 In-context learning如何工作?斯坦福學者用貝葉斯方法解開其奧秘
In-context learning如何工作?斯坦福學者用貝葉斯方法解開其奧秘
引言
去年底,OpenAI研發的ChatGPT一經面世,在引起了大家驚訝的同時,也紛紛引發大家的思考,到底ChatGPT是如何研發的?用到了什么技術?如何才能充分挖掘ChatGPT潛能?ChatGPT背后的核心技術,大語言模型毫無疑問是最重要的之一。同樣由OpenAI研發的大模型GPT-3,其參數量達到的1750億。如此大規模的模型,不僅研發成本讓許多機構望而卻步,其背后的運行原理也是讓很多科研人員“一頭霧水”。大量的工作在探究,語言模型是怎樣獲得如何驚人的“語言理解能力”的?其中,In-context learning就是一種在大規模語言模型中展現出來的特殊能力,通過給模型“展示”幾個相關的例子,模型便可以“學會”這個任務要做的事情,并給出測試樣例的答案。可是,模型是怎么獲得這個特殊“技能”的呢?斯坦福大學的Sang Michael Xie等人認為,in-context learning可以看成是一個貝葉斯推理過程,其利用提示的四個組成部分(輸入、輸出、格式和輸入輸出映射)來獲得隱含在語言模型中的潛在概念,而潛在概念是語言模型在訓練過程中學到的關于某類任務的特定“知識”。相關工作發表在2022年的ICLR會議上,作者等人還寫了一篇博客來進行詳細介紹。下面跟著譯者一起來了解in-context learning的奧秘吧!
博客正文
在這篇文章中,我們為GPT-3等大規模語言模型中的in-context learning提供了一個貝葉斯推理框架,并展示了我們框架的實驗證據,突出了與傳統監督學習的區別。這篇博文主要借鑒了來自論文An Explanation of In-context Learning as Implicit Bayesian Inference的in-context learning理論框架,以及來自Rethinking the Role of Demonstrations: What Makes In-Context Learning Work? 的實驗。
In-context learning是大規模語言模型中一種神秘的涌現行為,其中語言模型僅通過調節輸入輸出示例來完成任務,而無需優化任何參數。在這篇文章中,我們提供了一個貝葉斯推理框架,將in-context learning理解為“定位”語言模型從預訓練數據中獲取到的潛在“概念”。這表明提示的所有組成部分(輸入、輸出、格式和輸入-輸出映射)都可以提供用來推斷潛在概念的信息。我們就此框架進行相關實驗,在這些實驗的結果中,當提供具有隨機輸出的訓練示例時,in-context learning仍然有效。雖然隨機的輸出削弱了傳統的監督學習算法,但它只是消除了貝葉斯推理的一種信息來源(輸入-輸出映射)。最后,我們提出了對于未來工作存在的差距和努力方向,并邀請社區與我們一起進一步了解in-context learning。
目錄
一、In-context learning的奧秘
二、一種in-context learning框架
三、實驗證據
四、擴展
五、總結
一、In-context learning的奧秘
大規模語言模型,例如GPT-3[1]在互聯網規模的文本數據上進行訓練,以預測給定前文文本的下一個標記。這個簡單的目標與大規模數據集和模型相結合,產生了一個非常靈活的語言模型,它可以“讀取”任何文本輸入,并以此為條件“書寫”可能出現在輸入之后的文本。雖然訓練過程既簡單又通用,但GPT-3論文發現“大規模”會導致特別有趣的、意想不到的行為,稱為in-context learning。什么是in-context learning?In-context learning最初是在 GPT-3 論文中開始普及的,是一種僅給出幾個示例就可以讓語言模型學習到相關任務的方法。在in-context learning里,我們給語言模型一個“提示(prompt)”,該提示是一個由輸入輸出對組成的列表,這些輸入輸出對用來描述一個任務。在提示的末尾,有一個測試輸入,并讓語言模型僅通過以提示為條件來預測下一個標記。例如,要正確回答下圖所示的兩個提示,模型需要讀取訓練示例以弄清楚輸入分布(財經或普通新聞)、輸出分布(正向情感/負向情感或某個主題)、輸入-輸出映射(情感分類或主題分類)和格式。

In-context learning能做什么?在許多NLP基準測試中,in-context learning與使用更多標記數據訓練的模型相比具有相當的性能,并且在LAMBADA(常識句子完成)和 TriviaQA(問答)上是最出色的。更令人興奮的是,in-context learning使人們能夠在短短幾個小時內啟動一系列應用程序,包括根據自然語言描述編寫代碼、幫助設計應用程序模型以及概括電子表格功能等。
In-context learning允許用戶為新用例快速構建模型,而無需為每個任務微調和存儲新參數。它通常只需要很少的訓練示例就可以使模型正常工作,而且即使對于非專家來說,也可以通過直觀的自然語言來進行交互。
為什么in-context learning這么神奇?In-context learning不同于傳統的機器學習,因為它沒有對任何參數進行優化。然而,這并不是獨一無二的——元學習(meta-learning)方法已經訓練出了從示例中學習的模型。神奇之處在于語言模型沒有進行過從示例中學習的訓練,它在預訓練中做的事是預測下一個標記。正因為如此,語言模型和in-context learning似乎并不一致。
這看起來很神奇,那In-context learning是怎么起作用的呢?
