") 基于預(yù)訓(xùn)練語言模型設(shè)計了一套統(tǒng)一的模型架構(gòu)
基于預(yù)訓(xùn)練語言模型設(shè)計了一套統(tǒng)一的模型架構(gòu)
本文介紹了本小組發(fā)表于ICLR 2023的論文UniKGQA,其基于預(yù)訓(xùn)練語言模型設(shè)計了一套統(tǒng)一的模型架構(gòu),同時適用于多跳KBQA檢索和推理,在多個KBQA數(shù)據(jù)集上取得顯著提升。

該論文發(fā)表于 ICLR-2023 Main Conference:
論文鏈接:https://arxiv.org/pdf/2212.00959.pdf
開源代碼:https://github.com/RUCAIBox/UniKGQA
進(jìn)NLP群—>加入NLP交流群(備注nips/emnlp/nlpcc進(jìn)入對應(yīng)投稿群)
前言
如何結(jié)合PLM和KG以完成知識與推理仍然是一大挑戰(zhàn)。我們在NAACL-22關(guān)于常識知識圖譜推理的研究 (SAFE) 中發(fā)現(xiàn),PLM 是執(zhí)行復(fù)雜語義理解的核心。因此,我們深入分析了已有的復(fù)雜 GNN 建模外部 KG 知識的方法是否存在冗余。最終,基于發(fā)現(xiàn),我們提出使用純 MLP 輕量化建模輔助 PLM 推理的 KG 知識,初步探索了 PLM+KG 的使用方法。
進(jìn)一步,本文研究了在更依賴 KG 的知識庫問答任務(wù)中如何利用 PLM。已有研究通常割裂地建模檢索-推理兩階段,先從大規(guī)模知識圖譜上檢索問題相關(guān)的小子圖,然后在子圖上推理答案節(jié)點(diǎn),這種方法忽略了兩階段間的聯(lián)系。我們重新審視了兩階段的核心能力,并從數(shù)據(jù)形式,模型架構(gòu),訓(xùn)練策略三個層面進(jìn)行了統(tǒng)一,提出UniKGQA。同時受 SAFE 啟發(fā),我們認(rèn)為 KG 僅為執(zhí)行推理的載體,因此 UniKGQA 架構(gòu)的設(shè)計思考為:核心利用 PLM 匹配問題與關(guān)系的語義,搭配極簡 GNN 在 KG 上傳播匹配信息,最終推理答案節(jié)點(diǎn)。針對這樣的簡潔架構(gòu),我們同時設(shè)計了一套高效的訓(xùn)練方法,使得 UniKGQA 可以將檢索的知識遷移到推理階段,整體性能更高效地收斂到更好的表現(xiàn)。實(shí)驗證明,在多個標(biāo)準(zhǔn)數(shù)據(jù)集上相較于已有 SOTA,取得顯著提升。
一、研究背景與動機(jī)
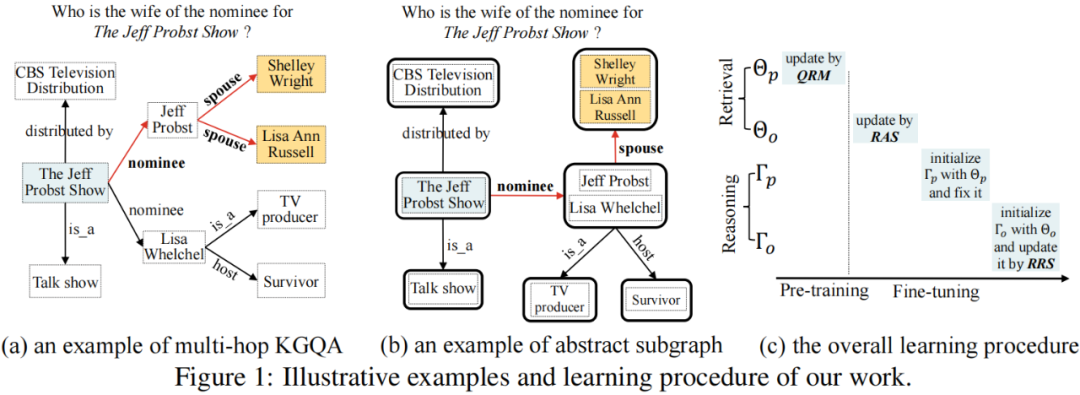
1、多跳知識庫問答
