 通俗易懂chatGPT原理
通俗易懂chatGPT原理
目前關于chatGPT的資料過于零散,沒有詳盡所有知識點、系統概述的文章,因此,筆者作了這篇總結性文章。
訓練過程總覽
理清演化路徑
預訓練(pretrain)
GPT-3概述
GPT 3模型的理念
GPT-3如何學習
數據集
指令微調 (Instruction Fine-Tuning,IFT)
有監督微調 (Supervised Fine-tuning, SFT)
人類反饋強化學習 (Reinforcement Learning From Human Feedback,RLHF)
其他方法
思維鏈 (Chain-of-thought,CoT)
與chatGPT類似的工作
引用
進NLP群—>加入NLP交流群(備注nips/emnlp/nlpcc進入對應投稿群)
訓練過程總覽
OpenAI 使用了 175B參數的大型語言模型(LM) 和 6B參數的獎勵模型(RM)。除預訓練之外,訓練過程分為三步:
收集NLP各種任務的數據集,加上任務描述和提示組裝成新的數據集,并使用這些數據微調預訓練的大型語言模型。包括指令微調和有監督微調。
從上述數據集中采樣,使用大型語言模型生成多個響應,手動對這些響應進行排名,并訓練獎勵模型 (RM) 以適應人類偏好。
基于第一階段的有監督微調模型和第二階段的獎勵模型,使用強化學習算法進一步訓練大型語言模型。

img
理清演化路徑
GPT-3.5 參數量仍然為175B,總體進化樹如下:
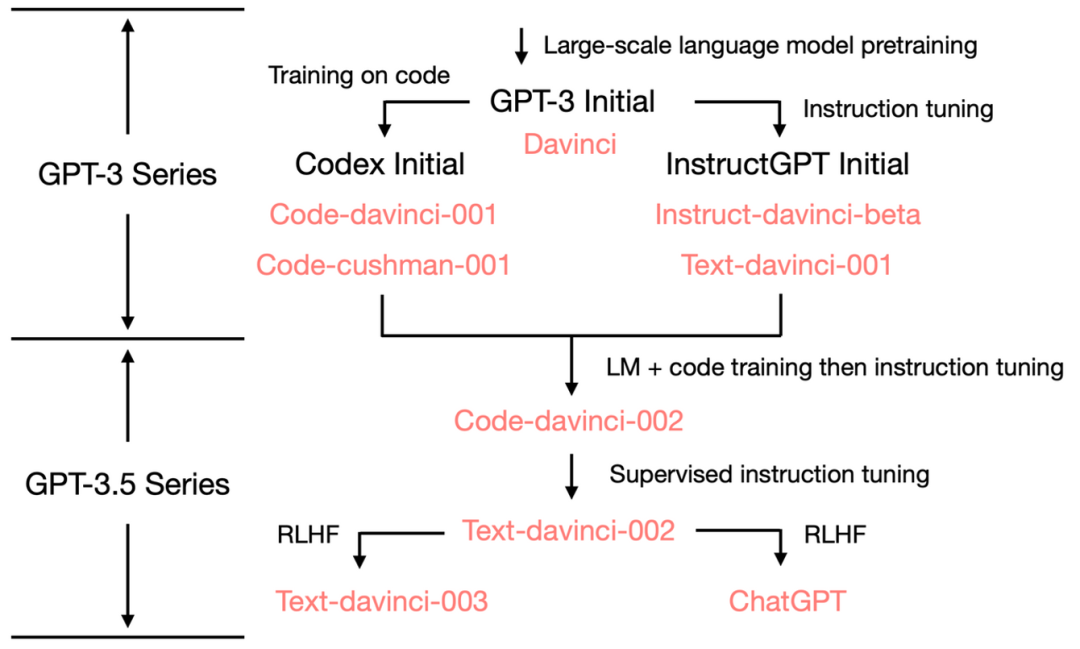
img

img
預訓練(pretrain)
GPT-3概述
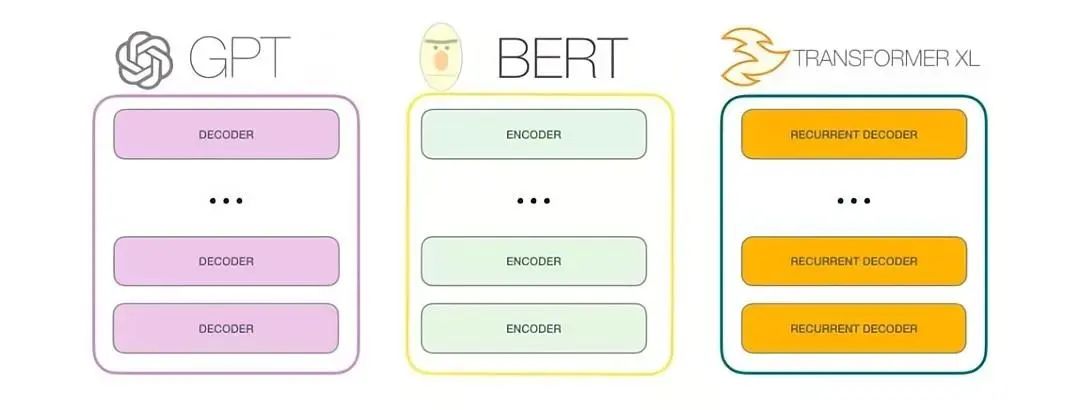
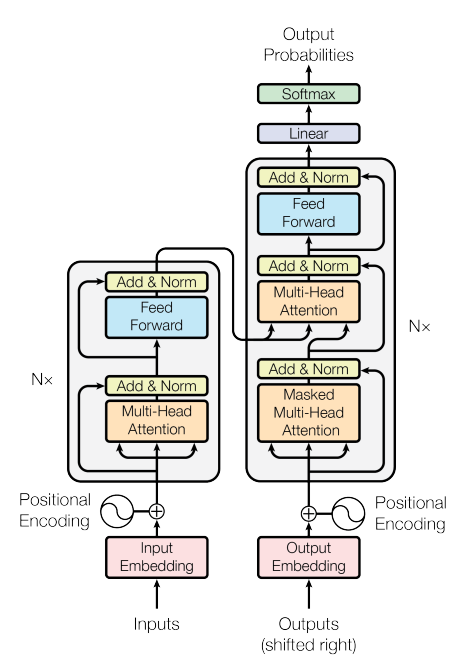
GPT-3是一種自回歸模型,僅使用解碼器,訓練目標也是預測下一個單詞(沒有判斷下一句任務)。
最大的GPT-3模型有175B參數,是BERT模型大470倍(0.375B)