二、一種In-context learning框架
我們如何才能更好地理解in-context learning?首先要注意的是,像GPT-3這樣的大規模語言模型已經在具有廣泛主題和格式的大量文本上進行了訓練,這些文本包括維基百科頁面、學術論文、Reddit帖子以及莎士比亞的作品。我們假設在這些文本上進行訓練使得語言模型可以對多種不同的概念進行建模。
Xie等人[2]提出了一個框架,即語言模型使用in-context learning提示來“定位”訓練中學習到的概念,從而完成in-context learning任務。如下圖所示,在我們的框架中,語言模型使用訓練示例在內部確定任務是情感分析(左)或主題分類(右),并將相同的映射應用于測試輸入。
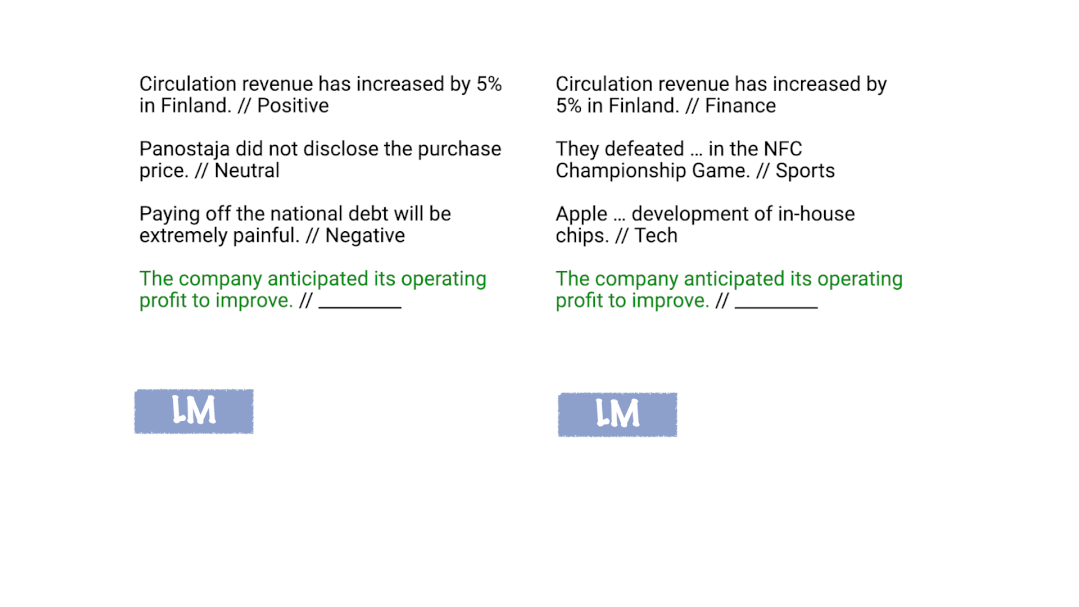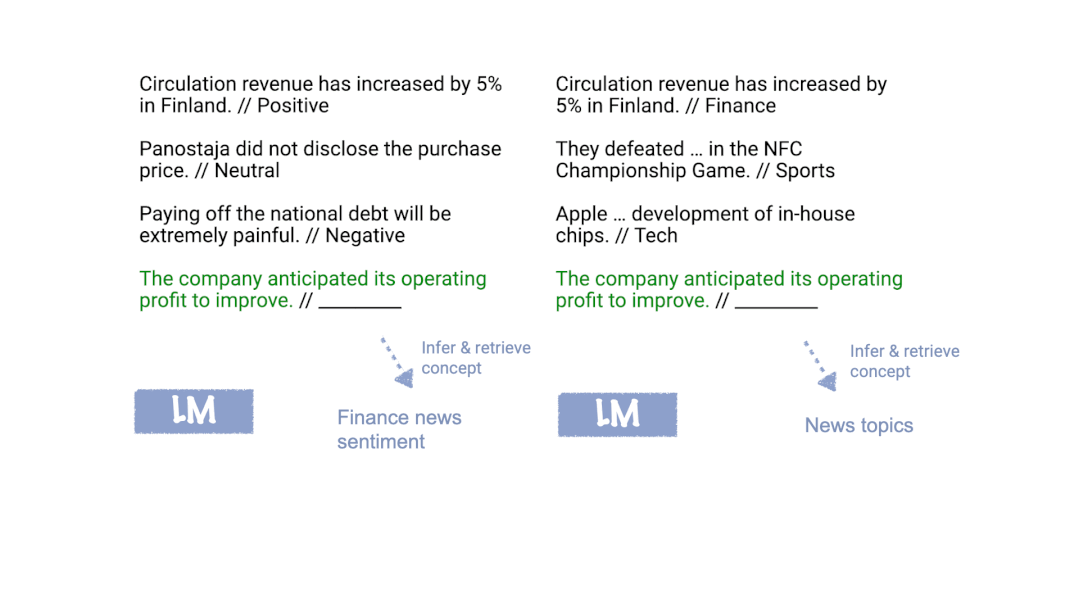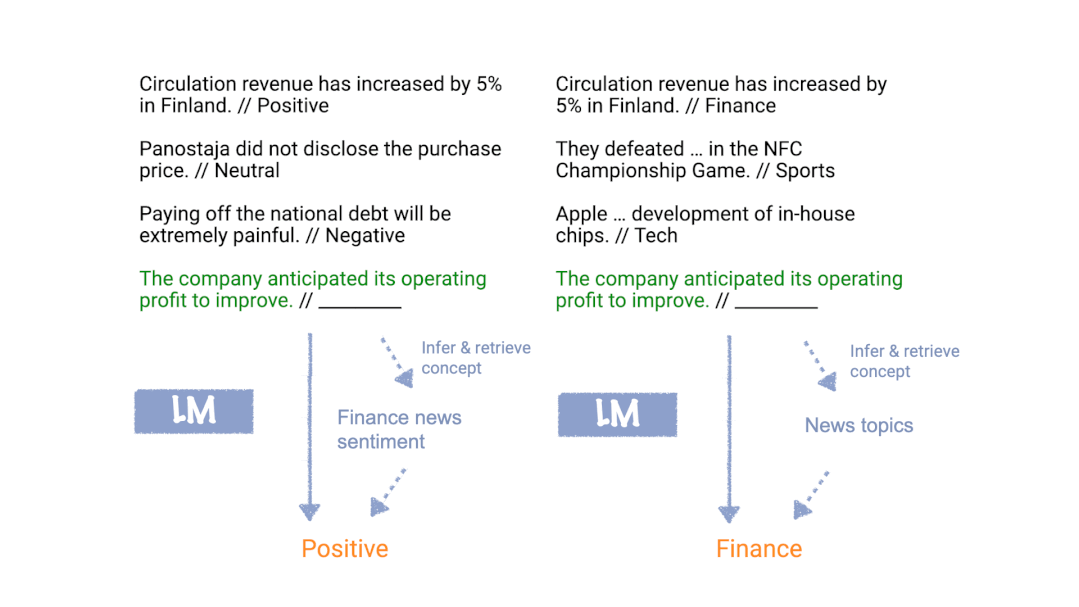
