 基于深度學習立體匹配的基本網絡結構和變種
基于深度學習立體匹配的基本網絡結構和變種
深度學習立體匹配之 MC-CNN中兩種結構:MC-CNN-fst和MC-CNN-acrt。這兩個算法由Zbontar和LeCun共同研發,分別代表了速度與精度的平衡。MC-CNN-fst關注于快速處理,而MC-CNN-acrt則更注重匹配精度。這兩種算法為深度學習立體匹配技術的發展奠定了基礎,而從效果上看他們明顯超過了當時很多優秀的立體匹配算法,成為了SOTA。我們先看看當前的學習地圖:
學習進度地圖 那么在本篇文章中,我將更深入地探討基于深度學習的立體匹配算法,涉及一系列有趣的網絡結構和變種。我會帶你首先回顧這兩個算法的基本架構,然后討論如何通過網絡變種、訓練策略、正則化和視差估計等技巧來進一步提升它們的性能。這篇文章旨在幫助大家全面地了解深度學習立體匹配算法的發展現狀和研究趨勢。今天的文章大量參考引用了參考文獻[1],再次對作者表示敬意! 1. 基本網絡結構回顧
1.1 網絡架構回顧
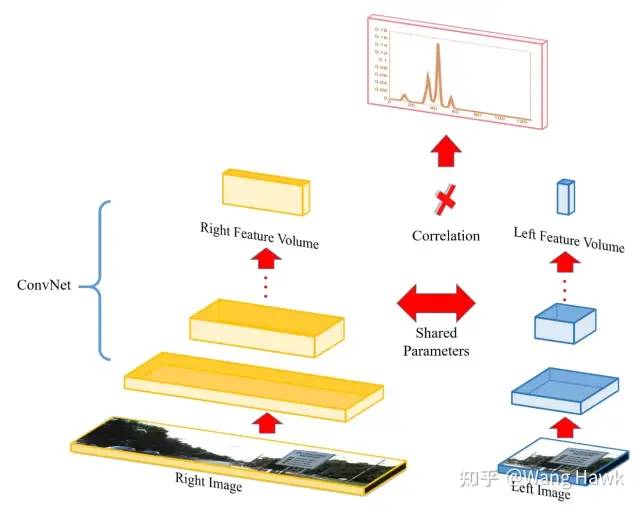
下面是我上次提到的Zbontar和LeCun[2][3]提出的兩種算法的架構圖,這是是深度學習立體匹配領域最基礎的結構。其中一個被作者命名為MC-CNN-fst,另外一個則命名為MC-CNN-acrt,其后綴fst和acrt分別代表fast和accurate,顧名思義MC-CNN-fst追求的是計算效率,而MC-CNN-acrt追求的則是準確性。
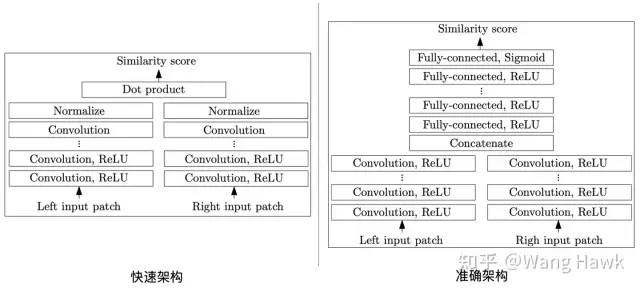
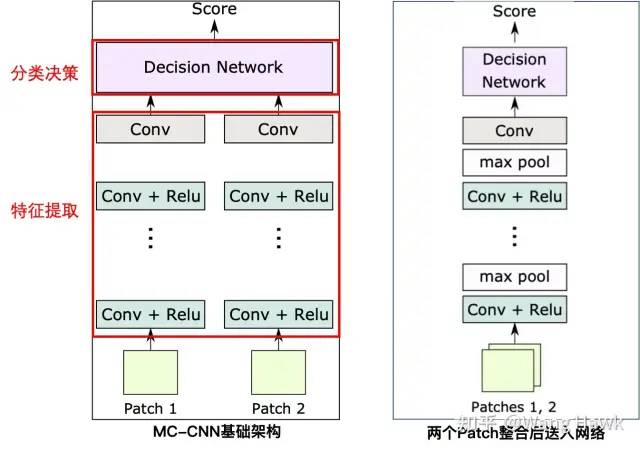
MC-CNN的兩種架構 我們可以利用下圖來描述它們的共同點,它們都是由左右兩條分支組成了特征提取的網絡,提取出來的特征圖都會進入到決策模塊,該模塊負責計算出左右兩個Patch對應的兩個特征圖之間的相似度,所以整個網絡分為特征提取和分類決策這兩部分。
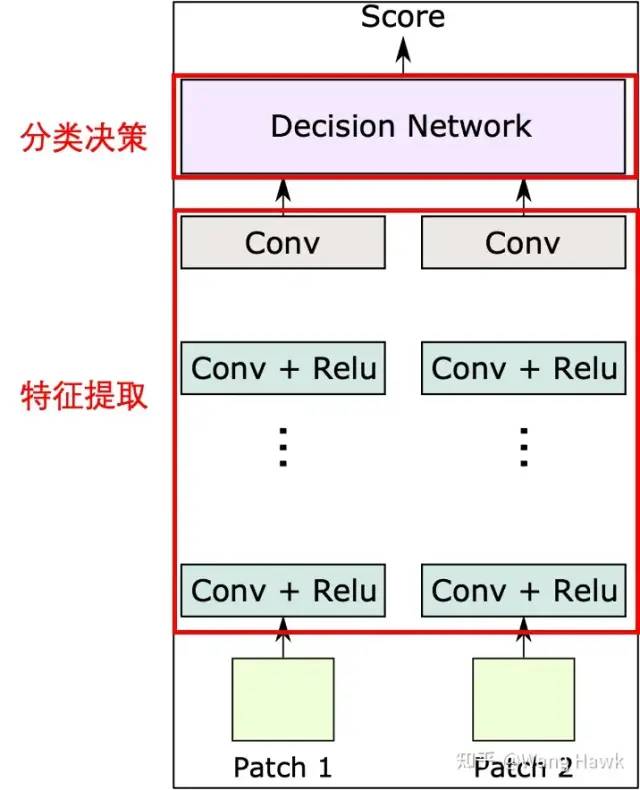
基本網絡構成 它們的不同點是:
特征提取網絡不同。除開層數等信息之外,fast結構還在特征提取網絡的尾部添加了歸一化層,用于對特征圖進行歸一化。
