 MySQL MHA基本介紹
MySQL MHA基本介紹
******** 摘要********
MySQL是目前主流的關系型數據庫管理系統,目前在全球被廣泛地應用。由于其開源、體積小、速度快、成本低、安全性高,因此許多網站選擇MySQL作為數據庫進行存儲數據。
****以前在運維數據庫過程中經常會遇到這樣的困擾:沒有工具快速切換集群主庫,如果切換主庫,需要DBA手動修改從庫指向,修改元信息等。所以今天給大家介紹一款工具MHA,可以實現需求快速上線,不影響當前架構,整個切換全部自動化處理,方便DBA使用,例如檢查,操作,展示等。
在 MySQL(5.5 及以下)傳統復制的時代,MHA(Master High Availability)在 MySQL 高可用應用中非常成熟。在 MySQL(5.6)及 GTID 時代開啟以后,MHA 沒有隨之進行進一步的更新,但是很多互聯網公司依然在沿用這個技術。因此本文給出了MHA的簡單介紹。
2
MHA簡介
【 什么是MHA 】
****MHA目前在MySQL高可用方面是一個相對成熟的解決方案,它由日本DeNA公司youshimaton開發,是一套優秀的作為MySQL高可用性環境下故障切換和主從提升的高可用軟件。在MySQL故障切換過程中,MHA能做到在0~30秒之內自動完成數據庫的故障切換操作,并且在進行故障切換的過程中,MHA能在最大程度上保證數據的一致性,以達到真正意義上的高可用。
目前MHA主要支持一主多從的架構,在搭建MHA時至少要有一個Master主庫和兩個Slave從庫,MHA架構支持任何存儲引擎。
****該軟件由兩部分組成:MHA Manager(管理節點)和MHA Node(數據節點)。MHA Manager可以單獨部署在一臺獨立的機器上管理多個master-slave集群,也可以部署在一臺slave節點上。MHA Node運行在每臺MySQL服務器上,MHA Manager會定時探測集群中的master節點,當master出現故障時,它可以自動將最新數據的slave提升為新的master,然后將所有其他的slave重新指向新的master。整個故障轉移過程對應用程序完全透明。
【 MHA優勢 】
