 兩萬字簡述自動駕駛路徑規劃的常用算法
兩萬字簡述自動駕駛路徑規劃的常用算法
自動駕駛自誕生那天起,其志向便已立下,成為熟知城市每一處道路的“老司機”,成為乘客更安全、更舒適、更高效出行的“守護神”。在搞錢撈錢的大背景下,這個無私追求樸素得令人敬畏。 在自動駕駛的分工中,決策規劃將承擔上述志向實現的大部分工作,也因此被毫不吝嗇的稱為自動駕駛的大腦。決策規劃這塊網上已經有數量眾多的優秀科普文章,但他們都沒有長成《十一號組織》的樣子。抱著將所有自動駕駛知識都“擼一遍”的偉大理想,我決定用兩萬字簡述決策規劃的常用算法。
01 概述
1. 1 自動駕駛系統分類
自動駕駛系統沒有嚴謹的分類,但行業內普遍喜歡將自動駕駛系統區別為模塊化的和端到端的,圖1所示為兩者系統的原理框圖對比。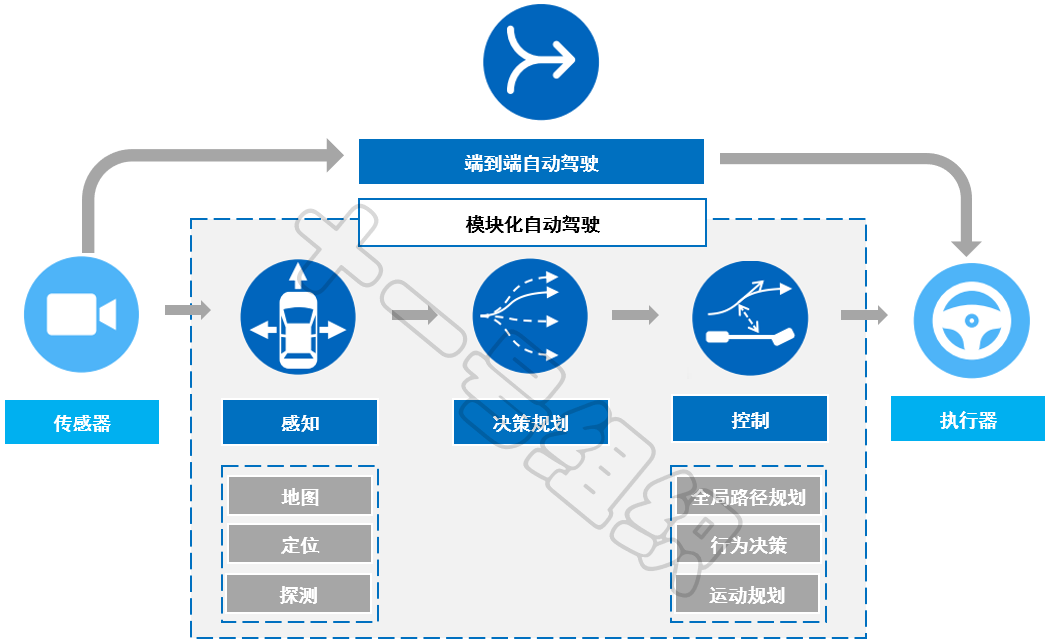
圖1 模塊化和端到端自動駕駛系統原理簡圖
1.1.1 模塊化自動駕駛系統
這是最經典也是業界采用最多的一種自動駕駛系統,也是最簡明清爽的一種結構,其作用是實時地求解出連續的控制輸出使得自動駕駛車輛可以安全地由初始位置行駛到目標位置。基于模塊化的思想,將自動駕駛系統劃分為三層:環境感知層、決策規劃層和控制執行層。每一層還可以劃分為不同的模塊,每個模塊還可以劃分為不同的子模塊……。
環境感知層就像是人的眼睛和耳朵,負責對外部環境進行感知并將感知結果送入決策規劃層。決策規劃層就像是人的大腦,在接收到感知信息后進行分析、決策,并生成加減速、變道、直行等控制命令。控制執行層就像人的雙手和雙腳,在接收到控制命令后控制執行器完成加速、轉向等操作。 模塊化自動駕駛系統中每一層都是關鍵和核心。但從實現自動駕駛功能的角度,環境感知層是基礎,決策規劃層是核心,控制執行層是保障。作為核心的決策規劃層帶著自動駕駛往“更安全、更舒適、更高效”的道路上狂奔,畢竟小小的失誤小則影響乘坐舒適性、通行效率,大則影響人身財產安全。
在模塊化自動駕駛系統中,不同團隊負責不同的模塊,可以實現更好的分工合作,從而提高開發效率。同時團隊內部可以對負責的模塊進行充分的評估,了解各模塊的性能瓶頸所在,從而讓我們能對最后的0.1%的不足有更清晰的認知,技術的迭代、更新。
缺點就是整個系統非常復雜、龐大、需要人工設計成百上千個模塊。二是對車載硬件計算能力要求高,如果越來越多的子模塊采用深度學習網絡,這將帶來災難性的計算需求爆炸。基于模塊化的自動駕駛系統,我們可能花10%的時間就實現了99.9%的問題,但我們還需要花90%的時間去解決最后0.1%的不足。 這個系統的難度之大,已經遠超一家公司的能力范圍,需要一個協作的生態。
1.1.2 端到端自動駕駛系統
術語端到端(End to End)來源于深度學習,指的是算法直接由輸入求解出所需的輸出,即算法直接將系統的輸入端連接到輸出端。2016年NVIDIA將端到端的深度學習技術應用在自動駕駛汽車之后,端到端自動駕駛迅速捕獲圈內一眾大佬的芳心,各種demo更是層出不窮。 所謂端到端自動駕駛是指車輛將傳感器采集到的信息(原始圖像數據、原始點云數據等),直接送入到一個統一的深度學習神經網絡,神經網絡經過處理之后直接輸出自動駕駛汽車的駕駛命令(方向盤轉角、方向盤轉速、油門踏板開度、制動踏板開度等)。
2016年NVIDIA發表了論文《End to End Learning for Self-Driving Cars》,拉開了端到端自動駕駛內卷的序幕。 論文首先展示了訓練數據的采集系統,如圖2所示。論文中只涉及了車道保持功能,因此訓練數據也只對攝像機的視頻數據和人類駕駛員操作方向盤的角度數據進行了采集。
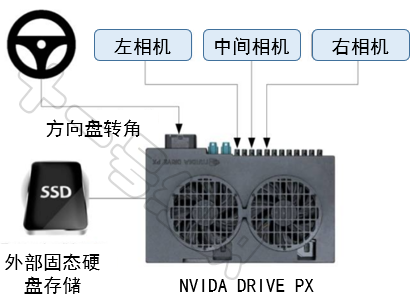
圖2 數據采集系統框圖 三架攝像機安裝在采集車的擋風玻璃后面,并按照左中右依次布置,這樣布置是為了捕獲完整的前向路面信息。一臺NVIDIA DRIVETM PX被用來作為采集車的計算單元。攝像機生成的每一幀視頻數據(30FPS)都與人類駕駛員的轉向角度進行時間同步。 采集車最終在各式道路以及多樣照明和天氣條件組合下采集了72小時的駕駛數據。訓練數據包含視頻采樣得到的單一圖像,搭配相應的轉向命令。
但是只有來自人類駕駛員的正確數據是不足以完成訓練的,神經網絡還必須學習如何從任何錯誤中恢復,否則自動駕駛汽車就將慢慢偏移道路。因此訓練數據還擴充了額外的圖像,這些圖像顯示了遠離車道中心的偏離程度以及不同道路方向上的轉動。兩個特定偏離中心的變化圖像可由左右兩個攝像機捕獲。 訓練數據準備完畢之后,將其送入一個卷積神經網絡(CNN),訓練系統框圖如圖3所示。
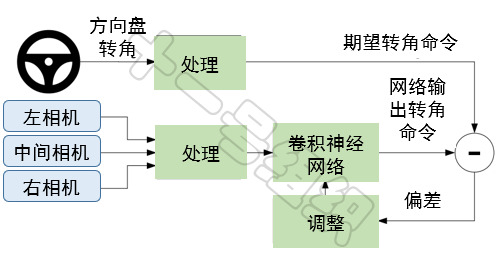
圖3 訓練系統框圖 CNN計算一個被推薦的轉向命令,這個被推薦的轉向命令會與該圖像的期望命令相比較,CNN權重就會被調整以使其實際輸出更接近期望輸出。在這個框架中,只要提供足夠的訓練數據,即人類駕駛員駕駛攜帶有攝像頭的車輛累計駕駛大量的里程,再加上人為創造系統的“極限”道路狀態——偏離道路線的各種工況,CNN就會得到充分的訓練,而變得足夠強大。 一旦訓練完成,網絡就能夠從單中心攝像機(single center camera)的視頻圖像中生成轉向命令,圖4展示了這個配置。
