 為什么需要分布式鎖?基于Redis如何實現一個分布式鎖?
為什么需要分布式鎖?基于Redis如何實現一個分布式鎖?
為什么需要分布式鎖?
在開始講分布式鎖之前,有必要簡單介紹一下,為什么需要分布式鎖?
與分布式鎖相對應的是「單機鎖」,我們在寫多線程程序時,避免同時操作一個共享變量產生數據問題,通常會使用一把鎖來「互斥」,以保證共享變量的正確性,其使用范圍是在「同一個進程」中。
如果換做是多個進程,需要同時操作一個共享資源,如何互斥呢?
例如,現在的業務應用通常都是微服務架構,這也意味著一個應用會部署多個進程,那這多個進程如果需要修改 MySQL 中的同一行記錄時,為了避免操作亂序導致數據錯誤,此時,我們就需要引入「分布式鎖」來解決這個問題了。
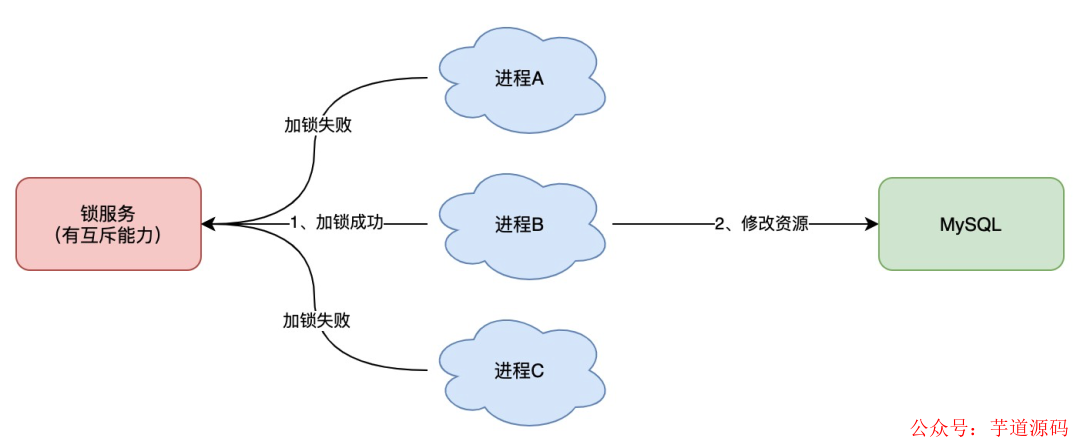
想要實現分布式鎖,必須借助一個外部系統,所有進程都去這個系統上申請「加鎖」。
而這個外部系統,必須要實現「互斥」的能力,即兩個請求同時進來,只會給一個進程返回成功,另一個返回失敗(或等待)。
這個外部系統,可以是 MySQL,也可以是 Redis 或 Zookeeper。但為了追求更好的性能,我們通常會選擇使用 Redis 或 Zookeeper 來做。
下面我就以 Redis 為主線,由淺入深,帶你深度剖析一下,分布式鎖的各種「安全性」問題,幫你徹底理解分布式鎖。
分布式鎖怎么實現?
我們從最簡單的開始講起。
想要實現分布式鎖,必須要求 Redis 有「互斥」的能力,我們可以使用 SETNX 命令,這個命令表示SET if N ot eX ists,即如果 key 不存在,才會設置它的值,否則什么也不做。
兩個客戶端進程可以執行這個命令,達到互斥,就可以實現一個分布式鎖。
客戶端 1 申請加鎖,加鎖成功:
127.0.0.1:6379>SETNXlock1 (integer)1//客戶端1,加鎖成功
客戶端 2 申請加鎖,因為它后到達,加鎖失敗:
127.0.0.1:6379>SETNXlock1 (integer)0//客戶端2,加鎖失敗
此時,加鎖成功的客戶端,就可以去操作「共享資源」,例如,修改 MySQL 的某一行數據,或者調用一個 API 請求。
操作完成后,還要及時釋放鎖,給后來者讓出操作共享資源的機會。如何釋放鎖呢?
也很簡單,直接使用 DEL 命令刪除這個 key 即可:
127.0.0.1:6379>DELlock//釋放鎖 (integer)1
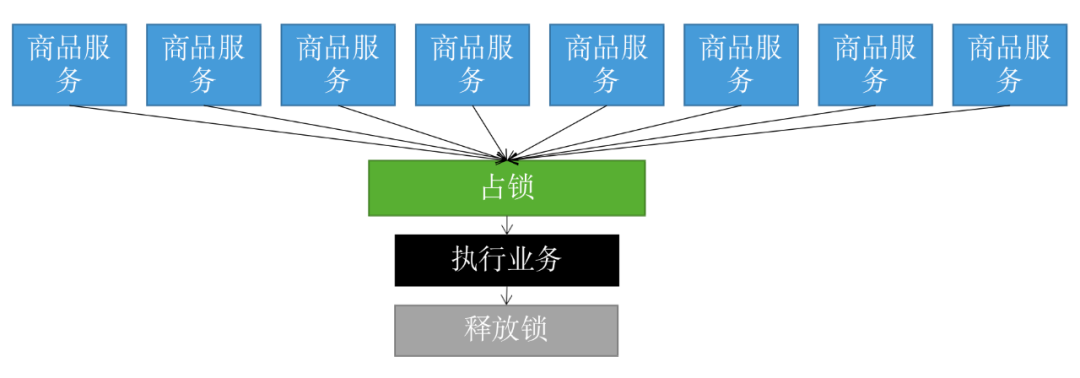
這個邏輯非常簡單,整體的路程就是這樣:

但是,它存在一個很大的問題,當客戶端 1 拿到鎖后,如果發生下面的場景,就會造成「死鎖」:
程序處理業務邏輯異常,沒及時釋放鎖
進程掛了,沒機會釋放鎖
這時,這個客戶端就會一直占用這個鎖,而其它客戶端就「永遠」拿不到這把鎖了。
怎么解決這個問題呢?
如何避免死鎖?
我們很容易想到的方案是,在申請鎖時,給這把鎖設置一個「租期」。
在 Redis 中實現時,就是給這個 key 設置一個「過期時間」。這里我們假設,操作共享資源的時間不會超過 10s,那么在加鎖時,給這個 key 設置 10s 過期即可:
127.0.0.1:6379>SETNXlock1//加鎖 (integer)1 127.0.0.1:6379>EXPIRElock10//10s后自動過期 (integer)1
這樣一來,無論客戶端是否異常,這個鎖都可以在 10s 后被「自動釋放」,其它客戶端依舊可以拿到鎖。
但這樣真的沒問題嗎?
