 正則表達式(RegularExpression)使用指南
正則表達式(RegularExpression)使用指南
在芯片開發過程中,正則表達式的使用非常常見。初次上手晦澀難懂,多用幾次愛不釋手!
本文將概述正則表達式以及實用的匹配規則,并給出使用表達式的輔助工具:CheatSheet和在線測試工具。
01 正則表達式概述
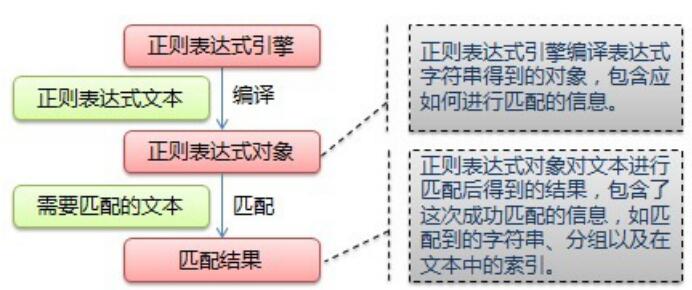
正則表達式,Regular Expression,或縮寫regexp,是一種用于描述文本模式(pattern)的表達式。通過該文本模式,我們可以從文本中高效和準確地匹配查找到想要的字符串。
正則表達式的搜索和匹配功能非常強大,以至于幾乎所有的腳本語言(比如Python, Perl,JavaScript),Java等高級編程語言,甚至grep等一些Linux命令,都支持正則表達式。
在芯片開發過程中,難免會有很多膠水腳本(glue script)用來串接各種流程,也就不可避免的需要對流程中產生的中間文件做處理,可能是提取、刪除或者修改內容等等。另外,在代碼review、仿真調試等階段,通常需要對代碼或者仿真日志做信息檢索或數據有效性檢查。
而這些,都是正則表達式在芯片開發過程中大顯身手的地方。
02 Cheat Sheet
CheatSheet可作為日常工具手冊,用戶可以快速地查閱正則表達式的匹配規則。不過,實際經驗告訴我,多用了幾次之后,常用的匹配規則也就都記住了。

