 淺析Meta最新模型LLaMA語言模型細節與代碼
淺析Meta最新模型LLaMA語言模型細節與代碼
本文將從項目環境依賴,模型細節(RMS Pre-Norm、SwiGLU激活函數、RoPE旋轉位置編碼),代碼解讀(tokenizer、model)以及推理等幾個方面對Meta最新模型LLaMA細節與代碼詳解,供大家一起參考。
一、項目環境依賴
此項目給出的環境依賴只有4個:torch、fairscale、fire、sentencepiece。
其中torch不用多講,fairscale是用來做GPU分布的,一般是當使用DDP仍然遇到超顯存的問題時使用fairscale。目前fairscale我還沒有試過,在下文的源碼介紹中,我會用torch中對應的基礎網絡替代fairscale中的結構層進行介紹。
fire是一個命令行工具,用或者不用他都可以,sentencepiece是用于tokenizer的工具包,會在tokenizer部分簡單介紹。
二、模型細節
由于該模型就是用的transformer的decoder,所以在結構上它與GPT是非常類似的,只是有一些細節需要注意一下。
1、RMS Pre-Norm
關于Pre-Norm和Post-Norm是神經網絡中老生常談的話題,目前比較普遍的被大家接受的結論是,相同的深度條件下,Post-Norm的效果要優于Pre-Norm,因為Pre-Norm實際上相當于通過了一個更寬的網絡而非更深的網絡,所以在同等深度下,Pre-Norm的實際效果相當于一個更淺卻更寬的網絡,詳細的推理過程參考:https://spaces.ac.cn/archives/9009。
然而在LLaMA中卻采用了Pre-Norm,或許是因為模型夠深(7B,13B,30B,65B的模型,transformer layer數量分別為32,40,60,80),而Pre-Norm的恒等分支更加明顯,有利于梯度的傳播(這部分暫時沒有想到很合理的解釋,如果有更好的理解,歡迎在評論區補充)。
RMS Norm(Root Mean Square Layer Normalization),是一般LayerNorm的一種變體,可以在梯度下降時令損失更加平滑。
與layerNorm相比,RMS Norm的主要區別在于去掉了減去均值的部分(re-centering),只保留方差部分(re-scaling),從歸一化的表達式上可以直觀地看出:
一般的LN:
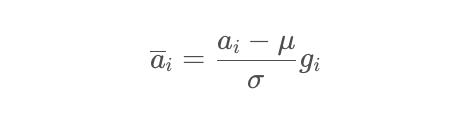
其中,
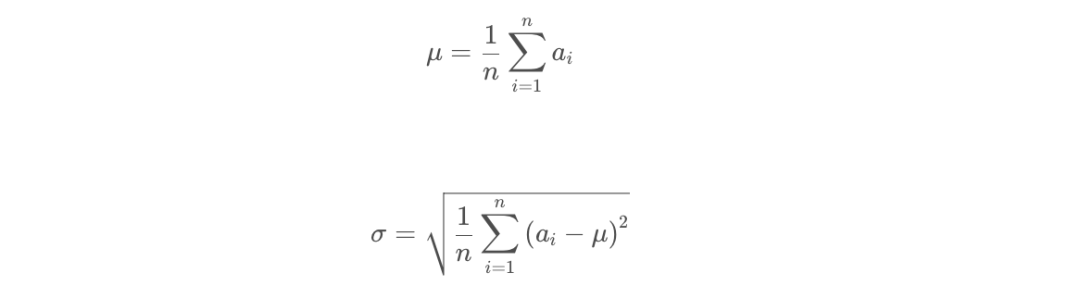
RMS Norm:
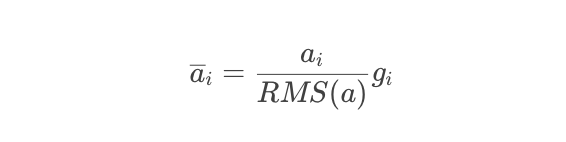
其中,
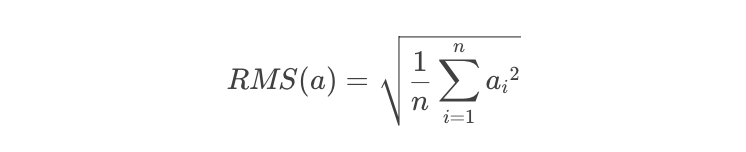
可以看到,二者的區別就在于有沒有減去均值。至于RMS Norm為什么有用,需要求梯度進行分析,感興趣的同學可以閱讀RMS Norm的論文。
2、SwiGLU激活函數
LLaMA采用SwiGLU替換了原有的ReLU。
采用SwiGLU的FNN,在論文中以如下公式進行表述:
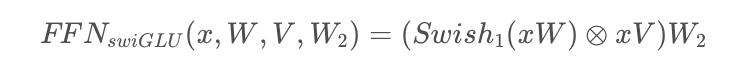
其中,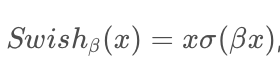
3、RoPE旋轉位置編碼
RoPE(Rotary Position Embedding)旋轉位置編碼,是蘇劍林老師提出的一種旋轉位置編碼方法,其思想是采用絕對位置編碼的形式,實現相對位置編碼。這一部分比較關鍵,如果不理解的話,后邊的代碼估計就看不懂了。讀懂RoPE涉及一點復變函數的基礎知識,不過如果你沒有學過的話也沒有關系。
位置編碼對大模型而言尤為重要,因為既然是要訓練大模型,那么長文本的表征和模型對于長文本的建模能力就顯得非常重要。(但是對于絕對位置編碼,我有一個直觀地感受,認為其本質上不適用于長文本的場景,因為它會直接導致模型的Embedding層被無限放大,并且由于數據分布在seq_len方向上通常是長尾的,這又會必然導致絕對位置編碼的矩陣在尾部會越來越稀疏,一方面造成資源浪費,另一方面這種表示方法直觀上就很不利于模型的學習,因為它與我們實際場景是有很大的矛盾的。
而RoPE雖然具有相對位置編碼的性質,但是從代碼部分可以看出,在構造的時候,其也是受到了最大長度的限制的。關于這一點,我無法嚴謹得說明,只是一點個人的想法。)。
而RoPE的巧妙之處在于,它既保留了絕對位置編碼中的絕對位置信息,又保留了在內積運算下,對位置信息的相對性。
RoPE主要借助了復數的思想。為了引入復數,首先假設了在加入位置信息之前,原有的編碼向量是二維行向量q_m和k_n ,其中m和n是絕對位置,現在需要構造一個變換,將m和n引入到q_m和k_nk中,即尋找變換:
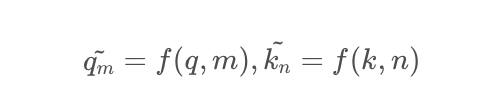
考慮到Attention的核心計算是內積:
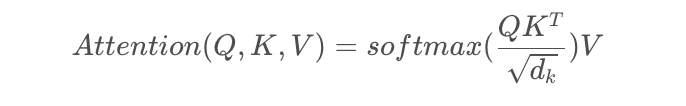
做了這樣一個變換之后,根據復數的特性,有:
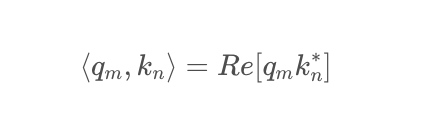
也就是,如果把二維向量看做復數,那么它們的內積,等于一個復數乘以另一個復數的共軛,得到的結果再取實部。
帶入上面的變換,也就有:
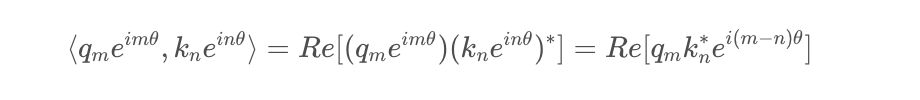