還是有問題。
現在的操作,加鎖、設置過期是 2 條命令,有沒有可能只執行了第一條,第二條卻「來不及」執行的情況發生呢?例如:
SETNX 執行成功,執行 EXPIRE 時由于網絡問題,執行失敗
SETNX 執行成功,Redis 異常宕機,EXPIRE 沒有機會執行
SETNX 執行成功,客戶端異常崩潰,EXPIRE 也沒有機會執行
總之,這兩條命令不能保證是原子操作(一起成功),就有潛在的風險導致過期時間設置失敗,依舊發生「死鎖」問題。
怎么辦?
在 Redis 2.6.12 版本之前,我們需要想盡辦法,保證 SETNX 和 EXPIRE 原子性執行,還要考慮各種異常情況如何處理。
但在 Redis 2.6.12 之后,Redis 擴展了 SET 命令的參數,用這一條命令就可以了:
//一條命令保證原子性執行 127.0.0.1:6379>SETlock1EX10NX OK
這樣就解決了死鎖問題,也比較簡單。
我們再來看分析下,它還有什么問題?
試想這樣一種場景:
客戶端 1 加鎖成功,開始操作共享資源
客戶端 1 操作共享資源的時間,「超過」了鎖的過期時間,鎖被「自動釋放」
客戶端 2 加鎖成功,開始操作共享資源
客戶端 1 操作共享資源完成,釋放鎖(但釋放的是客戶端 2 的鎖)
看到了么,這里存在兩個嚴重的問題:
鎖過期 :客戶端 1 操作共享資源耗時太久,導致鎖被自動釋放,之后被客戶端 2 持有
釋放別人的鎖 :客戶端 1 操作共享資源完成后,卻又釋放了客戶端 2 的鎖
導致這兩個問題的原因是什么?我們一個個來看。
第一個問題,可能是我們評估操作共享資源的時間不準確導致的。
例如,操作共享資源的時間「最慢」可能需要 15s,而我們卻只設置了 10s 過期,那這就存在鎖提前過期的風險。
過期時間太短,那增大冗余時間,例如設置過期時間為 20s,這樣總可以了吧?
這樣確實可以「緩解」這個問題,降低出問題的概率,但依舊無法「徹底解決」問題。
為什么?
原因在于,客戶端在拿到鎖之后,在操作共享資源時,遇到的場景有可能是很復雜的,例如,程序內部發生異常、網絡請求超時等等。
既然是「預估」時間,也只能是大致計算,除非你能預料并覆蓋到所有導致耗時變長的場景,但這其實很難。
有什么更好的解決方案嗎?
別急,關于這個問題,我會在后面詳細來講對應的解決方案。
我們繼續來看第二個問題。
第二個問題在于,一個客戶端釋放了其它客戶端持有的鎖。
想一下,導致這個問題的關鍵點在哪?
重點在于,每個客戶端在釋放鎖時,都是「無腦」操作,并沒有檢查這把鎖是否還「歸自己持有」,所以就會發生釋放別人鎖的風險,這樣的解鎖流程,很不「嚴謹」!
如何解決這個問題呢?
鎖被別人釋放怎么辦?
解決辦法是:客戶端在加鎖時,設置一個只有自己知道的「唯一標識」進去。
例如,可以是自己的線程 ID,也可以是一個 UUID(隨機且唯一),這里我們以 UUID 舉例:
//鎖的VALUE設置為UUID 127.0.0.1:6379>SETlock$uuidEX20NX OK
這里假設 20s 操作共享時間完全足夠,先不考慮鎖自動過期的問題。
之后,在釋放鎖時,要先判斷這把鎖是否還歸自己持有,偽代碼可以這么寫:
//鎖是自己的,才釋放
ifredis.get("lock")==$uuid:
redis.del("lock")
這里釋放鎖使用的是 GET + DEL 兩條命令,這時,又會遇到我們前面講的原子性問題了。
客戶端 1 執行 GET,判斷鎖是自己的
客戶端 2 執行了 SET 命令,強制獲取到鎖(雖然發生概率比較低,但我們需要嚴謹地考慮鎖的安全性模型)
客戶端 1 執行 DEL,卻釋放了客戶端 2 的鎖
由此可見,這兩個命令還是必須要原子執行才行。
怎樣原子執行呢?Lua 腳本。
我們可以把這個邏輯,寫成 Lua 腳本,讓 Redis 來執行。
因為 Redis 處理每一個請求是「單線程」執行的,在執行一個 Lua 腳本時,其它請求必須等待,直到這個 Lua 腳本處理完成,這樣一來,GET + DEL 之間就不會插入其它命令了。
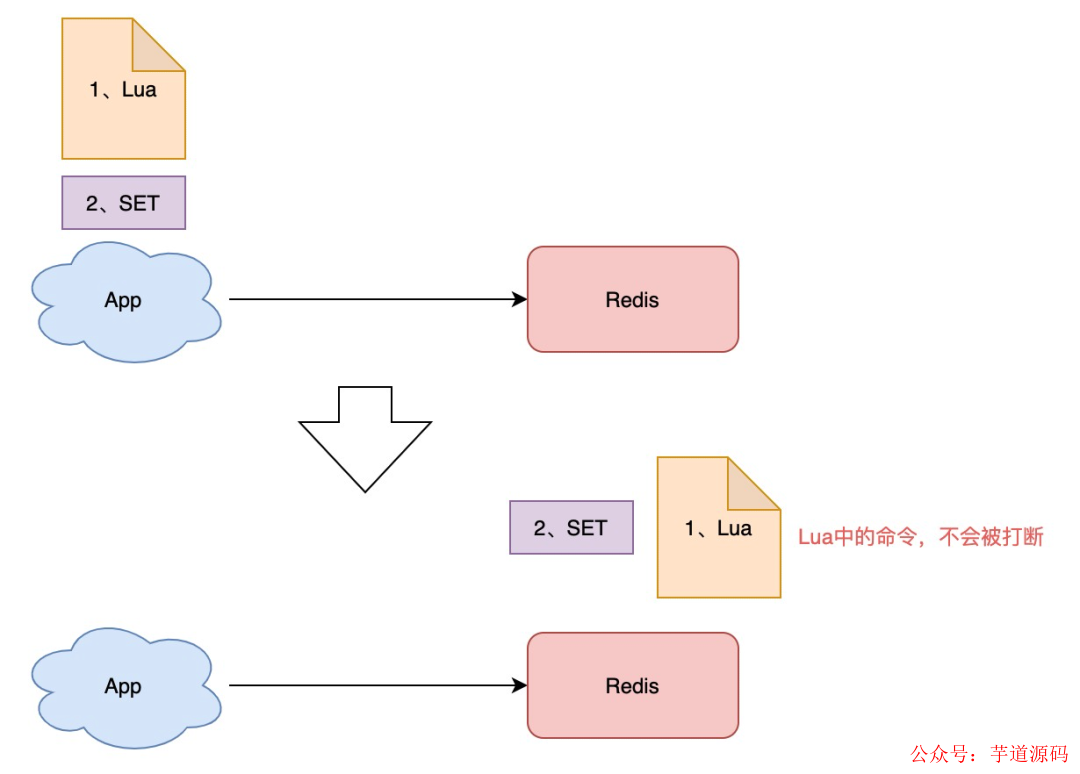
安全釋放鎖的 Lua 腳本如下:
//判斷鎖是自己的,才釋放
ifredis.call("GET",KEYS[1])==ARGV[1]
then
returnredis.call("DEL",KEYS[1])
else
return0
end
好了,這樣一路優化,整個的加鎖、解鎖的流程就更「嚴謹」了。
這里我們先小結一下,基于 Redis 實現的分布式鎖,一個嚴謹的的流程如下:
加鎖:SET lock_key expire_time NX
操作共享資源
釋放鎖:Lua 腳本,先 GET 判斷鎖是否歸屬自己,再 DEL 釋放鎖

好,有了這個完整的鎖模型,讓我們重新回到前面提到的第一個問題。
鎖過期時間不好評估怎么辦?