- 不影響服務器性能,易安裝,不改變現有部署
- 故障切換(實現自動故障檢測和故障轉移,通常在30秒以內)
- 數據一致性保證
- 不需要對當前mysql環境做重大修改
- 不需要添加額外的服務器(僅一臺manager就可管理上百個replication)
- ****性能優秀,可工作在半同步復制和異步復制,當監控mysql狀態時,僅需要每隔N秒向master發送ping包(默認3秒),所以對性能無影響。你可以理解為MHA的性能和簡單的主從復制框架性能一樣
- ****只要replication支持的存儲引擎mha都支持
【 MHA組成 】
MHA軟件由兩部分組成,Manager工具包和Node工具包,具體的說明如下。
Manager工具包主要包括以下幾個工具:
- masterha_check_ssh 檢查MHA的SSH配置狀況
- masterha_check_repl 檢查MySQL復制狀況
- masterha_manger 啟動MHA
- masterha_check_status 檢測當前MHA運行狀態
- masterha_master_monitor 檢測master是否宕機
- masterha_master_switch 控制故障轉移(自動或者手動)
- masterha_conf_host 添加或刪除配置的server信息
Node工具包(這些工具通常由MHA Manager的腳本觸發,無需人為操作)主要包括以下幾個工具:
- save_binary_logs 保存和復制master的二進制日志
- apply_diff_relay_logs 識別差異的中繼日志事件并將其差異的事件應用于其他的slave