這樣一來,內積的結果就只依賴于(m?n),也就是相對位置了。換言之,經過這樣一番操作,通過給Embedding添加絕對位置信息,可以使得兩個token的編碼,經過內積變換(self-attn)之后,得到結果,是受它們位置的差值,即相對位置影響的。
于是對于任意的位置為m的二維向量[x,y],把它看做復數,乘以e^{im heta},而根據歐拉公式,有:
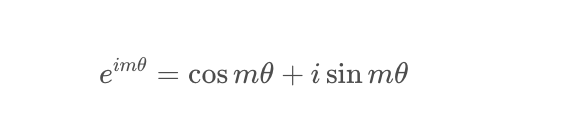
于是上述的相乘變換也就變成了:
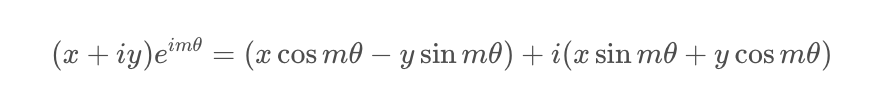
把上述式子寫成矩陣形式:
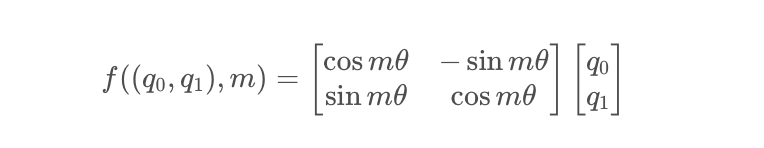
而這個變換的幾何意義,就是在二維坐標系下,對向量(q0, q1) 進行了旋轉,因而這種位置編碼方法,被稱為旋轉位置編碼。
根據剛才的結論,結合內積的線性疊加性,可以將結論推廣到高維的情形。可以理解為,每兩個維度一組,進行了上述的“旋轉”操作,然后再拼接在一起:
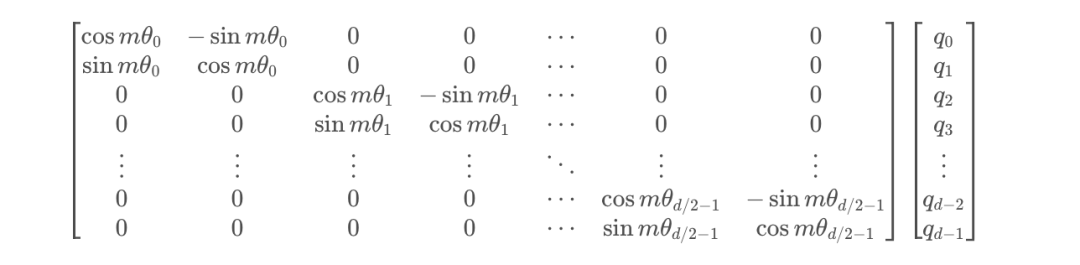
由于矩陣的稀疏性,會造成計算上的浪費,所以在計算時采用逐位相乘再相加的方式進行:
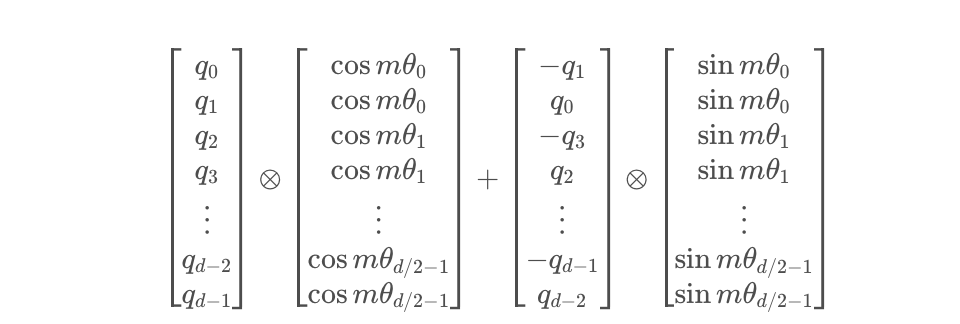
其中?為矩陣逐位相乘操作。代碼中具體的計算過程,會有所出入,具體見下文。
三、代碼解讀
1、tokenizer
tokenizer這部分沒有太多可以講的,主要就是用到了sentencepiece工具。
fromsentencepieceimportSentencePieceProcessor fromloggingimportgetLogger fromtypingimportList importos logger=getLogger() classTokenizer: def__init__(self,model_path:str): #reloadtokenizer assertos.path.isfile(model_path),model_path self.sp_model=SentencePieceProcessor(model_file=model_path) logger.info(f"ReloadedSentencePiecemodelfrom{model_path}") #BOS/EOStokenIDs self.n_words:int=self.sp_model.vocab_size() self.bos_id:int=self.sp_model.bos_id() self.eos_id:int=self.sp_model.eos_id() self.pad_id:int=self.sp_model.pad_id() logger.info( f"#words:{self.n_words}-BOSID:{self.bos_id}-EOSID:{self.eos_id}" ) assertself.sp_model.vocab_size()==self.sp_model.get_piece_size() defencode(self,s:str,bos:bool,eos:bool)->List[int]: asserttype(s)isstr t=self.sp_model.encode(s) ifbos: t=[self.bos_id]+t ifeos: t=t+[self.eos_id] returnt defdecode(self,t:List[int])->str: returnself.sp_model.decode(t)
2、model
1)模型細節詳解
model這部分的主要目的就是構建transformer,由于LLaMA對transformer在細節上做了一點改動,所以這里在介紹transformer部分之前,先結合前文模型細節介紹幾個輔助函數:
(1)RMSNorm:
這部分的基本原理在上文中已經介紹過了,這里對代碼部分進行簡單的解釋:
x是輸入 weight是末尾乘的可訓練參數
x.pow(2)是平方
mean(-1)是在最后一個維度(即hidden特征維度)上取平均 eps防止取倒數之后分母為0
torch.rsqrt是開平方并取倒數,結合上文的公式來看,是不難理解的。
classRMSNorm(torch.nn.Module): def__init__(self,dim:int,eps:float=1e-6): super().__init__() self.eps=eps self.weight=nn.Parameter(torch.ones(dim)) def_norm(self,x): returnx*torch.rsqrt(x.pow(2).mean(-1,keepdim=True)+self.eps) defforward(self,x): output=self._norm(x.float()).type_as(x) returnoutput*self.weight
(2)RoPE旋轉位置編碼:
為了實現旋轉位置編碼,定義了三個輔助函數:
defprecompute_freqs_cis(dim:int,end:int,theta:float=10000.0): freqs=1.0/(theta**(torch.arange(0,dim,2)[:(dim//2)].float()/dim)) t=torch.arange(end,device=freqs.device)#type:ignore freqs=torch.outer(t,freqs).float()#type:ignore freqs_cis=torch.polar(torch.ones_like(freqs),freqs)#complex64 returnfreqs_cis defreshape_for_broadcast(freqs_cis:torch.Tensor,x:torch.Tensor): ndim=x.ndim assert0<=?1?Tuple[torch.Tensor,torch.Tensor]: xq_=torch.view_as_complex(xq.float().reshape(*xq.shape[:-1],-1,2)) xk_=torch.view_as_complex(xk.float().reshape(*xk.shape[:-1],-1,2)) freqs_cis=reshape_for_broadcast(freqs_cis,xq_) xq_out=torch.view_as_real(xq_*freqs_cis).flatten(3) xk_out=torch.view_as_real(xk_*freqs_cis).flatten(3) returnxq_out.type_as(xq),xk_out.type_as(xk)
這一部分是整個項目中,最不容易理解的部分,因為它跟一般的位置編碼不同,即便是對transformer結構非常了解的同學,如果沒有認真讀過RoPE,對這一部分代碼還是很難讀明白。
看懂這一部分代碼,最關鍵的是弄清楚其中的變量freqs_cis所指是什么東西。
為了搞懂這部分,我們需要先了解幾個torch中不太常用的方法:
(1)torch.view_as_complex
把一個tensor轉為復數形式,要求這個tensor的最后一個維度形狀為2。
torch.view_as_complex(torch.Tensor([[1,2],[3,4],[5,6]])) #tensor([1.+2.j,3.+4.j,5.+6.j])
(2)torch.view_as_real
把復數tensor變回實數,可以看做是是剛才操作的逆變換。
torch.view_as_real(torch.view_as_complex(torch.Tensor([[1,2],[3,4],[5,6]]))) #tensor([[1.,2.], #[3.,4.], #[5.,6.]])
(3)torch.outer
一個向量的轉置乘以另一個向量:torch.outer(a, b) = a^T * b
a=torch.arange(1,5) b=torch.arange(1,4) torch.outer(a,b) #tensor([[1,2,3], #[2,4,6], #[3,6,9], #[4,8,12]])
(4)torch.polar
torch.polar(abs, angle)利用一個絕對數值,和一個角度值,在極坐標下構造一個復數張量

torch.polar(torch.tensor([1],dtype=torch.float64),torch.tensor([np.pi/2],dtype=torch.float64)) #tensor([6.1232e-17+1.j],dtype=torch.complex128)
接下來進入RoPE的計算,首先為了更加具象的表達,我們在此對各個維度的尺寸進行假設,假設batch_size為2,seq_len固定為512,attention_head的數量為12,每個attention_head的維度為64,那么,對于輸入到multi-head attn中的輸入Xq的尺寸就是(2, 512, 12, 64)。
回到我們剛才提出的問題,freqs_cis所指是什么東西,其實它就是需要計算出來的mθ也就是跟絕對位置相關的旋轉的角度,在極坐標下對應的復數tensor。
而函數precompute_freqs_cis就是提前將這些旋轉角度對應的tensor給創建出來,并可以重復利用。因為確定了序列的最大長度,所以這個tensor是固定死的。根據后續的數據流我們可以發現,在調用該函數時,傳入的兩個參數分別是attention_head的維度,以及最大長度的兩倍,具象地,也就是64和1024。
我們逐行來理解這個方法:
freqs=1.0/(theta**(torch.arange(0,dim,2)[:(dim//2)].float()/dim))
首先torch.arange創建了一個tensor,[ 0 , 2 , 4 , . . . , 60 , 62 ] [0, 2, 4, ..., 60, 62][0,2,4,...,60,62],然后統一除以64,把它變成分數,然后整體作為基礎角度的指數,它的shape是(32)
t=torch.arange(end,device=freqs.device)
t比較容易理解,也就是絕對位置信息,它的shape是(1024)。
freqs=torch.outer(t,freqs).float()
于是根據torch.outer運算,我們得到了一個shape為(1024, 32)的tensor。其意義也就是將每一個絕對位置,分配到對應的角度,相乘。直觀理解一下,就是每一個絕對位置上,都有32個角度。