圖4 訓練過的網絡用于從單中心前向攝像機中生成轉向命令
在端到端自動駕駛中,沒有人工設計的繁復規則,只需要極少的來自人類的訓練數據,深度學習神經網絡就會學會駕駛。且不用關心有沒有高精地圖覆蓋、此時是行駛在高速主干路還是城區道路、道路上車道線有沒有缺失等。 相比模塊化自動駕駛系統,端到端自動駕駛系統設計難度低,硬件成本小,還能借助數據的多樣性獲得不同場景下的泛用性。各方面條件得天獨厚,從理論層面看堪稱自動駕駛的終極夢想。
然而端到端深度學習神經網絡是一個完完全全的黑盒子,不具解釋分析性,可靠性、靈活性差,工程師們沒有辦法對它進行系統化的解釋分析,而是只能依靠推測和實驗進行調整。最終帶來的結果是安全難以得到保障,而自動駕駛最最關注的恰是安全。
比如端到端自動駕駛系統下汽車做出一個汽車減速左轉的行動,工程師們無法確定這是因為汽車看到行人,還是因為看到較遠處的紅燈。但是,在模塊化的自動駕駛系統下,由于多個識別系統嵌套,相對好理解到底汽車所做的每一個舉動背后的邏輯。
這也意味著,如果端到端系統出現問題時,工程師們并不能對其對癥下藥,做出合理的應對。更多情況下甚至只能簡單向模型灌注更多的數據,希冀它能在進一步的訓練中“自行”解決問題。這也會大大降低端到端自動駕駛系統原本開發簡單的優勢。
1.2 決策規劃分層架構
決策規劃的任務,就是在對感知到的周邊物體的預測軌跡的基礎上,結合結合自動駕駛車輛的和當前位置,對車輛做出最合理的決策和控制。 正如人的大腦又分為左腦和右腦、并負責不同的任務一樣,模塊化自動駕駛系統中決策規劃層也可以繼續細分為執行不同任務的子層。而這一分層設計最早其實是源自2007年舉辦的DAPRA城市挑戰賽,比賽中多數參賽隊伍都將自動駕駛系統的決策規劃方式包括三層:全局路徑規劃層(Route Planning)、行為決策層(Behavioral Layer)和運動規劃層(Motion Planning),如圖5所示。
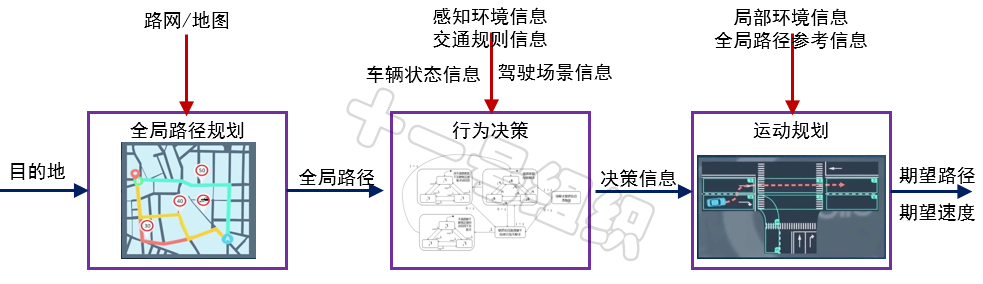
圖5決策規劃分層架構
全局路徑規劃層聚焦在相對頂層的路徑規劃,聚焦在分鐘到小時級別的規劃。該層在接收到輸入的目的地信息后,基于存儲的地圖信息搜索出一條自起始點至目標點的一條可通過的路徑。如圖6所示,在藍色起點和黃色終點之間,黑色就是搜索出來的一條可通行的路徑,當然路徑不止一條,如何搜索出最優是下文將要介紹的內容。
在全局路徑規劃的時候,也可以基于地圖精度和豐富度,提前考慮道路曲率半徑、坡度等信息,來避免搜索出部分參數超出ODD要求的全局路徑。但是高度隨機的交通參與者、高度動態的交通流以及高度復雜的道路結構,全局路徑規劃是無法考慮周到的,因此還需要基于具體的行為決策進行后面的運動規劃,也就是局部路徑規劃。
行為決策層在收到全局路徑后,結合感知環境信息、交通規則信息、車輛狀態信息、駕駛場景信息等,推導判斷下一分鐘或下一秒時刻的情況,作出車道保持、車輛跟隨、車道變換和制動避撞等的適合當前交通環境的駕駛行為。如圖7所示,自車在檢測到前方存在低速行駛車輛,且右側車道滿足變道條件后,作出向右變道的駕駛行為決策。
運動規劃層也被稱為局部路徑規劃層,與全局路徑規劃聚焦在分鐘到小時級別的規劃不同,運動規劃聚焦在毫秒級到秒級的規劃。規劃的時候,根據輸入的行為決策信息、結合車輛實時位姿信息、局部環境信息、全局路徑參考信息等,在“安全、舒適、效率”的精神引領下,規劃生成一條滿足特定約束條件的平滑軌跡軌跡(包括行駛軌跡、速度、方向等),并輸入給控制執行層。 如圖8所示,在車輛收到行為決策層的左變道指令后,主車基于各種信息規劃出幾條可行的路徑,如何規劃出最優的路徑也是下文要介紹的內容。
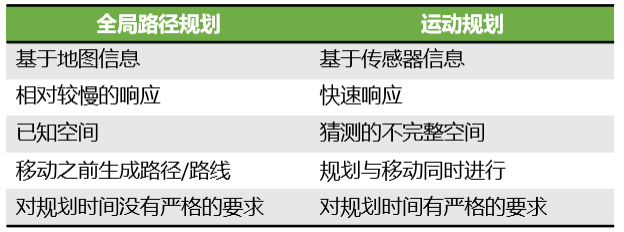
全局路徑規劃與運動規劃作為兩個層級的不同規劃,現將其特點匯總為表1。
表1 全局路徑規劃與運動規劃特點對比
02 全局路徑規劃常用算法
正菜之前,我們先來了解一下圖(包括有向圖和無向圖)的概念。圖是圖論中的基本概念,用于表示物體與物體之間存在某種關系的結構。在圖中,物體被稱為節點或頂點,并用一組點或小圓圈表示。節點間的關系稱作邊,可以用直線或曲線來表示節點間的邊。
如果給圖的每條邊規定一個方向,那么得到的圖稱為有向圖,其邊也稱為有向邊,如圖9所示。在有向圖中,與一個節點相關聯的邊有出邊和入邊之分,而與一個有向邊關聯的兩個點也有始點和終點之分。相反,邊沒有方向的圖稱為無向圖。
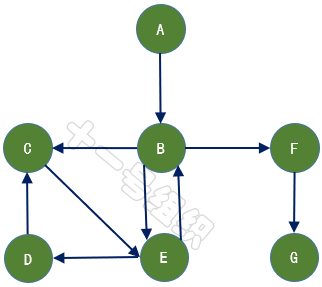
圖9 有向圖示例
數學上,常用二元組G =(V,E)來表示其數據結構,其中集合V稱為點集,E稱為邊集。對于圖6所示的有向圖,V可以表示為{A,B,C,D,E,F,G},E可以表示為{
在圖的邊中給出相關的數,稱為權。權可以代表一個頂點到另一個頂點的距離、耗費等,帶權圖一般稱為網。
在全局路徑規劃時,通常將圖10所示道路和道路之間的連接情況,通行規則,道路的路寬等各種信息處理成有向圖,其中每一個有向邊都是帶權重的,也被稱為路網(Route Network Graph)。
那么,全局路徑的規劃問題就變成了在路網中,搜索到一條最優的路徑,以便可以盡快見到那個心心念念的她,這也是全局路徑規劃算法最樸素的愿望。而為了實現這個愿望,誕生了Dijkstra和A*兩種最為廣泛使用的全局路徑搜索算法。
