 技術大牛分享快手面試面經
技術大牛分享快手面試面經
這段時間分享了很多校招的面經,有很多讀者說想看社招的,其實社招面試是基于你的工作項目來展開問的,比如你項目用了 xxx 技術,那么面試就會追問你項目是怎么用 xxx 技術的,遇到什么難點和挑戰,然后再考察一下這個 xxx 技術的原理。
今天就分享一位快手社招面經,崗位是后端開發,問題都是基于項目涉及的技術棧去展開聊的,同時最后也會有算法題。
項目
- 自我介紹+項目介紹
- 就你負責比較多的項目詳細說說,項目背景,data模型,流程,難點和挑戰
- 講講項目后端用到的技術棧,比如mq,rpc,緩存啥的
- 消息隊列用過嗎,業務場景?
- 怎么保證消息的有序性?
Redis
Redis有哪些數據類型
回答:String,list,map,set,Zset,stream,hyperloglog。。。
(打斷)追問:map怎么擴容,擴容時會影響緩存嗎
回答:底層有兩個dict,一個dict負責請求,到達負載比例進行擴容,漸進式擴容,一部分一部分轉移到新的dict
追問:擴容時訪問key怎么處理?
回答:先從舊dict獲取key,查不到的話,然后從新的dict獲取key
小林補充:
進行 rehash 的時候,需要用上 2 個哈希表了。
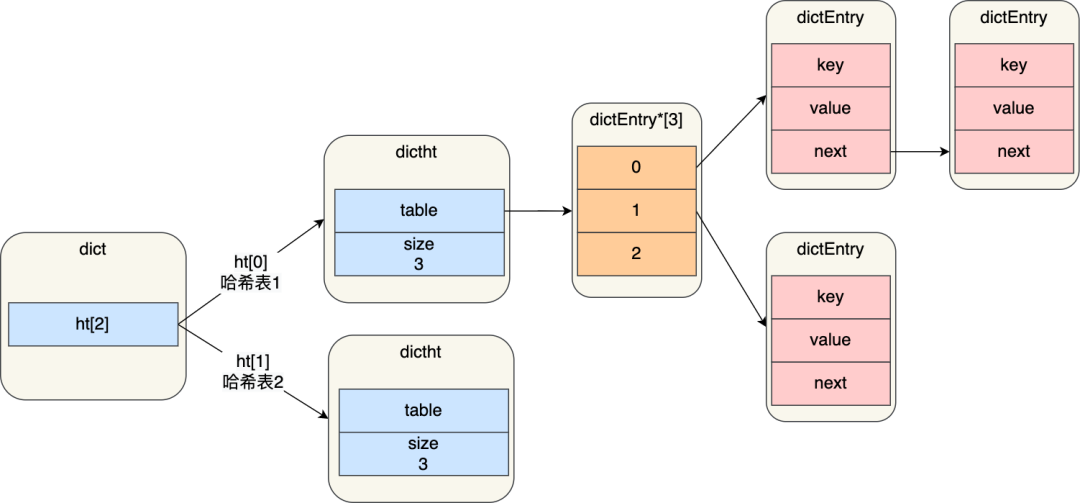 img
img在正常服務請求階段,插入的數據,都會寫入到「哈希表 1」,此時的「哈希表 2 」 并沒有被分配空間。
隨著數據逐步增多,觸發了 rehash 操作,這個過程分為三步:
- 給「哈希表 2」 分配空間,一般會比「哈希表 1」 大 2 倍;
- 將「哈希表 1 」的數據遷移到「哈希表 2」 中;
- 遷移完成后,「哈希表 1 」的空間會被釋放,并把「哈希表 2」 設置為「哈希表 1」,然后在「哈希表 2」 新創建一個空白的哈希表,為下次 rehash 做準備。
為了方便你理解,我把 rehash 這三個過程畫在了下面這張圖:
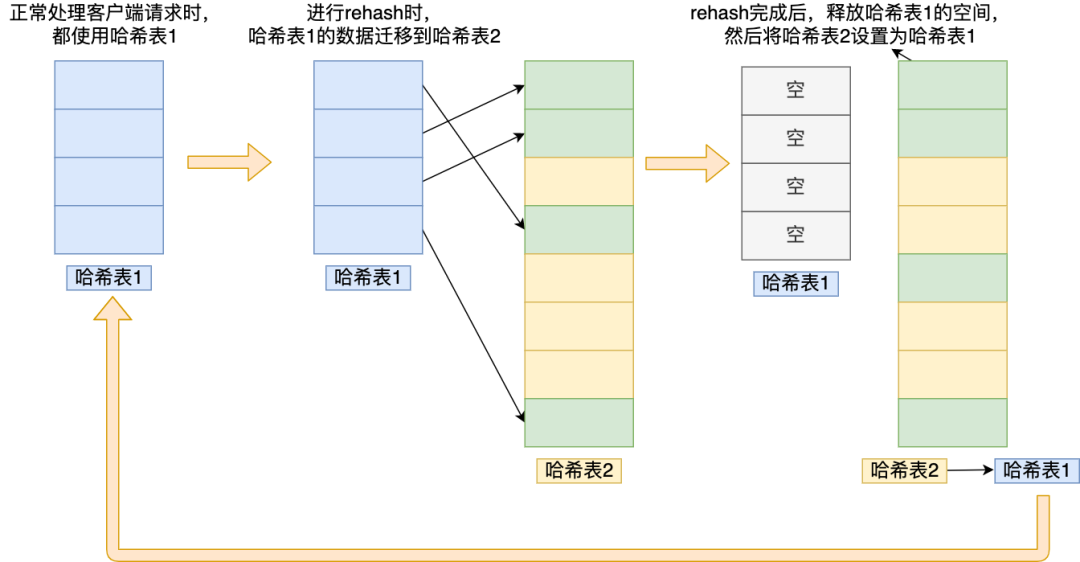 img
img這個過程看起來簡單,但是其實第二步很有問題,如果「哈希表 1 」的數據量非常大,那么在遷移至「哈希表 2 」的時候,因為會涉及大量的數據拷貝,此時可能會對 Redis 造成阻塞,無法服務其他請求。
為了避免 rehash 在數據遷移過程中,因拷貝數據的耗時,影響 Redis 性能的情況,所以 Redis 采用了漸進式 rehash,也就是將數據的遷移的工作不再是一次性遷移完成,而是分多次遷移。
漸進式 rehash 步驟如下:
- 給「哈希表 2」 分配空間;
- 在 rehash 進行期間,每次哈希表元素進行新增、刪除、查找或者更新操作時,Redis 除了會執行對應的操作之外,還會順序將「哈希表 1 」中索引位置上的所有 key-value 遷移到「哈希表 2」 上;