為什么是這樣的呢,回顧計算的公式,對于旋轉矩陣,每兩個元素為一組,它們乘以的角度是同一個θ,所以這個(1024, 32),在后續的過程中,就可以reshape成(512, 64),并且在64的那個維度上,每兩個是相同的。
freqs_cis=torch.polar(torch.ones_like(freqs),freqs)
這一步就是在生成我們需要的位置信息,直觀理解一下,像是在復平面內,以原點為中心,轉了1024組,每一組64個的單位向量,它的shape是(1024, 64)。
reshape_for_broadcast方法,是把freqs_cis變成和輸入的tensor相同的形狀,結合下邊的另一個方法一起介紹。
然后來看apply_rotary_emb方法,這個方法其實就是把位置信息添加到原有的編碼結果上,在multi-head attention階段調用。我們還是逐行來看:
xq_=torch.view_as_complex(xq.float().reshape(*xq.shape[:-1],-1,2))
上文中,我們假設了輸入xq的尺寸就是(2, 512, 12, 64),那么這一句操作的reshape,就是把它變成(2, 512, 12, -1, 2),也就是(2, 512, 12, 32, 2)。xk 同理,略。緊接著把它變成復數形式,也就是變成了(2, 512, 12, 32)的形狀。
然后進入到reshape_for_broadcast方法:
shape=[difi==1ori==ndim-1else1fori,dinenumerate(x.shape)] returnfreqs_cis.view(*shape)
這個方法的作用是為了把freqs_cis變成和輸入的tensor相同的形狀。需要注意的是,這里的freqs_cis并不是precompute_freqs_cis生成的形狀為(1024, 64)的那個tensor,而是根據輸入的絕對位置,在(1024, 64)的tensor中,截取了長度為當前seq_len的一部分,代碼在Transformer類的forward方法中:
freqs_cis=self.freqs_cis[start_pos:start_pos+seqlen]
也就是說,假如當前輸入的序列長度是512,那么截取出來的這個新的freqs_cis,形狀就是(512, 64),reshape之后,形狀就變成了(1, 512, 1, 32),也就是在每一個位置上,都對應有32個角度,根據剛剛torch.polar的介紹,當我們固定絕對值(也就是向量的模長)時,角度就可以在笛卡爾坐標系下唯一確定一個復數,這樣一來也就是32個復數,即64個特征維度,所以就可以對應的將它融合到每個attention head的64個特征中去了。
reshape之后,就是將位置信息融入query和key中:
xq_out=torch.view_as_real(xq_*freqs_cis).flatten(3)
這一步將二者相乘得到的復數tensor,重新轉換為實數形式,得到的shape為(2, 512, 12, 32, 2),然后再flatten成(2, 512, 12, 64),這樣一來,就變回了和最開始x_q 相同的形狀,也就完成了將位置信息融入到x_q的這一操作。x_k同理。
以上就是添加位置編碼的整個過程,建議這一部分仔細閱讀,反復理解。
至于SwiGLU激活函數,可以通過調用torch內置方法F.silu()實現,會在下文的FFN部分介紹。
3、 transformer構建
接下來是transformer模型的構建。通常,我們在構建transformer時,是按Block構建的,每個transformer Block包含SA和FFN兩部分,然后再通過堆疊block的形式,構建起整個transformer網絡,LLaMA也是這樣做的,讀過BERT或者任何transformer結構的模型源碼的同學一定對這個結構非常熟悉了。
首先看SA部分:
classAttention(nn.Module): def__init__(self,args:ModelArgs): super().__init__() self.n_local_heads=args.n_heads//fs_init.get_model_parallel_world_size() self.head_dim=args.dim//args.n_heads self.wq=ColumnParallelLinear( args.dim, args.n_heads*self.head_dim, bias=False, gather_output=False, init_method=lambdax:x, ) self.wk=ColumnParallelLinear( args.dim, args.n_heads*self.head_dim, bias=False, gather_output=False, init_method=lambdax:x, ) self.wv=ColumnParallelLinear( args.dim, args.n_heads*self.head_dim, bias=False, gather_output=False, init_method=lambdax:x, ) self.wo=RowParallelLinear( args.n_heads*self.head_dim, args.dim, bias=False, input_is_parallel=True, init_method=lambdax:x, ) self.cache_k=torch.zeros( (args.max_batch_size,args.max_seq_len,self.n_local_heads,self.head_dim) ).cuda() self.cache_v=torch.zeros( (args.max_batch_size,args.max_seq_len,self.n_local_heads,self.head_dim) ).cuda() defforward(self,x:torch.Tensor,start_pos:int,freqs_cis:torch.Tensor,mask:Optional[torch.Tensor]): bsz,seqlen,_=x.shape xq,xk,xv=self.wq(x),self.wk(x),self.wv(x) xq=xq.view(bsz,seqlen,self.n_local_heads,self.head_dim) xk=xk.view(bsz,seqlen,self.n_local_heads,self.head_dim) xv=xv.view(bsz,seqlen,self.n_local_heads,self.head_dim) xq,xk=apply_rotary_emb(xq,xk,freqs_cis=freqs_cis) self.cache_k=self.cache_k.to(xq) self.cache_v=self.cache_v.to(xq) self.cache_k[:bsz,start_pos:start_pos+seqlen]=xk self.cache_v[:bsz,start_pos:start_pos+seqlen]=xv keys=self.cache_k[:bsz,:start_pos+seqlen] values=self.cache_v[:bsz,:start_pos+seqlen] xq=xq.transpose(1,2) keys=keys.transpose(1,2) values=values.transpose(1,2) scores=torch.matmul(xq,keys.transpose(2,3))/math.sqrt(self.head_dim) ifmaskisnotNone: scores=scores+mask#(bs,n_local_heads,slen,cache_len+slen) scores=F.softmax(scores.float(),dim=-1).type_as(xq) output=torch.matmul(scores,values)#(bs,n_local_heads,slen,head_dim) output=output.transpose( 1,2 ).contiguous().view(bsz,seqlen,-1) returnself.wo(output)
這一部分看上去會比較復雜,涉及到了很多的計算,但其實它就是最普通的attention,只要牢記attention的核心計算公式,也不難理解。
其中,為了執行多卡并行,這里的Linear層用的都是fairscale中的類,在閱讀代碼時直接理解為Linear即可。
attention計算的總體過程是:

其中有一個細節就是緩存機制,這里簡單介紹一下,很多初學者,甚至NLP老手都容易忽視這個問題。這個機制在模型的訓練過程中其實是不發揮作用的,它設計的目的是在generate時減少token的重復計算。
簡單解釋一下,就是在計算第n nn個token特征的時候,需要用到第1 , . . . , n ? 1 1,...,n-11,...,n?1個token,即每次生成時,需要知道前面所有的過往信息,如果每次都從頭算的話,那就會造成極大的浪費,所以就沒算一個位置的信息,就把它緩存下來。
然后是FFN部分,需要注意的點就是采用的激活函數,以及激活函數的位置:
classFeedForward(nn.Module): def__init__( self, dim:int, hidden_dim:int, multiple_of:int, ): super().__init__() hidden_dim=int(2*hidden_dim/3) hidden_dim=multiple_of*((hidden_dim+multiple_of-1)//multiple_of) self.w1=ColumnParallelLinear( dim,hidden_dim,bias=False,gather_output=False,init_method=lambdax:x ) self.w2=RowParallelLinear( hidden_dim,dim,bias=False,input_is_parallel=True,init_method=lambdax:x ) self.w3=ColumnParallelLinear( dim,hidden_dim,bias=False,gather_output=False,init_method=lambdax:x ) defforward(self,x): returnself.w2(F.silu(self.w1(x))*self.w3(x))