2.1Dijkstra算法
戴克斯特拉算法(Dijkstra’s algorithm)是由荷蘭計算機科學家Edsger W. Dijkstra在1956年提出,解決的是有向圖中起點到其他頂點的最短路徑問題。
假設有A、B、C、D、E、F五個城市,用有向圖表示如圖11,邊上的權重代表兩座城市之間的距離,現在我們要做的就是求出起點A城市到其它城市的最短距離。
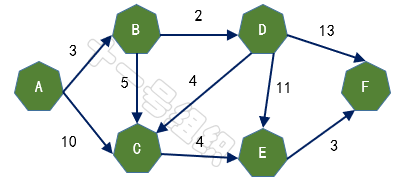
圖11 五個城市構建的有向圖
用Dijkstra算法求解步驟如下:
(1)創建一個二維數組E來描述頂點之間的距離關系,如圖12所示。E[B][C]表示頂點B到頂點C的距離。自身之間的距離設為0,無法到達的頂點之間設為無窮大。
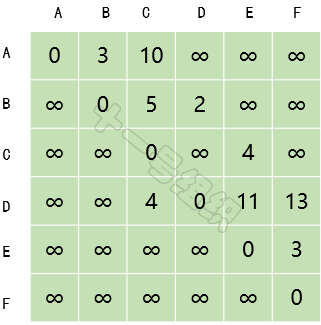
圖12 頂點之間的距離關系
(2)創建一個一維數組Dis來存儲起點A到其余頂點的最短距離。一開始我們并不知道起點A到其它頂點的最短距離,一維數組Dis中所有值均賦值為無窮大。接著我們遍歷起點A的相鄰頂點,并將與相鄰頂點B和C的距離3(E[A][B])和10(E[A][C])更新到Dis[B]和Dis[C]中,如圖13所示。這樣我們就可以得出起點A到其余頂點最短距離的一個估計值。
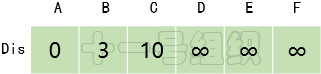
圖13 Dis經過一次遍歷后得到的值
(3)接著我們尋找一個離起點A距離最短的頂點,由數組Dis可知為頂點B。頂點B有兩條出邊,分別連接頂點C和D。因起點A經過頂點B到達頂點C的距離8(E[A][B] + E[B][C] = 3 + 5)小于起點A直接到達頂點C的距離10,因此Dis[C]的值由10更新為8。同理起點A經過B到達D的距離5(E[A][B] + E[B][D] = 3 + 2)小于初始值無窮大,因此Dis[D]更新為5,如圖14所示。
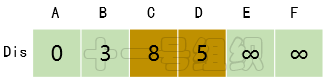
圖14Dis經過第二次遍歷后得到的值
(4)接著在剩下的頂點C、D、E、F中,選出里面離起點A最近的頂點D,繼續按照上面的方式對頂點D的所有出邊進行計算,得到Dis[E]和Dis[F]的更新值,如圖15所示。
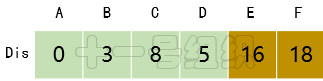
圖15 Dis經過第三次遍歷后得到的值
(5)繼續在剩下的頂點C、E、F中,選出里面離起點A最近的頂點C,繼續按照上面的方式對頂點C的所有出邊進行計算,得到Dis[E]的更新值,如圖16所示。
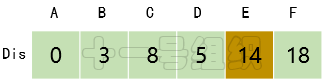
圖16 Dis經過第四次遍歷后得到的值
(6)繼續在剩下的頂點E、F中,選出里面離起點A最近的頂點E,繼續按照上面的方式對頂點E的所有出邊進行計算,得到Dis[F]的更新值,如圖17所示。
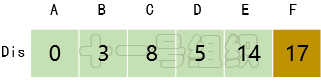
圖17 Dis經過第五次遍歷后得到的值
(7)最后對頂點F所有點出邊進行計算,此例中頂點F沒有出邊,因此不用處理。至此,數組Dis中距離起點A的值都已經從“估計值”變為了“確定值”。
基于上述形象的過程,Dijkstra算法實現過程可以歸納為如下步驟:
(1)將有向圖中所有的頂點分成兩個集合P和Q,P用來存放已知距離起點最短距離的頂點,Q用來存放剩余未知頂點。可以想象,一開始,P中只有起點A。同時我們創建一個數組Flag[N]來記錄頂點是在P中還是Q中。對于某個頂點N,如果Flag[N]為1則表示這個頂點在集合P中,為1則表示在集合Q中。
(2)起點A到自己的最短距離設置為0,起點能直接到達的頂點N,Dis[N]設為E[A][N],起點不能直接到達的頂點的最短路徑為設為∞。
(3)在集合Q中選擇一個離起點最近的頂點U(即Dis[U]最小)加入到集合P。并計算所有以頂點U為起點的邊,到其它頂點的距離。例如存在一條從頂點U到頂點V的邊,那么可以通過將邊U->V添加到尾部來拓展一條從A到V的路徑,這條路徑的長度是Dis[U]+e[U][V]。如果這個值比目前已知的Dis[V]的值要小,我們可以用新值來替代當前Dis[V]中的值。
(4)重復第三步,如果最終集合Q結束,算法結束。最終Dis數組中的值就是起點到所有頂點的最短路徑。
2.2A*算法
1968年,斯坦福國際研究院的Peter E. Hart, Nils Nilsson以及Bertram Raphael共同發明了A*算法。A*算法通過借助一個啟發函數來引導搜索的過程,可以明顯地提高路徑搜索效率。
下文仍以一個實例來簡單介紹A*算法的實現過程。如圖18所示,假設小馬要從A點前往B點大榕樹底下去約會,但是A點和B點之間隔著一個池塘。為了能盡快提到達約會地點,給姑娘留下了一個守時踏實的好印象,我們需要給小馬搜索出一條時間最短的可行路徑。
A*算法的第一步就是簡化搜索區域,將搜索區域劃分為若干柵格。并有選擇地標識出障礙物不可通行與空白可通行區域。一般地,柵格劃分越細密,搜索點數越多,搜索過程越慢,計算量也越大;柵格劃分越稀疏,搜索點數越少,相應的搜索精確性就越低。
