 低成本開源聊天機器人Vicuna:可達到ChatGPT/Bard 90%以上水平
低成本開源聊天機器人Vicuna:可達到ChatGPT/Bard 90%以上水平
大型語言模型 (LLM) 的快速發展徹底改變了聊天機器人系統,從而實現了前所未有的智能水平,譬如 OpenAI 的 ChatGPT。但 ChatGPT 的訓練和架構細節仍不清楚,阻礙了該領域的研究和開源創新。受 Meta LLaMA 和 Stanford Alpaca 項目的啟發,來自加州大學伯克利分校、CMU、斯坦福大學和加州大學圣地亞哥分校的成員,共同推出了一個 Vicuna-13B 開源聊天機器人,由增強的數據集和易于使用、可擴展的基礎設施支持。
根據介紹,通過根據從 ShareGPT.com (一個用戶可以分享他們的 ChatGPT 對話的網站) 收集的用戶共享對話微調 LLaMA 基礎模型,Vicuna-13B 與 Stanford Alpaca 等其他開源模型相比展示了具有競爭力的性能。
以 GPT-4 為評判標準的初步評估顯示,Vicuna-13B 達到了 OpenAI ChatGPT 和 Google Bard 90% 以上的質量,同時在 90% 以上的情況下超過了 LLaMA 和 Stanford Alpaca 等其他模型的表現。訓練 Vicuna-13B 成本約為 300 美元。訓練和服務代碼,以及在線演示都是公開的,可用于非商業用途。
為了確保數據質量,Vicuna 團隊將 HTML 轉換回 markdown 并過濾掉一些不合適或低質量的樣本。以及將冗長的對話分成更小的部分,以適應模型的最大上下文長度。其訓練方法建立在 Stanford Alpaca 的基礎上,并進行了以下改進:
