元數據操作的事務性,而 JuiceFS 對于事務性有著更嚴格的要求,需要保證全局強一致性(即要求跨分片的事務性)。因此目前支持的所有數據庫都必須具有單機或者分布式事務特性,否則是沒有辦法作為元數據引擎接入進來的(一個例子就是 Redis Cluster 不支持跨 slot 的事務)。基于可以橫向擴展的元數據引擎(比如 TiKV),JuiceFS 目前已經能做到在單個文件系統中存儲 200 多億個文件,滿足企業海量數據的存儲需求。

上圖是使用 KV 存儲(比如 TiKV)作為 JuiceFS 元數據引擎時的數據結構設計,如果對比 Tectonic 的設計,既有相似之處也有一些大的差異。比如第一個 key,在 JuiceFS 的設計里沒有對文件和目錄進行區分,同時文件或目錄的屬性信息也沒有放在 value 里,而是有一個單獨的 key 用于存儲屬性信息(即第三個 key)。
第二個 key 用于存儲數據對應的塊 ID,由于 JuiceFS 基于對象存儲,因此不需要像 Tectonic 那樣存儲具體的磁盤信息,只需要通過某種方式得到對象的 key 即可。在 JuiceFS 的存儲格式[3]中元數據分了 3 層:Chunk、Slice、Block,其中 Chunk 是固定的 64MiB 大小,所以第二個 key 中的chunk_index是可以通過文件大小、offset 以及 64MiB 直接計算得出。通過這個 key 獲取到的 value 是一組 Slice 信息,其中包含 Slice 的 ID、長度等,結合這些信息就可以算出對象存儲上的 key,最終實現讀取或者寫入數據。
最后有一點需要特別注意,為了減少執行分布式事務帶來的開銷,第三個 key 在設計上需要靠近前面兩個 key,確保事務盡量在單個元數據引擎節點上完成。不過如果分布式事務無法避免,JuiceFS 底層的元數據引擎也支持(性能略有下降),確保元數據操作的原子性。
最后來看看客戶端的設計。JuiceFS 和另外兩個系統最大的區別就是這是一個同時支持多種標準訪問方式的客戶端,包括 POSIX、HDFS、S3、Kubernetes CSI 等。GFS 的客戶端基本可以認為是一個非標準協議的客戶端,不支持 POSIX 標準,只支持追加寫,因此只能用在單一場景。Tectonic 的客戶端和 GFS 差不多,也不支持 POSIX 標準,只支持追加寫,但 Tectonic 采用了一種富客戶端的設計,把很多功能都放在客戶端這一邊來實現,這樣也使得客戶端有著最大的靈活性。此外 JuiceFS 的客戶端還提供了緩存加速特性,這對于云原生架構下的存儲分離場景是非常有價值的。
結語
文件系統誕生于上個世紀 60 年代,隨著時代的發展,文件系統也在不斷演進。一方面由于互聯網的普及,數據規模爆發式增長,文件系統經歷了從單機到分布式的架構升級,Google 和 Meta 這樣的公司便是其中的引領者。
另一方面,云計算的誕生和流行推動著云上存儲的發展,企業用云進行備份和存檔已逐漸成為主流,一些在本地機房進行的高性能計算、大數據場景,也已經開始向云端遷移,這些對性能要求更高的場景給文件存儲提出了新的挑戰。JuiceFS 誕生于這樣的時代背景,作為一款基于對象存儲的分布式文件系統,JuiceFS 希望能夠為更多不同規模的公司和更多樣化的場景提供可擴展的文件存儲方案。
審核編輯:劉清
-
Linux系統
+關注
關注
4文章
595瀏覽量
27442 -
SSD
+關注
關注
21文章
2868瀏覽量
117538 -
fat32文件系統
+關注
關注
0文章
7瀏覽量
6728 -
APFS
+關注
關注
0文章
2瀏覽量
11557
原文標題:淺析三款大規模分布式文件系統架構設計
文章出處:【微信號:OSC開源社區,微信公眾號:OSC開源社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
華納云:VFS在提升文件系統性能方面的具體實踐
Jtti:Linux中虛擬文件系統和容器化的關系
虛擬化數據恢復—UFS2文件系統數據恢復案例
服務器數據恢復—raid5陣列+reiserfs文件系統數據恢復案例
Linux根文件系統的掛載過程
小型文件系統如何選擇?FatFs和LittleFs優缺點比較

服務器數據恢復—xfs文件系統服務器數據恢復案例
如何修改buildroot和debian文件系統
聚徽觸控-工業一體機選擇什么操作系統好
嵌入式實時操作系統:Intewell操作系統與VxWorks操作系統有啥區別

linux--sysfs文件系統

工業實時操作系統對比:鴻道Intewell跟rt-linux有啥區別






 工商網監
工商網監
評論