 淺聊泛型常量參數
淺聊泛型常量參數
淺聊泛型常量參數Const Generic
引題
最近有網友私信我討論:若使用規則宏編譯時統計token tree序列的長度,如何繞開由宏遞歸自身局限性造成的:
- 被統計序列不能太長
- 編譯延時顯著拖長
fn main() { macro_rules! count_tts { ($_a:tt $($tail: tt)*) => { 1_usize + count_tts!($($tail)*) }; () => { 0_usize }; } assert_eq!(10, count_tts!(,,,,,,,,,,)); }
嚯!這段短小精悍的代碼餒餒地演示了Incremental TT Muncher設計模式的精髓。贊!
首先,宏遞歸深度是有極限的(默認是128層)。所以,若每次遞歸僅新統計一個token,那么被統計序列的最大長度自然不能超過128。否則,突破上限,編譯失敗!
其次,尾遞歸優化是運行時壓縮函數調用棧的技術手段,卻做不到編譯時抑制宏調用棧的膨脹。所以,巧用#![recursion_limit="…"]元屬性強制調高宏遞歸深度上限很可能會導致編譯器棧溢出。
由此,如果僅追求快速繞過問題,那最經濟實惠的作法是:在每次宏遞歸期間,多統計幾個token例程2(而不是一次一個)。從算數上,將總遞歸次數降下來,和使計數更長的token tree序列成為可能。fn main() { // 這代碼看著就“傻乎乎的”。 macro_rules! count_tts { ($_a: tt $_b: tt $_c: tt $_d: tt $_e: tt $_f: tt // 一次遞歸統計 6 個。 $($tail: tt)*) => { 6_usize + count_tts!($($tail)*) }; ($_a: tt $_b: tt $_c: // 一次遞歸統計 3 個。 tt $($tail: tt)*) => { 3_usize + count_tts!($($tail)*) }; ($_a: tt // 一次遞歸統計 1 個。 $($tail: tt)*) => { 1_usize + count_tts!($($tail)*) }; () => { 0_usize }; // 結束了,統計完成 } println!("token tree 個數是 {}", count_tts!(,,,,,,,,,,)); } 倘若要標本兼治地解決問題,將遞歸調用變形成循環結構才是正途,因為循環本身不會增加調用棧的深度。這涵蓋了:
-
宏循環結構將
token tree序列變形成數組字面量。 - 常量函數調用觸發編譯器對數組字面量的類型推導。
-
因為
rust數組在編譯時明確大小,所以數組長度被編入了數據類型定義內。 - 泛型常量參數從數據類型定義中提取出數組長度值,并作為序列長度返回。
Array length設計模式。它帶入了兩個技術難點:-
如何觸發
rustc對數組字面量的類型推導,和從推導結果中提取出數組長度信息。 -
如何撇開遞歸的“吐吞模式”(即,吐
Incremental TT Muncher和吞Push-down Accumulation),僅憑宏循環結構,將token tree序列變形成為數組字面量。
rustc 1.51才穩定的新語言特性“泛型常量參數Const Generic”。而第二個難點的解決就多樣化了-
要么,采用“循環替換設計模式
Repetition Replacement(RR)” -
要么,啟用試驗階段語言特性“元變量表達式
Meta-variable Expression”
泛型常量參數
從rustc 1.51+起,【泛型常量參數 】允許泛型項(類或函數)接受常量值或常量表達式為泛型參數。根據泛型常量參數出現的位置不同(請見下圖例程3),它又細分為- 泛型常量參數的形參
- 泛型常量參數的實參

泛型參數的分類
于是,已知的泛型參數就包含有三種類型:
泛型常量參數的數據類型
可用作【泛型常量參數】的數據類型包括兩類:-
整數數字類型:
