") 揭秘ChatGPT的優(yōu)秀性能:新訓(xùn)練范式下的啟示與發(fā)展預(yù)測(cè)
揭秘ChatGPT的優(yōu)秀性能:新訓(xùn)練范式下的啟示與發(fā)展預(yù)測(cè)
ChatGPT應(yīng)該是近期當(dāng)之無愧的“炸子雞”,不論是因它掀起的微軟、谷歌、百度等在AI領(lǐng)域血雨腥風(fēng)、或明或暗的“狂飆”,抑或是微軟將GPT 4植入Office引起的打工人們的恐慌或狂歡,有關(guān)ChatGPT的新聞不絕于耳。那么,為什么在一眾AI技術(shù)和產(chǎn)品中,ChatGPT能殺出重圍引發(fā)海量關(guān)注呢?“不是我優(yōu)秀,全靠同行襯托”,其優(yōu)秀的性能表現(xiàn)將AI的發(fā)展帶入了一個(gè)新階段。那么,它是如何實(shí)現(xiàn)的呢?
本文作者對(duì)ChatGPT的版本發(fā)展和特點(diǎn)進(jìn)行了梳理,發(fā)現(xiàn)明明更擅長(zhǎng)RL(強(qiáng)化學(xué)習(xí))的ChatGPT技術(shù)團(tuán)隊(duì),在GPT 3中融入了情景學(xué)習(xí),并在后續(xù)的InstructGPT/ChatGPT中利用人類反饋優(yōu)化模型,在參數(shù)數(shù)量減少的情況下,通過語言模型的預(yù)訓(xùn)練、獎(jiǎng)勵(lì)模型訓(xùn)練、利用RL方式微調(diào)LM等新訓(xùn)練范式,使得ChatGPT模型的性能和質(zhì)量得到了極大提升,并由此對(duì)機(jī)器學(xué)習(xí)的研究方法有了新的啟示:機(jī)器學(xué)習(xí)技術(shù)的交叉和融合、數(shù)據(jù)的價(jià)值、ChatGPT的影響與挑戰(zhàn)等。
在ChatGPT處在風(fēng)口浪尖的當(dāng)下,希望讀者朋友們不論是進(jìn)行技術(shù)研究還是投資布局,在閱讀本文后都會(huì)有所收獲。
前 言
經(jīng)過了近十年的高速發(fā)展和擴(kuò)張,數(shù)據(jù)驅(qū)動(dòng)的人工智能模型已經(jīng)廣泛應(yīng)用于計(jì)算機(jī)視覺(Computer Vision , CV)、自然語言處理(Natural Language Processing, NLP)、智能控制等諸多領(lǐng)域。為了獲得更強(qiáng)的模型性能,工程師們不斷增加模型的參數(shù)、壓榨訓(xùn)練設(shè)備的性能極限,模型結(jié)構(gòu)也經(jīng)歷著不斷迭代和更新。隨著對(duì)算法模型性能的提升逐漸趨于穩(wěn)定,業(yè)界對(duì)人工智能(Artificial Intelligence, AI)快速發(fā)展和擴(kuò)張的熱情也逐漸冷卻,L4級(jí)別的自動(dòng)駕駛和NLP問答機(jī)器人等領(lǐng)域發(fā)展均遇到瓶頸。在此背景下,ChatGPT的出現(xiàn)成為人工智能領(lǐng)域的一個(gè)全新亮點(diǎn),為人工智能的發(fā)展注入動(dòng)力。
