") FPGA原型平臺到底能跑多快呢?
FPGA原型平臺到底能跑多快呢?
前面有講到過,FPGA原型設(shè)計是在芯片流片之前最接近芯片應(yīng)用真實環(huán)境的場景,這個真實環(huán)境不僅僅是說外部物理環(huán)境接近,還在于性能速率是最接近的,當然真的比起ASIC芯片的實際速率還是差的很多的,當然這個速率已經(jīng)是流片之前能模擬的最佳場景了,所以對于軟件的debug作用就很大了。那么,F(xiàn)PGA原型平臺到底能跑多快呢?
FPGA原型平臺的性能估計與應(yīng)用過程的資源利用率以及FPGA性能參數(shù)密切相關(guān),甚至FPGA的制程也是一個因素。性能從相關(guān)的FPGA資源數(shù)據(jù)表中的時序信息中容易地提取特殊功能模塊的估計。但要評估FPGA原型平臺的整體速率是很困難的。但是,可以從綜合工具獲得整個設(shè)計比較好的性能估計。盡管綜合工具會考慮布線的延遲,但布線實際延遲時間取決于FPGA的位置和布線過程,并且可能與綜合工具的估計不同。在較高的利用率水平下,由于布線可能變得更困難,因此差異可能會很明顯,但初始性能估計是一個非常有用的指導。
現(xiàn)代原型驗證平臺中采用的FPGA芯片,很多是多die封裝的芯片(例如VU19P等),使用多die FPGA時,或多或少的都遇到過時序收斂問題;而這些時序收斂的問題很大程度上影響性能,F(xiàn)PGA性能在很大程度上取決于提供給綜合工具的約束。而這些約束取決于FPGA工程師的經(jīng)驗,這些約束指導綜合工具以及隨后的布局布線工具如何最佳地實現(xiàn)期望的性能。以下的總結(jié)非常受到認可,因此直接引用過來。
多die芯片其實是SSI(Stacked Silicon Interconnect)芯片,其結(jié)構(gòu)如下圖所示。其實就是在一個封裝里,把多個芯片,也就是我們說的SLR(Super Logic Region)用interposer“綁”在一起,SLR之間的連接用專用布線資源SLL(Super Long Line)。
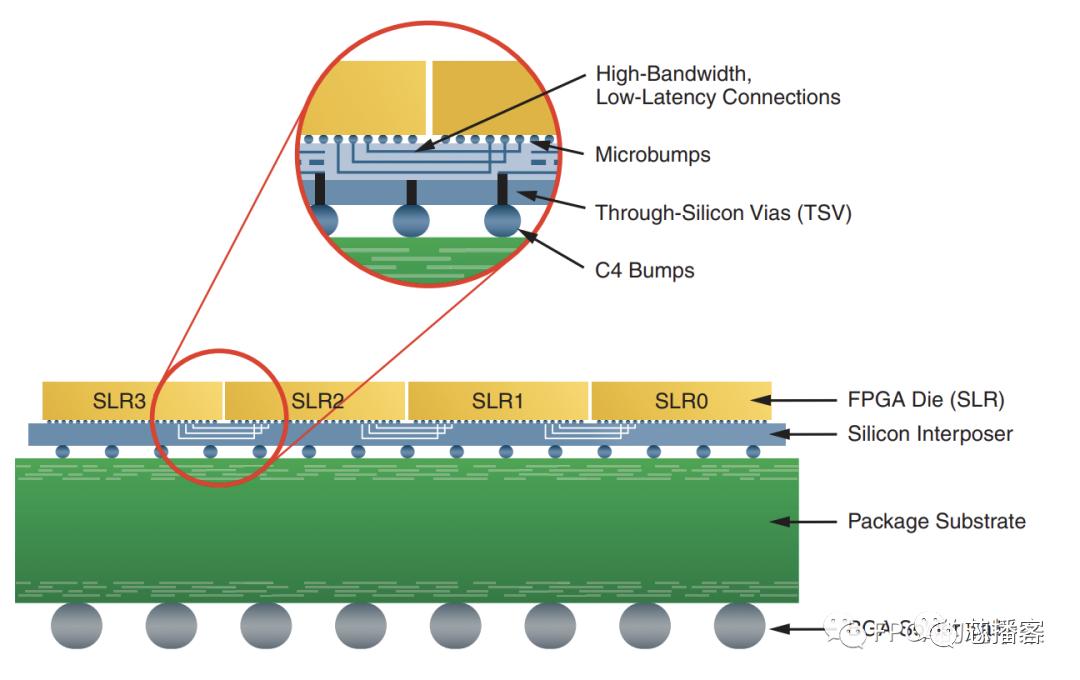
該截圖來自xilinx文檔872 - Large FPGA Methodology Guide (v14.3)
多die芯片為什么容易出現(xiàn)時序問題了,一個是SLL資源有限,兩個SLR之間的SSL資源是有限的。第二個就是本身die之間的走線延時相對比較長。