- filter_mysqlbinlog 去除不必要的ROLLBACK事件
- purge_relay_logs 清除中繼日志(不會阻塞SQL線程)
【 MHA版本選擇 】
從MHA的0.56版本開始,也支持基于GTID的故障切換。MHA會自動檢測mysqld是否在GTID運行,如果GTID開啟,MHA就實現帶GTID的故障切換,如果沒有啟用,MHA就使用基于relay log的故障切換。
3MHA實現
【 工作流程 】
- 從宕機崩潰的master保存二進制日志事件(binlog events);
- 識別含有最新更新的slave;
- 應用差異的中繼日志(relay log)到其他的slave;
- 應用從master保存的二進制日志事件(binlog events);
- 提升一個slave為新的master;
- 使其他的slave連接新的master進行復制。
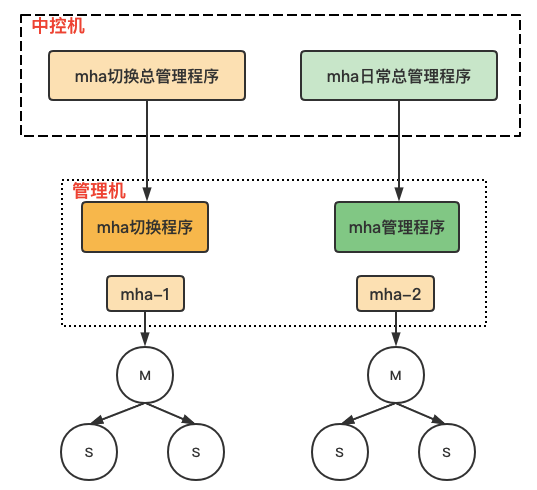
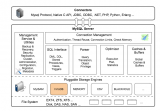
【 MHA架構 】
中控機管理工具,用于管理mha部署、主從切換等;****
****mha管理工具,支持部署、更新配置文件、目錄等開關。manager收集切換日志、集群互信、檢查ssh、repl狀態、配置文件一致性等。
【 核心腳本工作原理介紹 】
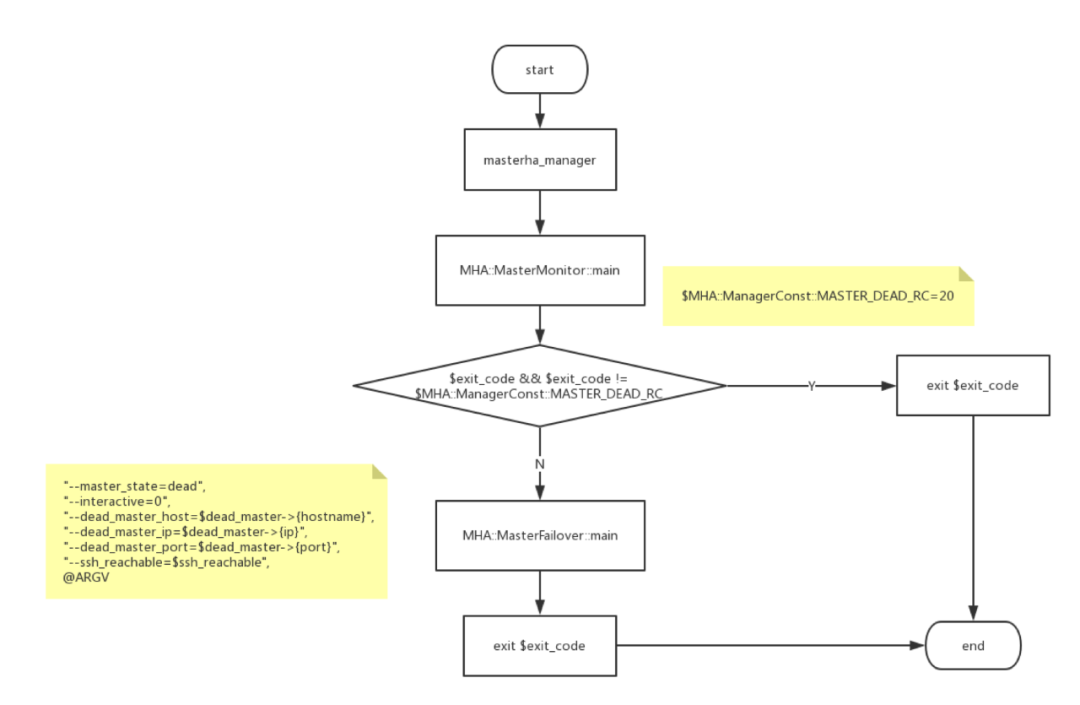
1) masterha_manager
mha啟動腳本為masterha_manager,可選參數為remove_dead_master_conf、manger_log、ignore_last_failover。
masterha_manager主要流程為:
1.調用MasterMonitor,監控MySQL master狀態;