ChatGPT是OpenAI公司提出的一種多模態(tài)大型語言模型(Large Language Model, LLM)。一經(jīng)推出,憑借著出色的性能立刻吸引了全球無數(shù)用戶的目光。
OpenAI公司發(fā)展的主要事件如下:
2015年12月11日,OpenAI成立;
2016年4月27日,發(fā)布OpenAI Gym Beta;
2017年7月20日,發(fā)布Proximal Policy Optimization (PPO)算法;
2019年7月22日,微軟投資OpenAI并與其合作;
2021年1月5日,研究從文本創(chuàng)建圖像神經(jīng)網(wǎng)絡(luò)DALL-E;
2022年12月1日,ChatGPT發(fā)布;
2023年2月2日,OpenAI宣布推出ChatGPT Plus訂閱服務(wù)。
可見,OpenAI是一家以強(qiáng)化學(xué)習(xí)(Reinforcement Learning, RL)立足,并逐漸在AIGC(AI Generated Content)領(lǐng)域深耕的公司。OpenAI構(gòu)建的Gym庫(kù)是常用于測(cè)試RL算法性能的環(huán)境庫(kù),而PPO算法憑借優(yōu)秀的性能以及泛用性,成為了RL算法的基準(zhǔn)。一個(gè)在RL領(lǐng)域有深厚積淀的公司推出了ChatGPT,而不是專職研究NLP的團(tuán)隊(duì),這是非常有趣的事。從之前發(fā)布的論文看,該方法的主要研究人員中,甚至很多作者更擅長(zhǎng)RL領(lǐng)域。
ChatGPT的由來
在ChatGPT問世之前,OpenAI公司已經(jīng)推出了3代GPT模型以及InstructGPT模型,它們的公布時(shí)間、主要研究點(diǎn)和參數(shù)規(guī)模如表1所示[1]。
表1 GPT系列模型指標(biāo)
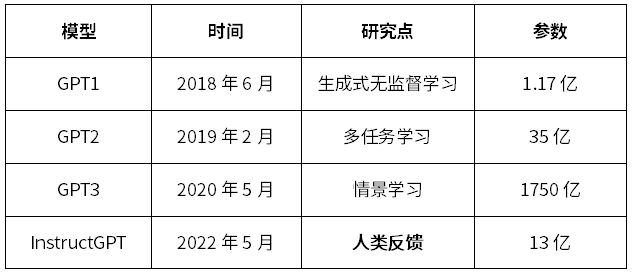
從ChatGPT的發(fā)展歷程可見,從GPT3開始,它加入了情景學(xué)習(xí)的要素,使得模型的輸出可以聯(lián)系前后文的語義和語境,產(chǎn)生的結(jié)果性能更符合邏輯。而在InstructGPT中加入了人類反饋,成為了GPT系列模型性能取得突破的關(guān)鍵因素,即以RL方式依據(jù)人類反饋優(yōu)化原模型,這就是Reinforcement Learning from Human Feedback。
對(duì)于數(shù)據(jù)驅(qū)動(dòng)的語言模型(Language Model, LM),常規(guī)的方法是以預(yù)測(cè)下一個(gè)單詞的方式和損失函數(shù)來建模,通過降低損失函數(shù)使模型預(yù)測(cè)的準(zhǔn)確度提高。這種方式的目標(biāo)是最小化損失函數(shù),與用戶希望獲得的體驗(yàn)在優(yōu)化方向上并不完全一致。因此,用人類反饋?zhàn)鳛樾阅芎饬繕?biāo)準(zhǔn)調(diào)整模型,使模型的輸出與人類價(jià)值對(duì)齊,取得了很好的效果。兩種思路的對(duì)比如圖1所示。