鎖過期時間不好評估怎么辦?
前面我們提到,鎖的過期時間如果評估不好,這個鎖就會有「提前」過期的風險。
當時給的妥協方案是,盡量「冗余」過期時間,降低鎖提前過期的概率。
這個方案其實也不能完美解決問題,那怎么辦呢?
是否可以設計這樣的方案:加鎖時,先設置一個過期時間,然后我們開啟一個「守護線程」,定時去檢測這個鎖的失效時間,如果鎖快要過期了,操作共享資源還未完成,那么就自動對鎖進行「續期」,重新設置過期時間。
這確實一種比較好的方案。
如果你是 Java 技術棧,幸運的是,已經有一個庫把這些工作都封裝好了:Redisson 。
Redisson 是一個 Java 語言實現的 Redis SDK 客戶端,在使用分布式鎖時,它就采用了「自動續期」的方案來避免鎖過期,這個守護線程我們一般也把它叫做「看門狗」線程。

除此之外,這個 SDK 還封裝了很多易用的功能:
可重入鎖
樂觀鎖
公平鎖
讀寫鎖
Redlock(紅鎖,下面會詳細講)
這個 SDK 提供的 API 非常友好,它可以像操作本地鎖的方式,操作分布式鎖。如果你是 Java 技術棧,可以直接把它用起來。
這里不重點介紹 Redisson 的使用,大家可以看官方 Github 學習如何使用,比較簡單。
到這里我們再小結一下,基于 Redis 的實現分布式鎖,前面遇到的問題,以及對應的解決方案:
死鎖 :設置過期時間
過期時間評估不好,鎖提前過期 :守護線程,自動續期
鎖被別人釋放 :鎖寫入唯一標識,釋放鎖先檢查標識,再釋放
還有哪些問題場景,會危害 Redis 鎖的安全性呢?
之前分析的場景都是,鎖在「單個」Redis 實例中可能產生的問題,并沒有涉及到 Redis 的部署架構細節。
而我們在使用 Redis 時,一般會采用主從集群 + 哨兵 的模式部署,這樣做的好處在于,當主庫異常宕機時,哨兵可以實現「故障自動切換」,把從庫提升為主庫,繼續提供服務,以此保證可用性。
那當「主從發生切換」時,這個分布鎖會依舊安全嗎?
試想這樣的場景:
客戶端 1 在主庫上執行 SET 命令,加鎖成功
此時,主庫異常宕機,SET 命令還未同步到從庫上(主從復制是異步的)
從庫被哨兵提升為新主庫,這個鎖在新的主庫上,丟失了!
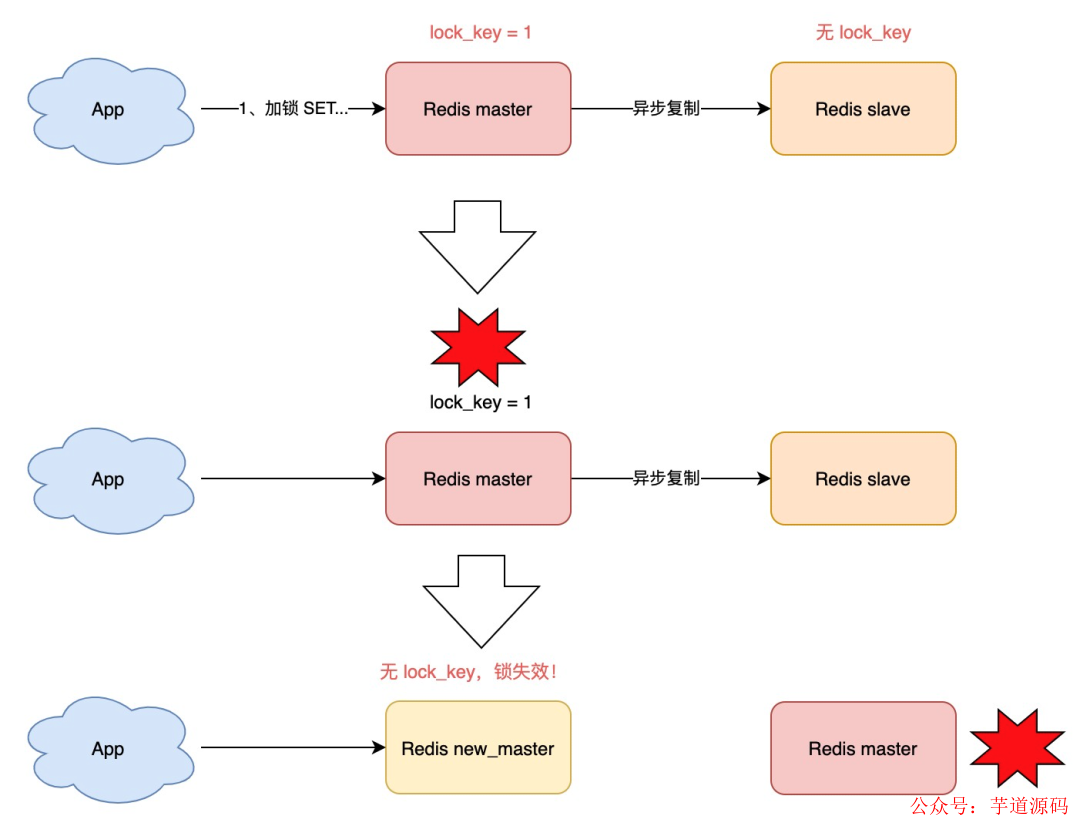
可見,當引入 Redis 副本后,分布鎖還是可能會受到影響。
怎么解決這個問題?