- 隨著處理客戶端發起的哈希表操作請求數量越多,最終在某個時間點會把「哈希表 1 」的所有 key-value 遷移到「哈希表 2」,從而完成 rehash 操作。
這樣就巧妙地把一次性大量數據遷移工作的開銷,分攤到了多次處理請求的過程中,避免了一次性 rehash 的耗時操作。
在進行漸進式 rehash 的過程中,會有兩個哈希表,所以在漸進式 rehash 進行期間,哈希表元素的刪除、查找、更新等操作都會在這兩個哈希表進行。比如,查找一個 key 的值的話,先會在「哈希表 1」 里面進行查找,如果沒找到,就會繼續到哈希表 2 里面進行找到。
另外,在漸進式 rehash 進行期間,新增一個 key-value 時,會被保存到「哈希表 2 」里面,而「哈希表 1」 則不再進行任何添加操作,這樣保證了「哈希表 1 」的 key-value 數量只會減少,隨著 rehash 操作的完成,最終「哈希表 1 」就會變成空表。
跳表結構了解嗎
回答:第一層是雙向鏈表,會有多層來作為鏈表的索引。
追問:和二叉樹有什么區別,從時間復雜度和空間復雜度分析
回答:二叉查找樹的時間復雜度是O(logn),空間復雜度是O(n);跳表的時間復雜度是O(log_{k}n),k為跳表索引步長,空間復雜度是O(n)
MySQL
MySQL事務用過嗎,應用場景是什么
自己學習的demo里用過,場景:銀行轉賬
追問:假如是跨行轉賬怎么解決事務
回答:我想一想。。。
小林補充:用分布式事務
(打斷)追問:跨行先不說,先說不跨行,先說說單庫事務,事務的4個基本特性
回答:原子性,一致性,隔離性,持久性
追問:一致性指的是什么
回答:一致性指的是事務提交前后數據庫狀態一致,是原子性,隔離性和持久性的整合
追問:隔離級別有哪幾種
回答:讀未提交,讀已提交,可重復讀,序列化
追問:可重復讀是是什么意思,怎么實現的
同一個事務中多次讀取結果一致。通過Read View + MVCC實現,在事務開始時創建一個Read View,之后都用這個Read View。
追問:可重復讀具體實現細節
回答:Read View的結構包含(1)當前事務id,(2)active事務id列表,(3)最小active事務id記為min_txn_id,(4)next事務id記為max_txn_id。如果record對應的事務id,小于最小active事務id,直接讀;否則讀取最小active事務id之前版本的數據(這塊的邏輯答得有問題,用語言表達時有點混亂,可以私下多練習練習表達)
小林補充:
我們需要了解兩個知識:
- Read View 中四個字段作用;
- 聚簇索引記錄中兩個跟事務有關的隱藏列;
那 Read View 到底是個什么東西?
