") 目標(biāo)檢測領(lǐng)域的一些共性問題總結(jié)
目標(biāo)檢測領(lǐng)域的一些共性問題總結(jié)
導(dǎo)讀
本文對目標(biāo)檢測領(lǐng)域的一些共性問題進(jìn)行了總結(jié),并給出了詳細(xì)的解答。
目標(biāo)檢測兩階段和一階段的核心區(qū)別
目標(biāo)檢測技術(shù)從階段上分為兩種,一階段和二階段。二階段的核心思想是首先提出proposal框,通過第一階段的網(wǎng)絡(luò)回歸出目標(biāo)框的大概位置、大小及是前景的概率,第二階段是通過另一個(gè)網(wǎng)絡(luò)回歸出目標(biāo)框的位置、大小及類別;而一階段網(wǎng)絡(luò)的核心是,對于輸入圖像,通過網(wǎng)絡(luò)直接回歸出目標(biāo)大小、位置和類別。
目標(biāo)檢測兩階段比一階段的算法精度高的原因
1.正負(fù)樣本的不均衡性
當(dāng)某一類別的樣本數(shù)特別多的時(shí)候,訓(xùn)練出來的網(wǎng)絡(luò)對該類的檢測精度往往會(huì)比較高。而當(dāng)某一類的訓(xùn)練樣本數(shù)較少的時(shí)候,模型對該類目標(biāo)的檢測精度就會(huì)有所下降,這就是所謂樣本的不均衡性導(dǎo)致的檢測精度的差異。
對于一階段的目標(biāo)檢測來說,它既要做定位又要做分類,最后幾層中1×1的卷積層的loss都混合在一起,沒有明確的分工哪部分專門做分類,哪部分專門做預(yù)測框的回歸,這樣的話對于每個(gè)參數(shù)來說,學(xué)習(xí)的難度就增加了。
對于二階段的目標(biāo)檢測來說(Faster RCNN),在RPN網(wǎng)絡(luò)結(jié)構(gòu)中進(jìn)行了前景和背景的分類和檢測,這個(gè)過程與一階段的目標(biāo)檢測直接一上來就進(jìn)行分類和檢測要簡單的很多,有了前景和背景的區(qū)分,就可以選擇性的挑選樣本,是的正負(fù)樣本變得更加的均衡,然后重點(diǎn)對一些參數(shù)進(jìn)行分類訓(xùn)練。訓(xùn)練的分類難度會(huì)比一階段目標(biāo)檢測直接做混合分類和預(yù)測框回歸要來的簡單很多。
2.樣本的不一致性
怎么理解樣本不一致性呢?首先我們都知道在RPN獲得多個(gè)anchors的時(shí)候,會(huì)使用一個(gè)NMS。在進(jìn)行回歸操作的時(shí)候,預(yù)測框和gt的IoU同回歸后預(yù)測框和gt的IOU相比,一般會(huì)有較大的變化,但是NMS使用的時(shí)候用的是回歸前的置信度,這樣就會(huì)導(dǎo)致一些回歸后高IoU的預(yù)測框被刪除。這就使得回歸前的置信度并不能完全表征回歸后的IoU大小。這樣子也會(huì)導(dǎo)致算法精度的下降。在第一次使用NMS時(shí)候這種情況會(huì)比較明顯,第二次使用的時(shí)候就會(huì)好很多,因此一階段只使用一次NMS是會(huì)對精度有影響的,而二階段目標(biāo)檢測中會(huì)在RPN之后進(jìn)行一個(gè)更為精細(xì)的回歸,在該處也會(huì)用到NMS,此時(shí)檢測的精度就會(huì)好很多。
如何解決目標(biāo)檢測中密集遮擋問題
遮擋本身也可以分為兩種類型,一種是由于非目標(biāo)造成的遮擋,一種是由于也是需要檢測的目標(biāo)造成的遮擋。這兩種遮擋分別被叫做occlusion和crowded。
對于前一種類型遮擋,很難有針對性的辦法去解決,最好的辦法也就是使用更多的數(shù)據(jù)和更強(qiáng)的feature。可以從訓(xùn)練數(shù)據(jù)入手。加掩膜,加擾動(dòng),提高算法對遮擋的應(yīng)對能力。
對于第二種遮擋,提出了兩個(gè)針對這個(gè)問題的loss,
