") 探秘消息在RocketMQ中短暫而又精彩的一生
探秘消息在RocketMQ中短暫而又精彩的一生
這篇文章我準(zhǔn)備來聊一聊RocketMQ消息的一生。
不知你是否跟我一樣,在使用RocketMQ的時(shí)候也有很多的疑惑:
- 消息是如何發(fā)送的,隊(duì)列是如何選擇的?
- 消息是如何存儲的,是如何保證讀寫的高性能?
- RocketMQ是如何實(shí)現(xiàn)消息的快速查找的?
- RocketMQ是如何實(shí)現(xiàn)高可用的?
- 消息是在什么時(shí)候會被清除?
- ...
本文就通過探討上述問題來探秘消息在RocketMQ中短暫而又精彩的一生。
核心概念
- NameServer :可以理解為是一個(gè)注冊中心,主要是用來保存topic路由信息,管理Broker。在NameServer的集群中,NameServer與NameServer之間是沒有任何通信的。
- Broker :核心的一個(gè)角色,主要是用來保存消息的,在啟動(dòng)時(shí)會向NameServer進(jìn)行注冊。Broker實(shí)例可以有很多個(gè),相同的BrokerName可以稱為一個(gè)Broker組,每個(gè)Broker組只保存一部分消息。
- topic :可以理解為一個(gè)消息的集合的名字,一個(gè)topic可以分布在不同的Broker組下。
- 隊(duì)列(queue) :一個(gè)topic可以有很多隊(duì)列,默認(rèn)是一個(gè)topic在同一個(gè)Broker組中是4個(gè)。如果一個(gè)topic現(xiàn)在在2個(gè)Broker組中,那么就有可能有8個(gè)隊(duì)列。
- 生產(chǎn)者 :生產(chǎn)消息的一方就是生產(chǎn)者
- 生產(chǎn)者組 :一個(gè)生產(chǎn)者組可以有很多生產(chǎn)者,只需要在創(chuàng)建生產(chǎn)者的時(shí)候指定生產(chǎn)者組,那么這個(gè)生產(chǎn)者就在那個(gè)生產(chǎn)者組
- 消費(fèi)者 :用來消費(fèi)生產(chǎn)者消息的一方
- 消費(fèi)者組 :跟生產(chǎn)者一樣,每個(gè)消費(fèi)者都有所在的消費(fèi)者組,一個(gè)消費(fèi)者組可以有很多的消費(fèi)者,不同的消費(fèi)者組消費(fèi)消息是互不影響的。
基于 Spring Boot + MyBatis Plus + Vue & Element 實(shí)現(xiàn)的后臺管理系統(tǒng) + 用戶小程序,支持 RBAC 動(dòng)態(tài)權(quán)限、多租戶、數(shù)據(jù)權(quán)限、工作流、三方登錄、支付、短信、商城等功能
- 項(xiàng)目地址:https://github.com/YunaiV/ruoyi-vue-pro
- 視頻教程:https://doc.iocoder.cn/video/
消息誕生與發(fā)送
我們都知道,消息是由業(yè)務(wù)系統(tǒng)在運(yùn)行過程產(chǎn)生的,當(dāng)我們的業(yè)務(wù)系統(tǒng)產(chǎn)生了消息,我們就可以調(diào)用RocketMQ提供的API向RocketMQ發(fā)送消息,就像下面這樣
DefaultMQProducerproducer=newDefaultMQProducer("sanyouProducer");
//指定NameServer的地址
producer.setNamesrvAddr("localhost:9876");
//啟動(dòng)生產(chǎn)者
producer.start();
//省略代碼。。
Messagemsg=newMessage("sanyouTopic","TagA","三友的java日記".getBytes(RemotingHelper.DEFAULT_CHARSET));
//發(fā)送消息并得到消息的發(fā)送結(jié)果,然后打印
SendResultsendResult=producer.send(msg);
雖然代碼很簡單,我們不經(jīng)意間可能會思考如下問題:
- 代碼中只設(shè)置了NameServer的地址,那么生產(chǎn)者是如何知道Broker所在機(jī)器的地址,然后向Broker發(fā)送消息的?
- 一個(gè)topic會有很多隊(duì)列,那么生產(chǎn)者是如何選擇哪個(gè)隊(duì)列發(fā)送消息?
- 消息一旦發(fā)送失敗了怎么辦?
路由表
當(dāng)Broker在啟動(dòng)的過程中,Broker就會往NameServer注冊自己這個(gè)Broker的信息,這些信息就包括自身所在服務(wù)器的ip和端口,還有就是自己這個(gè)Broker有哪些topic和對應(yīng)的隊(duì)列信息,這些信息就是路由信息,后面就統(tǒng)一稱為路由表。
 Broker向NameServer注冊
Broker向NameServer注冊當(dāng)生產(chǎn)者啟動(dòng)的時(shí)候,會從NameServer中拉取到路由表,緩存到本地,同時(shí)會開啟一個(gè)定時(shí)任務(wù),默認(rèn)是每隔30s從NameServer中重新拉取路由信息,更新本地緩存。
隊(duì)列的選擇
好了通過上一節(jié)我們就明白了,原來生產(chǎn)者會從NameServer拉取到Broker的路由表的信息,這樣生產(chǎn)者就知道了topic對應(yīng)的隊(duì)列的信息了。
但是由于一個(gè)topic可能會有很多的隊(duì)列,那么應(yīng)該將消息發(fā)送到哪個(gè)隊(duì)列上呢?