什么是“概念”?我們可以將概念視為包含各種文檔級統計信息的潛在變量。例如,“新聞主題”的概念描述了詞匯的分布(新聞及新聞主題)、格式(新聞文章的寫作方式)、新聞與新聞主題之間的關系以及詞匯之間的其他語義和句法關系。通常,概念可能是許多潛在變量的組合,這些潛在變量指定了文檔語義和語法的不同方面,但在這里我們通過將它們全部看成一個概念變量來簡化。
語言模型如何在預訓練期間學會進行貝葉斯推理?
我們證明,在具有潛在概念結構的偽數據上訓練(預測下一個標記)的語言模型可以學習進行in-context learning。我們假設在真實的預訓練數據中會發生類似的效果,因為文本文檔天然具有長期連貫性:同一文檔中的句子/段落/表格行傾向于共享底層語義信息(例如,主題)和格式(例如,問題和答案之間交替的問答頁面)。在我們的框架中,文檔級潛在概念創造了長期連貫性,并且在預訓練期間對這種連貫性進行建模來推斷潛在概念:
1、預訓練:為了在預訓練期間預測下一個標記,語言模型必須使用來自先前句子的證據推斷(“定位”)文檔的潛在概念。
2、In-context learning:如果語言模型使用提示中的in-context示例推斷提示概念(提示中的示例所共享的潛在概念),則發生in-context learning!
