 深入剖析CPU的調度原理
深入剖析CPU的調度原理
前言
軟件工程師們總習慣把 OS (Operating System,操作系統)當成是一個非常值得信賴的管家,我們只管把程序托管到OS上運行,卻很少深入了解操作系統的運行原理。
確實,OS作為一個通用的軟件系統,在大多數的場景下都表現得足夠的優秀。但仍會有一些特殊的場景,需要我們對OS進行各項調優,才能讓業務系統更高效地完成任務。
這就要求我們必須深入了解OS的原理,不僅僅只會使喚這個管家,還能懂得如何讓管家做得更好 。
OS是一個非常龐大的軟件系統,本文主要探索其中的冰山一角: CPU的調度原理 。
說起CPU的調度原理,很多人的第一反應是基于時間片的調度,也即每個進程都有占用CPU運行的時間片,時間片用完之后,就讓出CPU給其他進程。
至于OS是如何判斷一個時間片是否用完的、如何切換到另一個進程等等更深層的原理,了解的人似乎并不多。
其實,基于時間片的調度只是眾多CPU的調度算法的一類,本文將會從最基礎的調度算法說起,逐個分析各種主流調度算法的原理,帶大家一起探索CPU調度的奧秘。
CPU的上下文切換
在探索CPU調度原理之前,我們先了解一下CPU的上下文切換,它是CPU調度的基礎。
如今的OS幾乎都支持"同時"運行遠大于CPU數量的任務,OS會將CPU輪流分配給它們使用。
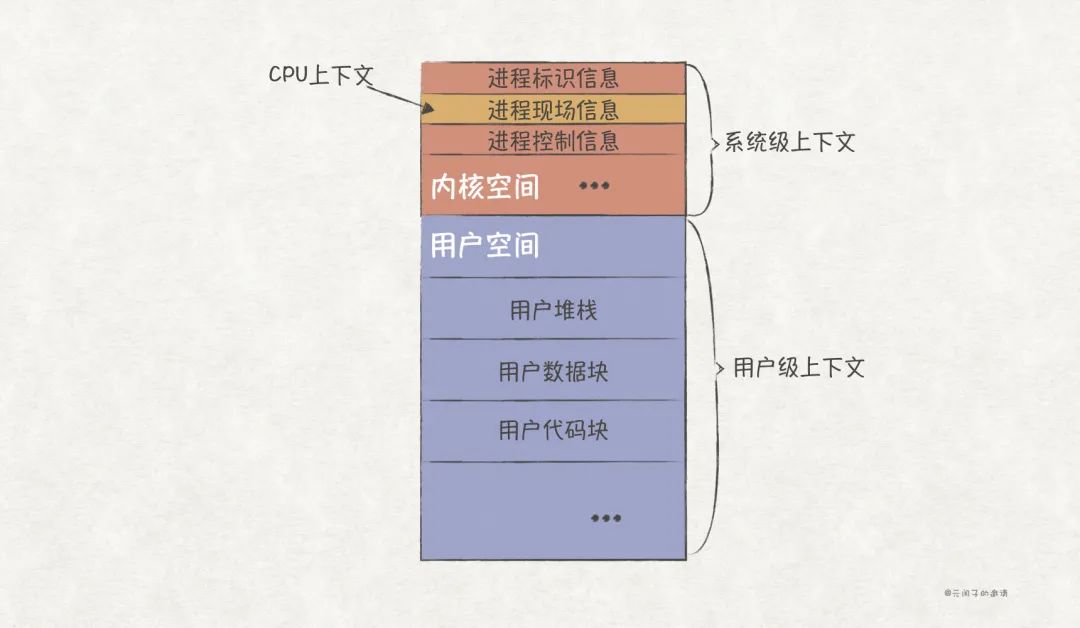
這就要求OS必須知道從哪里加載任務,以及加載后從哪里開始運行,而這些信息都保存在CPU的寄存器中,其中即將執行的下一條指令的地址被保存在 程序計數器 (PC)這一特殊寄存器上。 我們將寄存器的這些信息稱為CPU的上下文,也叫硬件上下文 。
OS在切換運行任務時, 將上一任務的上下文保存下來,并將即將運行的任務的上下文加載到CPU寄存器上的這一動作,被稱為CPU上下文切換 。
CPU上下文屬于進程上下文的一部分,我們常說的進程上下文由如下兩部分組成:
- 用戶級上下文 :包含進程的運行時堆棧、數據塊、代碼塊等信息。
- 系統級上下文 :包含進程標識信息、進程現場信息(CPU上下文)、進程控制信息等信息。
這涉及到兩個問題:(1)上一任務的CPU上下文如何保存下來?(2)什么時候執行上下文切換?
問題1: 上一任務的CPU上下文如何保存下來 ?
CPU上下文會被保存在進程的 內核空間 (kernel space)上。OS在給每個進程分配虛擬內存空間時,會分配一個內核空間,這部分內存只能由內核代碼訪問。
OS在切換CPU上下文前,會先將當前CPU的通用寄存器、PC等進程現場信息保存在進程的內核空間上,待下次切換時,再取出重新裝載到CPU上,以恢復任務的運行。
問題2: 什么時候執行上下文切換 ?
OS要想進行任務上下文切換,必須占用CPU來執行切換邏輯。然而,用戶程序運行的過程中,CPU已經被用戶程序所占用,也即OS在此刻并未處于運行狀態,自然也無法執行上下文切換。針對該問題,有兩種解決策略,協作式策略與搶占式策略。
協作式策略依賴用戶程序主動讓出CPU,比如執行系統調用(System Call)或者出現除零等異常。但該策略并不靠譜,如果用戶程序沒有主動讓出CPU,甚至是惡意死循環,那么該程序將會一直占用CPU,唯一的恢復手段就是重啟系統了。
搶占式策略則依賴硬件的定時中斷機制(Timer Interrupt),OS會在初始化時向硬件注冊中斷處理回調(Interrupt Handler)。當硬件產生中斷時,硬件會將CPU的處理權交給來OS,OS就可以在中斷回調上實現CPU上下文的切換。