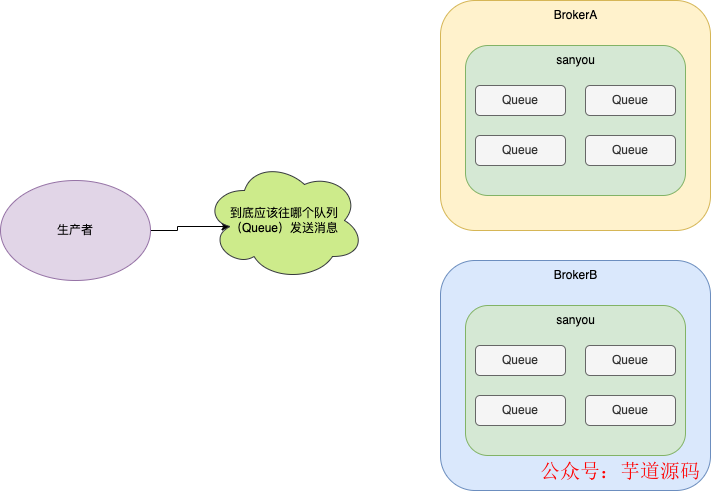
面對這種情況,RocketMQ提供了兩種消息隊(duì)列的選擇算法。
- 輪詢算法
- 最小投遞延遲算法
輪詢算法 就是一個(gè)隊(duì)列一個(gè)隊(duì)列發(fā)送消息,這些就能保證消息能夠均勻分布在不同的隊(duì)列底下,這也是RocketMQ默認(rèn)的隊(duì)列選擇算法。
但是由于機(jī)器性能或者其它情況可能會出現(xiàn)某些Broker上的Queue可能投遞延遲較嚴(yán)重,這樣就會導(dǎo)致生產(chǎn)者不能及時(shí)發(fā)消息,造成生產(chǎn)者壓力過大的問題。所以RocketMQ提供了最小投遞延遲算法。
最小投遞延遲算法 每次消息投遞的時(shí)候會統(tǒng)計(jì)投遞的時(shí)間延遲,在選擇隊(duì)列的時(shí)候會優(yōu)先選擇投遞延遲時(shí)間小的隊(duì)列。這種算法可能會導(dǎo)致消息分布不均勻的問題。
如果你想啟用最小投遞延遲算法,只需要按如下方法設(shè)置一下即可。
producer.setSendLatencyFaultEnable(true);
當(dāng)然除了上述兩種隊(duì)列選擇算法之外,你也可以自定義隊(duì)列選擇算法,只需要實(shí)現(xiàn)MessageQueueSelector接口,在發(fā)送消息的時(shí)候指定即可。
SendResultsendResult=producer.send(msg,newMessageQueueSelector(){
@Override
publicMessageQueueselect(Listmqs,Messagemsg,Objectarg) {
//從mqs中選擇一個(gè)隊(duì)列
returnnull;
}
},newObject());
MessageQueueSelector RocketMQ也提供了三種實(shí)現(xiàn)
- 隨機(jī)算法
- Hash算法
- 根據(jù)機(jī)房選擇算法(空實(shí)現(xiàn))
其它特殊情況處理
發(fā)送異常處理
終于,不論是通過RocketMQ默認(rèn)的隊(duì)列選擇算法也好,又或是自定義隊(duì)列選擇算法也罷,終于選擇到了一個(gè)隊(duì)列,那么此時(shí)就可以跟這個(gè)隊(duì)列所在的Broker機(jī)器建立網(wǎng)絡(luò)連接,然后通過網(wǎng)絡(luò)請求將消息發(fā)送到Broker上。
但是不幸的事發(fā)生了,Broker掛了,又或者是機(jī)器負(fù)載太高了,發(fā)送消息超時(shí)了,那么此時(shí)RockerMQ就會進(jìn)行重試。
RockerMQ重試其實(shí)很簡單,就是重新選擇其它Broker機(jī)器中的一個(gè)隊(duì)列進(jìn)行消息發(fā)送,默認(rèn)會重試兩次。
當(dāng)然如果你的機(jī)器比較多,可以將設(shè)置重試次數(shù)設(shè)置大點(diǎn)。
producer.setRetryTimesWhenSendFailed(10);
消息過大的處理
一般情況下,消息的內(nèi)容都不會太大,但是在一些特殊的場景中,消息內(nèi)容可能會出現(xiàn)很大的情況。
遇到這種消息過大的情況,比如在默認(rèn)情況下消息大小超過4M的時(shí)候,RocketMQ是會對消息進(jìn)行壓縮之后再發(fā)送到Broker上,這樣在消息發(fā)送的時(shí)候就可以減少網(wǎng)絡(luò)資源的占用。
基于 Spring Cloud Alibaba + Gateway + Nacos + RocketMQ + Vue & Element 實(shí)現(xiàn)的后臺管理系統(tǒng) + 用戶小程序,支持 RBAC 動(dòng)態(tài)權(quán)限、多租戶、數(shù)據(jù)權(quán)限、工作流、三方登錄、支付、短信、商城等功能
消息存儲
好了,經(jīng)過以上環(huán)節(jié)Broker終于成功接收到了生產(chǎn)者發(fā)送的消息了,但是為了能夠保證Broker重啟之后消息也不丟失,此時(shí)就需要將消息持久化到磁盤。
如何保證高性能讀寫
由于涉及到消息持久化操作,就涉及到磁盤數(shù)據(jù)的讀寫操作,那么如何實(shí)現(xiàn)文件的高性能讀寫呢?這里就不得不提到的一個(gè)叫零拷貝的技術(shù)。
傳統(tǒng)IO讀寫方式
說零拷貝之前,先說一下傳統(tǒng)的IO讀寫方式。
