") 河套IT TALK 67: (原創(chuàng)) 基于深度學(xué)習(xí)的超分技術(shù)(萬(wàn)字長(zhǎng)文)
河套IT TALK 67: (原創(chuàng)) 基于深度學(xué)習(xí)的超分技術(shù)(萬(wàn)字長(zhǎng)文)


當(dāng)我們談?wù)?a href="http://www.1cnz.cn/v/" target="_blank">視頻技術(shù)時(shí),超高清視頻(Ultra High Definition,簡(jiǎn)稱UHD)無(wú)疑是當(dāng)今最令人興奮的領(lǐng)域之一。上期,我們介紹了使用復(fù)雜的算法來(lái)創(chuàng)建一個(gè)三維聲場(chǎng),給觀眾帶來(lái)音頻的空間感、方位感、高還原度、高沉浸度、臨場(chǎng)感,個(gè)性化的三維聲技術(shù)。本期,我們就聊聊最近非常火的基于深度學(xué)習(xí)的超分技術(shù)。
關(guān)聯(lián)回顧
全圖說(shuō)電視的發(fā)展歷史
全圖說(shuō)視頻編解碼的發(fā)展歷史
由淺入深說(shuō)高清——聊聊高動(dòng)態(tài)范圍(HDR)
由淺入深說(shuō)高清——HDR的標(biāo)準(zhǔn)之爭(zhēng)
由淺入深說(shuō)高清——HDR的適配性與流程化的挑戰(zhàn)由淺入深說(shuō)高清——讓人眼花繚亂的超高清視頻編解碼格式由淺入深說(shuō)高清——超高清視頻的三維聲技術(shù)1. 前言
視頻超分技術(shù)(Video super-resolution),簡(jiǎn)稱VSR,是將低分辨率(Low Resolution,簡(jiǎn)稱:LR)的視頻轉(zhuǎn)換為高分辨率(High Resolution,簡(jiǎn)稱:HR)視頻的過(guò)程。與單圖像超分技術(shù)(Single Image Super-Resolution,簡(jiǎn)稱:SISR)不同,這不是把視頻圖像的每一幀恢復(fù)到更多的細(xì)節(jié),更重要的是能夠保持整個(gè)視頻幀的運(yùn)動(dòng)一致性。
為什么我們不直接看高分辨率的視頻,而要使用超分技術(shù)去逆向轉(zhuǎn)換呢?答案也非常簡(jiǎn)單:因?yàn)闆]有高清片源。高清視頻是最近幾年才火起來(lái)的事情,在這之前大量的視頻片源就沒有高清。而且我們經(jīng)常在手機(jī)上觀看以為的高清視頻,投射到大的液晶屏幕上,就顯得模糊不清,因?yàn)橥瑯酉袼氐囊曨l內(nèi)容,被延展到更大屏幕上,只會(huì)把原本很小的彩色像素點(diǎn)拉成一個(gè)一個(gè)肉眼可見的彩色小方塊。如果不通過(guò)超分技術(shù),要么忍受這種模糊,要么就只能在高清電視上重新去搜索匹配的高清片源,但又要花錢不是?能搜到片源還算好的,好多時(shí)候,花錢也未必能解決問(wèn)題。比如在醫(yī)學(xué)圖像領(lǐng)域(MRT、CT、PET等等),出于圖像掃描技術(shù)的局限,片源的分辨率很難做上來(lái),如果沒有超分技術(shù),那些原始醫(yī)療圖像掃描完,醫(yī)生看到就都是慘不忍睹的噪點(diǎn)。
第一次正式提出深度學(xué)習(xí)這個(gè)詞兒的是加州大學(xué)的計(jì)算機(jī)科學(xué)教授麗娜·德克特(Rina Dechter)。她在 1986 年的一篇論文中率先使用了深度學(xué)習(xí)(Deep Learning)。深度學(xué)習(xí)是機(jī)器學(xué)習(xí)的一種,它使用多層人工神經(jīng)網(wǎng)絡(luò) (ANN) 對(duì)數(shù)據(jù)中的復(fù)雜模式進(jìn)行建模。對(duì)于必須將多少層的 ANN 視為“深度”并沒有嚴(yán)格的規(guī)定,但通常,具有多個(gè)隱藏層的神經(jīng)網(wǎng)絡(luò)可被視為深度學(xué)習(xí)模型。實(shí)際上,深度學(xué)習(xí)模型可以有幾十層、幾百層甚至幾千層。然而,層數(shù)本身并不是決定深度學(xué)習(xí)模型性能的唯一因素,其他因素如每層神經(jīng)元數(shù)量、使用的激活函數(shù)和訓(xùn)練方法也會(huì)對(duì)深度學(xué)習(xí)模型產(chǎn)生重大影響。模型的有效性。
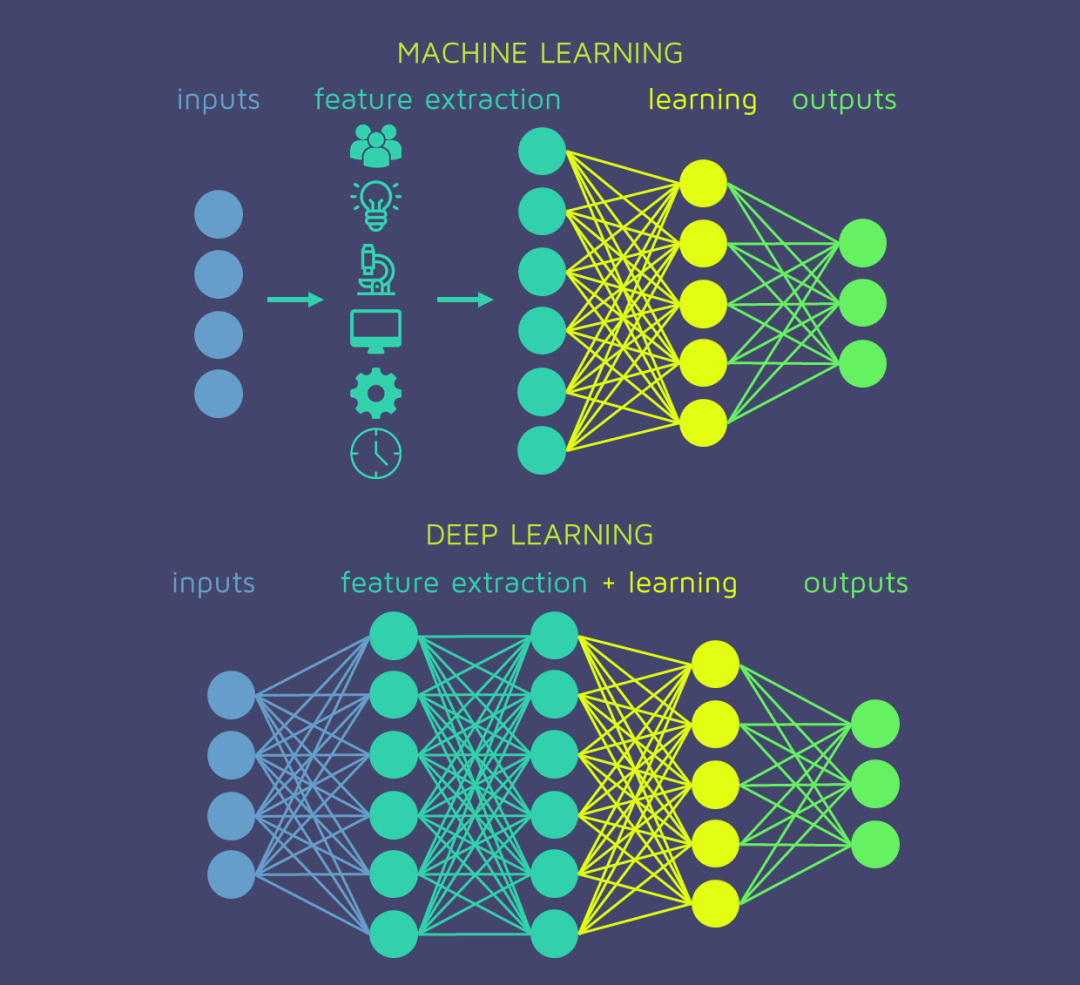
深度學(xué)習(xí)使用多層從原始輸入中逐步提取更高級(jí)別的特征。例如,在圖像處理中,較低層可以識(shí)別邊緣,而較高層可以識(shí)別與人類相關(guān)的概念,例如數(shù)字、字母或面孔。從另一個(gè)角度來(lái)看深度學(xué)習(xí),深度學(xué)習(xí)是指“計(jì)算機(jī)模擬”或“自動(dòng)化”人類從源(例如,狗的圖像)到學(xué)習(xí)對(duì)象(狗)的學(xué)習(xí)過(guò)程。
深度學(xué)習(xí)的算法本來(lái)就有很多種,比較經(jīng)典的包括:深度神經(jīng)網(wǎng)絡(luò)(Deep Neural Networks, 簡(jiǎn)稱DNN)、深度置信網(wǎng)絡(luò)(Deep Belief Networks, 簡(jiǎn)稱DBN)、深度強(qiáng)化學(xué)習(xí)(Deep Reinforcement Learning, 簡(jiǎn)稱DRN)、遞歸神經(jīng)網(wǎng)絡(luò)(Recurrent Neural Networks, 簡(jiǎn)稱RNN)、卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Networks, 簡(jiǎn)稱CNN)以及我們最近非常火的應(yīng)用在ChatGPT中的Transformer。這些算法被廣泛應(yīng)用在計(jì)算機(jī)視覺、語(yǔ)音識(shí)別、自然語(yǔ)言處理、機(jī)器翻譯、生物信息學(xué)、藥物設(shè)計(jì)、氣象科學(xué)、信息管理等領(lǐng)域。視頻超分當(dāng)然是其中的熱門應(yīng)用場(chǎng)景。
3. 為什么現(xiàn)在才熱起來(lái)?你可能會(huì)好奇,為啥基于深度學(xué)習(xí)的視頻超分技術(shù)最近才火起來(lái)?深度學(xué)習(xí)也不是一個(gè)新鮮概念了。萬(wàn)事萬(wàn)物的發(fā)展都是相互關(guān)聯(lián)和相互促進(jìn)的,任何技術(shù)領(lǐng)域的拐點(diǎn)或者奇點(diǎn)爆發(fā),都是經(jīng)過(guò)長(zhǎng)時(shí)間的鋪墊和蓄能醞釀。在25年前,我還在讀研究生的時(shí)候,當(dāng)時(shí)的課題就是通過(guò)神經(jīng)網(wǎng)絡(luò)的方式用紫外光傳感器對(duì)制冷系統(tǒng)中潤(rùn)滑油質(zhì)量分?jǐn)?shù)的實(shí)時(shí)測(cè)量。我理解為什么深度學(xué)習(xí)被研究人員一直追捧,但總是雷聲大雨點(diǎn)小,主要有以下幾個(gè)約束:1. 計(jì)算機(jī)的處理性能;2. 網(wǎng)絡(luò)速度的局限;3. 學(xué)習(xí)樣本的局限,以及在學(xué)習(xí)樣本中的數(shù)字版權(quán)問(wèn)題;4. 缺乏良好的開源軟件管理系統(tǒng)讓算法被充分共享。近些年,以上瓶頸都已經(jīng)化解,深度學(xué)習(xí)開始出現(xiàn)了爆炸式的增長(zhǎng)。
4. 基于深度學(xué)習(xí)的超分技術(shù)的優(yōu)勢(shì)有一些傳統(tǒng)的超分技術(shù),包括小波變換和第二代小波變換的頻域超分技術(shù)、使用卡爾曼濾波器的迭代自適應(yīng)濾波算法、最大后驗(yàn)(MAP)和馬爾可夫隨機(jī)場(chǎng)(MRF)的概率方法等等,毫無(wú)疑問(wèn),這些傳統(tǒng)超分技術(shù)表現(xiàn)并不如意。近期,基于深度學(xué)習(xí)的視頻超分算法表現(xiàn)出了比傳統(tǒng)超分算法明顯的優(yōu)勢(shì),主要表現(xiàn)以下幾點(diǎn):
-
-
學(xué)習(xí)復(fù)雜關(guān)系的能力強(qiáng):傳統(tǒng)方法依靠手工制作的特征和啟發(fā)式方法在低分辨率視頻幀中插入缺失的信息。這限制了他們學(xué)習(xí)低分辨率和高分辨率視頻幀之間復(fù)雜關(guān)系的能力,并且他們可能無(wú)法生成視覺上令人愉悅的高辨率視頻。基于深度學(xué)習(xí)的方法可以學(xué)習(xí)低分辨率和高分辨率視頻幀之間更復(fù)雜的關(guān)系,使它們能夠產(chǎn)生更準(zhǔn)確和視覺上令人愉悅的結(jié)果。
-
