


編者按:不確定環境下的自動駕駛的自主決策源于對當前環境的準確判斷,從根本上來說,環境感知技術是實現自動駕駛需要解決的首要問題。目前基于激光雷達與相機融合的目標感知在高級別自動駕駛汽車的環境感知領域中非常流行,依據傳感器到融合中心的數據處理程度從高到低可以劃分為后融合、深度融合和前融合,后融合在提升感知精度方面能力有限,前融合對硬件帶寬和算力要求高,因而深度融合成為實現準確目標檢測的主流趨勢。深度融合的難點之一在于如何解決兩種模態經過數據增強后的特征對齊問題,基于此本文提出了一種通用多模態融合3D目標檢測模型DeepFusion,引入了兩種新技術InverseAug和LearnableAlign,能夠作為插件,應用于現有的單激光雷達3D目標檢測方法中,在Waymo數據集上驗證了所提方法的有效性和魯棒性。
摘要:激光雷達和相機是為自動駕駛中的3D目標檢測提供互補信息的關鍵傳感器。流行的多模態方法[34,36]只是簡單地用相機特征來裝飾原始激光雷達點云,并將其直接輸入現有的3D目標檢測模型,但我們的研究表明,將相機特征與激光雷達深度特征而不是原始點融合,可以帶來更好的性能。然而,由于這些特征經常被增廣和聚合,融合中的一個關鍵挑戰是如何有效地對齊來自兩種模態的轉換后的特征。在本文中,我們提出了兩種新技術:InverseAug,其反轉與幾何相關的數據增強(例如:旋轉),以實現激光雷達點云與圖像像素之間的精確幾何對齊;LearnableAlign,其在融合期間利用交叉注意力動態捕獲圖像與激光雷達特征之間的相關性。基于InverseAug和LearnableAlign,我們開發了名為DeepFusion的通用多模態3D檢測模型,該模型比以前的方法更準確。例如,DeepFusion分別提高了PointPillars、CenterPoint和3D-MAN行人檢測基準為6.7、8.9和6.2 LEVEL_2 APH。值得注意的是,我們的模型在Waymo Open Dataset上實現了最先進(SOTA)的性能,并對輸入損壞和分布外數據顯示出強大的模型魯棒性。
Ⅰ。 引言
激光雷達和相機是用于自動駕駛的兩種互補傳感器。對于3D目標檢測,激光雷達提供低分辨率形狀和深度信息,而相機提供高分辨率形狀和紋理信息。雖然人們期望兩個傳感器的組合提供最好的3D目標檢測器,但事實證明大多數最先進(SOTA)的3D目標檢測僅使用激光雷達作為輸入(Waymo挑戰排行榜,于2021年10月14日訪問)。這表明如何有效地融合來自這兩個傳感器的信息仍然具有挑戰性。在本文中,我們力求為這個問題提供一個通用的、有效的解決方案。
現有的激光雷達和相機融合大致遵循兩種方法(圖1):它們要么在早期階段融合特征,例如通過使用相應的相機特征裝飾激光雷達點云中的點[34,36],要么使用中期融合,在特征提取之后組合特征[13,17]。兩種方法的最大挑戰之一是找出激光雷達和相機特征之間的對應關系。為了解決這個問題,我們提出了兩種方法:InverseAug 和LearnableAlign 以實現有效的中級融合。InverseAug反轉與幾何相關的數據增強(例如,RandomRotation [46]),然后使用原始相機和激光雷達參數來關聯兩種模態。LearnableAlign 利用交叉注意力動態學習激光雷達特征與其相應的相機特征之間的相關性。這兩種技術都是簡單、通用的和有效的。基于主流的3D點云檢測框架,例如PointPillars [16]和CenterPoint [44],InverseAug和LearnableAlign有助于相機圖像與的激光雷達點云有效對齊,且具有最低限度的計算成本(即僅一個交叉注意力層)。當融合對齊的多模態特征時,相機信息具有更高的分辨率,能顯著提高模型的識別和定位能力。這些優點對于遠距離物體檢測特別有益。
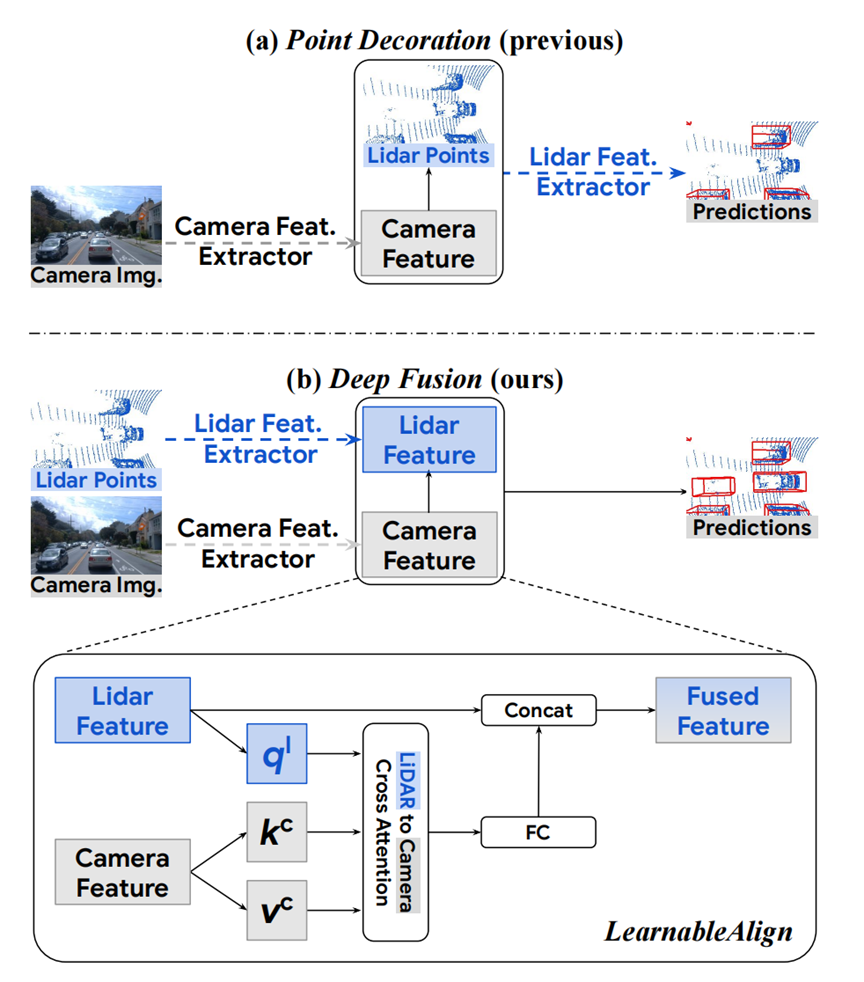
圖1 我們的方法在深度特征級上融合兩種模態,而以前的SOTA方法(例如PointPainting[34]和PointAugmenting[36])在輸入層用相機特征來裝飾激光雷達點云。為了解決深度特征融合的模態對齊問題(參見第1節),我們提出了兩種技術:InverseAug(參見圖2和3)和LearnableAlign,這是基于交叉注意力的特征級對齊技術。
我們開發了一種稱為DeepFusion的多模態3D檢測模型,其優勢如下:(1)可以端到端地訓練;(2)能與許多現有的基于體素的3D檢測方法兼容的通用模塊。DeepFusion作為插件,可輕松應用于大多數基于體素的3D檢測方法,如PointPillars [16]和CenterPoint [44]。