為此,Redis 的作者提出一種解決方案,就是我們經常聽到的 Redlock(紅鎖) 。
它真的可以解決上面這個問題嗎?
Redlock 真的安全嗎?
好,終于到了這篇文章的重頭戲。啊?上面講的那么多問題,難道只是基礎?
是的,那些只是開胃菜,真正的硬菜,從這里剛剛開始。
如果上面講的內容,你還沒有理解,我建議你重新閱讀一遍,先理清整個加鎖、解鎖的基本流程。
如果你已經對 Redlock 有所了解,這里可以跟著我再復習一遍,如果你不了解 Redlock,沒關系,我會帶你重新認識它。
值得提醒你的是,后面我不僅僅是講 Redlock 的原理,還會引出有關「分布式系統」中的很多問題,你最好跟緊我的思路,在腦中一起分析問題的答案。
現在我們來看,Redis 作者提出的 Redlock 方案,是如何解決主從切換后,鎖失效問題的。
Redlock 的方案基于 2 個前提:
不再需要部署從庫 和哨兵 實例,只部署主庫
但主庫要部署多個,官方推薦至少 5 個實例
也就是說,想用使用 Redlock,你至少要部署 5 個 Redis 實例,而且都是主庫,它們之間沒有任何關系,都是一個個孤立的實例。
注意:不是部署 Redis Cluster,就是部署 5 個簡單的 Redis 實例。
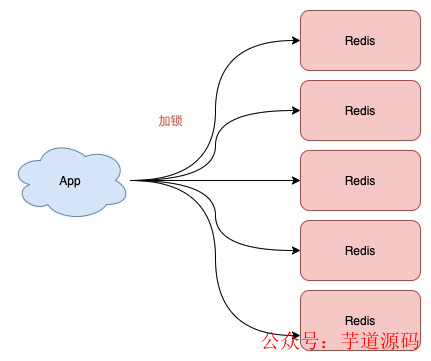
Redlock 具體如何使用呢?
整體的流程是這樣的,一共分為 5 步:
客戶端先獲取「當前時間戳T1」
客戶端依次向這 5 個 Redis 實例發起加鎖請求(用前面講到的 SET 命令),且每個請求會設置超時時間(毫秒級,要遠小于鎖的有效時間),如果某一個實例加鎖失敗(包括網絡超時、鎖被其它人持有等各種異常情況),就立即向下一個 Redis 實例申請加鎖
如果客戶端從 >=3 個(大多數)以上 Redis 實例加鎖成功,則再次獲取「當前時間戳T2」,如果 T2 - T1 < 鎖的過期時間,此時,認為客戶端加鎖成功,否則認為加鎖失敗
加鎖成功,去操作共享資源(例如修改 MySQL 某一行,或發起一個 API 請求)
加鎖失敗,向「全部節點」發起釋放鎖請求(前面講到的 Lua 腳本釋放鎖)
我簡單幫你總結一下,有 4 個重點:
客戶端在多個 Redis 實例上申請加鎖
必須保證大多數節點加鎖成功
大多數節點加鎖的總耗時,要小于鎖設置的過期時間
釋放鎖,要向全部節點發起釋放鎖請求
第一次看可能不太容易理解,建議你把上面的文字多看幾遍,加深記憶。
然后,記住這 5 步,非常重要,下面會根據這個流程,剖析各種可能導致鎖失效的問題假設。
好,明白了 Redlock 的流程,我們來看 Redlock 為什么要這么做。
1) 為什么要在多個實例上加鎖?
本質上是為了「容錯」,部分實例異常宕機,剩余的實例加鎖成功,整個鎖服務依舊可用。
2) 為什么大多數加鎖成功,才算成功?
多個 Redis 實例一起來用,其實就組成了一個「分布式系統」。
在分布式系統中,總會出現「異常節點」,所以,在談論分布式系統問題時,需要考慮異常節點達到多少個,也依舊不會影響整個系統的「正確性」。
這是一個分布式系統「容錯」問題,這個問題的結論是:如果只存在「故障」節點,只要大多數節點正常,那么整個系統依舊是可以提供正確服務的。
這個問題的模型,就是我們經常聽到的「拜占庭將軍」問題,感興趣可以去看算法的推演過程。
3) 為什么步驟 3 加鎖成功后,還要計算加鎖的累計耗時?
因為操作的是多個節點,所以耗時肯定會比操作單個實例耗時更久,而且,因為是網絡請求,網絡情況是復雜的,有可能存在延遲、丟包、超時 等情況發生,網絡請求越多,異常發生的概率就越大。
所以,即使大多數節點加鎖成功,但如果加鎖的累計耗時已經「超過」了鎖的過期時間,那此時有些實例上的鎖可能已經失效了,這個鎖就沒有意義了。
4) 為什么釋放鎖,要操作所有節點?
在某一個 Redis 節點加鎖時,可能因為「網絡原因」導致加鎖失敗。
例如,客戶端在一個 Redis 實例上加鎖成功,但在讀取響應結果時,網絡問題導致讀取失敗 ,那這把鎖其實已經在 Redis 上加鎖成功了。
所以,釋放鎖時,不管之前有沒有加鎖成功,需要釋放「所有節點」的鎖,以保證清理節點上「殘留」的鎖。
好了,明白了 Redlock 的流程和相關問題,看似 Redlock 確實解決了 Redis 節點異常宕機鎖失效的問題,保證了鎖的「安全性」。
但事實真的如此嗎?
Redlock 的爭論誰對誰錯?
Redis 作者把這個方案一經提出,就馬上受到業界著名的分布式系統專家的質疑 !
這個專家叫 Martin ,是英國劍橋大學的一名分布式系統研究員。在此之前他曾是軟件工程師和企業家,從事大規模數據基礎設施相關的工作。它還經常在大會做演講,寫博客,寫書,也是開源貢獻者。
他馬上寫了篇文章,質疑這個 Redlock 的算法模型是有問題的,并對分布式鎖的設計,提出了自己的看法。
之后,Redis 作者 Antirez 面對質疑,不甘示弱,也寫了一篇文章,反駁了對方的觀點,并詳細剖析了 Redlock 算法模型的更多設計細節。
而且,關于這個問題的爭論,在當時互聯網上也引起了非常激烈的討論。
二人思路清晰,論據充分,這是一場高手過招,也是分布式系統領域非常好的一次思想的碰撞!雙方都是分布式系統領域的專家,卻對同一個問題提出很多相反的論斷,究竟是怎么回事?
下面我會從他們的爭論文章中,提取重要的觀點,整理呈現給你。
提醒:后面的信息量極大,可能不宜理解,最好放慢速度閱讀。
分布式專家 Martin 對于 Relock 的質疑
在他的文章中,主要闡述了 4 個論點:
1) 分布式鎖的目的是什么?