u8,u16,u32,u64,u128,usize,i8,i16,i32,i64,i128,isize -
可數字化類型:
char,bool
泛型常量參數的“怪癖”
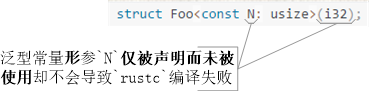
首先,就“同名沖突”而言,若【泛型常量形參】與【類型】同名并作為另一個泛型項的泛型參數實參,那么rustc會優先將該泛型參數當作類型帶入程序上下文。多數情況下,這會造成程序編譯失敗。解決方案是使用塊表達式{...}包裝泛型常量參數,以向rustc標注此同名參數是泛型常量參數而不是類型名例程4。
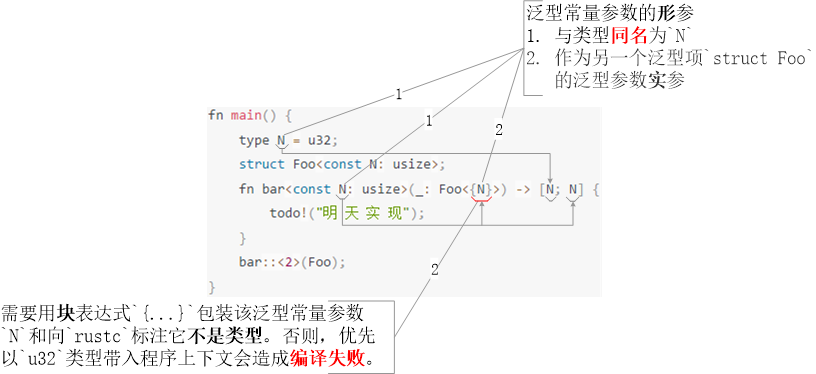
 最后,泛型常量實參的
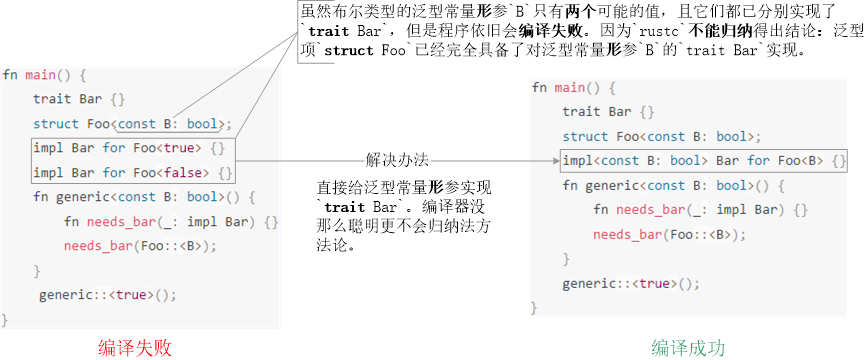
最后,泛型常量實參的trait實現不會因為窮舉了全部備選形參值而自動過渡給泛型常量形參。如下例程6(左),即便泛型項struct Foo顯示地給泛型常量形參B的每個可能的(實參)值true / false都實現的同一個trait Bar,編譯器也不會“聰明地”歸納出該trait Bar已經被此泛型項的泛型常量形參充分實現了,因為編譯器可不會“歸納法”方法論(不確定chatGPT是否能做到?)。相反,每個實參上的trait實現都被視作不相關的個例。正確地作法是:泛型項必須明確地給泛型常量形參實現trait例程7(右)。
泛型常量參數的適用位置
泛型常量參數原則上可出現于常量項適用的全部位置,包括但不限于:-
運行時求值表達式
#1— 模糊了編譯時泛型參數與運行時值之間的界限。 -
常量表達式
#2 -
關聯常量
#2 -
關聯類型
#3 -
結構體字段 或 綁定變量的數據類型
#4。比如,編譯時參數化數組長度。 -
結構體字段 或 綁定變量的值
#5
#1 ~ #5,可在下面例程8源碼內找到對應的代碼行。use rand::{thread_rng, Rng}; fn main() { fn foo1<const N1: usize>(input: usize) { // 在泛型函數內,泛型常量參數的形參可用于 let sum = 1 + N1 * input; // #1 運行時求值的表達式 let foo = Foo([input; N1]); // #5 結構體字段的值 let arr: [usize; N1] = [input; N1]; // #4 綁定變量的數據類型 —— 編譯時參數化數組長度 // #5 綁定變量的值 println!("運行時表達式:{sum}, 元組結構體: {foo:?}, 數組: {arr:?}"); } trait Trait<const N2: usize> { const CONST: usize = N2 + 4; // #2 關聯常量 + 常量表達式 type Output; } #[derive(Debug)] struct Foo<const N3: usize>( [usize; N3] // #4 結構體字段的數據類型 —— 編譯時參數化數組長度 ); impl<const N4: usize> Trait
泛型常量參數的不適用位置
首先,泛型常量形參不能:-
定義常量和靜態變量,無論是作為類型定義的一部分,還是值
#1 -
隔層使用。比如,在子函數內引用由外層函數聲明的泛型常量形參
#2。除了子函數,該規則也適用于在函數體內定義的-
結構體
#3 -
類型別名
#4
-
結構體