我們的大量實驗表明,(1)有效的深度特征對齊是多模態3D目標檢測的關鍵;(2)通過我們提出的InverseAug和LearnableAlign改進對齊質量,DeepFusion能顯著地提高了檢測精度;(3)與單模態基準相比,DeepFusion對輸入損壞和分布外數據更魯棒。
在Waymo Open Dataset上,DeepFusion分別提高了幾種主流的3D檢測模型的精度,如PointPillars [16]、CenterPoints [44]和3D-MAN [43]分別提高了6.7、8.9和6.2 LEVEL_2 APH。我們在Waymo Open Dataset上獲得了SOTA的結果,即DeepFusion在驗證集上比PointAugmenting [36](先前的最佳多模態方法)提高了7.4行人LEVEL_2 APH。結果表明,我們的方法能夠有效地將激光雷達和相機模態結合起來,其中最大的改進在于對遠距離目標的識別和定位。
我們的貢獻可以歸納為三個方面:
? 據我們所知,我們是第一個系統地研究深度特征對齊對多模態3D目標檢測的影響;
? 通過 InverseAug 和LearnableAlign 實現深度特征對齊,從而實現精確、魯棒的3D目標檢測器;
? 我們提出的模型DeepFusion在Waymo Open Dataset上實現了SOTA的性能。
Ⅱ。相關工作
點云3D目標檢測。激光雷達點云通常表現為無序的集合,許多3D目標檢測方法傾向于直接處理這些原始的無序點。PointNet [25]和PointNet++ [26]是直接將神經網絡應用于點云的早期開創性工作。隨后,[22、24、31、42]還學習了類似PointNet[25]層的特征。激光雷達點云也可以表示為密集的距離圖像,其中每個像素包含額外的深度信息。[1,18]直接在距離圖像上工作以預測3D邊界框。
另一種3D目標檢測方法將激光雷達點云轉換為體素或垂直柱,從而出現兩種更常用的3D目標檢測方法:基于體素和基于垂直柱的方法。VoxelNet [46]提出了一種基于體素的方法,該方法將點云離散化為3D網格,每個子空間稱為體素。然后可以將密集3D卷積網絡應用于該網格以學習檢測特征。SECOND [40]建立在VoxelNet之上,并提出使用稀疏3D卷積來提高效率。由于3D體素的處理通常很耗時,PointPillars [16]和PIXOR [41]進一步將3D體素簡化為鳥瞰2D垂直柱,其中具有相同z軸的所有體素被折疊成單個垂直柱。然后,可以利用現有的2D卷積網絡來處理這些2D垂直柱以產生鳥瞰圖邊界框。由于2D垂直柱通常易于且快速處理,因此最近的許多3D目標檢測方法[34、38、43、44]建立在PointPillars之上。在本文中,我們還選擇了PointPillar作為處理激光雷達點云的基準方法。
激光雷達和相機融合。與依賴激光雷達點云不同,單目檢測方法直接從2D圖像預測3D盒子[3,15,27]。這些方法的關鍵挑戰是2D圖像不具有深度信息,因此大多數單目檢測需要隱式或顯式地預測每個2D圖像像素的深度,這通常是另一個非常困難的任務。近來,存在組合激光雷達和相機數據以改進3D檢測的趨勢。一些方法[24,39]首先檢測2D圖像中的目標,然后使用該信息來進一步處理點云。先前的工作[4,14]也使用兩階段框架來執行以目標為中心的模態融合。與這些方法相比,我們的方法更容易插入大多數現有的基于體素的3D目標檢測方法。
點裝飾融合。PointPainting[34]提出用相機圖像的語義分數來增強每個激光雷達點,這些圖像是利用預先訓練的語義來提取的。PointAugmenting [36]指出了語義分數的局限性,并提出利用相機圖像的2D目標檢測網絡提取的深度特征增強激光雷達點云。如圖1(a)所示,這些方法依賴于預訓練模型(例如,2D檢測或分割模型)從相機圖像中提取特征,用于裝飾原始點云,然后送入激光雷達特征體素化網絡構建鳥瞰偽圖像。
中級融合。Deep Continuous Fusion [17]、EPNet [13]和4D-Net [23]試圖通過在2D和3D backbones之間共享信息來融合兩種模態。然而,相機與激光雷達特征之間的有效對齊機制是這些工作中的一個重要遺漏,這在我們的實驗中被證實是構建高效的端到端多模態3D目標檢測的關鍵。即使知道有效對齊的重要性,我們也指出,由于以下原因,這樣做具有挑戰性。第一,為了在現有基準上實現最佳性能,如Waymo Open Dataset,在融合階段之前,對激光雷達點云和相機圖像應用了各種數據增強策略。例如,沿z軸3D全局旋轉的RandomRotation[46]通常應用于激光雷達點云,但不適用于相機圖像,這使得后續特征對齊變得困難。第二,由于多個激光雷達點被聚集到場景中的同一3D立方體中,即體素,所以一個體素對應于多個相機特征,并且這些相機特征對于3D目標檢測并不同等重要。
