 使用Google Colab快速體驗ScaledYOLOv4
使用Google Colab快速體驗ScaledYOLOv4
「對象偵測」一直是計算機視覺的重點項目,已發展了二十多年,早期利用各種特征提取和比對來找出人們對影像中有興趣的像素集合(對象),如VJ, HOG等。近幾年來,大家則把重點放在了「深度學習」的模型上,從剛開始的二階段偵測器(Two-stage Detector),如RCNN, SPPNet, Fast RCNN, Faster RCNN等,到目前最流行的一階段偵測器(One-stageDetector),如SSD, RetinaNet, EfficientDet, YOLO等,其中又以YOLO(You OnlyLook Once)系列發展的最好,一路發展出YOLOv2, YOLOv3, YOLOv4, YOLOv5, 去年更有ScaledYOLOv4,YOLOX, YOLOR等技術推出,讓大家有更快推論速度、更高推論精度、更彈性模型架構,讓同一張影像中大小對象都能順利被檢出。
「ScaledYOLOv4」這個模型可依輸入影像大小選擇不同尺度架構,以往YOLOv4只分標準和tiny兩種,而這里分為tiny, csp, large,而large又分p5, p6, p7,完整的架構可參考Fig. 1 & 2。至于模型的運作原理[7]寫得頗清楚,這里就不多作說明。從Fig. 1就可明顯看出其效能大幅優于YOLOv3, YOLOv4及EfficientDet。
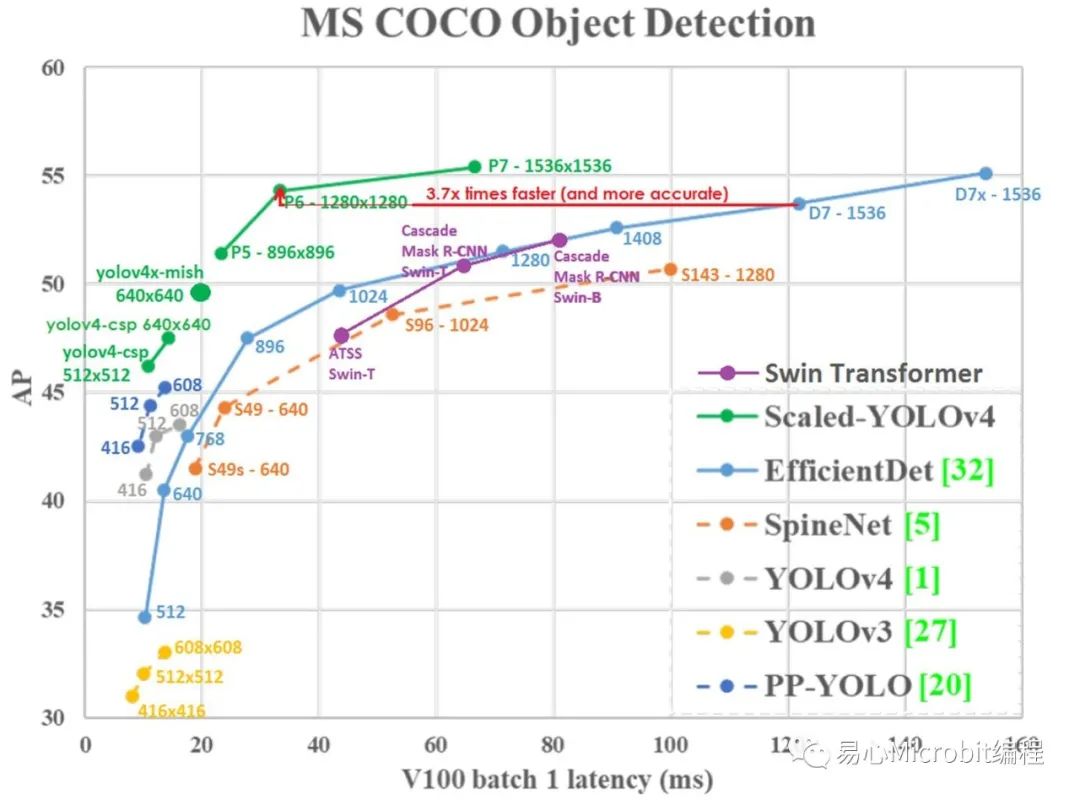
Fig. 1 ScaledYOLOv4和其它模型在COCO數據集推論效能比較表。
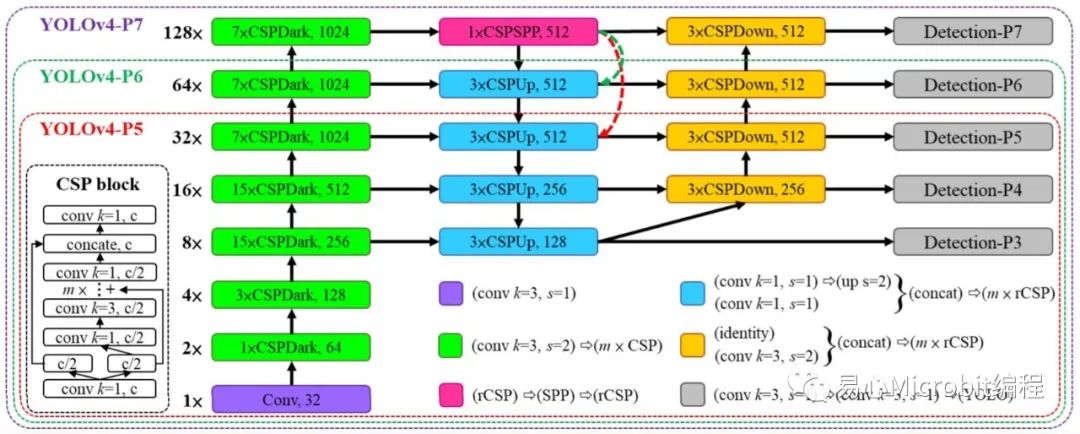
Fig. 2 ScaledYOLOv4模型架構(csp, p5,p6, p7)。
為了讓大家快速上手,這里參考了王建堯博士釋出的PyTorch源碼,
https://github.com/WongKinYiu/ScaledYOLOv4
另外提供了一個完整的Google Colab范例,說明如何建立環境及運行COCO數據集預訓練參數。而訓練及推論自定義數據集就留待下回分解。完整范例請參考下列網址。
https://github.com/OmniXRI/Colab_ScaledYOLOv4
由于csp和large(p5)在模型定義的格式略有不同,前者為cfg,后者是采yaml,權重值亦有不同,前者為weight,后者為pt,所以這里有兩個范例程序,分別對應csp和large兩種格式,而large又以p5為例,若要執行p6, p7則自行修改內容即可。
scaled-yolov4-csp_coco_test.ipynb
scaled-yolov4-large_coco_test.ipynb
整個程序主要有八個動作,如下說明,這里以csp為例。
1. 檢查GPU及CUDA版本
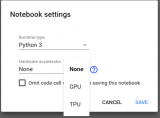
由于后面的程序需要用要Nvidia CUDA,所以要先檢查。執行后若顯示failed,則至左上角選單中「編輯」─「筆記本設定」下「硬件加速器」選擇「GPU」,再重新運行一次即可。至于配置到那一種Nvidia GPU則無妨。