03 常用關系特性
從CheatSheet可以直接看到正則表達式最基礎的匹配規則,包括匹配數字、字母、空白、通配符、開頭、結尾等等。但在實際使用中,還需要考慮一些匹配關系,這也是本小節想要呈現的內容。
> 捕獲分組(capturing group)和非捕獲分組(non-capturing group)
在正則表達式中,可以使用圓括號對表達式進行分組。在匹配完成后,就可以使用分組編號來對圓括號中的內容進行提取。默認情況下,整個表達式的分組編號是0,之后從左往右每遇到一個”(”就分配一個遞增的分組編號。舉個栗子:
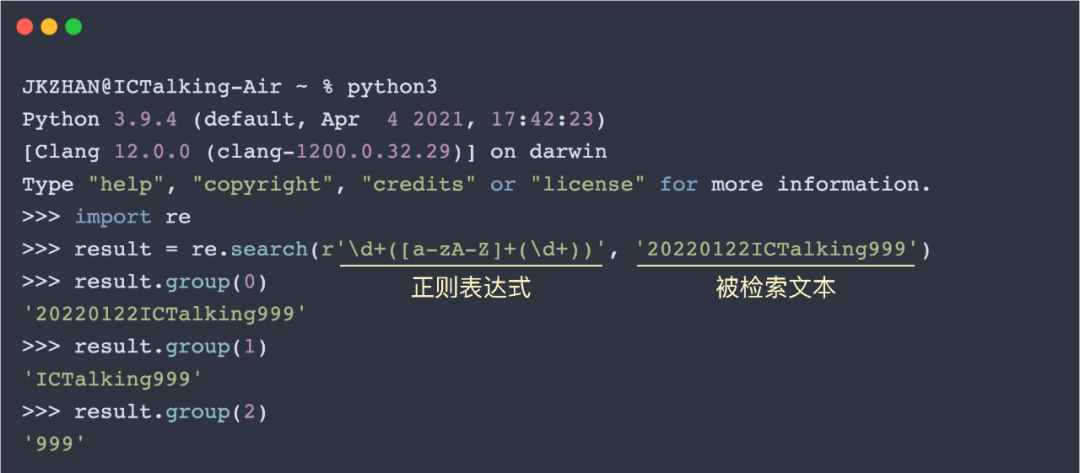
除了如上圖所示直接使用分組編號對匹配結果進行索引,我們還可以在表達式內進行分組命名,這樣就可以是使用組名來進行索引。舉個栗子:
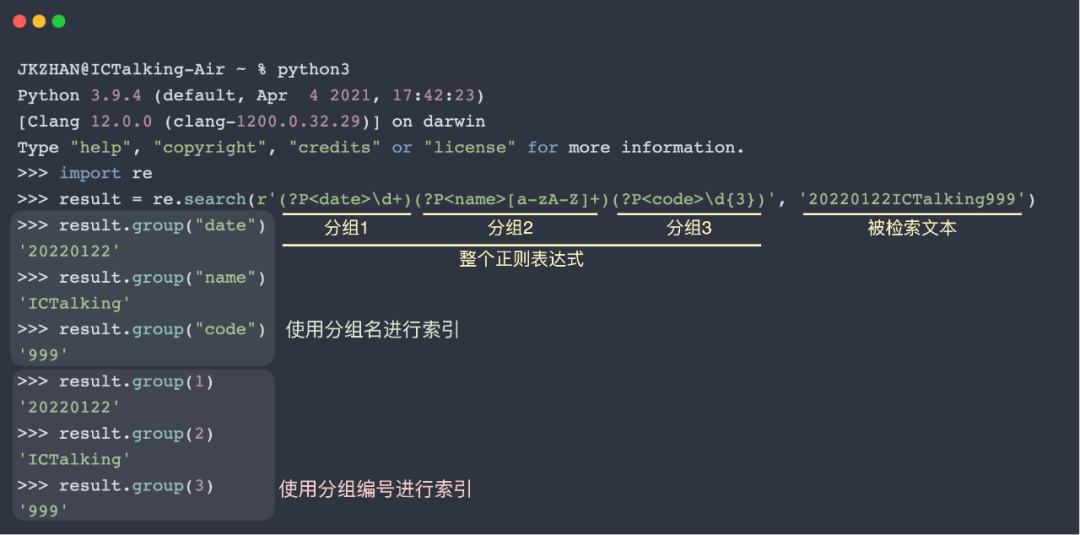
非捕獲分組同樣使用小括號來進行匹配,其格式是(?:exp)。非捕獲分組只能在當前的位置匹配文本,不會被分配分組編號,也即是說,在匹配完成之后無法通過分組編號對其進行索引。
> 前向匹配(lookahead)和后向匹配(lookbehind)
前向匹配和后向匹配,嚴格來講也是非捕獲分組。在有些地方會叫做環視(lookaround),意味著在匹配的時候需要先“環顧四周”。前后向匹配在實際應用中非常常用。
前向匹配(?=exp),用來匹配右邊跟著指定字符串的文本;后向匹配(?<=exp),用來匹配左邊跟著指定字符串的文本。舉個栗子,匹配2022年且日期為22號的月份:
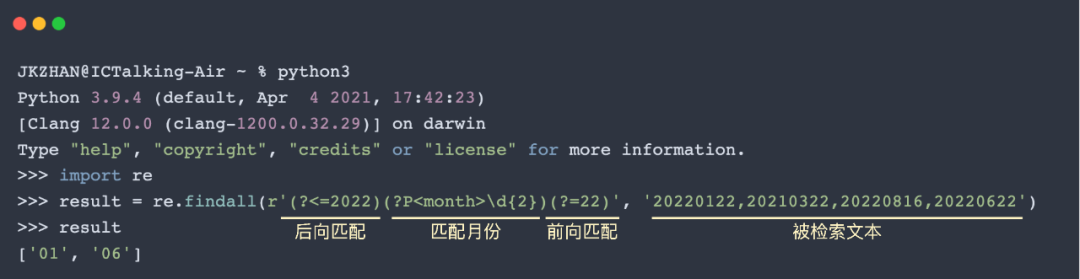
相反,通過把前后匹配表達式中的”=“改成”!”,即(?
> 貪婪匹配(greedy)和非貪婪匹配(non-greedy)
貪婪程度指的是正則表達式匹配停止的條件,貪婪模式會盡可能多的匹配,非貪婪模式會盡可能少的匹配。