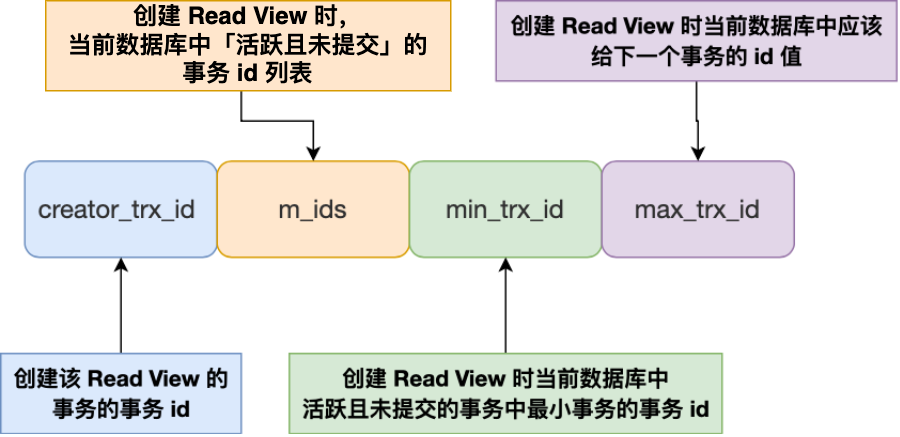 img
imgRead View 有四個重要的字段:
- m_ids :指的是在創建 Read View 時,當前數據庫中「活躍事務」的事務 id 列表,注意是一個列表,“活躍事務”指的就是,啟動了但還沒提交的事務。
- min_trx_id :指的是在創建 Read View 時,當前數據庫中「活躍事務」中事務 id 最小的事務,也就是 m_ids 的最小值。
- max_trx_id :這個并不是 m_ids 的最大值,而是創建 Read View 時當前數據庫中應該給下一個事務的 id 值,也就是全局事務中最大的事務 id 值 + 1;
- creator_trx_id :指的是創建該 Read View 的事務的事務 id。
知道了 Read View 的字段,我們還需要了解聚簇索引記錄中的兩個隱藏列。
假設在賬戶余額表插入一條小林余額為 100 萬的記錄,然后我把這兩個隱藏列也畫出來,該記錄的整個示意圖如下:
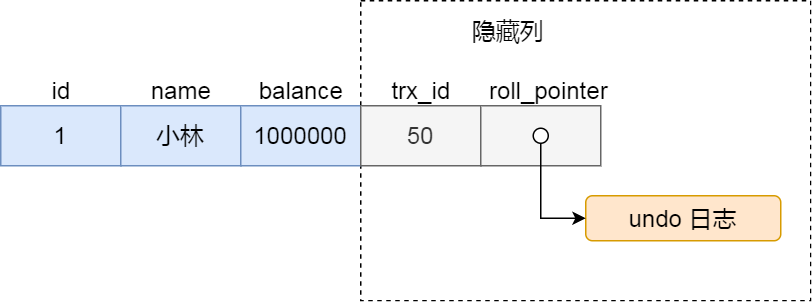 圖片
圖片對于使用 InnoDB 存儲引擎的數據庫表,它的聚簇索引記錄中都包含下面兩個隱藏列:
- trx_id,當一個事務對某條聚簇索引記錄進行改動時,就會把該事務的事務 id 記錄在 trx_id 隱藏列里;
- roll_pointer,每次對某條聚簇索引記錄進行改動時,都會把舊版本的記錄寫入到 undo 日志中,然后這個隱藏列是個指針,指向每一個舊版本記錄,于是就可以通過它找到修改前的記錄。
在創建 Read View 后,我們可以將記錄中的 trx_id 劃分這三種情況:
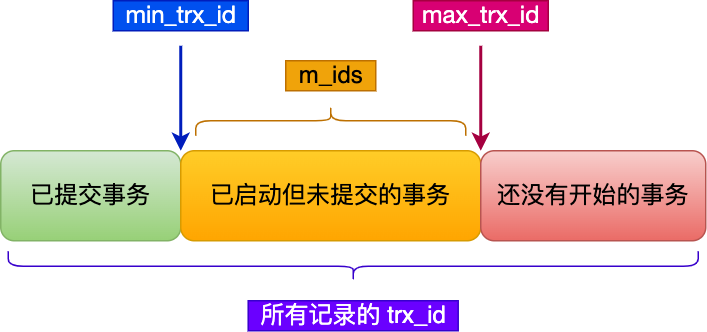 img
img一個事務去訪問記錄的時候,除了自己的更新記錄總是可見之外,還有這幾種情況:
-
如果記錄的 trx_id 值小于 Read View 中的
min_trx_id值,表示這個版本的記錄是在創建 Read View 前已經提交的事務生成的,所以該版本的記錄對當前事務可見。 -
如果記錄的 trx_id 值大于等于 Read View 中的
max_trx_id值,表示這個版本的記錄是在創建 Read View 后才啟動的事務生成的,所以該版本的記錄對當前事務不可見。 -
如果記錄的 trx_id 值在 Read View 的
min_trx_id和
max_trx_id之間,需要判斷 trx_id 是否在 m_ids 列表中:
-
如果記錄的 trx_id 在
m_ids列表中,表示生成該版本記錄的活躍事務依然活躍著(還沒提交事務),所以該版本的記錄對當前事務不可見。 -
如果記錄的 trx_id 不在
m_ids列表中,表示生成該版本記錄的活躍事務已經被提交,所以該版本的記錄對當前事務可見。
-
如果記錄的 trx_id 在
MySQL binlog,redolog和undolog的區別
回答:從這三種log的功能進行分析,undolog用來做事務回滾;redolog用來處理mysql宕機(或進程掛掉)時的數據恢復;binlog記錄所有的數據修改操作,可以用來做全量的數據恢復,主從復制(后一點當時沒答出來)。
小林補充:
-
binlog(二進制日志):記錄所有對MySQL數據庫的修改操作,包括插入、更新和刪除等。binlog主要用于數據恢復到指定時間點或者指定事務。可以使用mysqlbinlog命令將binlog文件解析成SQL語句,從而恢復MySQL數據庫的狀態。
