") 納多德端到端IB解決方案
納多德端到端IB解決方案
在 ChatGPT 引爆科技領(lǐng)域之后,人們一直在討論 AI「下一步」的發(fā)展會(huì)是什么,很多學(xué)者都提到了多模態(tài),我們并沒有等太久。近期,OpenAI 發(fā)布了多模態(tài)預(yù)訓(xùn)練大模型 GPT-4,GPT-4 實(shí)現(xiàn)了以下幾個(gè)方面的飛躍式提升:強(qiáng)大的識(shí)圖能力、文字輸入限制提升至 2.5 萬字、回答準(zhǔn)確性顯著提高、能夠生成歌詞、創(chuàng)意文本,實(shí)現(xiàn)風(fēng)格變化。
如此高效的迭代,離不開人工智能大規(guī)模模型訓(xùn)練,需要大量的計(jì)算資源和高速的數(shù)據(jù)傳輸網(wǎng)絡(luò)。其中,端到端IB(InfiniBand)網(wǎng)絡(luò)是一種高性能計(jì)算網(wǎng)絡(luò),特別適合用于高性能計(jì)算和人工智能模型訓(xùn)練。本文將介紹什么是AIGC模型訓(xùn)練,為什么需要端到端IB網(wǎng)絡(luò)以及如何使用ChatGPT模型進(jìn)行AIGC訓(xùn)練。
AIGC是什么?
AIGC 即 AI Generated Content,是指人工智能自動(dòng)生成內(nèi)容,可用于繪畫、寫作、視頻等多種類型的內(nèi)容創(chuàng)作。2022年AIGC高速發(fā)展,這其中深度學(xué)習(xí)模型不斷完善、開源模式的推動(dòng)、大模型探索商業(yè)化的可能,成為AIGC發(fā)展的“加速度”。以最近爆火的聊天機(jī)器人ChatGPT為例,這款機(jī)器人既會(huì)寫論文,也能創(chuàng)作小說,還可編代碼,上線僅2個(gè)月,月活用戶達(dá)1億。因?yàn)槌龊跻饬系摹奥斆鳌保珹IGC被認(rèn)為是“科技行業(yè)的下一個(gè)顛覆者”“內(nèi)容生產(chǎn)力的一次重大革命”。
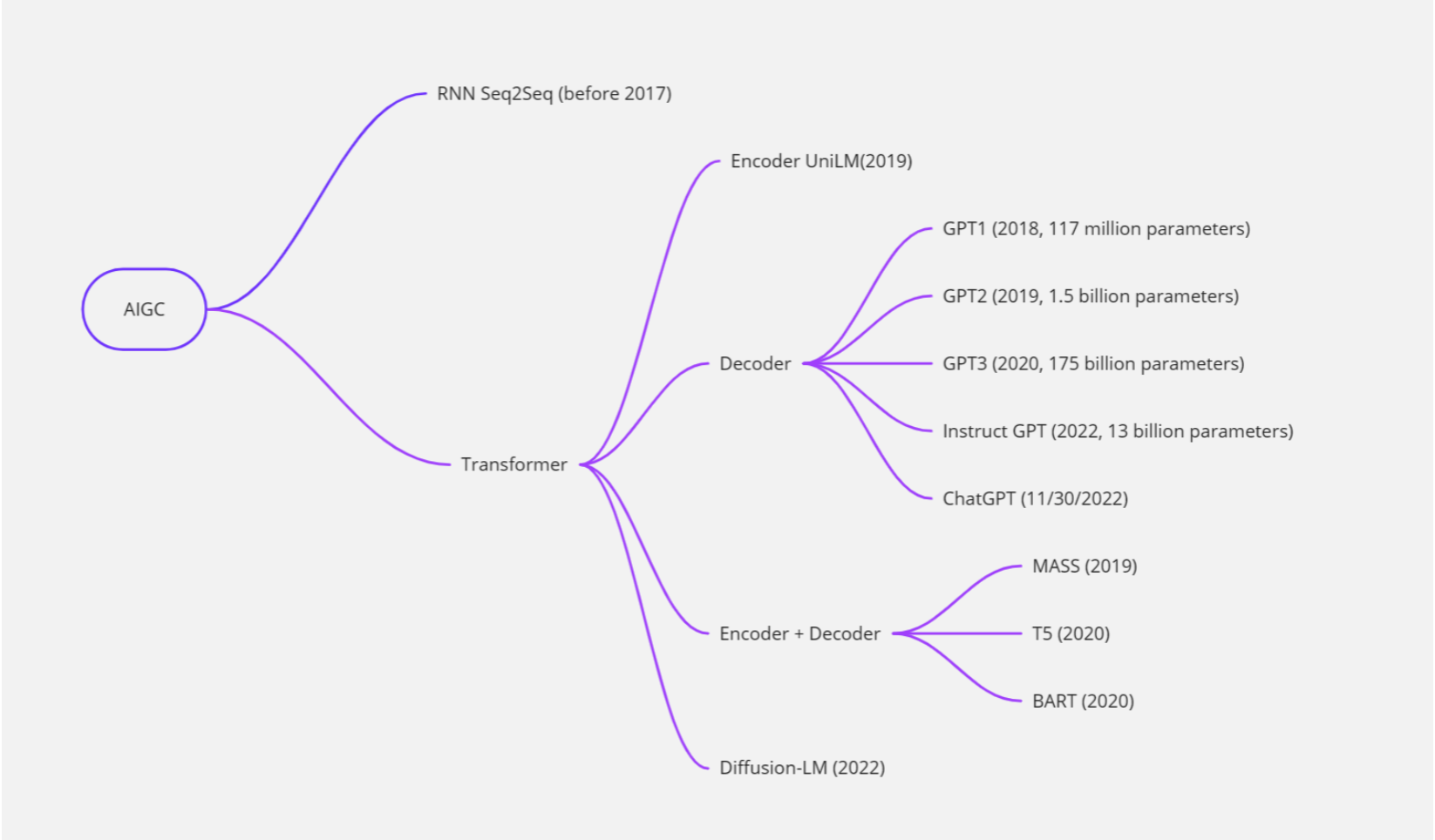
大型語言模型(LLM)和ChatGPT