比如現(xiàn)在需要將磁盤文件通過網(wǎng)絡(luò)傳輸出去,那么整個(gè)傳統(tǒng)的IO讀寫模型如下圖所示
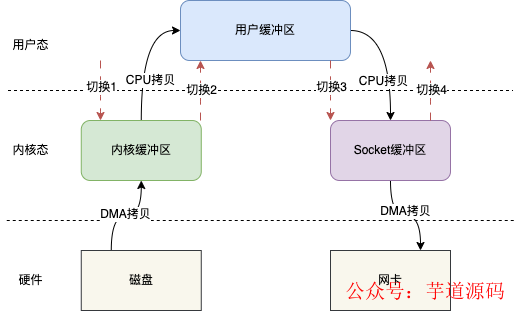
傳統(tǒng)的IO讀寫其實(shí)就是read + write的操作,整個(gè)過程會分為如下幾步
- 用戶調(diào)用read()方法,開始讀取數(shù)據(jù),此時(shí)發(fā)生一次上下文從用戶態(tài)到內(nèi)核態(tài)的切換,也就是圖示的切換1
- 將磁盤數(shù)據(jù)通過DMA拷貝到內(nèi)核緩存區(qū)
- 將內(nèi)核緩存區(qū)的數(shù)據(jù)拷貝到用戶緩沖區(qū),這樣用戶,也就是我們寫的代碼就能拿到文件的數(shù)據(jù)
- read()方法返回,此時(shí)就會從內(nèi)核態(tài)切換到用戶態(tài),也就是圖示的切換2
- 當(dāng)我們拿到數(shù)據(jù)之后,就可以調(diào)用write()方法,此時(shí)上下文會從用戶態(tài)切換到內(nèi)核態(tài),即圖示切換3
- CPU將用戶緩沖區(qū)的數(shù)據(jù)拷貝到Socket緩沖區(qū)
- 將Socket緩沖區(qū)數(shù)據(jù)拷貝至網(wǎng)卡
- write()方法返回,上下文重新從內(nèi)核態(tài)切換到用戶態(tài),即圖示切換4
整個(gè)過程發(fā)生了4次上下文切換和4次數(shù)據(jù)的拷貝,這在高并發(fā)場景下肯定會嚴(yán)重影響讀寫性能。
所以為了減少上下文切換次數(shù)和數(shù)據(jù)拷貝次數(shù),就引入了零拷貝技術(shù)。
零拷貝
零拷貝技術(shù)是一個(gè)思想,指的是指計(jì)算機(jī)執(zhí)行操作時(shí),CPU不需要先將數(shù)據(jù)從某處內(nèi)存復(fù)制到另一個(gè)特定區(qū)域。
實(shí)現(xiàn)零拷貝的有以下幾種方式
- mmap()
- sendfile()
mmap()
mmap(memory map)是一種內(nèi)存映射文件的方法,即將一個(gè)文件或者其它對象映射到進(jìn)程的地址空間,實(shí)現(xiàn)文件磁盤地址和進(jìn)程虛擬地址空間中一段虛擬地址的一一對映關(guān)系。
簡單地說就是內(nèi)核緩沖區(qū)和應(yīng)用緩沖區(qū)共享,從而減少了從讀緩沖區(qū)到用戶緩沖區(qū)的一次CPU拷貝。
比如基于mmap,上述的IO讀寫模型就可以變成這樣。
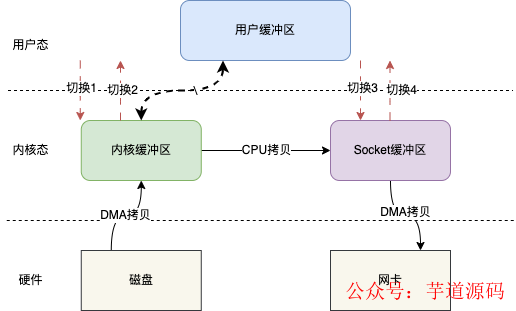
基于mmap IO讀寫其實(shí)就變成mmap + write的操作,也就是用mmap替代傳統(tǒng)IO中的read操作。
當(dāng)用戶發(fā)起mmap調(diào)用的時(shí)候會發(fā)生上下文切換1,進(jìn)行內(nèi)存映射,然后數(shù)據(jù)被拷貝到內(nèi)核緩沖區(qū),mmap返回,發(fā)生上下文切換2;隨后用戶調(diào)用write,發(fā)生上下文切換3,將內(nèi)核緩沖區(qū)的數(shù)據(jù)拷貝到Socket緩沖區(qū),write返回,發(fā)生上下文切換4。
整個(gè)過程相比于傳統(tǒng)IO主要是不用將內(nèi)核緩沖區(qū)的數(shù)據(jù)拷貝到用戶緩沖區(qū),而是直接將數(shù)據(jù)拷貝到Socket緩沖區(qū)。上下文切換的次數(shù)仍然是4次,但是拷貝次數(shù)只有3次,少了一次CPU拷貝。
在Java中,提供了相應(yīng)的api可以實(shí)現(xiàn)mmap,當(dāng)然底層也還是調(diào)用Linux系統(tǒng)的mmap()實(shí)現(xiàn)的
FileChannelfileChannel=newRandomAccessFile("test.txt","rw").getChannel();
MappedByteBuffermappedByteBuffer=fileChannel.map(FileChannel.MapMode.READ_WRITE,0,fileChannel.size());
如上代碼拿到MappedByteBuffer,之后就可以基于MappedByteBuffer去讀寫。
sendfile()
sendfile()跟mmap()一樣,也會減少一次CPU拷貝,但是它同時(shí)也會減少兩次上下文切換。
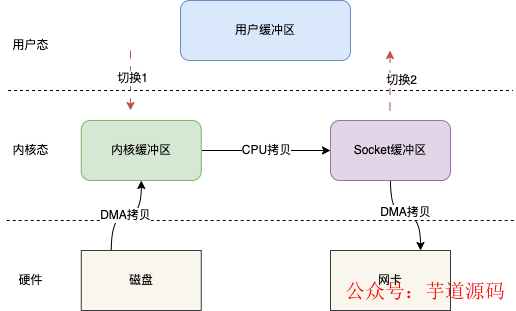
