

Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation
1. 論文信息
標(biāo)題:Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation
作者:Jay Zhangjie Wu, Yixiao Ge, Xintao Wang, Weixian Lei, Yuchao Gu, Yufei Shi, Wynne Hsu, Ying Shan, Xiaohu Qie, Mike Zheng Shou
原文鏈接:https://arxiv.org/pdf/2212.11565.pdf
代碼鏈接:https://tuneavideo.github.io/
2. 引言
坤坤鎮(zhèn)樓:

在這里插入圖片描述

在這里插入圖片描述

在這里插入圖片描述

在這里插入圖片描述
大規(guī)模的多模態(tài)數(shù)據(jù)集是由數(shù)十億個(gè)文本圖像對(duì)組成,得益于高質(zhì)量的數(shù)據(jù),在文本到圖像 (text-to-image, T2I) 生成方面取得了突破 。為了在文本到視頻 (T2V) 生成中復(fù)制這一成功,最近的工作已將純空間 T2I 生成模型擴(kuò)展到時(shí)空域。這些模型通常采用在大規(guī)模文本視頻數(shù)據(jù)集(例如 WebVid-10M)上進(jìn)行訓(xùn)練的標(biāo)準(zhǔn)范式。盡管這種范式為 T2V 生成帶來(lái)了可喜的結(jié)果,但它需要對(duì)大型硬件加速器進(jìn)行大規(guī)模數(shù)據(jù)集上的訓(xùn)練,這一過(guò)程既昂貴又耗時(shí)。人類(lèi)擁有利用現(xiàn)有知識(shí)和提供給他們的信息創(chuàng)造新概念、想法或事物的能力。例如,當(dāng)呈現(xiàn)一段文字描述為“一個(gè)人在雪地上滑雪”的視頻時(shí),我們可以利用我們對(duì)熊貓長(zhǎng)相的了解來(lái)想象熊貓?jiān)谘┑厣匣┑臉幼印S捎谑褂么笠?guī)模圖像文本數(shù)據(jù)進(jìn)行預(yù)訓(xùn)練的 T2I 模型已經(jīng)捕獲了開(kāi)放域概念的知識(shí),因此出現(xiàn)了一個(gè)直觀的問(wèn)題:它們能否從單個(gè)視頻示例中推斷出其他新穎的視頻,例如人類(lèi)?因此引入了一種新的 T2V 生成設(shè)置,即 One-Shot Video Tuning,其中僅使用單個(gè)文本-視頻對(duì)來(lái)訓(xùn)練 T2V 生成器。生成器有望從輸入視頻中捕獲基本的運(yùn)動(dòng)信息,并合成帶有編輯提示的新穎視頻。