大型語言模型(Large Language Model)是一種能夠自動(dòng)學(xué)習(xí)并理解自然語言的人工智能技術(shù)。它通常基于深度學(xué)習(xí)算法,通過對(duì)大量文本數(shù)據(jù)的學(xué)習(xí)來獲取語言知識(shí),并能夠自動(dòng)生成自然語言文本,如對(duì)話、文章等。
ChatGPT是一種基于大型語言模型的聊天機(jī)器人,它采用了OpenAI開發(fā)的GPT(Generative Pre-trained Transformer)模型,通過對(duì)大量文本數(shù)據(jù)的預(yù)訓(xùn)練和微調(diào),能夠生成富有語言表達(dá)力的自然語言文本,并實(shí)現(xiàn)與用戶的交互。
因此,可以說ChatGPT是一種基于大型語言模型技術(shù)的聊天機(jī)器人,它利用了大型語言模型的強(qiáng)大語言理解和生成能力,從而能夠在對(duì)話中進(jìn)行自然語言文本的生成和理解。
隨著深度學(xué)習(xí)技術(shù)的發(fā)展,大型語言模型的能力和規(guī)模不斷提升。最初的語言模型(如N-gram模型)只能考慮有限的上下文信息,而現(xiàn)代的大型語言模型(如BERT、GPT-3等)能夠考慮更長(zhǎng)的上下文信息,并且具有更強(qiáng)的泛化能力和生成能力。
大型語言模型通常采用深度神經(jīng)網(wǎng)絡(luò)進(jìn)行訓(xùn)練,如循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)、長(zhǎng)短時(shí)記憶網(wǎng)絡(luò)(LSTM)、門控循環(huán)單元(GRU)和變壓器網(wǎng)絡(luò)(Transformer)等。在訓(xùn)練中,模型利用大規(guī)模的文本數(shù)據(jù)集,采用無監(jiān)督或半監(jiān)督的方式進(jìn)行訓(xùn)練。例如,BERT模型通過預(yù)測(cè)掩碼、下一個(gè)句子等任務(wù)來訓(xùn)練,而GPT-3則采用了大規(guī)模的自監(jiān)督學(xué)習(xí)方式。
大型語言模型在自然語言處理領(lǐng)域有廣泛的應(yīng)用,例如機(jī)器翻譯、自然語言生成、問答系統(tǒng)、文本分類、情感分析等。
當(dāng)前訓(xùn)練LLM的瓶頸在哪里?