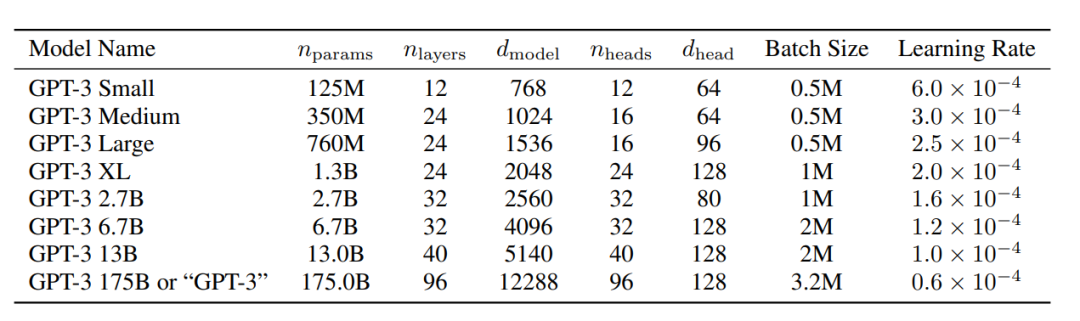
image-20230221144754842
GPT 3模型的理念
不需要接新的模型結構:如bert用于NER任務一般接LSTM+CRF
不需要微調
一個模型解決NLP多種任務
NLP任務都可以用生成模型解決
和人類一樣,只需要看極少數量的樣例就能學會
GPT-3如何學習
零樣本學習:提供任務描述、提示
單樣本學習:提供任務描述、一個樣例、提示
少樣本學習:提供任務描述、幾個樣例、提示

數據集
| 模型 | 發布時間 | 參數量 | 預訓練數據量 |
|---|---|---|---|
| BERT-large | 2019 年 3 月 | 3.75 億 | 約3.3GB |
| GPT | 2018 年 6 月 | 1.17 億 | 約 5GB |
| GPT-2 | 2019 年 2 月 | 15 億 | 40GB |
| GPT-3 | 2020 年 5 月 | 1,750 億 | 45TB |
BERT-large:BooksCorpus 800M words、 English Wikipedia 2.5Bwords
GPT:WebText2, BooksCorpus、Wikipedia超過 5GB。
GPT-2:WebText2, BooksCorpus、Wikipedia總量達到了40GB。
GPT-3:**WebText2, BooksCorpus、Wikipedia、Common Crawl **等數據集45TB數據。
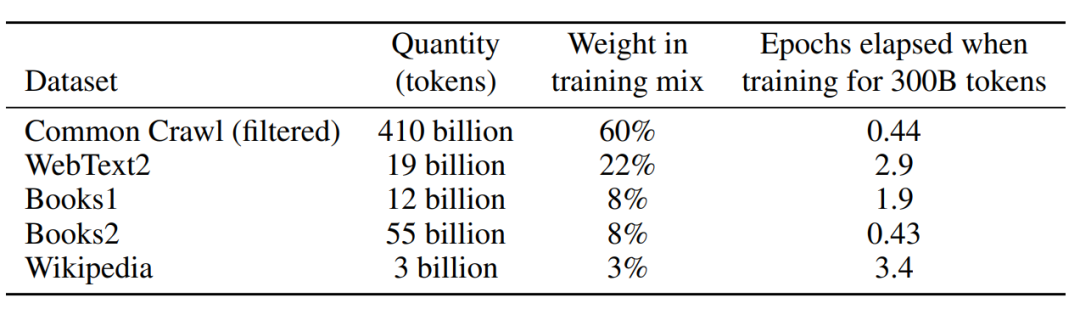
image-20230221153905277
指令微調 (Instruction Fine-Tuning,IFT)
收集NLP各種任務的數據集,加上任務描述和提示組裝成新的數據集。chatGPT使用到的數據集如下:
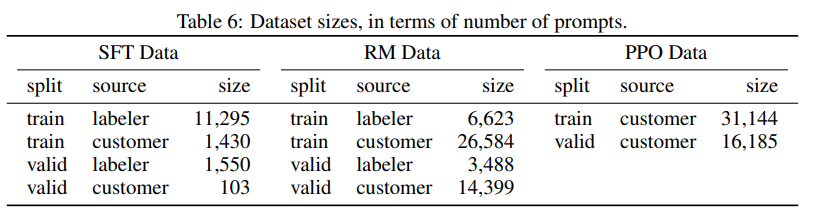