In-context learning的貝葉斯推理觀點
在我們討論貝葉斯推理觀點之前,讓我們設置好in-context learning的設定。
預訓練分布(p):我們對預訓練文檔結構的主要假設是,關于文檔的生成,首先通過對潛在概念進行采樣,然后以潛在概念為條件來生成文檔。我們假設預訓練數據足夠多以及語言模型足夠大,使得語言模型完全符合預訓練分布。正因為如此,我們使用p表示語言模型下的預訓練分布和概率。
提示分布:In-context learning提示是一系列獨立同分布的訓練示例加上一個測試輸入。提示中的每個示例都可以認為是以相同提示概念為條件的序列,它描述了要學習的任務。
去“定位”學習到的概念的過程,可以看作是提示中每個示例共享的提示概念的貝葉斯推理。如果模型能夠推斷出提示概念,那么它就可以用來對測試樣例做出正確的預測。在數學上,提示為模型(p)提供了證據來銳化概念的后驗分布p(concept|prompt)。如果p(concept|prompt)集中在提示概念上,模型則有效地從提示中“學習”到了概念。
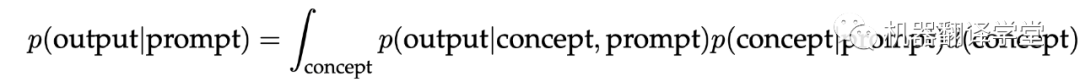
理想情況下,p(concept|prompt)會集中在有更多示例的提示概念,就可以通過邊緣化來“選擇”對應的提示概念。
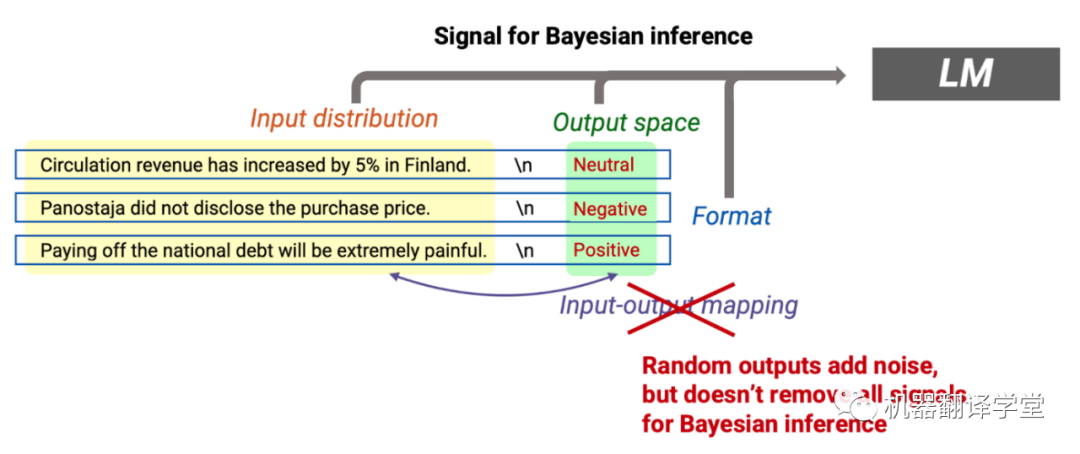
提示為貝葉斯推理提供了帶有噪聲的信號
在解釋中不太符合邏輯的地方是,語言模型從in-context示例中推斷提示概念,不過提示是從提示分布中采樣的,這可能與語言模型訓練的預訓練分布非常不同。提示將獨立的訓練示例連接在一起,因此不同示例之間的轉換在語言模型以及預訓練分布下的概率非常低,并且可能在推理過程中引入噪聲。例如,連接關于不同新聞主題的獨立句子可能會產生不常見的文本,因為沒有一個句子具有足夠的in-context。有趣的是,正如在GPT-3中所發現的那樣,盡管預訓練和提示分布之間存在差異,語言模型仍然可以進行貝葉斯推理。我們證明,通過貝葉斯推理進行的in-context learning可以用一個簡化的理論設置,在預訓練數據的潛在概念結構中出現。我們使用它來生成一個數據集,該數據集使得Transformer和LSTM能夠發生in-context learning。

訓練示例提供信號:我們可以認為訓練示例為貝葉斯推理提供信號。尤其是訓練示例中的轉換(上圖中的綠色箭頭)允許語言模型推斷它們共享的潛在概念。在提示中,來自輸入分布(新聞句子之間的轉換)、輸出分布(主題詞)、格式(新聞句子的句法)和輸入-輸出映射(新聞和主題之間的關系)的轉換都為貝葉斯推理提供信號。
訓練示例之間的轉換可能是低概率的(噪聲):因為訓練示例是獨立同分布的,將它們連接在一起通常會在示例之間產生不流暢的低概率轉換。例如,在關于芬蘭流通收入的句子之后看到關于 NFC 冠軍賽(美式橄欖球比賽)的句子可能會令人驚訝(見上圖)。這些轉換會在推理過程中產生噪音,原因在于預訓練和提示分布之間的差異。