Martin 表示,你必須先清楚你在使用分布式鎖的目的是什么?
他認為有兩個目的。
第一,效率。
使用分布式鎖的互斥能力,是避免不必要地做同樣的兩次工作(例如一些昂貴的計算任務)。如果鎖失效,并不會帶來「惡性」的后果,例如發了 2 次郵件等,無傷大雅。
第二,正確性。
使用鎖用來防止并發進程互相干擾。如果鎖失效,會造成多個進程同時操作同一條數據,產生的后果是數據嚴重錯誤、永久性不一致、數據丟失 等惡性問題,就像給患者服用了重復劑量的藥物,后果很嚴重。
他認為,如果你是為了前者——效率,那么使用單機版 Redis 就可以了,即使偶爾發生鎖失效(宕機、主從切換),都不會產生嚴重的后果。而使用 Redlock 太重了,沒必要。
而如果是為了正確性,Martin 認為 Redlock 根本達不到安全性的要求,也依舊存在鎖失效的問題!
2) 鎖在分布式系統中會遇到的問題
Martin 表示,一個分布式系統,更像一個復雜的「野獸」,存在著你想不到的各種異常情況。
這些異常場景主要包括三大塊,這也是分布式系統會遇到的三座大山:NPC 。
N:Network Delay,網絡延遲
P:Process Pause,進程暫停(GC)
C:Clock Drift,時鐘漂移
Martin 用一個進程暫停(GC)的例子,指出了 Redlock 安全性問題:
客戶端 1 請求鎖定節點 A、B、C、D、E
客戶端 1 的拿到鎖后,進入 GC(時間比較久)
所有 Redis 節點上的鎖都過期了
客戶端 2 獲取到了 A、B、C、D、E 上的鎖
客戶端 1 GC 結束,認為成功獲取鎖
客戶端 2 也認為獲取到了鎖,發生「沖突」
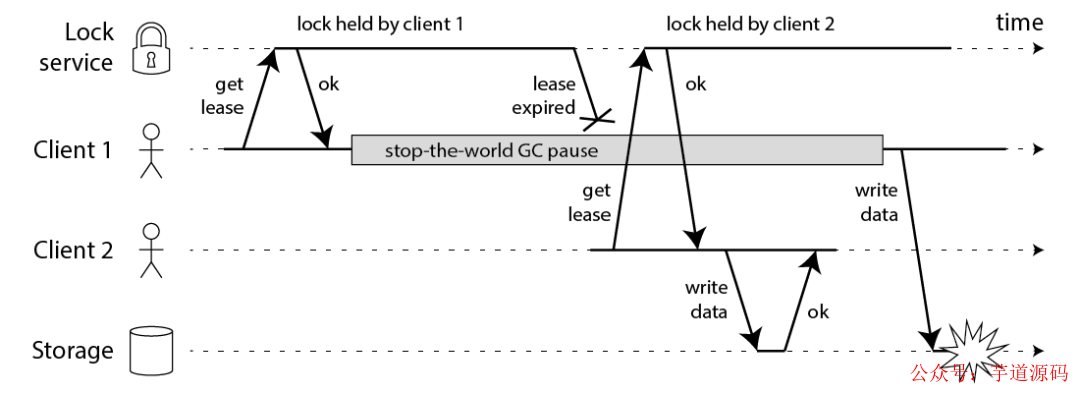
Martin 認為,GC 可能發生在程序的任意時刻,而且執行時間是不可控的。
注:當然,即使是使用沒有 GC 的編程語言,在發生網絡延遲、時鐘漂移時,也都有可能導致 Redlock 出現問題,這里 Martin 只是拿 GC 舉例。
3) 假設時鐘正確的是不合理的
又或者,當多個 Redis 節點「時鐘」發生問題時,也會導致 Redlock 鎖失效 。
客戶端 1 獲取節點 A、B、C 上的鎖,但由于網絡問題,無法訪問 D 和 E
節點 C 上的時鐘「向前跳躍」,導致鎖到期
客戶端 2 獲取節點 C、D、E 上的鎖,由于網絡問題,無法訪問 A 和 B
客戶端 1 和 2 現在都相信它們持有了鎖(沖突)
Martin 覺得,Redlock 必須「強依賴」多個節點的時鐘是保持同步的,一旦有節點時鐘發生錯誤,那這個算法模型就失效了。
即使 C 不是時鐘跳躍,而是「崩潰后立即重啟」,也會發生類似的問題。
Martin 繼續闡述,機器的時鐘發生錯誤,是很有可能發生的:
系統管理員「手動修改」了機器時鐘
機器時鐘在同步 NTP 時間時,發生了大的「跳躍」
總之,Martin 認為,Redlock 的算法是建立在「同步模型」基礎上的,有大量資料研究表明,同步模型的假設,在分布式系統中是有問題的。
在混亂的分布式系統的中,你不能假設系統時鐘就是對的,所以,你必須非常小心你的假設。
4) 提出 fecing token 的方案,保證正確性
相對應的,Martin 提出一種被叫作 fecing token 的方案,保證分布式鎖的正確性。
這個模型流程如下:
客戶端在獲取鎖時,鎖服務可以提供一個「遞增」的 token
客戶端拿著這個 token 去操作共享資源
共享資源可以根據 token 拒絕「后來者」的請求
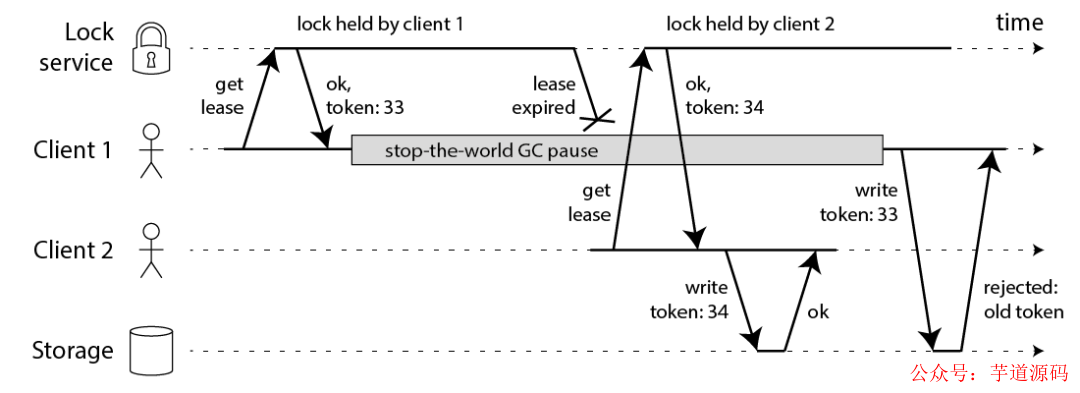
這樣一來,無論 NPC 哪種異常情況發生,都可以保證分布式鎖的安全性,因為它是建立在「異步模型」上的。
而 Redlock 無法提供類似 fecing token 的方案,所以它無法保證安全性。
他還表示,一個好的分布式鎖,無論 NPC 怎么發生,可以不在規定時間內給出結果,但并不會給出一個錯誤的結果。也就是只會影響到鎖的「性能」(或稱之為活性),而不會影響它的「正確性」。
Martin 的結論:
1、Redlock 不倫不類 :它對于效率來講,Redlock 比較重,沒必要這么做,而對于正確性來說,Redlock 是不夠安全的。
2、時鐘假設不合理 :該算法對系統時鐘做出了危險的假設(假設多個節點機器時鐘都是一致的),如果不滿足這些假設,鎖就會失效。
3、無法保證正確性 :Redlock 不能提供類似 fencing token 的方案,所以解決不了正確性的問題。為了正確性,請使用有「共識系統」的軟件,例如 Zookeeper。
好了,以上就是 Martin 反對使用 Redlock 的觀點,看起來有理有據。
下面我們來看 Redis 作者 Antirez 是如何反駁的。
Redis 作者 Antirez 的反駁
在 Redis 作者的文章中,重點有 3 個:
1) 解釋時鐘問題
首先,Redis 作者一眼就看穿了對方提出的最為核心的問題:時鐘問題 。
Redis 作者表示,Redlock 并不需要完全一致的時鐘,只需要大體一致就可以了,允許有「誤差」。
例如要計時 5s,但實際可能記了 4.5s,之后又記了 5.5s,有一定誤差,但只要不超過「誤差范圍」鎖失效時間即可,這種對于時鐘的精度要求并不是很高,而且這也符合現實環境。
對于對方提到的「時鐘修改」問題,Redis 作者反駁到:
手動修改時鐘 :不要這么做就好了,否則你直接修改 Raft 日志,那 Raft 也會無法工作...