Ⅲ。 DeepFusion方法
在3.1節中,我們首先介紹了我們的深度特征融合流程。然后,我們進行了一系列初步實驗,定量地說明了3.2節中對齊對深度特征融合的重要性。最后,在3.3節中,我們提出了兩種改進對齊質量的方法:InverseAug和LearnableAlign。
3.1. 深度特征融合流程
如圖1(a)所示,先前的方法,例如PointPainting [34]和PointAugmenting [36],通常使用額外訓練好的檢測或分割模型作為相機特征提取器。例如,PointPainting使用Deeplabv3+1生成每像素分割標簽作為相機特征[34]。然后,用提取的相機特征來裝飾原始激光雷達點云。最后,將相機特征裝飾的激光雷達點云饋送到3D點云目標檢測框架中。
由于以下原因,上述流程是可改進的。首先,將相機特征輸入到專門為處理點云數據而設計的幾個模塊中。例如,如果采用PointPillars[16]作為3D檢測框架,則相機特征需要與原始點云一起進行體素化,以構建鳥瞰圖偽圖像。然而,體素化模塊不是設計用于處理相機信息。其次,相機特征從其他獨立任務(即2D檢測或分割)中學習,這可能導致:(1)域間隙,(2)需要額外標注,(3)引入額外計算,以及更重要的(4)非最優特征提取,因為這些特征是以啟發式選擇而不是以端到端的方式學習的。
為了解決上述兩個問題,我們提出了一種深度特征融合流程。為了解決第一個問題,我們融合了相機和激光雷達的深度特征,而不是在輸入水平上裝飾原始激光雷達點云,以便相機信息不通過為點云設計的模塊。對于第二個問題,我們使用卷積層來提取相機特征并以端到端的方式將這些卷積層與網絡的其它組件一起訓練。總之,我們提出的深特征融合流程如圖1(b)所示:LIDAR點云被輸入到現有的LIDAR特征提取器(例如,來自PointPillars [16]的Pillar特征提取網絡),以獲得激光雷達特征(例如,來自PointPillars [16]的偽圖像);相機圖像被輸入到2D圖像特征提取器(例如,ResNet [10]),以獲得相機特征;然后,將相機特征融合到激光雷達特征;最后,由所選LIDAR目標檢測框架的剩余組件(例如,Pointpillars的Backbone和檢測頭[16])獲得檢測結果。
與先前的設計相比,我們的方法具有兩大優點:(1)豐富上下文信息的高分辨率相機特征不會被錯誤地體素化,并且不需要從透視圖轉換為鳥瞰圖;(2)緩解了域間隙和額外標注的問題,并且由于端到端訓練,可以獲得更好的相機特征。然而,缺點也是顯而易見的:與輸入級裝飾相比,在深度特征級上將相機特征與激光雷達信息對齊變得不那么簡單。例如,兩種模態的異構數據增強導致的不準確對齊可能對融合階段構成潛在挑戰。在第3.2節中,我們驗證了特征錯位確實會損害檢測模型,并在第3.3節中提供我們的解決方案。
3.2. 對齊質量的影響
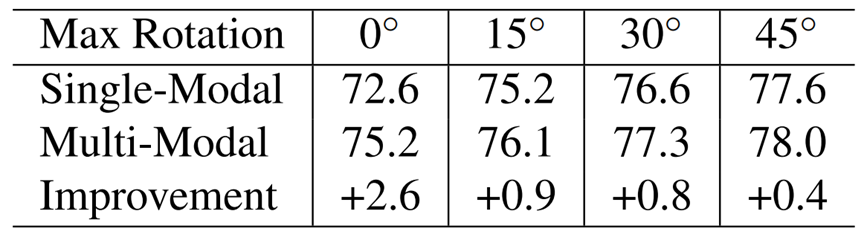
為了定量評估對齊對深度特征融合的影響,我們禁用了所有其他數據增強,但在訓練期間僅將RandomRotation [46]的數據增強方式添加到深層融合流程的激光雷達點云中。有關實驗設置的更多詳細信息,請參見附錄材料。因為我們只增廣激光雷達點云,但保持相機圖像不變,越強的幾何相關的數據增強會導致越差的特征對齊。如表1所示,多模態融合的優勢隨著旋轉角度的增大而減少。例如,當不施加增強時(最大旋轉=0°),改善最顯著(+2.6 AP);當最大旋轉為45°時,只有+0.4 AP增益。基于這些觀測,我們得出結論,對齊對于深度特征融合是關鍵的,如果對齊不精確,則來自相機輸入的益處變得微不足道。
表1 多模態融合的性能增益隨著RandomRotation[46]的幅度增加而減小,這表明精確對齊的重要性(此處不使用InverseAug)。在Waymo Open Dataset的行人檢測任務中,顯示了從單模態到多模態的LEVEL_1 AP改進。更多詳情見第3.2節。
3.3. 提高對齊質量
鑒于深度特征對齊的重要性,我們提出了兩種方法,InverseAug和LearnableAlign,以有效地對齊兩種模態的深度特征。