不必依賴特定運(yùn)動(dòng)模型:傳統(tǒng)方法假設(shè)視頻幀有特定的運(yùn)動(dòng)模型,例如全局運(yùn)動(dòng)或塊運(yùn)動(dòng)。這會(huì)限制它們處理視頻幀之間復(fù)雜運(yùn)動(dòng)的能力,并可能導(dǎo)致運(yùn)動(dòng)偽影和高辨率視頻中的模糊。基于深度學(xué)習(xí)的方法可以處理視頻幀之間的復(fù)雜運(yùn)動(dòng)。
-
計(jì)算成本低:傳統(tǒng)方法的計(jì)算成本可能很高,并且可能需要大量計(jì)算資源才能生成高分辨率視頻。這限制了它們實(shí)時(shí)執(zhí)行超分計(jì)算的能力,并可能使它們對(duì)某些應(yīng)用不切實(shí)際。許多基于深度學(xué)習(xí)的視頻超分方法可以實(shí)時(shí)進(jìn)行超分計(jì)算,這對(duì)于低成本視頻流和實(shí)時(shí)視頻分析等應(yīng)用很重要。
- 對(duì)噪聲和偽影的魯棒性強(qiáng):傳統(tǒng)方法對(duì)輸入視頻幀中的噪聲和偽影敏感,并且在面對(duì)嘈雜或低質(zhì)量輸入幀時(shí)可能會(huì)產(chǎn)生模糊或失真的結(jié)果。而基于深度學(xué)習(xí)的方法對(duì)輸入視頻幀中的噪聲和偽影的魯棒性更強(qiáng),即使輸入幀有噪聲或失真,也能生成高質(zhì)量的高辨率視頻。
-
正是因?yàn)榍懊嫣岬降膬?yōu)勢(shì),使得基于深度學(xué)習(xí)的超分技術(shù)最近成為視頻處理和計(jì)算機(jī)視覺領(lǐng)域許多應(yīng)用的熱門選擇,顯示出巨大潛力。現(xiàn)在,深度學(xué)習(xí)如春筍般在超分技術(shù)領(lǐng)域開得漫山遍野,但目前尚未出現(xiàn)一種深度學(xué)習(xí)的超分算法展露絕對(duì)的優(yōu)勢(shì),達(dá)到普遍“令人滿意”的狀態(tài)。以至于直到當(dāng)下,不管在研究領(lǐng)域,還是在生態(tài)運(yùn)用領(lǐng)域,所有的算法都是百花爭(zhēng)鳴,各有千秋。之所以出現(xiàn)這種狀況,有以下幾個(gè)原因:
-
-
不同的數(shù)據(jù)集:基于深度學(xué)習(xí)的視頻超分算法需要在特定的數(shù)據(jù)集上進(jìn)行訓(xùn)練和評(píng)估,以確保其有效性。然而,不同的數(shù)據(jù)集具有不同的特征,例如分辨率、噪聲水平和運(yùn)動(dòng)模式。這會(huì)影響視頻超分算法的性能,這意味著在一個(gè)數(shù)據(jù)集上表現(xiàn)良好的方法在另一個(gè)數(shù)據(jù)集上可能表現(xiàn)不佳。這其實(shí)也暴露了深度學(xué)習(xí)一直以來(lái)的問(wèn)題,就是結(jié)果的不可預(yù)知性。
-
不同視頻類型的運(yùn)動(dòng)特征差異巨大:視頻幀可以有不同類型的運(yùn)動(dòng),例如全局運(yùn)動(dòng)、局部運(yùn)動(dòng)和復(fù)雜運(yùn)動(dòng)。不同的視頻超分方法可能更適合處理不同類型的運(yùn)動(dòng),這意味著在一種類型的運(yùn)動(dòng)上表現(xiàn)良好的方法可能在另一種類型的運(yùn)動(dòng)上表現(xiàn)不佳。
-
不同因素的權(quán)衡,魚與熊掌不可兼得:不同的視頻超分方法可能會(huì)在計(jì)算復(fù)雜度、視覺質(zhì)量和速度等因素之間做出不同的權(quán)衡。例如,生成高質(zhì)量高分辨率視頻的方法可能計(jì)算量大且速度慢,而速度更快的方法可能生成質(zhì)量較低的視頻。
-
看來(lái)我們要簡(jiǎn)單明了地單刀直入,講明白基于深度學(xué)習(xí)的超分技術(shù)并不容易,必須要娓娓道來(lái)。
6. 超分技術(shù)的基本概念和評(píng)價(jià)指標(biāo)高清視頻的退化公式
談超分技術(shù),必須要懂得基礎(chǔ)圖像的知識(shí),首當(dāng)其沖,就是要理解高清視頻的退化公式:
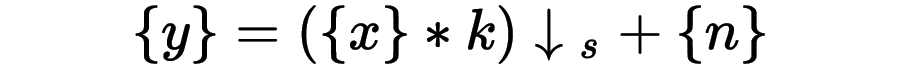
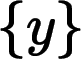 ?—— 代表低分辨率幀序列
?—— 代表低分辨率幀序列
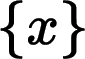 ?—— 代表原始高分辨率幀序列
?—— 代表原始高分辨率幀序列
* ——卷積運(yùn)算
k——模糊核
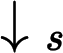 ?——?代表下采樣s倍
?——?代表下采樣s倍
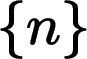 ?——?代表高斯噪聲
?——?代表高斯噪聲
超分計(jì)算是逆運(yùn)算,也就是根據(jù)幀序列來(lái)估計(jì)幀序列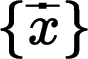 ,并且讓接近原裝的這么一個(gè)過(guò)程。
,并且讓接近原裝的這么一個(gè)過(guò)程。
視頻質(zhì)量主要通過(guò)峰值信噪比(PSNR)和結(jié)構(gòu)相似性指數(shù)(SSIM)來(lái)評(píng)價(jià)。
峰值信噪比(PSNR)
PSNR是峰值信噪比(Peak Signal-to-Noise Ratio)的英文縮寫。
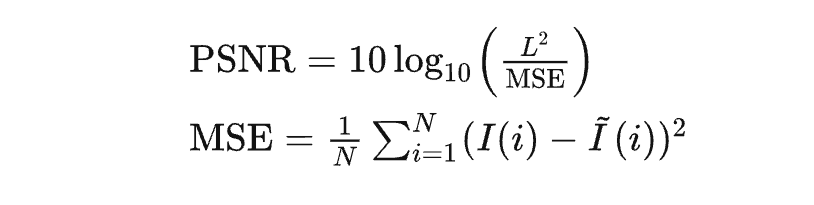
其中L表示顏色值的最大范圍,通常為255,N表示圖像中像素的總數(shù),MSE經(jīng)常作為損失函數(shù)出現(xiàn)。MSE表示輸出視頻和原始視頻的均方誤差(Mean Square Error)。
盡管PSNR是最普遍和使用最為廣泛的一種圖像客觀評(píng)價(jià)指標(biāo),然而它并未考慮到人眼的視覺特性(人眼對(duì)空間頻率較低的對(duì)比差異敏感度較高,人眼對(duì)亮度對(duì)比差異的敏感度較色度高,人眼對(duì)一個(gè)區(qū)域的感知結(jié)果會(huì)受到其周圍鄰近區(qū)域的影響等),因而經(jīng)常出現(xiàn)評(píng)價(jià)結(jié)果與人的主觀感覺不一致的情況。
結(jié)構(gòu)相似性(SSIM)
SSIM是結(jié)構(gòu)相似性(Structural SIMilarity)的英文縮寫。
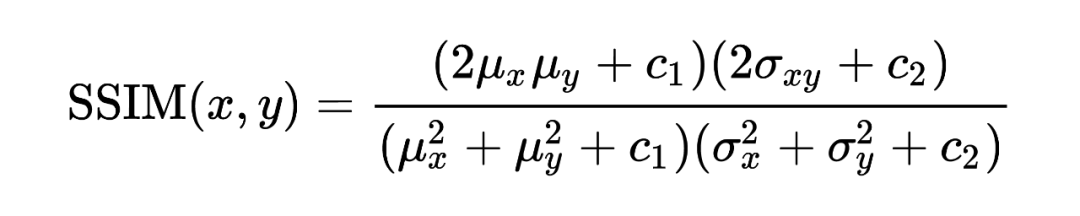
SSIM是一種衡量?jī)煞鶊D像相似度的指標(biāo)。SSIM 在圖像處理社區(qū)以及電視和社交媒體行業(yè)得到廣泛采用。該指標(biāo)首先由德州大學(xué)奧斯丁分校的圖像和視頻工程實(shí)驗(yàn)室(Laboratory for Image and Video Engineering)提出。而如果兩幅圖像是壓縮前和壓縮后的圖像,那么SSIM算法就可以用來(lái)評(píng)估壓縮后的圖像質(zhì)量。SSIM公式基于樣本之間的三個(gè)比較衡量:亮度 (luminance)、對(duì)比度 (contrast) 和結(jié)構(gòu) (structure)。
目前除了PSNR和SSIM,還有一些其他的指標(biāo)也被使用,包括:信息保真度標(biāo)準(zhǔn)(IFC)、視覺信息保真度(VIF)、基于運(yùn)動(dòng)的視頻完整性評(píng)估指數(shù)(MOVIE)和視頻多方法評(píng)估融合(VMAF)等等,但是這些指標(biāo)也并無(wú)完美,目前缺乏客觀指標(biāo)來(lái)驗(yàn)證視頻超分辨率方法還原真實(shí)細(xì)節(jié)的能力。該領(lǐng)域目前正在進(jìn)行研究。很多機(jī)構(gòu)組織的視頻超分技術(shù)比拼的基準(zhǔn)測(cè)試,普遍都是用PSNR , SSIM等客觀指標(biāo)來(lái)評(píng)價(jià),當(dāng)然也會(huì)依賴于平均意見得分(MOS)非常主觀的評(píng)價(jià)進(jìn)行糾偏和修正。
7. 基于深度學(xué)習(xí)的超分算法示例既然基于深度學(xué)習(xí)的超分技術(shù)對(duì)應(yīng)的算法很多,我們就無(wú)法做到一一解釋,不僅讓本篇的篇幅冗長(zhǎng),而且全部都是專業(yè)術(shù)語(yǔ),相信也會(huì)超級(jí)乏味,嚇阻你們繼續(xù)讀下去。所以我們僅摘錄其中典型的算法給大家簡(jiǎn)單解釋一下,希望能讓大家有一個(gè)基本概況的了解。但即便如此,今天談到的超分算法也有9大類16個(gè)算法,而這些只是諸多超分算法中的一小部分。
7.1 預(yù)上采樣
