") RDMA網(wǎng)卡相比以太網(wǎng)卡的優(yōu)勢(shì)在哪里呢?
RDMA網(wǎng)卡相比以太網(wǎng)卡的優(yōu)勢(shì)在哪里呢?
RDMA 技術(shù)簡(jiǎn)介
不過(guò),相對(duì)于以太網(wǎng)方案,RDMA 方案對(duì)網(wǎng)卡提出了新的要求,主要有兩點(diǎn)。
? 能夠解析頁(yè)表:由于應(yīng)用程序申請(qǐng)的數(shù)據(jù)緩存一般都是虛擬地址連續(xù)而物理地址不連續(xù)的,因此要求硬件有解析頁(yè)表的能力,能夠訪問物理地址不連續(xù)的緩存。注意,此處所說(shuō)的頁(yè)表是軟件專門為 RDMA 網(wǎng)卡建立的,不是 MMU 訪問的頁(yè)表。
? 能夠封裝和解析數(shù)據(jù)包:網(wǎng)卡需要按照協(xié)議,在發(fā)送數(shù)據(jù)前加上協(xié)議報(bào)頭與校驗(yàn)和,并在接收數(shù)據(jù)后將其剝離。
13.2 RDMA 的優(yōu)勢(shì)
人們經(jīng)常用 100M、1G、10G、25G、100G(單位為 bit/s)等描述網(wǎng)卡支持的最大帶寬(常被稱為速率),無(wú)論是以太網(wǎng)卡和 RDMA 網(wǎng)卡都是如此。但如果同為 100G 帶寬,除了降低了 CPU 的工作負(fù)載,單純從網(wǎng)絡(luò)性能方面考慮,RDMA 網(wǎng)卡相比以太網(wǎng)卡的優(yōu)勢(shì)在哪里呢?
先考慮使用以太網(wǎng)卡的情況。假設(shè)應(yīng)用程序從時(shí)刻 0 開始產(chǎn)生數(shù)據(jù)(Data),之后每 1ns(納秒)持續(xù)產(chǎn)生 1 個(gè) Data(100 位),每個(gè) Data 產(chǎn)生之后的每個(gè)操作步驟都花費(fèi) 1ns,可以得到如圖 13-4 所示的數(shù)據(jù)流水線模型。
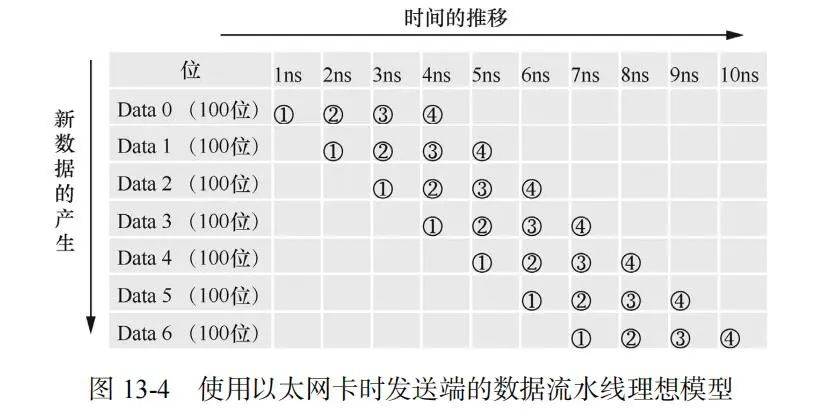
對(duì)應(yīng)圖 13-4 中的編號(hào),每個(gè) Data 的操作步驟如下。
① 應(yīng)用程序申請(qǐng)用戶空間緩存并寫入數(shù)據(jù)。
② 內(nèi)核協(xié)議棧申請(qǐng)內(nèi)核空間緩存,并將數(shù)據(jù)從用戶空間緩存復(fù)制到內(nèi)核空間緩存。
③ 驅(qū)動(dòng)程序操作網(wǎng)卡把數(shù)據(jù)從內(nèi)核空間緩存通過(guò) DMA 復(fù)制到網(wǎng)卡內(nèi)部緩存。
④ 網(wǎng)卡把數(shù)據(jù)發(fā)送到對(duì)端網(wǎng)卡。
理論上只要滿足如下三個(gè)條件就可以實(shí)現(xiàn) 100Gbit/s 的發(fā)送速率。
? ①②③④每一步的操作時(shí)長(zhǎng)都小于 1ns(實(shí)際應(yīng)該是 0.93ns,但不影響理解數(shù)據(jù)流水線模型的概念),即每一步都足夠快。
? 每隔 1ns 就有新的數(shù)據(jù)產(chǎn)生,即有源源不斷的數(shù)據(jù)。
? 從第一個(gè) Data 處理的最后一步(第 4ns)之后開始計(jì)算帶寬,即合適的計(jì)算時(shí)機(jī)。
需要注意的是,這種模式下每個(gè) Data 需要 4ns 發(fā)送到對(duì)端網(wǎng)卡,也就是說(shuō)對(duì)端網(wǎng)卡當(dāng)前接收到的是 4ns 之前產(chǎn)生的數(shù)據(jù)。
基于同樣的假設(shè),可以得到 RDMA 網(wǎng)卡的數(shù)據(jù)流水線模型,如圖 13-5 所示。