image-20230221113507381
相關的一些論文:
Unnatural Instructions (Honovich 等, '22)//arxiv.org/abs/2212.09689
Super-natural instructions (Wang 等, '22)//arxiv.org/abs/2204.07705
Self-Instruct (Wang 等, '22)//arxiv.org/abs/2212.10560
T0 (Sanh 等, '22)//arxiv.org/abs/2110.08207
Natural instructions 數據集 (Mishra 等, '22)//arxiv.org/abs/2104.08773
FLAN LM (Wei 等, '22)//arxiv.org/abs/2109.01652
OPT-IML (Iyer 等, '22)//arxiv.org/abs/2212.12017
有監督微調 (Supervised Fine-tuning, SFT)
此步驟未為了防止遇到敏感話題時,回復【不知道】這種無意義的回答,以加入一些人工標注數據,增加回復安全性,百級別的數據集即可完成。

相關的一些論文:
Google 的 LaMDA:附錄 Ahttps://arxiv.org/abs/2201.08239
DeepMind 的 Sparrow: Sparrow :附錄 Fhttps://arxiv.org/abs/2209.14375
人類反饋強化學習 (Reinforcement Learning From Human Feedback,RLHF)
描述:
策略 (policy) :一個接受提示并返回一系列文本 (或文本的概率分布) 的 LM。
行動空間 (action space) :LM 的詞表對應的所有詞元 (一般在 50k 數量級) ,
觀察空間 (observation space) 是可能的輸入詞元序列,也比較大 (詞匯量 ^ 輸入標記的數量) 。