“預(yù)上采樣”部分意味著低分辨率輸入圖像在被輸入深度學(xué)習(xí)模型之前首先使用簡(jiǎn)單的算法(例如雙線性插值)增加尺寸。這樣做的原因是為模型提供更詳細(xì)的信息以供處理,從而產(chǎn)生更高質(zhì)量的輸出圖像。通過(guò)在輸入圖像通過(guò)模型之前對(duì)其進(jìn)行上采樣,模型可以更好地理解圖像的細(xì)節(jié)和紋理,并產(chǎn)生更準(zhǔn)確和詳細(xì)的輸出。總的來(lái)說(shuō),預(yù)上采樣超分辨率是一種通過(guò)使用輸入圖像的放大版本的深度學(xué)習(xí)模型來(lái)使低分辨率圖像看起來(lái)更好的技術(shù)。
7.1.1 SRCNN
SRCNN是超分卷積神經(jīng)網(wǎng)絡(luò)(Super-Resolution Convolutional. Neural Network)的縮寫。
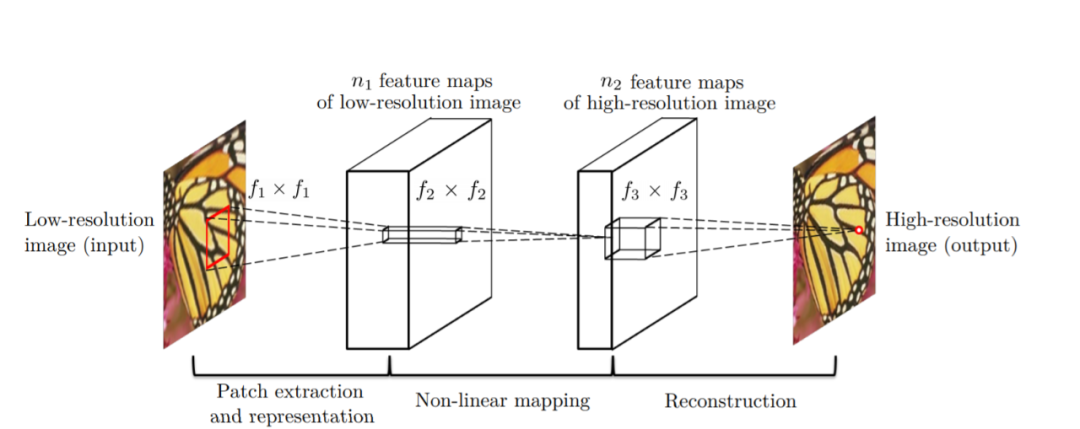
SRCNN 架構(gòu),由三層組成:補(bǔ)丁提取層(Patch Extraction and Representation)、非線性映射層(Non-Linear Mapping)和重建層(Reconstruction)。補(bǔ)丁提取層用于從輸入中提取密集補(bǔ)丁,并使用卷積濾波器表示它們。非線性映射層由 1×1 卷積濾波器組成,用于改變通道數(shù)并添加非線性。最后,重建層來(lái)重建高分辨率圖像。

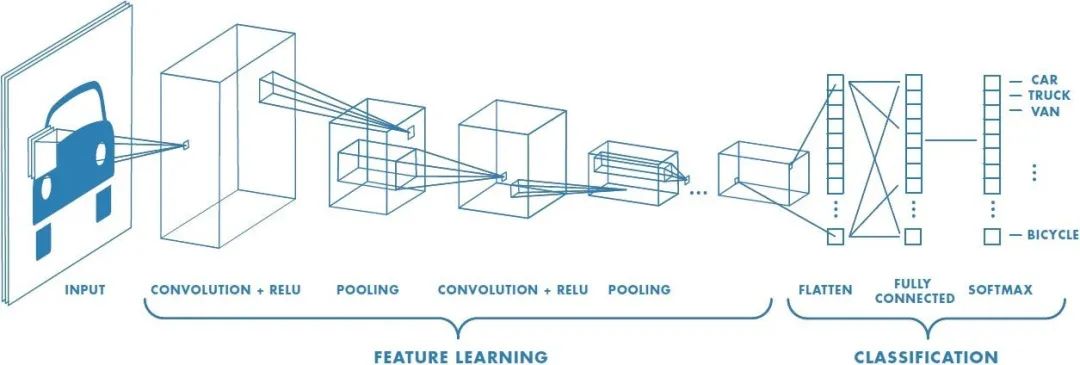 卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Networks,簡(jiǎn)稱:CNN) 背后的基本思想是使用卷積層從輸入數(shù)據(jù)中自動(dòng)學(xué)習(xí)和提取特征。卷積是一種數(shù)學(xué)運(yùn)算,它將兩個(gè)函數(shù)結(jié)合起來(lái)產(chǎn)生第三個(gè)函數(shù),該函數(shù)表示一個(gè)原始函數(shù)如何被另一個(gè)函數(shù)修改。在 CNN 中,卷積層將一組過(guò)濾器應(yīng)用于輸入數(shù)據(jù),這些過(guò)濾器可以識(shí)別圖像中的特定特征或模式,例如邊緣、角或紋理。
卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Networks,簡(jiǎn)稱:CNN) 背后的基本思想是使用卷積層從輸入數(shù)據(jù)中自動(dòng)學(xué)習(xí)和提取特征。卷積是一種數(shù)學(xué)運(yùn)算,它將兩個(gè)函數(shù)結(jié)合起來(lái)產(chǎn)生第三個(gè)函數(shù),該函數(shù)表示一個(gè)原始函數(shù)如何被另一個(gè)函數(shù)修改。在 CNN 中,卷積層將一組過(guò)濾器應(yīng)用于輸入數(shù)據(jù),這些過(guò)濾器可以識(shí)別圖像中的特定特征或模式,例如邊緣、角或紋理。CNN 通常由多層組成,包括卷積層、池化層和全連接層。池化層用于減小輸入的空間大小,同時(shí)保留重要特征,全連接層用于根據(jù)卷積層和池化層學(xué)習(xí)到的特征進(jìn)行預(yù)測(cè)。
CNN 已被證明在許多圖像和視頻相關(guān)任務(wù)中非常有效,例如對(duì)象檢測(cè)、圖像分類和分割。
7.1.2 VDSR
VDSR是非常深超分 (Very Deep Super Resolution) 的縮寫,VDSR是對(duì) SRCNN 的改進(jìn),增加了以下功能:
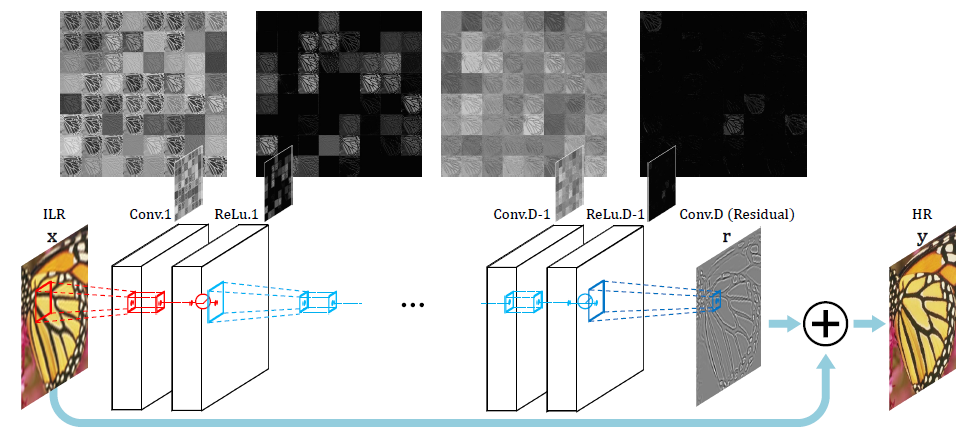
網(wǎng)絡(luò)嘗試學(xué)習(xí)輸出圖像和插值輸入的殘差,而不是學(xué)習(xí)直接映射(如 SRCNN),如上圖所示。這種操作簡(jiǎn)化了任務(wù),將初始的低分辨率圖像添加到網(wǎng)絡(luò)輸出中以獲得最終的 高分辨率輸出。
通過(guò)梯度裁剪用于訓(xùn)練具有更高學(xué)習(xí)率的深度網(wǎng)絡(luò)。梯度裁剪是一種在訓(xùn)練期間用于防止梯度變得太大或太小的技術(shù)。當(dāng)梯度的范數(shù)超過(guò)某個(gè)閾值時(shí),按比例縮小梯度,使其范數(shù)等于閾值。這有助于穩(wěn)定訓(xùn)練過(guò)程并防止數(shù)值不穩(wěn)定,以幫助模型更快收斂并產(chǎn)生更好的結(jié)果。避免在某些情況下,梯度會(huì)變得太大或太小,這會(huì)導(dǎo)致優(yōu)化算法發(fā)散或收斂太慢。
7.2 后上采樣
上文說(shuō)到的預(yù)上采樣,存在諸多不便:
-
-
?預(yù)上采樣首先使用簡(jiǎn)單的上采樣算法增加輸入圖像的分辨率,這在計(jì)算上可能很昂貴,尤其是對(duì)于大圖像。
-
預(yù)上采樣有時(shí)會(huì)導(dǎo)致過(guò)度擬合,模型會(huì)記住上采樣算法的細(xì)節(jié),而不是學(xué)習(xí)圖像的底層特征。
-
預(yù)上采樣用于提高輸入圖像分辨率的上采樣算法是固定的,這可能導(dǎo)致分辨率與訓(xùn)練分辨率不同的圖像輸出圖像質(zhì)量較低。
-
預(yù)上采樣首先使用簡(jiǎn)單的上采樣算法提高輸入圖像的分辨率,而后上采樣在圖像經(jīng)過(guò)超分模型處理后再執(zhí)行上采樣。具體來(lái)說(shuō)就是低分辨率輸入圖像通過(guò)深度學(xué)習(xí)模型,學(xué)習(xí)從圖像中提取高級(jí)特征和細(xì)節(jié)。一旦模型處理完圖像,就會(huì)使用學(xué)習(xí)到的上采樣算法將生成的特征圖上采樣到所需的分辨率。最終通過(guò)將上采樣的特征圖與原始低分辨率圖像相結(jié)合而獲得高分辨率圖像。
這樣一來(lái),后上采樣在處理圖像之前不需要額外的上采樣步驟,從而降低計(jì)算復(fù)雜度和內(nèi)存使用量。同時(shí)由于上采樣算法是作為模型的一部分學(xué)習(xí)的,又會(huì)避免過(guò)度擬合。最后,深度學(xué)習(xí)模型可以在上采樣之前從低分辨率輸入圖像中學(xué)習(xí)最相關(guān)的特征和細(xì)節(jié),更有效地處理不同的分辨率,從而產(chǎn)生更準(zhǔn)確和更詳細(xì)的輸出圖像。
7.2.1 FSRCNN
FSRCNN是快速超分卷積神經(jīng)網(wǎng)絡(luò)(Fast Super-Resolution Convolutional Neural Network)的縮寫。
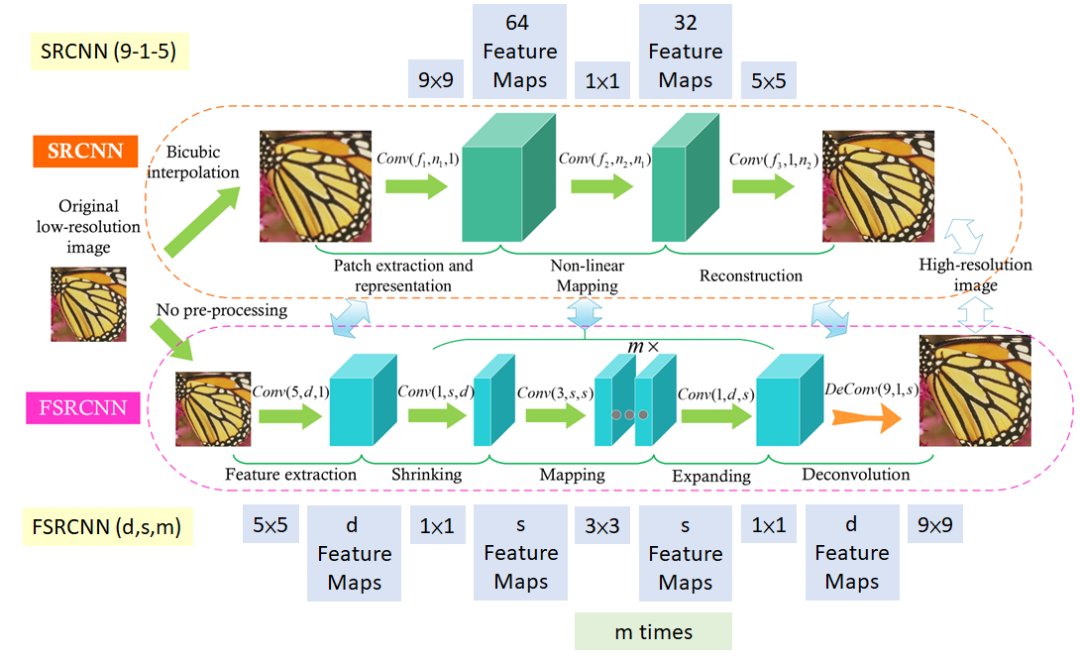
從上圖可以看出,和SRCNN相比,F(xiàn)SRCNN有以下變化:
-
-
更少的參數(shù):與 SRCNN 相比,F(xiàn)SRCNN 的參數(shù)更少,這使其速度更快,內(nèi)存效率更高。使用多個(gè) 3×3 卷積,而不是使用大的卷積濾波器,類似于視覺幾何組(VGG)網(wǎng)絡(luò)通過(guò)簡(jiǎn)化架構(gòu)來(lái)減少參數(shù)數(shù)量的工作方式。
-
更快的推理:在初始 5×5 卷積之后使用 1×1 卷積來(lái)減少通道數(shù)量,從而減少計(jì)算和內(nèi)存。FSRCNN 旨在通過(guò)使用較少數(shù)量的過(guò)濾器和減小中間特征圖的大小來(lái)比 SRCNN 更快。這使其能夠?qū)崟r(shí)或接近實(shí)時(shí)地執(zhí)行超分辨率,使其適用于現(xiàn)實(shí)世界的應(yīng)用。
-
多個(gè)上采樣階段:FSRCNN 使用多個(gè)上采樣階段來(lái)逐漸提高圖像的分辨率,這有助于保留精細(xì)細(xì)節(jié)并減少偽影。上采樣是通過(guò)使用學(xué)習(xí)的反卷積濾波器完成的,從而改進(jìn)了模型。
-
端到端訓(xùn)練:FSRCNN 是端到端訓(xùn)練的,這意味著整個(gè)網(wǎng)絡(luò)一起優(yōu)化,而不是使用單獨(dú)的預(yù)處理步驟進(jìn)行上采樣。一開始沒有預(yù)處理或上采樣。特征提取發(fā)生在低分辨率空間中。這會(huì)導(dǎo)致更好的性能和更有效地使用訓(xùn)練數(shù)據(jù)。
-
更好的結(jié)果:FSRCNN 已被證明在多項(xiàng)基準(zhǔn)測(cè)試中優(yōu)于 SRCNN,包括 PSNR 和視覺質(zhì)量指標(biāo)。這意味著它可以生成質(zhì)量更好的超分辨率圖像,尤其是對(duì)于高放大倍數(shù)。
-
FSRCNN 最終取得了比 SRCNN 更好的結(jié)果,同時(shí)速度也更快。
7.2.2 ESPCN
ESPCN是高效的像素卷積神經(jīng)網(wǎng)絡(luò)(Efficient Sub-Pixel CNN)的縮寫。