在訓(xùn)練大型語言模型時(shí),需要高速、可靠的網(wǎng)絡(luò)來傳輸大量的數(shù)據(jù)。例如OpenAI發(fā)布了第一版GPT模型(GPT-1),其模型規(guī)模為1.17億個(gè)參數(shù)。之后,OpenAI相繼發(fā)布了GPT-2和GPT-3等更大的模型,分別擁有1.5億和1.75萬億個(gè)參數(shù)。如此大的參數(shù)在單機(jī)訓(xùn)練是完全不可能的,需要高度依賴GPU計(jì)算集群,目前的瓶頸在于如何解決訓(xùn)練集群中各節(jié)點(diǎn)之間高效通信的問題。
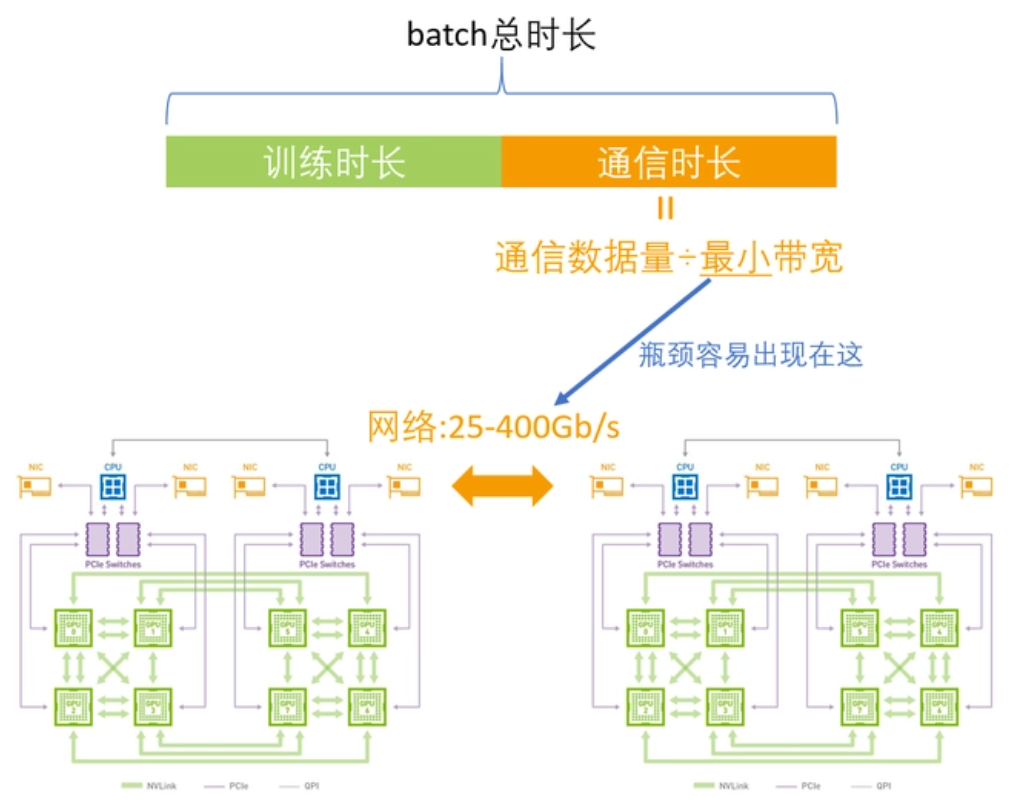
目前比較常用的GPU通信算法就是Ring-Allreduce。其基本思想就是讓GPU形成一個(gè)環(huán),讓數(shù)據(jù)在環(huán)內(nèi)流動(dòng)。環(huán)中的GPU都被安排在一個(gè)邏輯中,每個(gè)GPU有一個(gè)左鄰和一個(gè)右鄰,它只會(huì)向它的右鄰居發(fā)送數(shù)據(jù),并從它的左鄰居接收數(shù)據(jù)。
該算法分兩個(gè)步驟進(jìn)行:首先是scatter-reduce,然后是allgather。在scatter-reduce步驟中,GPU將交換數(shù)據(jù),使每個(gè)GPU可得到最終結(jié)果的一個(gè)塊。在allgather步驟中,GPU將交換這些塊,以便所有GPU得到完整的最終結(jié)果。
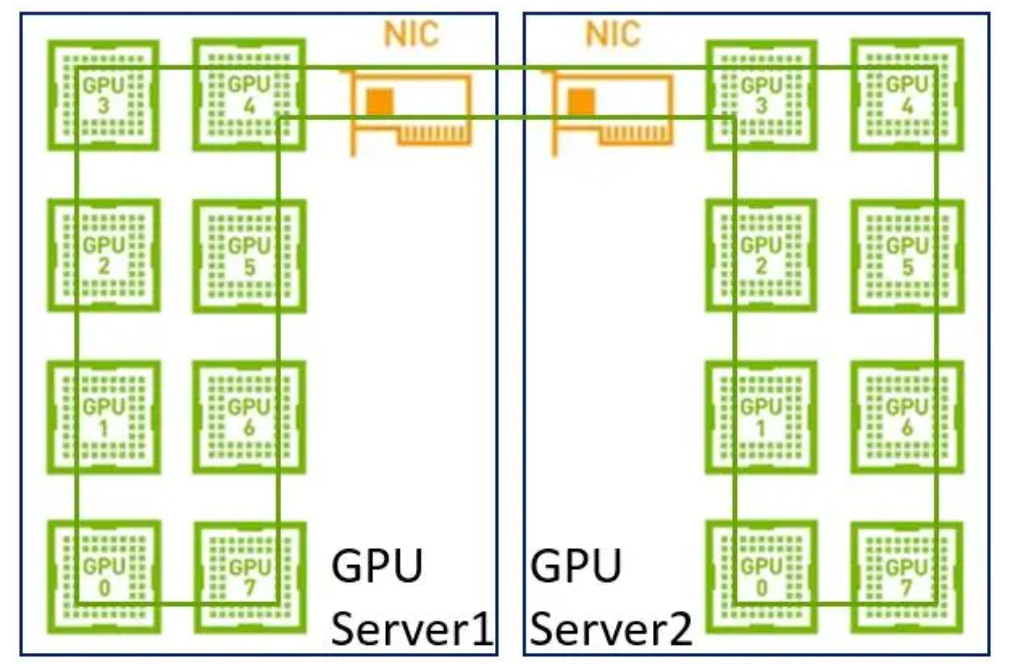
在早期,單機(jī)內(nèi)部沒有NVLink,網(wǎng)絡(luò)上沒有RDMA,帶寬相對(duì)較低,單機(jī)分布式和多機(jī)分布式在帶寬上沒太大差別,所以建一個(gè)大環(huán)即可。