如圖19所示,我們在這里將要搜索的區域劃分成了正方形(當然也可以劃分為矩形、六邊形等)的格子,圖中藍色格子代表A點(小馬當前的位置),紫色格子代表B點(大榕樹的位置),灰色格子代表池塘。同時我們可以用一個二維數組S來表示搜素區域,數組中的每一項代表一個格子,狀態代表可通行和不可通行。
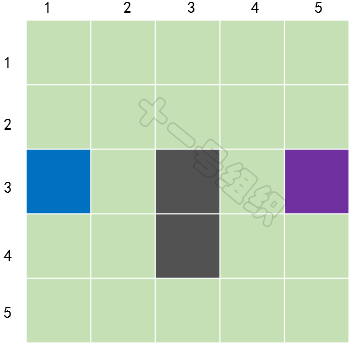
圖19 經過簡化后的搜索區域
接著我們引入兩個集合OpenList和CloseList,以及一個估價函數F = G + H。OpenList用來存儲可到達的格子,CloseList用來存儲已到達的格子。G代表從起點到當前格子的距離,H表示在不考慮障礙物的情況下,從當前格子到目標格子的距離。F是起點經由當前格子到達目標格子的總代價,值越小,綜合優先級越高。
G和H也是A*算法的精髓所在,通過考慮當前格子與起始點的距離,以及當前格子與目標格子的距離來實現啟發式搜索。對于H的計算,又有兩種方式,一種是歐式距離,一種是曼哈頓距離。
歐式距離用公式表示如下,物理上表示從當前格子出發,支持以8個方向向四周格子移動(橫縱向移動+對角移動)。
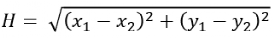
曼哈頓距離用公式表示如下,物理上表示從當前格子出發,支持以4個方向向四周格子移動(橫縱向移動)。這是A*算法最常用的計算H值方法,本文H值的計算也采用這種方法。
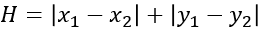
現在我們開始搜索,查找最短路徑。首先將起點A放入到OpenList中,并計算出此時OpenList中F值最小的格子作為當前方格移入到CloseList中。由于當前OpenList中只有起點A這個格子,所以將起點A移入CloseList,代表這個格子已經檢查過了。
接著我們找出當前格子A上下左右所有可通行的格子,看它們是否在OpenList當中。如果不在,加入到OpenList中計算出相應的G、H、F值,并把當前格子A作為它們的父節點。本例子,我們假設橫縱向移動代價為10,對角線移動代價為14。
我們在每個格子上標出計算出來的F、G、H值,如圖20所示,左上角是F,左下角是G,右下角是H。通過計算可知S[3][2]格子的F值最小,我們把它從OpenList中取出,放到CloseList中。
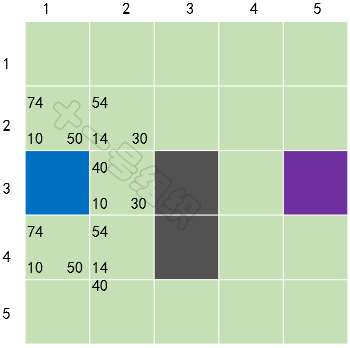
圖20 第一輪計算后的結果
接著將S[3][2]作為當前格子,檢查所有與它相鄰的格子,忽略已經在CloseList或是不可通行的格子。如果相鄰的格子不在OpenList中,則加入到OpenList,并將當前方格子S[3][2]作為父節點。
已經在OpenList中的格子,則檢查這條路徑是否最優,如果非最優,不做任何操作。如果G值更小,則意味著經由當前格子到達OpenList中這個格子距離更短,此時我們將OpenList中這個格子的父節點更新為當前節點。
對于當前格子S[3][2]來說,它的相鄰5個格子中有4個已經在OpenList,一個未在。對于已經在OpenList中的4個格子,我們以它上面的格子S[2][2]舉例,從起點A經由格子S[3][2]到達格子S[2][2]的G值為20(10+10)大于從起點A直接沿對角線到達格子S[2][2]的G值14。顯然A經由格子S[3][2]到達格子S[2][2]不是最優的路徑。當把4個已經在OpenList 中的相鄰格子都檢查后,沒有發現經由當前方格的更好路徑,因此我們不做任何改變。
對于未在OpenList的格子S[2][3](假設小馬可以斜穿墻腳),加入OpenList中,并計算它的F、G、H值,并將當前格子S[3][2]設置為其父節點。經歷這一波騷操作后,OpenList中有5個格子,我們需要從中選擇F值最小的那個格子S[2][3],放入CloseList中,并設置為當前格子,如圖21所示。
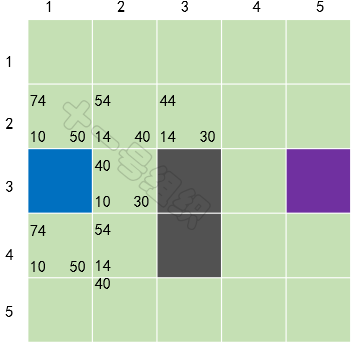
圖21第二輪計算后的結果
重復上面的故事,直到終點也加入到OpenList中。此時我們以當前格子倒推,找到其父節點,父節點的父節點……,如此便可搜索出一條最優的路徑,如圖22中紅色圓圈標識。
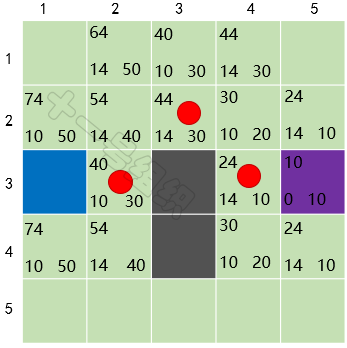
圖22 最后計算得到的結果
基于上述形象的過程,A*算法實現過程可以歸納為如下步驟:
(1)將搜索區域按一定規則劃分,把起點加入OpenList。
(2)在OpenList中查找F值最小的格子,將其移入CloseList,并設置為當前格子。
(3)查找當前格子相鄰的可通行的格子,如果它已經在OpenList中,用G值衡量這條路徑是否更好。如果更好,將該格子的父節點設置為當前格子,重新計算F、G值,如果非更好,不做任何處理;如果不在OpenList中,將它加入OpenList中,并以當前格子為父節點計算F、G、H值。
(4)重復步驟(2)和步驟(3),直到終點加入到OpenList中。
2.3兩種算法比較
Dijkstra算法的基本思想是“貪心”,主要特點是以起點為中心向周圍層層擴展,直至擴展到終點為止。通過Dijkstra算法得出的最短路徑是最優的,但是由于遍歷沒有明確的方向,計算的復雜度比較高,路徑搜索的效率比較低。且無法處理有向圖中權值為負的路徑最優問題。