在圖像處理中,亞像素(Sub-Pixel)是指像素的一部分。像素是可以顯示在數(shù)字屏幕上或打印在紙上的圖像的最小單位。亞像素是用于表示像素的不同顏色分量的較小單元。
數(shù)字圖像中的每個(gè)像素都由三種顏色成分組成:紅色、綠色和藍(lán)色 (RGB)。一個(gè)亞像素代表每個(gè)顏色分量的一小部分。例如,在 RGB 圖像中,每個(gè)像素包含三個(gè)亞像素,每個(gè)亞像素對(duì)應(yīng)一個(gè)顏色分量。
亞像素用于各種圖像處理技術(shù),包括亞像素渲染和亞像素運(yùn)動(dòng)估計(jì)。在亞像素渲染中,亞像素用于在圖像中創(chuàng)建更高分辨率或更平滑邊緣的外觀。在亞像素運(yùn)動(dòng)估計(jì)中,亞像素通過(guò)分析相鄰亞像素之間的顏色值差異來(lái)估計(jì)視頻中對(duì)象的運(yùn)動(dòng)。
ESPCN技術(shù)中,亞像素卷積用于通過(guò)重新排列低分辨率圖像的通道以形成更高分辨率的圖像來(lái)提高圖像的分辨率,其中高分辨率圖像中的每個(gè)像素對(duì)應(yīng)于低分辨率圖像中的一組亞像素。亞像素卷積層將低分辨率特征圖作為輸入,通過(guò)重新排列低分辨率特征圖的通道輸出高分辨率特征圖。通過(guò)以這種方式重新排列通道,亞像素卷積層能夠有效地提高圖像的分辨率,而不會(huì)引入偽影或模糊。
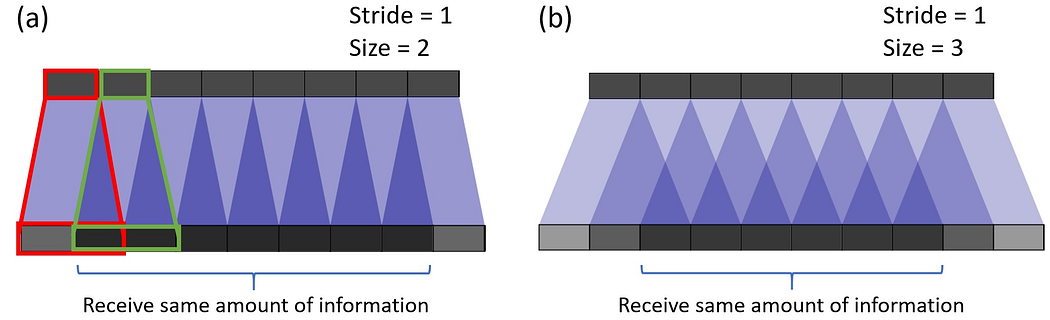
ESPCN 引入了亞像素卷積的概念來(lái)代替反卷積層進(jìn)行上采樣。這解決了與之相關(guān)的兩個(gè)問(wèn)題:
-
-
反卷積發(fā)生在高分辨率空間,因此計(jì)算成本更高。
-
它解決了反卷積中的棋盤問(wèn)題,這是由于卷積的重疊操作而發(fā)生的(如下圖所示)。
-
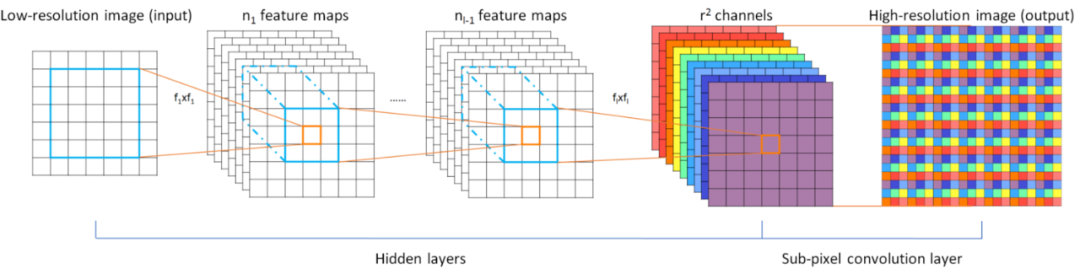
亞像素卷積通過(guò)將深度轉(zhuǎn)換為空間來(lái)工作,如下圖所示。來(lái)自低分辨率圖像中多個(gè)通道的像素被重新排列到高分辨率圖像中的單個(gè)通道。舉個(gè)例子,尺寸為 5×5×4 的輸入圖像可以將最后四個(gè)通道中的像素重新排列為一個(gè)通道,從而產(chǎn)生 10×10 高分辨率圖像。
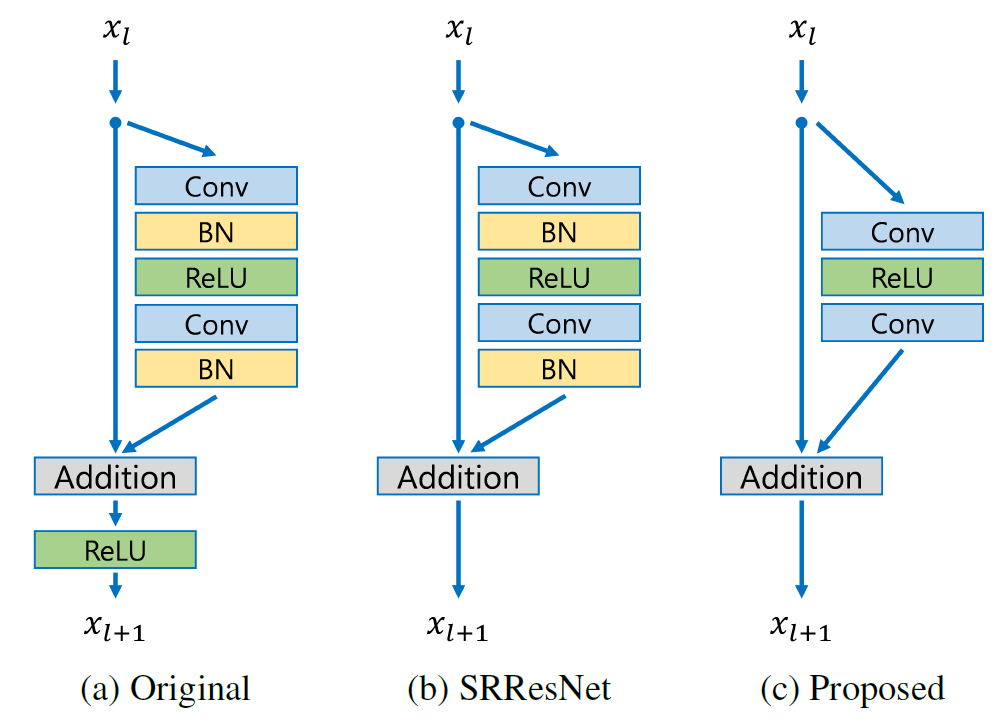
-
-
EDSR 使用比 SRResNet 更深的網(wǎng)絡(luò),這使其能夠?qū)W習(xí)低分辨率和高分辨率圖像之間更復(fù)雜的映射。EDSR 還使用比 SRResNet 中使用的殘差塊計(jì)算效率更高的殘差塊,這有助于降低該方法的總體計(jì)算成本。
-
EDSR 的另一個(gè)進(jìn)步是刪除批量歸一化層(Batch Normalization layers,簡(jiǎn)稱:BN),因?yàn)榕繗w一化會(huì)在超分辨率圖像中引入不需要的偽影。EDSR 使用一種稱為“均值減法”的標(biāo)準(zhǔn)化形式來(lái)標(biāo)準(zhǔn)化每一層的輸入。這有助于減少在訓(xùn)練深度神經(jīng)網(wǎng)絡(luò)時(shí)可能發(fā)生的內(nèi)部協(xié)變量偏移問(wèn)題,而不會(huì)引入不需要的偽影。因?yàn)槿コ?BN 會(huì)提高準(zhǔn)確度,還可減少高達(dá) 40% 的內(nèi)存,從而使網(wǎng)絡(luò)訓(xùn)練更加高效。
-
EDSR 還使用一種稱為 Charbonnier 損失的新型損失函數(shù),這是一種 L1 損失,它對(duì)異常值的敏感度低于 SRResNet 中使用的均方誤差 (MSE) 損失。這有助于減少超分辨率圖像中的偽影并獲得更高質(zhì)量的結(jié)果。
-
7.3.2 MDSR
MDSR是多尺度深度超分(multi-scale deep super-resolution)的縮寫。
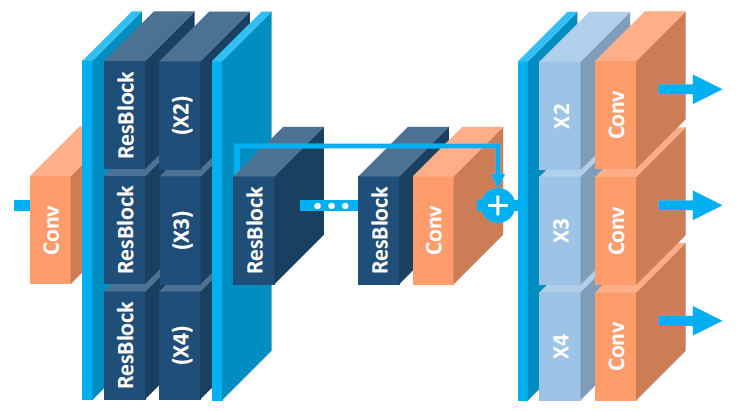
MDSR 是 EDSR 的擴(kuò)展,具有多個(gè)輸入和輸出模塊,可在 2x、3x 和 4x 提供相應(yīng)的分辨率輸出。一開始,存在用于特定尺度輸入的預(yù)處理模塊,由兩個(gè)具有 5×5 內(nèi)核的殘差塊組成。
MDSR使用多個(gè)尺度來(lái)學(xué)習(xí)低分辨率和高分辨率圖像之間的映射。MDSR可以更有效地處理具有不同細(xì)節(jié)級(jí)別的圖像。通過(guò)使用多個(gè)子網(wǎng)絡(luò),該方法可以學(xué)習(xí)對(duì)具有不同細(xì)節(jié)量的圖像的不同部分進(jìn)行上采樣。這有助于保留圖像中的高頻細(xì)節(jié)并生成更高質(zhì)量的超分辨率圖像。
MDSR預(yù)處理層中使用更大的內(nèi)核,增加網(wǎng)絡(luò)感受野同時(shí)保持其淺層和計(jì)算效率。神經(jīng)網(wǎng)絡(luò)的感受野是指網(wǎng)絡(luò)中每個(gè)神經(jīng)元對(duì)輸入圖像敏感的區(qū)域。在超分技術(shù)領(lǐng)域,感受野越大越好,因?yàn)樗试S網(wǎng)絡(luò)捕獲有關(guān)輸入圖像的更多信息并產(chǎn)生更高質(zhì)量的高分辨率圖像。增加神經(jīng)網(wǎng)絡(luò)感受野的一種方法是使用更大的卷積核。然而,使用更大的內(nèi)核也會(huì)增加網(wǎng)絡(luò)中的參數(shù)數(shù)量,這會(huì)導(dǎo)致過(guò)度擬合和更慢的訓(xùn)練時(shí)間。在多尺度深度超分辨率方法中,一種保持網(wǎng)絡(luò)淺層同時(shí)仍實(shí)現(xiàn)高感受野的方法是在網(wǎng)絡(luò)的預(yù)處理層中使用更大的卷積核。這些層通常在低分辨率輸入圖像上運(yùn)行,并用于提取與超分辨率相關(guān)的高級(jí)特征。通過(guò)在這些層中使用更大的內(nèi)核,網(wǎng)絡(luò)可以在不增加太多參數(shù)數(shù)量的情況下捕獲有關(guān)輸入圖像的更多信息。這有助于提高網(wǎng)絡(luò)性能,同時(shí)保持其計(jì)算效率。
MDSR在特定比例的預(yù)處理模塊的末尾是共享殘差塊,這是所有分辨率數(shù)據(jù)的公共塊。最后,在共享殘差塊之后是特定比例的上采樣模塊。
MDSR比 EDSR 等方法的計(jì)算效率更高。這是因?yàn)槊總€(gè)子網(wǎng)絡(luò)都被訓(xùn)練為以較小的因子對(duì)輸入圖像進(jìn)行上采樣,這需要更少的層和更少的參數(shù)。這可以導(dǎo)致更快的訓(xùn)練時(shí)間和更低的計(jì)算成本。
MDSR的缺點(diǎn)是它們的實(shí)施和訓(xùn)練比 EDSR 等方法更復(fù)雜。這是因?yàn)樗鼈兩婕坝?xùn)練多個(gè)子網(wǎng)絡(luò)并組合它們的輸出以生成最終的超分辨率圖像。這可能需要更仔細(xì)地調(diào)整超參數(shù)和更長(zhǎng)的訓(xùn)練時(shí)間。盡管與單尺度 EDSR 相比,MDSR 的整體深度是 5 倍,但由于共享參數(shù),參數(shù)數(shù)量?jī)H為 2.5 倍,而不是 5 倍。MDSR 取得了與規(guī)模特定的 EDSR 相當(dāng)?shù)慕Y(jié)果。
總的來(lái)說(shuō),多尺度深度超分辨率和EDSR都各有優(yōu)缺點(diǎn)。方法的選擇取決于應(yīng)用程序的具體要求以及可用于訓(xùn)練和推理的資源。
7.3.3 CARNCARN是級(jí)聯(lián)殘差網(wǎng)絡(luò)(Cascading Residual Network)的縮寫。CARN在傳統(tǒng)殘差網(wǎng)絡(luò)之上提出了以下改進(jìn):
局部和全局級(jí)別的級(jí)聯(lián)機(jī)制,合并來(lái)自多個(gè)層的特征并賦予網(wǎng)絡(luò)接收更多信息的能力。
除了 CARN 之外,在遞歸網(wǎng)絡(luò)架構(gòu)的幫助下,還提出了一個(gè)更小的 CARN-M,它具有更輕的架構(gòu),并且結(jié)果不會(huì)有太大的惡化。
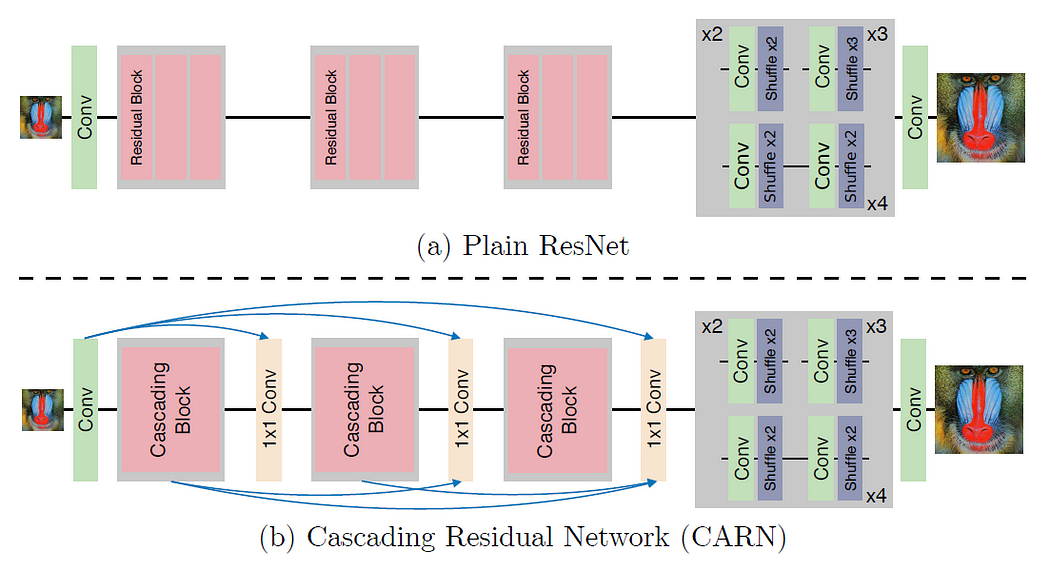
CARN 中的全局連接如上圖所示。每個(gè)具有 1×1 卷積的級(jí)聯(lián)塊的頂點(diǎn)接收來(lái)自所有先前級(jí)聯(lián)塊的輸入和初始輸入,從而導(dǎo)致信息的有效傳輸。
7.4 多階段殘差網(wǎng)絡(luò)多級(jí)殘差網(wǎng)絡(luò)(Multi-Stage Residual Networks),顧名思義,涉及使用多級(jí)或多級(jí)殘差網(wǎng)絡(luò)將圖像從低分辨率圖像上采樣到高分辨率圖像。