但是現(xiàn)在我們單機(jī)內(nèi)部有了NVLink,在使用同樣的方法就不合適了。因?yàn)榫W(wǎng)絡(luò)的帶寬是遠(yuǎn)低于NVLink,如果再用一個(gè)大環(huán),那會(huì)導(dǎo)致NVLink的高帶寬被嚴(yán)重拉低到網(wǎng)絡(luò)的水平。其次,現(xiàn)在是具備多網(wǎng)卡的環(huán)境,如果只用一個(gè)環(huán)也無法充分利用多網(wǎng)卡優(yōu)勢(shì)。
因此,在這樣的場(chǎng)景下建議采用兩級(jí)環(huán):首先利用NVLink高帶寬優(yōu)勢(shì)在單機(jī)內(nèi)部的GPU之間完成數(shù)據(jù)同步;然后多機(jī)之間的GPU利用多網(wǎng)卡建立多個(gè)環(huán),對(duì)不同分段數(shù)據(jù)進(jìn)行同步;最后單機(jī)內(nèi)部的GPU再同步一次,最終完成全部GPU的數(shù)據(jù)同步,在這里就不得不提到NCCL。
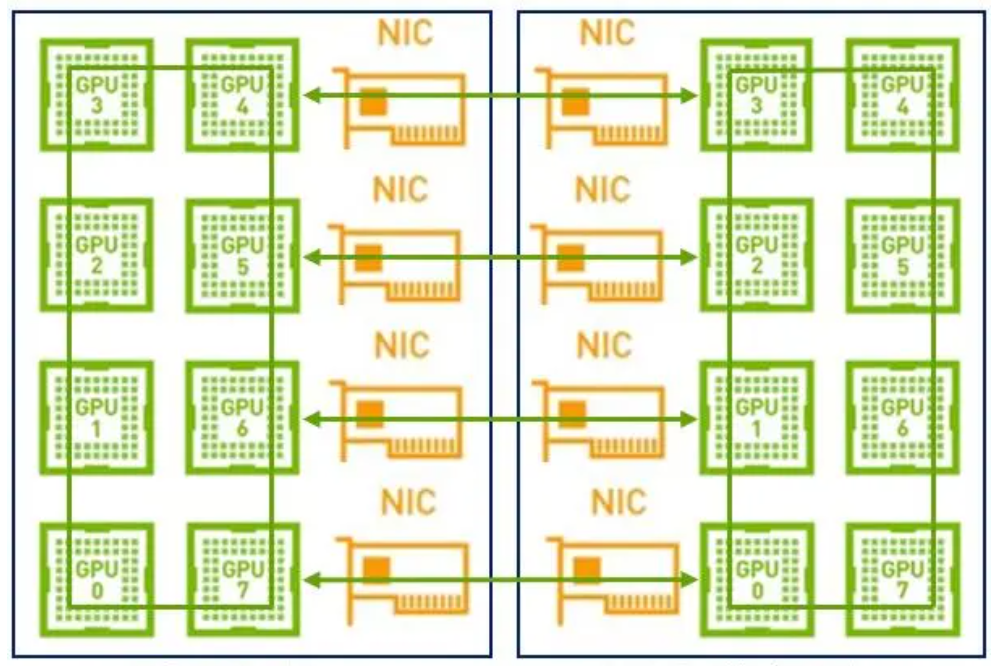
NVIDIA集體通信庫(NCCL)實(shí)現(xiàn)了針對(duì)NVIDIA GPU和網(wǎng)絡(luò)優(yōu)化的多GPU和多節(jié)點(diǎn)通信原語。
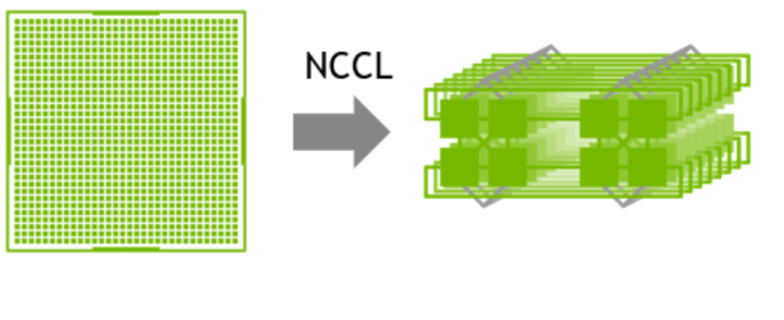
1GPU->multi-GPU multi node
NCCL提供全收集、全減、廣播、減少、減少散射以及點(diǎn)對(duì)點(diǎn)發(fā)送和接收等例程,這些例程經(jīng)過優(yōu)化,通過節(jié)點(diǎn)內(nèi)和NVIDIA Mellanox網(wǎng)絡(luò)通過PCIe和NVLink高速互連實(shí)現(xiàn)高帶寬和低延遲。
為什么要使用端到端IB網(wǎng)絡(luò)?