給定一個自然語言問題 和一個知識圖譜 ,知識圖譜問答 (KGQA) 旨在從知識圖譜上尋找答案集合,表示為 。我們在圖1 (a)中展示了一個例子。給定問題:Who is the wife of the nominee for The Jeff Probst Show?,該任務(wù)的目標(biāo)是從主題實(shí)體 The Jeff Probst Show 開始,尋找匹配問題語義的推理路徑 nominee --> spouse,最終得到答案實(shí)體 Shelley Wright 和 Lisa Ann Russell。已有研究通常假設(shè)問題中提到的實(shí)體 (例如圖1 (a)中的The Jeff Probst Show) 被標(biāo)記并鏈接到知識圖譜上,即主題實(shí)體,表示為 。
本文關(guān)注多跳 KGQA 任務(wù),即答案實(shí)體和主題實(shí)體在知識圖譜上距離多跳。考慮到效率和精度之間的平衡,我們遵循已有工作,通過檢索-推理兩階段框架解決此任務(wù)。具體而言,給定一個問題 和主題實(shí)體 ,檢索階段旨在從超大知識圖譜 中檢索出一個小的子圖 ,而推理階段則在檢索子圖 上推理答案實(shí)體 。
2、研究動機(jī)
雖然兩個階段的目的不同,但是兩個階段都需要評估候選實(shí)體與問題的語義關(guān)聯(lián)性 (用于檢索階段remove或推理階段rerank)。本質(zhì)上,上述過程可以被視為一個語義匹配問題。由于 KG 中實(shí)體與實(shí)體間的聯(lián)系通過關(guān)系表示,為了衡量實(shí)體的相關(guān)性,在構(gòu)建語義匹配模型時,基于關(guān)系的特征(直接的一跳關(guān)系或復(fù)合的多跳關(guān)系路徑),都被證明是特別有用的。如圖1 (a)所示,給定問題,關(guān)鍵是要在知識圖譜中識別出與問題語義匹配的關(guān)系及其組成的關(guān)系路徑 (例如nominee --> spouse),以找到答案實(shí)體。
由于兩個階段處理知識圖譜時,面臨的搜索空間尺度不同 (例如,檢索時數(shù)百萬個實(shí)體結(jié)點(diǎn)與推理時數(shù)千個實(shí)體結(jié)點(diǎn)),已有方法通常割裂地為兩階段考慮對應(yīng)的解決方案:前者關(guān)注如何使用更高效的方法提升召回性能,而后者關(guān)注如和利用更細(xì)粒度的匹配信號增強(qiáng)推理。這種思路僅將檢索到的三元組從檢索階段傳遞到推理階段,而忽略了整個流程中其他有用的語義匹配信號,整體性能為次優(yōu)解。由于多跳知識圖譜問答是一項非常具有挑戰(zhàn)性的任務(wù),我們需要充分利用兩個階段習(xí)得的各種能力。
因此,本文探討能否設(shè)計一個統(tǒng)一的模型架構(gòu)來為兩個階段提供更好的性能?如果這樣,我們可以緊密關(guān)聯(lián)兩階段并增強(qiáng)習(xí)得能力的共享,從而提升整體性能。
二、UniKGQA:適用于檢索和推理的統(tǒng)一架構(gòu)
