


近日,由微軟亞洲研究院提出的 Roll-out Diffusion Network (RODIN) 模型,首次實現了利用生成擴散模型在 3D 訓練數據上自動生成 3D 數字化身(Avatar)的功能。僅需一張圖片甚至一句文字描述,RODIN 擴散模型就能秒級生成 3D 化身,讓低成本定制 3D 頭像成為可能,為 3D 內容創作領域打開了更多想象空間。相關論文“RODIN: A Generative Model for Sculpting 3D Digital Avatars Using Diffusion”已被 CVPR 2023 接收。
創建個性化的用戶形象在如今的數字世界中非常普遍,很多 3D 游戲都設有這一功能。然而在創建個人形象的過程中,繁瑣的細節調整常常讓人又愛又恨,有時候大費周章地選了與自己相似的眼睛、鼻子、發型、眼鏡等細節之后,卻發現拼接起來與自己仍大相徑庭。既然現在的 AI 技術已經可以生成惟妙惟肖的 2D 圖像,那么在 3D 世界中,我們是否可以擁有一個“AI 雕塑家”,僅通過一張照片就可以幫我們量身定制自己的 3D 數字化身呢?
微軟亞洲研究院新提出的 3D 生成擴散模型 Roll-out Diffusion Network (RODIN)可以輕松做到。讓我們先來看看 RODIN 的實力吧!


(a) 給定的照片

(b)生成的虛擬形象
圖1:給定一張照片,RODIN 模型即可生成虛擬形象

(a)輸入文字“留卷發和大胡子穿著黑色皮夾克的男性”

(b) 輸入文字“紅色衣著非洲發型的女性”
圖2:給定文本描述,RODIN 模型可直接生成虛擬形象
與傳統 3D 建模需要投入大量人力成本、制作過程繁瑣不同的是,RODIN 以底層思路的創新突破與精巧的模型設計,突破了二次元到三次元的結界,實現了只輸入一張圖片或一句文字就能在幾秒之內生成定制的 3D 數字化身的能力。在此之前,AI 生成技術還僅僅圍繞 2D 圖像進行創作,RODIN 模型的出現也將極大地推動 AI 在 3D 生成領域的進步。相關論文“RODIN: A Generative Model for Sculpting 3D Digital Avatars Using Diffusion”已被 CVPR 2023 接收。
論文鏈接:
RODIN: A Generative Model for Sculpting 3D Digital Avatars Using Diffusion
https://arxiv.org/abs/2212.06135
項目頁面:
https://3d-avatar-diffusion.microsoft.com

