 李開復稱AI 2.0已至,將籌建新AI公司,中文版ChatGPT熱背后的冷思考
李開復稱AI 2.0已至,將籌建新AI公司,中文版ChatGPT熱背后的冷思考
電子發燒友網報道(文/吳子鵬)日前,創新工場董事長兼首席執行官、創新工場人工智能工程院院長李開復在朋友圈表示,正在籌組一個全球化公司Project AI 2.0,致力于打造AI 2.0全新平臺和AI-first生產力應用。
李開復在國內被稱為“創業教父”,這條朋友圈信息表明,他和美團元老王慧文、前京東技術掌門人周伯文等人一樣,也加入到了中文版ChatGPT的混戰。
李開復和他的AI 2.0
目前,在創新工場官網已經上線“Project AI 2.0”的入口,目前主要在做兩方面的工作:其一是尋找AI大模型、NLP、Multi-modality等領域能力的優秀技術人和研究員,和團隊相關;其二是尋找具有 AI 2.0 相關技術、場景、算力、投資興趣的合作方,和合伙人相關。
那么,李開復所謂的AI 2.0到底是什么呢?是不是就單單指中文版ChatGPT。在3月14日的一場分享會上,李開復專門回答過這個問題。
李開復表示,AI 2.0 將會帶來平臺式的變革,改寫用戶的入口和界面,誕生全新平臺催生新一代 AI 2.0應用的研發和商業化。從他的描述中能夠看到,AI 2.0最大的改變應該是多模態,這使得AI 2.0突破了傳統AI 1.0的單領域、低縱效等瓶頸。
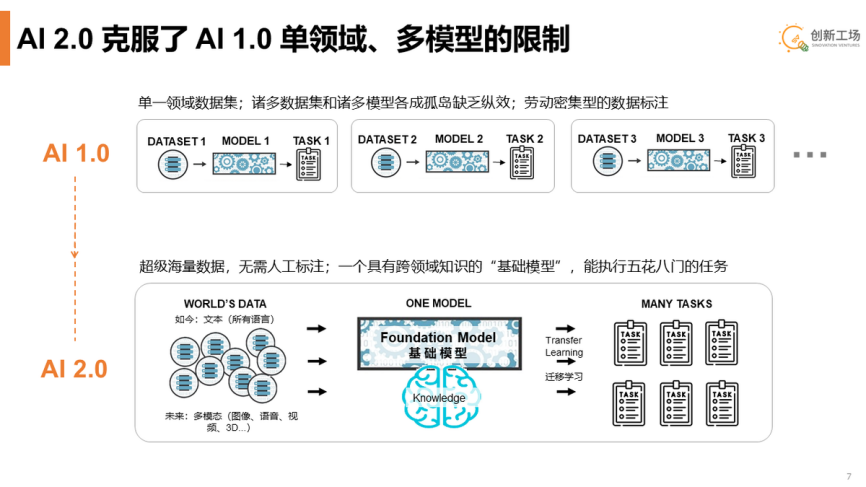
通過上面的示意圖可以看到,在AI 1.0階段,應用主要是基于單一領域的數據集,因此在諸多數據集和諸多模型之間存在很明顯的孤島效應。并且,在這個階段,需要大量的人工對數據完成標注,以提升訓練的效率。
在AI 2.0階段,大模型會容納進來更多的數據,李開復將其定義為超級海量數據。當然,為了提升訓練的效率,這些數據將不再依靠人工去標注。最終訓練得到的模型是一個跨領域知識的“基礎模型”,能夠執行各種各樣的任務。
從李開復的描述來看,當前以ChatGPT為代表的AIGC只是AI 2.0的初期,這一時期的特點是AI從輔助性工具真正開始替代人工,將在寫代碼、創意和編輯等領域最先開始。然后隨著大模型的發展,AI 2.0不會只停留在生成式AI的階段,將逐漸演化出預測、決策、探索等更高級別的認知智能。因此,AI 2.0囊括的遠景要遠遠超過以ChatGPT為代表的AIGC,絕不是單純打造一個ChatGPT中文版那么簡單。
所以說,AIGC只是AI 2.0的開端。
從李開復的言論可以看出,他對AI 2.0工作的開展非常重視,將親自帶隊。創新工場方面表示,已有多位具有全球大廠帶領大型團隊的技術管理人才,確認了加入意向。李開復講到,創新工場主要關注三大方向:AI 2.0智能應用、AI 2.0平臺、AI基礎設施。其中,AI 2.0應用將會迎來遍地開花的階段,包括各行各業的垂類AI助理、元宇宙應用等之前做不出的應用都會出現。
李開復認為,AI 2.0將分為三個階段來逐步釋放生產力。第一階段是順承AI 1.0的模式——人機協同,不過和過往逐字輸入而得到大量泛泛的答案不同,AI 2.0將使得文檔能夠通過用戶的描述而精準的輸出。不過,這一階段依然需要人工的協助,以校對AI輸出的內容是否準確。在第一階段,搜索引擎的改變是最直接的,所有用戶界面都將被重塑。
第二階段是局部自動的階段,這一時期AI將在容錯率高的領域獨自完成工作,而無需人工的介入,進而顯著提升工作效率,比較顯著的代表領域是廣告、游戲和電子商務等。
第三階段則是全自動化階段,完全不再需要人工的介入。這一階段最典型的特征是,AI將被應用于不容出錯的領域中,比如醫療、金融等。
除了自己研究之外,李開復還在朋友圈提到,“我們也積極尋找AI 2.0技術和應用相關的投資機會,加速打造AI 2.0的全新創業生態,對于AI 2.0的未來,我們具有更多更大的想象。 ”
AI 2.0的幾道門檻