獎勵函數是偏好模型和策略轉變約束 (Policy shift constraint) 的結合。
此過程分為兩步:
聚合問答數據并訓練一個獎勵模型 (Reward Model,RM)
用強化學習 (RL) 方式微調 LM
開源數據集:
Anthropic/hh-rlhf · Datasets at Hugging Face
OpenAI 使用的是用戶提交的反饋。
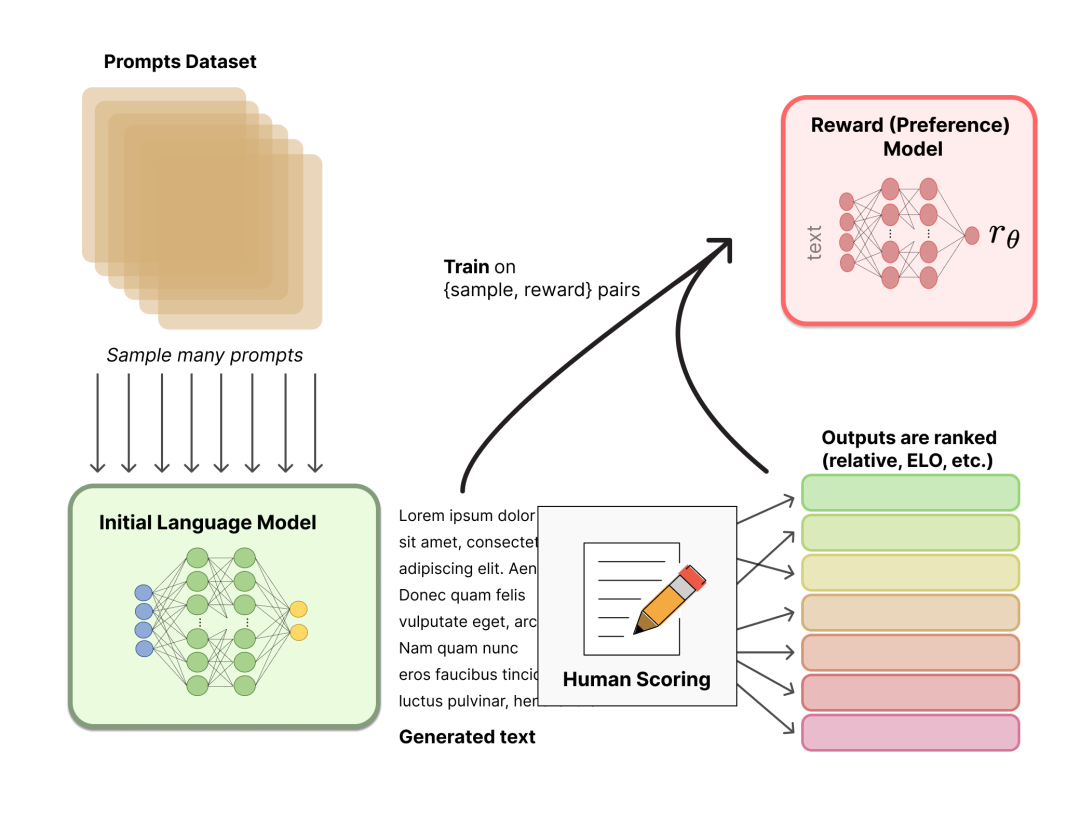
image-20230221111329526
其他方法
這部分簡單介紹一下和chatGPT使用的微調并列的一些方法
思維鏈 (Chain-of-thought,CoT)
如下圖所示使用一些帶有逐步推理的數據集進行微調
橙色是任務描述,粉色是問題和答案,藍色是推理過程
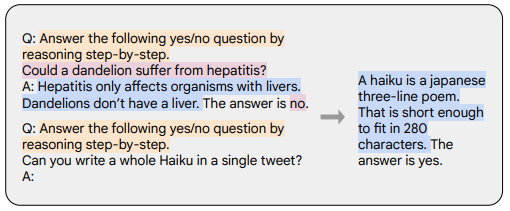
思維鏈提示 (Wei 等, '22)//arxiv.org/abs/2201.11903
與chatGPT類似的工作
Meta 的 BlenderBot//arxiv.org/abs/2208.03188
Google 的 LaMDA//arxiv.org/abs/2201.08239
DeepMind 的 Sparrow//arxiv.org/abs/2209.14375
Anthropic 的 Assistant//arxiv.org/abs/2204.05862
審核編輯 :李倩
-
數據集
+關注
關注
4文章
1208瀏覽量
24689 -
nlp
+關注
關注
1文章
488瀏覽量
22033 -
ChatGPT
+關注
關注
29文章
1558瀏覽量
7596
原文標題:通俗易懂chatGPT原理
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
通俗易懂的PID教程
通俗易懂系列整合—電源基礎知識講解
通俗易懂之電子稱開發導航篇

通俗易懂的講解FFT的讓你快速了解FFT





 工商網監
工商網監
評論