分類決策部分不同,fast結構中,特征圖在每個分支中已經進行了歸一化。所以分支決策部分直接是計算兩個歸一化的特征圖的點積,及余弦相似度。而在accurate架構中,特征圖首先在通道維度連接在一起,然后經過多個全連接層,再通過Sigmoid函數得到最后的相似度得分
這種架構可以快速判斷左右兩幅圖中取出的兩個Patch是否相似,結構也很簡單,所以很多學者采用了這種架構,并進行了改進,我在下一節會談到各種改進方向。
1.2 相似度計算
在特征提取之后,特征被送入上層模塊進行相似度的計算。相似度計算是立體匹配算法的核心部分,可以分為兩大類:手動相似度計算和決策網絡。
1.2.1 手動相似度計算
手動相似度計算無需訓練,它直接通過一些預先定義好的距離度量方法計算特征之間的相似性。常見的手動相似度計算方法包括L2距離、余弦距離、歸一化的相關度或歸一化內積等。這些方法的優勢在于可以通過卷積操作實現,提高計算效率,并且無需訓練。然而,它們可能無法充分適應不同的數據集特性,導致匹配精度受到限制。MC-CNN-fst算法就是采用的這種方式
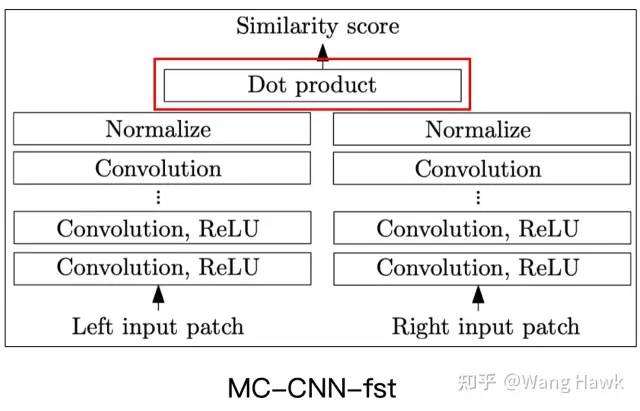
快速架構采用余弦相似度
1.2.2 采用神經網絡計算相似度
與手動相似度計算相比,用于決策的神經網絡需要訓練,但可以提供更準確的相似度計算結果。決策網絡可以采用1x1卷積、全卷積層實現,或通過卷積層與全連接層的組合實現。決策網絡與特征提取模塊聯合訓練,從而學習到更適應當前數據集的相似度計算方式, MC-CNN-acrt就是典型代表
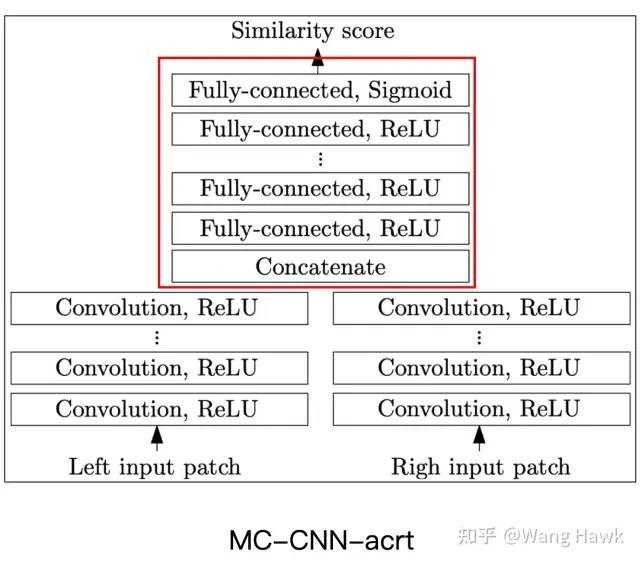
準確架構采用Sigmoid結果 全連接層實現的方法包括Han等人[4]的全連接層+SoftMax,Zagoruyko和Komodakis[5]的方法,以及Zbontar等人[3]提出的MC-CNN-acrt網絡。在這些方法中,特征提取分支的特征圖的結合方式有兩種:一種是在通道層面連接[4][5][3],另一種是通過類似Mean Pooling等方式連接[5],這樣可以處理任意多個Patch的相似度,而不用改變網絡結構。

