 異構數據庫排序一致性填坑教程
異構數據庫排序一致性填坑教程
不同數據庫對于字符值的排序規則各不相同,要達成在不同數據庫上對于同樣數據集執行查詢語句的輸出結果順序一致性目標,則必須進行相應的設置或改寫,本文通過對五種數據庫的分析,對該問題進行了較為深入的分析。
01
概述.
在異構數據庫之間進行數據遷移之后,為驗證數據一致性,就需要比對源庫和目標庫的同表數據是否一致。
為了提高比對效率,一般而言會將數據排序并抽取出來后進行比對。
在實際過程中發現,指定了ORDER BY的同樣兩條SQL語句在不同數據庫執行后,輸出結果集的順序經常會不同,本文關注該問題的產生并提供了相應的解決方案。
02
數據準備.
本文涉及的數據庫為:
- Oracle
- MySQL
- Postgres
- Gauss(華為open Gauss)
- GoldiLocks(科藍)
所有的數據庫均采用UTF8編碼,且MySQL數據庫不區分大小寫建表。
在各數據庫中創建一張測試表LEXSORT,該表僅有一個字符列NAME,具體語句如下:
CREATE TABLE LEXSORT ( NAME VARCHAR(10) );
然后將以下數據插入該表中:
INSERT INTO LEXSORT VALUES ('0');
INSERT INTO LEXSORT VALUES ('9');
INSERT INTO LEXSORT VALUES ('a');
INSERT INTO LEXSORT VALUES ('z');
INSERT INTO LEXSORT VALUES ('A');
INSERT INTO LEXSORT VALUES ('Z');
INSERT INTO LEXSORT VALUES ('_');
INSERT INTO LEXSORT VALUES ('~');
INSERT INTO LEXSORT VALUES (NULL);
03
查詢結果.
在各個數據庫中執行如下查詢語句:
SELECT * FROM LEXSORT ORDER BY NAME;
其輸出結果見下圖:
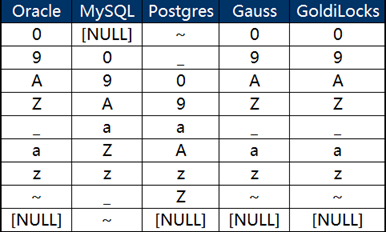
通過上面的結果可以發現:
其一,Oracle、Gauss和GoldiLocks的缺省排序保持一致,而與MYSQL和Postgres的各不相同。
其二,數據排序的不同體現在兩個方面上
- NULL值與非NULL字符值之間的順序
- 非NULL字符值之間的順序
那么,這背后的機制是什么呢?又該如何解決呢?
04
數據庫分析.
其實,產生這一現象的原因是各數據庫的缺省排序規則各不相同所致。要解決這一問題,就需要從各數據庫自身出發,了解其排序規則,并分別進行設置,才可能達到在不同數據庫之間的一致性。
具體如何操作,后文將為您逐一展開。
Oracle數據庫
**Oracle數據庫提供了控制排序規則的參數,可以在系統級別和會話級別分別進行設置,一般而言,為了不影響其他應用,我們在會話級別進行設置即可。
**
1. NULL值的排序規則
Oracle支持在ORDER BY字句的每個字段上進行控制。可以指定為NULLS FIRST或NULLS LAST,即NULL值排在前面還是后面,缺省為NULLS LAST,即NULL值排在其它非NULL值的后面。
Postgres、Gauss和GoldiLocks也采用了同樣的處理,后文不再贅述。
2. 非NULL值的排序規則
Oracle提供了控制參數NLS_SORT來指定排序規則,缺省的排序規則為BINARY,即按照字符串中每個字符的編碼值進行排序,另一個常用排序規則為BINARY_CI,即按照二進制值進行排序,同時字母(A-Z,a-z)不區分大小寫。
根據以上規則重新修改一下SQL語句或會話設置:
ALTER SESSION SET NLS_SORT=BINARY;
ALTER SESSION SET NLS_SORT=BINARY_CI;
SELECT * FROM LEXSORT ORDER BY NAME NULLS FIRST;
此時不同組合后查詢的輸出結果見下圖:
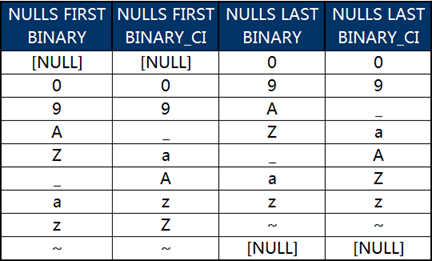
在上圖中我們會注意到,不區分大小寫排序時字符“_”的位置似乎有些“飄忽不定”。為了解決這個問題,我們把這些字符對應的編碼數值出來看一下:

根據編碼值就會發現,“飄忽不定”的符號“_”的編碼正好位于大寫字母和小寫字母之間,與它存在同樣情況的還有5個字符。這就意味著,Oracle在采用BINARY_CI方式忽略字母大小寫排序時,會自動將所有的字母視為了小寫字母。
MySQL數據庫
MySQL數據庫在排序控制方面較弱,首先對于NULL值,MySQL自動視為NULLS FIRST,在ORDER BY字句中無相應的控制選項。
再看一下字母的排序,MySQL在建表時可以指定區分大小寫或不區分大小寫,一旦指定無法再修改,除非重新建表。
因此對于區分大小寫的庫,其排序規則會與Oracle的BINARY規則保持一致。
那么不區分大小寫的呢?其實在前面的截圖中已經有了體現,不過為了清晰起見,我們將Oracle設置為NULL FIRST和不區分大小寫,單獨拿出來再進行一下比較:
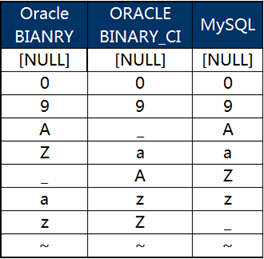
此時我們會發現Oracle和MySQL的排序依然不一致!發生問題的依然是那個“飄忽不定”的“_”。
顯然,稍加分析后我們就會知道,在不區分大小寫的情形下,MySQL自動將所有字母視為了大寫字母進行排序,正是因為這個區別,位于大寫和小寫字母之間的那六個字符又一次給我們惹了麻煩。
這樣,不區分大小寫建表的MySQL數據庫與Oracle數據庫的排序一致性就不存在完美的解決方案!
Postgres數據庫
Postgres數據庫的缺省排序對我來說一直是個迷……

上圖中,符號排在最前面,而“~”的編碼卻比“_”大,相當于降序;然后是數字和字母,而此時又是升序。鑒于本人對Postgres的研究有限,此處暫不作深究,只專注如何解決排序一致性問題。
Postgres提供了collate語句用以調整排序規則。將排序規則設置為C(必須用雙引號括起來且為大寫字母)或ucs_basic(如果用雙引號括起則必須為小寫)則代表按照字符編碼排序,此時會區分大小寫。
不區分大小寫且又要按照編碼值進行排序,目前暫未找到合適的方法。
需要注意指定collate和null first時的SQL語句順序問題,當二者都需指定時示例語句如下,具體的輸出結果大家可以自行測試:
SELECT * FROM LEXSORT ORDER BY NAME COLLATE ucs_basic NULLS FIRST;
Gauss數據庫
大家都知道Open Gauss實際上是基于Postgres進行的定制,它在增加部分功能的同時也刪減了部分Postgres的功能。不過對于ORDER BY子句,Gauss依然保留了Postgres的能力,也就是說collate子句同樣適用于Gauss數據庫,不過Gauss數據庫的缺省排序規則即為按照字符編碼值進行排序。
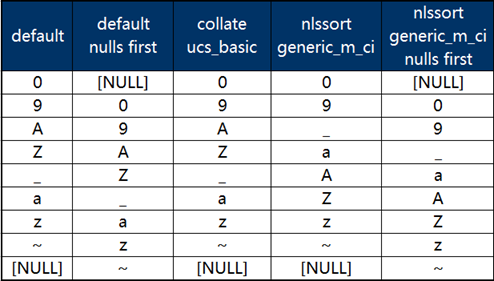
同時,Gauss數據庫提供了排序函數NLSSORT,解決了不區分大小排序的問題,此時其排序結果與Oracle保持一致。使用該函數時需指定排序規則,不區分大小寫的規則為generic_m_ci,具體SQL示例語句如下:
SELECT * FROM LEXSORT ORDER BY NLSSORT(NAME,'nls_sort=generic_m_ci');
SELECT * FROM LEXSORT ORDER BY NLSSORT(NAME,'nls_sort=generic_m_ci') NULLS FIRST;
幾種不同組合的查詢結果見下圖(未寫明null first時均為nulls last):
****GoldiLocks數據庫 ****
該數據庫除了NULLS FIRST/LAST處理與Oracle保持一致外,并沒有可以修改排序規則的參數,不過其缺省的排序規則即為按照字符編碼值進行排序。因此在排序一致性方面依然可以與Oracle、Postgres、Gauss做到很好的兼容。
05
總結.
雖然本文起源于數據比對場景,不過通過上面的分析,我們可以意識到,排序一致性問題也是異構數據庫遷移時必須考慮的問題之一。試想一下,如果不做SQL語句改造,原有的業務查詢語句在新數據庫中結果集排序可能會發生變化,進而導致后續處理結果也可能發生變化。
通過分析我們也發現,大多數數據庫的排序一致性可以通過設置會話參數或修改SQL語句等來實現保持不變,不過部分數據庫,例如本例中的MySQL,卻缺乏完美的解決方案,那么我們就必須要分析其影響并進行應對。
-
數據庫
+關注
關注
7文章
3799瀏覽量
64380 -
Oracle
+關注
關注
2文章
289瀏覽量
35129 -
數據集
+關注
關注
4文章
1208瀏覽量
24699
發布評論請先 登錄
相關推薦
如何解決數據庫與緩存一致性