如圖,用戶在發(fā)起sendfile()調(diào)用時(shí)會發(fā)生切換1,之后數(shù)據(jù)通過DMA拷貝到內(nèi)核緩沖區(qū),之后再將內(nèi)核緩沖區(qū)的數(shù)據(jù)CPU拷貝到Socket緩沖區(qū),最后拷貝到網(wǎng)卡,sendfile()返回,發(fā)生切換2。
同樣地,Java也提供了相應(yīng)的api,底層還是操作系統(tǒng)的sendfile()
FileChannelchannel=FileChannel.open(Paths.get("./test.txt"),StandardOpenOption.WRITE,StandardOpenOption.CREATE);
//調(diào)用transferTo方法向目標(biāo)數(shù)據(jù)傳輸
channel.transferTo(position,len,target);
通過FileChannel的transferTo方法即可實(shí)現(xiàn)。
transferTo方法(sendfile)主要是用于文件傳輸,比如將文件傳輸?shù)搅硪粋€(gè)文件,又或者是網(wǎng)絡(luò)。
在如上代碼中,并沒有文件的讀寫操作,而是直接將文件的數(shù)據(jù)傳輸?shù)絫arget目標(biāo)緩沖區(qū),也就是說,sendfile是無法知道文件的具體的數(shù)據(jù)的;但是mmap不一樣,他是可以修改內(nèi)核緩沖區(qū)的數(shù)據(jù)的。假設(shè)如果需要對文件的內(nèi)容進(jìn)行修改之后再傳輸,只有mmap可以滿足。
通過上面的一些介紹,主要就是一個(gè)結(jié)論,那就是基于零拷貝技術(shù),可以減少CPU的拷貝次數(shù)和上下文切換次數(shù),從而可以實(shí)現(xiàn)文件高效的讀寫操作。
RocketMQ內(nèi)部主要是使用基于mmap實(shí)現(xiàn)的零拷貝(其實(shí)就是調(diào)用上述提到的api),用來讀寫文件,這也是RocketMQ為什么快的一個(gè)很重要原因。
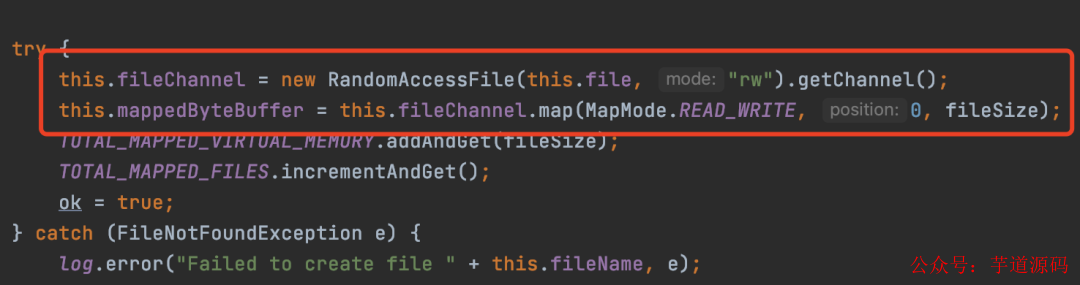 RocketMQ中使用mmap代碼
RocketMQ中使用mmap代碼
CommitLog
前面提到消息需要持久化到磁盤文件中,而CommitLog其實(shí)就是存儲消息的文件的一個(gè)稱呼,所有的消息都存在CommitLog中,一個(gè)Broker實(shí)例只有一個(gè)CommitLog。
由于消息數(shù)據(jù)可能會很大,同時(shí)兼顧內(nèi)存映射的效率,不可能將所有消息都寫到同一個(gè)文件中,所以CommitLog在物理磁盤文件上被分為多個(gè)磁盤文件,每個(gè)文件默認(rèn)的固定大小是1G。

當(dāng)生產(chǎn)者將消息發(fā)送過來的時(shí)候,就會將消息按照順序?qū)懙轿募校?dāng)文件空間不足時(shí),就會重新建一個(gè)新的文件,消息寫到新的文件中。

消息在寫入到文件時(shí),不僅僅會包含消息本身的數(shù)據(jù),也會包含其它的對消息進(jìn)行描述的數(shù)據(jù),比如這個(gè)消息來自哪臺機(jī)器、消息是哪個(gè)topic的、消息的長度等等,這些數(shù)據(jù)會和消息本身按照一定的順序同時(shí)寫到文件中,所以圖示的消息其實(shí)是包含消息的描述信息的。
刷盤機(jī)制
RocketMQ在將消息寫到CommitLog文件中時(shí)并不是直接就寫到文件中,而是先寫到PageCache,也就是前面說的內(nèi)核緩存區(qū),所以RocketMQ提供了兩種刷盤機(jī)制,來將內(nèi)核緩存區(qū)的數(shù)據(jù)刷到磁盤。
異步刷盤
異步刷盤就是指Broker將消息寫到PageCache的時(shí)候,就直接返回給生產(chǎn)者說消息存儲成功了,然后通過另一個(gè)后臺線程來將消息刷到磁盤,這個(gè)后臺線程是在RokcetMQ啟動(dòng)的時(shí)候就會開啟。異步刷盤方式也是RocketMQ默認(rèn)的刷盤方式。
其實(shí)RocketMQ的異步刷盤也有兩種不同的方式,一種是固定時(shí)間,默認(rèn)是每隔0.5s就會刷一次盤;另一種就是頻率會快點(diǎn),就是每存一次消息就會通知去刷盤,但不會去等待刷盤的結(jié)果,同時(shí)如果0.5s內(nèi)沒被通知去刷盤,也會主動(dòng)去刷一次盤。默認(rèn)的是第一種固定時(shí)間的方式。
同步刷盤
同步刷盤就是指Broker將消息寫到PageCache的時(shí)候,會等待異步線程將消息成功刷到磁盤之后再返回給生產(chǎn)者說消息存儲成功。