以太網(wǎng)是一種廣泛使用的網(wǎng)絡(luò)協(xié)議,但其傳輸速率和延遲無法滿足大型模型訓(xùn)練的需求。相比之下,端到端IB(InfiniBand)網(wǎng)絡(luò)是一種高性能計(jì)算網(wǎng)絡(luò),能夠提供高達(dá) 400 Gbps 的傳輸速率和微秒級(jí)別的延遲,遠(yuǎn)高于以太網(wǎng)的性能。這使得IB網(wǎng)絡(luò)成為大型模型訓(xùn)練的首選網(wǎng)絡(luò)技術(shù)。
此外,端到端IB網(wǎng)絡(luò)還支持?jǐn)?shù)據(jù)冗余和糾錯(cuò)機(jī)制,能夠保證數(shù)據(jù)傳輸?shù)目煽啃浴_@在大型模型訓(xùn)練中尤為重要,因?yàn)樵谔幚砣绱硕嗟臄?shù)據(jù)時(shí),數(shù)據(jù)傳輸錯(cuò)誤或數(shù)據(jù)丟失可能會(huì)導(dǎo)致訓(xùn)練過程中斷甚至失敗。
隨著網(wǎng)絡(luò)節(jié)點(diǎn)數(shù)目的急劇增加和計(jì)算能力不斷上升,高性能計(jì)算消除性能瓶頸和改進(jìn)系統(tǒng)管理變得比以往更加重要。InfiniBand被認(rèn)為是可以提升當(dāng)前I/O架構(gòu)性能瓶頸的一種極具潛力的I/O技術(shù),如圖所示。InfiniBand是一種普及的、低延遲的、高帶寬的互連通信協(xié)議,處理開銷很低,非常適合在單個(gè)連接上承載多種流量類型(集群、通信、存儲(chǔ)和管理)。1999年,IBTA (InfiniBand Trade Association)制定了InfiniBand相關(guān)標(biāo)準(zhǔn),在InfiniBand?中規(guī)范定義了用于互連服務(wù)器、通信基礎(chǔ)設(shè)施設(shè)備、存儲(chǔ)和嵌入式系統(tǒng)的輸入/輸出體系結(jié)構(gòu)。InfiniBand是一項(xiàng)成熟的、經(jīng)過現(xiàn)場(chǎng)驗(yàn)證的技術(shù),被廣泛應(yīng)用于高性能計(jì)算集群中。
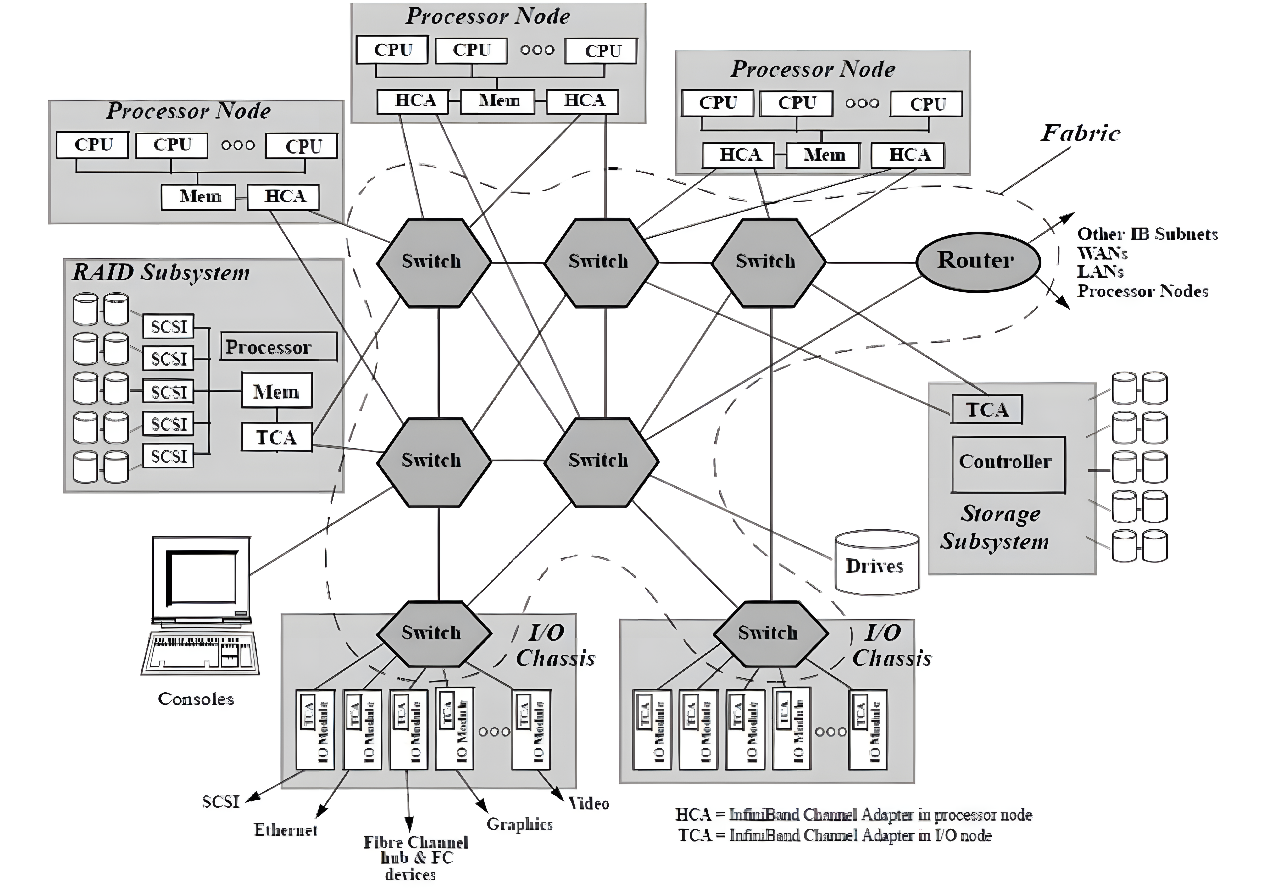
InfiniBand互連架構(gòu)圖
InfiniBand互聯(lián)協(xié)議中規(guī)定,每個(gè)端節(jié)點(diǎn)必須有一個(gè)主機(jī)通道適配器(HCA)來設(shè)置和維護(hù)與主機(jī)設(shè)備的鏈接,交換機(jī)包含多個(gè)端口,并將數(shù)據(jù)包從一個(gè)端口轉(zhuǎn)發(fā)到另一個(gè)端口,完成在子網(wǎng)內(nèi)傳輸數(shù)據(jù)的功能。