2.發現master狀態異常后,調用MasterFailover進行切換;
3.manager通過monitor監測master狀態,一旦獲得返回值,則表明monitor狀態異常。通過判斷exit_code確定是否應切換。
4.檢測通過后,調用MasterFailover進執行切換操作。
具體流程如下:
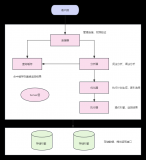
2) MasterMonitor
MasterHA_Manager調用MasterMonitor的main方法對MySQL進行監控。
具體流程圖如下:
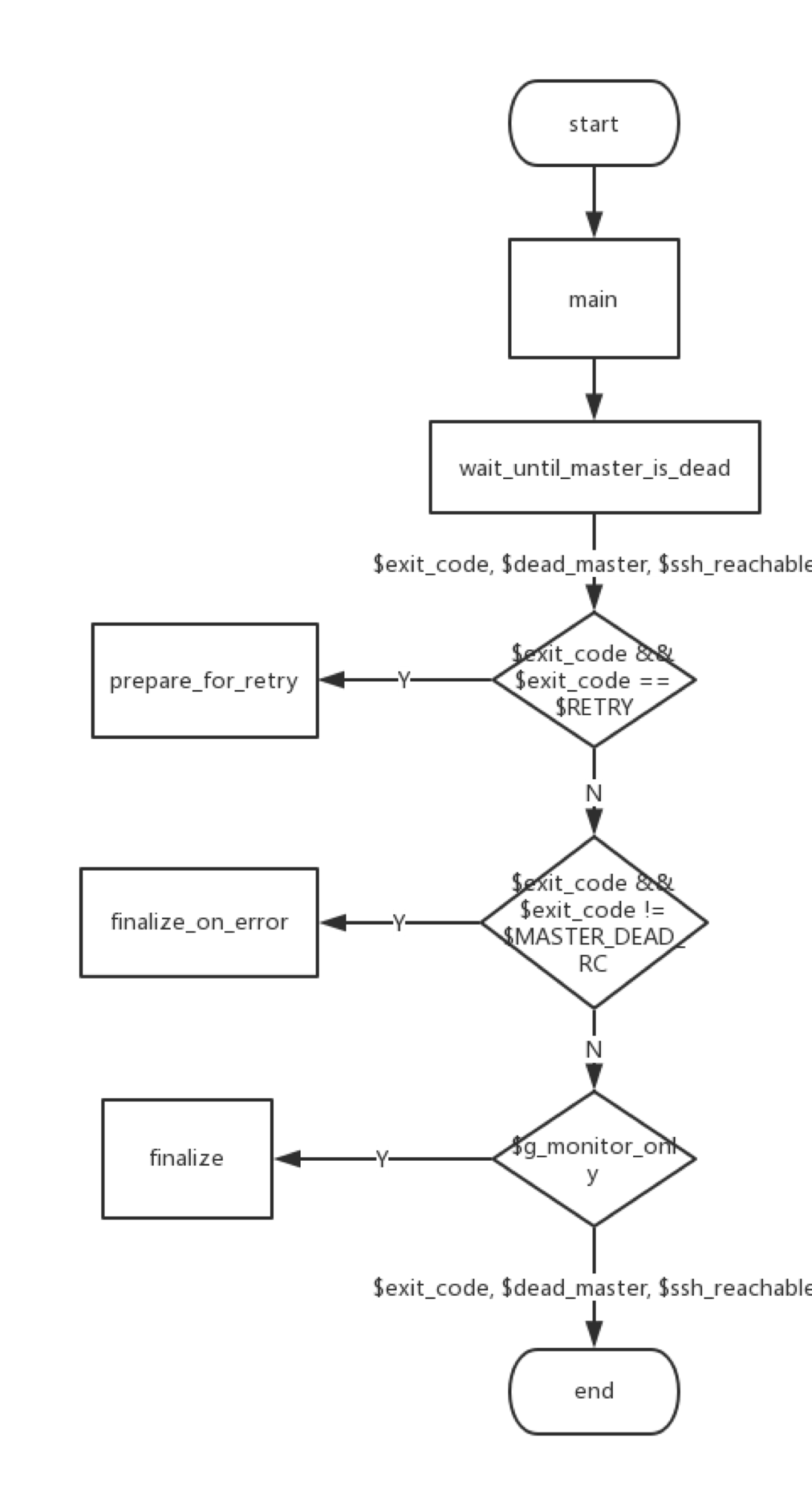
核心方法是一個死循環,不斷調用wait_until_master_is_dead方法監測主庫狀態。wait_until_master_is_dead方法的返回值中,exit_code有的值有四種,分別是0、1、20、retry。其中只有當exit_code=MHA::ManagerConst::MASTER_DEAD_RC,也就是20時,后續才會調用failover方法。
wait_until_master_is_dead方法中,核心方法是調用wait_until_master_is_unreachable方法并處理其返回值。邏輯關系如下:
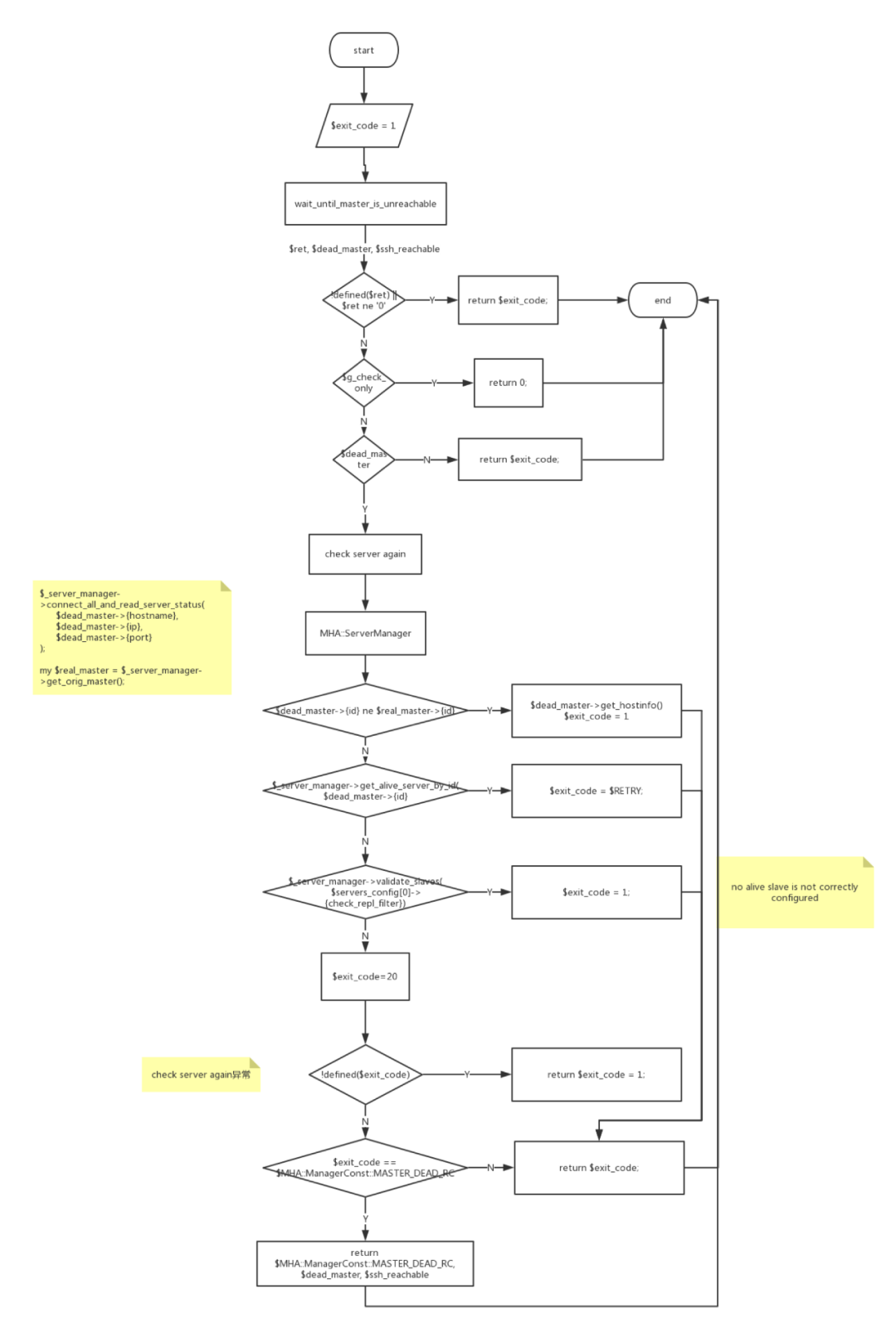
拿到wait_until_master_is_unreachable的返回值后,會再次根據配置文件探活,確認主庫連接失敗后,根據配置文件檢測slave狀態和數量,有合適新主庫后,exit_code返回20,否則返回0或者1。
wait_until_master_is_unreachable方法的返回值有三個,分別是ret、dead_master和ssh_reachable。該方法的邏輯如下:
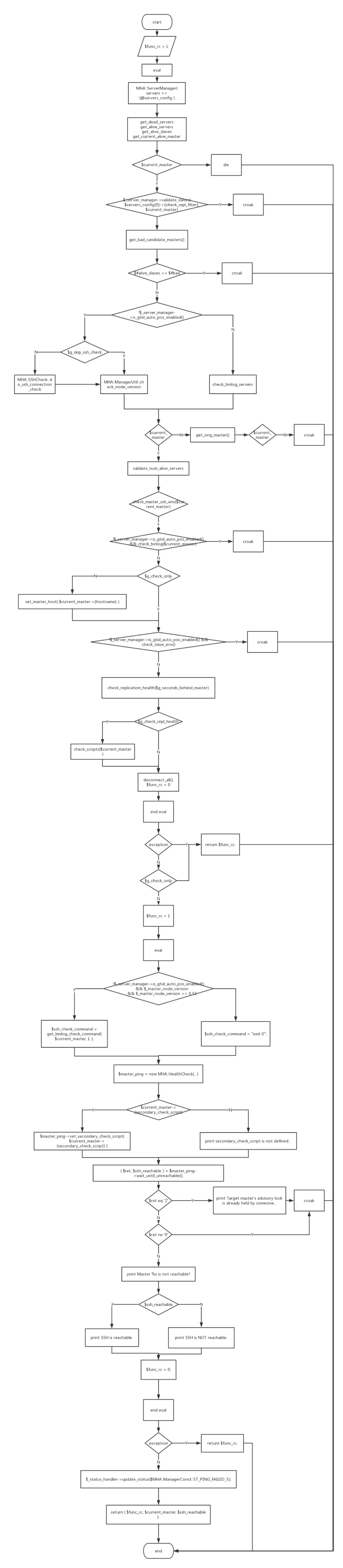
wait_until_master_is_unreachable調用MHA::ServerManager對主庫進行實時檢測,包括deadservers、aliveservers、aliveslaves等。如果啟用GTID,則檢查binlog server,否則進行ssh和slave版本檢測。
后續使用MHA::HealthCheck對主庫進行ping檢查。檢查確認主庫的確不可達后,返回func_rc, current_master, ssh_reachable。
4
總結
MHA 由日本 DeNA 公司 youshimaton 開發,他認為在 GTID 環境下MHA 存在的價值不大,MHA 最近一次發版是 2018 年。現如今使用 MySQL 已離不開 GTID ,無論是從功能、性能角度,還是從維護角度,GTID 能具備更優異的表現。但是無論是什么技術,他的核心原理都是可以自動將最新數據的Slave提升為新的 Master,然后將所有其他的Slave重新指向新的Master。整個故障轉移過程對應用程序是完全透明的,因此MHA的時代是值得被大家了解和記憶的。
-
數據庫
+關注
關注
7文章
3794瀏覽量
64364 -
MySQL
+關注
關注
1文章
804瀏覽量
26538 -
存儲數據
+關注
關注
0文章
88瀏覽量
14100
發布評論請先 登錄
相關推薦
MySQL數據遷移的流程介紹
MySQL還能跟上PostgreSQL的步伐嗎

MySQL編碼機制原理
適用于MySQL的dbForge架構比較
Jtti:MySQL初始化操作如何設置root密碼

華納云:如何修改MySQL的默認端口

MySQL的整體邏輯架構
MySQL忘記root密碼解決方案
查詢SQL在mysql內部是如何執行?





 工商網監
工商網監
評論