!nvidia-smi
2. 檢查系統默認安裝套件及版本
建議版本如下所示,若大于下列版本而造成無法順利運作則請自行降版后再執行后續工作。
Python3.7.12
opencv-contrib-python4.1.2.30
opencv-python4.1.2.30
tensorboard2.7.0
torch1.10.0+cu111
torchvision0.11.1+cu111
!python--version
!piplist
3. 安裝 mish-cuda
這是ScaledYOLOv4必要組件,一定要安裝,否則無法順利運行,預設安裝版本 0.0.3。
本范例無法于無Nvidia CUDA環境下運行。
!pipinstall git+https://github.com/JunnYu/mish-cuda.git
!piplist
4. 下載ScaledYOLOv4
依需求下載不同版本(csp, large)的PyTorch ScaledYOLOv4到 /content/ScaledYOLOv4 路徑下。請注意這里 -byolov4-csp 為指定下載csp版本分支,若無-b參數則為large(default版本)。
!gitclone -b yolov4-csp https://github.com/WongKinYiu/ScaledYOLOv4
%cdScaledYOLOv4
!ls
5. 下載COCO預訓練權重檔
在 /content/ScaledYOLOv4下新增 /weights 路徑,將Google共享文件COCO預訓練權重值檔案下載到該路徑下。主要差別在--ld后面的路徑,可自行更換。
yolov4-csp.weights: 1TdKvDQb2QpP4EhOIyks8kgT8dgI1iOWT
yolov4-p5.pt: 1aXZZE999sHMP1gev60XhNChtHPRMH3Fz
yolov4-p6.pt: 1aB7May8oPYzBqbgwYSZHuATPXyxh9xnf
yolov4-p7.pt: 18fGlzgEJTkUEiBG4hW00pyedJKNnYLP3
!mkdirweights
%cdweights
!gdown--id 1TdKvDQb2QpP4EhOIyks8kgT8dgI1iOWT
!ls
6. 下載測試影像
在 /data 路徑下建立 /images 用于存放測試影像
隨便從網絡上下載一張影像并更名為 test01.jpg
%cd/content/ScaledYOLOv4/data
!mkdirimages
%cdimages
!wgethttps://raw.githubusercontent.com/WongKinYiu/PyTorch_YOLOv4/master/data/samples/bus.jpg
!mvbus.jpg test01.jpg
!ls
7. 進行推論
根據下列參數執行推論程序 detect.py
影像大小 640x640, (預設csp為640, p5為896, p6為1280, p7為1536)
置信度 0.3, (可自行調整)
推論裝置(GPU) 0, (第一組GPU)