然而,實(shí)現(xiàn)統(tǒng)一的多跳 KGQA 模型架構(gòu)面臨兩個主要挑戰(zhàn): (1) 如何應(yīng)對兩個階段的搜索空間尺度差異很大的問題? (2) 如何在兩個階段之間有效地共享或傳遞習(xí)得的能力? 考慮到這些挑戰(zhàn),我們從數(shù)據(jù)形式,模型架構(gòu),訓(xùn)練策略三方面進(jìn)行探索,最終對兩階段的模型架構(gòu)進(jìn)行了統(tǒng)一。
1、數(shù)據(jù)形式
在 KG 中,存在大量的一對多現(xiàn)象,例如,頭實(shí)體為中國,關(guān)系為城市,那么存在多個尾實(shí)體,每個尾實(shí)體又會存在各自的一對多現(xiàn)象,使得圖的規(guī)模隨跳數(shù)成指數(shù)級增長。實(shí)際上,在檢索階段,我們僅需要通過關(guān)系或關(guān)系路徑召回一批相關(guān)的實(shí)體,而不需要細(xì)粒度關(guān)注實(shí)體本身的信息。結(jié)合以上思考,我們針對檢索階段提出了Abstract Subgraph(抽象子圖) 的概念,核心是將同一個頭實(shí)體和關(guān)系派生出的尾實(shí)體聚合在一起,得到對應(yīng)的抽象結(jié)點(diǎn),如圖1 (b)即為圖1 (a)的抽象子圖表示,這樣可以顯著降低原始知識圖譜的規(guī)模。因此,檢索階段通過關(guān)系或關(guān)系路徑判斷抽象節(jié)點(diǎn)的相關(guān)性,檢索完成后,將含有抽象節(jié)點(diǎn)的子圖進(jìn)行還原,得到包含原始節(jié)點(diǎn)的子圖;推理階段通過關(guān)系或關(guān)系路徑同時考慮具體的節(jié)點(diǎn)信息推理最終的答案節(jié)點(diǎn)。這樣,我們就可以減緩兩個階段面臨的搜索空間尺度過大的問題。
基于抽象子圖,我們針對兩階段提出一個評估實(shí)體相關(guān)性的通用形式,即給定問題 和候選實(shí)體的子圖 。對于檢索階段, 是抽象子圖,包含抽象節(jié)點(diǎn)以合并同一關(guān)系派生的尾實(shí)體。對于推理階段, 是基于檢索階段的檢索子圖構(gòu)建的,還原后沒有抽象節(jié)點(diǎn)。這種通用的輸入格式為開發(fā)統(tǒng)一的模型架構(gòu)提供了基礎(chǔ)。接下來,我們將以一般方式描述針對這種統(tǒng)一數(shù)據(jù)形式設(shè)計的模型架構(gòu),而不考慮特定的檢索或推理階段。
2、模型架構(gòu)
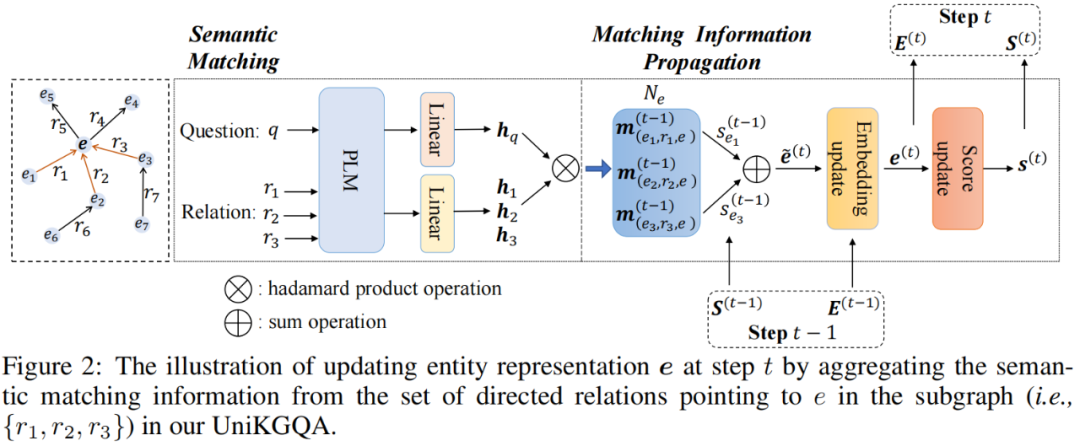
基于上述統(tǒng)一數(shù)據(jù)形式,我們開發(fā)的模型架構(gòu)包含兩個基礎(chǔ)模塊:(1) 語義匹配 (SM) 模塊,利用 PLM 執(zhí)行問題和關(guān)系之間的語義匹配;(2) 匹配信息傳播 (MIP) 模塊,在知識圖譜上傳播語義匹配信息。我們在圖2中展示了模型架構(gòu)的概覽。