A*算法將Dijkstra算法與廣度優先搜索(Breadth-First-Search,BFS)算法相結合,并引入啟發函數(估價函數),大大減少了搜索節點的數量,提高了搜索效率。但是A*先入為主的將最早遍歷路徑當成最短路徑,不適用于動態環境且不太適合高維空間,且在終點不可達時會造成大量性能消耗。
圖24是兩種算法路徑搜索效率示意圖,左圖為Dijkstra算法示意圖,右圖為A*算法示意圖,帶顏色的格子表示算法搜索過的格子。由圖23可以看出,A*算法更有效率,手術的格子更少。
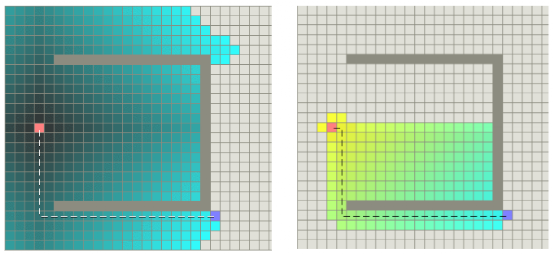
圖23 Dijkstra算法和A*算法搜索效率對比圖(圖片來源:https://mp.weixin.qq.com/s/myU204Uq3tfuIKHGD3oEfw)
03 行為決策常用算法
作為L4級自動駕駛的優秀代表Robotaxi,部分人可能已經在自己的城市欣賞過他們不羈的造型,好奇心強烈的可能都已經體驗過他們的無人“推背”服務。作為一個占有天時地利優勢的從業人員,我時常在周末選一個人和的時間,叫個免費Robotaxi去超市買個菜。
剛開始幾次乘坐,我的注意力全都放在安全員的雙手,觀察其是否在接管;過了一段時間,我的注意力轉移到中控大屏,觀察其夢幻般的交互方式;而現在,我的注意力轉移到了智能上,觀察其在道路上的行為決策是否足夠聰明。 而這一觀察,竟真總結出不少共性問題。比如十字路口左轉,各家Robotaxi總是表現的十分小心謹慎,人類司機一腳油門過去的場景,Robotaxi總是再等等、再看看。且不同十字路口同一廠家的Robotaxi左轉的策略基本一致,完全沒有人類司機面對不同十字路口、不同交通流、不同天氣環境時的“隨機應變”。
面對復雜多變場景時自動駕駛行為決策表現出來的小心謹慎,像極了人類進入一個新環境時采取的猥瑣發育策略。但在自動駕駛終局到來的那天,自動駕駛的決策規劃能否像人類一樣,在洞悉了人情社會的生活法則之后,做到“見人說人話”、“見人下飯”呢? 在讓自動駕駛車輛的行為決策變得越來越像老司機的努力過程中,主要誕生了基于規則和基于學習的兩大類行為決策方法。
3.1基于規則的方法
在基于規則的方法中,通過對自動駕駛車輛的駕駛行為進行劃分,并基于感知環境、交通規則等信息建立駕駛行為規則庫。自動駕駛車輛在行駛過程中,實時獲取交通環境、交通規則等信息,并與駕駛行為規則庫中的經驗知識進行匹配,進而推理決策出下一時刻的合理自動駕駛行為。
正如全局路徑規劃的前提是地圖一樣,自動駕駛行為分析也成為基于規則的行為決策的前提。不同應用場景下的自動駕駛行為不完全相同,以高速主干路上的L4自動駕駛卡車為例,其自動駕駛行為可簡單分解為單車道巡航、自主變道、自主避障三個典型行為。
單車道巡航是卡車L4自動駕駛系統激活后的默認狀態,車道保持的同時進行自適應巡航。此駕駛行為還可以細分定速巡航、跟車巡航等子行為,而跟車巡航子行為還可以細分為加速、加速等子子行為,真是子子孫孫無窮盡也。 自主變道是在變道場景(避障變道場景、主干路變窄變道場景等)發生及變道空間(與前車和后車的距離、時間)滿足后進行左/右變道。自主避障是在前方出現緊急危險情況且不具備自主變道條件時,采取的緊急制動行為,避免與前方障礙物或車輛發生碰撞。其均可以繼續細分,此處不再展開。
上面列舉的駕駛行為之間不是獨立的,而是相互關聯的,在一定條件滿足后可以進行實時切換,從而支撐起L4自動駕駛卡車在高速主干路上的自由自在。現將例子中的三種駕駛行為之間的切換條件簡單匯總如表2,真實情況比這嚴謹、復雜的多,此處僅為后文解釋基于規則的算法所用。
表2 狀態間的跳轉事件
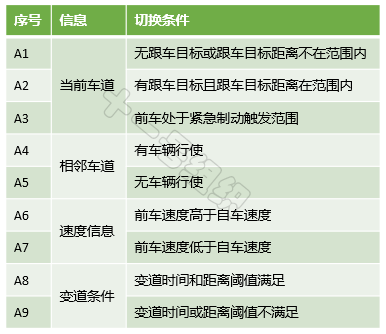
在基于規則的方法中,有限狀態機(FiniteStateMaechine,FSM)成為最具有代表性的方法。2007年斯坦福大學參加DARPA城市挑戰賽時的無人車“Junior”,其行為決策采用的就是有限狀態機方法。 有限狀態機是一種離散的數學模型,也正好符合自動駕駛行為決策的非連續特點,主要用來描述對象生命周期內的各種狀態以及如何響應來自外界的各種事件。有限狀態機包含四大要素:狀態、事件、動作和轉移。
事件發生后,對象產生相應的動作,從而引起狀態的轉移,轉移到新狀態或維持當前狀態。 我們將上述駕駛行為定義為有限狀態機的狀態,每個狀態之間在滿足一定的事件(或條件)后,自動駕駛車輛執行一定的動作后,就可以轉移到新的狀態。
比如單車道巡航狀態下,前方車輛低速行駛,自車在判斷旁邊車道滿足變道條件要求后,切換到自主變道狀態。自主變道完成后,系統再次回到單車道巡航狀態。 結合表2中的切換條件,各個狀態在滿足一定事件(或條件)后的狀態跳轉示意圖如圖24所示。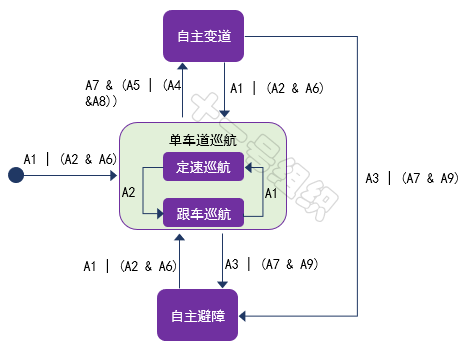
圖24 狀態跳轉示意圖
基于有限狀態機理論構建的智能車輛自動駕駛行為決策系統,可將復雜的自動駕駛過程分解為有限個自動駕駛駕駛行為,邏輯推理清晰、應用簡單、實用性好等特點,使其成為當前自動駕駛領域目前最廣泛使用的行為決策方法。 但該方法沒有考慮環境的動態性、不確定性以及車輛運動學以及動力學特性對駕駛行為決策的影響,因此多適用于簡單場景下,很難勝任具有豐富結構化特征的城區道路環境下的行為決策任務。
