") 嵌入式邊緣AI應(yīng)用開發(fā)簡化指南
嵌入式邊緣AI應(yīng)用開發(fā)簡化指南
如果在沒有嵌入式處理器供應(yīng)商提供的合適工具和軟件的支持下,既想設(shè)計高能效的邊緣人工智能(AI)系統(tǒng),同時又要加快產(chǎn)品上市時間,這項工作難免會冗長乏味。面臨的一系列挑戰(zhàn)包括選擇恰當(dāng)?shù)?a href="http://www.1cnz.cn/v/tag/448/" target="_blank">深度學(xué)習(xí)模型、針對性能和精度目標(biāo)對模型進(jìn)行訓(xùn)練和優(yōu)化,以及學(xué)習(xí)使用在嵌入式邊緣處理器上部署模型的專用工具。
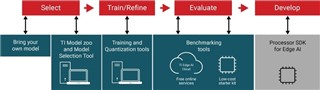
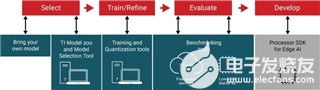
從模型選擇到在處理器上部署,TI可免費(fèi)提供相關(guān)工具、軟件和服務(wù),為您深度神經(jīng)網(wǎng)絡(luò)(DNN)開發(fā)工作流程的每一步保駕護(hù)航。下面讓我們來了解如何不借助手動工具或手動編程來選擇模型、隨時隨地訓(xùn)練模型并將其無縫部署到TI處理器上,從而實(shí)現(xiàn)硬件加速推理。
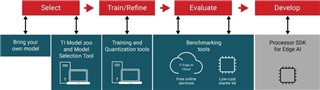
圖1: 邊緣AI應(yīng)用的開發(fā)流程
第1步:選擇模型
邊緣AI系統(tǒng)開發(fā)的首要任務(wù)是選擇合適的DNN模型,同時要兼顧系統(tǒng)的性能、精度和功耗目標(biāo)。GitHub上的TI邊緣AI Model Zoo等工具可助您加速此流程。
Model Zoo廣泛匯集了TensorFlow、PyTorch和MXNet框架中常用的開源深度學(xué)習(xí)模型。這些模型在公共數(shù)據(jù)集上經(jīng)過預(yù)訓(xùn)練和優(yōu)化,可以在TI適用于邊緣AI的處理器上高效運(yùn)行。TI會定期使用開源社區(qū)中的新模型以及TI設(shè)計的模型對Model Zoo進(jìn)行更新,為您提供性能和精度經(jīng)過優(yōu)化的廣泛模型選擇。
Model Zoo囊括數(shù)百個模型,TI模型選擇工具(如圖2所示)可以幫助您在不編寫任何代碼的情況下,通過查看和比較性能統(tǒng)計數(shù)據(jù)(如推理吞吐量、延遲、精度和雙倍數(shù)據(jù)速率帶寬),快速比較和找到適合您AI任務(wù)的模型。
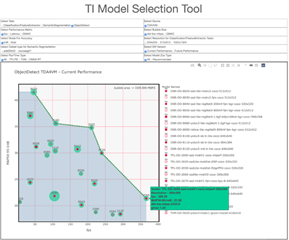
圖2:TI 模型選擇工具
第2步:訓(xùn)練和優(yōu)化模型
選擇模型后,下一步是在TI處理器上對其進(jìn)行訓(xùn)練或優(yōu)化,以獲得出色的性能和精度。憑借我們的軟件架構(gòu)和開發(fā)環(huán)境,您可隨時隨地訓(xùn)練模型。
從TI Model Zoo中選擇模型時,借助訓(xùn)練腳本可讓您在自定義數(shù)據(jù)集上為特定任務(wù)快速傳輸和訓(xùn)練模型,而無需花費(fèi)較長時間從頭開始訓(xùn)練或使用手動工具。訓(xùn)練腳本、框架擴(kuò)展和量化感知培訓(xùn)工具可幫助您優(yōu)化自己的DNN模型。
第3步:評估模型性能
在開發(fā)邊緣AI應(yīng)用之前,需要在實(shí)際硬件上評估模型性能。
TI提供靈活的軟件架構(gòu)和開發(fā)環(huán)境,您可以在TensorFlow Lite、ONNX RunTime或TVM和支持Neo AI DLR的SageMaker Neo運(yùn)行環(huán)境引擎三者中選擇習(xí)慣的業(yè)界標(biāo)準(zhǔn)Python或C++應(yīng)用編程接口(API),只需編寫幾行代碼,即可隨時隨地訓(xùn)練自己的模型,并將模型編譯和部署到TI硬件上。在這些業(yè)界通用運(yùn)行環(huán)境引擎的后端,我們的TI深度學(xué)習(xí)(TIDL)模型編譯和運(yùn)行環(huán)境工具可讓您針對TI的硬件編譯模型,將編譯后的圖或子圖部署到深度學(xué)習(xí)硬件加速器上,并在無需任何手動工具的情況下實(shí)現(xiàn)卓越的處理器推理性能。