通過設(shè)置損失函數(shù)的方式,即Repulsion Loss,使預(yù)測框和所負(fù)責(zé)的真實(shí)目標(biāo)框的距離縮小,而使得其與周圍非負(fù)責(zé)目標(biāo)框(包含真實(shí)目標(biāo)框和預(yù)測框)的距離加大 。如下式,如果與周圍目標(biāo)的距離越大,損失值會(huì)越小。
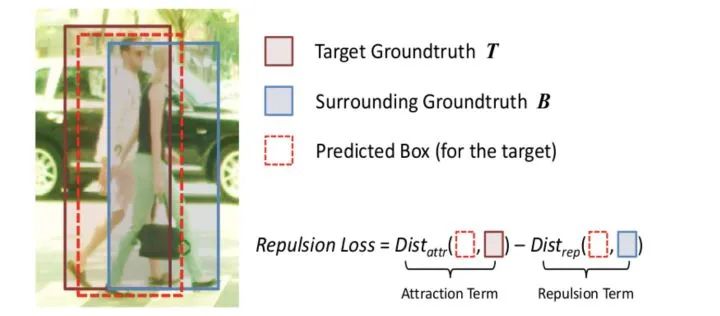
除了常用的smooth L1使回歸目標(biāo)與GT接近之外,這兩個(gè)loss一個(gè)的目標(biāo)是使proposal和要盡量遠(yuǎn)離和它overlap的第二大的GT,另一個(gè)目標(biāo)是要上被assign到不同GT的proposal之間盡量遠(yuǎn)離。通過這兩個(gè)loss,不僅僅使得proposal可以向正確的目標(biāo)靠近,也可以使其遠(yuǎn)離錯(cuò)誤的目標(biāo),從而減少NMS時(shí)候的誤檢。

“狹長形狀”目標(biāo)檢測有什么合適方法
使用可旋轉(zhuǎn)bonding box進(jìn)行標(biāo)注
手工設(shè)計(jì)anchors
如何解決動(dòng)態(tài)目標(biāo)檢測
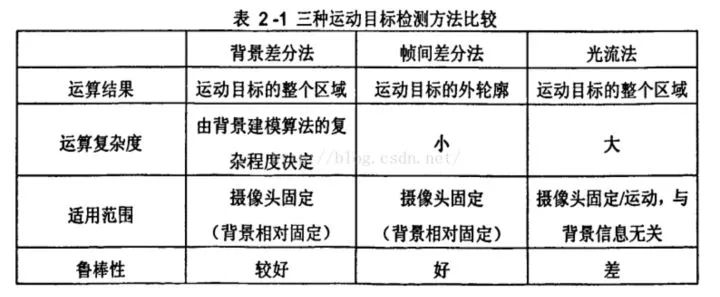
1.光流法
光流是空間運(yùn)動(dòng)物體被觀測面上的像素點(diǎn)運(yùn)動(dòng)產(chǎn)生的瞬時(shí)速度場,包含了物體表面結(jié)構(gòu)和動(dòng)態(tài)行為的重要信息。光流計(jì)算法大致可分為三類:
(1)基于匹配的光流計(jì)算方法,包括基于特征和基于區(qū)域的兩種。基于特征的方法是不斷地對目標(biāo)主要特征進(jìn)行定位和跟蹤,對大目標(biāo)的運(yùn)動(dòng)和亮度變化具有魯棒性,存在的問題是光流通常很稀疏,而且特征提取和精確匹配也十分困難;基于區(qū)域的方法先對類似的區(qū)域進(jìn)行定位,然后通過相似區(qū)域的位移計(jì)算光流,這種方法在視頻編碼中得到了廣泛的應(yīng)用,但它計(jì)算的光流仍不稠密。
(2)基于頻域的方法利用速度可調(diào)的濾波組輸出頻率或相位信息,雖然能獲得很高精度的初始光流估計(jì),但往往涉及復(fù)雜的計(jì)算,而且可靠性評(píng)價(jià)也十分困難。
(3)基于梯度的方法利用圖像序列的時(shí)空微分計(jì)算2D速度場(光流)。由于計(jì)算簡單和較好的實(shí)驗(yàn)結(jié)果,基于梯度的方法得到了廣泛應(yīng)用。
2.相鄰幀差法
相鄰幀差法是在運(yùn)動(dòng)目標(biāo)檢測中使用的最多的一類算法。原理就是將前后兩幀圖像對應(yīng)的像素值相減,在環(huán)境亮度變化不大的情況下,如果對應(yīng)像素值相差值很小,可認(rèn)為此處景物是靜止的,反之,則是運(yùn)動(dòng)物體。
相鄰幀差法對于動(dòng)態(tài)環(huán)境具有較強(qiáng)的自適應(yīng)性,魯棒性較好,能夠適應(yīng)各種動(dòng)態(tài)環(huán)境,但一般不能完全提取出所有相關(guān)的特征像素點(diǎn),這樣在運(yùn)動(dòng)實(shí)體內(nèi)部容易產(chǎn)生空洞現(xiàn)象。
3.背景差法
背景差法是常用的運(yùn)動(dòng)目標(biāo)檢測方法之一。它的基本思想是將輸入圖像與背景模型進(jìn)行比較,通過判定灰度等特征的變化,或用直方圖等統(tǒng)計(jì)信息的變化來判斷異常情況的發(fā)生和分割運(yùn)動(dòng)目標(biāo)。
與幀間差法比較,背景差法可以檢測視頻中停止運(yùn)動(dòng)的物體,其缺點(diǎn)是背景的更新導(dǎo)致算法的復(fù)雜性增加,實(shí)時(shí)性變差。