決策網絡的優點是相似度計算結果更加適配當前的數據集,因此匹配精度更高,但相應地計算速度會更慢。因此,在實際應用中,需要根據具體問題和場景權衡決策網絡與手動相似度計算方法的選擇。
2. 網絡的變種
在上面結構的基礎上,很多學者研究了各種改進和提升的方法,這一節我們就來談談各種改進
2.1 引入Max-pooling操作處理大視差和大尺度Patch
回顧一下最簡單的立體匹配代價計算公式:
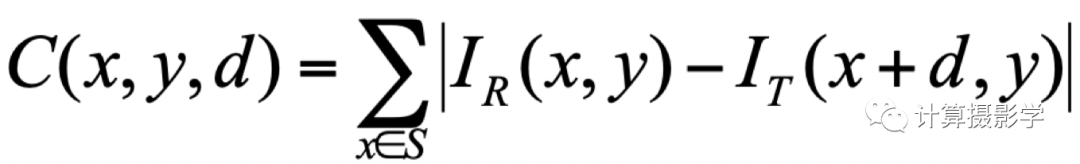
SAD代價計算公式 我們看到整個計算的時間復雜度是O(WHSD),其中W/H是圖像的長寬,S是支持窗的尺寸,D則是視差值的范圍。所以支持窗越大,計算復雜度越高。對應到我們的深度學習架構中,特征圖越大,計算復雜度越高。對應到我們深度學習的方法里面,則是特征圖越大,計算復雜度越高,視差范圍越大,計算復雜度越高。所以為了解決原始MC-CNN在處理大視差和大尺寸Patch時的效率問題,Zagoruyko和Komodakis[37]以及Han等人[4]在每層后面都添加了max-pooling和下采樣操作。這樣做的目的是使網絡能夠適應更大的Patch尺寸和視角變化。通過這種方式,增強的架構能夠在保持較高匹配精度的同時提高處理速度,因為這樣得到的特征圖尺寸更小,如下圖所示:
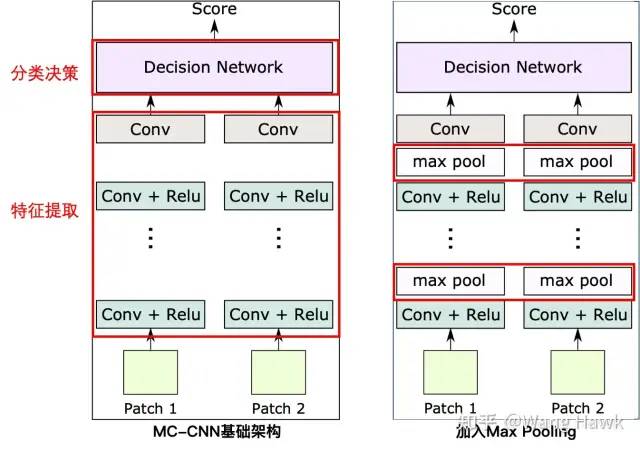
加入Max Pooling前后對比
2.2 引入SPP模塊增強網絡結構應對不同尺度輸入時的靈活性
另一個重要的改進是在特征計算分支的末端加入了空間金字塔池化(SPP)模塊。SPP模塊可以輸入任意尺寸的特征Patch,輸出固定尺寸的特征圖(如圖2-c所示)。SPP的Pooling尺寸根據輸入尺寸而改變,這樣使得不同尺寸的輸入可以得到相同尺寸的輸出。這樣當輸入的Patch尺寸改變時,網絡結構不用改變。這一點對于處理不同尺寸的圖像數據具有重要意義,使得這個架構更具靈活性。
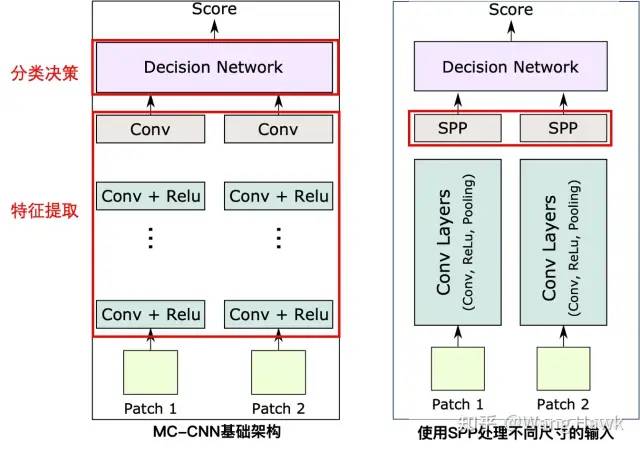
加入SPP前后對比
2.3 使用ResNet使得網絡可以更深