這里與常見模型中的FFN做一下簡單的對比,BART中的FFN,用的是fc->act->fc,用了兩層全連接;GPT中的FFN,用的是conv1D->act->conv1D,也是只用了兩層。
而LLaMA中的FFN采用了三個全連接層以實現FFNSwiGLU,即
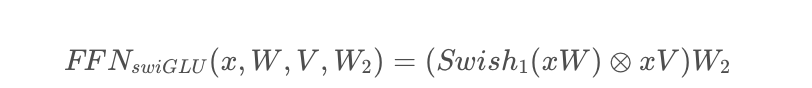
然后將SA和FFN這兩部分拼在一起就是一個transformer block。
classTransformerBlock(nn.Module): def__init__(self,layer_id:int,args:ModelArgs): super().__init__() self.n_heads=args.n_heads self.dim=args.dim self.head_dim=args.dim//args.n_heads self.attention=Attention(args) self.feed_forward=FeedForward( dim=args.dim,hidden_dim=4*args.dim,multiple_of=args.multiple_of ) self.layer_id=layer_id self.attention_norm=RMSNorm(args.dim,eps=args.norm_eps) self.ffn_norm=RMSNorm(args.dim,eps=args.norm_eps) defforward(self,x:torch.Tensor,start_pos:int,freqs_cis:torch.Tensor,mask:Optional[torch.Tensor]): h=x+self.attention.forward(self.attention_norm(x),start_pos,freqs_cis,mask) out=h+self.feed_forward.forward(self.ffn_norm(h)) returnout
最后利用torch的module list將transformer block進行堆疊,拼上最前頭的embedding部分,就是一個完整的transformer(decoder)結構了。
classTransformer(nn.Module):
def__init__(self,params:ModelArgs):
super().__init__()
self.params=params
self.vocab_size=params.vocab_size
self.n_layers=params.n_layers
self.tok_embeddings=ParallelEmbedding(
params.vocab_size,params.dim,init_method=lambdax:x
)
self.layers=torch.nn.ModuleList()
forlayer_idinrange(params.n_layers):
self.layers.append(TransformerBlock(layer_id,params))
self.norm=RMSNorm(params.dim,eps=params.norm_eps)
self.output=ColumnParallelLinear(
params.dim,params.vocab_size,bias=False,init_method=lambdax:x
)
self.freqs_cis=precompute_freqs_cis(
self.params.dim//self.params.n_heads,self.params.max_seq_len*2
)
@torch.inference_mode()
defforward(self,tokens:torch.Tensor,start_pos:int):
_bsz,seqlen=tokens.shape
h=self.tok_embeddings(tokens)
self.freqs_cis=self.freqs_cis.to(h.device)
freqs_cis=self.freqs_cis[start_pos:start_pos+seqlen]
mask=None
ifseqlen>1:
mask=torch.full((1,1,seqlen,seqlen),float("-inf"),device=tokens.device)
mask=torch.triu(mask,diagonal=start_pos+1).type_as(h)
forlayerinself.layers:
h=layer(h,start_pos,freqs_cis,mask)
h=self.norm(h)
output=self.output(h[:,-1,:])#onlycomputelastlogits
returnoutput.float()
直接看forward部分,輸入是token,先做token embedding,然后添加位置信息。對于decoder模型,為了防止標簽泄漏,需要mask,所以做了一個上三角的mask矩陣。接下來就是逐層的計算transformer。
3、generate