RODIN模型首次將
擴散模型應用于3D訓練數據
在 3D 生成領域,盡管此前有不少研究利用 GAN(生成對抗網絡)或 VAE(變分自動編碼器)技術,從大量 2D 圖像訓練數據中生成 3D 圖像,但結果卻不盡如人意,“兩面派”、“三頭哪吒”等抽象派 3D 圖像時有出現。科研人員們認為,造成這種現象的原因在于這些方法存在一個基礎的欠定(ill posed)問題,也就是說由于單視角圖片存在幾何二義性,從僅僅通過大量的 2D 數據很難學到高質量 3D 化身的合理分布,所以才造成了各種不完美的生成結果。
對此,微軟亞洲研究院的研究員們轉變思路,首次提出 3D Diffusion Model,利用擴散模型的表達能力來建模 3D 內容。這種方法通過多張視角圖來訓練 3D 模型,消除了歧義性、二義性所帶來的“四不象”結果,從而得到一個正確解,創建出更逼真的 3D 形象。
然而,要實現這種方法,還需要克服三個難題:
-
首先,盡管擴散模型此前在 2D 內容生成上取得巨大成功,將其應用在 3D 數據上并沒有可參考的實踐方法和可遵循的前例。如何將擴散模型用于生成 3D 模型的多視角圖,是研究員們找到的關鍵切入點;
-
其次,機器學習模型的訓練需要海量的數據,但一個多視圖、一致且多樣、高質量和大規模的 3D 圖像數據很難獲取,還存在隱私和版權等方面的風險。網絡公開的 3D 圖像又無法保證多視圖的一致性,且數據量也不足以支撐 3D 模型的訓練;
-
第三,在機器上直接拓展 2D 擴散模型至 3D 生成,所需的內存存儲與計算開銷幾乎無法承受。
多項技術創新讓RODIN模型
以低成本生成高質量的3D圖像
為了解決上述難題,微軟亞洲研究院的研究員們創新地提出了 RODIN 擴散模型,并在實驗中取得了優異的效果,超越了現有模型的 SOTA 水平。
RODIN 模型采用神經輻射場(NeRF)方法,并借鑒英偉達的 EG3D 工作,將 3D 空間緊湊地表達為空間三個互相垂直的特征平面(Triplane),并將這些圖展開至單個 2D 特征平面中,再執行 3D 感知擴散。具體而言,就是將 3D 空間在橫、縱、垂三個正交平面視圖上以二維特征展開,這樣不僅可以讓 RODIN 模型使用高效的 2D 架構進行 3D 感知擴散,將三維圖像降維成二維圖像也大幅降低了計算復雜度和計算成本。
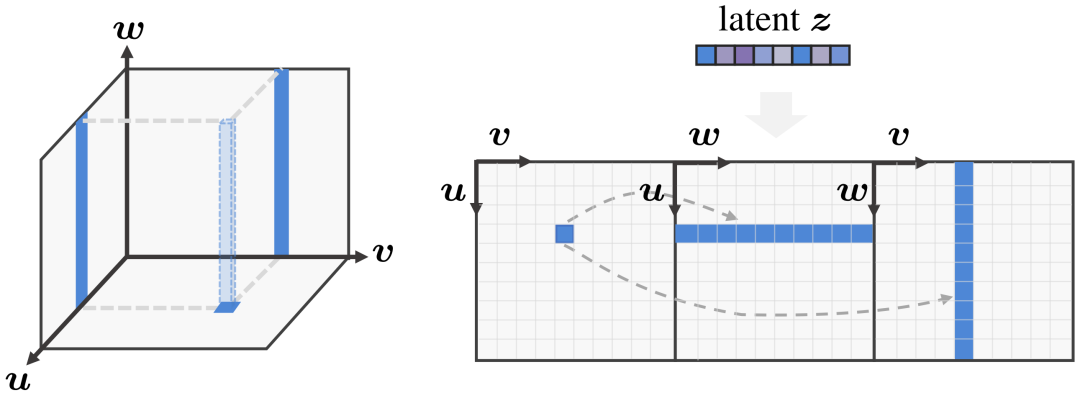
圖3:3D 感知卷積高效處理 3D 特征。(左圖) 用三平面(triplane)表達 3D 空間,此時底部特征平面的特征點對應于另外兩個特征平面的兩條線。(右圖)引入 3D 感知卷積處理展開的 2D 特征平面,同時考慮到三個平面的三維固有對應關系。
要實現 3D 圖像的生成需要三個關鍵要素:
-
3D 感知卷積,確保降維后的三個平面的內在關聯。傳統 2D 擴散中使用的 2D 卷積神經網絡(CNN)并不能很好地處理 Triplane 特征圖。而 3D 感知卷積并不是簡單生成三個 2D 特征平面,而是在處理這樣的 3D 表達時,考慮了其固有的三維特性,即三個視圖平面中其中一個視圖的 2D 特征本質上是 3D 空間中一條直線的投影,因此與其他兩個平面中對應的直線投影特征存在關聯性。為了實現跨平面通信,研究員們在卷積中考慮了這樣的 3D 相關性,因此高效地用 2D 的方式合成 3D 細節。
-
隱空間協奏三平面 3D 表達生成。研究員們通過隱向量來協調特征生成,使其在整個三維空間中具有全局一致性,從而獲得更高質量的化身并實現語義編輯,同時,還通過使用訓練數據集中的圖像訓練額外的圖像編碼器,該編碼器可提取語義隱向量作為擴散模型的條件輸入。這樣,整體的生成網絡可視為自動編碼器,用擴散模型作為解碼隱空間向量。對于語義可編輯性,研究員們采用了一個凍結的 CLIP 圖像編碼器,與文本提示共享隱空間。
-
層級式合成,生成高保真立體細節。研究員們利用擴散模型先生成了一個低分辨率的三視圖平面(64×64),然后再通過擴散上采樣生成高分辨率的三平面(256×256)。這樣,基礎擴散模型集中于整體 3D 結構生成,而后續上采樣模型專注于細節生成。
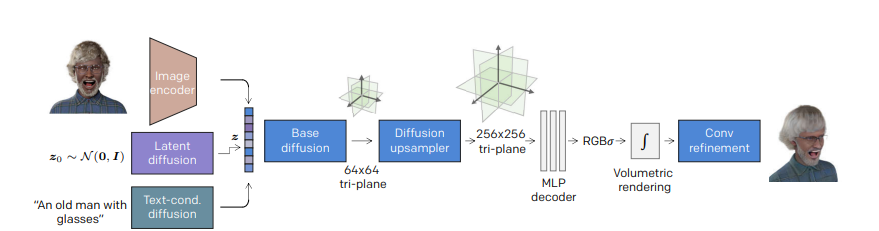
圖4:RODIN 模型概述
此外,在訓練數據集方面,研究員們借助開源的三維渲染軟件 Blender,通過隨機組合畫師手動創建的虛擬 3D 人物圖像,再加上從大量頭發、衣服、表情和配飾中隨機采樣,進而創建了10萬個合成個體,同時為每個個體渲染出了300個分辨率為256*256的多視圖圖像。在文本到 3D 頭像的生成上,研究員們采用了 LAION-400M數據集的人像子集訓練從輸入模態到 3D 擴散模型隱空間的映射,最終讓 RODIN 模型可以只使用一張 2D 圖像或一句文字描述就能創建出逼真的 3D 頭像。