語義匹配 (SM):SM 模塊旨在生成問題 與給定子圖 中的三元組間的語義匹配特征。具體而言,我們首先利用 PLM 對和的文本進(jìn)行編碼,然后使用 [CLS] 令牌的輸出表示作為它們的表示:
基于 和 ,受 NSM 模型的啟發(fā),我們通過對應(yīng)的投影層,在第 步獲得問題 和三元組間語義匹配特征的向量間語義匹配特征的向量:
其中,, 是第 步投影層的參數(shù), 和 分別是 PLM 和特征向量的隱藏層維度, 是 sigmoid 激活函數(shù),而 是 hadamard 積。
匹配信息傳播 (MIP):基于語義匹配特征,MIP 模塊首先將它們聚合起來以更新實(shí)體表示,然后利用它來獲取實(shí)體匹配得分。為了初始化匹配得分,對于給定問題 和子圖 中的每個實(shí)體 ,我們將 和 之間的匹配分?jǐn)?shù)設(shè)置為:如果 是主題實(shí)體,則 ,否則 。在第 步,我們利用上一步計算出的頭實(shí)體的匹配分?jǐn)?shù)作為權(quán)重,聚合相鄰三元組的匹配特征,以獲得尾實(shí)體的表示:
其中, 是第 步中實(shí)體 的表示, 是可學(xué)習(xí)的矩陣。在第一步中,由于沒有匹配分?jǐn)?shù),我們按照NSM模型的方法,直接將其一跳關(guān)系的表示聚合為實(shí)體表示:,其中 是可學(xué)習(xí)的矩陣。基于所有實(shí)體 的表示,我們使用 softmax 函數(shù)更新它們的實(shí)體匹配分?jǐn)?shù):
其中, 是一個可學(xué)習(xí)的向量。
經(jīng)過 步迭代,我們可以獲得最終的實(shí)體匹配得分 ,它是子圖 中所有實(shí)體的概率分布。這些匹配分?jǐn)?shù)可以用來衡量實(shí)體作為給定問題 答案的可能性,并將在檢索和推理階段中使用。
訓(xùn)練策略
我們在多跳知識圖譜問答的推理和檢索階段都使用了前述的模型架構(gòu),分別為推理模型和檢索模型。由于這兩個模型采用相同的架構(gòu),我們引入 和 來分別表示用于檢索和推理的模型參數(shù)。如前所述,我們的架構(gòu)包含兩組參數(shù),即基礎(chǔ) PLM 以及用于匹配和傳播的其他參數(shù)。因此, 和 可以分解為 和 ,其中下標(biāo) 和 分別表示我們架構(gòu)中的 PLM 參數(shù)和其他參數(shù)。為了學(xué)習(xí)這些參數(shù),我們基于統(tǒng)一架構(gòu)設(shè)計了預(yù)訓(xùn)練 (即問題-關(guān)系匹配)和微調(diào) (即面向檢索和推理的學(xué)習(xí))策略。下面,我們描述模型訓(xùn)練方法。