在編譯步驟中,訓(xùn)練后量化工具可以自動將浮點(diǎn)模型轉(zhuǎn)換為定點(diǎn)模型。該工具可通過配置文件實(shí)現(xiàn)層級混合精度量化(8位和16位),從而能夠足夠靈活地調(diào)整模型編譯,以獲得出色的性能和精度。
不同常用模型的運(yùn)算方式各不相同。同樣位于GitHub上的TI邊緣AI基準(zhǔn)工具可幫助您為TI Model Zoo中的模型無縫匹配DNN模型功能,并作為自定義模型的參考。
評估TI處理器模型性能的方式有兩種:TDA4VM入門套件評估模塊(EVM)或TI Edge AI Cloud,后者是一項免費(fèi)在線服務(wù),可支持遠(yuǎn)程訪問TDA4VM EVM,以評估深度學(xué)習(xí)推理性能。借助針對不同任務(wù)和運(yùn)行時引擎組合的數(shù)個示例腳本,五分鐘之內(nèi)便可在TI硬件上編程、部署和運(yùn)行加速推理,同時收集基準(zhǔn)測試數(shù)據(jù)。
第4步:部署邊緣AI應(yīng)用程序
您可以使用開源Linux?和業(yè)界通用的API來將模型部署到TI硬件上。然而,將深度學(xué)習(xí)模型部署到硬件加速器上只是難題的冰山一角。
為幫助您快速構(gòu)建高效的邊緣AI應(yīng)用,TI采用了GStreamer框架。借助在主機(jī)Arm?內(nèi)核上運(yùn)行的GStreamer插件,您可以自動將計算密集型任務(wù)的端到端信號鏈加速部署到硬件加速器和數(shù)字信號處理內(nèi)核上。
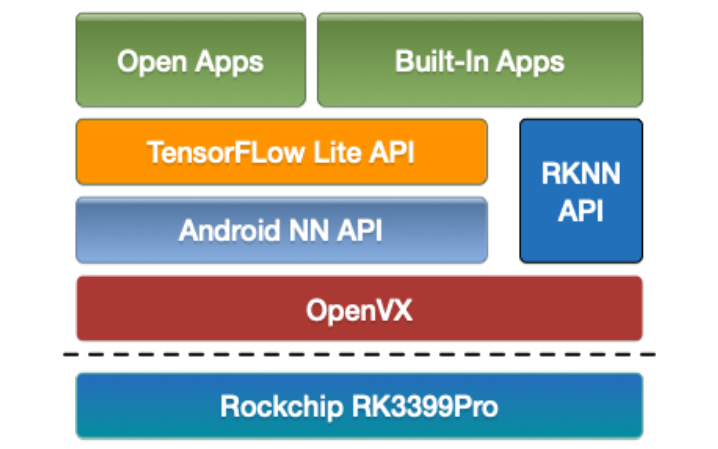
圖3展示了適用于邊緣AI的Linux Processor SDK的軟件棧和組件。
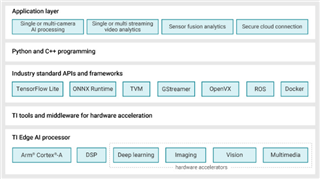
圖3:適用于邊緣AI的Linux Processor SDK組件
結(jié)語
如果您對本文中提及的工具感到陌生或有所擔(dān)憂,請放寬心,因?yàn)榧词鼓胍_發(fā)和部署AI模型或構(gòu)建AI應(yīng)用,也不必成為AI專家。TI Edge AI Academy能夠幫助您在自學(xué)、課堂環(huán)境中通過測驗(yàn)學(xué)習(xí)AI基礎(chǔ)知識,并深入了解AI系統(tǒng)和軟件編程。實(shí)驗(yàn)室提供了構(gòu)建“Hello World” AI應(yīng)用的分步代碼,而帶有攝像頭捕獲和顯示功能的端到端高級應(yīng)用使您能夠按照自己的節(jié)奏順利開發(fā)AI應(yīng)用。
審核編輯:郭婷
-
處理器
+關(guān)注
關(guān)注
68文章
19259瀏覽量
229653 -
嵌入式
+關(guān)注
關(guān)注
5082文章
19104瀏覽量
304817 -
AI
+關(guān)注
關(guān)注
87文章
30728瀏覽量
268888
發(fā)布評論請先 登錄
相關(guān)推薦
嵌入式邊緣AI應(yīng)用開發(fā)簡化指南
嵌入式邊緣AI應(yīng)用開發(fā)指南
ST MCU邊緣AI開發(fā)者云 - STM32Cube.AI
AI開發(fā)平臺如何幫助嵌入式開發(fā)者加速應(yīng)用產(chǎn)品化落地
基于Jetson AGX Orin的邊緣AI和嵌入式計算系統(tǒng)
嵌入式邊緣AI應(yīng)用開發(fā)簡化指南

嵌入式ai應(yīng)用開發(fā)
TI Edge AI Academy簡化嵌入式邊緣AI應(yīng)用開發(fā)
【2023電子工程師大會】ARM嵌入式AI邊緣計算開發(fā)流程要點(diǎn)p
AI引爆邊緣計算變革,塑造嵌入式產(chǎn)業(yè)新未來AI引爆邊緣計算變革,塑造嵌入式產(chǎn)業(yè)新未來——2024研華嵌入式

嵌入式軟件開發(fā)與AI整合

AMD分析嵌入式邊緣AI的發(fā)展





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論