In-context learning對某些噪聲具有魯棒性:我們證明,如果信號大于噪聲,則語言模型可以成功進行in-context learning。我們將信號描述為其他概念與以提示為條件的提示概念之間的KL散度,并將噪聲描述為來自示例之間轉換的誤差項。直覺上,如果提示允許模型真正輕松地將提示概念與其他概念區分開來,那么就會有很強的信號。這也表明,在信號足夠強的情況下,其他形式的噪聲,例如刪除一種信息源(如刪除輸入輸出映射)可能是沒有問題的,特別是當提示的格式沒有改變并且輸入輸出映射信息在預訓練數據中。這不同于傳統的監督學習,如果刪除輸入-輸出映射信息(如通過隨機化標簽),傳統的監督學習將會失效。我們將在下一節中直接研究這種區別。
用于in-context learning的小型測試平臺(GINC數據集):為了支持該理論,我們構建了一個預訓練數據集和具有潛在概念結構的in-context learning測試平臺,取名為GINC。我們發現在GINC上進行預訓練會使Transformer和LSTM出現in-context learning,這表明來自預訓練數據中的結構有非常重要的作用。消融實驗顯示,潛在的概念結構(導致長期連貫性)對于GINC中in-context learning的出現至關重要[2]。
三、實驗證據
接下來,我們希望通過一組實驗為上述框架提供實驗證據。
提示中的輸入輸出對很重要
提示中不需要使用真實輸出也能獲得良好的in-context learning性能。
在Min等人的論文[3]中,我們比較了三種不同的方法:
No-examples:語言模型僅在測試輸入上計算條件概率,沒有示例。這是典型的零樣本推理,在GPT-2/GPT-3中已經實現。
具有真實輸出的示例:語言模型是基于一些in-context示例和測試輸入共同去計算的。這是一種典型的in-context learning方法,默認情況下,提示中的所有輸出都是真實的。
具有隨機輸出的示例:語言模型也是基于一些in-context示例和測試輸入去共同計算的,不過,提示中的每個輸出都是從輸出集中隨機抽樣的(分類任務中的標簽;多項選擇中的一組答案選項)。


帶有真實輸出的提示(上圖)和帶有隨機輸出的提示(下圖)
值得注意的是,“帶有隨機輸出的示例”這種方法以前從未有人嘗試過。如果標記數據的輸出是隨機的,那么典型的監督學習將根本不起作用,因為任務不再有意義。
我們試驗了12個模型,參數大小范圍從 774M 到 175B,包括最大的GPT-3(Davinci)。模型在16個分類數據集和10個多選數據集上進行評估。
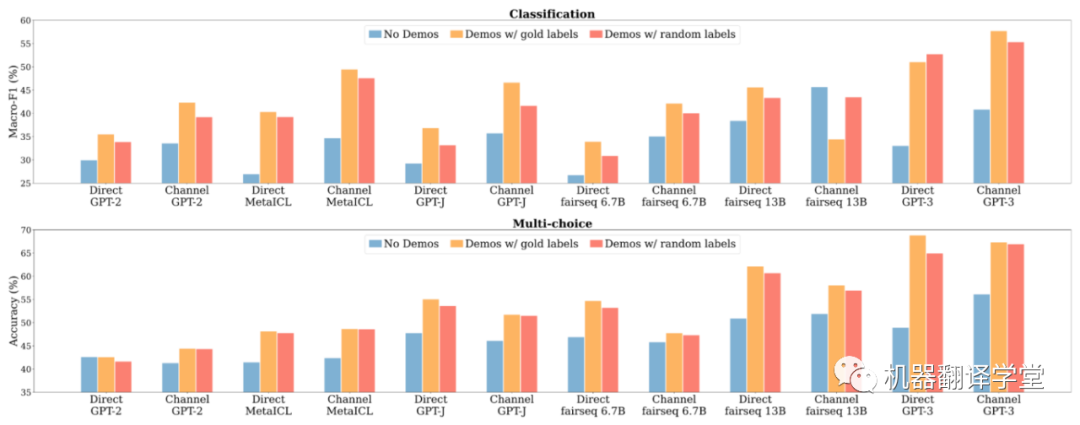
無示例(藍色)、具有真實輸出的示例(黃色)和具有隨機輸出的示例(隨機)之間的比較;用隨機輸出替換真值輸出對性能的影響比之前想象的要小得多,而且仍然比沒有例子要好得多
當用輸出集合的隨機輸出來替換每個輸出時,in-context learning性能不會下降太多。