配置文件, (csp為yolov4-csp.cfg, large為yolov4-p5.yaml)
模型權重文件, (csp為yolov4-csp.weights,large為yolov4-p5.pt)
來源影像(可指定單張影像、單個影片、檔案夾等)
%cd/content/ScaledYOLOv4/
!pythondetect.py
--img640
--conf0.3
--device0
--cfgmodels/yolov4-csp.cfg
--weightsweights/yolov4-csp.weights
--sourcedata/images/test01.jpg
8. 顯示推論結果
推論完成會將結果置于 /inference/output 路徑下
使用OpenCV函數顯示結果影像
importcv2
fromgoogle.colab.patches import cv2_imshow
img1 =cv2.imread('data/images/test01.jpg')
cv2_imshow(img1)
img2 =cv2.imread('inference/output/test01.jpg')
cv2_imshow(img2)

Fig. 3ScaledYOLOv4運行結果,左:csp,右:large(p5)。
從Fig. 3上可以看出,連右上角的遮擋的很嚴重的腳踏車都能偵測到。而左側穿白外套男人領口的橘色部位在large(p5)被辨識為領帶,人眼不仔細看還真的會誤判,更何況模型。整體來說表現不錯。
小結
這篇文章先幫大家暖暖身,如果你想辨識的內容在COCO數據集80類范圍內的話,那就直接使用就可以,若需要自己訓練自定義的數據集,就靜待下回分解啰!
審核編輯 :李倩
-
Google
+關注
關注
5文章
1762瀏覽量
57507 -
計算機視覺
+關注
關注
8文章
1698瀏覽量
45980 -
數據集
+關注
關注
4文章
1208瀏覽量
24690 -
深度學習
+關注
關注
73文章
5500瀏覽量
121113
原文標題:使用Google Colab快速體驗ScaledYOLOv4
文章出處:【微信號:易心Microbit編程,微信公眾號:易心Microbit編程】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
使用google-translate和wwe合并后無法使用google-tts怎么解決?
如何預防Google Toolbar監控您的網絡行為
【轉載】Google Glass應用開發探索
淺析ADK Google fast pair功能
Google Colab現在提供免費的T4 GPU
Google“黑科技”,Pixel 4 或將實現指尖級的隔空操作
Google推出了超級強大的在線編輯器Colaboratory
怎樣將Google日歷附加到Google網站
Google重磅發布開源庫TFQ,快速建立量子機器學習模型
如何在Colab中使用SQL

谷歌Colab硬剛Github Copilot,編程效率要翻天
PyTorch教程23.4之使用Google Colab






 工商網監
工商網監
評論