 內存和磁盤的關系&數據壓縮(下)
內存和磁盤的關系&數據壓縮(下)
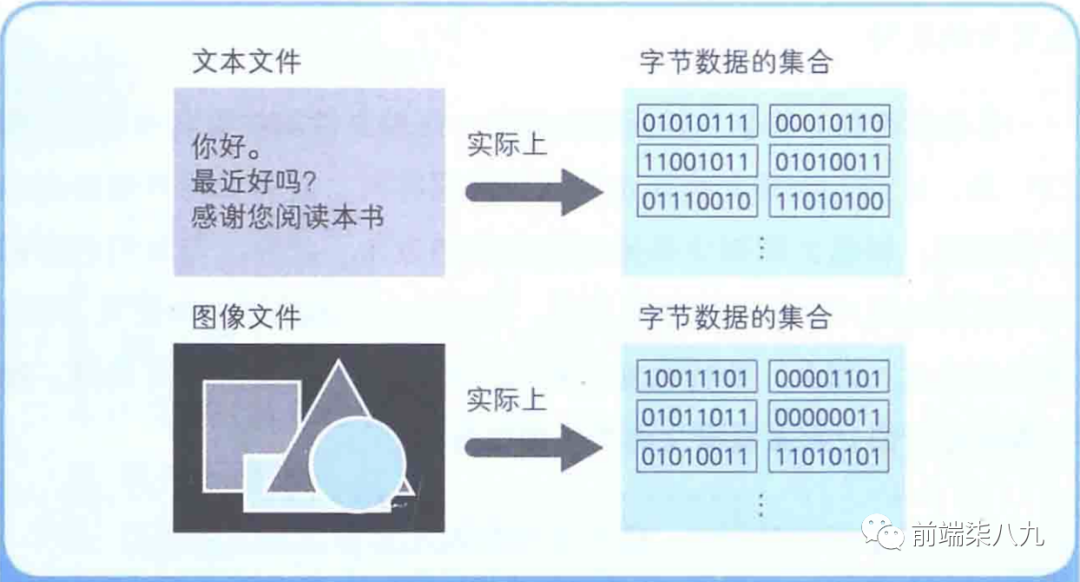
文件以字節位單位保存
文件是將數據存儲在磁盤等存儲媒介中的一種形式。程序文件中存儲數據的單位是 「字節」 。文件的大小之所以用xxKB、xxMB等來表示,就是因為文件是以字節(B = Byte)為單位來存儲的。
?文件就是**「字節數據的集合」**
?
用1字節(=8位)表示的字節數據有256種,用二進制數來表示的話,其范圍就是00000000~11111111。
- 如果文件中存儲的數據是文字,那么該文件就是**「文本文件」**
- 如果是圖形,那么該文件就是 「圖像文件」 。
?在任何情況下,文件中的字節數據都是 「連續存儲」 的。
?
RLE算法
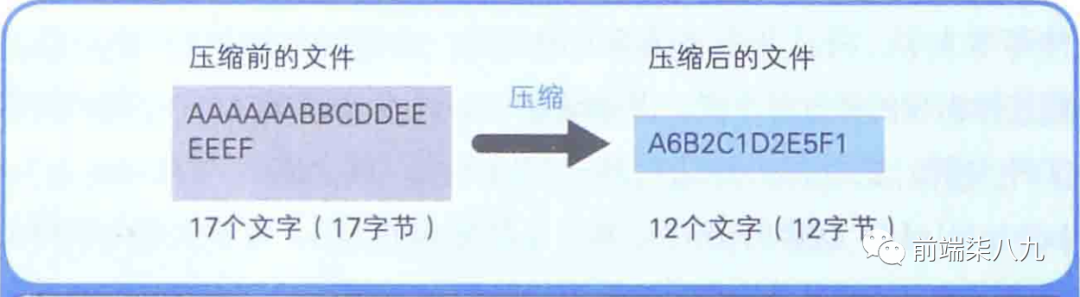
我們來嘗試對存儲著AAAAAABBCDDEEEEEF這17個 「半角字符」 的文本文件進行壓縮。
由于半角字母中, 「1個字符是作為1個字節」 的數據被保存在文件中的。因此,上述文件的大小就是17個字節。
我們可以采用將文件的內容用 「字符 × 重復次數」 這樣的表現方式來壓縮。所以,AAAAAABBCDDEEEEEF就可以用A6B2C1D2E5F1來表示。而A6B2C1D2E5F1是12個字符,那么對應的文本文件就變成了12字節。