問題-關(guān)系匹配的預(yù)訓(xùn)練 (QRM): 對于預(yù)訓(xùn)練,我們主要關(guān)注學(xué)習(xí)基礎(chǔ) PLMs (即 和 ) 的參數(shù)。在實(shí)現(xiàn)中,我們讓兩個模型共享相同的 PLM 參數(shù),即 。語義匹配模塊的基本功能是對一個問題和一個單獨(dú)的關(guān)系進(jìn)行相關(guān)性建模 (式2)。因此,我們設(shè)計了一個基于問題-關(guān)系匹配的對比預(yù)訓(xùn)練任務(wù)。具體來說,我們采用對比學(xué)習(xí)目標(biāo)來對齊相關(guān)問題-關(guān)系對的表示,同時將其他不相關(guān)的對分開。為了收集相關(guān)問題-關(guān)系對,對于一個由問題 、主題實(shí)體 和答案實(shí)體 組成的例子,我們從整個知識圖譜中提取 和 之間的所有最短路徑,并將這些路徑中的所有關(guān)系視為與 相關(guān)的關(guān)系,表示為 。這樣,我們就可以獲得許多弱監(jiān)督樣例。在預(yù)訓(xùn)練期間,對于每個問題 ,我們隨機(jī)采樣一個相關(guān)的關(guān)系 ,并利用對比學(xué)習(xí)損失進(jìn)行預(yù)訓(xùn)練:
其中,是一個溫度超參數(shù),是一個隨機(jī)采樣的負(fù)關(guān)系,是余弦相似度,、是由SM模塊(式1)中的 PLM 編碼的問題和關(guān)系。這樣,通過預(yù)訓(xùn)練 PLM 參數(shù),問題-關(guān)系匹配能力將得到增強(qiáng)。請注意,在預(yù)訓(xùn)練之后,PLM 參數(shù)將被固定。
在抽象子圖上微調(diào)檢索 (RAS):在預(yù)訓(xùn)練之后,我們在檢索任務(wù)上學(xué)習(xí)參數(shù) 。回憶一下,我們將子圖轉(zhuǎn)化為一種抽象子圖的形式,其中包含抽象節(jié)點(diǎn),用于合并來自同一關(guān)系派生的尾實(shí)體。由于我們的 MIP 模塊可以生成子圖中節(jié)點(diǎn)的匹配分?jǐn)?shù) (式4),其中下標(biāo) 表示節(jié)點(diǎn)來自抽象子圖。此外,我們利用標(biāo)注的答案來獲取標(biāo)簽向量,表示為 。如果抽象節(jié)點(diǎn)中包含答案實(shí)體,則在 中將抽象節(jié)點(diǎn)設(shè)置為1。接下來,我們最小化學(xué)習(xí)匹配得分向量和標(biāo)簽向量之間的KL散度,如下式所示:
通過RAS損失微調(diào)后,可以有效地學(xué)習(xí)檢索模型。我們通過它們的匹配得分選擇排名前 個節(jié)點(diǎn),利用它們來檢索給定問題 的子圖。請注意,僅選擇與主題實(shí)體距離合理的節(jié)點(diǎn)進(jìn)入子圖,這可以確保推理階段使用的子圖 相對較小但與問題相關(guān)。