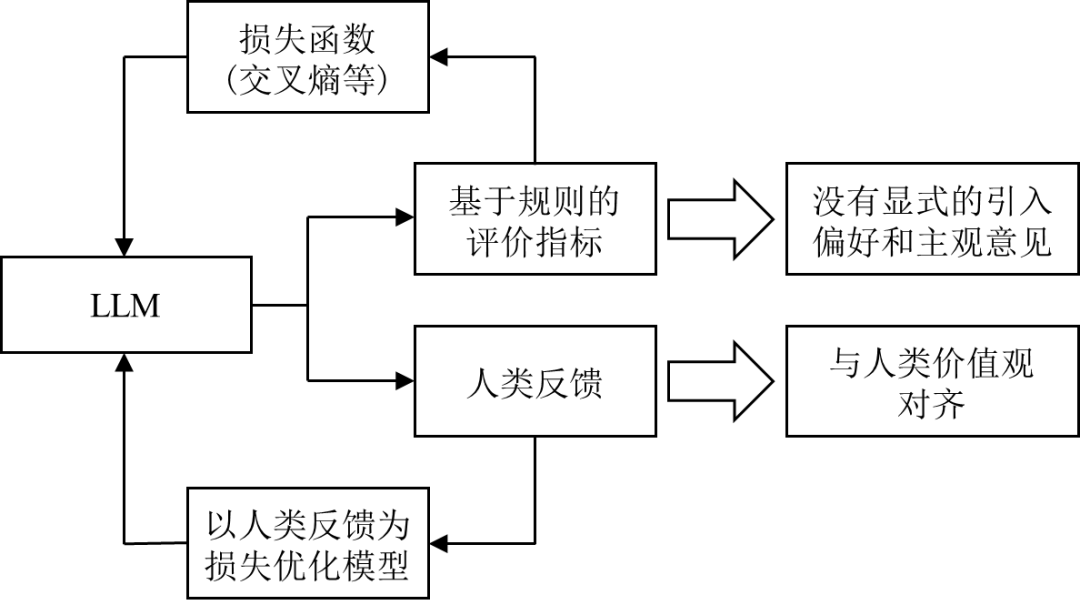
| 圖1 對(duì)于機(jī)器學(xué)習(xí)模型追求目標(biāo)的不同
因此,在GPT3的基礎(chǔ)上,InstructGPT由于加入了人類反饋,取得了驚人的性能。從GPT1到GPT3,模型的規(guī)模快速擴(kuò)張,參數(shù)量從1.17億飆升至1750億[1]。但規(guī)模的擴(kuò)張沒有帶來性能的跨代提升。為何InstructGPT僅用了不到GPT3百分之一的參數(shù)量,卻取得了更好的效果,RLHF發(fā)揮了巨大的作用。
*由于ChatGPT的算法細(xì)節(jié)官方還沒有公開,考慮到InstructGPT使用的方法和ChatGPT接近,下面的討論和應(yīng)用的文獻(xiàn)以InstructGPT為主。
優(yōu)秀的性能從何而來
ChatGPT/InstructGPT的模型訓(xùn)練主要分為三個(gè)部分[2][3]
語言模型的預(yù)訓(xùn)練
原始的語言模型是不需要嚴(yán)格意義上的標(biāo)簽的,可以從數(shù)據(jù)庫(kù)中抽取樣本進(jìn)行訓(xùn)練。在ChatGPT/InstructGPT中,OpenAI雇傭了40位專家對(duì)從數(shù)據(jù)集抽取的提示(prompt)編寫了理想的輸出,即進(jìn)行了數(shù)據(jù)編寫及標(biāo)記數(shù)據(jù),制作了包含11295個(gè)樣本的監(jiān)督學(xué)習(xí)訓(xùn)練集[4],如圖2所示。利用該數(shù)據(jù)集對(duì)原始模型進(jìn)行了監(jiān)督訓(xùn)練,得到了SFT(supervised fine-tune)模型。
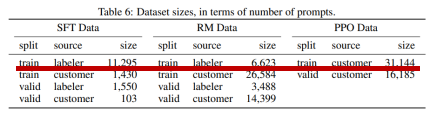
| 圖2 InstructGPT的數(shù)據(jù)集數(shù)量
獎(jiǎng)勵(lì)模型訓(xùn)練
利用預(yù)訓(xùn)練的SFT模型,可以根據(jù)不同的prompt輸出回答了。但生成的回答不一定都能讓用戶滿意。解決該問題的一個(gè)合理的思路是請(qǐng)標(biāo)記者(labeler)對(duì)模型的輸出進(jìn)行打分,給更優(yōu)秀的答案賦予更高的分值,以引導(dǎo)模型產(chǎn)生更合適的回答。但面臨著以下問題:1.labeler很難一直跟上模型訓(xùn)練的過程;2.人工成本高昂;3.分值容易受到labeler主觀因素影響。因此,考慮構(gòu)建一個(gè)獎(jiǎng)勵(lì)模型。