子網(wǎng)管理器(Subnet Manager, SM)用于配置其本地子網(wǎng)并確保其持續(xù)運(yùn)行,借助子網(wǎng)管理器數(shù)據(jù)包(Subnet Manager Packet, SMP)和每個(gè)InfiniBand設(shè)備上的子網(wǎng)管理代理(Subnet Manager Agent, SMA),子網(wǎng)管理器發(fā)現(xiàn)并初始化網(wǎng)絡(luò),為所有設(shè)備分配唯一標(biāo)識(shí)符,確定MTU(Maximum Transmission Unit,最小傳輸單元),并根據(jù)選定的路由算法生成交換機(jī)路由表。SM還定期對(duì)子網(wǎng)進(jìn)行光掃描,以檢測(cè)任何拓?fù)渥兓⑾鄳?yīng)地配置網(wǎng)絡(luò)。與其他網(wǎng)絡(luò)通信協(xié)議相比,InfiniBand網(wǎng)絡(luò)提供了更高的帶寬、更低的延遲和更強(qiáng)的可擴(kuò)展性。此外,由于InfiniBand提供了基于credit的流控制(其中發(fā)送方節(jié)點(diǎn)發(fā)送的數(shù)據(jù)不會(huì)超過鏈路另一端的接收緩沖區(qū)公布的credit數(shù)量),傳輸層不需要像TCP窗口算法那樣的丟包機(jī)制來確定最佳的正在傳輸?shù)臄?shù)據(jù)包數(shù)量,這使得InfiniBand網(wǎng)絡(luò)能夠以極低的延遲和極低的CPU使用率為應(yīng)用程序提供極高的數(shù)據(jù)傳輸速率。InfiniBand使用RDMA技術(shù)(Remote Direct Memory Access,遠(yuǎn)程直接內(nèi)存訪問)將數(shù)據(jù)從通道一端傳輸?shù)搅硪欢耍琑DMA是一種通過網(wǎng)絡(luò)在應(yīng)用程序之間直接傳輸數(shù)據(jù)的協(xié)議,無需操作系統(tǒng)的參與,同時(shí)消耗雙方極低的CPU資源(零拷貝傳輸),一端的應(yīng)用程序只需直接從內(nèi)存中讀取消息,消息就已成功傳輸,減少的CPU開銷增加了網(wǎng)絡(luò)快速傳輸數(shù)據(jù)的能力,并允許應(yīng)用程序更快地接收數(shù)據(jù)。
納多德端到端IB網(wǎng)絡(luò)解決方案
納多德基于對(duì)高速率網(wǎng)絡(luò)發(fā)展趨勢(shì)的理解,和豐富的HPC、AI項(xiàng)目實(shí)施經(jīng)驗(yàn),提供基于NVIDIA Quantum-2交換機(jī)、 ConnectX InfiniBand 智能網(wǎng)卡和靈活的400Gb/s InfiniBand端到端解決方案,在降低成本和復(fù)雜性的同時(shí)在高性能計(jì)算 (HPC)、AI 和超大規(guī)模云基礎(chǔ)設(shè)施中帶來超強(qiáng)性能。
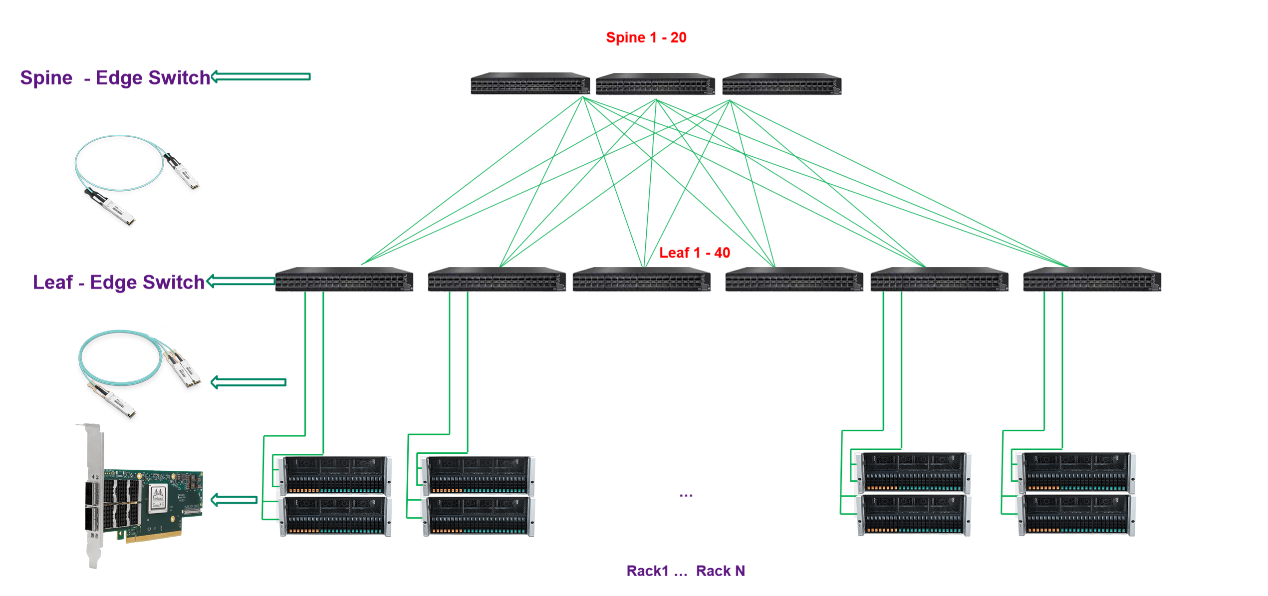
納多德數(shù)據(jù)中心IB網(wǎng)絡(luò)解決方案
交換機(jī)