在檢索子圖上微調(diào)推理 (RRS):在微調(diào)檢索模型后,我們繼續(xù)微調(diào)推理模型,學(xué)習(xí)參數(shù) 。通過微調(diào)后的檢索模型,我們可以獲得每個問題 的較小子圖 。在推理階段,我們專注于執(zhí)行準(zhǔn)確的推理,以找到答案實(shí)體。因此,我們還原抽象節(jié)點(diǎn)中的原始節(jié)點(diǎn)及其原始關(guān)系。由于檢索和推理階段高度依賴,我們首先使用檢索模型的參數(shù)來初始化推理模型的參數(shù): 。然后,根據(jù)式4,我們采用類似的方法使用KL損失函數(shù)來使學(xué)習(xí)到的匹配得分 (表示為 ) 擬合標(biāo)簽向量 (表示為 ):
其中,下標(biāo) 表示節(jié)點(diǎn)來自檢索子圖。通過RRS損失的微調(diào)后,我們可以利用學(xué)習(xí)的推理模型選擇排名前個實(shí)體。
如圖1 (c)所示,整體的訓(xùn)練過程由以下三個步驟組成:(1) 與 共享參數(shù),(2) 使用問題-關(guān)系匹配預(yù)訓(xùn)練 ,(2) 使用抽象子圖微調(diào) 以進(jìn)行檢索,(3) 使用子圖微調(diào) 以進(jìn)行推理,其中 使用 進(jìn)行初始化。
討論
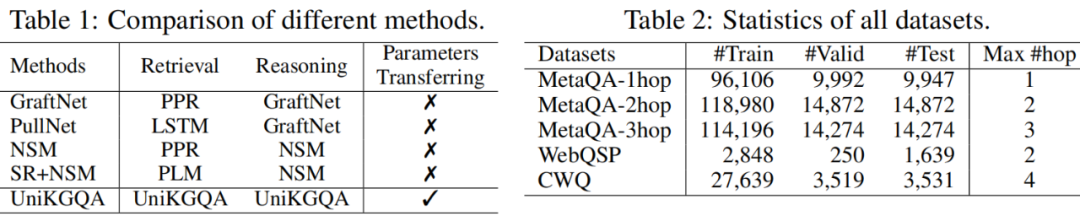
據(jù)我們所知,我們是KGQA領(lǐng)域首次提出使用統(tǒng)一模型在檢索和推理階段共享推理能力。在表格1中,我們總結(jié)了我們的方法和幾種流行的多跳知識庫問答方法(包括 GraphfNet、PullNet、NSM 和 SR+NSM 之間的區(qū)別。我們可以看到,現(xiàn)有方法通常針對檢索和推理階段采用不同的模型,而我們的方法更為統(tǒng)一。統(tǒng)一帶來的一個主要優(yōu)點(diǎn)是,兩個階段之間的信息可以有效地共享和復(fù)用,即,我們使用學(xué)習(xí)的檢索模型來初始化推理模型。
三、實(shí)驗結(jié)果
1、主實(shí)驗
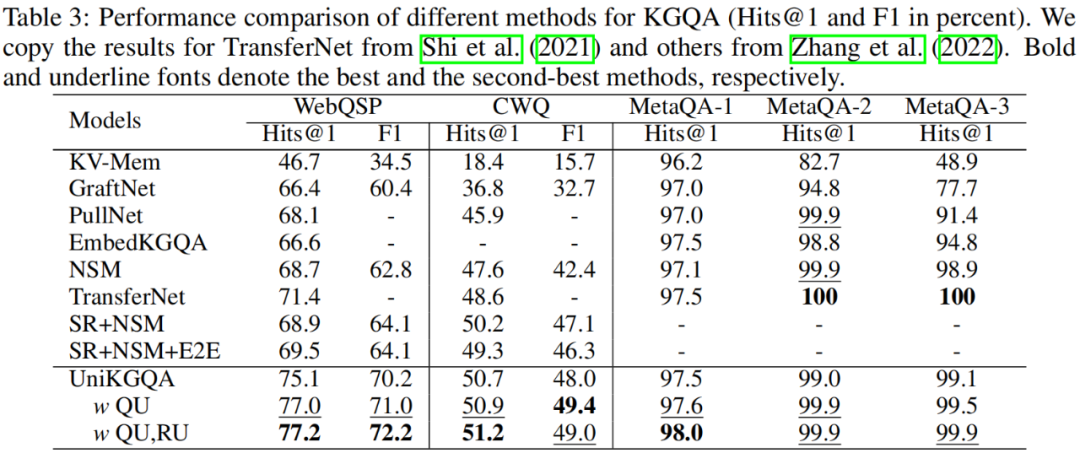
我們在3個公開的文檔檢索數(shù)據(jù)集上進(jìn)行實(shí)驗,分別是 WebQuestionsSP (WebQSP)、Complex WebQuestions 1.1 (CWQ)、和 MetaQA 數(shù)據(jù)集。實(shí)驗結(jié)果如下表所示,通過對比可以清晰地看出我們的方法的優(yōu)勢。例如,在難度較大的數(shù)據(jù)集 WebQSP 和 CWQ 上,我們的方法遠(yuǎn)遠(yuǎn)優(yōu)于現(xiàn)有的最先進(jìn)基線(例如,WebQSP 的 Hits@1 提高了8.1%,CWQ 的 Hits@1 提高了2.0%)。
在我們的方法中,為了提高效率,我們固定了基于 PLM 的編碼器的參數(shù)。實(shí)際上,更新其參數(shù)可以進(jìn)一步提高模型性能。這樣的方法使研究人員在實(shí)際應(yīng)用中可以權(quán)衡效率和精度。因此,我們提出了兩種 UniKGQA 的變體來研究它:(1) 僅在編碼問題時更新 PLM 編碼器的參數(shù),(2) 同時在編碼問題和關(guān)系時更新 PLM 編碼器的參數(shù)。