同步刷盤相對于異步刷盤來說消息的可靠性更高,因?yàn)楫惒剿⒈P可能出現(xiàn)消息并沒有成功刷到磁盤時(shí),機(jī)器就宕機(jī)的情況,此時(shí)消息就丟了;但是同步刷盤需要等待消息刷到磁盤,那么相比異步刷盤吞吐量會降低。所以同步刷盤適合那種對數(shù)據(jù)可靠性要求高的場景。
如果你需要使用同步刷盤機(jī)制,只需要在配置文件指定一下刷盤機(jī)制即可。
高可用
在說高可用之前,先來完善一下前面的一些概念。
在前面介紹概念的時(shí)候也說過,一個(gè)RokcetMQ中可以有很多個(gè)Broker實(shí)例,相同的BrokerName稱為一個(gè)組,同一個(gè)Broker組下每個(gè)Broker實(shí)例保存的消息是一樣的,不同的Broker組保存的消息是不一樣的。
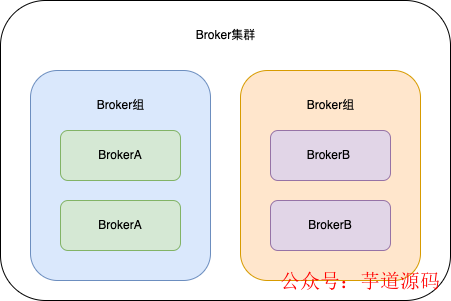
如圖所示,兩個(gè)BrokerA實(shí)例組成了一個(gè)Broker組,兩個(gè)BrokerB實(shí)例也組成了一個(gè)Broker組。
前面說過,每個(gè)Broker實(shí)例都有一個(gè)CommitLog文件來存儲消息的。那么兩個(gè)BrokerA實(shí)例他們CommitLog文件存儲的消息是一樣的,兩個(gè)BrokerB實(shí)例他們CommitLog文件存儲的消息也是一樣的。
那么BrokerA和BrokerB存的消息不一樣是什么意思呢?
其實(shí)很容易理解,假設(shè)現(xiàn)在有個(gè)topicA存在BrokerA和BrokerB上,那么topicA在BrokerA和BrokerB默認(rèn)都會有4個(gè)隊(duì)列。
前面在說發(fā)消息的時(shí)候需要選擇一個(gè)隊(duì)列進(jìn)行消息的發(fā)送,假設(shè)第一次選擇了BrokerA上的隊(duì)列發(fā)送消息,那么此時(shí)這條消息就存在BrokerA上,假設(shè)第二次選擇了BrokerB上的隊(duì)列發(fā)送消息,那么那么此時(shí)這條消息就存在BrokerB上,所以說BrokerA和BrokerB存的消息是不一樣的。
那么為什么同一個(gè)Broker組內(nèi)的Broker存儲的消息是一樣的呢?其實(shí)比較容易猜到,就是為了保證Broker的高可用,這樣就算Broker組中的某個(gè)Broker掛了,這個(gè)Broker組依然可以對外提供服務(wù)。
那么如何實(shí)現(xiàn)同Broker組的Broker存的消息數(shù)據(jù)相同的呢?這就不得不提到Broker的高可用模式。
RocketMQ提供了兩種Broker的高可用模式
- 主從同步模式
- Dledger模式
主從同步模式
在主從同步模式下,在啟動(dòng)的時(shí)候需要在配置文件中指定BrokerId,在同一個(gè)Broker組中,BrokerId為0的是主節(jié)點(diǎn)(master),其余為從節(jié)點(diǎn)(slave)。
當(dāng)生產(chǎn)者將消息寫入到主節(jié)點(diǎn)是,主節(jié)點(diǎn)會將消息內(nèi)容同步到從節(jié)點(diǎn)機(jī)器上,這樣一旦主節(jié)點(diǎn)宕機(jī),從節(jié)點(diǎn)機(jī)器依然可以提供服務(wù)。
主從同步主要同步兩部分?jǐn)?shù)據(jù)
- topic等數(shù)據(jù)
- 消息
topic等數(shù)據(jù)是從節(jié)點(diǎn)每隔10s鐘主動(dòng)去主節(jié)點(diǎn)拉取,然后更新本身緩存的數(shù)據(jù)。
消息是主節(jié)點(diǎn)主動(dòng)推送到從節(jié)點(diǎn)的。當(dāng)主節(jié)點(diǎn)收到消息之后,會將消息通過兩者之間建立的網(wǎng)絡(luò)連接發(fā)送出去,從節(jié)點(diǎn)接收到消息之后,寫到CommitLog即可。
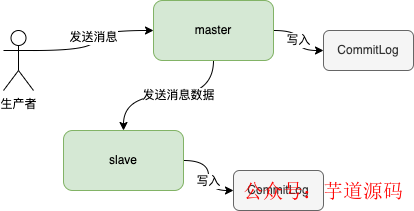
從節(jié)點(diǎn)有兩種方式知道主節(jié)點(diǎn)所在服務(wù)器的地址,第一種就是在配置文件指定;第二種就是從節(jié)點(diǎn)在注冊到NameServer的時(shí)候會返回主節(jié)點(diǎn)的地址。