時鐘跳躍 :通過「恰當的運維」,保證機器時鐘不會大幅度跳躍(每次通過微小的調整來完成),實際上這是可以做到的
為什么 Redis 作者優先解釋時鐘問題?因為在后面的反駁過程中,需要依賴這個基礎做進一步解釋。
2) 解釋網絡延遲、GC 問題
之后,Redis 作者對于對方提出的,網絡延遲、進程 GC 可能導致 Redlock 失效的問題,也做了反駁:
我們重新回顧一下,Martin 提出的問題假設:
客戶端 1 請求鎖定節點 A、B、C、D、E
客戶端 1 的拿到鎖后,進入 GC
所有 Redis 節點上的鎖都過期了
客戶端 2 獲取節點 A、B、C、D、E 上的鎖
客戶端 1 GC 結束,認為成功獲取鎖
客戶端 2 也認為獲取到鎖,發生「沖突」
Redis 作者反駁到,這個假設其實是有問題的,Redlock 是可以保證鎖安全的。
這是怎么回事呢?
還記得前面介紹 Redlock 流程的那 5 步嗎?這里我再拿過來讓你復習一下。
客戶端先獲取「當前時間戳T1」
客戶端依次向這 5 個 Redis 實例發起加鎖請求(用前面講到的 SET 命令),且每個請求會設置超時時間(毫秒級,要遠小于鎖的有效時間),如果某一個實例加鎖失敗(包括網絡超時、鎖被其它人持有等各種異常情況),就立即向下一個 Redis 實例申請加鎖
如果客戶端從 3 個(大多數)以上 Redis 實例加鎖成功,則再次獲取「當前時間戳T2」,如果 T2 - T1 < 鎖的過期時間,此時,認為客戶端加鎖成功,否則認為加鎖失敗
加鎖成功,去操作共享資源(例如修改 MySQL 某一行,或發起一個 API 請求)
加鎖失敗,向「全部節點」發起釋放鎖請求(前面講到的 Lua 腳本釋放鎖)
注意,重點是 1-3,在步驟 3,加鎖成功后為什么要重新獲取「當前時間戳T2」?還用 T2 - T1 的時間,與鎖的過期時間做比較?
Redis 作者強調:如果在 1-3 發生了網絡延遲、進程 GC 等耗時長的異常情況,那在第 3 步 T2 - T1,是可以檢測出來的,如果超出了鎖設置的過期時間,那這時就認為加鎖會失敗,之后釋放所有節點的鎖就好了!
Redis 作者繼續論述,如果對方認為,發生網絡延遲、進程 GC 是在步驟 3 之后,也就是客戶端確認拿到了鎖,去操作共享資源的途中發生了問題,導致鎖失效,那這不止是 Redlock 的問題,任何其它鎖服務例如 Zookeeper,都有類似的問題,這不在討論范疇內。
這里我舉個例子解釋一下這個問題:
客戶端通過 Redlock 成功獲取到鎖(通過了大多數節點加鎖成功、加鎖耗時檢查邏輯)
客戶端開始操作共享資源,此時發生網絡延遲、進程 GC 等耗時很長的情況
此時,鎖過期自動釋放
客戶端開始操作 MySQL(此時的鎖可能會被別人拿到,鎖失效)
Redis 作者這里的結論就是:
客戶端在拿到鎖之前,無論經歷什么耗時長問題,Redlock 都能夠在第 3 步檢測出來
客戶端在拿到鎖之后,發生 NPC,那 Redlock、Zookeeper 都無能為力
所以,Redis 作者認為 Redlock 在保證時鐘正確的基礎上,是可以保證正確性的。
3) 質疑 fencing token 機制
Redis 作者對于對方提出的 fecing token 機制,也提出了質疑,主要分為 2 個問題,這里最不宜理解,請跟緊我的思路。
第一 ,這個方案必須要求要操作的「共享資源服務器」有拒絕「舊 token」的能力。
例如,要操作 MySQL,從鎖服務拿到一個遞增數字的 token,然后客戶端要帶著這個 token 去改 MySQL 的某一行,這就需要利用 MySQL 的「事物隔離性」來做。
//兩個客戶端必須利用事物和隔離性達到目的 //注意token的判斷條件 UPDATEtableTSETval=$new_valWHEREid=$idANDcurrent_token
但如果操作的不是 MySQL 呢?例如向磁盤上寫一個文件,或發起一個 HTTP 請求,那這個方案就無能為力了,這對要操作的資源服務器,提出了更高的要求。
也就是說,大部分要操作的資源服務器,都是沒有這種互斥能力的。
再者,既然資源服務器都有了「互斥」能力,那還要分布式鎖干什么?