InverseAug為了在現有基準上實現最佳性能,大多數方法都需要強大的數據增廣,因為訓練通常會陷入過擬合的情況。數據增強的重要性可從表1中看出,數據增廣可以使精度提升5.0,適用于單模態。此外,Cheng等人[5]還提出數據增廣對于訓練3D目標檢測模型的重要性。然而,數據增廣的必要性在我們的DeepFusion流程中具有重要的挑戰。具體而言,通常使用不同的增廣策略(例如,針對3D點云沿z軸旋轉與針對2D圖像的隨機翻轉相結合)來增強來自兩種模態的數據,這使得對齊具有挑戰性。
為了解決幾何相關數據增強引起的對齊問題,我們提出了InverseAug。如圖2所示,在數據增廣應用于點云之后,給定3D關鍵點(可以是任何3D坐標,例如激光雷達點、體素中心等)。在增強空間中,僅使用原始激光雷達和相機參數,無法在2D空間中定位相應的相機特征。為了使定位可行,當應用幾何相關數據增廣時,InverseAug首先保存增廣參數(例如,RandomRotate的旋轉度[46])。在融合階段,它對所有這些數據進行反向增強以獲得3D關鍵點的原始坐標(圖2(c)),然后在相機空間中找到其對應的2D坐標。注意,我們的方法是通用的,因為它可以對齊不同類型的關鍵點(例如,體素中心),為了簡單起見,我們只采用圖2中的激光雷達點,并且它還可以處理兩種模態都得到增強的情況。相比之下,現有的融合方法(如PointAugmenting [36])只能在增強之前處理數據。最后,我們在圖3(b)中展示了通過InverseAug改進對齊質量的示例。
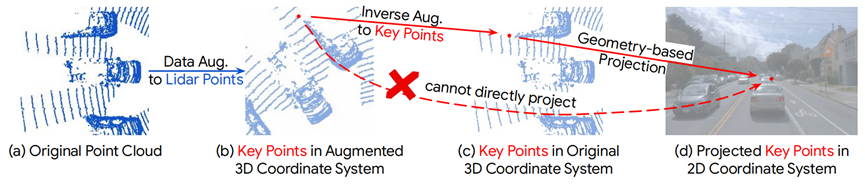
圖2 InverseAug的流程。所提出的目標是將數據增強后獲得的關鍵點,即(a)→(b),投影到2D相機坐標系中。關鍵點是一個通用的概念,它可以是任何3D坐標,如激光雷達點或體素中心。為了簡單起見,我們在這里使用一個激光雷達點來說明這個想法。利用相機和激光雷達參數,即直接從(b)到(d)。在這里直接將關鍵點從增強的3D坐標系投影到2D相機坐標系的精度較低,我們建議首先將所有的數據增強反向應用于3D關鍵點,從而在原始坐標中找到所有的關鍵點,即(b)→(c)。然后,用激光雷達和相機參數將3D關鍵點投影到相機特征上,即(c)→(d)。如圖3所示,其顯著提高了對齊質量。

圖3 相機和激光雷達對齊質量應用前后的比較。如(a)所示,如果沒有InverseAug,激光雷達點(標記為白色)在相機視圖中沒有與行人和柱子很好地對齊。相比之下,如(b)所示,激光雷達點與相機數據對齊更好。請注意,我們在這個圖中只添加了一小部分的數據增強。在訓練中,如果沒有InverseAug,錯位會更嚴重。
LearnableAlign。對于輸入級裝飾方法,如PointPainting[34]和PointAugmenting[36],給定3D激光雷達點云,只有相應的相機像素可以精確定位,因為存在一對一映射。相比之下,當在我們的DeepFusion流程中融合深層特征時,每個激光雷達特征表示一個包含點云子集的體素,因此其相應的相機像素處于多邊形中。因此,對齊變成了一個單體素對多像素的問題。一種簡單的方法是對給定體素對應的所有像素求平均。然而,直觀地,正如我們可視化結果所支持的,這些像素并不同樣重要,因為來自激光雷達深度特征的信息與每個相機像素不相等地對齊。例如,一些像素可以包含用于檢測的關鍵信息,諸如要檢測的目標對象,而其他像素可能較少提供信息,包括諸如道路、植物、遮光器等的背景。
為了更好地將來自激光雷達特征的信息與最相關的相機特征對齊,我們引入了LearnableAlign,它利用交叉注意力機制來動態捕獲兩個模態之間的相關性,如圖1所示。具體地,輸入包含體素單元及其所有對應的N個相機特征。LearnableAlign使用三個全連接層來分別將體素轉換為查詢q1,并將相機特征轉換為鍵kc和值vc。對于每個查詢(即,體素單元),我們進行查詢和鍵之間的內積,以獲得包含體素與其所有對應的N個相機特征之間的1×N個相關性的注意力親和度矩陣。然后將,注意力親和矩陣由softmax歸一化后,用于加權和聚合包含相機信息的值vc。聚合的相機信息通過一個全連接層處理,并最終與原始激光雷達特征連接。最終的輸出可以輸入到任何標準的3D目標檢測框架中,例如PointPillars或CenterPoint。
Ⅳ。 實驗