綜上所述,很顯然李開復看到的AI 2.0是以ChatGPT中文版為起點,最終實現的是AI對各行各業的滲透。
不過,李開復所提到的AI 2.0在實現的過程中,有幾個明顯的門檻,并且都極具挑戰。
首先是大模型在提示和標注方面的工作,目前這方面的工作很多還是依靠人工。就以提示工作來說,這個崗位除了要求熟悉LLM架構會編程,還要求有探索思維,需要腦洞大開,用合適的描述讓AI發揮出最大的潛力,這就說明現階段的AI還不夠聰明;再看一下數據標注,我們都知道光耀的GPT大模型背后隱藏著數據標注的“血汗工廠”,為了訓練ChatGPT,OpenAI雇傭了時薪不到2美元的外包肯尼亞勞工,他們所負責的工作就是數據標注,包括數據標注、打標簽、分類、調整和處理等。這些需要人工參與的環節隨著模型規模的增加將逐漸成為明顯的限制,否則那些參數萬億級別的大模型肯定要比GPT強,現實是訓練數據更精準的GPT明顯更厲害。
其次是法律法規的缺失,GPT-3.5模型已經顯示出,如果監管不到位,ChatGPT可能存在對人類的偏見,并表現出攻擊性。目前,在GPT-4發布時,微軟依然在依賴人工對抗訓練來優化這方面,并沒有現成的法規來說明需要達到什么程度。如果繼續這樣野蠻生長,特斯拉CEO埃隆·馬斯克、ChatGPT之父Sam Altman等人的擔憂也許會成為現實,把人類尤其是分辨力不強的孩童帶入到危險的境地,甚至可能產生自主思維消滅人類。因此Sam Altman呼吁,監管機構和社會需要參與這項技術,以防止對人類可能產生的負面影響。
正如中國科學院大學人工智能學院副院長肖俊所言,ChatGPT是人工智能發展過程中的一個正常產物。而我們也都清楚,現階段以及未來的AI都需要持續依仗大數據。然而,面向公眾層面的大數據基本來源于互聯網。互聯網也被稱為數據大染缸,目前還有非常多監管不到位的問題。那么,為了讓基于大模型的應用是安全準確的,目前來看李開復所提到的超級海量數據自動篩選和標注在可預見的未來是難以做到的。否則,訓練出來的產物將非常不可控。
第三個門檻是國內需要獨自面臨的問題——國產高端計算芯片的缺失。在李開復的描述中,基礎設施建設是AI 2.0環節的重要一環。不過在現階段,我們見到GPT或者其他相關的大模型實際上都是基于英偉達的GPU在做訓練,也就說英偉達產品是當前AIGC發展的動力之源。在這方面,國內硬件差距可能是五年,軟硬件的綜合差距可能是十年。在全球主要國家和地區都關注AIGC發展時,英偉達GPU隨時都可能成為緊俏資源,或者是限制資源,那么我們在基礎設施方面的工作到時候只能被迫延后。
此前,有行業人士在接受電子發燒友網采訪時表示,目前支撐大模型訓練的算力架構從馮諾依曼開始就沒有發生過改變,計算、傳輸和存儲是三大核心環節。在這個基本框架下,國內在諸多環節處于落后并受到掣肘。因此,有從業者認為,在AIGC以及大模型狂飆的同時,國內也應該嘗試更多算力層面的創新,比如用ASIC+垂直大模型解決具體行業的問題,不再依靠英偉達的通用算力GPU;另外存內計算等創新型計算芯片也值得去關注。
后記
很明顯,李開復通過ChatGPT看到了AI 2.0時代更光明的未來,因此獨自帶隊,投身到“Project AI 2.0”項目上,也算是加入到了中文版ChatGPT的混戰。不過,AI 2.0圖謀的越大越遠,里面出現的問題就會越多,我們產業的薄弱環節也會被放大。如果這些短板不能隨著模型和算法一起得到增強,我們的AI 2.0時代很可能就是一個地基不穩的大廈,看著宏偉但經不起風吹雨打。
-
AI
+關注
關注
87文章
30728瀏覽量
268886 -
ChatGPT
+關注
關注
29文章
1558瀏覽量
7595
發布評論請先 登錄
相關推薦
大聯大推出基于MediaTek Genio 130與ChatGPT的AI語音助理方案


李開復:中國擅長打造經濟實惠的AI推理引擎
ChatGPT背后的AI背景、技術門道和商業應用

AI for Science:人工智能驅動科學創新》第4章-AI與生命科學讀后感





 工商網監
工商網監
評論