#1 ~ #4,可在下面例程9源碼內找到對應的代碼行。fn main() { fn outer<const N: usize>(input: usize) { // 泛型常量參數【不】可用于函數體內的 // #1 常量定義 // - 既不能定義類型 const BAD_CONST: [usize; N] = [1; N]; // - 既不能定義值 const BAD_CONST: usize = 1 + N; // #1 靜態變量定義 // - 既不能定義類型 static BAD_STATIC: [usize; N] = [N + 1; N]; // - 既不能定義值 static BAD_STATIC: usize = 1 + N; fn inner(bad_arg: [usize; N]) { // #2 在子函數內不能引用外層函數聲明的 // 泛型常量形參,無論是將其作為 // 變量類型,還是常量值。 let bad_value = N * 2; } // #3 結構體內也不能引用外層函數聲明的 // 泛型常量形參。 struct BadStruct([usize; N]); // 相反,需要給結構體重新聲明泛型常量參數 struct BadStruct<const N: usize>([usize; N]); // #4 類型別名內不能引用外層函數聲明的 // 泛型常量形參。 type BadAlias = [usize; N]; // 相反,需要給類型別名重新聲明泛型常量參數 type BadAlias<const N: usize> = [usize; N]; } } 其次,泛型常量實參不接受包含了泛型常量形參的常量表達式例程10。
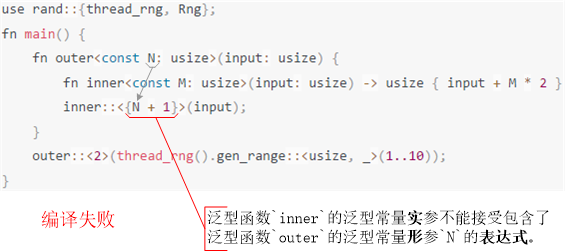
- 獨立泛型常量形參例程11
-
不包含泛型常量形參的普通常量表達式例程12
題外話,不確定這么翻譯該術語
lookahead是否正確。我借鑒了 @余晟 在《精通正則表達式》一書中對此詞條的譯文。-
被用作泛型常量實參的常量表達式必須被包裝在塊表達式
{...}內。避免編譯器在解析AST過程中陷入正向環視lookahead的無限循環中。
-
被用作泛型常量實參的常量表達式必須被包裝在塊表達式
數組重復表達式與泛型常量參數
數組重復表達式[repeat_operand; length_operand]是數組字面量的一種形式。在數組重復表達式中,泛型常量形參-
雖然既可用于左
repeat操作數位置,也可用于右length操作數位置例程13 -
但在右
length操作數位置上,泛型常量形參只能獨立出現例程14,而不能作為常量表達式的一部分 —— 等同于泛型常量實參的限制。

回到序列計數問題
類似于解析幾何中的“投影”方法,通過將高維物體(token tree序列)投影于低維平面(數組),以主動舍棄若干信息項(每個token的具體值與數據類型)為代價,突出該物體更有價值的信息內容(序列長度),便可降低從復雜結構中摘取特定關注信息項的合計復雜度。這套“降維算法”帶來的啟發就是:-
既然讀取數組長度是簡單的,那為什么不先將
token tree序列變形為數組呢?-
答:投影
token tree序列為數組
-
答:投影
-
既然
token tree序列的內容細節不被關注,那為什么還要糾結于數組的數據類型與填充值呢?全部充滿unit type豈不快哉!-
再答:投影
token tree序列為單位數組[(); N]。僅數組長度對我們有價值。
-
再答:投影
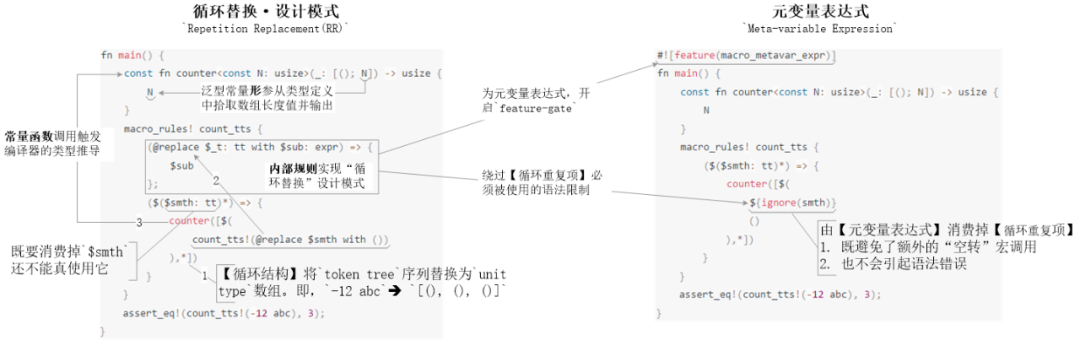
Repetition Replacement(RR)與元變量表達式${ignore(識別符名)}都是被用來改善【宏循環結構】的使用體驗,以允許Rustacean對循環結構中的循環重復項“宣而不用” —— 既遍歷token tree序列,同時又棄掉每個具體的token元素,最后還生成一個等長的單位數組[(); N]。否則,未被使用的“循環重復項”會導致error: attempted to repeat an expression containing no syntax variables matched as repeating at this depth的編譯錯誤。-
循環替換設計模式
Repetition Replacement(RR)是以在宏循環體內插入一層“空轉”宏調用,消費掉consuming未被使用的“循環重復項”例程15 -
元變量表達式