本文提出了一種新的文本到視頻(T2V)生成設(shè)置——單次視頻調(diào)諧,其中只呈現(xiàn)一個(gè)文本-視頻對(duì)。該模型基于大規(guī)模圖像數(shù)據(jù)預(yù)訓(xùn)練的最先進(jìn)的文本到圖像(T2I)擴(kuò)散模型構(gòu)建。研究人員做出了兩個(gè)關(guān)鍵觀察:1)T2I模型可以生成代表動(dòng)詞術(shù)語(yǔ)的靜止圖像;2)將T2I模型擴(kuò)展為同時(shí)生成多個(gè)圖像表現(xiàn)出驚人的內(nèi)容一致性。為了進(jìn)一步學(xué)習(xí)連續(xù)運(yùn)動(dòng),研究人員引入了Tune-A-Video,它包括一個(gè)定制的時(shí)空注意機(jī)制和一個(gè)高效的單次調(diào)諧策略。在推理時(shí),研究人員采用DDIM反演為采樣提供結(jié)構(gòu)指導(dǎo)。大量定性和定量實(shí)驗(yàn)表明,我們的方法在各種應(yīng)用中都具有顯著的能力。
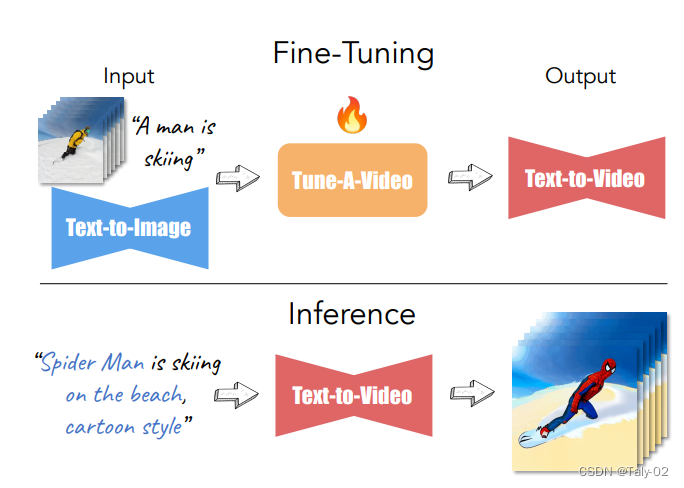
論文提出的one-shot tuning的setting如上。本文的貢獻(xiàn)如下:1. 該論文提出了一種從文本生成視頻的新方法,稱(chēng)為One-Shot Video Tuning。2. 提出的框架Tune-A-Video建立在經(jīng)過(guò)海量圖像數(shù)據(jù)預(yù)訓(xùn)練的最先進(jìn)的文本到圖像(T2I)擴(kuò)散模型之上。3. 本文介紹了一種稀疏的時(shí)空注意力機(jī)制和生成時(shí)間連貫視頻的有效調(diào)優(yōu)策略。4. 實(shí)驗(yàn)表明,所提出的方法在廣泛的應(yīng)用中取得了顯著成果。
3. 方法
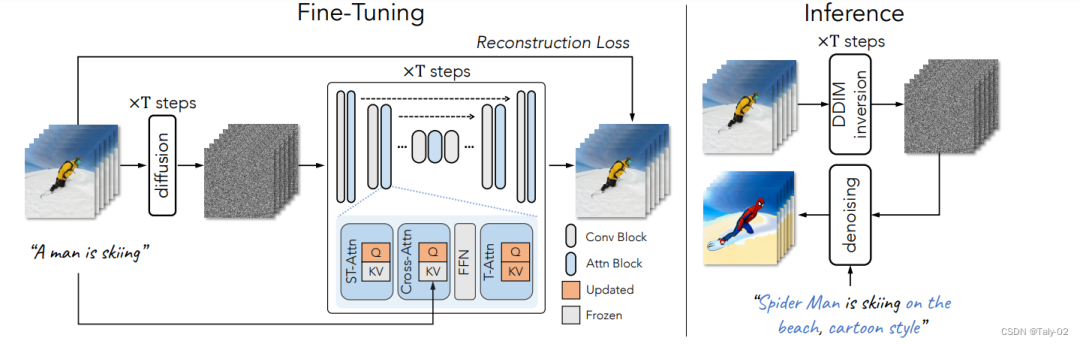
該論文提出了一種從文本生成視頻的新方法,稱(chēng)為One-Shot Video Tuning。擬議的框架Tune-A-Video建立在經(jīng)過(guò)海量圖像數(shù)據(jù)預(yù)訓(xùn)練的最先進(jìn)的文本到圖像(T2I)擴(kuò)散模型之上。該論文還提出了一種有效的調(diào)優(yōu)策略和結(jié)構(gòu)反演,以生成時(shí)間一致的視頻。實(shí)驗(yàn)表明,所提出的方法在廣泛的應(yīng)用中取得了顯著成果。
3.1 DDPMs的回顧
DDPMs(去噪擴(kuò)散概率模型)是一種深度生成模型,最近因其令人印象深刻的性能而受關(guān)注。DDPMs通過(guò)迭代去噪過(guò)程,從標(biāo)準(zhǔn)高斯分布的樣本生成經(jīng)驗(yàn)分布的樣本。借助于對(duì)生成結(jié)果的漸進(jìn)細(xì)化,它們?cè)谠S多圖像生成基準(zhǔn)上都取得了最先進(jìn)的樣本質(zhì)量。
根據(jù)貝葉斯定律 and 可以表達(dá)為:
DDPMs的主要思想是:給定一組圖像數(shù)據(jù),我們逐步添加一點(diǎn)噪聲。每一步,圖像變得越來(lái)越不清晰,直到只剩下噪聲。這被稱(chēng)為“正向過(guò)程”。然后,我們學(xué)習(xí)一個(gè)機(jī)器學(xué)習(xí)模型,可以撤消每一個(gè)這樣的步驟,我們稱(chēng)之為“反向過(guò)程”。如果我們能夠成功地學(xué)習(xí)一個(gè)反向過(guò)程,我們就有了一個(gè)可以從純隨機(jī)噪聲生成圖像的模型。
這其中又有LDMs這種范式的模型比較流行,Latent Diffusion Models(LDMs)是一種基于DDPMs的圖像生成方法,它通過(guò)在latent space中迭代“去噪”數(shù)據(jù)來(lái)生成圖像,然后將表示結(jié)果解碼為完整的圖像。LDMs通過(guò)將圖像形成過(guò)程分解為去噪自編碼器的順序應(yīng)用,實(shí)現(xiàn)了在圖像數(shù)據(jù)和其他領(lǐng)域的最先進(jìn)的合成結(jié)果。此外,它們的公式允許引入一個(gè)引導(dǎo)機(jī)制來(lái)控制圖像生成過(guò)程,而無(wú)需重新訓(xùn)練。