4. 基于事件相機(jī)來做
事件相機(jī)是具有微秒反應(yīng)時(shí)間的仿生傳感器,可記錄每像素亮度變化的異步流,稱為“事件”。事件相機(jī)通過檢測每個(gè)像素的亮度變化來生成一個(gè)事件,相比于傳統(tǒng)相機(jī),更適合在高動(dòng)態(tài)和高速度的環(huán)境下使用,具有高動(dòng)態(tài)范圍 (HDR)、高時(shí)間分辨率和無運(yùn)動(dòng)模糊的優(yōu)勢。
- 高動(dòng)態(tài)范圍:對于傳統(tǒng)相機(jī)來說,在黑暗的情況下,傳統(tǒng)的相機(jī)幾乎沒有辦法使用,但對于事件相機(jī)來說,只檢測正在運(yùn)動(dòng)的物體,所以無論是黑暗情況還是有光亮的情況,事件相機(jī)都可以發(fā)揮作用。
- 低延時(shí):相鄰事件之間的時(shí)間可以小于1毫秒
- 無運(yùn)動(dòng)模糊:即使是高速運(yùn)動(dòng)的物體,事件相機(jī)也可以捕獲到
FPN的作用
FPN是在卷積神經(jīng)網(wǎng)絡(luò)中圖像金字塔的應(yīng)用。圖像金字塔在多尺度識(shí)別中有重要的作用,尤其是小目標(biāo)檢測。頂層特征上采樣后和底層特征融合,每層獨(dú)立預(yù)測。
fpn設(shè)計(jì)動(dòng)機(jī):
1.高層特征向低層特征融合,增加低層特征表達(dá)能力,提升性能
2.不同尺度的目標(biāo)可以分配到不同層預(yù)測,達(dá)到分而治之。
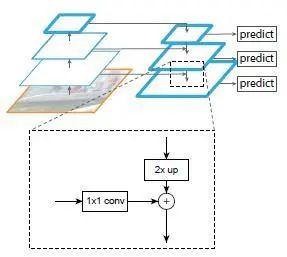
FPN每層做特征融合的特征圖有兩個(gè),首先是前向傳播,然后取了每個(gè)特征圖做上采樣(最近鄰插值),對應(yīng)前向傳播的特征圖做融合。融合的方式是:通過1x1卷積調(diào)整通道數(shù),然后直接add。之后進(jìn)行3x3卷積操作,目的是消除上采樣的混疊效應(yīng)。
其實(shí),fpn真正起作用的是分而治之的策略,特征融合的作用其實(shí)很有限,此外fpn存在消耗大量顯存,降低推理速度。
為什么FPN采用融合以后效果要比使用pyramidal feature hierarchy這種方式要好?
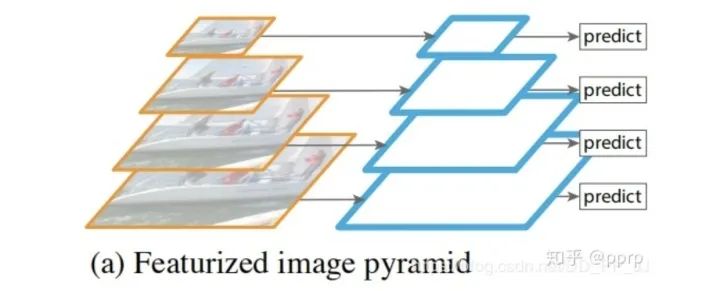
卷積雖然能夠高效地向上提取語義,但是也存在像素錯(cuò)位問題,通過上采樣還原特征圖很好地緩解了像素不準(zhǔn)的問題。
backbone可以分為淺層網(wǎng)絡(luò)和深層網(wǎng)絡(luò),淺層網(wǎng)絡(luò)負(fù)責(zé)提取目標(biāo)邊緣等底層特征,而深層網(wǎng)絡(luò)可以構(gòu)建高級(jí)的語義信息,通過使用FPN這種方式,讓深層網(wǎng)絡(luò)更高級(jí)語義的部分的信息能夠融合到稍淺層的網(wǎng)絡(luò),指導(dǎo)淺層網(wǎng)絡(luò)進(jìn)行識(shí)別。
從感受野的角度思考,淺層特征的感受野比較小,深層網(wǎng)絡(luò)的感受野比較大,淺層網(wǎng)絡(luò)主要負(fù)責(zé)小目標(biāo)的檢測,深層的網(wǎng)絡(luò)負(fù)責(zé)大目標(biāo)的檢測(比如人臉檢測中的SSH就使用到了這個(gè)特點(diǎn))。
FPN在RPN中的應(yīng)用