這一點我想很多讀者都不陌生,ResNet已經廣泛應用在各種領域的神經網絡里面了,所以盡管最初時,類似MC-CNN這樣的算法還沒有采用殘差網絡結構,后續的算法幾乎都加入了這個結構。比如Shaked and Wolf [6]就使用了ResNet,構建了如下的網絡結構,這里淺紅色標注的部分就是典型的殘差模塊,這使得我們可以訓練非常深的網絡,從而捕捉到圖像中更高層次的特征:
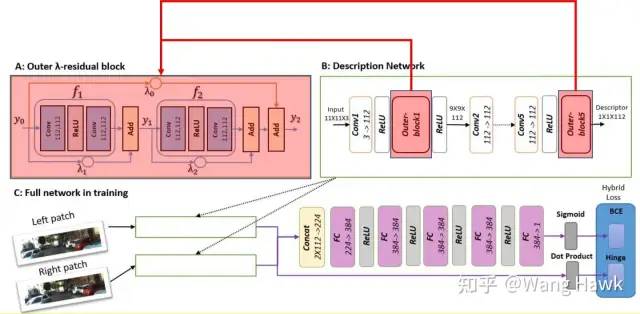
采用ResNet加深網絡
2.4 使用空洞卷積或SPP得到更大的感受野
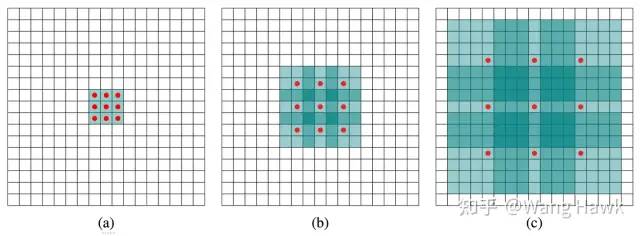
我在70. 三維重建5-立體匹配1,立體匹配算法總體理解中講過,在重復紋理、無紋理區域我們是希望盡量采用大尺寸的支持窗來來提升信噪比和像素之間的區分度。

不同尺度的支持窗 對應到我們深度學習的算法中,則是我們在某些時候需要更大的感受野。擴大感受野的方法有多種,比如增大輸入Patch的尺寸、或是使用更大的卷積核再配合帶有更大步長的池化操作降低尺寸。前者會導致計算復雜度上升,后者則會導致特征圖的分辨率降低使得細節丟失。所以就有了兩種更好的方式
2.4.1 使用空洞卷積來提升感受野尺寸
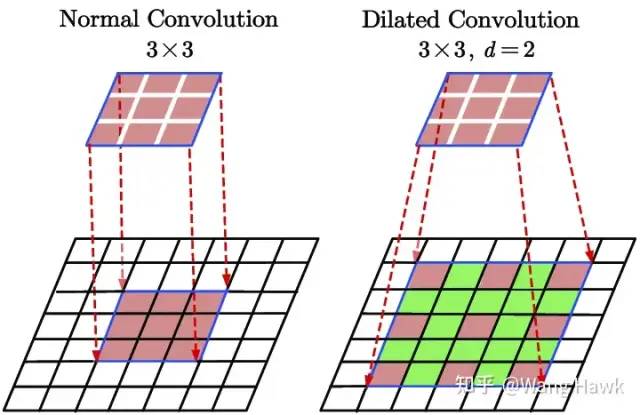
第一種方法是使用空洞卷積——顧名思義,空洞卷積的卷積核是有空洞的,這樣使得我們可以有更大的感受野,但是計算量卻不改變,這種技巧后來被用到了很多領域。
空洞卷積 下圖是普通卷積(左)和空洞卷積(右)的對比:
2.4.2 使用SPP來提升感受野尺寸
我們上面見過引入SPP模塊可以使得網絡可以靈活應對不同尺寸的輸入,而其中一個重要的應用就是利用SPP模塊來擴大感受野。比如Park et al. [11]提出了一種叫做FW-CNN的網絡架構,其中引入了一個簡稱為4P的模塊,即所謂Per-pixel Pyramid Pooling - 逐像素的金字塔池化操作。 我們之前講過,如果采用更大的卷積核,加上更大步長的小尺寸的池化操作,可以擴大感受野——但這樣會導致丟失原始特征圖中的細節信息。如果換成更大尺寸的池化操作,但步長設置為1呢,這樣當然也可以有更大的感受野——但同樣也會丟失圖像的細節。于是,這里的4P操作就對每個像素同時采用多種不同尺寸的池化窗口,并將輸出連接以創建新的特征圖。生成的特征圖包含了從粗到細的尺度信息:
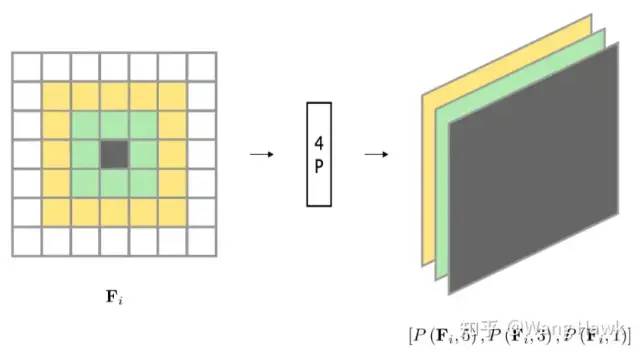
4P操作可以加入到網絡的不同位置,在FW-CNN中,4P模塊的位置如下所示:
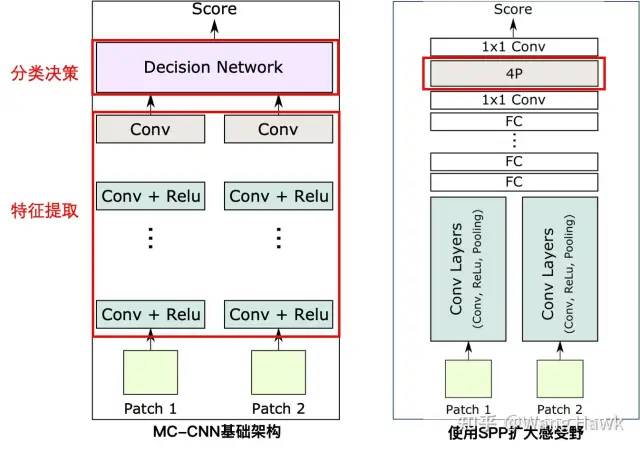
FW-CNN的這種方式雖然擴大了感受野,但是4P模塊需要和全連接層一樣,每個視差層級計算一次,所以計算量比較大。因此,Ye et al. [7]等提出了一種改進的方式,把SPP放到每個特征計算分支的末尾,并且采用多尺度的SPP,既降低了計算量,又能有較大的感受野。
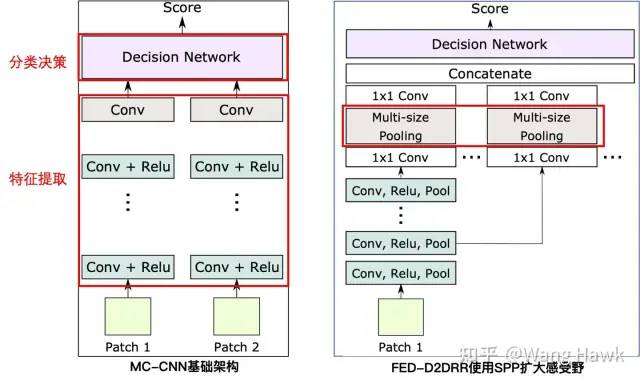
2.5 使用多尺度特征得到更好的結果 前面的方法都是采用一種尺寸的輸入Patch,但在基礎架構的基礎上,還可以擴展到學習多尺度的Patch的特征,進一步提升效果,比如Zagoruyko和Komodakis[5]中提到了一種架構如下:
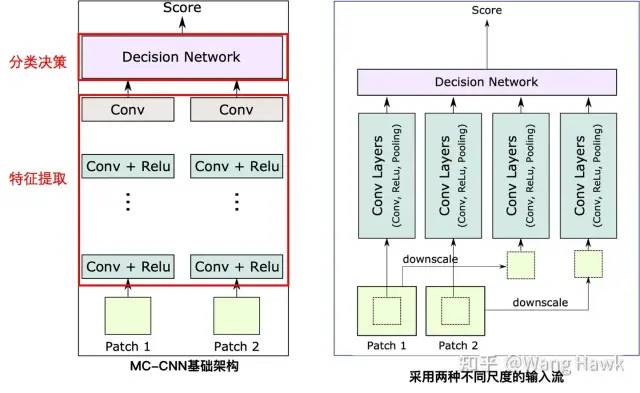
這里有兩種輸入,第一種是從輸入的Patch中心裁剪32x32的區域送入網絡,第二種是將輸入的64x64的Patch縮小為32x32送入網絡。因此前者比后者的解析力更高。這樣網絡在單次前向推理后就可以提取到不同尺度和解析力的特征,效果也就更好,效率也較高。Chen et al. [8]等提出了一種類似的結構,只不過兩組流各自做各自的特征提取和分類決策,決策的結果再通過投票整合到一起,作為最后的輸出。
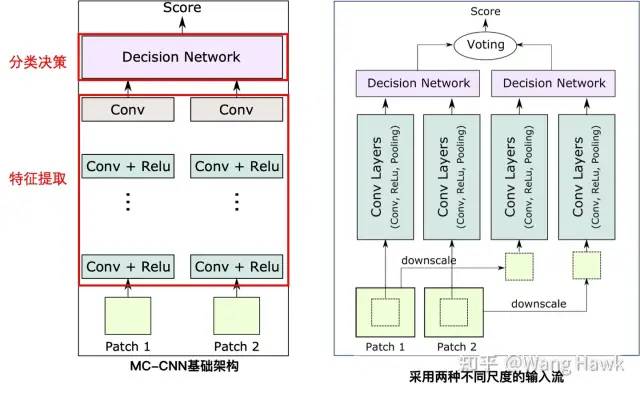
2.6 改變網絡結構,得到更高的效率
2.6.1 一次性計算所有視差層級的代價
前面我們講的方法在分類決策時,每個像素需要n_d次通過決策模塊來計算代價,其中nd是視差層次的數量。如果我們的決策模塊采用的是相關計算(類似內積計算),那么可以利用到相關性天然的高度并行性來大大減少前向傳播次數。例如,Luo等人[9] 就提出了下面這樣的結構,這里左圖的Patch尺寸不變,但右圖會采用更大尺寸的Patch,這樣一次性最大可以把所有可能得右圖Patch的特征全部提取出來,然后通過并行的相關性計算一次性把該像素所有可能的代價計算出來。在這個網絡中,左圖的特征是64維的,而右圖提到的特征則是nd x 64維的。