3.2 基于學習的方法
上文介紹的基于規則的行為決策方法依靠專家經驗搭建的駕駛行為規則庫,但是由于人類經驗的有限性,智能性不足成為基于規則的行為決策方法的最大制約,復雜交通工況的事故率約為人類駕駛員的百倍以上。鑒于此,科研工作者開始探索基于學習的方法,并在此基礎上了誕生了數據驅動型學習方法和強化學習方法。
數據驅動型學習是一種依靠自然駕駛數據直接擬合神經網絡模型的方法,首先用提前采集到的老司機開車時的自然駕駛數據訓練神經網絡模型,訓練的目標是讓自動駕駛行為決策水平接近老司機。
而后將訓練好的算法模型部署到車上,此時車輛的行為決策就像老司機一樣,穿行在大街小巷。讀者可參見端到端自動駕駛章節中介紹的NVIDIA demo案例。 強化學習方法通過讓智能體(行為決策主體)在交互環境中以試錯方式運行,并基于每一步行動后環境給予的反饋(獎勵或懲罰),來不斷調整智能體行為,從而實現特定目的或使得整體行動收益最大。通過這種試錯式學習,智能體能夠在動態環境中自己作出一系列行為決策,既不需要人為干預,也不需要借助顯式編程來執行任務。
強化學習可能不是每個人都聽過,但DeepMind開發的圍棋智能AlphaGo(阿爾法狗),2016年3月戰勝世界圍棋冠軍李世石,2017年5月后又戰勝圍棋世界排名第一柯潔的事,大家應該都有所耳聞。更過分的是,半年后DeepMind在發布的新一代圍棋智能AlphaZero(阿爾法狗蛋),通過21天的閉關修煉,就戰勝了家族出現的各種狗子們,成功當選狗蛋之王。 而賦予AlphaGo及AlphaZero戰勝人類棋手的魔法正是強化學習,機器學習的一種。
機器學習目前有三大派別:監督學習、無監督學習和強化學習。監督學習算法基于歸納推理,通過使用有標記的數據進行訓練,以執行分類或回歸;無監督學習一般應用于未標記數據的密度估計或聚類; 強化學習自成一派,通過讓智能體在交互環境中以試錯方式運行,并基于每一步行動后環境給予的反饋(獎勵或懲罰),來不斷調整智能體行為,從而實現特定目的或使得整體行動收益最大。
通過這種試錯式學習,智能體能夠在動態環境中自己作出一系列決策,既不需要人為干預,也不需要借助顯式編程來執行任務。 這像極了馬戲團訓練各種動物的過程,馴獸師一個抬手動作(環境),動物(智能體)若完成相應動作,則會獲得美味的食物(正反饋),若沒有完成相應動作,食物可能換成了皮鞭(負反饋)。
時間一久,動物就學會基于馴獸師不同的手勢完成不同動作,來使自己獲得最多數量的美食。 大道至簡,強化學習亦如此。一個戰勝人類圍棋冠軍的“智能”也僅由五部分組成:智能體(Agent)、環境(Environment)、狀態(State)、行動(Action)和獎勵(Reward)。強化學習系統架構如圖25所示,結合自動駕駛代客泊車中的泊入功能,我們介紹一下各組成的定義及作用。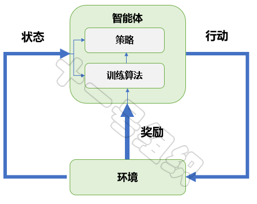
圖25 強化學習系統架構
代客泊車泊入功能的追求非常清晰,就是在不發生碰撞的前提下,實現空閑停車位的快速泊入功能。這個過程中,承載強化學習算法的控制器(域控制器/中央計算單元)就是智能體,也是強化學習訓練的主體。智能體之外的整個泊車場景都是環境,包括停車場中的立柱、車輛、行人、光照等。
訓練開始后,智能體實時從車載傳感器(激光雷達、相機、IMU、超聲波雷達等)讀取環境狀態,并基于當前的環境狀態,采取相應的轉向、制動和加速行動。如果基于當前環境狀態采用的行動,是有利于車輛快速泊入,則智能體會得到一個獎勵,反之則會得到一個懲罰。 在獎勵和懲罰的不斷刺激下,智能體學會了適應環境,學會了下次看到空閑車位時可以一把倒入,學會了面對不同車位類型時采取不同的風騷走位。 從上述例子,我們也可以總結出訓練出一個優秀的“智能”,大概有如下幾個步驟:
(1)創建環境。定義智能體可以學習的環境,包括智能體和環境之間的接口。環境可以是仿真模型,也可以是真實的物理系統。仿真環境通常是不錯的起點,一是安全,二是可以試驗。
(2)定義獎勵。指定智能體用于根據任務目標衡量其性能的獎勵信號,以及如何根據環境計算該信號。可能需要經過數次迭代才能實現正確的獎勵塑造。
(3)創建智能體。智能體由策略和訓練算法組成,因此您需要:
(a)選擇一種表示策略的方式(例如,使用神經網絡或查找表)。思考如何構造參數和邏輯,由此構成智能體的決策部分。
(b)選擇合適的訓練算法。大多數現代強化學習算法依賴于神經網絡,因為后者非常適合處理大型狀態/動作空間和復雜問題。
(4)訓練和驗證智能體。設置訓練選項(如停止條件)并訓練智能體以調整策略。要驗證經過訓練的策略,最簡單的方法是仿真。
(5)部署策略。使用生成的 C/C++ 或 CUDA 代碼等部署經過訓練的策略表示。此時無需擔心智能體和訓練算法;策略是獨立的決策系統。 強化學習方法除了具有提高行為決策智能水平的能力,還具備合并決策和控制兩個任務到一個整體、進行統一求解的能力。將決策與控制進行合并,這樣既發揮了強化學習的求解優勢,又能進一步提高自動駕駛系統的智能性。
實際上,人類駕駛員也是具有很強的整體性的,我們很難區分人類的行為中哪一部分是自主決策,哪一部分是運動控制。 現階段強化學習方法的應用還處在摸索階段,應用在自動駕駛的潛力還沒有被完全發掘出來,這讓我想起了母校的一句校歌:“能不奮勉乎吾曹?”
