") 計算機視覺中的主動學習
計算機視覺中的主動學習
Active Learning主動學習是機器學習 (ML) 的一個研究領域,旨在通過以智能方式查詢管道的下一個數(shù)據(jù)來降低構建新機器學習解決方案的成本和時間。在開發(fā)新的 AI 解決方案和處理圖像、音頻或文本等非結構化數(shù)據(jù)時,我們通常需要人工對數(shù)據(jù)進行注釋,然后才能使用它們來訓練我們的模型。這個數(shù)據(jù)注釋過程非常耗時且昂貴。它通常是現(xiàn)代 ML 團隊中最大的瓶頸之一。
通過主動學習,您可以創(chuàng)建一個反饋循環(huán),您可以在注釋、訓練和選擇之間進行迭代。使用良好的選擇算法,您可以減少訓練模型以達到所需精度所需的數(shù)據(jù)量。
2. 不同的Active learning方法
在進行主動學習時,我們通常使用模型的預測。每當利用模型進行預測時,我們還會獲得相關的預測概率。由于模型天生就無法了解自身的局限性,因此我們嘗試在研究中使用其他技巧來克服這些局限性。在計算機視覺中,Active Learning 是一種主動學習方法,它可以通過最小化標記數(shù)據(jù)的量來提高機器學習模型的準確性和效率。以下是一些常見的 Active Learning 方法:
Uncertainty Sampling:選擇那些讓模型不確定的樣本進行標記,如模型輸出的概率值最大的前幾個樣本,或者模型預測結果的方差最大的前幾個樣本。
Query-by-Committee:從多個訓練好的模型中挑選出相互矛盾的樣本進行標記,以期望在后續(xù)的訓練中降低模型的誤差。
Expected Model Change:通過計算在當前模型下對標記某個樣本的貢獻,選擇那些最有可能改善模型性能的樣本進行標記。
Diversity Sampling:選擇那些與當前已經標記的樣本差異最大的樣本進行標記,以期望能夠提高模型的泛化能力。
Information Density Sampling:選擇那些在當前模型下信息密度最大的樣本進行標記,即選擇對模型最有幫助的樣本。
Active Transfer Learning:在已經標記的數(shù)據(jù)集和目標任務的數(shù)據(jù)集之間進行遷移學習,以期望能夠提高模型的泛化能力和訓練效率。
這些方法可以單獨或結合使用,具體選擇哪種方法取決于具體的問題和應用場景。
舉個例子,我們不僅可以考慮單個模型,還可以考慮一組模型(集成)。這為我們提供了有關實際模型不確定性的更多信息。如果模型組都同意預測,則不確定性很低。如果他們都不同意,那么不確定性就很高。但是擁有多個模型非常昂貴。像“Training Data Subset Search with Ensemble Active Learning, 2020”這樣的論文使用了 4 到 8 種不同的集成方法模型。
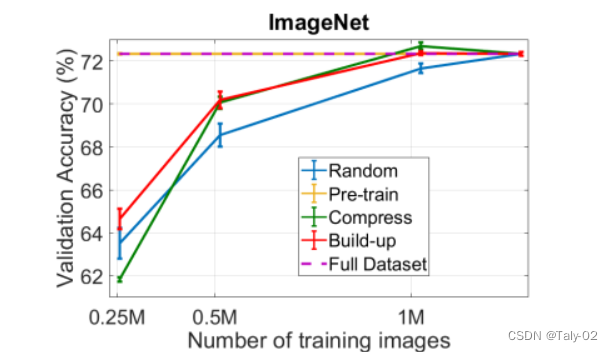
繪圖來自“使用集成主動學習訓練數(shù)據(jù)子集搜索,2020”論文,展示了他們的不同方法與 ImageNet 上的隨機基線相比如何。
我們可以通過使用 Monte Carlo dropout 來提高效率,我們在模型的最后幾層之間添加了 dropout。這允許我們使用一個模型來創(chuàng)建多個預測(使用 Dropout),類似于使用模型集成。但是,這樣做的缺點是我們需要更改模型架構并添加 dropout 層。
3. 在Active Learning中利用embedding

插圖來自“目標檢測的可擴展主動學習,2020”
最近,論文也開始使用embedding。通過embedding,我們可以了解不同樣本的相似程度。在計算機視覺中,我們可以使用嵌入來檢查相似的圖像甚至相似的對象。然后我們可以在embedding空間中使用距離度量,例如歐幾里德距離或余弦相似度,并將其與預測的不確定性結合起來。
然而,使用來自同一個模型的embedding和預測有一個缺點,即兩者都依賴于模型學習到的相同特征。通常,嵌入是預測前一層或幾層模型的輸出。為了克服這個限制,我們開始使用來自其他模型的嵌入,而不是我們所說的“任務”模型。任務模型就是您想要使用主動學習改進的實際模型。
我們自己的基準和與自動駕駛、衛(wèi)星想象、機器人技術和視頻分析等領域的數(shù)十家公司合作的經驗表明,使用使用自我監(jiān)督學習訓練的模型具有最強大的嵌入。最近的模型,如 CLIP 或 SEER 都在使用自監(jiān)督學習。
4. 我們可以利用active learning做什么?