首先針對(duì)同一個(gè)prompt利用模型產(chǎn)生多個(gè)結(jié)果,labeler僅需要對(duì)生成的結(jié)果按照從好到壞的順序排序即可。該方法一方面可以降低labeler的工作量,另一方面,對(duì)于直接打分存在主觀影響,給結(jié)果排序更可能獲得一個(gè)相對(duì)收斂的結(jié)果。再引入Elo排位系統(tǒng),將針對(duì)結(jié)果的排序轉(zhuǎn)換成數(shù)值。該數(shù)值就以標(biāo)量的形式表示了不同回答的好壞。也就構(gòu)建起了《samples, reward》的訓(xùn)練樣本。利用這些訓(xùn)練樣本即可訓(xùn)練得到獎(jiǎng)勵(lì)模型。
利用RL方式微調(diào)LM
將該微調(diào)(fine-tune)任務(wù)描述為一個(gè)RL問題。InstructGPT是利用PPO算法微調(diào)語言模型。首先將一個(gè)prompt輸出微調(diào)的LM模型和輸出的SFT模型。微調(diào)的LM模型是根據(jù)RL策略產(chǎn)生的輸出,并根據(jù)步驟2的獎(jiǎng)勵(lì)模型產(chǎn)生獎(jiǎng)勵(lì)值,以評(píng)價(jià)輸出結(jié)果的好壞。根據(jù)PPO算法的原理,除了需要以獲得更多獎(jiǎng)勵(lì)的方向進(jìn)行微調(diào)LM模型的訓(xùn)練,還要計(jì)算該微調(diào)模型和SFT模型的KL散度,如下式所示[4]。
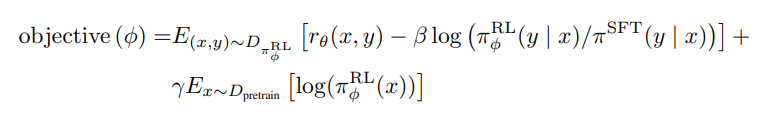
式中,期望的第一項(xiàng) 即為獎(jiǎng)勵(lì)函數(shù)反饋的獎(jiǎng)勵(lì)值。第二項(xiàng) 為微調(diào)模型和SFT模型的KL散度,該懲罰項(xiàng)有助于保證模型輸出合理連貫的文本片段。如果沒有該懲罰項(xiàng),優(yōu)化可能會(huì)產(chǎn)生亂碼的文本。第三項(xiàng) 是在預(yù)訓(xùn)練模型上求的期望,提升模型的泛化能力,防止模型僅關(guān)注當(dāng)前任務(wù)。隨著RL策略的更新,由于有獎(jiǎng)勵(lì)模型的引導(dǎo),微調(diào)LM模型的輸出為逐漸向人類評(píng)分較高的結(jié)果靠近。
*對(duì)于該訓(xùn)練過程,用戶還可以繼續(xù)將這些輸出與模型的早期版本進(jìn)行排名,目前還沒有論文討論這一點(diǎn)。這引入了RL策略和獎(jiǎng)勵(lì)模型演變的復(fù)雜動(dòng)態(tài),是一個(gè)復(fù)雜而開放的研究問題。
ChatGPT的思考和啟示
ChatGPT的成功在給用戶和研究者帶來震撼的同時(shí),也將目前機(jī)器學(xué)習(xí)的研究方法清晰的展現(xiàn)在人們面前。
機(jī)器學(xué)習(xí)技術(shù)的交叉和融合
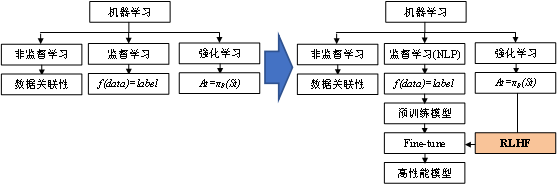
| 圖3 機(jī)器學(xué)習(xí)技術(shù)融合