多階段殘差網(wǎng)絡(luò)中,低分辨率輸入圖像首先通過(guò)預(yù)處理階段,該階段通常由一組具有小感受野的卷積層組成。預(yù)處理階段的輸出然后通過(guò)一系列殘差階段,每個(gè)殘差階段包含多個(gè)殘差塊。
在每個(gè)階段,網(wǎng)絡(luò)學(xué)習(xí)按特定因子(例如 2 倍或 4 倍)對(duì)圖像進(jìn)行上采樣。然后將每個(gè)階段的輸出傳遞到下一個(gè)階段,下一個(gè)階段通過(guò)提高分辨率進(jìn)一步細(xì)化圖像。
多階段殘差網(wǎng)絡(luò)的一個(gè)優(yōu)點(diǎn)是它們可以在使用相對(duì)較少的參數(shù)的同時(shí)生成高質(zhì)量的超分圖像。這是因?yàn)槭褂脷埐钸B接和小的卷積濾波器可以幫助提高網(wǎng)絡(luò)的效率。
總體而言,多級(jí)殘差網(wǎng)絡(luò)是一種強(qiáng)大且流行的超分技術(shù),已在多個(gè)基準(zhǔn)數(shù)據(jù)集上實(shí)現(xiàn)了最先進(jìn)的性能。
7.4.1 BTSRN BTSRN是平衡兩階段殘差網(wǎng)絡(luò)(balanced two-stage residual networks)的縮寫。
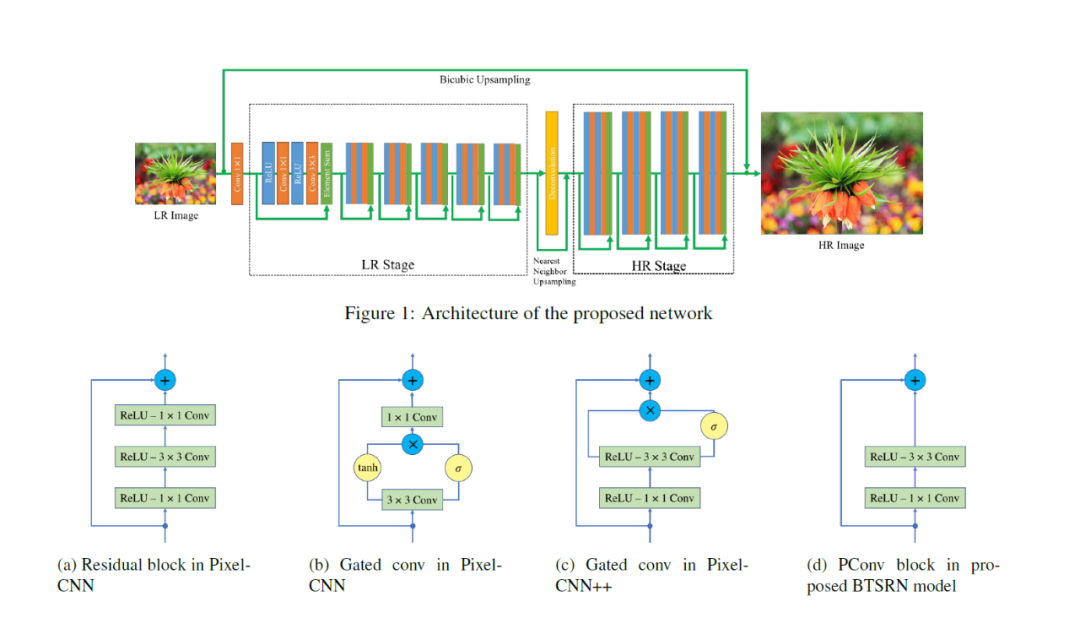
BTSRN使用兩級(jí)殘差網(wǎng)絡(luò)將圖像從低分辨率圖像上采樣到高分辨率圖像。與使用多個(gè)階段并增加上采樣級(jí)別的多階段殘差網(wǎng)絡(luò)相比,BTSRN 平衡每個(gè)階段中使用的濾波器數(shù)量以提高網(wǎng)絡(luò)性能。
BTSRN 的第一階段由一系列對(duì)低分辨率輸入圖像進(jìn)行操作的殘差塊組成(如上圖,第一階段由 6 個(gè)殘差塊組成。)。此階段通常將輸入圖像的分辨率提高兩倍或四倍。第一階段的輸出隨后被傳遞到第二階段,第二階段進(jìn)一步將圖像上采樣到所需的高分辨率輸出。
BTSRN 的第二階段使用一組相似的殘差塊,但過(guò)濾器數(shù)量與第一階段不同(如上圖,第二階段由 4 個(gè)殘差塊組成。)。每個(gè)塊中的過(guò)濾器數(shù)量是平衡的,以確保網(wǎng)絡(luò)能夠有效地學(xué)習(xí)低級(jí)和高級(jí)特征。
BTSRN 的一個(gè)優(yōu)點(diǎn)是它可以在使用相對(duì)較少的參數(shù)的同時(shí)生成高質(zhì)量的超分辨率圖像。通過(guò)平衡每個(gè)階段的過(guò)濾器數(shù)量,BTSRN 可以有效地學(xué)習(xí)不同尺度下輸入圖像的特征,這有助于提高網(wǎng)絡(luò)性能。
7.5 遞歸網(wǎng)絡(luò)遞歸網(wǎng)絡(luò)(Recursive Networks)是使用遞歸或迭代過(guò)程從低分辨率輸入生成高分辨率圖像。這種技術(shù)有時(shí)也稱為迭代超分辨率(Iterative Super-Resolution)。
遞歸網(wǎng)絡(luò)背后的基本思想是首先使用簡(jiǎn)單的插值方法(例如雙三次插值)生成高分辨率圖像的初始估計(jì)。然后將該初始估計(jì)輸入深度神經(jīng)網(wǎng)絡(luò),該網(wǎng)絡(luò)通過(guò)學(xué)習(xí)提取和合并額外的高頻細(xì)節(jié)進(jìn)一步完善估計(jì)。
在神經(jīng)網(wǎng)絡(luò)的每一輪處理之后,使用另一種插值方法(例如最近鄰插值)將生成的圖像放大到所需的分辨率。然后將放大后的圖像反饋到神經(jīng)網(wǎng)絡(luò)中進(jìn)行進(jìn)一步處理。這個(gè)過(guò)程會(huì)重復(fù)多次,通常是 5 到 10 輪,直到輸出圖像達(dá)到所需的分辨率。
遞歸網(wǎng)絡(luò)的一個(gè)優(yōu)點(diǎn)是即使輸入圖像的分辨率非常低,它們也可以生成高質(zhì)量的超分辨率圖像。這是因?yàn)榫W(wǎng)絡(luò)能夠在多個(gè)尺度上逐步細(xì)化圖像,提取低分辨率輸入中不存在的高頻細(xì)節(jié)。
然而,遞歸網(wǎng)絡(luò)的計(jì)算成本可能很高,尤其是在使用具有多層的深度神經(jīng)網(wǎng)絡(luò)時(shí)。此外,該方法的迭代性質(zhì)有時(shí)會(huì)導(dǎo)致對(duì)訓(xùn)練數(shù)據(jù)的過(guò)度擬合,從而導(dǎo)致新圖像的泛化性能不佳。因此,需要仔細(xì)的正則化和驗(yàn)證技術(shù)來(lái)確保遞歸網(wǎng)絡(luò)在各種不同的圖像和輸入分辨率上表現(xiàn)良好。
總體而言,BTSRN 是一種強(qiáng)大而有效的超分辨率技術(shù),已在多個(gè)基準(zhǔn)數(shù)據(jù)集上實(shí)現(xiàn)了最先進(jìn)的性能。
7.5.1 DRCN DRCN是深度遞歸卷積網(wǎng)絡(luò)(Deeply-Recursive Convolutional Network)的縮寫。
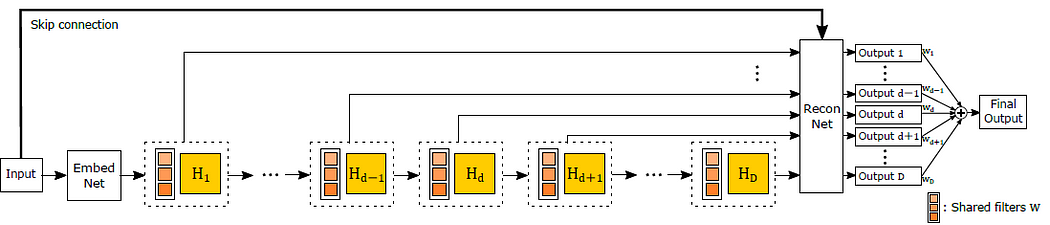
DRCN使用具有大量卷積層的非常深的神經(jīng)網(wǎng)絡(luò)來(lái)生成高質(zhì)量的超分辨率圖像。
DRCN 背后的基本思想類似于遞歸網(wǎng)絡(luò),因?yàn)樗褂玫^(guò)程從低分辨率輸入中逐漸生成更詳細(xì)的圖像。然而,DRCN 不是每次迭代都使用相對(duì)較淺的神經(jīng)網(wǎng)絡(luò),而是使用具有多級(jí)遞歸的非常深的網(wǎng)絡(luò)。
DRCN 架構(gòu)由兩個(gè)主要組件組成:特征提取網(wǎng)絡(luò)和重建網(wǎng)絡(luò)。特征提取網(wǎng)絡(luò)負(fù)責(zé)從輸入圖像中學(xué)習(xí)一組低級(jí)和高級(jí)特征。該網(wǎng)絡(luò)通常由多層卷積和池化操作組成,類似于典型的卷積神經(jīng)網(wǎng)絡(luò)。
另一方面,重建網(wǎng)絡(luò)負(fù)責(zé)根據(jù)特征提取網(wǎng)絡(luò)學(xué)習(xí)的特征生成高分辨率輸出圖像。該網(wǎng)絡(luò)使用一系列反卷積層(也稱為轉(zhuǎn)置卷積層)將特征圖放大到所需的分辨率。
除了這兩個(gè)主要組件之外,DRCN 還在特征提取網(wǎng)絡(luò)的每一層和重建網(wǎng)絡(luò)的相應(yīng)層之間加入了跳躍連接。這些跳過(guò)連接允許網(wǎng)絡(luò)繞過(guò)某些層并保留來(lái)自早期處理階段的重要信息。
DRCN 的一個(gè)優(yōu)勢(shì)是它能夠從輸入圖像中捕獲非常復(fù)雜和高級(jí)的特征,這要?dú)w功于其深層架構(gòu)。然而,這也意味著 DRCN 的計(jì)算成本可能很高,并且需要大量的訓(xùn)練數(shù)據(jù)才能獲得良好的結(jié)果。此外,跳躍連接的使用有時(shí)會(huì)導(dǎo)致過(guò)度擬合,因此需要仔細(xì)的正則化和驗(yàn)證技術(shù)以確保良好的泛化性能。
7.5.2 DRRN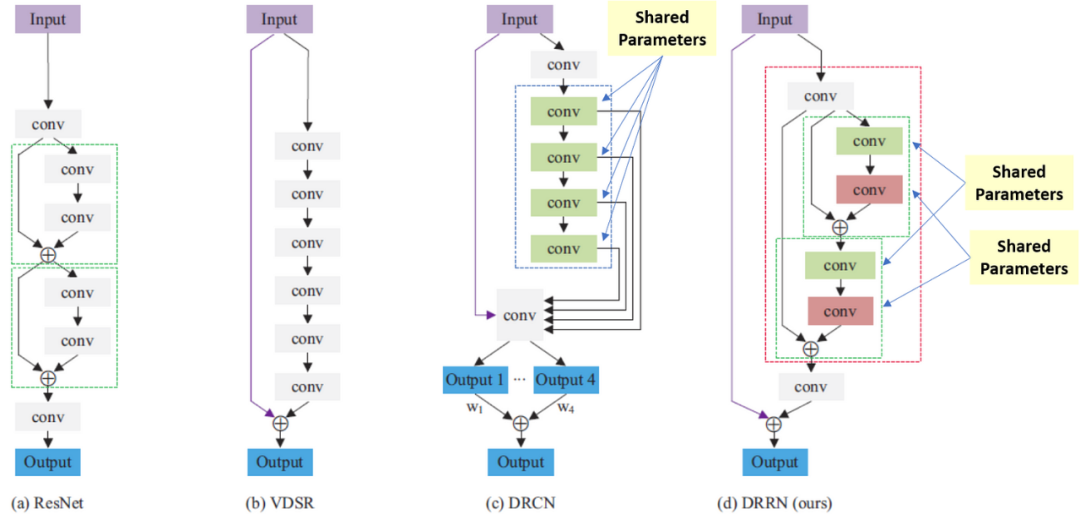 DRRN是深度遞歸殘差網(wǎng)絡(luò)(Deep Recursive Residual Network)的縮寫。
DRRN是深度遞歸殘差網(wǎng)絡(luò)(Deep Recursive Residual Network)的縮寫。DRRN建立在殘差網(wǎng)絡(luò) (ResNet) 架構(gòu)和遞歸網(wǎng)絡(luò)中使用的遞歸方法之上。
DRRN 利用一個(gè)深度神經(jīng)網(wǎng)絡(luò)架構(gòu),該架構(gòu)由幾個(gè)殘差塊組成,它們之間有跳躍連接。每個(gè)殘差塊包含多個(gè)卷積層和批量歸一化層,殘差連接將輸入直接傳遞到塊的輸出。這允許網(wǎng)絡(luò)學(xué)習(xí)低分辨率輸入和高分辨率輸出圖像之間的殘差或差異,然后將其添加到低分辨率輸入以生成超分辨率圖像。
DRRN 的遞歸方面來(lái)自于它使用遞歸過(guò)程來(lái)細(xì)化超分辨圖像。在每次遞歸迭代中,首先使用雙三次插值或其他簡(jiǎn)單的上采樣方法對(duì)低分辨率輸入圖像進(jìn)行放大。然后由 DRRN 網(wǎng)絡(luò)處理此放大圖像以生成初始超分辨率圖像。然后在下一次遞歸迭代中將這個(gè)超分辨率圖像用作網(wǎng)絡(luò)的輸入,進(jìn)一步完善它。這個(gè)過(guò)程一直持續(xù)到達(dá)到所需的超分辨率水平。