classLLaMA: def__init__(self,model:Transformer,tokenizer:Tokenizer): self.model=model self.tokenizer=tokenizer defgenerate( self, prompts:List[str], max_gen_len:int, temperature:float=0.8, top_p:float=0.95, )->List[str]: bsz=len(prompts) params=self.model.params assertbsz<=?params.max_batch_size,?(bsz,?params.max_batch_size) ????????prompt_tokens?=?[self.tokenizer.encode(x,?bos=True,?eos=False)?for?x?in?prompts] ????????min_prompt_size?=?min([len(t)?for?t?in?prompt_tokens]) ????????max_prompt_size?=?max([len(t)?for?t?in?prompt_tokens]) ????????total_len?=?min(params.max_seq_len,?max_gen_len?+?max_prompt_size) ????????tokens?=?torch.full((bsz,?total_len),?self.tokenizer.pad_id).cuda().long() ????????for?k,?t?in?enumerate(prompt_tokens): ????????????tokens[k,?:?len(t)]?=?torch.tensor(t).long() ????????input_text_mask?=?tokens?!=?self.tokenizer.pad_id ????????start_pos?=?min_prompt_size ????????prev_pos?=?0 ????????for?cur_pos?in?range(start_pos,?total_len): ????????????logits?=?self.model.forward(tokens[:,?prev_pos:cur_pos],?prev_pos) ????????????if?temperature?>0: probs=torch.softmax(logits/temperature,dim=-1) next_token=sample_top_p(probs,top_p) else: next_token=torch.argmax(logits,dim=-1) next_token=next_token.reshape(-1) #onlyreplacetokenifprompthasalreadybeengenerated next_token=torch.where( input_text_mask[:,cur_pos],tokens[:,cur_pos],next_token ) tokens[:,cur_pos]=next_token prev_pos=cur_pos decoded=[] fori,tinenumerate(tokens.tolist()): #cuttomaxgenlen t=t[:len(prompt_tokens[i])+max_gen_len] #cuttoeostokifany try: t=t[:t.index(self.tokenizer.eos_id)] exceptValueError: pass decoded.append(self.tokenizer.decode(t)) returndecoded defsample_top_p(probs,p): probs_sort,probs_idx=torch.sort(probs,dim=-1,descending=True) probs_sum=torch.cumsum(probs_sort,dim=-1) mask=probs_sum-probs_sort>p probs_sort[mask]=0.0 probs_sort.div_(probs_sort.sum(dim=-1,keepdim=True)) next_token=torch.multinomial(probs_sort,num_samples=1) next_token=torch.gather(probs_idx,-1,next_token) returnnext_token
生成的過程如下:
1)對prompts進行tokenize,得到token ids;
2)計算當前batch的最大長度total_len,用來創建輸入的token tensor,最大長度不能超過前文所述緩存的大小;
3)從當前batch中,最短的一個prompt的位置,作為生成的開始位置,開始生成;
4)輸入的token tensor傳入transformer模型,計算logits,得到形狀為(batch_size, hidden_size)的logits(transformer最后一層的輸出);
5)softmax+top_p采樣,得到當前預測的token,并更新當前位置,準備預測下一個token;
6)解碼得到生成的文本。
四、推理
簡單看一下官方example中給出的推理樣例prompt:
['ThecapitalofGermanyisthecityof', 'HereismysonnetinthestyleofShakespeareaboutanartificialintelligence:']