我們在自動駕駛汽車的大規模3D目標檢測數據集Waymo Open Dataset[32]上對DeepFusion進行了評估。Waymo Open Dataset包含798個訓練序列、202個驗證序列和150個測試序列。每個序列有大約200幀,并且每幀都有激光雷達點云、相機圖像和標注的3D邊界框。我們使用推薦的指標,即平均精度(AP)和通過Heading(APH)加權的平均精度對模型進行評估和比較,并報告LEVEL_1(L1)和LEVEL_2(L2)困難目標的結果。我們在表格中突出了LEVEL_2 APH,因為其是在Waymo挑戰排行榜中排名的主要指標。
4.1 實施細節
3D目標檢測模型。我們利用三種流行的點云3D目標檢測方法:PointPillars[16]、CenterPoint[44]和3D-MAN [43]作為基準。此外,我們還發現他們的改進本(即PointPillars++,CenterPoint++,3D-MAN++)是更好的基準,其使用3層hidden size為256的多層感知機(MLP)將輸入的點云構造成偽圖像,并將非線性激活函數從ReLU[9,21]改成SILU[7,28]。默認情況下,所有實驗都采用3D-MAN++行人模型進行。提交給測試服務器的最終模型還結合其他技術,如模型集成(記為“Ens”),這些技術將在附錄A.2中進行討論。
LearnableAlign。我們使用256個filters的全連接層來融合激光雷達特征與其相應的相機特征。在激光雷達到相機的交叉注意力模塊中,訓練過程將30%丟棄率的dropout操作應用于注意親和矩陣作為正則化。交叉注意力模塊之后的MLP層是一個帶有192個filters的全連接層。最后,由另一個全連接層進行特征拼接(Concatenate),以壓縮通道數。與標準的注意力模塊實現過程不同,我們實現的是將注意力模塊與動態體素化[45]結合的方式。因此,我們在附錄材料中放了基于TensorFlow框架的偽代碼,其中包含了LearnableAlign實現的更多細節。
InverseAug。受PPBA[5]的啟發,我們在訓練過程中依次將以下數據增強策略應用于激光雷達點云:隨機旋轉→全局縮放→全局平移噪聲→隨機翻轉→Frustum-Dropout→隨機丟棄激光點。關于數據增強操作的更多細節可以在[5]中找到。與PPBA [5]和其他工作不同的是,這里我們保存所有隨機生成的與幾何變換相關的數據增強參數(即隨機旋轉、全局縮放、全局平移噪聲、隨機翻轉)。在融合階段,我們將所有這些保存的參數反向應用幾何增廣方法將3D關鍵點轉換到原始坐標下。此外,我們還需要反轉增廣操作的順序(即隨機翻轉→全局平移噪聲→全局縮放→隨機旋轉)。
4.2 Waymo數據集上的SOTA性能
將我們的方法與Waymo Open Dataset(驗證集和測試集)上已發表和未發表的3D目標檢測方法進行了比較。
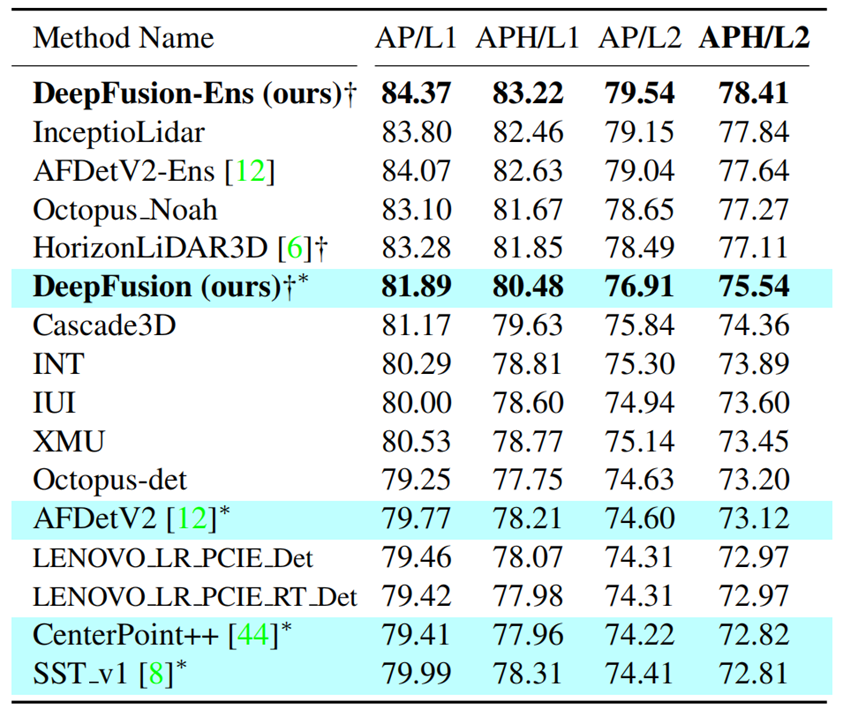
根據表2中的測試結果,DeepFusion在Waymo挑戰排行榜上取得了最好的結果,證明了我們方法的有效性。例如,DeepFusion-Ens在Waymo挑戰排行榜上取得了最好的結果;與之前最先進的單模態方法AFDetV2[12]相比,深度融合提高了2.42 APH/L2。
表2 Waymo Open Dataset挑戰排行榜。?:據我們所知,這些方法(用淺藍色突顯)不使用模型集成。?:多模態的方法。
我們還比較了驗證集上的不同方法,如表3所示。DeepFusion明顯優于現有的方法,證明了我們方法的有效性。
表3 在Waymo驗證集上的3D目標檢測模型之間的性能比較。?:多模態的方法。
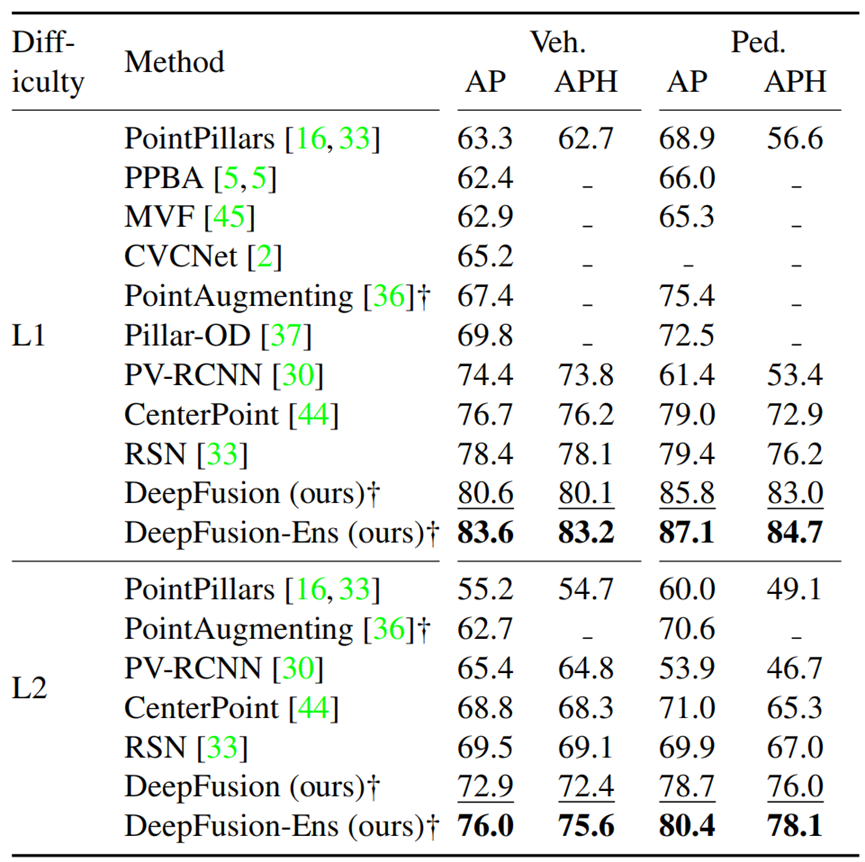
4.3 DeepFusion是一種通用的融合方法
將我們方法插入目前流行的3D目標檢測框架中,以驗證我們方法的通用性。我們比較了六對,每對都有單模態方法和多模態方法。這六個單模態分別是只有激光雷達模態的PointPillars, CenterPoint, 3D-MAN和他們的改進版本(標記為“++”)。如表4所示,表明DeepFusion的插入能夠改進單模態檢測基準的性能。這些結果表明,DeepFusion是通用的,能夠應用于其他3D目標檢測框架。
表4 在Waymo驗證集上將DeepFusion插入到不同的單模態基準中。L表示僅有激光雷達;L+C表示激光雷達+相機。我們對Pointpillar, CenterPoint, 3D-MAN和它們的改進版本(用“++”表示)進行了評估。通過添加相機信息,我們的DeepFusion能夠進一步提高檢測性能,超過了只有激光雷達模態的方法。
4.4 改進從何而來?