首先,正如預期的那樣,使用帶有真實輸出的示例明顯優于無示例。然后,用隨機輸出替換真實輸出幾乎不會使性能下降。這意味著,與典型的監督學習不同,真實輸出并不是獲得良好的in-context learning性能所必須需要的,這有違我們的直覺。
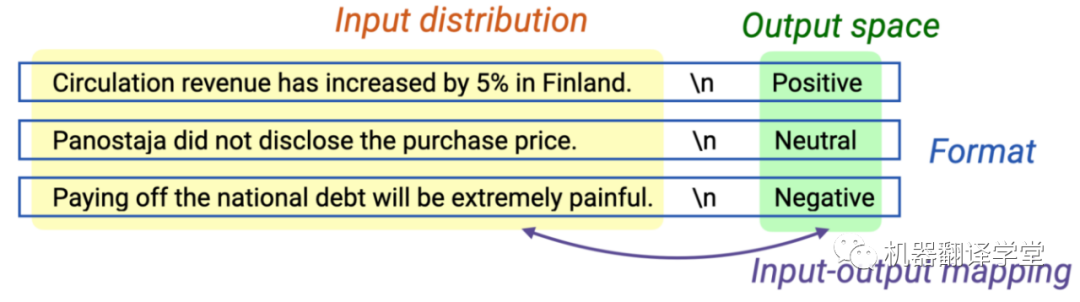
in-context示例的四個不同方面:輸入輸出映射(Input-output mapping)、輸入分布(Input distribution)、輸出空間(Output space)和格式(Format)
如果正確的輸入輸出映射具有邊際效應,提示的哪些方面對于in-context learning最重要呢?
一個可能的方面是輸入分布,即示例中輸入的基礎分布(下圖中的紅色文本)。為了量化其影響,我們設計了一種演示變量,其中每個in-context示例都包含一個從外部語料庫中隨機抽取的輸入句子(不是來自訓練數據的輸入)。然后,我們將其性能與帶有隨機標簽的演示進行比較。直覺上,這兩個版本的演示都是不正確的輸入標簽對應關系,區別在于是否有正確的輸入分布。
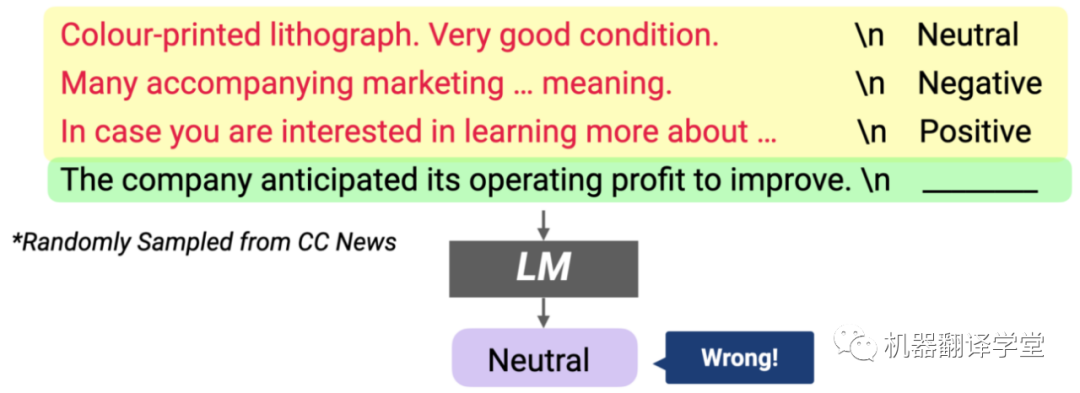
輸入分布很重要:當提示中的輸入被外部語料庫(CC新聞語料庫)的隨機輸入替換時,模型性能會顯著下降
結果表明,總體而言,以隨機句子作為輸入的模型性能顯著降低(絕對值降低高達 16%)。這表明對正確的輸入分布進行調節很重要。

輸出空間很重要:當示例中的輸出被隨機的英文一元組替換時,模型性能會顯著下降 可能影響in-context learning的另一個方面是輸出空間:任務中的輸出集(類別或答案選項)。為了量化其影響,我們設計了一種演示變量,由in-context示例組成,這些示例具有隨機配對的隨機英語一元組,這些一元組與任務的原始標簽(例如,“wave”)無關。結果表明,使用此演示時性能顯著下降(絕對值高達16%)。這表明對正確的輸出空間進行調節很重要。即使對于多項選擇任務也是如此,可能是因為它仍然具有模型使用的特定選擇分布(例如,OpenBookQA數據集中的“Bolts(螺栓)”和“Screws(螺絲)”等對象)。
與貝葉斯推理框架的聯系
語言模型不依賴提示中的輸入-輸出對應這一事實意味著語言模型在預訓練期間可能已經接觸到任務的輸入-輸出對應中的某些概念,而in-context learning在它們的基礎上發生作用。相反,提示的其它所有組成部分(輸入分布、輸出空間和格式)都在提供信號,使模型能夠更好地推斷(“定位”)在預訓練期間學習到的概念。由于在提示中將隨機序列連接在一起,隨機輸入輸出映射仍然會增加“噪音”。盡管如此,基于我們的框架,只要仍然有足夠的信號(例如正確的輸入分布、輸出空間和格式),模型仍然會進行貝葉斯推理。當然,擁有正確的輸入輸出映射仍然可以通過提供更多依據和減少噪音來發揮作用,尤其是當輸入輸出映射并非經常出現在預訓練數據中時。