傳統(tǒng)上,機(jī)器學(xué)習(xí)可以分成監(jiān)督學(xué)習(xí)、非監(jiān)督學(xué)習(xí)和強(qiáng)化學(xué)習(xí)。非監(jiān)督學(xué)習(xí)專注以挖掘數(shù)據(jù)之間的規(guī)律和價(jià)值。監(jiān)督學(xué)習(xí)建立起數(shù)據(jù)和標(biāo)簽之間的映射關(guān)系,即 。強(qiáng)化學(xué)習(xí)則是可以根據(jù)當(dāng)前狀態(tài)進(jìn)行智能決策。算法的進(jìn)步不僅是在各自的領(lǐng)域深挖和探索,分支之間的技術(shù)融合也可以迸發(fā)出強(qiáng)大的性能提升。2013年,DeepMind提出用神經(jīng)網(wǎng)絡(luò)取代RL中的價(jià)值表格,可看作是利用深度學(xué)習(xí)(Deep Learning, DL)對(duì)RL的優(yōu)化方法。該方法解決了價(jià)值表格由于表達(dá)能力不足無法適用于具有高緯度離散狀態(tài)空間和連續(xù)動(dòng)作空間的RL問題,極大地?cái)U(kuò)展了RL的研究范圍和使用場(chǎng)景,開拓了深度強(qiáng)化學(xué)習(xí)(Deep Reinforcement Learning, DRL)這一領(lǐng)域[5]。該成果在后續(xù)優(yōu)化后于2015年發(fā)表在Nature上[6]。而ChatGPT則是利用RL算法優(yōu)化了DL模型的一個(gè)很好的例子。目前,利用RL進(jìn)行fine-tune已經(jīng)出現(xiàn)成為全新的模型訓(xùn)練范式的趨勢(shì)。可以預(yù)見,該范式未來會(huì)廣泛應(yīng)用于其他研究領(lǐng)域。ChatGPT是否會(huì)像DQN那樣,成為新的訓(xùn)練范式促進(jìn)DL發(fā)展的標(biāo)志,我們拭目以待。
*根據(jù)2023年2月26日的新聞,google計(jì)劃將利用RL微調(diào)模型的訓(xùn)練范式引入到CV。
數(shù)據(jù)的價(jià)值
傳統(tǒng)上對(duì)于深度模型的研究,無論是設(shè)計(jì)更巧妙的模型結(jié)構(gòu)、或者是標(biāo)記更多的訓(xùn)練樣本、再或者是擴(kuò)大模型參數(shù)期望大力出奇跡,都在“大”或者“多”的方向深挖。ChatGPT讓我們看到了“質(zhì)”的重要性。

| 圖4 分階段的模型訓(xùn)練方法
OpenAI公開表示將模型和人類意圖對(duì)齊的投資,相較于訓(xùn)練更大的模型,投入產(chǎn)出比更高更好。就像前文所說,GPT3的參數(shù)有1750億個(gè),而InstructGPT的參數(shù)僅有13億。數(shù)據(jù)量大幅縮減的同時(shí),反而取得了碾壓的性能優(yōu)勢(shì)。這是否意味著,目前超大規(guī)模的模型在“體型”方面是否已經(jīng)足夠應(yīng)付目前研究的任務(wù),而真正缺少的是高質(zhì)量的關(guān)鍵數(shù)據(jù)呢?