為了更好地理解DeepFusion是如何利用相機信息來改進3D目標檢測模型的,我們進行了定性和定量的深入分析。
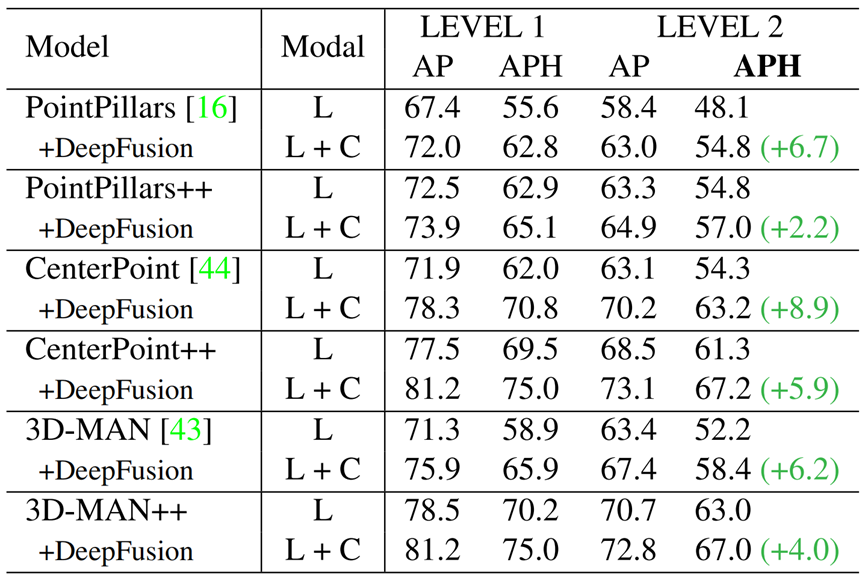
首先,根據目標與自車的距離將目標分為三組:30米以內,30米到50米,以及50米以上。圖4顯示了各組經多模態融合后的相對增益。簡而言之,DeepFusion可以在每一個距離范圍內均勻地提高精度。特別是,其可實現遠距離目標(》50米的LEVEL_2目標提高6.6%)比近距離目標(《30米的LEVEL_2目標提高1.5%)獲得更好的檢測精度,其原因可能是遠距離目標的激光雷達點云非常稀疏,而高分辨率的相機能夠填補信息空白。
圖4 通過展示不同真值深度范圍內的AP指標(所有藍條都歸一化為100%),比較單模式基準和DeepFusion。結果顯示,DeepFusion略微提高對近距離目標(如在30米以內)的檢測性能,但顯著提高對遠距離目標(如超過50米)的檢測性能。
然后,圖5為LearnableAlign的可視化注意力圖。我們觀察到,該模型傾向于關注具有較強辨別能力的區域,如行人的頭部,以及目標的末端,如行人的背部。基于這些觀察結果,我們得出結論,高分辨率的相機信息能夠幫助識別和預測物體的邊界。

圖5 LearnableAlign的可視化注意力圖。對于每個子圖,我們研究一個3D point pillar,并在2D圖像中用白框標記。注意力圖上所顯示的重要區域用紅點標記。我們有兩個有趣的觀察:首先,如(a)和(b)所示,LearnableAlign通常注意行人的頭部,可能是因為從相機圖像來看頭部是識別人類的重要部分(由于激光雷達信息很難識別頭部);第二,如(c)和(d)所示,LearnableAlign還關注目標末端(如背部),利用高分辨率相機信息來預測目標邊界,以獲得準確的目標大小。
4.5 InverseAug和LearnableAlign的效果
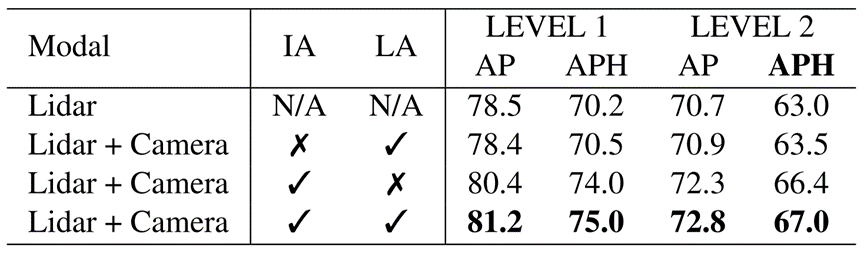
在本節中,我們將展示InverseAug和LearnableAlign這兩個組件的有效性。如表5所示,我們觀察到這兩個組件都可以提高單模態基準的性能。特別是,InverseAug的提高效果更為突出。例如,如果沒有InverseAug,對LEVEL_2目標檢測的性能從67.0 APH大幅下降到63.5 APH,這已經非常接近僅激光雷達模態63.0 APH的性能。另一方面,雖然LearnableAlign提高比較小,但它的改進也不容忽視。例如,LearnableAlign將LEVEL_2目標檢測的最終性能從66.4 APH提高到67.0 APH。消融研究表明,這兩個組件都非常關鍵,我們不應該去掉它們的任何一個。
表5 InverseAug(IA)和LearnableAlign(LA)的消融研究。這兩種技術都有助于提高性能,而InverseAug提高的比重更大。
4.6 DeepFusion是一種有效的融合策略
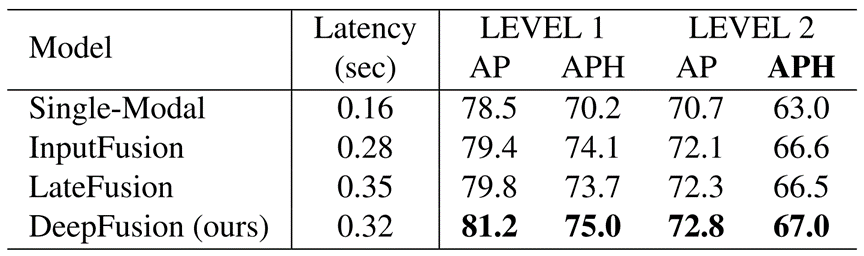
在本節中,將DeepFusion與其他融合策略進行比較。具體來說,我們考慮的方法是:(1)InputFusion,在輸入階段融合相機特征和激光雷達點[34,36],(2)LateFusion,其中激光雷達點和相機特征分別通過體素網絡后進行拼接(concatenation)[36],以及(3)我們提出的DeepFusion。
結果如表6所示。我們觀察到,DeepFusion明顯優于其他融合策略。例如,DeepFusion比LateFusion提高了0.5 LEVEL_2 APH(從66.5提高到67.0)。值得注意的是,在我們的實驗中,InputFusion與LateFusion相同,但在[36]中,LateFusion更好,因為其解決了激光雷達和相機之間的模態間隙問題。我們假設,在我們的設置中,模態間隙問題已經通過端到端訓練來解決,無論何時進行融合,它都將不再發生。
表6 與其他融合策略的比較。輸入融合來自點畫[34]和點增強[36]。延遲融合來自于點增強[36]。所有的延遲都在一個V100 GPU上測量,具有相同的Lingvo [29] 3D目標檢測實現,相同的3D檢測主干,和相同的相機特征提取器。DeepFusion在所有評估指標上獲得最佳性能,而延遲與其他融合方法相當。
4.7 DeepFusion的魯棒性
魯棒性是在自動駕駛汽車上部署模型的一個重要指標[20]。在本小節中,我們將研究模型對噪聲輸入[11]和分布外(OOD)數據[35]的魯棒性。
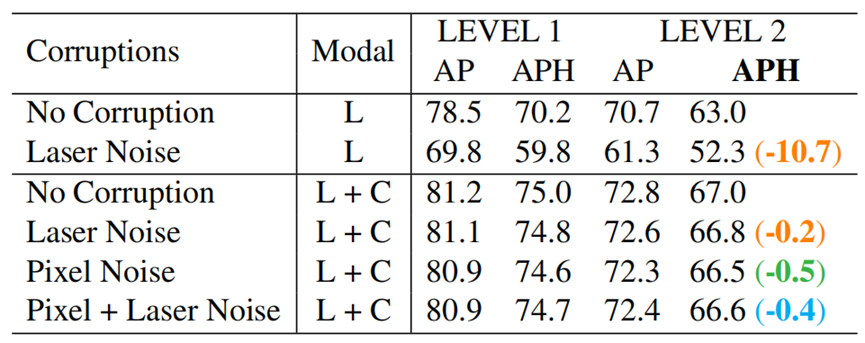
對損壞輸入的魯棒性。我們首先測試了兩種常見噪聲模型在驗證集上的魯棒性,包括激光噪聲(隨機添加噪聲到激光雷達反射值中)和像素噪聲(隨機添加噪聲到相機像素中)。