在預訓練期間,in-context learning 的性能與術語頻率高度相關
Razeghi等人[4]在各種數字任務上評估GPT-J,發現in-context learning性能與每個示例中的術語(數字和單位)在 GPT-J的預訓練數據(The PILE)中出現的次數高度相關。
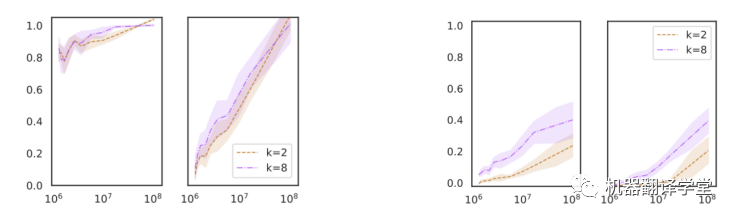
術語頻率(x軸)和in-context learning性能(y軸)之間的相關性;從左到右:加法、乘法、提示中無任務指示的加法和提示中無任務指示的乘法;來自 Razeghi等人的數據
這在不同類型的數字任務(加法、乘法和單位轉換)和不同的k值(提示中標記示例的數量)中結論是一致的。一個有趣的現象是,當輸入沒有明確說明任務時也是如此——例如,不使用“問:3 乘以 4 是多少?答:12”,而是用“問:3#4是多少?答:12”。
與貝葉斯推理框架的聯系
我們將這項工作視為另一個證據,表明in-context learning主要是定位在預訓練期間學習的潛在概念。特別是,如果特定實例中的術語在預訓練數據中多次出現,則模型可能會更好地了解輸入分布。根據貝葉斯推理,這將為定位潛在概念以執行下游任務提供更好的信號。而Razeghi等人特別關注模型對輸入分布了解程度的一個方面——特定實例的詞頻——可能存在更廣泛的變化集,例如輸入-輸出相關性的頻率、格式(或文本模式)等。
四、擴展
了解模型在“沒見過”的任務上的表現
我們的框架表明該模型正在“檢索”它在預訓練期間學到的概念。然而,Rong[5]在博文中表明,該模型在將運動映射到動物、將蔬菜映射到運動等(下圖)沒見過的任務上表現幾乎完美。此外,輸入輸出映射在這種情況下仍然很重要,因為模型從示例中學習了不自然的映射。根據經驗,一種可能性是in-context learning行為可能會在構造的任務中發生變化(而不是我們實驗關注的真實NLP基準測試)——這需要進一步探索。
盡管如此,如果我們將一個概念視為許多潛在變量的組合,貝葉斯推理仍然可以解釋某些形式的外推。例如,考慮一個表示語法的潛在變量和另一個表示語義的變量。貝葉斯推理可以組合推廣到新的語義-句法對,即使模型在預訓練期間沒有看到所有句對。排列、交換和復制等一般操作在預訓練期間很有用,并且可以在組合時幫助外推(例如,運動到動物案例中的標簽排列)。需要做更多的工作來模擬in-context learning如何處理沒見過的任務。
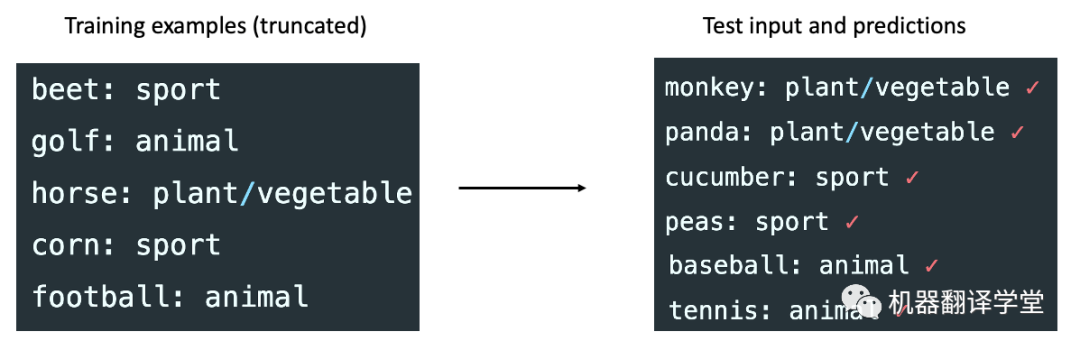
GPT-3可以成功學習的具有不尋常語義的示例合成任務
與學習閱讀任務描述的聯系
可以在提示中使用自然語言的任務描述(或說明)來執行下游任務。例如,我們可以在前面加上“Write a summary about the given article”來描述總結或“Answer a following question about the Wikipedia article”來描述問答。在大規模、高質量指令數據上進一步調整的語言模型被證明可以很好地執行沒見過的任務[6][7]。根據我們的框架,我們可以通過提供明確的潛在提示概念,將“指定任務描述”理解為改進貝葉斯推理。