主從同步模式有一個(gè)比較嚴(yán)重的問題就是如果集群中的主節(jié)點(diǎn)掛了,這時(shí)需要人為進(jìn)行干預(yù),手動(dòng)進(jìn)行重啟或者切換操作,而非集群自己從從節(jié)點(diǎn)中選擇一個(gè)節(jié)點(diǎn)升級為主節(jié)點(diǎn)。
為了解決上述的問題,所以RocketMQ在4.5.0就引入了Dledger模式。
Dledger模式
在Dledger模式下的集群會基于Raft協(xié)議選出一個(gè)節(jié)點(diǎn)作為leader節(jié)點(diǎn),當(dāng)leader節(jié)點(diǎn)掛了后,會從follower中自動(dòng)選出一個(gè)節(jié)點(diǎn)升級成為leader節(jié)點(diǎn)。所以Dledger模式解決了主從模式下無法自動(dòng)選擇主節(jié)點(diǎn)的問題。
在Dledger集群中,leader節(jié)點(diǎn)負(fù)責(zé)寫入消息,當(dāng)消息寫入leader節(jié)點(diǎn)之后,leader會將消息同步到follower節(jié)點(diǎn),當(dāng)集群中過半數(shù)(節(jié)點(diǎn)數(shù)/2 +1)節(jié)點(diǎn)都成功寫入了消息,這條消息才算真正寫成功。
至于選舉的細(xì)節(jié),這里就不多說了,有興趣的可以自行谷歌,還是挺有意思的。
消息消費(fèi)
終于,在生產(chǎn)者成功發(fā)送消息到Broker,Broker在成功存儲消息之后,消費(fèi)者要消費(fèi)消息了。
消費(fèi)者在啟動(dòng)的時(shí)候會從NameSrever拉取消費(fèi)者訂閱的topic的路由信息,這樣就知道訂閱的topic有哪些queue,以及queue所在Broker的地址信息。
為什么消費(fèi)者需要知道topic對應(yīng)的哪些queue呢?
其實(shí)主要是因?yàn)橄M(fèi)者在消費(fèi)消息的時(shí)候是以隊(duì)列為消費(fèi)單元的,消費(fèi)者需要告訴Broker拉取的是哪個(gè)隊(duì)列的消息,至于如何拉到消息的,后面再說。

消費(fèi)的兩種模式
前面說過,消費(fèi)者是有個(gè)消費(fèi)者組的概念,在啟動(dòng)消費(fèi)者的時(shí)候會指定該消費(fèi)者屬于哪個(gè)消費(fèi)者組。
DefaultMQPushConsumerconsumer=newDefaultMQPushConsumer("sanyouConsumer");
一個(gè)消費(fèi)者組中可以有多個(gè)消費(fèi)者,不同消費(fèi)者組之間消費(fèi)消息是互不干擾的。
在同一個(gè)消費(fèi)者組中,消息消費(fèi)有兩種模式。
- 集群模式
- 廣播模式
集群模式
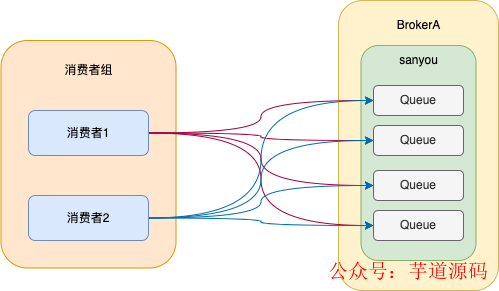
同一條消息只能被同一個(gè)消費(fèi)組下的一個(gè)消費(fèi)者消費(fèi),也就是說,同一條消息在同一個(gè)消費(fèi)者組底下只會被消費(fèi)一次,這就叫集群消費(fèi)。
集群消費(fèi)的實(shí)現(xiàn)就是將隊(duì)列按照一定的算法分配給消費(fèi)者,默認(rèn)是按照平均分配的。
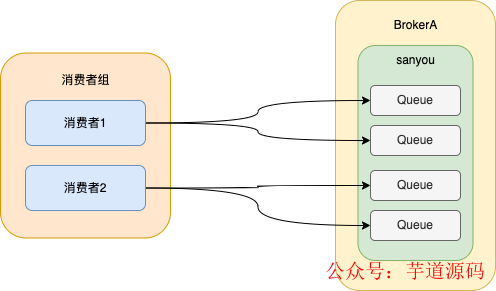
如圖所示,將每個(gè)隊(duì)列分配只分配給同一個(gè)消費(fèi)者組中的一個(gè)消費(fèi)者,這樣消息就只會被一個(gè)消費(fèi)者消費(fèi),從而實(shí)現(xiàn)了集群消費(fèi)的效果。
RocketMQ默認(rèn)是集群消費(fèi)的模式。
廣播模式
廣播模式就是同一條消息可以被同一個(gè)消費(fèi)者組下的所有消費(fèi)者消費(fèi)。
其實(shí)實(shí)現(xiàn)也很簡單,就是將所有隊(duì)列分配給每個(gè)消費(fèi)者,這樣每個(gè)消費(fèi)者都能讀取topic底下所有的隊(duì)列的數(shù)據(jù),就實(shí)現(xiàn)了廣播模式。
如果你想使用廣播模式,只需要在代碼中指定即可。
consumer.setMessageModel(MessageModel.BROADCASTING);
ConsumeQueue
上一節(jié)我們提到消費(fèi)者是從隊(duì)列中拉取消息的,但是這里不經(jīng)就有一個(gè)疑問,那就是消息明明都存在CommitLog文件中的,那么是如何去隊(duì)列中拉的呢?難道是去遍歷所有的文件,找到對應(yīng)隊(duì)列的消息進(jìn)行消費(fèi)么?
