

一、MapReduce
(1)MapReduce概要介紹
MapReduce是一種編程模型,可用于大規模數據集(數據量大于1TB的數據集)的并行運算(根據百度百科:并行運算是一種一次可執行多個指令的算法,可提高計算速度)。MapReduce可使程序的并行運算更加簡單。
Map(映射)是于各個節點對本地數據的預處理操作。 Reduce(歸約)是將Map預處理操作后的數據匯總。Reduce可使編程人員不必關心如何實現分布式并行程序,基于Reduce,編程人員可只關注業務數據處理。
(2)處理模型
MapReduce框架負責處理并行計算中的復雜問題,包括:分布式存儲、作業調度、負載均衡、容錯處理、網絡通信等。
MapReduce的處理流程如圖一所示。
首先,數據在數據節點被劃分為數據塊(個人理解:數據塊即圖一中的split),MapReduce確定待處理的數據塊數量并確定每個記錄(個人理解:此處記錄可被理解關系數據庫的一行數據)在數據塊中的位置;
然后,劃分后的數據塊作為Map的輸入;
再然后,Map的輸出數據需要經過sort(個人理解:分類)、copy(個人理解:復制)、merge(個人理解:合并)操作成為Reduce的輸入,Reduce的輸入數據間沒有交集,系統中處于Reduce運行的節點的數量等于merge操作后的數據數量;
最后,輸出Reduce運行后的數據。 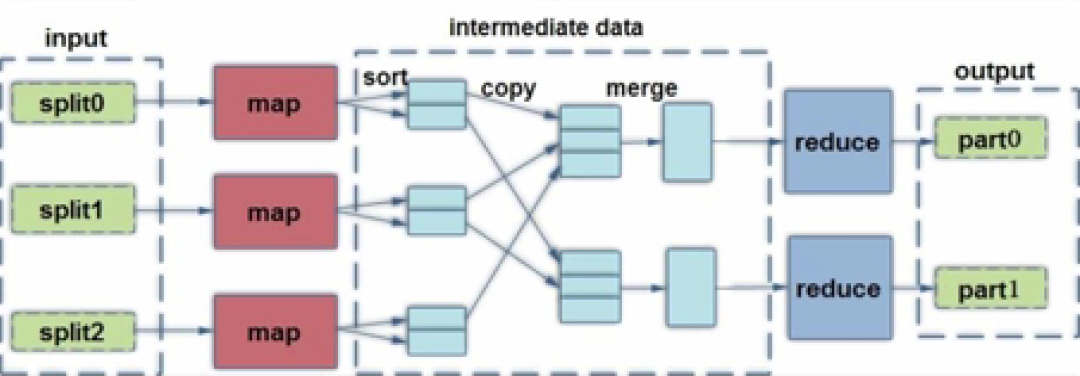
圖一,圖片來源:學堂在線《大數據導論》
二、Spark
(1)Spark概要介紹
Spark是針對大規模數據處理的快速通用引擎,其功能是類似MapReduce的計算引擎。
(2)Spark的特點
1)計算速度快。Spark計算速度是Hadoop計算速度的一百倍。
2)可用性高。Spark可使用Java、Python、R、SQL等編程語言。
3)通用性。Spark由一系列解決處理復雜問題的組件構成,可處理多種類型有關數據庫的復雜問題。
4)可運行于多種環境中,運行環境包括Hadoop等。
圖片來源:學堂在線《大數據導論》
(3)Spark的體系架構
1)Cluster Manager:Cluster Manager是主節點,控制整個集群,監控 Worker Node。
2)Worker Node:Worker Node是從節點,負責控制計算節點,啟動Executor 或者Driver
3)Driver:運行Application(個人理解:此處Application指某一應用)的main()函數
4)Executor:為Application運行Worker Node上的一個進程。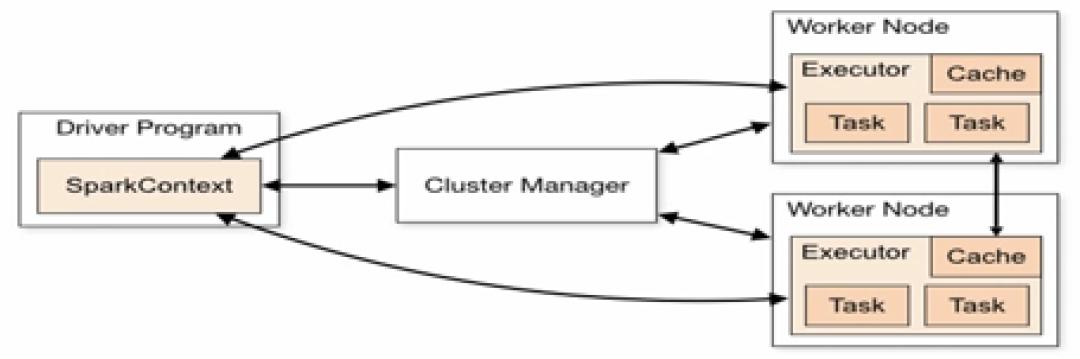
圖片來源:學堂在線《大數據導論》
(4)RDD
RDD(Resilient Distributed Dataset)被稱為彈性分布式數據集,利用SparkContext實例(根據網絡資料理解:每個SparkContext實例是Spark的一個應用)創建的對象均為RDD。RDD是不可變、可分區、其內部元素可并行計算的集合,數據可在RDD中運行RDD的自有函數。
RDD的函數被稱為RDD算子,RDD算子分為Transformation和Action兩種類型。Transformation具有類似于MapReduce的功能,Action的功能包括:觸發RDD計算、統計RDD元素個數等。
RDD的特點包括:自動容錯、位置感知性調度、可伸縮性(個人理解:數據量的多少對RDD的運行影響較小)、可在已有RDD的基礎上創建新的RDD、延遲執行(延遲執行即Transformation只有在Action被觸發后才執行)。
另外,RDD允許用戶在執行多個查詢時可將工作集緩存在內存中,后續的查詢可重用工作集,可提升查詢速度。
審核編輯:劉清
-
SQL
+關注
關注
1文章
777瀏覽量
44591 -
編程語言
+關注
關注
10文章
1952瀏覽量
35519 -
RDD
+關注
關注
0文章
7瀏覽量
8041 -
SPARK
+關注
關注
1文章
105瀏覽量
20227 -
MapReduce
+關注
關注
0文章
45瀏覽量
6435
原文標題:大數據相關介紹(22)——MapReduce和Spark
文章出處:【微信號:行業學習與研究,微信公眾號:行業學習與研究】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
NVIDIA加速的Apache Spark助力企業節省大量成本

CAN通信協議——中文版
NVIDIA GTC2025 亮點 NVIDIA推出 DGX Spark個人AI計算機

NVIDIA 宣布推出 DGX Spark 個人 AI 計算機


IEEE2030.5概要
spark為什么比mapreduce快?
PGA309正常只校準一個溫度點大概要多久時間呢?
廣汽能源與泰國Spark EV簽訂合作框架協議
spark運行的基本流程
Spark基于DPU的Native引擎算子卸載方案

關于Spark的從0實現30s內實時監控指標計算
“Spark+Hive”在DPU環境下的性能測評 | OLAP數據庫引擎選型白皮書(24版)DPU部分節選





 工商網監
工商網監

評論