更快的服務(wù)器、高性能存儲(chǔ)和日益復(fù)雜的計(jì)算應(yīng)用正在將數(shù)據(jù)帶寬要求推向新的高度。NVIDIA Mellanox QM9700 交換機(jī)提供具有極低的延遲,NVIDIA Quantum-2 采用第七代 NVIDIA InfiniBand 架構(gòu),可為 AI 開發(fā)者和科學(xué)研究人員提供超強(qiáng)網(wǎng)絡(luò)性能和豐富功能,幫助他們解決充滿挑戰(zhàn)性的問題。NVIDIA Quantum-2 通過軟件定義網(wǎng)絡(luò)、網(wǎng)絡(luò)計(jì)算、性能隔離、高級(jí)加速引擎、遠(yuǎn)程直接內(nèi)存訪問 (RDMA) 以及高達(dá) 400 Gb/s 的超快的速度,為先進(jìn)的超級(jí)計(jì)算數(shù)據(jù)中心提供助力。
智能網(wǎng)卡
納多德在網(wǎng)卡側(cè)提供NVIDIA ConnectX SmartNIC智能網(wǎng)卡,NVIDIA ConnectX InfiniBand 智能網(wǎng)卡支持更快的速度和創(chuàng)新的網(wǎng)絡(luò)計(jì)算技術(shù),實(shí)現(xiàn)了超強(qiáng)性能和可擴(kuò)展性。NVIDIA ConnectX 降低了每次操作的成本,從而可為高性能計(jì)算 (HPC)、機(jī)器學(xué)習(xí)、高性能存儲(chǔ)及數(shù)據(jù)庫業(yè)務(wù)和低延遲嵌入式等應(yīng)用提高投資回報(bào)率。來自 NVIDIA Quantum-2 InfiniBand 架構(gòu)的 ConnectX-7 智能網(wǎng)卡(HCA)可提供超高的網(wǎng)絡(luò)性能,用于處理極具挑戰(zhàn)性的工作負(fù)載。ConnectX-7 支持超低時(shí)延、400Gb/s 吞吐量和創(chuàng)新的 NVIDIA 網(wǎng)絡(luò)計(jì)算加速引擎,實(shí)現(xiàn)額外加速,為超級(jí)計(jì)算機(jī)、人工智能和超大規(guī)模云數(shù)據(jù)中心提供所需的高可擴(kuò)展性和功能豐富的技術(shù)。
光模塊
納多德提供靈活的NVIDIA 400Gb/s InfiniBand光連接方案,包括使用單模和多模收發(fā)器、MPO光纖跳線、有源銅纜(ACC)和無源銅纜(DAC),用以滿足搭建各種網(wǎng)絡(luò)拓?fù)涞男枰?/p>
>配有帶鰭設(shè)計(jì)的 OSFP 連接器的雙端口收發(fā)器適用于風(fēng)冷固定配置交換機(jī),而配有扁平式OSFP 連接器的雙端口收發(fā)器則適用于液冷模塊化交換機(jī)和 HCA 中。
>在交換機(jī)互連上,可選擇采用全新OSFP封裝 2XNDR(800Gbps) 光模塊進(jìn)行兩臺(tái) QM9700交換機(jī)的互連,帶鰭的設(shè)計(jì),可以大大提高光模塊散熱性。
>交換機(jī)和HCA的互聯(lián)上,交換機(jī)端采用OSFP封裝2xNDR(800Gbps)帶鰭光模塊,網(wǎng)卡端采用帶有扁平OSFP 400Gbps光模塊,MPO光纖跳線可提供3-150米,一對(duì)二分光器光纖可提供3-50米。