RLHF的訓(xùn)練范式被越來越多的研究驗(yàn)證,對(duì)于模型性能的提升是空前的。那么未來針對(duì)不同的問題構(gòu)建fine-tune的數(shù)據(jù)集就成為了關(guān)鍵。如圖5所示。傳統(tǒng)的、大量的數(shù)據(jù)集可能構(gòu)建起了模型的初始性能,在此基礎(chǔ)上需要專家樣本對(duì)其進(jìn)行引導(dǎo),這部分?jǐn)?shù)據(jù)的量遠(yuǎn)小于初始的數(shù)據(jù)集,但對(duì)模型取得的效果卻遠(yuǎn)超簡(jiǎn)單的增加原始數(shù)據(jù)集的效果。針對(duì)任務(wù),如何構(gòu)建高質(zhì)量的fine-tune數(shù)據(jù)也是需要解決的問題。
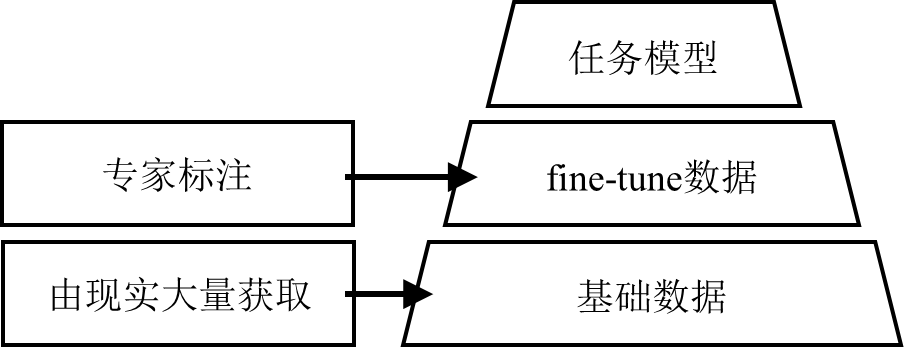
| 圖5 不同質(zhì)量的數(shù)據(jù)支撐模型訓(xùn)練
ChatGPT的影響與挑戰(zhàn)
在NovaAI問世之初,人們就見識(shí)到了AIGC的威力。如今,ChatGPT已經(jīng)出現(xiàn)在我們的面前,高超的性能讓很多行業(yè)的從業(yè)者感受到了巨大的壓力。未來,GPT4的公布和投入使用,將會(huì)很大程度地影響當(dāng)前的業(yè)界態(tài)勢(shì)。
工作效率的提升
狹義上說,ChatGPT直接改變了文本處理、簡(jiǎn)單的代碼編寫、資料查詢等生產(chǎn)和生活方式。微軟已經(jīng)將ChatGPT融合進(jìn)bing搜索引擎,直接對(duì)google和baidu等搜索引擎取得了絕對(duì)的優(yōu)勢(shì);將ChatGPT融合進(jìn)office,提升工作效率。一些工作組也在嘗試制作插件融合進(jìn)集成開發(fā)環(huán)境(Integrated Development Environment, IDE),輔助程序員更快的完成項(xiàng)目代碼等。
廣義上說,受到ChatGPT啟發(fā),未來在更多的領(lǐng)域?qū)a(chǎn)生性能直逼人類專家的AI模型和算法。ChatGPT是將RLHF應(yīng)用與LLM的成功案例,但相信利用此方法產(chǎn)生高性能模型的探索會(huì)迎來快速增長(zhǎng),未來將會(huì)在各領(lǐng)域涌現(xiàn)。工具性能的差距某種程度上會(huì)影響社會(huì)信息化的發(fā)展進(jìn)度,掌握未來核心算法和數(shù)據(jù)也是國(guó)內(nèi)研究者需要面臨的問題。
用戶數(shù)據(jù)的獲取
ChatGPT在上線之后僅5天就實(shí)現(xiàn)了獲得超過100萬用戶的里程碑。這個(gè)速度遠(yuǎn)超twitter、FB等知名應(yīng)用,大量的用戶為ChatGPT帶來了海量的數(shù)據(jù)。在大數(shù)據(jù)的時(shí)代,先入場(chǎng)往往就能夠吸引更多的數(shù)據(jù)。但從目前的研究看,fine-tune數(shù)據(jù)是提升模型性能的關(guān)鍵,而這些數(shù)據(jù)往往需要具備專業(yè)知識(shí)的專家標(biāo)記。大量的用戶數(shù)據(jù)由于質(zhì)量參差不齊,是否會(huì)使GPT的后續(xù)模型性能越來越優(yōu)秀,并逐漸成為該領(lǐng)域獨(dú)樹一幟的存在,也是一個(gè)值得觀察和研究的問題。
在生成模型之上的新范式