-
redolog(重做日志):記錄所有對MySQL數據庫的修改操作,但是只記錄了物理操作,比如頁的修改。redolog主要用于MySQL的崩潰恢復,即在MySQL崩潰后,通過重做日志,將數據庫恢復到最近一次提交的狀態。可以使用 Forcing InnoDB Recovery 來進行崩潰恢復。
-
undolog(回滾日志):用于記錄事務的回滾操作,即在事務執行過程中,如果發生了回滾,會將回滾操作記錄到undolog中。undolog主要用于 MySQL 的回滾操作,比如使用ROLLBACK語句回滾事務。undolog是InnoDB存儲引擎的特有日志,不同于其他存儲引擎。
追問:binlog和redolog做數據恢復的區別
回答:redolog有大小限制,數據可能被覆蓋,用來處理緊急數據庫故障;binlog是全量操作日志,可以進行做全量的數據恢復。
小林補充:
binlog和redolog都是用于MySQL數據庫的日志。它們都可以用于數據恢復,但是它們的使用場景和恢復方法有所不同。
binlog是MySQL的二進制日志,它記錄了所有對MySQL數據庫的修改操作,包括插入、更新和刪除等。binlog可以用于恢復MySQL數據庫到指定的時間點或者指定的事務。具體來說,可以使用mysqlbinlog命令將binlog文件解析成SQL語句,然后再執行這些SQL語句,從而恢復MySQL數據庫的狀態。
redolog是MySQL的重做日志,它記錄了所有對MySQL數據庫的修改操作,但是只記錄了物理操作,比如頁的修改。redolog可以用于恢復MySQL數據庫的崩潰恢復,即在MySQL崩潰后,通過重做日志,將數據庫恢復到最近一次提交的狀態。具體來說,可以使用innodb_recovery命令來進行崩潰恢復,該命令會根據重做日志來恢復數據庫。
因此,binlog和redolog都可以用于數據恢復,但是它們的使用場景和恢復方法有所不同。binlog主要用于數據恢復到指定時間點或者指定事務,而redolog主要用于MySQL的崩潰恢復。
算法
- 合并兩個有序數組
面試總結
感覺
基礎知識答得還行,編程拉了不足之處
有些地方的表達邏輯不夠清晰,代碼得多寫。
-
算法
+關注
關注
23文章
4607瀏覽量
92835 -
數據庫
+關注
關注
7文章
3794瀏覽量
64360 -
代碼
+關注
關注
30文章
4779瀏覽量
68521 -
MySQL
+關注
關注
1文章
804瀏覽量
26530 -
Redis
+關注
關注
0文章
374瀏覽量
10871
原文標題:快手面試,一直追著問我。。。
文章出處:【微信號:小林coding,微信公眾號:小林coding】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【CANNON試用體驗】面試
軟件開發實習面經 精選資料分享
CVTE嵌入式面試相關資料分享
快手刷粉絲,深度的講解下快手漲粉技巧的方法
快手刷評論的作用是什么?
深信服面算法工程師面試經歷
工程師技術面試應該準備什么
CVTE嵌入式面試匯總

【嵌入式工程師】海康威視面試經驗 | 內涵紫光展銳、瑞芯微等公司嵌入式面經
面試面經 | 2021大疆嵌入式軟件工程師筆試題B卷
嵌入式軟件工程師筆試面試指南-C/C++





 工商網監
工商網監
評論