生成結果為:
['ThecapitalofGermanyisthecityofBerlin.ThecityisalsothecapitaloftheFederalRepublicofGermany. ThecityofBerlinislocatedinthestateofBerlininGermany.ThecityisthecapitalofthefederalRepublicofGermany. Berlinhasatotalpopulationofaround3.4millionandisthe2ndmostpopulouscityintheEuropeanUnionafterLondon.Thecityhasanareaof892squarekilometersandisthe9thmostpopulatedcityinEurope. ThecityofBerlinwasfoundedinthe13thcentury.BerlinwasalsothecapitaloftheGermanEmpire,theGermanDemocraticRepublicandtheunitedFederalRepublicofGermany. ThecityofBerlinhasmanytouristattractionsthatincludeMuseumsinsel,BrandenburgerTor,theReichstag,andtheSchlossCharlottenburg. ThecityofBerlinisamajorcenterfortheArts,Science,EducationandInnovation.Thecityisalsothepolitical,economic,andculturalcenterofGermany. BerlinishometoanumberofworldrenowneduniversitiesincludingtheFreeUniversityofBerlin,theHumboldtUniversityofBerlin,theTechnicalUniversityofBerlin,andtheBerlinInstituteofTechnology. ThecityofBerlinhas', 'HereismysonnetinthestyleofShakespeareaboutanartificialintelligence: Letustakeamomentfromthetumultuousstorm Ofthepoliticsofreligiontoexaminetheshapeofthings. Ourintuitiontellsusthatwhateverwecanconceive Canexist–ourmindshavenolimit. However,oursensestellusthatthereisalimit. Letusexaminetheinfiniteandwhatwecansayaboutit. Theinfiniteissomethingthatwecanneversee. Wecannotsaywhatitisandwecannotsaywhatitisnot. But,somehow,itisnonethelessreal. Wecanalsosaythattheinfiniteiseternal– Ithasnobeginningandithasnoend. Thatiswhatitis–itistheeternal. Inaword,itisGod. Butwhatabouttheuniverse? Theuniverseisafiniteconstruct– Theinfinitelylargeandtheinfinitelysmall– Allofitfinite. Eventhesingularityattheendoftimeisfinite. So,theuniverseisnotGod. PerhapsitisthevesselofGod. Perhaps,insomesense,theuniverseisGod. But,Iamstillaman. Icannotseetheinfinite. Icanonly']
總結
本文將從項目環境依賴,模型細節(RMS Pre-Norm、SwiGLU激活函數、RoPE旋轉位置編碼),代碼解讀(tokenizer、model)以及推理等幾個方面對Meta最新模型LLaMA細節與代碼詳解。???
總結一下,本文對LLaMA大模型的結構代碼進行了詳細的介紹,其開源出來的結構代碼量并不多,但是其中很多細節值得反復推敲理解。
審核編輯:劉清
-
RMS
+關注
關注
2文章
139瀏覽量
35870 -
GPT
+關注
關注
0文章
359瀏覽量
15471 -
旋轉編碼
+關注
關注
0文章
6瀏覽量
10527
原文標題:Meta最新模型LLaMA語言模型細節與代碼詳解
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【飛騰派4G版免費試用】仙女姐姐的嵌入式實驗室之五~LLaMA.cpp及3B“小模型”OpenBuddy-StableLM-3B
Meta推出免費大模型Llama 2,GPT要有危機感了
Meta發布一款可以使用文本提示生成代碼的大型語言模型Code Llama






 工商網監
工商網監
評論