答案是否定的,因?yàn)檫@種每次都遍歷數(shù)據(jù)的效率會很低,所以為了解決這種問題,引入了ConsumeQueue的這個(gè)概念,而消費(fèi)實(shí)際是從ConsumeQueue中拉取數(shù)據(jù)的。
用戶在創(chuàng)建topic的時(shí)候,Broker會為topic創(chuàng)建隊(duì)列,并且每個(gè)隊(duì)列其實(shí)會有一個(gè)編號queueId,每個(gè)隊(duì)列都會對應(yīng)一個(gè)ConsumeQueue,比如說一個(gè)topic在某個(gè)Broker上有4個(gè)隊(duì)列,那么就有4個(gè)ConsumeQueue。
前面說過,消息在發(fā)送的時(shí)候,會根據(jù)一定的算法選擇一個(gè)隊(duì)列,之后再發(fā)送消息的時(shí)候會攜帶選擇隊(duì)列的queueId,這樣Broker就知道消息屬于哪個(gè)隊(duì)列的了。當(dāng)消息被存到CommitLog之后,其實(shí)還會往這條消息所在的隊(duì)列的ConsumeQueue插一條數(shù)據(jù)。
ConsumeQueue也是由多個(gè)文件組成,每個(gè)文件默認(rèn)是存30萬條數(shù)據(jù)。
插入ConsumeQueue中的每條數(shù)據(jù)由20個(gè)字節(jié)組成,包含3部分信息,消息在CommitLog的起始位置(8個(gè)字節(jié)),消息在CommitLog存儲的長度(8個(gè)字節(jié)),還有就是tag的hashCode(4個(gè)字節(jié))。
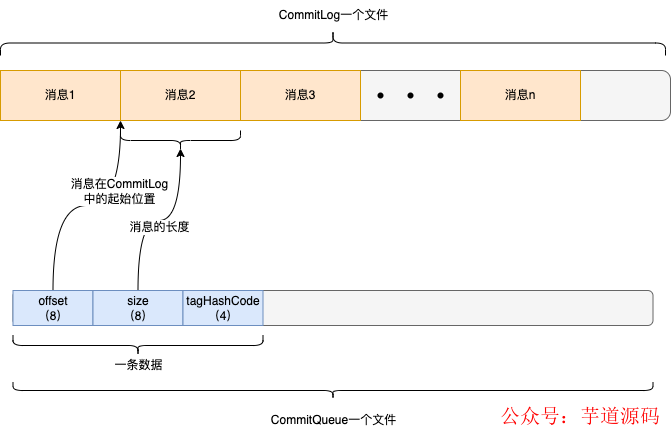
所以當(dāng)消費(fèi)者從Broker拉取消息的時(shí)候,會告訴Broker拉取哪個(gè)隊(duì)列(queueId)的消息、這個(gè)隊(duì)列的哪個(gè)位置的消息(queueOffset)。
queueOffset就是指上圖中ConsumeQueue一條數(shù)據(jù)的編號,單調(diào)遞增的。
Broker在接受到消息的時(shí)候,找個(gè)指定隊(duì)列的ConsumeQueue,由于每條數(shù)據(jù)固定是20個(gè)字節(jié),所以可以輕易地計(jì)算出queueOffset對應(yīng)的那條數(shù)據(jù)在哪個(gè)文件的哪個(gè)位置上,然后讀出20個(gè)字節(jié),從這20個(gè)字節(jié)中在解析出消息在CommitLog的起始位置和存儲的長度,之后再到CommitLog中去查找,這樣就找到了消息,然后在進(jìn)行一些處理操作返回給消費(fèi)者。
到這,我們就清楚的知道消費(fèi)者是如何從隊(duì)列中拉取消息的了,其實(shí)就是先從這個(gè)隊(duì)列對應(yīng)的ConsumeQueue中找到消息所在CommmitLog中的位置,然后再從CommmitLog中讀取消息的。
RocketMQ如何實(shí)現(xiàn)消息的順序性
這里插入一個(gè)比較常見的一個(gè)面試,那么如何保證保證消息的順序性。
其實(shí)要想保證消息的順序只要保證以下三點(diǎn)即可
- 生產(chǎn)者將需要保證順序的消息發(fā)送到同一個(gè)隊(duì)列
- 消息隊(duì)列在存儲消息的時(shí)候按照順序存儲
- 消費(fèi)者按照順序消費(fèi)消息

第一點(diǎn)如何保證生產(chǎn)者將消息發(fā)送到同一個(gè)隊(duì)列?