第一、從方案架構(gòu)設(shè)計的角度看,F(xiàn)PGA的設(shè)計其實是數(shù)據(jù)流0和1的流動路徑的設(shè)計,即數(shù)據(jù)流在不同模塊之間進行傳遞。多die的FPGA中,關(guān)鍵就是處理相關(guān)數(shù)據(jù)流跨die傳輸?shù)膯栴}。在方案設(shè)計階段,首先要考慮一級模塊在不同die中的分布。如何合理分配一級模塊的布局,主要從以下2個方面考慮。
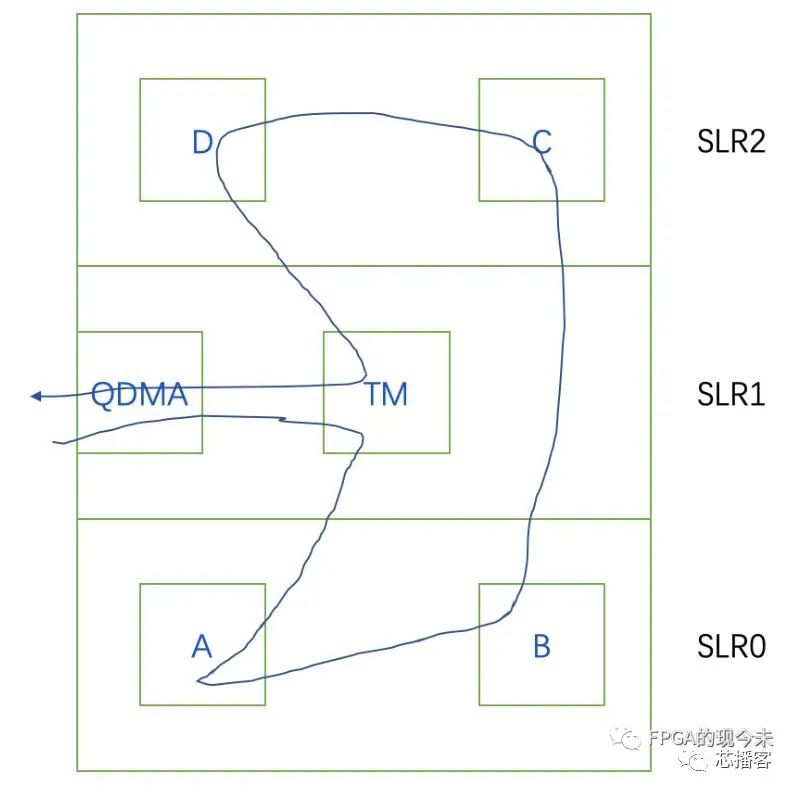
(1)資源,各個一級模塊分布在各個die的時候,要進行合理的資源評估,考慮到資源占用情況,建議每個die中LUT在60%左右(原文是不超過70%),REG資源不超過80%,RAM資源不超過80%。即moudle A + moudle B的資源盡量不要超過上述限制,如果超過,就要考慮把一個模塊做拆分,移入SLR1或者SLR2中。如果想跑的更快,建議資源利用率在50%左右。
(2)數(shù)據(jù)流,以die為單位,做到高內(nèi)聚、低耦合。一級模塊(越往頂層的方向)之間的接口要簡單,盡量采用流式接口。數(shù)據(jù)流也要簡單,數(shù)據(jù)流不要在各個die之間來回穿越(input和output減少交互)。即一級模塊劃分的時候,不但要考慮資源,還要考慮數(shù)據(jù)流的走向。
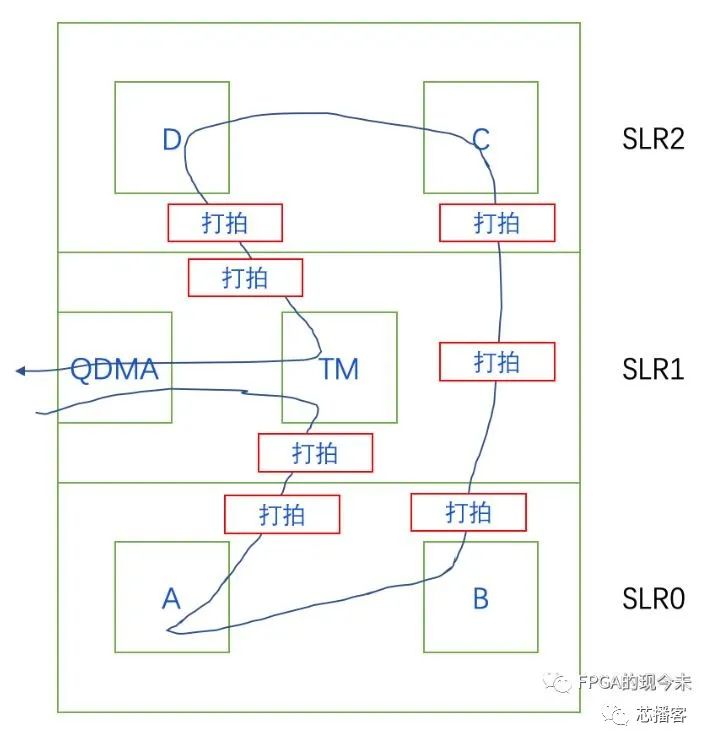
第二、在具體實現(xiàn)中,對于跨die的信號處理,官方的文檔(ug949)中提供了2種方式,一種是通過約束的方式使用LAGUNA寄存器,一種是通過自動流水打拍的方式。秉承問題的解決能用代碼就不用約束的思想,這里介紹一種和官方指導的第二種方案類似的方法,但是是用RTL代碼解決,可移植性更好。如下圖所示,紅色打拍邏輯(將所有的跨die信號打2-3拍)插入在跨die數(shù)據(jù)流的兩側(cè)。對于穿越整個die的數(shù)據(jù)流,比如module B到module C的數(shù)據(jù)流,可以在中間die插入一個過橋的打拍模塊。這種方案在實踐中被證明也能很好地解決時序收斂問題。
第三、復位信號的處理。跨die邏輯中有一類時序收斂問題就是復位信號的問題。筆者曾遇到一個問題,如下左圖所示,復位邏輯在中間的die,復位3個die的所有邏輯。每個die的資源消耗比較高,LUT在70%,RAM在80%,REG相對好點,不到50%。最終因為扇出較大,導致Recovery不滿足。