圖5:利用文字做 3D 肖像編輯

圖6:更多隨機生成的虛擬形象 (更多結果請點擊閱讀原文,移步項目網頁)
微軟亞洲研究院主管研究員張博表示,“此前,3D 領域的研究受限于技術或高成本,生成的 3D 結果主要是點云、體素、網格等形式的粗糙幾何體,而 RODIN 模型可創建出前所未有的 3D 細節,為 3D 內容生成研究打開了新的思路。我們希望 RODIN 模型在未來可以成為 3D 內容生成領域的基礎模型,為后續的學術研究和產業應用創造更多可能。”
讓3D內容生成
更個性、更普適
現如今,虛擬人、數字化身在電影、游戲、元宇宙、線上會議、電商等行業和場景中的需求日益增多,但其制作流程卻相當復雜專業,每個高質量的化身都必須由專業的 3D 畫師精心創作,尤其是在建模頭發和面部毛發時,甚至需要逐根繪制,其中的艱辛歷程外人難以想象。微軟亞洲研究院 RODIN 模型的快速生成能力,可以協助 3D 畫師減輕數字化身創作的工作量,提升效率,促進 3D 內容產業的發展。
目前,3D 真人化身的創建耗時耗力,很多項目背后可能都有一個上百人的團隊在做支持,實現方法更多的是借助虛幻引擎、游戲引擎,再加上畫師的專業繪畫能力,才能設計出高度逼真的真人定制 3D 化身,普通大眾很難使用這些服務,通常只能得到一些現成的、與本人毫無關連的化身。而 RODIN 模型低成本和可定制化的 3D 建模技術,兼具普適性和個性化,讓 3D 內容生成走向大眾成為可能。
劉潏
微軟亞洲研究院資深產品經理
盡管當前 RODIN 模型生成結果主要為半身的 3D 頭像,但是其技術能力并不僅限于 3D 頭像的生成。隨著包括花草樹木、建筑、汽車家居等更多類別和更大規模訓練數據的學習,RODIN 模型將能生成更多樣的 3D 圖像。下一步,微軟亞洲研究院的研究員們將用 RODIN 模型探索更多 3D 場景創建的可能,向一個模型生成 3D 萬物的終極目標不斷努力。
了解更多科技前沿資訊
 ?
?
?
?-
微軟
+關注
關注
4文章
6678瀏覽量
105555
原文標題:一張照片定制自己的3D數字化身?
文章出處:【微信號:mstech2014,微信公眾號:微軟科技】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
3D打印技術:如何讓古老文物重獲新生?
用DLP4500燒錄9張8bit位深度的相移圖,3張合成了一張24bit,結果每一張24bit都重復投射三次,這是為什么?
索尼裸眼3D和投影技術助力提升博物館數字化體驗
騰訊混元3D AI創作引擎正式上線
3D掃描與數字拓片:打造文化遺產的數字復本

3D掃描技術醫療領域創新實踐,積木易搭3D掃描儀Mole助力定制個性化手臂康復輔具
3D打印技術應用的未來
發掘3D文件格式的無限潛力:打造沉浸式虛擬世界


3D 建模:塑造未來的無限可能
掃描“紅色文物”,致敬崢嶸歲月 3D數字化助力文物保護與傳播

能源裝備數字化 3D掃描助力大型汽輪機鑄件余量檢測及精準劃線!

歡創播報 騰訊元寶首發3D生成應用






 工商網監
工商網監

評論