事實(shí)上,這兩種變體都可以提高我們的 UniKGQA 的性能。只在編碼問題時更新 PLM 編碼器可以獲得與同時更新兩者相當(dāng)甚至更好的性能。可能的原因是在編碼問題和關(guān)系時更新 PLM 編碼器可能會導(dǎo)致過度擬合下游任務(wù)。因此,僅在編碼問題時更新PLM 編碼器是更有價值的,因為它可以在相對較少的額外計算成本下實(shí)現(xiàn)更好的性能。
2、深入分析
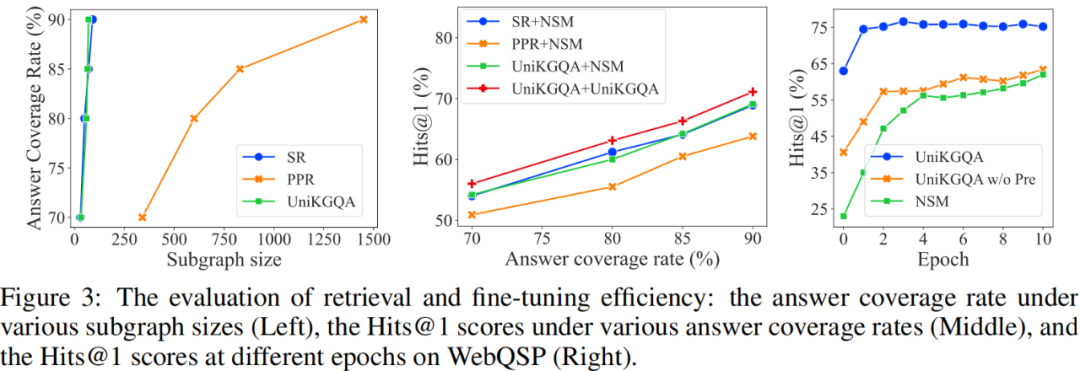
檢索性能:我們從三個方面評估檢索性能:子圖大小、答案覆蓋率和最終 QA 性能。可以看到,在檢索出相同大小的子圖的情況下,UniKGQA 和 SR 的答案覆蓋率顯著高于 PPR 的。這證明了訓(xùn)練可學(xué)習(xí)的檢索模型的有效性和必要性。此外,盡管 UniKGQA 和 SR 的曲線非常相似,但我們的 UniKGQA 比 SR+NSM 可以實(shí)現(xiàn)更好的最終 QA 性能。原因是 UniKGQA 可以基于統(tǒng)一體系結(jié)構(gòu)將相關(guān)信息從檢索階段傳遞到推理階段,學(xué)習(xí)更有效的推理模型。這一發(fā)現(xiàn)可以通過將我們的 UniKGQA 與 UniKGQA+NSM 進(jìn)行比較來進(jìn)一步驗證。
微調(diào)效率:我們比較了 UniKGQA 和較強(qiáng)基線模型 NSM 在相同檢索的子圖上進(jìn)行微調(diào)時,性能隨迭代輪數(shù)的變化。如圖3右側(cè)展示。首先,我們可以看到,在微調(diào)之前(即迭代輪數(shù)為零時),我們的 UniKGQA 已經(jīng)達(dá)到了與 NSM 最佳結(jié)果相當(dāng)?shù)男阅堋_@表明推理模型已經(jīng)成功利用了檢索模型習(xí)得的知識,可以進(jìn)行一定的推理。迭代兩輪之后,我們的 UniKGQA 已經(jīng)達(dá)到接近收斂的性能。表明我們的模型可以實(shí)現(xiàn)高效的微調(diào)。
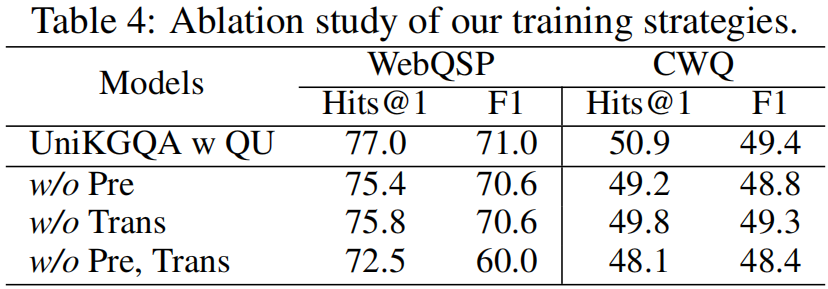
消融實(shí)驗:我們提出兩個重要的訓(xùn)練策略以提高性能:(1) 使用問題-關(guān)系匹配進(jìn)行預(yù)訓(xùn)練,(2) 使用檢索模型的參數(shù)初始化推理模型。我們通過消融實(shí)驗驗證它們的有效性。我們提出了三種變體:(1) 去除預(yù)訓(xùn)練過程, (2) 去除使用檢索模型參數(shù)初始化,(3) 同時去除預(yù)訓(xùn)練和初始化過程。我們在表格4中展示了消融研究的結(jié)果。可以看到,所有這些變體的性能都低于完整的 UniKGQA,這表明這兩個訓(xùn)練策略對最終性能都很重要。此外,這種觀察還驗證了我們的 UniKGQA 確實(shí)能夠轉(zhuǎn)移和重用習(xí)得的知識以提高最終性能。