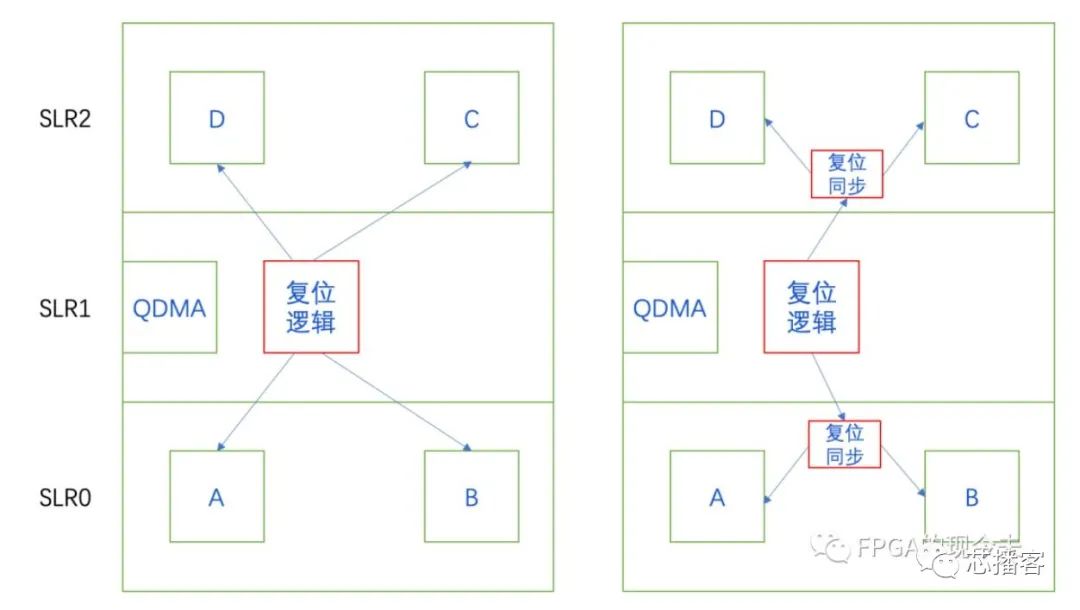
解決方案很簡單,就是將復位信號先同步到各個die后,只復位一個die的邏輯,這樣很好地解決了大量復位信號跨die問題,如下右圖所示。
總結(jié),解決多die FPGA的時序收斂問題,就是合理規(guī)劃數(shù)據(jù)流、復位的方案,跨die數(shù)據(jù)流做好“橋接”。
有許多因素影響映射到多FPGA系統(tǒng)設(shè)計的時鐘速率,如下所述:
設(shè)計類型:高度流水線化的設(shè)計可以更好地映射到FPGA的資源架構(gòu)中,并利用其豐富的FF,可能比流水線化程度較低的設(shè)計運行得更快。
設(shè)計內(nèi)部連接:具有復雜連接的設(shè)計(其中許多節(jié)點具有較高的扇出)將比具有較低扇出連接的設(shè)計運行得慢,因為可能存在較長的布線延遲。在設(shè)計中也很難找到分區(qū)解決方案的位置,因為只有很少的IO可以容納在FPGA面積內(nèi)。更高的互連設(shè)計將更可能需要將多個信號復用到相同的IO引腳上。
資源利用率級別:通常利用率級別越高,設(shè)計越擁擠,導致內(nèi)部延遲越長,時鐘速率越慢。
FPGA性能:FPGA本身的性能。即使采用了比較合適的優(yōu)化的FPGA版本設(shè)計,我們最終也會達到FPGA結(jié)構(gòu)的上限。然而,在大多數(shù)情況下,在FPGA的絕對內(nèi)部時鐘速率之前,設(shè)計的非優(yōu)化性質(zhì)和工具的效率將被視為一個極限。
FPGA間時鐘:在多FPGA系統(tǒng)中,F(xiàn)PGA到FPGA的時鐘偏移和連接延遲會限制系統(tǒng)時鐘速率。雖然FPGA理論上可以以數(shù)百兆的時鐘速率運行內(nèi)部邏輯,但其標準IO速度明顯較慢,通常是限制系統(tǒng)時鐘速率的主要因素。
外部接口:映射到FPGA原型系統(tǒng)中的SoC設(shè)計可能以比SoC目標時鐘慢的時鐘速率運行。除了預期的性能損失外,這并不是很大對于沒有外部刺激運行的封閉系統(tǒng)或刺激可以以較慢的速率運行以匹配系統(tǒng)時鐘速率的系統(tǒng)而言,這是一個問題。在某些情況下,原型系統(tǒng)必須與無法減緩的刺激交互。
