 求一種基于flink的數字集成方案
求一種基于flink的數字集成方案
Labs 導讀
數據集成平臺作為連接各種異構數據的紐帶,需要連接多種多樣的存儲系統。而不同的技術棧和不同的業務場景會對數據集成系統提出不同的設計要求。
1
概述
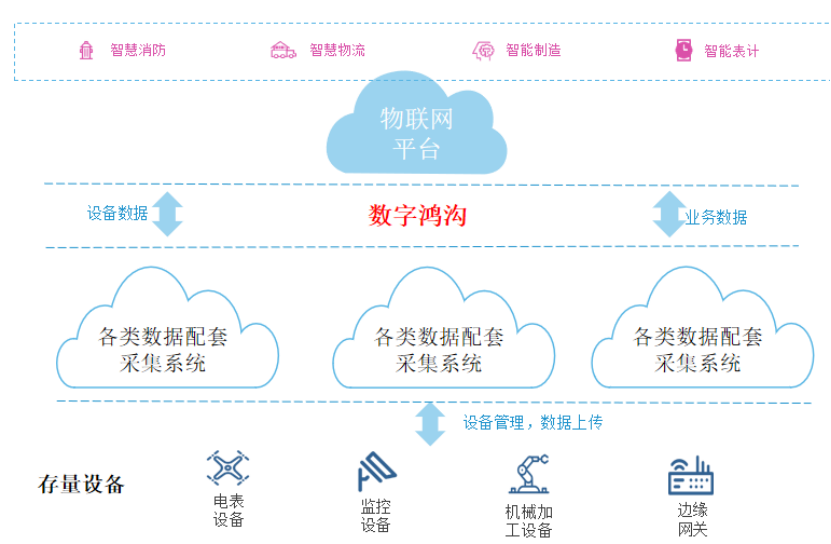
在實際私有化物聯網平臺項目中,部分存量設備由于異構總線、多制式以太網、協議多樣化等因素導致無法直接連接物聯網平臺,大量數據較難集成,平臺側和設備側面臨大量定制化開發,成本較高。因此難以推動客戶或設備廠商進行存量設備接入改造,導致設備無法直連物聯網平臺,無法達到物聯網平臺對企業所有設備數據進行統一納管。
企業內部存量的數據采集系統多為“煙囪式”,各個廠商的系統只需對接自己廠商的設備即可,數據孤島問題突出。
各“煙囪”的數據格式各不相同,定制化采集任務代碼不可復用,費時費力,難以同時支撐多個項目。
除了設備數據采集外,還有業務數據采集需求,傳統物聯網系統只能采集設備數據而無法集成業務數據。
2
技術選型
數字集成技術通過對不同系統數據的抽取(Extract),數據清洗和轉換(Transformation)以及輸入最終的目標系統(Load),打通各個業務孤島,實現數據互聯互通,助力企業數字化轉型。由于物聯網場景下的數據處理大多都要求實時性,所以要求實現時具備實時數據處理能力。實時計算也被稱作流計算,代表是Storm、Spark Streaming、Flink等大數據技術。計算引擎也在不斷更新迭代,從第一代的Hadoop MapReduce,到第二代的Spark,再到第三代的Flink技術,從批處理到微批,再到真正的流式計算。
Apache Flink是一個開源的流處理框架,應用于分布式、高性能、高可用的數據流應用程序。可以處理有限數據流和無限數據,即能夠處理有邊界和無邊界的數據流。無邊界的數據流就是真正意義上的流數據,所以Flink是支持流計算的。Flink可以部署在各種集群環境,可以對各種大小規模的數據進行快速計算。
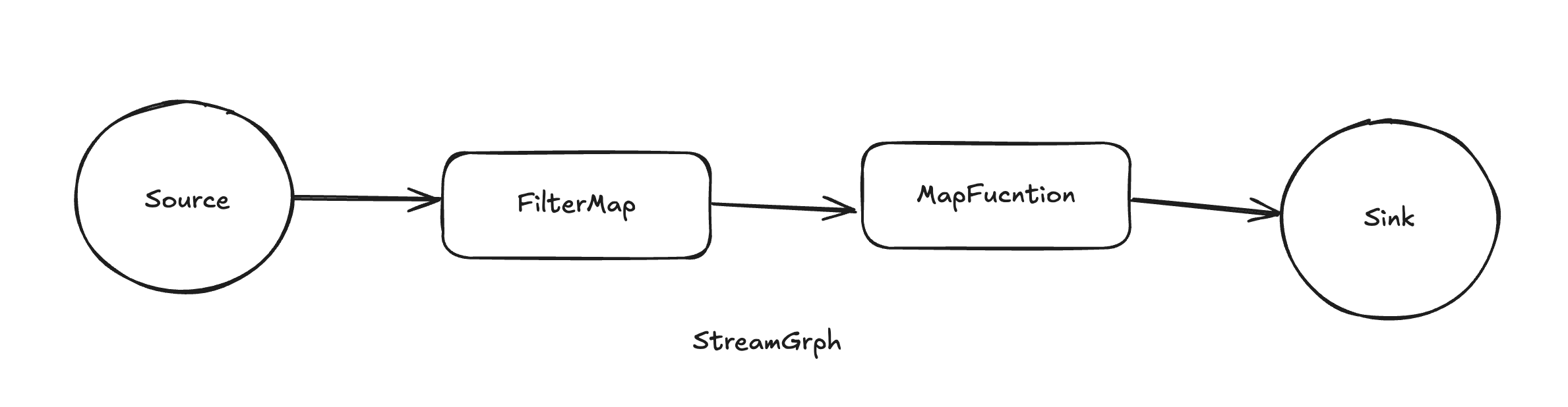
Flink框架具備強大的流式ETL的能力,依靠其豐富的算子實現。
2.1 Source算子