對于單模態只用激光噪聲,而激光噪聲和像素噪聲用于多模態。如表7所示,在存在噪聲的情況下,多模態通常比單模態更穩健。值得注意的是,激光/像素噪聲幾乎不能降低我們的多模態方法的性能(只有0.2 / 0.5 L2 APH的下降)。即使同時應用激光和像素噪聲的情況下,性能下降仍然很低(0.4 L2 APH的下降)。同時,單模態只應用激光噪聲就使模型性能下降超過10 APH。
表7 模型對輸入噪聲的魯棒性。給定相同訓練好的單模態(Lidar)和多模態(Lidar+Camera)模型,我們在原始的Waymo驗證集(沒有噪聲)上進行評估,并手動添加來自激光和像素噪聲驗證集中的樣本。對于激光噪聲,我們在所有激光點的反射值上添加擾動。對于像素噪聲,我們對相機圖像添加擾動。請注意,像素噪聲僅適用于使用相機圖像作為輸入的多模態模型。擾動在激光和像素噪聲的均勻分布中采樣,最多為原始值的2.5%。我們觀察到,與單模態相比,DeepFusion對這些噪聲更魯棒。L表示僅激光雷達;L+C表示激光雷達+相機。
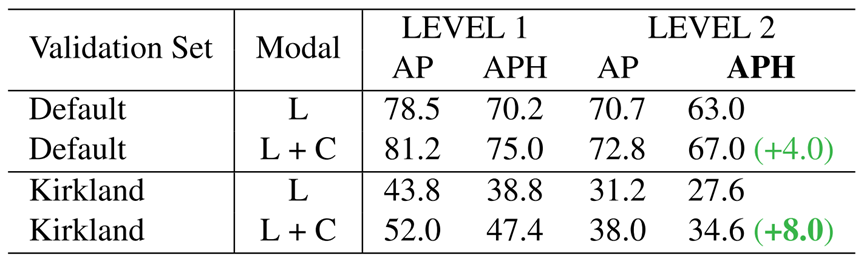
對OOD數據的魯棒性。為了測試我們的方法對OOD數據的魯棒性,我們利用Mountain View、San Francisco和Phoenix三個城市的數據訓練我們的模型,并在Kirkland上評估模型。結果匯總見表8。我們觀察到多模態對OOD數據有更大的魯棒性。例如,DeepFusion在分布外數據上提高了8.0 LEVEL_2 APH,而在分布內數據上只提高了4.0 LEVEL_2 APH。
表8 模型對分布外數據的魯棒性。我們在分布內驗證集(Default)和分布外驗證集(Kirkland)上評估了單模態(Lidar)和多模態(Lidar + Camera)模型。DeepFusion在分布外驗證集上實現了更大的提升。L表示僅激光雷達;L+C表示激光雷達+相機。
Ⅴ。 結論
本文研究了如何有效地融合激光雷達和相機數據進行多模態3D目標檢測。我們的研究表明,當兩個模態對齊后的最后階段的深度特征融合是更有效的,但要對齊不同模態的兩個深度特征具有挑戰性。為了解決這一挑戰,我們提出了InverseAug和LearnableAlign兩種技術,使多模態特征能夠有效對齊。基于這些技術,我們開發了一系列簡單的、通用的、有效的多模態3D目標檢測方法,稱為DeepFusions,其在Waymo Open Dataset上實現了SOTA的性能。
A. 附錄
A.1 對齊質量的影響
在本節中,將為主論文的第3.2節提供更詳細的實驗設置和更多的初步實驗結果。
實驗設置。我們使用了第4.1節和第A.2節中提到的3D-MAN++行人模型。為了檢查對齊質量,將刪除InverseAug和所有數據增強。然后,我們將不同幅度的隨機旋轉[46]應用于單模態和多模態模型。最后,對于相同的擾動量級,我們計算了來自單模態和多模態模型的最佳驗證結果的性能差距。
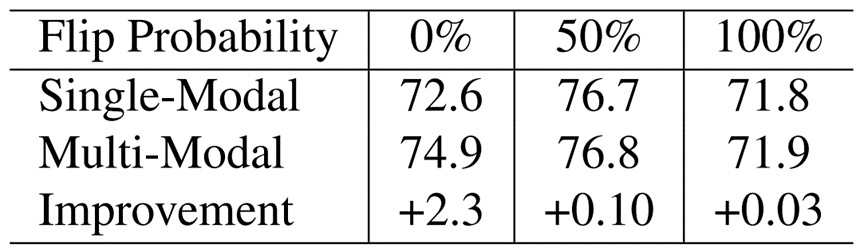
其他結果。除了使用隨機旋轉[46]進行測試外,我們還使用隨機翻轉[46]進行測試,這是另一種在3D點云目標檢測模型中常用的數據增強策略。具體來說,隨機翻轉以給定的概率p沿著Y軸翻轉3D場景。在這里,我們將概率分別設置為0%、50%和100%,結果如表9所示。觀察結果是相似的:當應用大幅度的數據增強時,從多模態融合的好處減少。例如,當用零概率隨機翻轉(即不用數據增強)時,改進最顯著(+2.3 AP);當翻轉概率為100%時(即每次翻轉3D場景),改進幾乎為零(+0.03 AP)。
表9 多模態融合的性能增益隨著隨機翻轉[46]幅度的增加而降低,這表明了精確對齊的重要性。這里不使用InverseAug。在Waymo Open Dataset的行人檢測任務中,報告了從單模態到多模態的LEVEL 1 AP的改善。
A.2 3D檢測器的實施細節
在本文中,由于空間的限制,我們主要提供關于DeepFusion的更多細節。在本節中,我們還將說明構建3D目標檢測模型的其他重要實現細節。
點云3D目標檢測方法。我們重新實現了三種經典的點云3D目標檢測方法,PointPillars[16]、CenterPoint[44]和3D-MAN[43]。如第2節所述,PointPillars將點云體素化,每個地圖網格位置有一個細高的體素,構建鳥瞰偽圖像;最后,將偽圖像輸入基于anchor的目標檢測流程。一個高級別的模型流程如圖6所示。CenterPoint也是一種基于PointPillars的方法,但使用無anchor的檢測頭。請注意,我們只實現了基于PointPillars的單階段版本的CenterPoint。3D-MAN與CenterPoint相似,主要的區別是在計算損失時,3D-MAN使用匈牙利算法將預測結果和真值關聯起來(更多細節見Yang等[43]的3.1節)。