ChatGPT依然是一個(gè)文本生成模型,即使利用RLHF進(jìn)行了和人類價(jià)值的對(duì)齊,但依然無法和人類輸出的結(jié)果在任何情形下都一樣。例如,當(dāng)向ChatGPT詢問某領(lǐng)域或者某會(huì)議的論文時(shí),輸出的結(jié)果從形式上看有模有樣。但如果查閱,會(huì)發(fā)現(xiàn)很多文章是ChatGPT杜撰的。因此,ChatGPT目前只學(xué)到了“形似”。但將ChatGPT和bing搜索引擎融合的new bing一定程度上克服了這個(gè)問題。因?yàn)橄噍^于ChatGPT的生成,new bing是搜索+生成的模型,而搜索得到的結(jié)果是客觀存在的。因此,當(dāng)使用new bing獲取某領(lǐng)域或者某會(huì)議的文章時(shí),產(chǎn)生的結(jié)果是真實(shí)存在的。這在一些領(lǐng)域可能更有使用價(jià)值。
國(guó)內(nèi)缺少可對(duì)標(biāo)的產(chǎn)品
ChatGPT帶來的工作效率的提升是顯而易見的,并且當(dāng)該模型投入商業(yè)化后,能夠取得的收益相信也是非常可觀的。目前國(guó)內(nèi)還沒有性能可與之對(duì)標(biāo)的產(chǎn)品。該模型訓(xùn)練不僅需要高昂的成本和時(shí)間,對(duì)于fine-tune的構(gòu)建和后續(xù)的優(yōu)化也非常重要。我們期待能夠媲美GPT系列的國(guó)內(nèi)語言模型的問世。
審核編輯 :李倩
-
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8434瀏覽量
132875 -
大數(shù)據(jù)
+關(guān)注
關(guān)注
64文章
8903瀏覽量
137610 -
ChatGPT
+關(guān)注
關(guān)注
29文章
1566瀏覽量
7890
原文標(biāo)題:揭秘ChatGPT的優(yōu)秀性能:新訓(xùn)練范式下的啟示與發(fā)展預(yù)測(cè)
文章出處:【微信號(hào):SDNLAB,微信公眾號(hào):SDNLAB】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
基于梯度下降算法的三元鋰電池循環(huán)壽命預(yù)測(cè)

【「大模型啟示錄」閱讀體驗(yàn)】+開啟智能時(shí)代的新鑰匙
【「大模型啟示錄」閱讀體驗(yàn)】如何在客服領(lǐng)域應(yīng)用大模型
ChatGPT:怎樣打造智能客服體驗(yàn)的重要工具?
如何評(píng)估 ChatGPT 輸出內(nèi)容的準(zhǔn)確性
端到端InfiniBand網(wǎng)絡(luò)解決LLM訓(xùn)練瓶頸

llm模型和chatGPT的區(qū)別
谷景揭秘如何在色環(huán)電感封裝尺寸不變的情況下升級(jí)電感性能
使用espbox lite進(jìn)行chatgpt_demo的燒錄報(bào)錯(cuò)是什么原因?
名單公布!【書籍評(píng)測(cè)活動(dòng)NO.34】大語言模型應(yīng)用指南:以ChatGPT為起點(diǎn),從入門到精通的AI實(shí)踐教程
OpenAI 深夜拋出王炸 “ChatGPT- 4o”, “她” 來了
探索ChatGPT模型的人工智能語言模型





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論