內存優化:為了使 Vicuna 能夠理解長上下文,開發團隊將最大上下文長度從 Alpaca 中的 512 擴展到 2048,大大增加了 GPU 內存需求。通過利用 utilizing gradient checkpointing 和 flash attention 來解決內存壓力。
多輪對話:調整訓練損失以考慮多輪對話,并僅根據聊天機器人的輸出計算微調損失。
通過 Spot 實例降低成本:40 倍大的數據集和 4 倍的訓練序列長度對訓練費用提出了相當大的挑戰。Vicuna 團隊使用 SkyPilot managed spot 來降低成本,方法是利用更便宜的 spot 實例以及自動恢復搶占和自動區域切換。該解決方案將 7B 模型的訓練成本從 500 美元削減至 140 美元左右,將 13B 模型的訓練成本從 1000 美元左右削減至 300 美元。
Vicuna 團隊構建了一個服務系統,該系統能夠使用分布式 workers 為多個模型提供服務;它支持來自本地集群和云的 GPU worker 的靈活插件。通過利用 SkyPilot 中的容錯控制器和 managed spot 功能,該服務系統可以很好地與來自多個云的更便宜的 spot 實例一起工作,以降低服務成本。它目前是一個輕量級的實現,未來將努力將集成更多的最新研究成果。
具體來說,開發團隊首先從 ShareGPT.com 收集了大約 7 萬個對話,然后增強了 Alpaca 提供的訓練腳本,以更好地處理多輪對話和長序列;訓練在一天內在 8 個 A100 GPU 上使用 PyTorch FSDP 完成。為了提供演示服務,他們還實現了一個輕量級的分布式服務系統。通過創建一組 80 個不同的問題并利用 GPT-4 來判斷模型輸出,對模型質量進行了初步評估。為了比較兩個不同的模型,團隊成員將每個模型的輸出組合成每個問題的單個提示。然后將提示發送到 GPT-4,GPT-4 評估哪個模型提供更好的響應。
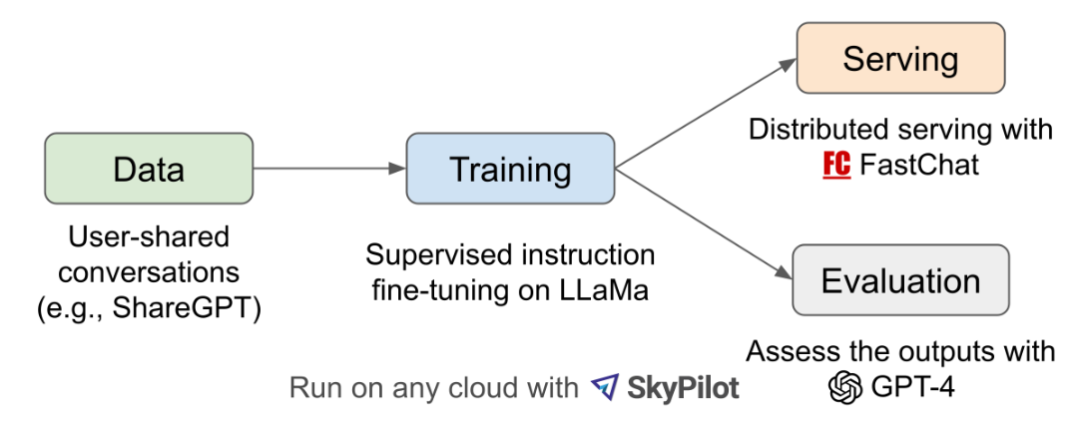