并行相關度計算提升效率
2.6.2 一次性提取特征
我們之前展示的結構的輸入都是兩個Patch,而非整個圖像。在Zagoruyko和Komodakis[5]中提到,實際上可以通過輸入兩個圖像,一次性提取左右兩個視圖的特征圖,不需要逐Patch的計算,也不需要每個視差層級計算一次
2.6.3 對整幅圖計算代價,而非逐Patch計算
另外,在Zagoruyko和Komodakis[5]還提到,可以通過將決策網絡中的全連接層改為1x1卷積操作,這樣就可以對整幅圖計算代價,而不是對Patch計算,當然每個視差層級還是需要計算一次。 以上兩個方法在我上一篇文章種已經講過了,下面是我當時給的偽代碼
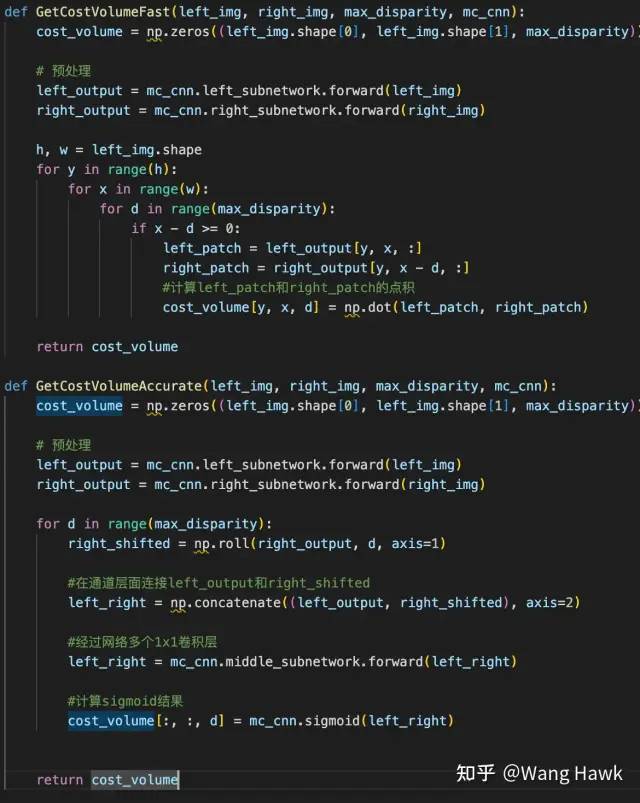
加速推理的偽代碼
2.7 整合特征提取和決策模塊,得到更好的效果
在Zagoruyko and Komodakis [5]中還提到了一種特別的結構,輸入的兩個Patch從一開始就整合成多通道的圖像送入網絡。于是網絡沒有專門分開的特征提取模塊,而是將特征提取與決策整合到一起,如下所示。這種結構訓練比較簡單,不過在推理時效率低,因為每個像素需要推理nd次:
通道維度上連接圖像再送入網絡 這種將多個輸入直接在通道維度上連接再送入網絡的方式很有用,我們之后還會看到類似的用法。這一節我們看到了多種網絡結構的變種,而下一節我來介紹一下各類網絡的訓練策略。
3. 網絡訓練策略
我們之前看到的特征提取網絡和代價決策網絡都需要訓練,而訓練的策略則分為強監督型和弱監督型兩類。我重點介紹一下強監督型訓練,然后捎帶提一下弱監督或自監督的訓練策略
3.1 強監督型訓練
這里面又分為兩種形式。 第一種的訓練樣本的基本單元是一對patch,它們要么是匹配的正樣本,要么是不匹配的負樣本。網絡要學習的是這一對patch間的匹配程度。那么如果輸入的是正樣本對,理想的匹配程度為1,如果輸入的是負樣本對,那么理想的匹配程度為0。通過某些損失函數的迭代約束,網絡會調整自身權重,使得最終能夠甄別出輸入patch對之間是匹配的還是不匹配的。