對(duì)應(yīng)圖 13-5 中的編號(hào),每個(gè) Data 的操作步驟如下:
② 應(yīng)用程序向用戶空間緩存寫入數(shù)據(jù)。
② 驅(qū)動(dòng)程序操作網(wǎng)卡把數(shù)據(jù)從用戶空間緩存通過(guò) DMA 復(fù)制到網(wǎng)卡內(nèi)部緩存。
③ 網(wǎng)卡把數(shù)據(jù)發(fā)送到對(duì)端網(wǎng)卡。
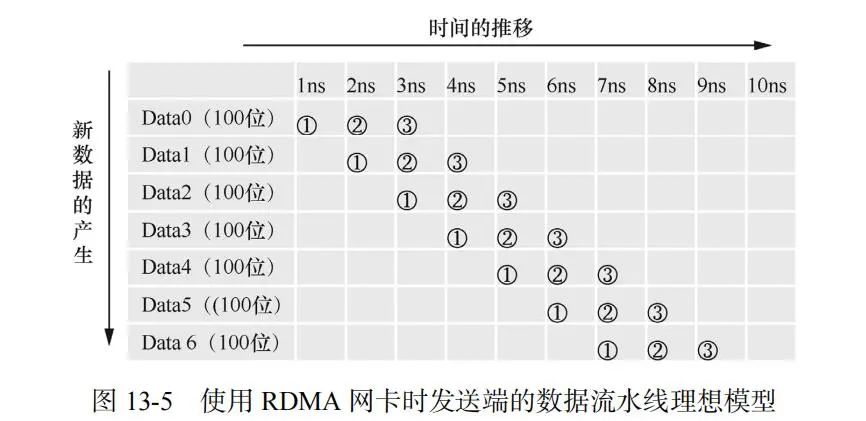
同樣地,只要滿足前文提到的三個(gè)條件,就可以實(shí)現(xiàn) 100Gbit/s 的發(fā)送速率。只是最后一個(gè)條件的計(jì)算時(shí)間可以提前 1ns,從第 3ns 開始算。在此可以看出 RDMA 方案的優(yōu)勢(shì):每個(gè)Data 只需要 3 ns 就可以到達(dá)對(duì)端網(wǎng)卡(即具有更低的時(shí)延)。
通信領(lǐng)域出現(xiàn)率最高的性能指標(biāo)就是帶寬和時(shí)延。簡(jiǎn)單來(lái)說(shuō),所謂帶寬是指單位時(shí)間內(nèi)能夠傳輸?shù)臄?shù)據(jù)量(比如 100Gbit/s),而時(shí)延指的是數(shù)據(jù)從本端發(fā)出到被對(duì)端接收所消耗的時(shí)間。
相比傳統(tǒng)以太網(wǎng),RDMA 技術(shù)實(shí)現(xiàn)了更低的時(shí)延,所以 RDMA 能夠在很多對(duì)時(shí)延要求較高的場(chǎng)景中(比如分布式神經(jīng)網(wǎng)絡(luò)多個(gè)計(jì)算節(jié)點(diǎn)間的數(shù)據(jù)同步)得以發(fā)揮作用。
審核編輯:劉清
-
以太網(wǎng)
+關(guān)注
關(guān)注
40文章
5419瀏覽量
171603 -
dma
+關(guān)注
關(guān)注
3文章
560瀏覽量
100548 -
MMU
+關(guān)注
關(guān)注
0文章
91瀏覽量
18283 -
RDMA
+關(guān)注
關(guān)注
0文章
77瀏覽量
8945
原文標(biāo)題:好書連載 | RDMA 技術(shù)簡(jiǎn)介(2)
文章出處:【微信號(hào):LinuxDev,微信公眾號(hào):Linux閱碼場(chǎng)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
千兆以太網(wǎng)卡芯片時(shí)鐘產(chǎn)生電路設(shè)計(jì)方案
為什么初始化以太網(wǎng)卡ENC28J60會(huì)出現(xiàn)錯(cuò)誤?
高效的以太網(wǎng)卡電路怎么實(shí)現(xiàn)?
請(qǐng)問有synopsys三速以太網(wǎng)卡的驅(qū)動(dòng)文件嗎?
Android系統(tǒng)啟動(dòng)以太網(wǎng)卡及支持雙網(wǎng)卡共存的操作流程
基于CPCI總線10/100 Mb/s以太網(wǎng)卡的設(shè)計(jì)與實(shí)現(xiàn)

圖解以太網(wǎng)卡功能與用料
Intel發(fā)布業(yè)界首款雙網(wǎng)口10Gb以太網(wǎng)卡
SFN5122F低功耗低延遲10G以太網(wǎng)卡
基于DSP的以太網(wǎng)卡的接口技術(shù)分析
網(wǎng)卡的分類
如何選擇最適合自己的RDMA網(wǎng)卡
什么是以太網(wǎng)卡 以太網(wǎng)卡的未來(lái)
以太網(wǎng)卡、IB網(wǎng)卡的詳細(xì)介紹以及區(qū)別分析





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論