所以,Redis 作者認為這個方案是站不住腳的。
第二 ,退一步講,即使 Redlock 沒有提供 fecing token 的能力,但 Redlock 已經提供了隨機值(就是前面講的 UUID),利用這個隨機值,也可以達到與 fecing token 同樣的效果。
如何做呢?
Redis 作者只是提到了可以完成 fecing token 類似的功能,但卻沒有展開相關細節,根據我查閱的資料,大概流程應該如下,如有錯誤,歡迎交流~
客戶端使用 Redlock 拿到鎖
客戶端在操作共享資源之前,先把這個鎖的 VALUE,在要操作的共享資源上做標記
客戶端處理業務邏輯,最后,在修改共享資源時,判斷這個標記是否與之前一樣,一樣才修改(類似 CAS 的思路)
還是以 MySQL 為例,舉個例子就是這樣的:
客戶端使用 Redlock 拿到鎖
客戶端要修改 MySQL 表中的某一行數據之前,先把鎖的 VALUE 更新到這一行的某個字段中(這里假設為 current_token 字段)
客戶端處理業務邏輯
客戶端修改 MySQL 的這一行數據,把 VALUE 當做 WHERE 條件,再修改
UPDATEtableTSETval=$new_valWHEREid=$idANDcurrent_token=$redlock_value
可見,這種方案依賴 MySQL 的事物機制,也達到對方提到的 fecing token 一樣的效果。
但這里還有個小問題,是網友參與問題討論時提出的:兩個客戶端通過這種方案,先「標記」再「檢查+修改」共享資源,那這兩個客戶端的操作順序無法保證啊?
而用 Martin 提到的 fecing token,因為這個 token 是單調遞增的數字,資源服務器可以拒絕小的 token 請求,保證了操作的「順序性」!
Redis 作者對這問題做了不同的解釋,我覺得很有道理,他解釋道:分布式鎖的本質,是為了「互斥」,只要能保證兩個客戶端在并發時,一個成功,一個失敗就好了,不需要關心「順序性」。
前面 Martin 的質疑中,一直很關心這個順序性問題,但 Redis 的作者的看法卻不同。
綜上,Redis 作者的結論:
1、作者同意對方關于「時鐘跳躍」對 Redlock 的影響,但認為時鐘跳躍是可以避免的,取決于基礎設施和運維。
2、Redlock 在設計時,充分考慮了 NPC 問題,在 Redlock 步驟 3 之前出現 NPC,可以保證鎖的正確性,但在步驟 3 之后發生 NPC,不止是 Redlock 有問題,其它分布式鎖服務同樣也有問題,所以不在討論范疇內。
是不是覺得很有意思?
在分布式系統中,一個小小的鎖,居然可能會遇到這么多問題場景,影響它的安全性!
不知道你看完雙方的觀點,更贊同哪一方的說法呢?
別急,后面我還會綜合以上論點,談談自己的理解。
好,講完了雙方對于 Redis 分布鎖的爭論,你可能也注意到了,Martin 在他的文章中,推薦使用 Zookeeper 實現分布式鎖,認為它更安全,確實如此嗎?
基于 Zookeeper 的鎖安全嗎?
如果你有了解過 Zookeeper,基于它實現的分布式鎖是這樣的:
客戶端 1 和 2 都嘗試創建「臨時節點」,例如 /lock
假設客戶端 1 先到達,則加鎖成功,客戶端 2 加鎖失敗
客戶端 1 操作共享資源
客戶端 1 刪除 /lock 節點,釋放鎖
你應該也看到了,Zookeeper 不像 Redis 那樣,需要考慮鎖的過期時間問題,它是采用了「臨時節點」,保證客戶端 1 拿到鎖后,只要連接不斷,就可以一直持有鎖。
而且,如果客戶端 1 異常崩潰了,那么這個臨時節點會自動刪除,保證了鎖一定會被釋放。
不錯,沒有鎖過期的煩惱,還能在異常時自動釋放鎖,是不是覺得很完美?
其實不然。
思考一下,客戶端 1 創建臨時節點后,Zookeeper 是如何保證讓這個客戶端一直持有鎖呢?
原因就在于,客戶端 1 此時會與 Zookeeper 服務器維護一個 Session,這個 Session 會依賴客戶端「定時心跳」來維持連接。
如果 Zookeeper 長時間收不到客戶端的心跳,就認為這個 Session 過期了,也會把這個臨時節點刪除。
同樣地,基于此問題,我們也討論一下 GC 問題對 Zookeeper 的鎖有何影響:
客戶端 1 創建臨時節點 /lock 成功,拿到了鎖
客戶端 1 發生長時間 GC
客戶端 1 無法給 Zookeeper 發送心跳,Zookeeper 把臨時節點「刪除」
客戶端 2 創建臨時節點 /lock 成功,拿到了鎖
客戶端 1 GC 結束,它仍然認為自己持有鎖(沖突)
可見,即使是使用 Zookeeper,也無法保證進程 GC、網絡延遲異常場景下的安全性。
這就是前面 Redis 作者在反駁的文章中提到的:如果客戶端已經拿到了鎖,但客戶端與鎖服務器發生「失聯」(例如 GC),那不止 Redlock 有問題,其它鎖服務都有類似的問題,Zookeeper 也是一樣!
所以,這里我們就能得出結論了:一個分布式鎖,在極端情況下,不一定是安全的。
如果你的業務數據非常敏感,在使用分布式鎖時,一定要注意這個問題,不能假設分布式鎖 100% 安全。
好,現在我們來總結一下 Zookeeper 在使用分布式鎖時優劣:
Zookeeper 的優點:
不需要考慮鎖的過期時間
watch 機制,加鎖失敗,可以 watch 等待鎖釋放,實現樂觀鎖
但它的劣勢是:
性能不如 Redis
部署和運維成本高
客戶端與 Zookeeper 的長時間失聯,鎖被釋放問題
我對分布式鎖的理解
好了,前面詳細介紹了基于 Redis 的 Redlock 和 Zookeeper 實現的分布鎖,在各種異常情況下的安全性問題,下面我想和你聊一聊我的看法,僅供參考,不喜勿噴。
1) 到底要不要用 Redlock?
前面也分析了,Redlock 只有建立在「時鐘正確」的前提下,才能正常工作,如果你可以保證這個前提,那么可以拿來使用。
但保證時鐘正確,我認為并不是你想的那么簡單就能做到的。
第一,從硬件角度來說 ,時鐘發生偏移是時有發生,無法避免。
例如,CPU 溫度、機器負載、芯片材料都是有可能導致時鐘發生偏移的。
第二,從我的工作經歷來說 ,曾經就遇到過時鐘錯誤、運維暴力修改時鐘的情況發生,進而影響了系統的正確性,所以,人為錯誤也是很難完全避免的。
所以,我對 Redlock 的個人看法是,盡量不用它,而且它的性能不如單機版 Redis,部署成本也高,我還是會優先考慮使用主從+ 哨兵的模式 實現分布式鎖。
那正確性如何保證呢?第二點給你答案。
2) 如何正確使用分布式鎖?