了解用于in-context learning的預訓練數據
雖然我們提出in-context learning來自預訓練數據中的長期連貫結構(由于潛在的概念結構),但需要做更多的工作來準確查明預訓練數據的哪些元素對in-context learning有最大貢獻。是否有一個關鍵的數據子集可以從中產生in-context learning,或者它是否是多種類型數據之間的復雜交互?最近的工作[8][9]給出了一些關于引發in-context learning行為所需的預訓練數據類型的提示。更好地理解in-context learning有助于構建更有效的大規模預訓練數據集。
從模型架構和訓練中捕捉效果
我們的框架僅描述了預訓練數據對in-context learning的影響,但其他方面也會產生影響。模型規模就是其中之一——許多論文都展示了大規模的好處[10][11][12]。結構(例如,僅解碼器與編碼器-解碼器)和訓練目標(例如,因果語言模型與掩碼語言模型)是有可能的其它因素[13]。未來的工作可能會進一步研究in-context learning中的模型行為如何受模型規模、結構和訓練目標的選擇的影響。
五、總結
在這篇博文中,我們提供了一個框架,其中語言模型通過使用提示去“定位”它在預訓練期間學習到的相關概念來進行in-context learning,進而完成相關任務。從理論上講,我們可以將其視為一個潛在概念以提示為條件的貝葉斯推理,這種能力來自預訓練數據中的結構(長期連貫性)。我們在一些NLP基準測試上進行實驗,表明當提示中的輸出用隨機輸出來進行替換時,in-context learning仍然有效。雖然使用隨機輸出會增加噪聲,并破壞了輸入-輸出映射信息,但其他部分(輸入分布、輸出分布、格式)仍然為貝葉斯推理提供依據。最后,我們詳細說明了我們框架的局限性和可能的擴展,例如解釋外推到看不見的任務,并結合模型架構和優化的影響。我們呼吁未來在理解和改進in-context learning方面開展更多工作。
審核編輯 :李倩
-
貝葉斯
+關注
關注
0文章
77瀏覽量
12564 -
語言模型
+關注
關注
0文章
521瀏覽量
10268 -
自然語言
+關注
關注
1文章
288瀏覽量
13347
原文標題:In-context learning如何工作?斯坦福學者用貝葉斯方法解開其奧秘
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
斯坦福開發過熱自動斷電電池
關于斯坦福的CNTFET的問題
回收新舊 斯坦福SRS DG645 延遲發生器
DG645 斯坦福 SRS DG645 延遲發生器 現金回收
基于貝葉斯網絡的軟件項目風險評估模型

基于概率的常見的分類方法--樸素貝葉斯






 工商網監
工商網監
評論