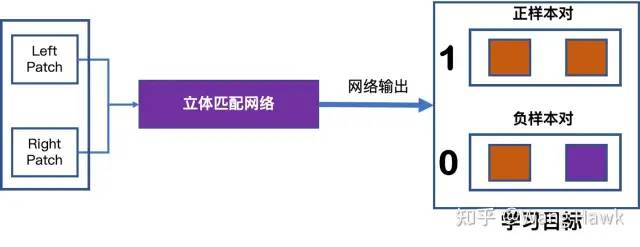
輸入一對Patch進行訓練 第二種的訓練樣本的基本單元是兩對Patch,其中一對Patch是匹配的,其中右視圖的Patch來自于與左視圖對應的右極線上。另外一對Patch則是不匹配的。此時網絡優化的目標是盡量放大這兩對Patch的匹配值之間的差異。正樣本對的相似度計算結果應該比負樣本對的相似度計算結果大得多。
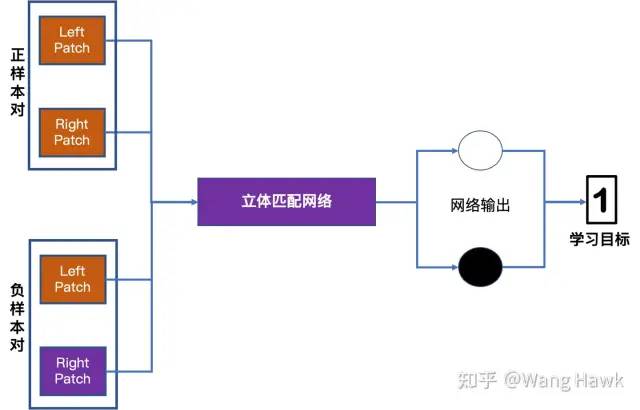
輸入兩對Patch進行訓練 強監督訓練的損失函數用于衡量網絡輸出和學習目標之間的差異,主要有三類損失函數
L1距離
Hinge損失函數
交叉熵損失函數
3.2 弱監督型訓練
為了減少對標注數據的需求,人們提出了弱監督訓練方式,這通常是通過引入一些先驗信息約束網絡的學習過程來實現的,Tulyakov等人[10]就利用多實例學習(MIL)結合立體約束和關于場景的粗略信息,來訓練立體匹配網絡,而這些數據集并沒有可用的真實標簽。 跟傳統的監督技術不同,弱監督訓練并不需要成對的匹配和不匹配圖像塊。實際上,訓練集是由N個三元組組成的。每個三元組包括:(1)從參考圖像上的水平線上提取的W個參考塊;(2)從右圖像對應的水平線上提取的W個Patch,作者成為正Patch,它們跟W個參考塊有可能是匹配的;(3)從右圖像上另一個水平線上提取的W個負Patch,即與參考塊絕對不匹配的塊。這樣一來,我們就可以直接從立體圖像對中自動生成訓練集,不需要手動進行標注了。 在訓練網絡時,研究人員使用了五個約束條件來引導學習過程:
對極約束:這個約束告訴我們,在左右圖像中的匹配點必須位于相應的水平線上。
視差范圍約束:它告訴我們每個像素的視差值在一個已知的范圍內。
唯一性約束:對于每個參考像素,只能有一個唯一的匹配像素。
連續性(平滑性)約束:表示物體表面的視差變化通常是平滑的,除非在物體邊界附近發生突變。
排序約束:指的是在左圖像上的參考點之間的順序應該與在右圖像上的匹配點之間的順序一致。
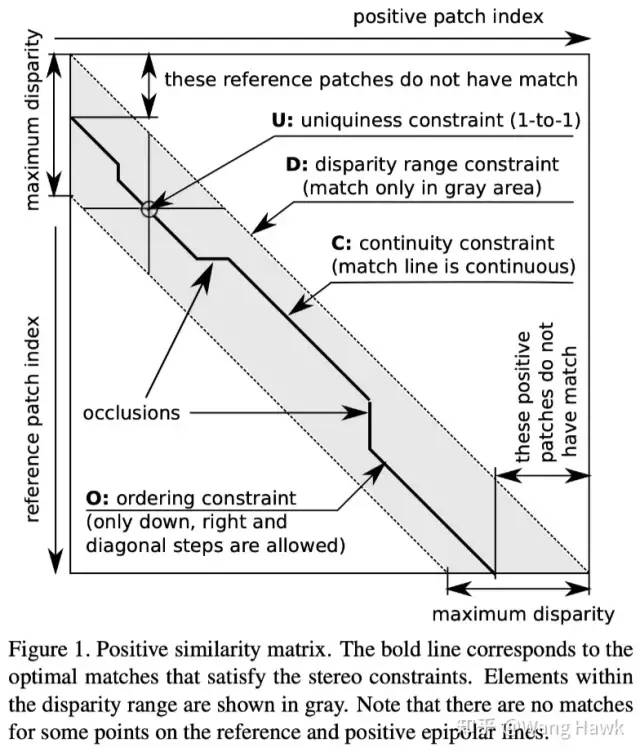