調度的衡量指標
對于一種CPU調度算法的好壞,一般都通過如下兩個指標來進行衡量:
- 周轉時間 (turnaround time),指從任務到達至任務完成之間的時間,即
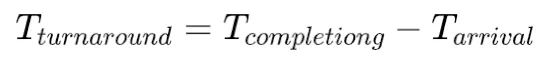
- 響應時間 (response time),指從任務到達至任務首次被調度的時間,即
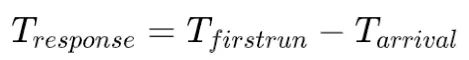
兩個指標從某種程度上是對立的,要求高的平均周轉時間,必然會降低平均響應時間。具體追求哪種指標與任務類型有關,比如程序編譯類的任務,要求周轉時間要小,盡可能快的完成編譯;用戶交互類的任務,則要求響應時間要小,避免影響用戶體驗。
工作負載假設
OS上的工作負載(也即各類任務運行的狀況)總是千變萬化的,為了更好的理解各類CPU調度算法原理,我們先對工作負載進行來如下幾種假設:
- 假設1 :所有任務都運行時長都相同。
- 假設2 :所有任務的開始時間都是相同的
- 假設3 :一旦任務開始,就會一直運行,直至任務完成。
- 假設4 :所有任務只使用CPU資源(比如不產生I/O操作)。
- 假設5 :預先知道所有任務的運行時長。
準備工作已經做好,下面我們開始進入CPU調度算法的奇妙世界。
FIFO:先進先出
FIFO(First In First Out,先進先出)調度算法以原理簡單,容易實現著稱,它 先調度首先到達的任務直至結束,然后再調度下一個任務,以此類推 。如果有多個任務同時到達,則隨機選一個。
在我們假設的工作負載狀況下,FIFO效率良好。比如有A、B、C三個任務滿足上述所有負載假設,每個任務運行時長為10s,在t=0時刻到達,那么任務調度情況是這樣的:

根據FIFO的調度原理,A、B、C分別在10、20、30時刻完成任務,平均周轉時間為20s( ),效果很好。
然而現實總是殘酷的,如果假設1被打破,比如A的運行時間變成100s,B和C的還是10s,那么調度情況是這樣的:

根據FIFO的調度原理,由于A的運行時間過長,B和C長時間得不到調度,導致平均周轉時間惡化為110( )。
因此, FIFO調度策略在任務運行時間差異較大的場景下,容易出現任務餓死的問題 !
針對這個問題,如果運行時間較短的B和C先被調度,問題就可以解決了,這正是SJF調度算法的思想。
SJF:最短任務優先
SJF(Shortest Job First,最短任務優先) 從相同到達時間的多個任務中選取運行時長最短的一個任務進行調度,接著再調度第二短的任務,以此類推 。
針對上一節的工作負載,使用SJF進行調度的情況如下,周轉時間變成了50s( ),相比FIFO的110s,有了2倍多的提升。

讓我們繼續打破 假設2 ,A在t=0時刻,B和C則在t=10時刻到達,那么調度情況會變成這樣:

因為任務B和C比A后到,它們不得不一直等待A運行結束后才有機會調度,即使A需要長時間運行。周轉時間惡化為103.33s(),再次出現任務餓死的問題!
STCF:最短時間完成優先
為了解決SJF的任務餓死問題,我們需要打破 假設3 ,也即任務在運行過程中是允許被打斷的。如果B和C在到達時就立即被調度,問題就解決了。
這屬于搶占式調度,原理就是CPU上下文切換一節提到的,在中斷定時器到達之后,OS完成任務A和B的上下文切換。
我們在協作式調度的SJF算法的基礎上,加上搶占式調度算法,就演變成了STCF算法(Shortest Time-to-Completion First,最短時間完成優先),調度原理是 當運行時長較短的任務到達時,中斷當前的任務,優先調度運行時長較短的任務 。
使用STCF算法對該工作負載進行調度的情況如下,周轉時間優化為50s(),再次解決了任務餓死問題!

到目前為止,我們只關心了周轉時間這一衡量指標,那么FIFO、SJF和STCF調度算法的響應時間又是多長呢?
不妨假設A、B、C三個任務都在t=0時刻到達,運行時長都是5s,那么這三個算法的調度情況如下,平均響應時長為5s():

更糟糕的是,隨著任務運行時長的增長,平均響應時長也隨之增長,這對于交互類任務來說將會是災難性的,嚴重影響用戶體驗。
該問題的根源在于,當任務都同時到達且運行時長相同時,最后一個任務必須等待其他任務全部完成之后才開始調度。
為了優化響應時間,我們熟悉的基于時間片的調度出現了。
RR:基于時間片的輪詢調度
RR(Round Robin,輪訓)算法給每個任務分配一個時間片,當任務的時間片用完之后,調度器會中斷當前任務,切換到下一個任務,以此類推 。
需要注意的是,時間片的長度設置必須是中斷定時器的整數倍,比如中斷定時器時長為2ms,那么任務的時間片可以設置為2ms、4ms、6ms ... 否則即使任務的時間片用完之后,定時中斷沒發生,OS也無法切換任務。
現在,使用RR進行調度,給A、B、C分配一個1s的時間片,那么調度情況如下,平均響應時長為1s():

從RR的調度原理可以發現,把時間片設置得越小,平均響應時間也越小。但隨著時間片的變小,任務切換的次數也隨之上升,也就是上下文切換的消耗會變大。
因此,時間片大小的設置是一個trade-off的過程,不能一味追求響應時間而忽略CPU上下文切換帶來的消耗。
CPU上下文切換的消耗,不只是保存和恢復寄存器所帶來的消耗。程序在運行過程中,會逐漸在CPU各級緩存、TLB、分支預測器等硬件上建立屬于自己的緩存數據。當任務被切換后,就意味著又得重來一遍緩存預熱,這會帶來巨大的消耗。
另外,RR調度算法的周轉時間為14s(),相比于FIFO、SJF和STCF的10s()差了不少。
這也驗證了之前所說的,周轉時間和響應時間在某種程度上是對立的,如果想要優化周轉時間,建議使用SJF和STCF;如果想要優化響應時間,則建議使用RR。
I/O操作對調度的影響
到目前為止,我們并未考慮任何的I/O操作。我們知道,當觸發I/O操作時,進程并不會占用CPU,而是阻塞等待I/O操作的完成。
現在讓我們打破 假設4 ,考慮任務A和B都在t=0時刻到達,運行時長都是50ms,但A每隔10ms執行一次阻塞10ms的I/O操作,而B沒有I/O。
如果使用STCF進行調度,調度的情況是這樣的:

從上圖看出,任務A和B的調度總時長達到了140ms,比實際A和B運行時長總和100ms要大。而且A阻塞在I/O操作期間,調度器并沒有切換到B,導致了CPU的空轉!
要解決該問題,只需使用RR的調度算法,給任務A和B分配10ms的時間片,這樣當A阻塞在I/O操作時,就可以調度B,而B用完時間片后,恰好A也從I/O阻塞中返回,以此類推,調度總時長優化至100ms。

該調度方案是建立在假設5之上的,也即要求調度器預先知道A和B的運行時長、I/O操作時間長等信息,才能如此充分地利用CPU。
然而,實際的情況遠比這復雜,I/O阻塞時長不會每次都一樣,調度器也無法準確知道A和B的運行信息。當假設5也被打破時,調度器又該如何實現才能最大程度保證CPU利用率,以及調度的合理性呢?
接下來,我們將介紹一個能夠在所有工作負載假設被打破的情況下依然表現良好,被許多現代操作系統采用的CPU調度算法,MLFQ。
MLFQ:多級反饋隊列
MLFQ(Multi-Level Feedback Queue,多級反饋隊列)調度算法的目標如下:
- 優化周轉時間。
- 降低交互類任務的響應時間,提升用戶體驗。
從前面分析我們知道,要優化周轉時間,可以優先調度運行時長短的任務(像SJF和STCF的做法);要優化響應時間,則采用類似RR的基于時間片的調度。然而,這兩個目標看起來是矛盾的,要降低響應時間,必然會增加周轉時間。
那么對MLFQ來說,就需要解決如下兩個問題:
- 在不預先清楚任務的運行信息(包括運行時長、I/O操作等)的前提下,如何權衡周轉時間和響應時間?
- 如何從歷史調度中學習,以便未來做出更好的決策?
劃分任務的優先級
MLFQ與前文介紹的幾種調度算法最顯著的特點就是新增了優先級隊列存放不同優先級的任務,并定下了如下兩個規則:
- 規則1 :如果Priority(A) > Priority(B),則調度A
- 規則2 :如果Priority(A) = Priority(B),則按照RR算法調度A和B

優先級的變化
MLFQ必須考慮改變任務的優先級,否則根據 規則1 和 規則2 ,對于上圖中的任務C,在A和B運行結束之前,C都不會獲得運行的機會,導致C的響應時間很長。因此,可以定下了如下幾個優先級變化規則:
- 規則3 :當一個新的任務到達時,將它放到最高優先級隊列中
- 規則4a :如果任務A運行了一個時間片都沒有主動讓出CPU(比如I/O操作),則優先級降低一級
- 規則4b :如果任務A在時間片用完之前,有主動讓出CPU,則優先級保持不變
規則3主要考慮到讓新加入的任務都能得到調度機會,避免出現任務餓死的問題
規則4a和4b主要考慮到,交互類任務大都是short-running的,并且會頻繁讓出CPU,因此為了保證響應時間,需要保持現有的優先級;而CPU密集型任務,往往不會太關注響應時間,因此可以降低優先級。
按照上述規則,當一個long-running任務A到達時,調度情況是這樣的:

如果在任務A運行到t=100時,short-time任務B到達,調度情況是這樣的:

從上述調度情況可以看出,MLFQ具備了STCF的優點,即可以優先完成short-running任務的調度,縮短了周轉時間。
如果任務A運行到t=100時,交互類任務C到達,那么調度情況是這樣的:

MLFQ會在任務處于阻塞時按照優先級選擇其他任務運行,避免CPU空轉 。因此,在上圖中,當任務C處于I/O阻塞狀態時,任務A得到了運行時間片,當任務C從I/O阻塞上返回時,A再次掛起,以此類推。
另外,因為任務C在時間片之內出現主動讓出CPU的行為,C的優先級一直保持不變,這對于交互類任務而言,有效提升了用戶體驗。
CPU密集型任務餓死問題
到目前為止,MLFQ似乎能夠同時兼顧周轉時間,以及交互類任務的響應時間,它真的完美了嗎?
考慮如下場景,任務A運行到t=100時,交互類任務C和D同時到達,那么調度情況會是這樣的:

由此可見,如果當前系統上存在很多交互類任務時,CPU密集型任務將會存在餓死的可能!
為了解決該問題,可以設立了如下規則:
- 規則5 :系統運行S時長之后,將所有任務放到最高優先級隊列上( Priority Boost )
加上該規則之后,假設設置S為50ms,那么調度情況是這樣的,餓死問題得到解決!