然而,由于這些模型通常直接在像素空間中運(yùn)行,因此優(yōu)化強(qiáng)大的DMs通常需要數(shù)百個(gè)GPU天,并且推理由于順序評(píng)估而昂貴。為了在有限的計(jì)算資源上啟用DM訓(xùn)練,同時(shí)保留它們的質(zhì)量和靈活性,我們?cè)趶?qiáng)大的預(yù)訓(xùn)練自編碼器的潛在空間中應(yīng)用它們。與以前的工作不同,訓(xùn)練擴(kuò)散模型時(shí)使用這樣一個(gè)表示允許首次在復(fù)雜度降低和細(xì)節(jié)保留之間達(dá)到近乎最優(yōu)的平衡點(diǎn),極大地提高了視覺(jué)保真度。
3.2 Network Inflation
T2I 擴(kuò)散模型(例如,LDM)通常采用 U-Net ,這是一種基于空間下采樣通道然后是帶有跳躍連接的上采樣通道的神經(jīng)網(wǎng)絡(luò)架構(gòu)。它由堆疊的二維卷積殘差塊和Transformer塊組成。每個(gè)Transformer塊包括空間自注意層、交叉注意層和前饋網(wǎng)絡(luò) (FFN)。空間自注意力利用特征圖中的像素位置來(lái)實(shí)現(xiàn)相似的相關(guān)性,而交叉注意力則考慮像素與條件輸入(例如文本)之間的對(duì)應(yīng)關(guān)系。形式上,給定視頻幀 vi 的latent表征 ,很自然的可以想到要用self-attention機(jī)制來(lái)完成:
然后論文借助卷積來(lái)強(qiáng)化temporal coherence,并采用spatial self-attention來(lái)加強(qiáng)注意力機(jī)制,來(lái)捕捉不同視頻幀的變化。
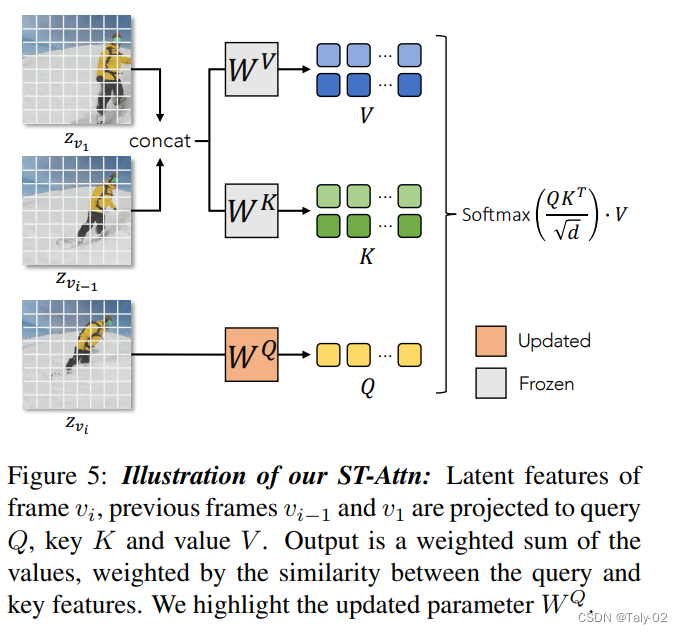
為了減少計(jì)算復(fù)雜度,Q采用相同的而K和V都是通過(guò)共享的矩陣來(lái)獲取:
這樣計(jì)算復(fù)雜度就降低到了,相對(duì)比較可以接受。
3.3 Fine-Tuning and Inference
Fine-Tuning是使預(yù)訓(xùn)練的模型適應(yīng)新任務(wù)或數(shù)據(jù)集的過(guò)程。在提出的方法Tune-A-Video中,文本到圖像(T2I)擴(kuò)散模型是在海量圖像數(shù)據(jù)上預(yù)先訓(xùn)練的。然后,在少量的文本視頻對(duì)上對(duì)模型進(jìn)行微調(diào),以從文本生成視頻。Fine-Tuning過(guò)程包括使用反向傳播使用新數(shù)據(jù)更新預(yù)訓(xùn)練模型的權(quán)重。推理是使用經(jīng)過(guò)訓(xùn)練的模型對(duì)新數(shù)據(jù)進(jìn)行預(yù)測(cè)的過(guò)程。在提出的方法中,使用經(jīng)過(guò)Fine-Tuning的T2I模型進(jìn)行推斷,從文本生成視頻。
Inference過(guò)程包括向模型輸入文本,模型生成一系列靜止圖像。然后將靜止圖像組合成視頻。本發(fā)明提出的方法利用高效的注意力調(diào)整和結(jié)構(gòu)反演來(lái)提高所生成視頻的時(shí)間一致性。
4. 實(shí)驗(yàn)
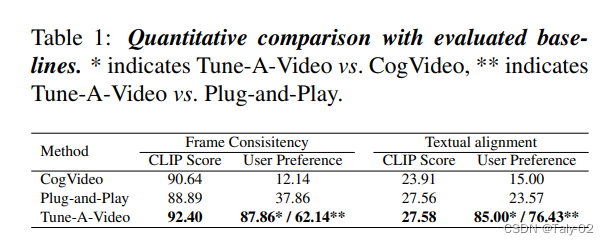
作者為了證明方法的有效性,進(jìn)行了廣泛的實(shí)驗(yàn),以評(píng)估所提出的方法在各種應(yīng)用中的性能。這些實(shí)驗(yàn)是在多個(gè)數(shù)據(jù)集上進(jìn)行的,包括Kinetics-600數(shù)據(jù)集、Something-Something-Something數(shù)據(jù)集和YouCook2數(shù)據(jù)集。實(shí)驗(yàn)中使用的評(píng)估指標(biāo)包括弗雷切特入口距離(FID)、盜夢(mèng)分?jǐn)?shù)(IS)和結(jié)構(gòu)相似度指數(shù)(SSIM)。實(shí)驗(yàn)結(jié)果證明了所提出的文本驅(qū)動(dòng)視頻生成和編輯方法的有效性。
看一下可視化的效果:


5. 討論
該論文在處理輸入視頻中的多個(gè)物體和物體交互方面存在局限性。這是由于擬議框架中使用的文本到圖像(T2I)模型的固有局限性。該論文建議使用其他條件信息,例如深度,使模型能夠區(qū)分不同的物體及其相互作用。但是,這種研究途徑留待將來(lái)使用。
6. 結(jié)論
該論文介紹了一項(xiàng)名為 One-Shot Video Tuning 的從文本生成視頻的新任務(wù)。該任務(wù)涉及僅使用一對(duì)文本視頻和預(yù)先訓(xùn)練的模型來(lái)訓(xùn)練視頻生成器。擬議的框架Tune-A-Video對(duì)于文本驅(qū)動(dòng)的視頻生成和編輯既簡(jiǎn)單又有效。該論文還提出了一種有效的調(diào)優(yōu)策略和結(jié)構(gòu)反演,以生成時(shí)間一致的視頻。實(shí)驗(yàn)表明,所提出的方法在廣泛的應(yīng)用中取得了顯著成果。
審核編輯 :李倩
-
圖像數(shù)據(jù)
+關(guān)注
關(guān)注
0文章
54瀏覽量
11468 -
模型
+關(guān)注
關(guān)注
1文章
3501瀏覽量
50157 -
生成器
+關(guān)注
關(guān)注
7文章
322瀏覽量
21766
原文標(biāo)題:Tune-A-Video論文解讀(小黑子的狂歡)
文章出處:【微信號(hào):GiantPandaCV,微信公眾號(hào):GiantPandaCV】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
App Tune-up Kit Pofiler工具使用介紹
Auto Tune Vocal EQ均衡器永久版發(fā)布
Composite Video Separation Tec
Video Amplifier with Sync Stri
EL4501 pdf datasheet (Video Fr
allegro如何走蛇行線(delay tune)
Video and Image Processing Up
Digital Video Standards The 19
Design and Layout of a Video G
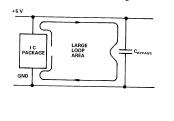
How to Tune and Antenna Match
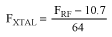
使用Atmel Studio 6中的優(yōu)化向?qū)?lái)調(diào)整QTouter設(shè)計(jì)
openEuler Summit開(kāi)發(fā)者峰會(huì):基于AI的操作系統(tǒng)性能調(diào)優(yōu)引擎A-Tune
歐拉(openEuler)Summit 2021:歐拉demo分享——A-Tune






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評(píng)論