12字節÷17字節 ≈70%。也就是采用上述的方式,使得文件壓縮到原來大小的70%。
把文件內容用 「數據 × 重復次數」 的形式來表示的壓縮方法稱為RLE(Run Length Encoding,行程長度編碼)算法
RLE算法的缺點
然而在實際的文本文件中,同樣字符多次重復出現的情況并不多見。雖然針對 「相同數據經常連續出現」 的圖像、文件等,RLE算法可以發揮不錯,但是它并不適合文本文件的壓縮。
哈夫曼算法
「哈夫曼算法」 是哈夫曼與1952年提出來的壓縮算法。
針對,哈夫曼算法,首先要拋棄 「半角英文數字的1個字符是1個字節(8位)的數據」 這一概念。
文本文件是由不同類型的字符組合而成的,而且不同的字符出現的次數也是不同的。例如,在某一個文本文件中,A出現了100次,Q出現了3次。
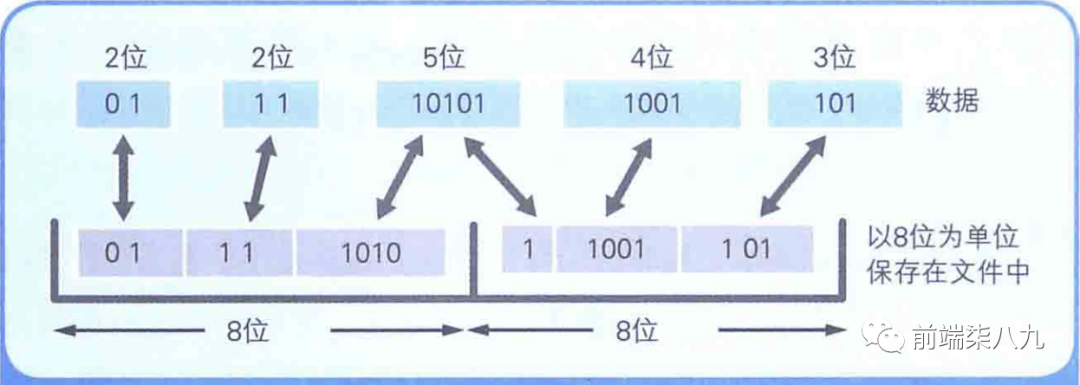
? 「哈夫曼算法」 的關鍵就在于 「多次出現的數據用小于8位的字節數來表示,不常用的數據則用超過8位的字節數來表示」 。
?
當A和Q都用8位來表示時,原文件的大小就是100次 × 8位 + 3次 × 8位 = 824位,而假設A用2位,Q用10位表示,壓縮后的大小就是100次 × 2位 + 3次 × 10位 = 230位。
不過,有一點需要注意,
?不管是不滿8位的數據,還是超過8位的數據,最終都要 「以8位為單位保存到文件中」 。
?