Flink可以使用StreamExecutionEnvironment.addSource(source)來為我們的程序添加數據來源。
Flink已經提供了若干實現好的source functions,當然也可通過實現SourceFunction來自定義非并行的source或者實現ParallelSourceFunction接口或者擴展RichParallelSourceFunction來自定義并行的source。
Flink在流處理上的source大致有4大類:
基于本地集合的source(Collection-based-source)
基于文件的source(File-based-source)- 讀取文本文件,即符合TextInputFormat規范的文件,并將其作為字符串返回
基于網絡套接字的source(Socket-based-source)- 從socket讀取。元素可以用分隔符切分。
自定義的source(Custom-source)
使用自定義Source算子可實現豐富的數據抽取功能。
2.2 Transform轉換算子
① map
將DataStream中的每一個元素轉換為另外一個元素,如將元素x變為原來的5倍:
dataStream.map { x => x * 5 }
② FlatMap
采用一個數據元并生成零個,一個或多個數據元。如,將句子分割為單詞的flatmap函數:
dataStream.flatMap { str => str.split(" ") }
③ Filter
計算每個數據元的布爾函數,并保存函數返回true的數據元。如,過濾掉零值的過濾器:
dataStream.filter { x != 0 }
當然flink還具備很多其他功能的轉換算子,如KeyBy、Reduce、Aggregations等,通過豐富的轉換算子,flink可實現對數據的清洗和轉換功能。
2.3 Sink算子
Flink的sink算子支持將數據輸出到:本地文件、本地集合、HDFS,除此之外,還支持:sink到kafka、sink到mysql、sink到redis以及自定義sink算子。
通過自定義sink算子將清洗轉換完成的數據輸入目標系統。
3
數字集成實現
實現過程如下:

第一步,抽象定義基礎控件類
數字集成基于flink可抽象定義3類基礎功能控件,每類控件又可根據不同的功能實現具體的子類功能控件;詳細如下:
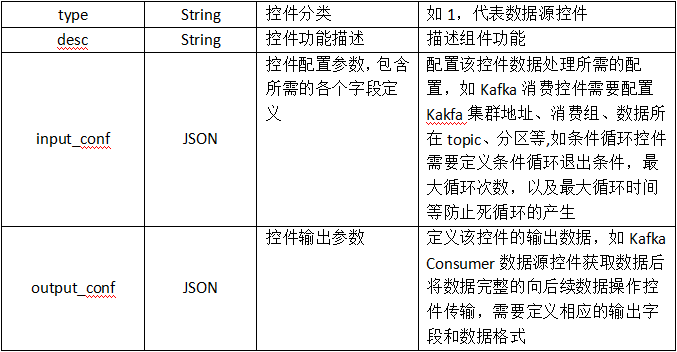
基礎功能控件分為三類:數據源控件、數據輸出控件、數據處理控件。

數據源控件:將Source算子抽象定義成具備抽取數據功能的數據源控件類,并制定相應的配置規范,使用時只需根據規范配置文件,系統根據配置文件創建具體的實例化對象,實現數據抽取功能;
數據操作控件:根據不同的基礎功能需求將Transform算子抽象成數據處理控件類,制定相應的配置規范,使用時只需根據規范配置文件,系統根據配置創建相應的實例化對象實現數據處理功能;
數據輸出控件:將Sink算子抽象成數據輸出控件類,制定相應的配置規范,使用時只需根據規范配置文件,系統根據配置創建實例化對象實現數據輸出功能。
同時系統內部明確定義flink算子之間流轉的數據格式作為內部流轉數據格式以及根據配置輸出每個基礎功能控件輸出的數據格式。
第二步,根據抽象定義的基礎功能控件,制定具體配置規范
基礎功能控件規范如下:
通過以上兩步規范定義后,在同一個系統中,同一個處理過程只需要定義一個基礎功能控件規范。如Kafka消費者所需的配置如Kafka集群地址、消費群組、數據所在topic、數據所在分區key,消費位置等,只需要規定上述舉例這樣一個Kafka消費控件并開發實現,該控件就可以在該系統中復用,每次配置的數據處理工作流,復用Kafka消費控件類并根據新配置的源系統提供的Kafka集群地址、數據所在topic等配置即可實例化該工作流所需的kafka 消費者,實現過程從開發無數次Kafka Consumer的代碼變為實現一次Kafka Consumer控件代碼,大量節省開發時間和開發成本。
第三步,通過對基本功能的抽象,實現如HTTP請求、kafka生產、數據遍歷、條件循環、數據映射、MySQL寫操作等基礎功能控件并實現,再根據各個基礎功能運行的先后邏輯組裝相應配置執行腳本來編排組建成一個完整flink流處理鏈路,即可完成不同系統間的數據集成功能。
如在私有化項目中有將設備廠商云平臺中智能門鎖狀態信息同步至自有云平臺進行智能門鎖控制的需求,由于智能門鎖設備協議與自有物聯網平臺數據采集協議不適配,無法直連,由設備廠商云平臺提供智能門鎖狀態信息推送功能,由自有物聯網平臺提供推送數據接收接口,完成智能門鎖狀態信息的同步功能。
在此案例中,通過flink框架的自定義Source算子實現HTTP POST功能接口的HTTP監聽控件完成設備廠商云平臺的推送數據接收功能,將接收到的智能門鎖狀態信息根據智能門鎖ID、狀態status與自有云平臺存儲的狀態進行比較的IF分支控件,將存在狀態變化的智能門鎖狀態信息數據向后序Sink算子流轉,通過自定義Sink算子實現自有云平臺數據上傳功能,完成智能門鎖狀態信息的跨平臺更新功能。

第四步,根據組建好的執行邏輯生成有向無環圖,提交Flink運行,具體如下:
通過對不同的基礎功能控件,基于有向無環圖,將基礎功能控件放入有向無環圖的頂點,其中整個圖中只有一個數據源控件,且無其他基礎功能控件可以將數據傳輸給它;數據輸出控件和數據操作控件可以多個,對應多條分支處理邏輯。將數據傳輸方向作為有向無環圖的邊,以此連接和組織跨系統數據傳輸過程中針對數據的不同邏輯順序,生成一條完整的數據傳輸處理鏈路,將此圖完整實現,提交flink執行,即可實現完整的數據抽取、轉換以及輸出的數字集成功能。
4
總結
最后我們來總結下基于Flink的數字集成能力的實現。得益于flink在ETL數據集成上的豐富能力以及算子之間易于處理的基礎功能,我們將flink的3類算子進行抽象定義實現3類基礎功能控件,實現不同的數據處理過程。根據不同的功能需求,通過Source算子實現從消息隊列、API、數據庫等多種數據源抽取數據的功能;通過豐富的Transform算子實現數據的清洗、篩選、轉換的功能;最后可通過Sink算子實現將目標格式數據輸入目標系統接收數據的渠道如消息隊列、數據庫、API等。綜上所述,基于Flink的數字集成能力是可以實現并且具備豐富功能和可擴展性的。
審核編輯:劉清
-
以太網
+關注
關注
40文章
5459瀏覽量
172366 -
數據采集
+關注
關注
39文章
6238瀏覽量
113897 -
MYSQL數據庫
+關注
關注
0文章
96瀏覽量
9420 -
HTTP協議
+關注
關注
0文章
66瀏覽量
9762
原文標題:基于flink的數字集成方案
文章出處:【微信號:CloudBrain-TT,微信公眾號:云腦智庫】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于圖遍歷的Flink任務畫布模式下零代碼開發實現方案

萬界星空科技MES數據的集成方式
音響集成電路是數字集成電路嗎
soc是數字芯片還是模擬芯片
什么是 Flink SQL 解決不了的問題?
兩種集成方案靈活搭建遠控方案,向日葵API集成方案解析
求一種基于RX13T的風扇電機控制方案
一種新的微帶線和矩形波導集成形結構研究
求一種汽車域控制器DCU電源浪涌過壓保護方案
求遠電子推出一種基于MP2796的ESS戶儲BMS方案





 工商網監
工商網監
評論