在分析 Martin 觀點時,它提到了 fecing token 的方案,給我了很大的啟發,雖然這種方案有很大的局限性,但對于保證「正確性」的場景,是一個非常好的思路。
所以,我們可以把這兩者結合起來用:
1、使用分布式鎖,在上層完成「互斥」目的,雖然極端情況下鎖會失效,但它可以最大程度把并發請求阻擋在最上層,減輕操作資源層的壓力。
2、但對于要求數據絕對正確的業務,在資源層一定要做好「兜底」,設計思路可以借鑒 fecing token 的方案來做。
兩種思路結合,我認為對于大多數業務場景,已經可以滿足要求了。
總結
好了,總結一下。
這篇文章,我們主要探討了基于 Redis 實現的分布式鎖,究竟是否安全這個問題。
從最簡單分布式鎖的實現,到處理各種異常場景,再到引出 Redlock,以及兩個分布式專家的辯論,得出了 Redlock 的適用場景。
最后,我們還對比了 Zookeeper 在做分布式鎖時,可能會遇到的問題,以及與 Redis 的差異。
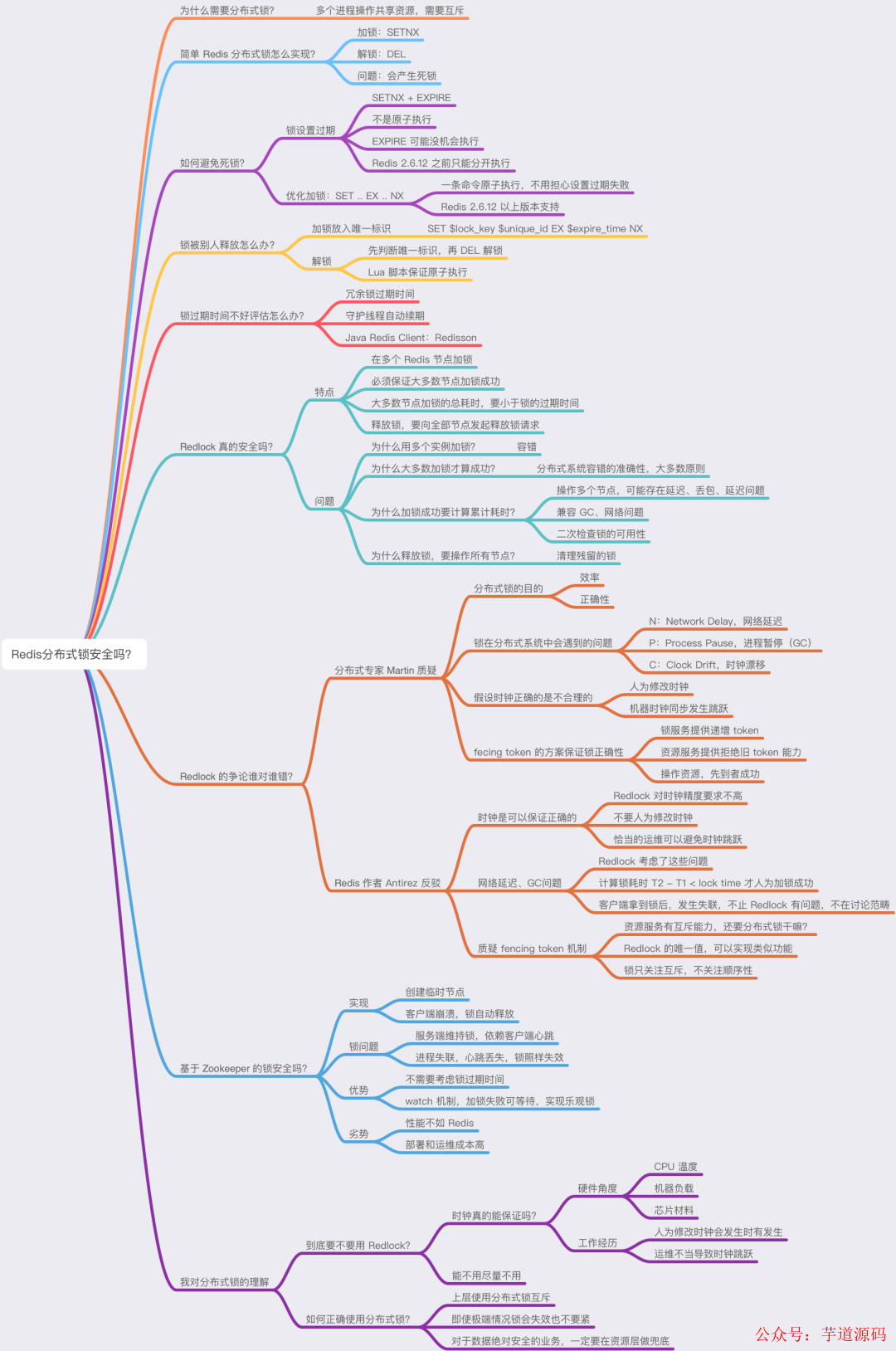
這里我把這些內容總結成了思維導圖,方便你理解。
后記
這篇文章的信息量其實是非常大的,我覺得應該把分布鎖的問題,徹底講清楚了。
如果你沒有理解,我建議你多讀幾遍,并在腦海中構建各種假定的場景,反復思辨。
在寫這篇文章時,我又重新研讀了兩位大神關于 Redlock 爭辯的這兩篇文章,可謂是是收獲滿滿,在這里也分享一些心得給你。
1、在分布式系統環境下,看似完美的設計方案,可能并不是那么「嚴絲合縫」,如果稍加推敲,就會發現各種問題。所以,在思考分布式系統問題時,一定要謹慎再謹慎 。
2、從 Redlock 的爭辯中,我們不要過多關注對錯,而是要多學習大神的思考方式,以及對一個問題嚴格審查的嚴謹精神。
審核編輯:劉清

-
MySQL
+關注
關注
1文章
804瀏覽量
26531 -
Del
+關注
關注
0文章
3瀏覽量
6498 -
UUID
+關注
關注
0文章
22瀏覽量
8125 -
lua腳本
+關注
關注
0文章
21瀏覽量
7583 -
Redis
+關注
關注
0文章
374瀏覽量
10871
原文標題:被問爛的Redis分布式鎖,你真的懂了?
文章出處:【微信號:芋道源碼,微信公眾號:芋道源碼】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
為什么需要分布式鎖 基于Zookeeper鎖安全嗎
深入理解redis分布式鎖





 工商網監
工商網監
評論