04 運動規劃常用算法
有了全局路徑參考信息,有了局部環境信息了,有了行為決策模塊輸入的決策信息,下一步自然而然的就要進行運動規劃,從而生成一條局部的更加具體的行駛軌跡,并且這條軌跡要滿足安全性和舒適性要求。
考慮到車輛是一個具有巨大慣性的鐵疙瘩且沒有瞬間移動的功能,如果僅考慮瞬時狀態的行駛軌跡,不規劃出未來一段時間有前瞻性的行駛軌跡,那么很容易造成一段時間后無解。因此,運動規劃生成的軌跡是一種由二維空間和一維時間組成的三維空間中的曲線,是一種偏實時的路徑規劃。
運動規劃的第一步往往采用隨機采樣算法,即走一步看一步,不斷更新行駛軌跡。代表算法是基于采樣的方法:PRM、RRT、Lattice。這類算法通過隨機采樣的方式在地圖上生成子節點,并與父節點相連,若連線與障礙物無碰撞風險,則擴展該子節點。重復上述步驟,不斷擴展樣本點,直到生成一條連接起點到終點的路徑。
4.1 PRM算法
概率路標法 (Probabilistic Road Maps, PRM),是一種經典的采樣方法,由Lydia E.等人在1996年提出。PRM主要包含三個階段,一是采樣階段,二是碰撞檢測階段,三是搜索階段。 圖26為已知起點A和終點B的地圖空間,黑色空間代表障礙物,白色空間代表可通行區域。在采樣階段中,PRM首先在地圖空間進行均勻的隨即采樣,也就是對地圖進行稀疏采樣,目的是將大地圖簡化為較少的采樣點。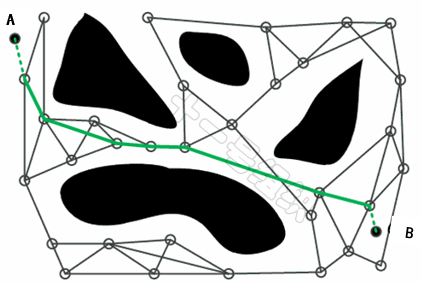
圖26 PRM工作原理示意圖
在碰撞檢測階段,剔除落在障礙物上的采樣點,并將剩下的點與其一定距離范圍內的點相連,同時刪除穿越障礙物的連線,從而構成一張無向圖。
在搜索階段,利用全局路徑規劃算法章節介紹的搜索算法(Dijkstra、A*等)在無向圖中進行搜索,從而找出一條起點A到終點B之間的可行路徑。
算法步驟可以總結為:
(1)構造無向圖G =(V,E),其中V代表隨機采樣的點集,E代表兩采樣點之間所有可能的無碰撞路徑,G初始狀態為空。
(2)隨機撒點,并選取一個無碰撞的點c(i)加入到V中。
(3)定義距離r,如果c(i)與V中某些點的距離小于r,則將V中這些點定義為c(i)的鄰域點。
(4)將c(i)與其鄰域點相連,生成連線t,并檢測連線t是否與障礙物發生碰撞,如果無碰撞,則將t加入E中。
(5)重復步驟2-4,直到所有采樣點(滿足采樣數量要求)均已完成上述步驟。
(6)采用圖搜索算法對無向圖G進行搜索,如果能找到起始點A到終點B的路線,說明存在可行的行駛軌跡。
PRM算法相比基于搜索的算法,簡化了環境、提高了效率。但是在有狹窄通道場景中,很難采樣出可行路徑,效率會大幅降低。
4.2 RRT
快速探索隨機樹(Rapidly Exploring Random Trees,RRT),是Steven M. LaValle和James J. Kuffner Jr.在1998年提出的一種基于隨機生長樹思想實現對非凸高維空間快速搜索的算法。與PRM相同的是兩者都是基于隨機采樣的算法,不同的是PRM最終生成的是一個無向圖,而RRT生成的是一個隨機樹。
RRT的最顯著特征就是具備空間探索的能力,即從一點向外探索拓展的特征。 RRT分單樹和雙樹兩種類型,單樹RRT將規起點作為隨機樹的根節點,通過隨機采樣、碰撞檢測的方式為隨機樹增加葉子節點,最終生成一顆隨機樹。而雙樹RRT則擁有兩顆隨機樹,分別以起點和終點為根節點,以同樣的方式進行向外的探索,直到兩顆隨機樹相遇,從而達到提高規劃效率的目的。
下面以圖27所示的地圖空間為例介紹單樹RRT算法的實現過程。在此地圖空間中,我們只知道起點A和終點B以及障礙物的位置(黑色的框)。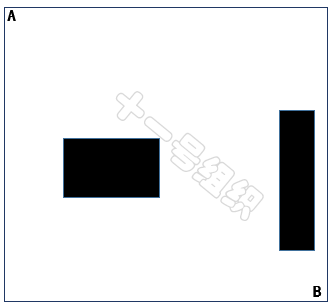
圖27 RRT算法舉例的地圖空間
對于單樹RRT算法,我們將起點A設置為隨機樹的根,并生成一個隨機采樣點,如圖27所示,隨機采樣點有下面這幾種情況。
(1)隨機采樣點1落在自由區域中,但是根節點A和隨機采樣點1之間的連線存在障礙物,無法通過碰撞檢測,采樣點1會被舍棄,重新再生成隨機采樣點。
(2)隨機采樣點2落在障礙物的位置,采樣點2也會被舍棄,重新再生成隨機采樣點。
(3)隨機采樣點3落在自由區域,且與根節點A之間的連線不存在障礙物,但是超過根節點的步長限制。但此時這個節點不會被簡單的舍棄點,而是會沿著根節點和隨機采樣點3的連線,找出符合步長限制的中間點,將這個中間點作為新的采樣點,也就是圖28中的4。
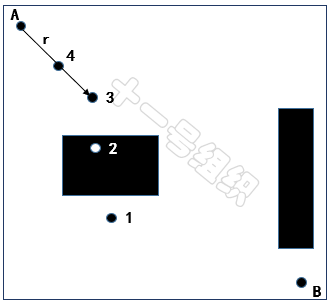
圖28 不同隨機采樣點舉例
接著我們繼續生成新的隨機采樣點,如果新的隨機采樣點位于自由區域,那么我們就可以遍歷隨機樹中已有的全部節點,找出距離新的隨機采樣點最近的節點,同時求出兩者之間的距離,如果滿足步長限制的話,我們將接著對這兩個節點進行碰撞檢測,如果不滿足步長限制的話,我們需要沿著新的隨機采樣點和最近的節點的連線方向,找出一個符合步長限制的中間點,用來替代新的隨機采樣點。
最后如果新的隨機采樣點和最近的節點通過了碰撞檢測,就意味著二者之間存在邊,我們便可以將新的隨機采樣點添加進隨機樹中,并將最近的點設置為新的隨機采樣點的父節點。 重復上述過程,直到新的隨機采樣點在終點的步長限制范圍內,且滿足碰撞檢測。則將新的隨機采樣點設為終點B的父節點,并將終點加入隨機樹,從而完成迭代,生成如圖29所示的完整隨機樹。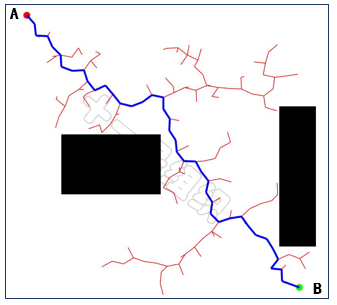
圖29隨機樹結算結果示例