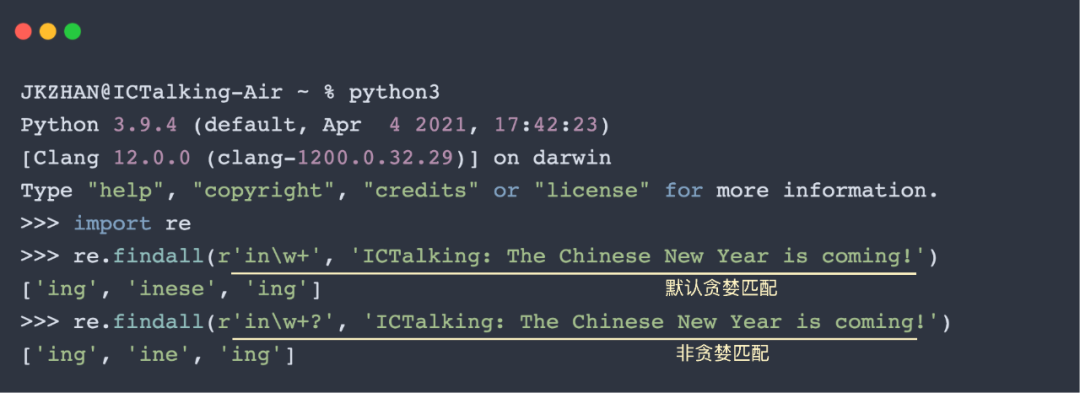
默認的匹配模式是貪婪模式,舉個栗子:d+可以匹配大于1個數字的字符串,那么針對被檢索文本“20220122”,正則表達式默認盡可能多的匹配,即匹配整個“20220122”,因為它都滿足“大于1個數字的字符串”這個pattern,而不是只匹配第一個數字“2”或匹配部分數字“20220”。
非貪婪匹配也是非常常用的匹配模式,有些地方會叫做懶惰匹配(lazy),但都是一個意思:通過添加?來改變正則表達式匹配停止的條件。舉個栗子:
04 測試工具
這里推薦正則表達式的在線測試工具。在該網站上,提供了正則表達式的使用參考,并且可以供用戶測試自己寫出來的正則表達式是否符合預期。
審核編輯:湯梓紅
-
Linux
+關注
關注
87文章
11378瀏覽量
211339 -
JAVA
+關注
關注
19文章
2980瀏覽量
105715 -
編程語言
+關注
關注
10文章
1952瀏覽量
35278 -
腳本語言
+關注
關注
0文章
48瀏覽量
8314 -
正則表達式
+關注
關注
0文章
27瀏覽量
3576
原文標題:芯片開發必備工具 | 正則表達式(RegularExpression)使用指南
文章出處:【微信號:處芯積律,微信公眾號:處芯積律】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
什么是正則表達式?正則表達式如何工作?哪些語法規則適用正則表達式?
shell正則表達式學習
深入淺出boost正則表達式
關于java正則表達式的用法詳解
快速入門IPv6和正則表達式

Python正則表達式教程之標準庫的完整介紹及使用示例說明

Python正則表達式的學習指南

Python正則表達式指南
python正則表達式中的常用函數
Linux入門之正則表達式
shell腳本基礎:正則表達式grep






 工商網監
工商網監
評論