上文提到過RocketMQ生產(chǎn)者在發(fā)送消息的時(shí)候需要選擇一個(gè)隊(duì)列,并且選擇算法是可以自定義的,這樣我們只需要在根據(jù)業(yè)務(wù)需要,自定義隊(duì)列選擇算法,將順序消息都指定到同一個(gè)隊(duì)列,在發(fā)送消息的時(shí)候指定該算法,這樣就實(shí)現(xiàn)了生產(chǎn)者發(fā)送消息的順序性。
第二點(diǎn),RocketMQ在存消息的時(shí)候,是按照順序保存消息在ConsumeQueue中的位置的,由于消費(fèi)消息的時(shí)候是先從ConsumeQueue查找消息的位置,這樣也就保證了消息存儲的順序性。
第三點(diǎn)消費(fèi)者按照順序消費(fèi)消息,這個(gè)RocketMQ已經(jīng)實(shí)現(xiàn)了,只需要在消費(fèi)消息的時(shí)候指定按照順序消息消費(fèi)即可,如下面所示,注冊消息的監(jiān)聽器的時(shí)候使用MessageListenerOrderly這個(gè)接口的實(shí)現(xiàn)。
consumer.registerMessageListener(newMessageListenerOrderly(){
@Override
publicConsumeOrderlyStatusconsumeMessage(Listmsgs,ConsumeOrderlyContextcontext) {
//按照順序消費(fèi)消息記錄
returnnull;
}
});
消息清理
由于消息是存磁盤的,但是磁盤空間是有限的,所以對于磁盤上的消息是需要清理的。
當(dāng)出現(xiàn)以下幾種情況下時(shí)就會觸發(fā)消息清理:
- 手動(dòng)執(zhí)行刪除
- 默認(rèn)每天凌晨4點(diǎn)會自動(dòng)清理過期的文件
- 當(dāng)磁盤空間占用率默認(rèn)達(dá)到75%之后,會自動(dòng)清理過期文件
- 當(dāng)磁盤空間占用率默認(rèn)達(dá)到85%之后,無論這個(gè)文件是否過期,都會被清理掉
上述過期的文件是指文件最后一次修改的時(shí)間超過72小時(shí)(默認(rèn)情況下),當(dāng)然如果你的老板非常有錢,服務(wù)器的磁盤空間非常大,可以將這個(gè)過期時(shí)間修改的更長一點(diǎn)。
有的小伙伴肯定會有疑問,如果消息沒有被消息,那么會被清理么?
答案是會被清理的,因?yàn)榍謇硐⑹侵苯觿h除CommitLog文件,所以只要達(dá)到上面的條件就會直接刪除CommitLog文件,無論文件內(nèi)的消息是否被消費(fèi)過。
當(dāng)消息被清理完之后,消息也就結(jié)束了它精彩的一生。
消息的一生總結(jié)
為了更好地理解本文,這里再來總結(jié)一下RokcetMQ消息一生的各個(gè)環(huán)節(jié)。
消息發(fā)送
- 生產(chǎn)者產(chǎn)生消息
- 生產(chǎn)者在發(fā)送消息之前會拉取topic的路由信息
- 根據(jù)隊(duì)列選擇算法,從topic眾多的隊(duì)列中選擇一個(gè)隊(duì)列
- 跟隊(duì)列所在的Broker機(jī)器建立網(wǎng)絡(luò)連接,將消息發(fā)送到Broker上
消息存儲
- Broker接收到生產(chǎn)者的消息將消息存到CommitLog中
- 在CosumeQueue中存儲這條消息在CommitLog中的位置
由于CommitLog和CosumeQueue都涉及到磁盤文件的讀寫操作,為了提高讀寫效率,RokcetMQ使用到了零拷貝技術(shù),其實(shí)就是調(diào)用了一下Java提供的api。。
高可用
如果是集群模式,那么消息會被同步到從節(jié)點(diǎn),從節(jié)點(diǎn)會將消息存到自己的CommitLog文件中。這樣就算主節(jié)點(diǎn)掛了,從節(jié)點(diǎn)仍然可以對外提供訪問。
消息消費(fèi)
- 消費(fèi)者會拉取訂閱的Topic的路由信息,根據(jù)集群消費(fèi)或者廣播消費(fèi)的模式來選擇需要拉取消息的隊(duì)列
- 與隊(duì)列所在的機(jī)器建立連接,向Broker發(fā)送拉取消息的請求
- Broker在接收到請求知道,找到隊(duì)列對應(yīng)的ConsumeQueue,然后計(jì)算出拉取消息的位置,再解析出消息在CommitLog中的位置
- 根據(jù)解析出的位置,從CommitLog中讀出消息的內(nèi)容返回給消費(fèi)者
消息清理
由于消息是存在磁盤的,而磁盤的空間是有限的,所以RocketMQ會根據(jù)一些條件去清理CommitLog文件。
審核編輯 :李倩
-
算法
+關(guān)注
關(guān)注
23文章
4615瀏覽量
93000 -
服務(wù)器
+關(guān)注
關(guān)注
12文章
9206瀏覽量
85563 -
隊(duì)列
+關(guān)注
關(guān)注
1文章
46瀏覽量
10917
原文標(biāo)題:面試官喜歡問RocketMQ,那就好好準(zhǔn)備下
文章出處:【微信號:芋道源碼,微信公眾號:芋道源碼】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
求大神幫忙設(shè)計(jì)一款電源!好人一生平安
求一個(gè)一生產(chǎn)者多消費(fèi)者的例子
雷軍:做芯片“九死一生”,是什么讓小米堅(jiān)持研發(fā)?

宇宙中那些短暫而劇烈的電磁爆發(fā)現(xiàn)象
一生的職業(yè)生涯都耗費(fèi)在研究真空管上的人

RocketMQ和RabbitMQ的區(qū)別
“一生一芯”廈門基地正式啟動(dòng)

矽速科技宣布認(rèn)可“一生一芯”計(jì)劃CBAS新認(rèn)證體系,獲認(rèn)證同學(xué)自動(dòng)獲得開源實(shí)習(xí)生聯(lián)合培養(yǎng)工程的實(shí)習(xí)OF

2024“一生一芯”暑期宣講會圓滿成功
RT-Thread宣布認(rèn)可“一生一芯”計(jì)劃CBAS新認(rèn)證體系,獲認(rèn)證同學(xué)自動(dòng)獲得開源實(shí)習(xí)生聯(lián)合培養(yǎng)工程的實(shí)習(xí)OFFER






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論