相比PRM,RRT無需搜索步驟、效率更高。通過增量式擴展的方式,找到路徑后就立即結束,搜索終點的目的性更強。但是RRT作為一種純粹的隨機搜索算法,對環境類型不敏感,當地圖空間中存在狹窄通道時,因被采樣的概率低,導致算法的收斂速度慢,效率會大幅下降,有時候甚至難以在有狹窄通道的環境找到路徑。 圖30展示了 RRT應對存在狹窄通道地圖空間時的兩種表現,一種是RRT很快就找到了出路,一種是一直被困在障礙物里面。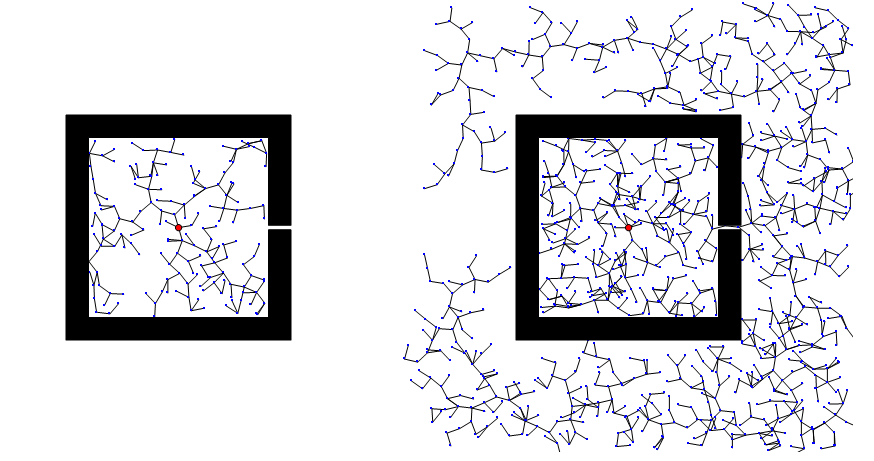
圖30 RRT面對狹窄通道時的表現
圍繞如何更好的“進行隨機采樣”、“定義最近的點”以及“進行樹的擴展”等方面,誕生了多種改進型的算法,包括雙樹RRT-Connect(雙樹)、lazy-RRT, RRT-Extend等。 PRM和RRT都是一個概率完備但非最優的路徑規劃算法,也就是只要起點和終點之間存在有效的路徑,那么只要規劃的時間足夠長,采樣點足夠多,必然可以找到有效的路徑。但是這個解無法保證是最優的。
采用PRM和RRT等隨機采樣算法生成的行駛軌跡,大多是一條條線段,線段之間的曲率也不不連續,這樣的行駛軌跡是不能保證舒適性的,所以還需要進一步進行曲線平滑、角度平滑處理。代表算法是基于曲線插值的方法:RS曲線、Dubins曲線、多項式曲線、貝塞爾曲線和樣條曲線等。 所有基于曲線插值方法要解決的問題就是:在圖31上的若干點中,求出一條光滑曲線盡可能逼近所有點。下文以多項式曲線和貝塞爾曲線為例,介紹曲線插值算法的示例。
4.3多項式曲線
找到一條曲線擬合所有的點,最容易想到的方法就是多項式曲線。常用的有三階多項式曲線、五階多項式曲線和七階多項式曲線。理論上只要多項式的階數足夠高,就可以擬合各種曲線。但從滿足需求和工程實現的角度,階數越低越好。 車輛在運動規劃中,舒適度是一個非常重要的指標,在物理中衡量舒適性的物理量為躍度(Jerk),它是加速度的導數。
Jerk的絕對值越小意味著加速度的變化越平緩,加速度的變化越平緩意味著越舒適。而五次多項式曲線則被證明是在運動規劃中可以使Jerk比較小的多項式曲線。 以圖30所示換道場景為例,已知Frenet坐標系下換道起點和終點的六個參數s0、v0、a0、st、vt、at,采用橫縱向解耦分別進行運動規劃的方法,可得橫向位置x(t)和縱向位置y(t)關于時間t的五次多項式表達式。
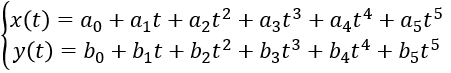
五次多項式中存在六個未知量,將起點和終點已知的六個參數代入便可這個六個未知量。然后根據時間t進行合并即可得到橫縱向聯合控制的曲線,即最終運動規劃的曲線。
4.4 貝塞爾曲線
對于比較少的點來說,采用多項式曲線非常合理。但是當點比較多時,為了逼近所有點,就不得不增加多項式的次數,而由此帶來的負面影響就是曲線震蕩。退一步講,即使震蕩能夠被消除,獲得的曲線由于存在非常多的起伏,也不夠光順。而貝塞爾曲線的出現,正好解決了上述問題。
1959年,法國數學家保爾·德·卡斯特里使用獨家配方求出貝塞爾曲線。1962年,法國雷諾汽車公司工程師皮埃爾·貝塞爾將自己在汽車造型設計的一些心得歸納總結,并廣泛發表。貝塞爾在造型設計的心得可簡單總結為:先用折線段勾畫出汽車的外形大致輪廓,再用光滑的參數曲線去逼近這個折線多邊形。
繪制貝塞爾曲線之前,我們需要知道起點和終點的參數,然后再提供任意數量的控制點的參數。如果控制點的數量為0,則為一階貝塞爾曲線,如果控制點的數量為1,則為二階貝塞爾曲線,如果控制點的數量為2,則為三階貝塞爾曲線,依次類推。不論是起點、終點還是控制點,它們均代表坐標系下的一個向量。
下面我們以經典的二階貝塞爾曲線為例,介紹其繪制方法。如圖32所示,P0和P2為已知的參數的起點和終點,P1為已知參數的控制點。首先我們按照起點、控制點、終點的順序依次連接,生成兩條直線。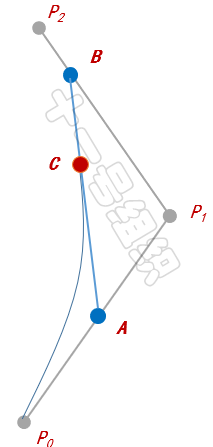
圖32 二階貝塞爾曲線示例
接著我們以每條直線的起點開始,向各自的終點按比例t取點,如圖中的A和B。隨后我們將A和B相連得到一條直線,也按相同的比例t取點,便可得到C點,這也是二階貝塞爾曲線在比例為t時會經過的點。比列t滿足如下的公式。
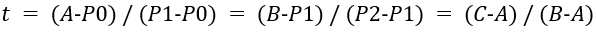
當我們比例t一點點變大(從0到1),就得到起點到終點的所有貝塞爾點,所有點相連便繪制出完整的二階貝塞爾曲線C(t),用公式表達為。
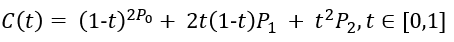
由二階貝塞爾曲線拓展到N階貝塞爾曲線,可得數學表達式如下。
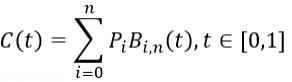
審核編輯:劉清
-
傳感器
+關注
關注
2551文章
51163瀏覽量
754123 -
神經網絡
+關注
關注
42文章
4772瀏覽量
100838 -
自動駕駛系統
+關注
關注
0文章
65瀏覽量
6775 -
卷積神經網絡
+關注
關注
4文章
367瀏覽量
11875
原文標題:兩萬字簡述自動駕駛路徑規劃的常用算法
文章出處:【微信號:WW_CGQJS,微信公眾號:傳感器技術】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何實現自動駕駛規控算法的仿真驗證

基于改進ResNet50網絡的自動駕駛場景天氣識別算法

自動駕駛汽車安全嗎?

多臺倉儲AGV協作全局路徑規劃算法的研究

智能駕駛與自動駕駛的關系







 工商網監
工商網監
評論