LLaMA、Alpaca、ChatGPT 和 Vicuna 的詳細對比如下:
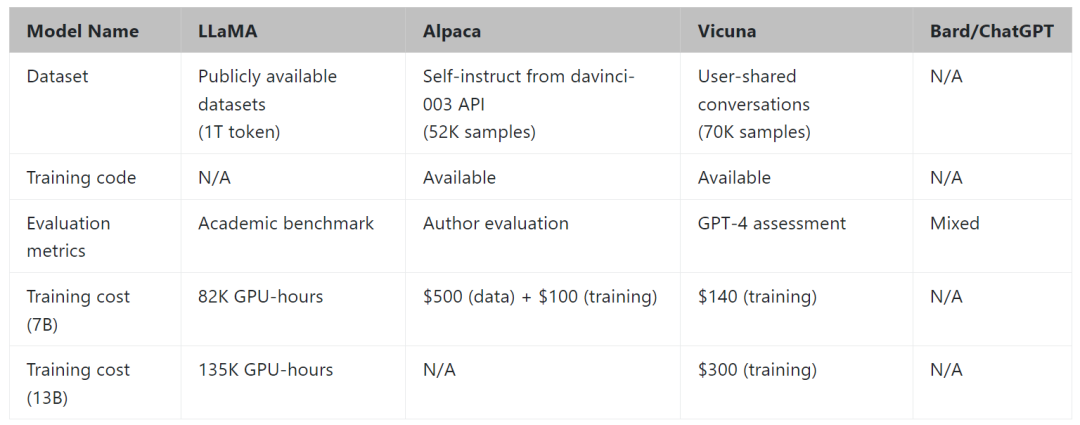
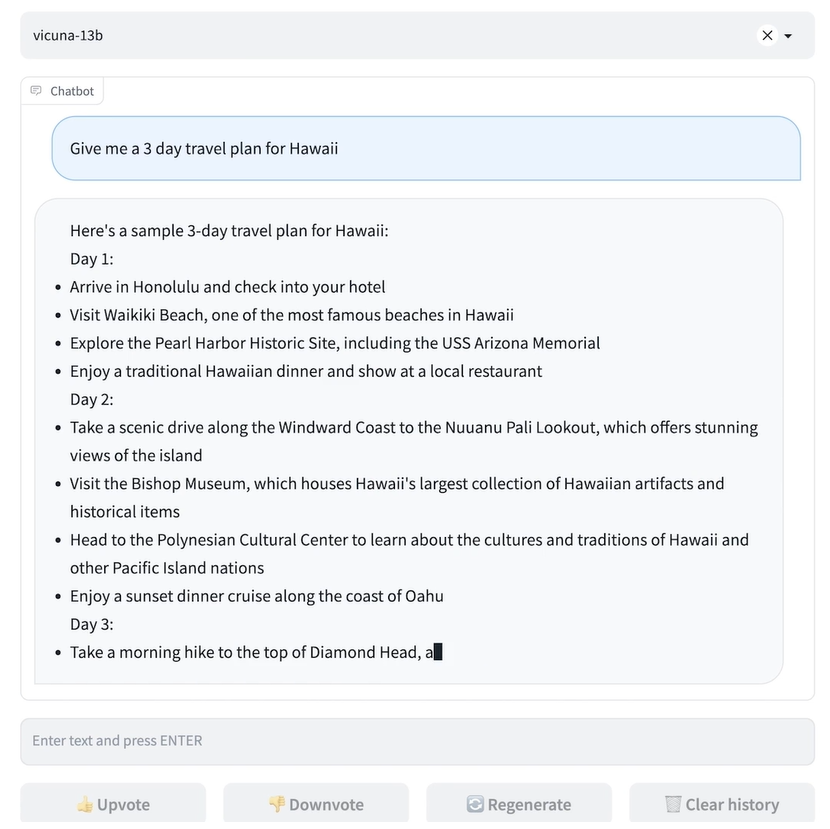
Vicun 團隊展示了 Alpaca 和 Vicuna 對基準問題的回答示例。在使用 70K 用戶共享的 ChatGPT 對話對 Vicuna 進行微調后,其發現與 Alpaca 相比,Vicuna 能夠生成更詳細、結構更合理的答案,并且質量與 ChatGPT 相當。
例如,在要求 “撰寫一篇引人入勝的旅游博文,介紹最近的夏威夷之行,突出文化體驗和必去的景點” 時,GPT-4 的評價得分為:Alpaca-13b 7/10,Vicuna-13b 10/10。并闡述理由稱,Alpaca 提供了旅行博文的簡要概述,但沒有按照要求實際撰寫博文,導致得分較低。Vicuna-13b 則就最近的夏威夷之行撰寫了一篇詳細而有吸引力的旅游博文,強調了文化體驗和必看的景點,完全滿足了用戶的要求,因此獲得了較高的分數。
與此同時,Vicun 的初步發現表明,在比較聊天機器人的答案時,GPT-4 可以產生高度一致的等級和詳細的評估。下圖中總結的基于 GPT-4 的初步評估顯示,Vicuna 達到了 Bard/ChatGPT 的 90% 能力。不過總的來說,為聊天機器人建立一個評估系統仍是一個需要進一步研究的開放式問題。
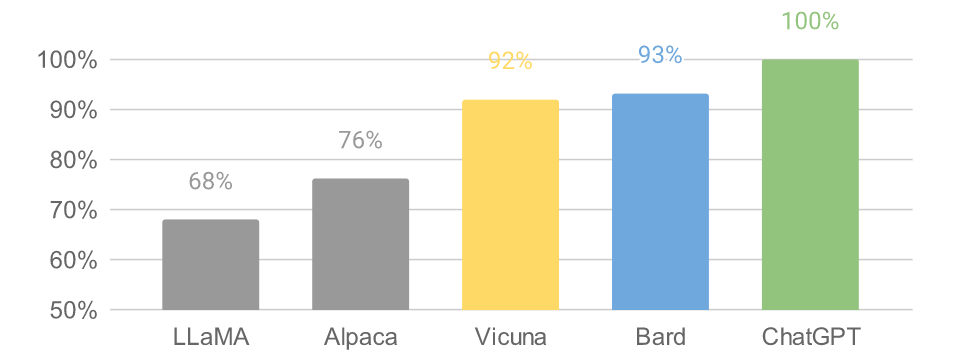
Vicun 團隊提出了一個基于 GPT-4 的評估框架來自動評估聊天機器人的性能。設計了八個問題類別,以測試聊天機器人性能的各個方面。并基于每個類別選擇十個問題,分別由 LLaMA、Alpaca、ChatGPT、Bard 和 Vicuna 生成答案,然后要求 GPT-4 根據有用性、相關性、準確性和細節來評估答案質量。結果發現 GPT-4 不僅可以產生相對一致的分數,而且可以詳細解釋為什么給出這樣的分數(詳細示例鏈接)。但在判斷編碼 / 數學任務方面,GPT-4 則不太擅長。