這是因為磁盤是以字節(8位)為單位來保存數據的。
用二叉樹實現哈夫曼編碼
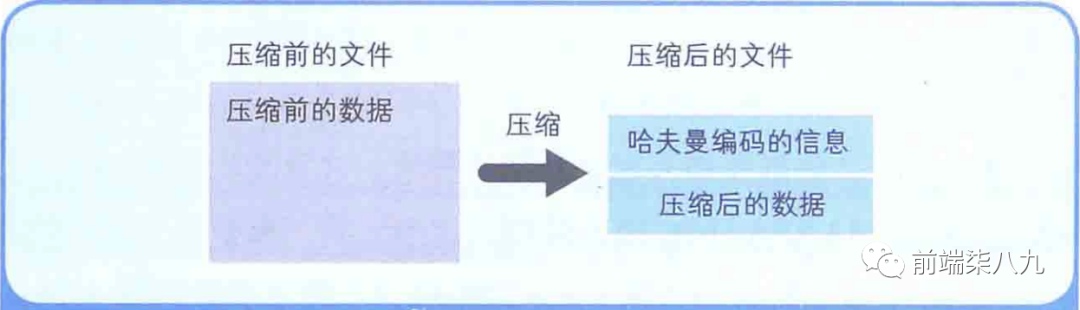
哈夫曼算法是指,為 「各壓縮對象文件」 分別構造最佳的編碼體系,并以該編碼體系為基礎來進行壓縮。因此,用什么樣的編碼(哈夫曼編碼)對數據進行分割,就要由各個文件而定。
用哈夫曼算法壓縮過的文件中,存儲著哈夫曼編碼信息和壓縮過的數據。
在哈夫曼算法中,通過借助 「哈夫曼樹」 構造編碼體系,即使在不使用字符區分符號的情況下,也可以構建能夠明確進行區分的編碼體系。也就是說,利用哈夫曼樹后,就算表示各字符的數據 「位數」 不同,也能夠做成明確區分的編碼。
制作哈夫曼樹
自然界的樹是從根開始生枝長葉,而哈夫曼樹是 「從葉生枝,然后再生根」 。

哈夫曼算法能夠大幅度提升壓縮比率
使用哈夫曼樹后,出現 「頻率越高的數據所占用的數據位數就越少」 ,而且數據的區分也可以很清晰的實現。
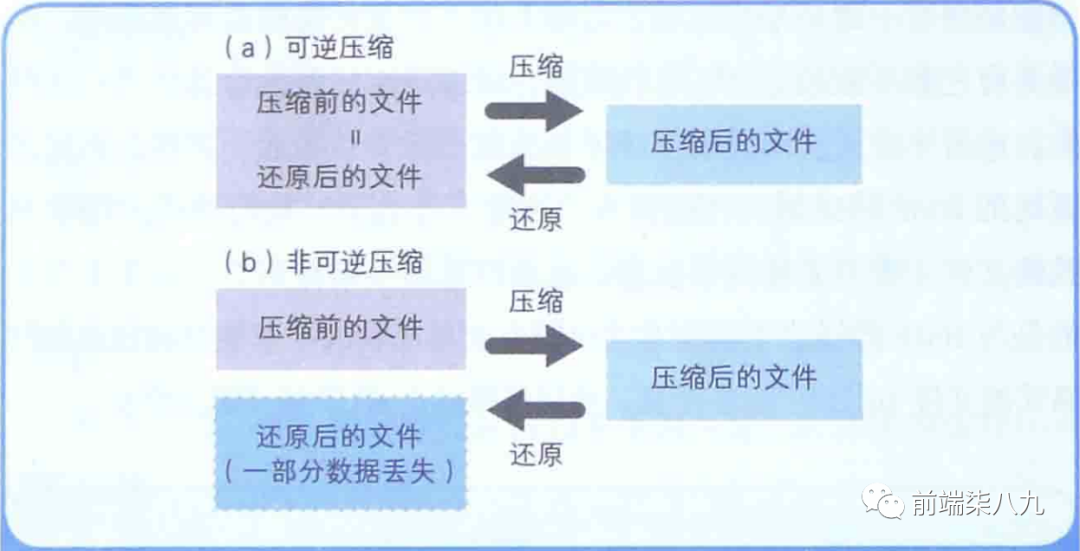
可逆壓縮和非可逆壓縮
- 「可逆壓縮」 :能還原到壓縮前狀態的壓縮
- 「非可逆壓縮」 :無法還原到壓縮前狀態的壓縮
-
cpu
+關注
關注
68文章
10858瀏覽量
211643 -
計算機
+關注
關注
19文章
7490瀏覽量
87889 -
計數器
+關注
關注
32文章
2256瀏覽量
94499
發布評論請先 登錄
相關推薦
【TL6748 DSP申請】井下數據壓縮技術
請問有沒有32可用的數據壓縮算法?
【ELT.ZIP】OpenHarmony啃論文俱樂部——多層存儲分級數據壓縮
【學習打卡】【ELT.ZIP】OpenHarmony啃論文俱樂部——多層存儲分級數據壓縮
數據壓縮技術
JPEG2000數據壓縮的FPGA實現
數據壓縮的重要性
數據壓縮算法計算步驟及過程
有趣!史記:數據壓縮算法列傳
內存和磁盤的關系&amp;數據壓縮(上)
高性能無損數據壓縮FPGA IP,LZO無損數據壓縮IP





 工商網監
工商網監
評論