>交換機(jī)到HCA的連接也提供DAC(最長(zhǎng)1.5米)或者ACC(最長(zhǎng)3米)的解決方案,一對(duì)二式分接線纜可用于交換機(jī)的一個(gè)OSFP端口(配備兩個(gè)400Gb/s InfiniBand端口)和兩個(gè)獨(dú)立的400Gb/s HCA。一分四式分接線纜可用于連接交換機(jī)的一個(gè)OSFP交換機(jī)端口和四個(gè)200Gb/s HCA。
納多德是光網(wǎng)絡(luò)解決方案的領(lǐng)先提供商,是NVIDIA網(wǎng)絡(luò)產(chǎn)品的Elite Partner,攜手NVIDIA實(shí)現(xiàn)光連接+網(wǎng)絡(luò)產(chǎn)品與解決方案的強(qiáng)強(qiáng)聯(lián)合,尤其是在InfiniBand高性能網(wǎng)絡(luò)建設(shè)與應(yīng)用加速方面擁有深刻的業(yè)務(wù)理解和豐富的項(xiàng)目實(shí)施經(jīng)驗(yàn),可根據(jù)用戶不同的應(yīng)用場(chǎng)景,提供最優(yōu)的InfiniBand高性能交換機(jī)+智能網(wǎng)卡+AOC/DAC/光模塊產(chǎn)品組合方案,為數(shù)據(jù)中心、高性能計(jì)算、邊緣計(jì)算、人工智能等應(yīng)用場(chǎng)景提供更具優(yōu)勢(shì)與價(jià)值的光網(wǎng)絡(luò)產(chǎn)品和整體解決方案,以低成本和出色的性能,大幅提高客戶業(yè)務(wù)加速能力。
審核編輯:湯梓紅
-
NVIDIA
+關(guān)注
關(guān)注
14文章
4994瀏覽量
103159 -
光模塊
+關(guān)注
關(guān)注
77文章
1269瀏覽量
59038 -
ChatGPT
+關(guān)注
關(guān)注
29文章
1563瀏覽量
7759 -
AIGC
+關(guān)注
關(guān)注
1文章
362瀏覽量
1556
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
恩智浦完整的Matter端到端解決方案
華為端到端解決方案
集成數(shù)據(jù)網(wǎng)絡(luò)端到端和段到段監(jiān)測(cè)解決方案
Airvana宣布全球首個(gè)端到端LTE毫微微蜂窩解決方案
USB Type-C端到端解決方案的應(yīng)用
首個(gè)基于APP應(yīng)用端的5G SA端到端切片解決方案成功實(shí)現(xiàn)
中興通訊端到端傳輸解決方案實(shí)現(xiàn)承載業(yè)務(wù)“光速直達(dá)”
松下幫助高校提供端到端解決方案
是德科技發(fā)布端到端PCIe5.0/6.0測(cè)試解決方案
端到端NVMe解決方案簡(jiǎn)介

語音識(shí)別技術(shù):端到端的挑戰(zhàn)與解決方案
華為IPv6+端到端解決方案通過信通院IPv6+ 2.0 Advanced測(cè)試評(píng)估

Mobileye端到端自動(dòng)駕駛解決方案的深度解析






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論