由于使用了殘差連接和遞歸方法,DRRN 的優(yōu)勢(shì)之一是它能夠使用相對(duì)較少的參數(shù)生成高質(zhì)量的超分辨率圖像。此外,批歸一化層的使用有助于加快訓(xùn)練速度并提高泛化性能。然而,DRRN 的計(jì)算成本仍然很高,尤其是在每個(gè)殘差塊使用大量遞歸迭代或大量卷積層時(shí)。
7.6 漸進(jìn)重建網(wǎng)絡(luò) 漸進(jìn)重建網(wǎng)絡(luò)(Progressive Reconstruction Networks(PRN))采用漸進(jìn)方法生成高分辨率圖像。它涉及生成一系列中間圖像,每個(gè)圖像的分辨率都比前一個(gè)圖像高,直到達(dá)到所需的最終分辨率。PRN 方法包括三個(gè)主要階段:從粗到精階段、殘差學(xué)習(xí)階段和重建階段。
-
-
第一階段,使用雙三次插值或其他簡(jiǎn)單的上采樣方法將低分辨率輸入圖像放大到中等分辨率。然后將該中間分辨率圖像用作深度神經(jīng)網(wǎng)絡(luò)的輸入,該網(wǎng)絡(luò)生成分辨率稍高的輸出圖像。這個(gè)過(guò)程重復(fù)多次,每個(gè)階段的輸出用作下一個(gè)階段的輸入,直到達(dá)到最終所需的分辨率。
-
第二階段,PRN 網(wǎng)絡(luò)使用殘差學(xué)習(xí)方法來(lái)細(xì)化第一階段生成的中間圖像。殘差學(xué)習(xí)方法涉及學(xué)習(xí)中間圖像與其對(duì)應(yīng)的高分辨率地面實(shí)況圖像之間的差異。這允許網(wǎng)絡(luò)學(xué)習(xí)生成低分辨率輸入圖像中不存在的高頻細(xì)節(jié)。
-
最后的重建階段,將中間圖像組合起來(lái)生成最終的高分辨率圖像。這是使用融合技術(shù)完成的,該融合技術(shù)以保留在殘差學(xué)習(xí)階段學(xué)習(xí)到的高頻細(xì)節(jié)的方式組合中間圖像。
-
PRN 的優(yōu)勢(shì)之一是它能夠以相對(duì)較少的參數(shù)生成高質(zhì)量圖像,這要?dú)w功于漸進(jìn)式重建和殘差學(xué)習(xí)的使用。此外,PRN 生成的中間圖像可用于其他計(jì)算機(jī)視覺任務(wù),例如圖像修復(fù)或去噪。然而,PRN 的計(jì)算成本仍然很高,尤其是在生成高分辨率圖像時(shí),并且可能需要大量的計(jì)算資源來(lái)訓(xùn)練和部署。
7.6.1 LAPSRN
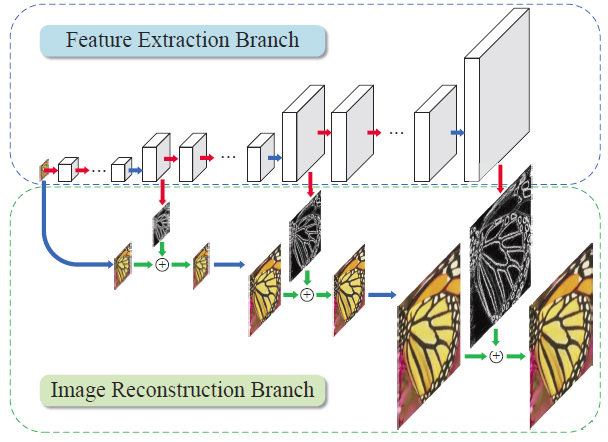
LapSRN 是拉普拉斯金字塔超分網(wǎng)絡(luò)(Laplacian Pyramid Super-Resolution Network)的縮寫。LapSRN通過(guò)使用一系列拉普拉斯金字塔對(duì)低分辨率圖像進(jìn)行逐步上采樣來(lái)生成高分辨率圖像。拉普拉斯金字塔是一種多尺度圖像表示,可將圖像分解為一系列子帶,每個(gè)子帶包含不同級(jí)別的細(xì)節(jié)。
LapSRN 方法包括三個(gè)主要階段:特征提取階段、拉普拉斯金字塔構(gòu)造階段和重建階段。
-
-
在特征提取階段,低分辨率輸入圖像由深度神經(jīng)網(wǎng)絡(luò)處理,提取多個(gè)尺度的特征圖。然后使用這些特征圖在下一階段構(gòu)建拉普拉斯金字塔。
-
在拉普拉斯金字塔構(gòu)造階段,使用拉普拉斯金字塔分解將特征圖分解為一系列子帶。每個(gè)子帶代表不同的細(xì)節(jié)級(jí)別,頻率最高的子帶包含最詳細(xì)的信息。
-
在重建階段,拉普拉斯金字塔用于通過(guò)使用深度神經(jīng)網(wǎng)絡(luò)逐步對(duì)每個(gè)子帶進(jìn)行上采樣來(lái)生成高分辨率圖像。上采樣以自下而上的方式完成,最高頻率的子帶首先被上采樣,然后是較低頻率的子帶。上采樣過(guò)程是使用卷積層和像素洗牌操作的組合完成的,這允許網(wǎng)絡(luò)學(xué)習(xí)生成高頻細(xì)節(jié)。
-
由于使用了拉普拉斯金字塔分解,LapSRN 的優(yōu)勢(shì)之一是它能夠以相對(duì)較少的參數(shù)生成高質(zhì)量圖像。此外,拉普拉斯金字塔的使用允許網(wǎng)絡(luò)生成高頻細(xì)節(jié),而不會(huì)引入其他超分辨率方法中常見的偽影。然而,LapSRN 的計(jì)算成本仍然很高,尤其是在生成高分辨率圖像時(shí),并且可能需要大量的計(jì)算資源來(lái)訓(xùn)練和部署。
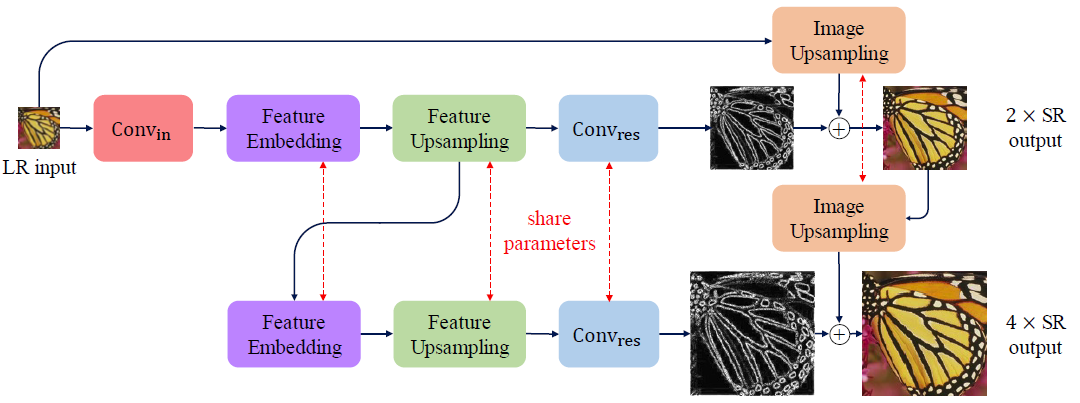
多分支網(wǎng)絡(luò)(Multi-branch networks),也稱為多分支卷積神經(jīng)網(wǎng)絡(luò),是一種具有多個(gè)分支的深度學(xué)習(xí)架構(gòu),每個(gè)分支以不同的方式處理輸入數(shù)據(jù)。每個(gè)分支由一系列卷積層組成,然后是激活函數(shù)和池化層。
每個(gè)分支中卷積層的輸出以某種方式組合,通常是將它們連接起來(lái),然后傳遞到網(wǎng)絡(luò)中的下一層或分支。這允許網(wǎng)絡(luò)通過(guò)同時(shí)以多種方式處理輸入數(shù)據(jù)來(lái)捕獲輸入數(shù)據(jù)的不同方面。
在超分辨率任務(wù)中,多分支網(wǎng)絡(luò)可用于通過(guò)利用輸入圖像的不同尺度和分辨率來(lái)生成具有更精細(xì)細(xì)節(jié)的高質(zhì)量圖像。例如,一個(gè)分支可以處理低分辨率的輸入圖像,而另一個(gè)分支可以處理高分辨率的圖像。然后可以組合這些分支的輸出,以生成比使用單個(gè)分支可能具有更多細(xì)節(jié)的高分辨率圖像。
多分支網(wǎng)絡(luò)已成功用于各種計(jì)算機(jī)視覺任務(wù),例如對(duì)象識(shí)別、分割和檢測(cè)。多分支網(wǎng)絡(luò)還在超分辨率任務(wù)中生成具有改進(jìn)的感知質(zhì)量和精細(xì)細(xì)節(jié)的高質(zhì)量圖像。然而,多分支網(wǎng)絡(luò)的計(jì)算成本可能很高,并且需要大量資源來(lái)訓(xùn)練和部署。
7.7.1 CMSC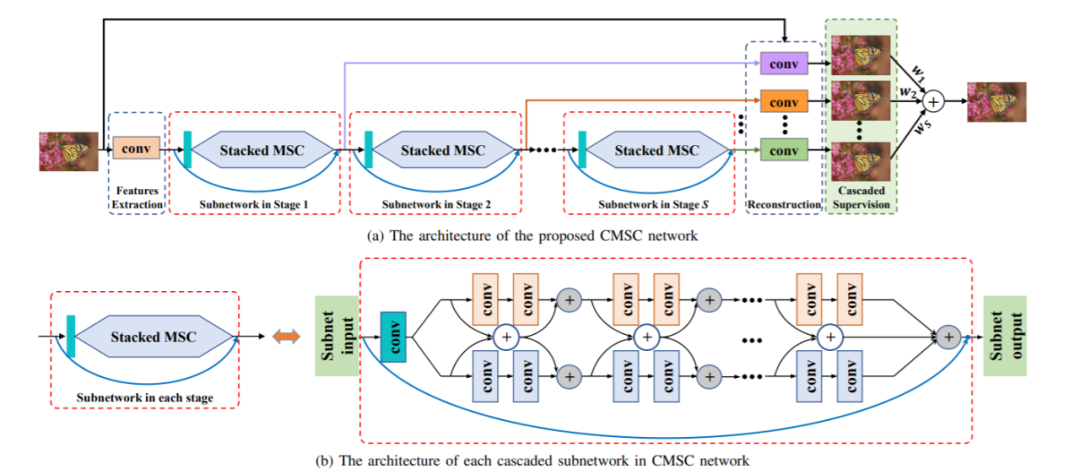 CMSC是級(jí)聯(lián)多尺度交叉網(wǎng)絡(luò)(Cascaded Multi-Scale Cross-Network)的縮寫。CMSC是一種利用級(jí)聯(lián)多尺度網(wǎng)絡(luò)生成高分辨率圖像的超分辨率方法。CMSC 由兩個(gè)主要階段組成:從粗到精階段和微調(diào)階段。
CMSC是級(jí)聯(lián)多尺度交叉網(wǎng)絡(luò)(Cascaded Multi-Scale Cross-Network)的縮寫。CMSC是一種利用級(jí)聯(lián)多尺度網(wǎng)絡(luò)生成高分辨率圖像的超分辨率方法。CMSC 由兩個(gè)主要階段組成:從粗到精階段和微調(diào)階段。-
-
在粗到精階段,輸入的低分辨率圖像首先使用雙三次插值放大 2 倍,然后由一系列多尺度網(wǎng)絡(luò)處理。序列中的每個(gè)網(wǎng)絡(luò)都設(shè)計(jì)為以不同的規(guī)模運(yùn)行,并專注于圖像的不同方面。然后組合這些網(wǎng)絡(luò)的輸出以生成中間高分辨率圖像。
-
在微調(diào)階段,使用單尺度網(wǎng)絡(luò)進(jìn)一步細(xì)化中間高分辨率圖像。微調(diào)網(wǎng)絡(luò)使用內(nèi)容損失和對(duì)抗性損失的組合進(jìn)行訓(xùn)練,以提高生成圖像的感知質(zhì)量。
-
CMSC 的關(guān)鍵特征之一是它使用跨網(wǎng)絡(luò)連接,它允許在網(wǎng)絡(luò)的不同規(guī)模和階段之間共享信息。這有助于提高網(wǎng)絡(luò)的準(zhǔn)確性和穩(wěn)定性,并使其能夠生成具有精細(xì)細(xì)節(jié)的高質(zhì)量圖像。
CMSC 的另一個(gè)優(yōu)勢(shì)是它能夠通過(guò)相應(yīng)地調(diào)整網(wǎng)絡(luò)架構(gòu)和訓(xùn)練策略來(lái)處理不同的比例因子。這使其成為一種通用且適應(yīng)性強(qiáng)的方法,可應(yīng)用于廣泛的超分辨率任務(wù)。
7.8 注意力網(wǎng)絡(luò)注意力網(wǎng)絡(luò)(Attention-Based Networks)是指一系列深度學(xué)習(xí)模型,它們利用注意力機(jī)制來(lái)提高超分辨率圖像的質(zhì)量。引入這些網(wǎng)絡(luò)是為了解決傳統(tǒng)超分辨率技術(shù)的局限性,傳統(tǒng)超分辨率技術(shù)通常使用固定且統(tǒng)一的濾波器來(lái)插值低分辨率圖像。基于注意力的網(wǎng)絡(luò)使用一組可學(xué)習(xí)的權(quán)重,這些權(quán)重可以根據(jù)圖像內(nèi)容自適應(yīng)地調(diào)整每個(gè)像素的濾波器系數(shù)。這使網(wǎng)絡(luò)能夠?qū)W⒂趫D像最重要的特征,并生成具有更清晰邊緣和更多細(xì)節(jié)的高質(zhì)量超分辨率圖像。