四、總結(jié)
在這項工作中,我們提出了一種多跳知識圖譜問答任務(wù)新的模型架構(gòu)。作為主要技術(shù)貢獻(xiàn),UniKGQA 引入了基于 PLMs 的統(tǒng)一模型架構(gòu),可同時適用于檢索階段與推理階段。為了應(yīng)對兩個階段的不同搜索空間規(guī)模,我們提出了檢索階段專用的抽象子圖的概念,它可以顯著減少需要搜索的節(jié)點(diǎn)數(shù)量。此外,我們針對統(tǒng)一模型架構(gòu),設(shè)計了一套高效的訓(xùn)練策略,包含預(yù)訓(xùn)練(即問題-關(guān)系匹配)和微調(diào)(即面向檢索和推理的學(xué)習(xí))。得益于統(tǒng)一的模型架構(gòu),UniKGQA 可以有效增強(qiáng)兩個階段之間習(xí)得能力的共享和轉(zhuǎn)移。我們在三個基準(zhǔn)數(shù)據(jù)集上進(jìn)行了廣泛的實(shí)驗,實(shí)驗結(jié)果表明,我們提出的統(tǒng)一模型優(yōu)于競爭方法,尤其是在更具挑戰(zhàn)性的數(shù)據(jù)集(WebQSP 和 CWQ)上表現(xiàn)更好。
審核編輯 :李倩
-
PLM
+關(guān)注
關(guān)注
2文章
132瀏覽量
21036 -
語言模型
+關(guān)注
關(guān)注
0文章
550瀏覽量
10425 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1212瀏覽量
24991 -
知識圖譜
+關(guān)注
關(guān)注
2文章
132瀏覽量
7788
原文標(biāo)題:四、總結(jié)
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
一文詳解知識增強(qiáng)的語言預(yù)訓(xùn)練模型
【大語言模型:原理與工程實(shí)踐】探索《大語言模型原理與工程實(shí)踐》
【大語言模型:原理與工程實(shí)踐】核心技術(shù)綜述
【大語言模型:原理與工程實(shí)踐】大語言模型的基礎(chǔ)技術(shù)
【大語言模型:原理與工程實(shí)踐】大語言模型的預(yù)訓(xùn)練
預(yù)訓(xùn)練語言模型設(shè)計的理論化認(rèn)識
如何向大規(guī)模預(yù)訓(xùn)練語言模型中融入知識?

Multilingual多語言預(yù)訓(xùn)練語言模型的套路
一種基于亂序語言模型的預(yù)訓(xùn)練模型-PERT
利用視覺語言模型對檢測器進(jìn)行預(yù)訓(xùn)練
CogBERT:腦認(rèn)知指導(dǎo)的預(yù)訓(xùn)練語言模型
什么是預(yù)訓(xùn)練 AI 模型?
一套開源的大型語言模型(LLM)—— StableLM






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論