根據這些約束條件,研究人員定義了三個損失函數來引導網絡學習。其中,多實例學習(MIL)損失使用了對極約束和視差范圍約束。收縮損失在MIL損失的基礎上增加了唯一性約束,使得匹配點更加準確。收縮-DP損失則結合了所有約束條件,并利用動態規劃來尋找最佳匹配。 通過這種方法,網絡能夠根據這些約束條件進行學習,從而在沒有充分標注的數據集上實現立體匹配。
4. 思考和小結
在本文中,我們介紹了深度學習立體匹配方法的基礎網絡架構和常見的網絡變種,以及訓練策略。我們看到,在不同的應用場景下,立體匹配問題需要不同的解決方案。為了應對這些挑戰,研究者們提出了各種改進和優化方法,從網絡結構到訓練策略都進行了探索。其中我們列出了網絡結構的各種變種
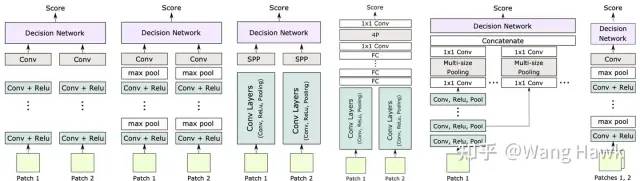
盡管深度學習立體匹配方法已經取得了顯著的進展,但仍然存在一些問題需要進一步研究和解決。例如,對于大視差和大尺度Patch的處理、不同尺度輸入的靈活性、更高的效率等方面還有改進的空間。此外,如何將深度學習方法應用于實際應用中,也是需要進一步探索和研究的問題。 我們目前看到的方法,都是類似MC-CNN這樣遵循了傳統立體匹配架構的方法。我會在下一篇文章開始介紹端到端的立體匹配算法,它們遵循完全不同的策略和邏輯,一定會給你帶來不一樣的感受! 下面是你現在的位置,喜歡今天的文章就點個贊,持續關注我吧!
學習進度地圖
審核編輯 :李倩
-
算法
+關注
關注
23文章
4608瀏覽量
92844 -
網絡結構
+關注
關注
0文章
48瀏覽量
11077 -
深度學習
+關注
關注
73文章
5500瀏覽量
121117
原文標題:基于深度學習立體匹配的基本網絡結構和變種
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
神經網絡結構搜索有什么優勢?
彩色鏡像圖像的立體匹配方法
基于蟻群優化算法的立體匹配
基于擴展雙權重聚合的實時立體匹配方法
基于顏色調整的立體匹配改進算法

超像素分割的快速立體匹配
基于mean-shift全局立體匹配方法
如何使用跨尺度代價聚合實現改進立體匹配算法
雙目立體計算機視覺的立體匹配研究綜述

一種基于PatchMatch的半全局雙目立體匹配算法

融合邊緣特征的立體匹配算法Edge-Gray





 工商網監
工商網監
評論