基于注意力的網(wǎng)絡(luò)在超分辨率方面的主要優(yōu)勢(shì)在于它們能夠選擇性地關(guān)注圖像中的重要特征,并生成具有更準(zhǔn)確細(xì)節(jié)的高質(zhì)量超分辨率圖像。此外,這些網(wǎng)絡(luò)可以處理復(fù)雜的圖像結(jié)構(gòu)和圖像內(nèi)容的變化,使其適用于計(jì)算機(jī)視覺中的廣泛應(yīng)用,例如對(duì)象識(shí)別、圖像分類和自然語(yǔ)言處理。
7.8.1 SelNet
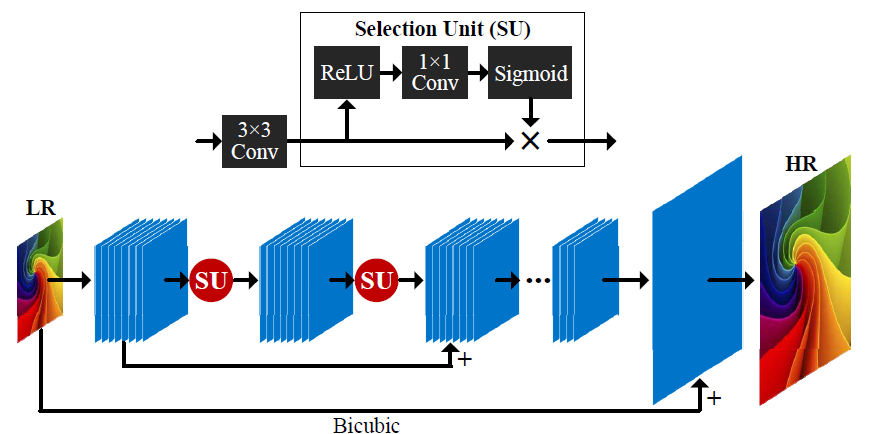
SelNet是具有注意力機(jī)制的選擇性卷積神經(jīng)網(wǎng)絡(luò)(Selective Convolutional Neural Network with Attention Mechanism)的縮寫。SelNet是2019年提出的一種基于注意力的超分辨率網(wǎng)絡(luò)。SelNet旨在選擇性地強(qiáng)調(diào)圖像中的重要特征,同時(shí)抑制不相關(guān)的細(xì)節(jié),使其能夠生成高分辨率的質(zhì)量超分辨率圖像。
SelNet 由一系列卷積層組成,后面是一組注意力模塊,這些模塊自適應(yīng)地加權(quán)特征圖中每個(gè)像素的重要性。注意模塊由一組卷積層和一個(gè) soft-max 函數(shù)組成,該函數(shù)根據(jù)每個(gè)像素與參考特征的相似性為其分配權(quán)重。參考特征是在訓(xùn)練期間學(xué)習(xí)的,代表圖像內(nèi)容的學(xué)習(xí)表示。
SelNet 的關(guān)鍵優(yōu)勢(shì)在于它能夠自適應(yīng)地選擇和強(qiáng)調(diào)重要的圖像特征,同時(shí)抑制不相關(guān)的細(xì)節(jié)。這是通過(guò)注意力機(jī)制實(shí)現(xiàn)的,它允許網(wǎng)絡(luò)學(xué)習(xí)強(qiáng)調(diào)圖像重要區(qū)域的空間變化加權(quán)方案。
與其他基于注意力的網(wǎng)絡(luò)相比,SelNet 相對(duì)簡(jiǎn)單,但可以有效生成高質(zhì)量的超分辨率圖像。
7.8.2 RCAN
RCAN是剩余通道注意力網(wǎng)絡(luò)(Residual Channel Attention Networks)的縮寫。
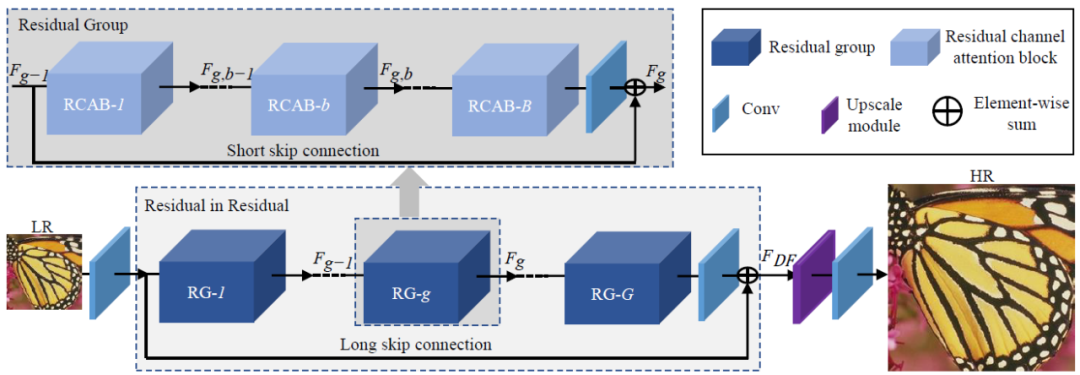
RCAN是 2018 年提出的另一種基于注意力的超分辨率網(wǎng)絡(luò)。RCAN 旨在通過(guò)使用通道注意力機(jī)制來(lái)增強(qiáng)網(wǎng)絡(luò)層之間剩余連接的學(xué)習(xí)。
RCAN 由一系列殘差塊組成,其中每個(gè)殘差塊包含一個(gè)卷積層,后跟一個(gè)通道注意模塊。通道注意模塊對(duì)每個(gè)殘差塊的特征圖進(jìn)行操作,并根據(jù)每個(gè)通道與圖像重建任務(wù)的相關(guān)性自適應(yīng)地對(duì)每個(gè)通道的重要性進(jìn)行加權(quán)。
RCAN 中的通道注意力模塊包括兩個(gè)步驟:第一步計(jì)算每個(gè)通道的平均特征激活,而第二步使用一組全連接層來(lái)學(xué)習(xí)一組通道權(quán)重,放大或抑制每個(gè)通道的重要性渠道。這允許網(wǎng)絡(luò)有選擇地強(qiáng)調(diào)重要通道,同時(shí)抑制嘈雜或不相關(guān)的通道。
RCAN 的關(guān)鍵優(yōu)勢(shì)在于它能夠更有效地學(xué)習(xí)網(wǎng)絡(luò)層之間的殘余連接。通過(guò)結(jié)合通道注意機(jī)制,RCAN 可以學(xué)習(xí)選擇性地放大或抑制每個(gè)殘差連接的重要性,從而導(dǎo)致更有效的信息流和更好的生成高質(zhì)量超分辨率圖像的性能。
7.9 生成模型生成模型(Generative models)是指一類深度學(xué)習(xí)模型,它學(xué)習(xí)從低分辨率輸入圖像生成高分辨率圖像。這些模型通常在低分辨率和高分辨率圖像對(duì)的數(shù)據(jù)集上進(jìn)行訓(xùn)練,目標(biāo)是學(xué)習(xí)兩者之間的映射。
超分辨率生成模型的優(yōu)勢(shì)在于能夠生成訓(xùn)練集中不存在的高分辨率圖像。這使得它們可用于圖像修復(fù)和具有復(fù)雜內(nèi)容的圖像的超分辨率等任務(wù)。然而,它們也可能比其他超分辨率方法的計(jì)算成本更高,并且可能需要更大量的訓(xùn)練數(shù)據(jù)才能獲得良好的性能。
7.9.1 SRGAN SRGAN是超分生成對(duì)抗網(wǎng)絡(luò)(Super-Resolution Generative Adversarial Networks)的縮寫。
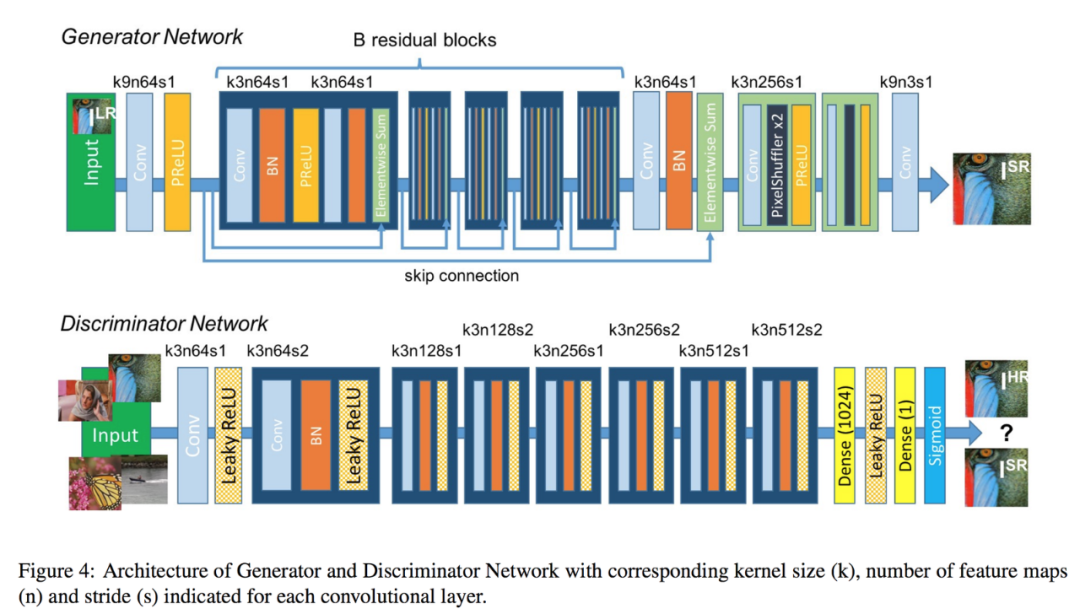
SRGAN使用生成對(duì)抗網(wǎng)絡(luò) (GAN) 從低分辨率輸入圖像生成高分辨率圖像。
SRGAN 的架構(gòu)由兩個(gè)網(wǎng)絡(luò)組成:生成器網(wǎng)絡(luò)和鑒別器網(wǎng)絡(luò)。生成器網(wǎng)絡(luò)接收低分辨率圖像并生成高分辨率圖像,而鑒別器網(wǎng)絡(luò)試圖區(qū)分生成的高分辨率圖像和真實(shí)的高分辨率圖像。這兩個(gè)網(wǎng)絡(luò)以對(duì)抗方式進(jìn)行訓(xùn)練,其中生成器嘗試生成可以欺騙鑒別器的圖像,而鑒別器則嘗試正確區(qū)分真實(shí)圖像和生成的圖像。
SRGAN 的關(guān)鍵創(chuàng)新是使用感知損失函數(shù),它衡量生成的高分辨率圖像與特征空間中相應(yīng)的地面真值高分辨率圖像之間的差異。具體來(lái)說(shuō),感知損失函數(shù)基于預(yù)訓(xùn)練的深度神經(jīng)網(wǎng)絡(luò),該網(wǎng)絡(luò)計(jì)算網(wǎng)絡(luò)不同層的特征圖。通過(guò)使用感知損失函數(shù),SRGAN 能夠生成高分辨率圖像,這些圖像不僅在視覺上與地面真實(shí)圖像相似,而且具有相似的高級(jí)特征和結(jié)構(gòu)。
SRGAN 已被證明在視覺質(zhì)量和定量指標(biāo)(如峰值信噪比 (PSNR) 和結(jié)構(gòu)相似性指數(shù) (SSIM))方面實(shí)現(xiàn)了最先進(jìn)的性能。它們還能夠生成具有精細(xì)細(xì)節(jié)和紋理的圖像,這對(duì)于醫(yī)學(xué)成像和衛(wèi)星成像等應(yīng)用非常重要。
7.9.2 EnhanceNet

EnhanceNet 使用深度神經(jīng)網(wǎng)絡(luò)來(lái)學(xué)習(xí)低分辨率和高分辨率圖像之間的映射。它基于條件 GAN 的概念,其中生成器網(wǎng)絡(luò)從低分辨率輸入圖像生成高分辨率圖像,鑒別器網(wǎng)絡(luò)區(qū)分生成的高分辨率圖像和真實(shí)高分辨率圖像。
EnhanceNet 的架構(gòu)由編碼器-解碼器網(wǎng)絡(luò)組成,其中編碼器網(wǎng)絡(luò)將輸入圖像下采樣為低分辨率特征圖,解碼器網(wǎng)絡(luò)將特征圖上采樣為所需的高分辨率輸出圖像。該網(wǎng)絡(luò)使用像素級(jí)損失和對(duì)抗性損失的組合進(jìn)行訓(xùn)練,其中像素級(jí)損失衡量生成的高分辨率圖像與真實(shí)高分辨率圖像之間的差異,而對(duì)抗性損失鼓勵(lì)生成器網(wǎng)絡(luò)生成與圖像無(wú)法區(qū)分的圖像。真正的高分辨率圖像。
EnhanceNet 的獨(dú)特之處之一是在編碼器和解碼器網(wǎng)絡(luò)之間使用殘差連接,這有助于在上采樣過(guò)程中保留輸入圖像的高頻細(xì)節(jié)。此外,EnhanceNet 還采用了一種感知損失函數(shù),該函數(shù)結(jié)合了預(yù)訓(xùn)練的深度卷積神經(jīng)網(wǎng)絡(luò)(例如 VGG),以根據(jù)感知特征來(lái)衡量生成的高分辨率圖像與真實(shí)高分辨率圖像之間的相似性。
8. 本期專業(yè)術(shù)語(yǔ)和縮略語(yǔ)匯總| 縮寫 | 英文 | 中文 |
|
UHD?? |
Ultra High Definition? |
超高清視頻 |
|
HDR |
High Dynamic Range |