基本方案的改進。我們將介紹兩種簡單但有效的發現,能夠顯著改善點云3D目標檢測基準。我們以PointPillars框架為例來介紹,但這些技術可以自然地應用于其他點云3D目標檢測框架,如CenterPoint和3D-MAN。如圖6所示,我們的框架建立在PointPillars模型的基礎上,并用紅色虛線框表示我們的修改。NAS塊表示使用神經架構搜索找到的體素特征編碼。我們還用SILU [7,28]替換了原始框架中的ReLU [9,21]激活函數。我們改進的模型(命名為PointPillars++、CenterPoint++和3D-MAN++)顯示出比基準方法更好的性能,如主論文中的表4所示。例如,對3D-MAN使用這兩種技術后,LEVEL_2 APH從52.2提高到63.0。這種改進是顯著的,并且從其他指標和其他基準中都可以觀察到一致地效果。
訓練細節。我們同時使用LEVEL_1和LEVEL_2兩種困難數據進行訓練。由于模型難以對LEVEL_2數據進行預測,我們在訓練過程中使用不確定性損失[19]以容許模型檢測低精度低自信度的目標。
提交模型的細節。我們將DeepFusion應用于CenterPoint來提交我們的模型。我們將隨機旋轉數據增強的最大旋轉擴大到180°(行人模型為120°),因為我們從表1發現其好處。我們還將偽圖像特征分辨率從512×512擴大到704×704。我們通過簡單地將最后N幀點云一起與之前幀的信息拼接(concatenate)。如圖7所示,為了防止在多幀配置下的過擬合問題,我們提出了DropFrame,即從之前的幀中隨機刪除點云。最好的模型是進行5幀拼接,在訓練過程中DropFrame幀的概率為0.5。此外,我們還使用了模型集成和測試時間增強(TTA)的加權框融合(WBF)[12]。對于TTA,我們使用航向旋轉和全局縮放。具體地說,我們使用[0°,±22.5°,±45°,±135°,±157.5°,±180°]用于航向旋轉,以及[0.95,1,1.05]用于全局縮放。對于模型集成,我們獲得了5種不同類型的模型,它們具有不同的偽圖像特征分辨率和不同的輸入模態,即單模態分辨率為512/704/1024分辨率,多模態分辨率為512/704分辨率。對于每種類型的模型,我們用不同的隨機種子訓練了5次。然后,我們根據驗證集和集成top-k模型的性能對所有25個模型進行排序,其中k是在驗證集上得到最佳結果的最優值。
A.3 與大型單模態方法比較
本節的目標是在相同的計算開銷下比較單模態基準和深度融合。為了實現這一點,我們首先擴大單模態的模型。由于我們在構建基準模型時已經充分擴大了體素特征編碼和backbone,為了進一步擴大單模態以匹配多模態的延遲,擴大偽圖像的分辨率可能是最有效的方式,因此我們采用這種策略。具體來說,我們在512到960的分辨率范圍下訓練模型,并測試每個配置的性能。圖8清楚地展示了,DeepFusion的延遲為0.32s,具有67.0 L2 APH的檢測性能,而單模態在相同的延遲下只能達到65.7 L2 APH的檢測性能。進一步擴大單模態給性能帶來了邊際增益,上限為66.5 L2 APH,仍然比 DeepFusion更差。
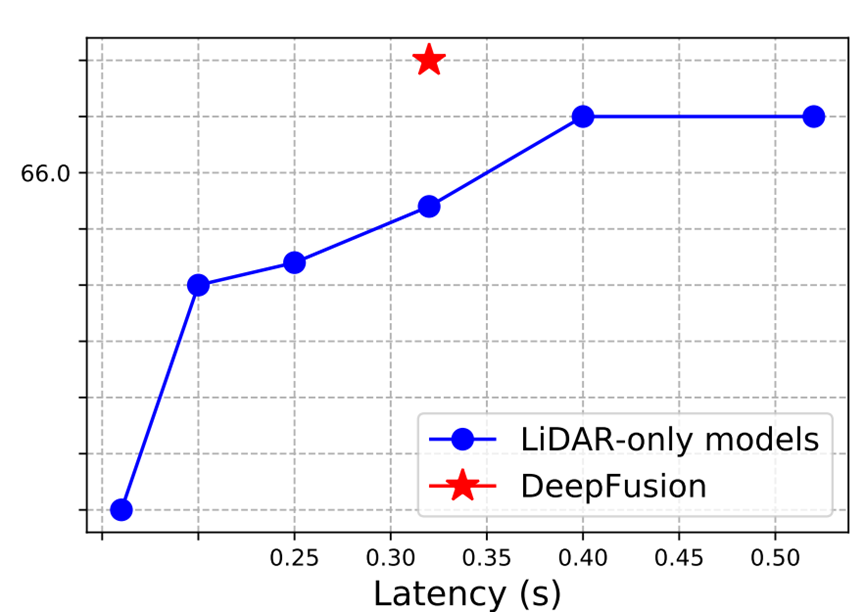
圖8 模型延遲與檢測性能的關系。DeepFusion在所有延遲條件下都顯著優于單模態。
局限性:本文主要關注激光雷達和相機信息的融合。然而,我們提出的方法也能夠擴展到其他模態,如深度圖像、毫米波雷達和高清地圖。此外,我們只采用了基于體素的方法,如PointPillars[16],但通過采用更強的基準[33]可以進一步提高性能。
審核編輯 :李倩
-
相機
+關注
關注
4文章
1458瀏覽量
54606 -
目標檢測
+關注
關注
0文章
223瀏覽量
15967 -
激光雷達
+關注
關注
971文章
4225瀏覽量
192576 -
點云
+關注
關注
0文章
58瀏覽量
3943
原文標題:DeepFusion:基于激光雷達和相機深度融合的多模態3D目標檢測
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
淺析自動駕駛發展趨勢,激光雷達是未來?
常見激光雷達種類
激光雷達除了可以激光測距外,還可以怎么應用?
5 款激光雷達:iDAR、高清3D LiDARInnovizPro、S3、SLAM on Chip、VLS-128
最佳防護——激光雷達與安防監控解決方案
3D激光雷達和相機校準是如何考慮傳感器之間誤差的?
基于金字塔的激光雷達和攝像頭深度融合網絡
基于3D激光雷達的安全系統

自動駕駛深度多模態目標檢測和語義分割:數據集、方法和挑戰

基于Transformer的相機-毫米波雷達融合3D目標檢測方法





 工商網監
工商網監

評論