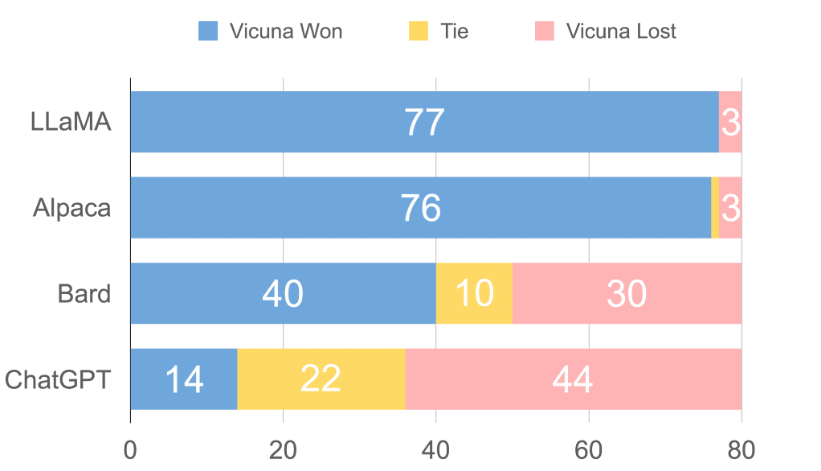
數據表明在超過 90% 的問題中,相較 LLaMA、Alpaca 等,GPT-4 更傾向 Vicuna 生成的答案,并且它實現了可與專有模型(ChatGPT、Bard)競爭的性能。在 45% 的問題中,GPT-4 將 Vicuna 的回答評為優于或等于 ChatGPT 的回答。
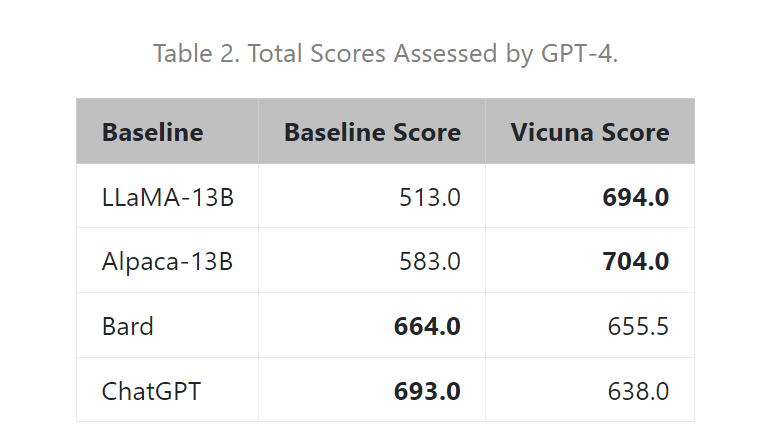
總的來說,雖然最近行業發展如火如荼,但事實上聊天機器人仍然面臨局限性,例如難以解決基本的數學問題或編碼能力有限。且為聊天機器人開發一個全面、標準化的評估系統,也是一個需要進一步研究的懸而未決的問題。
開發團隊承認,Vicuna 不擅長涉及推理或數學的任務,并且在準確識別自己或確保其輸出的事實準確性方面可能存在局限性。此外,它還沒有得到充分優化以保證安全性或減輕潛在的毒性或偏見。為了解決安全問題,他們使用 OpenAI moderation API 來過濾掉在線演示中不適當的用戶輸入。
審核編輯 :李倩
-
開源
+關注
關注
3文章
3363瀏覽量
42535 -
數據集
+關注
關注
4文章
1208瀏覽量
24722 -
聊天機器人
+關注
關注
0文章
339瀏覽量
12323 -
OpenAI
+關注
關注
9文章
1096瀏覽量
6556
原文標題:低成本開源聊天機器人Vicuna:可達到ChatGPT/Bard 90%以上水平
文章出處:【微信號:OSC開源社區,微信公眾號:OSC開源社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論