一致性規劃研究
加速器一致性接口
速度不可測的異構多智能體系統一致性分析
時延異構多自主體系統的群一致性分析
優化模型的乘性偏好關系一致性改進
緩存與數據庫一致性問題如何解決
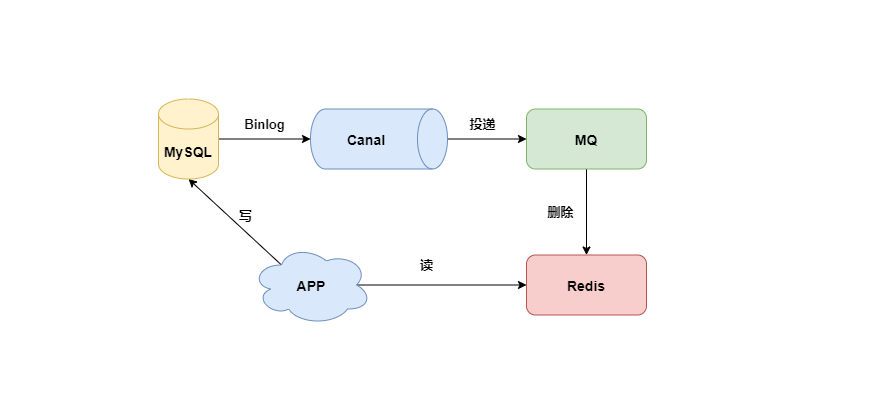
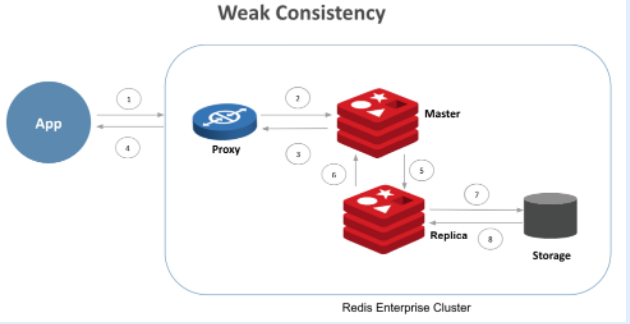
Redis緩存與Mysql如何保證一致性?

DDR一致性測試的操作步驟
深入理解數據備份的關鍵原則:應用一致性與崩潰一致性的區別

異構計算下緩存一致性的重要性





 工商網監
工商網監
評論