惡意任務問題
考慮如下一個惡意任務E,為了長時間占用CPU,任務E在時間片還剩1%時故意執行I/O操作,并很快返回。根據 規則4b ,E將會維持在原來的最高優先級隊列上,因此下次調度時仍然獲得調度優先權:

為了解決該問題,我們需要將規則4調整為如下規則:
- 規則4 :給每個優先級分配一個時間片,當任務用完該優先級的時間片后,優先級降一級
應用新的規則4后,相同的工作負載,調度情況變成了如下所述,不再出現惡意任務E占用大量CPU的問題。

到目前為止,MLFQ的基本原理已經介紹完,最后,我們總結下MLFQ最關鍵的5項規則:
- 規則1 :如果Priority(A) > Priority(B),則調度A
- 規則2 :如果Priority(A) = Priority(B),則按照RR算法調度A和B
- 規則3 :當一個新的任務到達時,將它放到最高優先級隊列中
- 規則4 :給每個優先級分配一個時間片,當任務用完該優先級的時間片后,優先級降一級
- 規則5 :系統運行S時長之后,將所有任務放到最高優先級隊列上( Priority Boost )
現在,再回到本節開始時提出的兩個問題:
1、在不預先清楚任務的運行信息(包括運行時長、I/O操作等)的前提下,MLFQ如何權衡周轉時間和響應時間 ?
在預先不清楚任務到底是long-running或short-running的情況下,MLFQ會先假設任務屬于shrot-running任務,如果假設正確,任務就會很快完成,周轉時間和響應時間都得到優化;即使假設錯誤,任務的優先級也能逐漸降低,把更多的調度機會讓給其他short-running任務。
2、MLFQ如何從歷史調度中學習,以便未來做出更好的決策 ?
MLFQ主要根據任務是否有主動讓出CPU的行為來判斷其是否是交互類任務,如果是,則維持在當前的優先級,保證該任務的調度優先權,提升交互類任務的響應性。
當然,MLFQ并非完美的調度算法,它也存在著各種問題,其中最讓人困擾的就是MLFQ各項參數的設定,比如優先級隊列的數量,時間片的長度、Priority Boost的間隔等。
這些參數并沒有完美的參考值,只能根據不同的工作負載來進行設置。
比如,我們可以將低優先級隊列上任務的時間片設置長一些,因為低優先級的任務往往是CPU密集型任務,它們不太關心響應時間,較長的時間片長能夠減少上下文切換帶來的消耗。
CFS:Linux的完全公平調度
本節我們將介紹一個平時打交道最多的調度算法,Linux系統下的CFS(Completely Fair Scheduler,完全公平調度)。與上一節介紹的MLFQ不同, CFS并非以優化周轉時間和響應時間為目標,而是希望將CPU公平地均分給每個任務 。
當然,CFS也提供了給進程設置優先級的功能,讓用戶/管理員決定哪些進程需要獲得更多的調度時間。
基本原理
大部分調度算法都是基于固定時間片來進行調度,而CFS另辟蹊徑,采用基于計數的調度方法,該技術被稱為 virtual runtime 。
CFS給每個任務都維護一個vruntime值,每當任務被調度之后,就累加它的vruntime。
比如,當任務A運行了5ms的時間片之后,則更新為vruntime += 5ms。 CFS在下次調度時,選擇vruntime值最小的任務來調度 ,比如:

那CFS應該什么時候進行任務切換呢?切換得頻繁些,任務的調度會更加的公平,但是上下文切換帶來的消耗也越大。因此,CFS給用戶提供了個可配參數sched_latency,讓用戶來決定切換的時機。
CFS將每個任務分到的時間片設置為 time_slice = sched_latency / n(n為當前的任務數) ,以確保在sched_latency周期內,各任務能夠均分CPU,保證公平性。
比如將sched_latency設置為48ms,當前有4個任務A、B、C和D,那么每個任務分到的時間片為12ms;后面C和D結束之后,A和B分到的時間片也更新為24ms:

從上述原理上看,在sched_latency 不變的情況下,隨著系統任務數的增加,每個任務分到的時間片也隨之減少,任務切換所帶來的消耗也會增大。為了避免過多的任務切換消耗,CFS提供了可配參數min_granularity來設置任務的最小時間片。
比如sched_latency設置為48ms,min_granularity設置為 6ms,那么即使當前任務數有12,每個任務數分到的時間片也是6ms,而不是4ms。
給任務分配權重
有時候,我們希望給系統中某個重要的業務進程多分配些時間片,而其他不重要的進程則少分配些時間片。但按照上一節介紹的基本原理,使用CFS調度時,每個任務都是均分CPU的,有沒有辦法可以做到這一點呢?
可以給任務分配權重,讓權重高的任務更多的CPU !
加上權重機制后,任務時間片的計算方式變成了這樣:

比如,sched_latency還是設置為48ms,現有A和B兩個任務,A的權重設置為1024,B的權重設置為3072,按照上述的公式,A的時間片是12ms,B的時間片是36ms。
從上一節可知,CFS每次選取vruntime值最小的任務來調度,而每次調度完成后,vruntime的計算規則為vruntime += runtime,因此僅僅改變時間片的計算規則不會生效,還需將vruntime的計算規則調整為:

還是前面的例子,假設A和B都沒有I/O操作,更新vruntime計算規則后,調度情況如下,任務B比任務A能夠分得更多的CPU了。

使用紅黑樹提升vruntime查找效率
CFS每次切換任務時,都會選取vruntime值最小的任務來調度,因此需要它有個數據結構來存儲各個任務及其vruntime信息。
最直觀的當然就是選取一個有序列表來存儲這些信息,列表按照vruntime排序。這樣在切換任務時,CFS只需獲取列表頭的任務即可,時間復雜度為O(1)。
比如當前有10個任務,vruntime保存為有序鏈表[1, 5, 9, 10, 14, 18, 17, 21, 22, 24],但是每次插入或刪除任務時,時間復雜度會是O(N),而且耗時隨著任務數的增多而線性增長!
為了兼顧查詢、插入、刪除的效率,CFS使用紅黑樹來保存任務和vruntime信息,這樣,查詢、插入、刪除操作的復雜度變成了log(N),并不會隨著任務數的增多而線性增長,極大提升了效率。

另外,為了提升存儲效率,CFS在紅黑樹中只保存了處于Running狀態的任務的信息。
應對I/O與休眠
每次都選取vruntime值最小的任務來調度這種策略,也會存在任務餓死的問題。考慮有A和B兩個任務,時間片為1s,起初A和B均分CPU輪流運行,在某次調度后,B進入了休眠,假設休眠了10s。
等B醒來后,就會比小10s,在接下來的10s中,B將會一直被調度,從而任務A出現了餓死現象。

為了解決該問題,CFS規定當任務從休眠或I/O中返回時,該任務的vruntime會被設置為當前紅黑樹中的最小vruntime值。上述例子,B從休眠中醒來后,會被設置為11,因此也就不會餓死任務A了。
這種做法其實也存在瑕疵,如果任務的休眠時間很短,那么它醒來后依舊是優先調度,這對于其他任務來說是不公平的。
寫在最后
本文花了很長的篇幅講解了幾種常見CPU調度算法的原理,每種算法都有各自的優缺點,并不存在一種完美的調度策略。在應用中,我們需要根據實際的工作負載,選取合適的調度算法,配置合理的調度參數,權衡周轉時間和響應時間、任務公平和切換消耗。
這些都應驗了《Fundamentals of Software Architecture》中的那句名言: Everything in software architecture is a trade-off .
本文中描述的調度算法都是基于單核處理器進行分析的,而多核處理器上的調度算法要比這復雜很多,比如需要考慮處理器之間共 享數據同步 、緩存親和性等,但本質原理依然離不開本文所描述的幾種基礎調度算法。
-
cpu
+關注
關注
68文章
10882瀏覽量
212229 -
OS
+關注
關注
0文章
91瀏覽量
34778 -
軟件系統
+關注
關注
0文章
63瀏覽量
9511
發布評論請先 登錄
相關推薦
STM32 單片機C語言課程3-C語言“函數”深入剖析
STM32 單片機C語言課程4-C語言預處理深入剖析1
STM32 單片機C語言課程5-C語言預處理深入剖析2
阻抗性能深入剖析
ITIL 3.0深入剖析
世界OLED技術產品最新發展深入剖析
Linux之CPU調度策略和CPU親和性






 工商網監
工商網監
評論