${ignore(識別符名)}是前者的語法糖,允許Rustacean少敲幾行代碼。但因為元變量表達式是試驗性的新語法,所以需要開啟對應的feature-gate開關#![feature(macro_metavar_expr)]才能被使用。例程16
結束語
除了前文提及的【宏遞歸法】與Array Length設計模式,統計token tree序列長度還有-
Slice Length設計模式-
原理類似
Array Length,但調用數組字面量的pub const fn len(&self) -> usize成員方法讀取長度值(而不是依賴類型推導和泛型參數提取)。
-
原理類似
-
枚舉計數法
-
規則宏將
token tree序列變形為“枚舉類”(而不是數組字面量),再由最后一個枚舉值的分辨因子discriminant值加1獲得序列長度。 -
但,缺點也明顯。比如,
token tree序列內不能包含rust語法關鍵字與重復項。
-
規則宏將
-
比特計數法
-
典型的算法優化。從數學層面,將程序復雜度從
O(n)降到O(log(n))。有些復雜,回頭單獨寫一篇文章分享之。
-
典型的算法優化。從數學層面,將程序復雜度從
rust編程語言提供的業務功能開發利器。宏循環結構與泛型常量參數僅只是它們的冰山一角。此文既匯總分享與網友的討論成果,也對此話題拋磚引玉。希望有機會與路過的神仙哥哥和仙女妹妹們更深入地交流相關技術知識點與實踐經驗。
審核編輯:湯梓紅
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
參數
+關注
關注
11文章
1864瀏覽量
32568 -
函數
+關注
關注
3文章
4353瀏覽量
63290 -
編譯
+關注
關注
0文章
666瀏覽量
33210 -
數據類型
+關注
關注
0文章
236瀏覽量
13694
原文標題:淺聊泛型常量參數
文章出處:【微信號:Rust語言中文社區,微信公眾號:Rust語言中文社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
詳解Rust的泛型
所有的編程語言都致力于將重復的任務簡單化,并為此提供各種各樣的工具。在 Rust 中,泛型(generics)就是這樣一種工具,它是具體類型或其它屬性的抽象替代。在編寫代碼時,我們可以直接描述泛
發表于 11-12 09:08
?1131次閱讀
Go語言常量的聲明
在 Go 語言中, 常量 表示的是固定的值,常量表達式的值在編譯期進行計算,常量的值不可以修改。例如:3 、 Let's go 、 3.14 等等。常量中的數據類型只可以是
發表于 07-20 15:24
?473次閱讀
Golang泛型的使用
眾所周知很多語言的function 中都支持 key=word 關鍵字參數, 但 golang 是不支持的, 我們可以利用泛型去簡單的實現。
發表于 08-16 12:24
?338次閱讀

labview連接mongdb問題,找到不.NET類中的泛型類
有沒有人用labview連接mongodb數據庫的?已下載mongodb的c#驅動,利用labview中的.net控件調用相關函數,但是驅動中有部分函數在泛型類中, labview能調用c#中的泛
發表于 04-08 13:38
聊聊java泛型實現的原理與好處
摘要: 和C++以模板來實現靜多態不同,Java基于運行時支持選擇了泛型,兩者的實現原理大相庭徑。C++可以支持基本類型作為模板參數,Java卻只能接受類作為泛
發表于 09-27 16:50
?0次下載
51單片機C語言的變量和常量如何區分常量的詳細資料說明
程序運行過程中不能改變值的量,而變量是可以在程序運行過程中不斷變化的量。變量的定義可以使用所有C51編譯器支持的數據類型,而常量的數據類型只有整型、浮點型、字符型、字符串型和位標量。這
發表于 07-24 17:37
?0次下載
C語言的常量-2
在C語言中,字符型常量是最特別的一種常量。他的特別之處在于我們需要對其使用指定的定界符對其進行限制。定界符為 ‘’ 。字符型常量可以分為兩種







 工商網監
工商網監
評論