首先,請注意主動學習是一種工具,與您使用的大多數(shù)其他工具一樣,您必須微調一些參數(shù)才能從中獲得最大價值。經過廣泛的研究并嘗試從最近的主動學習研究中復制許多論文,我們觀察到這些基本規(guī)則似乎適用于我們認為是“好的”訓練數(shù)據(jù):
選擇多樣化的數(shù)據(jù)——擁有多樣化的數(shù)據(jù)(多樣化的圖像、多樣化的對象)是最重要的因素
平衡數(shù)據(jù)集——確保數(shù)據(jù)在你的模式(天氣、性別、一天中的時間)之間保持平衡
與模型架構無關— 根據(jù)我們自己的實驗,看起來大型 ViT 模型的好數(shù)據(jù)對小型 ResNet 也有幫助
前兩點表明,我們的目標應該是從所有模式中獲取等量的多樣化數(shù)據(jù)。第三點很高興知道。這意味著,我們今天可以用一個模型選擇訓練數(shù)據(jù),一年后訓練一個全新的模型時,我們仍然可以重用相同的數(shù)據(jù)。請注意,這些只是觀察。如果實施得當,主動學習可以顯著提高模型的準確性。
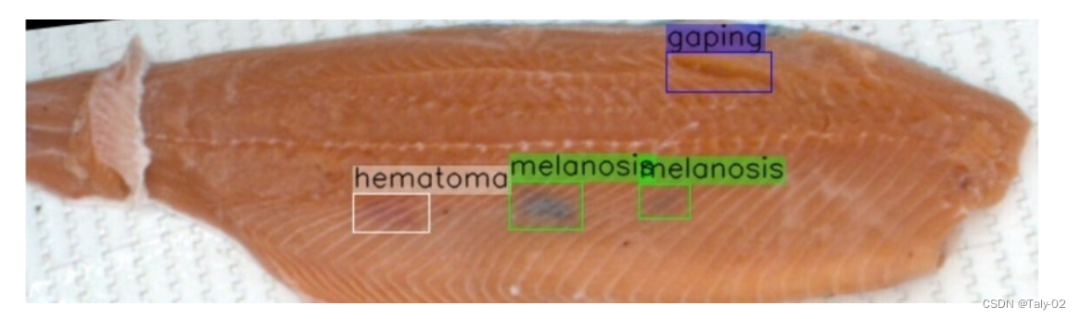
我們評估了結合 AL、多樣性和平衡選擇在檢測鮭魚片問題任務中的性能。目標是提高鮭魚“血腫”的模型準確性,因為這是最關鍵的類別。
5. Active Learning Algorithms的簡單Implement
以下是一個簡單的Active Learning偽代碼:
#假設我們已經有了一批標記好的數(shù)據(jù)集合和一個未標記的數(shù)據(jù)池 labeled_dataset=... unlabeled_pool=... #在每一輪迭代中,我們都會選擇一些未標記的數(shù)據(jù)點并請求標記 whilelen(unlabeled_pool)>0: #從未標記的數(shù)據(jù)池中選擇一些樣本 selected_samples=select_samples(unlabeled_pool) #請求這些樣本的標簽 labeled_samples=query_labels(selected_samples) #將新標記的樣本添加到已標記的數(shù)據(jù)集中 labeled_dataset=labeled_dataset+labeled_samples #更新未標記的數(shù)據(jù)池,移除已經被標記的樣本 unlabeled_pool=remove_labeled_samples(unlabeled_pool,labeled_samples) #訓練模型,根據(jù)當前的已標記數(shù)據(jù)集和模型更新策略 model=train_model(labeled_dataset) #在驗證集上評估模型表現(xiàn) validation_accuracy=evaluate_model(model,validation_dataset) #如果模型的表現(xiàn)已經滿足了停止準則,則停止訓練 ifstopping_criterion(validation_accuracy): break
以上偽代碼中的主要步驟包括:
從未標記的數(shù)據(jù)池中選擇一些樣本
請求這些樣本的標簽
將新標記的樣本添加到已標記的數(shù)據(jù)集中
移除已經被標記的樣本,更新未標記的數(shù)據(jù)池
根據(jù)當前的已標記數(shù)據(jù)集和模型更新策略訓練模型
在驗證集上評估模型表現(xiàn)
如果模型的表現(xiàn)已經滿足了停止準則,則停止訓練。
6. Active Learning的應用場景
Active Learning在計算機視覺中具有廣泛的應用前景。以下是一些可能的應用:
目標檢測:在目標檢測任務中,每個圖像都可能包含多個對象。Active Learning可以幫助減少需要手動標注的對象數(shù)量,從而降低人力成本。
語義分割:語義分割任務涉及將每個像素標記為特定的對象或類別。Active Learning可以幫助減少需要手動標注的像素數(shù)量,從而減少人工標注的工作量。
人臉識別:在人臉識別任務中,Active Learning可以幫助識別出哪些人的圖像需要被標記,以及哪些特征可以提高識別準確性。
圖像分類:在圖像分類任務中,Active Learning可以幫助選擇需要標注的圖像,以便提高模型的準確性。
總之,Active Learning在計算機視覺中的應用前景非常廣泛,可以幫助降低人力成本、提高模型準確性和提高算法的效率。隨著技術的進步和數(shù)據(jù)集的不斷擴大,Active Learning將變得越來越重要。
審核編輯:劉清
-
人臉識別
+關注
關注
76文章
4011瀏覽量
81867 -
計算機視覺
+關注
關注
8文章
1698瀏覽量
45984 -
機器學習
+關注
關注
66文章
8408瀏覽量
132580 -
Clip
+關注
關注
0文章
31瀏覽量
6665
原文標題:計算機視覺中的主動學習(Active Learning)
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
深度學習與傳統(tǒng)計算機視覺簡介
計算機視覺與機器視覺區(qū)別
計算機視覺的發(fā)展歷史_計算機視覺的應用方向
計算機視覺入門指南
計算機視覺為何重要?
計算機視覺中的九種深度學習技術






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論