高動(dòng)態(tài)范圍 |
|
VSR |
Video super-resolution |
視頻超分技術(shù) |
|
LR |
Low Resolution |
低分辨率 |
|
HR |
High Resolution |
高分辨率 |
|
SISR |
Single Image Super-Resolution |
單圖像超分技術(shù) |
|
DL |
Deep Learning |
深度學(xué)習(xí) |
|
ANN |
Artificial neural networks |
人工神經(jīng)網(wǎng)絡(luò) |
|
DNN |
Deep Neural Networks |
深度神經(jīng)網(wǎng)絡(luò) |
|
DBN |
Deep Belief Networks |
深度置信網(wǎng)絡(luò) |
|
DRN |
Deep Reinforcement Learning |
深度強(qiáng)化學(xué)習(xí) |
|
RNN |
Recurrent Neural Networks |
遞歸神經(jīng)網(wǎng)絡(luò) |
|
CNN |
Convolutional Neural Networks |
卷積神經(jīng)網(wǎng)絡(luò) |
|
SKF |
Schmidt–Kalman Filter |
施密特-卡爾曼濾波器 |
|
LMS |
least mean squares |
最小平均方差 |
|
MAP |
maximum a posteriori |
最大后驗(yàn) |
|
MRF |
Markov random fields |
馬爾可夫隨機(jī)場(chǎng) |
|
PSNR |
Peak Signal-to-Noise Ratio |
峰值信噪比 |
|
MSE |
Mean Square Error |
均方誤差 |
|
SSIM |
Structural SIMilarity |
結(jié)構(gòu)相似性 |
|
IFC |
Information Fidelity Criterion |
信息保真度標(biāo)準(zhǔn) |
|
VIF |
Visual Information Fidelity |
視覺信息保真度 |
|
MOVIE |
Motion-based Video Integrity Evaluation index |
基于運(yùn)動(dòng)的視頻完整性評(píng)估指數(shù) |
|
VMAF |
Video Multimethod Assessment Fusion |
視頻多方法評(píng)估融合 |
|
MOS |
Mean opinion score |
平均意見得分 |
|
SRCNN |
Super-Resolution Convolutional. Neural Network |
超分卷積神經(jīng)網(wǎng)絡(luò) |
|
VDSR |
Very Deep Super Resolution |
非常深超分 |
|
VGG |
Visual Geometry Group |
視覺幾何組 |
|
FSRCNN |
Fast Super-Resolution Convolutional Neural Network |
快速超分卷積神經(jīng)網(wǎng)絡(luò) |
|
ESPCN |
Efficient Sub-Pixel CNN |
高效的像素卷積神經(jīng)網(wǎng)絡(luò) |
|
SP |
Sub-Pixel |
亞像素 |
|
ResNets |
Residual Networks |
殘差網(wǎng)絡(luò) |
|
EDSR |
Enhanced Deep Super Resolution |
增強(qiáng)的深度超分 |
|
BN |
Batch Normalization layers |
批量歸一化層 |
|
MDSR |
multi-scale deep super-resolution |
多尺度深度超分 |
|
CARN |
Cascading Residual Network |
級(jí)聯(lián)殘差網(wǎng)絡(luò) |
|
MSRN |
Multi-Stage Residual Networks |
多級(jí)殘差網(wǎng)絡(luò) |
|
BTSRN |
balanced two-stage residual networks |
平衡兩階段殘差網(wǎng)絡(luò) |
|
RN |
Recursive Networks |
遞歸網(wǎng)絡(luò) |
|
ISR |
Iterative Super-Resolution |
迭代超分辨率 |
|
DRCN |
Deeply-Recursive Convolutional Network |
深度遞歸卷積網(wǎng)絡(luò) |
|
DRRN |
Deep Recursive Residual Network |
深度遞歸殘差網(wǎng)絡(luò) |
|
PRN |
Progressive Reconstruction Networks |
漸進(jìn)重建網(wǎng)絡(luò) |
|
LapSRN |
Laplacian Pyramid Super-Resolution Network |
拉普拉斯金字塔超分網(wǎng)絡(luò) |
|
MBN |
Multi-branch networks |
多分支網(wǎng)絡(luò) |
|
CMSC |
Cascaded Multi-Scale Cross-Network |
級(jí)聯(lián)多尺度交叉網(wǎng)絡(luò) |
|
ABN |
Attention-Based Networks |
注意力網(wǎng)絡(luò) |
|
SelNet |
Selective Convolutional Neural Network with Attention Mechanism |
具有注意力機(jī)制的選擇性卷積神經(jīng)網(wǎng)絡(luò) |
|
RCAN |
Residual Channel Attention Networks |
剩余通道注意力網(wǎng)絡(luò) |
|
GM |
Generative models |
生成模型 |
|
SRGAN |
Super-Resolution Generative Adversarial Networks |
超分生成對(duì)抗網(wǎng)絡(luò) |
好了,恭喜你能看到這里,說(shuō)明這個(gè)萬(wàn)字長(zhǎng)文確實(shí)讓您受益了。這是迄今為止,網(wǎng)絡(luò)上最為詳細(xì)的介紹超分技術(shù)的文章了,整整寫了18000多字。今天,我們就先聊到這里,下一期,我們?cè)僬归_談一下超高清視頻的另外一個(gè)話題:數(shù)字版權(quán)管理。
-
開源技術(shù)
+關(guān)注
關(guān)注
0文章
389瀏覽量
7928 -
OpenHarmony
+關(guān)注
關(guān)注
25文章
3716瀏覽量
16275
原文標(biāo)題:河套IT TALK 67: (原創(chuàng)) 基于深度學(xué)習(xí)的超分技術(shù)(萬(wàn)字長(zhǎng)文)
文章出處:【微信號(hào):開源技術(shù)服務(wù)中心,微信公眾號(hào):共熵服務(wù)中心】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
單日獲客成本超20萬(wàn),國(guó)產(chǎn)大模型開卷200萬(wàn)字以上的長(zhǎng)文本處理

萬(wàn)字長(zhǎng)文,看懂激光基礎(chǔ)知識(shí)!

NPU在深度學(xué)習(xí)中的應(yīng)用
激光雷達(dá)技術(shù)的基于深度學(xué)習(xí)的進(jìn)步
AI大模型與深度學(xué)習(xí)的關(guān)系
深度學(xué)習(xí)中的時(shí)間序列分類方法
萬(wàn)字長(zhǎng)文淺談系統(tǒng)穩(wěn)定性建設(shè)
深度學(xué)習(xí)的模型優(yōu)化與調(diào)試方法
深度學(xué)習(xí)在自動(dòng)駕駛中的關(guān)鍵技術(shù)
MiniMax推出“海螺AI”,支持超長(zhǎng)文本處理
深度解析深度學(xué)習(xí)下的語(yǔ)義SLAM

阿里通義千問(wèn)重磅升級(jí),免費(fèi)開放1000萬(wàn)字長(zhǎng)文檔處理功能
“單純靠大模型無(wú)法實(shí)現(xiàn) AGI”!萬(wàn)字長(zhǎng)文看人工智能演進(jìn)

詳解深度學(xué)習(xí)、神經(jīng)網(wǎng)絡(luò)與卷積神經(jīng)網(wǎng)絡(luò)的應(yīng)用






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論