FPGA間連接:當所有FPGA間IO連接耗盡時,可以使用引腳復用。在多時域復用(TDM)中,多個信號通過以比復用在一起的單個信號的數(shù)據(jù)速率更快的時鐘運行而共享單個引腳。例如,當復用四個信號時(TDM為1:4),假設(shè)要每個信號以20MHz的速率運行,組合信號將需要至少以80MHz的速率運行并且實際上更高,以便允許第一個和最后一個采樣信號的定時。由于FPGA到FPGA的數(shù)據(jù)速率受到物理FPGA引腳和電路板板間傳播延遲的限制,因此本示例中單個信號的有效數(shù)據(jù)速率將僅小于最大FPGA間數(shù)據(jù)速率的四分之一。
審核編輯:劉清
-
寄存器
+關(guān)注
關(guān)注
31文章
5336瀏覽量
120230 -
RAM
+關(guān)注
關(guān)注
8文章
1368瀏覽量
114641 -
RTL
+關(guān)注
關(guān)注
1文章
385瀏覽量
59761 -
SSI
+關(guān)注
關(guān)注
0文章
38瀏覽量
19243 -
FPGA芯片
+關(guān)注
關(guān)注
3文章
246瀏覽量
39795
原文標題:FPGA原型平臺能跑多快?如何優(yōu)化
文章出處:【微信號:于博士Jacky,微信公眾號:于博士Jacky】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
FPGA設(shè)計頻率計算方法
CAN FD的波特率到底能跑多快?
高頻RFID芯片的FPGA原型驗證平臺設(shè)計及驗證
高頻RFID芯片的FPGA原型驗證平臺的設(shè)計及結(jié)果介紹
lstm8l152c8t6的dac到底能跑多快
ARM Cortex-m3到底可以做多快
細數(shù)全球十大最快電動車輛大比拼,究竟能跑多快?
“加水就能跑1000公里的車”到底是黑科技還是騙局呢?
FACE-VUP:大規(guī)模FPGA原型驗證平臺
STM8L的DAC能跑多快(一)

如何建立適合團隊的FPGA原型驗證系統(tǒng)平臺與技術(shù)?
多臺FPGA原型驗證平臺可自由互連
多臺FPGA原型驗證平臺系統(tǒng)如何實現(xiàn)自由互連
原型平臺是做什么的?proFPGA驗證環(huán)境介紹






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論