rpn在faster rcnn中用于生成proposals,原版rpn生成在每個(gè)image的最后一張?zhí)卣鲌D上生成3x3個(gè)proposal。但實(shí)際上,小目標(biāo)下采樣到最后一個(gè)特征圖,已經(jīng)很小了。fpn可以在之前的多個(gè)特征圖上獲得proposal,具體做法是:在每個(gè)feature map上獲得1:1、1:2、2:1長寬比的框,尺寸是{32^2、64^2、128^2、256^2、512^2}分別對應(yīng){P2、P3、P4、P5、P6}這五個(gè)特征層上。P6是專門為了RPN網(wǎng)絡(luò)而設(shè)計(jì)的,用來處理512大小的候選框。它由P5經(jīng)過下采樣得到。
如何解決小目標(biāo)識(shí)別問題
通用的定義來自 COCO 數(shù)據(jù)集(https://so.csdn.net/so/search%3Fq%3D%25E6%2595%25B0%25E6%258D%25AE%25E9%259B%2586%26spm%3D1001.2101.3001.7020),定義小于 32x32 pix 的為小目標(biāo)。
小目標(biāo)檢測的難點(diǎn):可利用特征少,現(xiàn)有數(shù)據(jù)集中小目標(biāo)占比少,小目標(biāo)聚集問題
首先小目標(biāo)本身分辨率低,圖像模糊,攜帶的信息少。由此所導(dǎo)致特征表達(dá)能力弱,也就是在提取特征的過程中,能提取到的特征非常少,這不利于我們對小目標(biāo)的檢測。
另外通常網(wǎng)絡(luò)為了減少計(jì)算量,都使用到了下采樣,而下采樣過多,會(huì)導(dǎo)致小目標(biāo)的信息在最后的特征圖上只有幾個(gè)像素(甚至更少),信息損失較多。
-
數(shù)據(jù)。
提高圖像采集的分辨率:基于 GAN 的方法解決的也是小目標(biāo)本身判別性特征少的問題,其想法非常簡單但有效:利用 GAN 生成高分辨率圖片或者高分辨率特征。 - Data Augmentation。一些特別有用的小物體檢測增強(qiáng)包括隨機(jī)裁剪、隨機(jī)旋轉(zhuǎn)和馬賽克增強(qiáng)。copy pasting, 增加小目標(biāo)數(shù)量。縮放與拼接,增加中小目標(biāo)數(shù)量
- 修改模型輸入尺寸。提高模型的輸入分辨率,也就是減少或者不壓縮原圖像。tiling,將圖像切割后形成batch,可以在保持小輸入分辨率的同時(shí)提升小目標(biāo)檢測,但是推理時(shí)也需要 tiling,然后把目標(biāo)還原到原圖,整體做一次 NMS。
- 修改 Anchor。適合小目標(biāo)的 Anchor
- Anchor Free。錨框設(shè)計(jì)難以獲得平衡小目標(biāo)召回率與計(jì)算成本之間的矛盾,而且這種方式導(dǎo)致了小目標(biāo)的正樣本與大目標(biāo)的正樣本極度不均衡,使得模型更加關(guān)注于大目標(biāo)的檢測性能,從而忽視了小目標(biāo)的檢測。
- 多尺度學(xué)習(xí)。FPN, 空洞卷積,通過多尺度可以將下采樣前的特征保留,盡量保留小目標(biāo)
- 減小下采樣率。比如對于 YOLOv5 的 stride 為 32, 可以調(diào)整其 stride 來減小下采樣率,從而保留某些比較小的特征。
- SPP 模塊。增加感受野,對小目標(biāo)有效果,SPP size 的設(shè)置解決輸入 feature map 的size 可能效果更好。
- 損失函數(shù)。小目標(biāo)大權(quán)重,此外也可以嘗試 Focal Loss。
介紹目標(biāo)檢測RCNN系列和Yolo系列的區(qū)別
YOLO所屬類別為one-stage,F(xiàn)ast-Rcnn所屬類別為two-stage
two stage:
先進(jìn)行區(qū)域生成,該區(qū)域稱為region proposal(RP,一個(gè)有可能包含物體的預(yù)選框);再通過卷積神經(jīng)網(wǎng)絡(luò)進(jìn)行樣本分類,精度高,適合做高檢測精度的任務(wù)
任務(wù)流程:特征提取—生成RP—分類/定位回歸
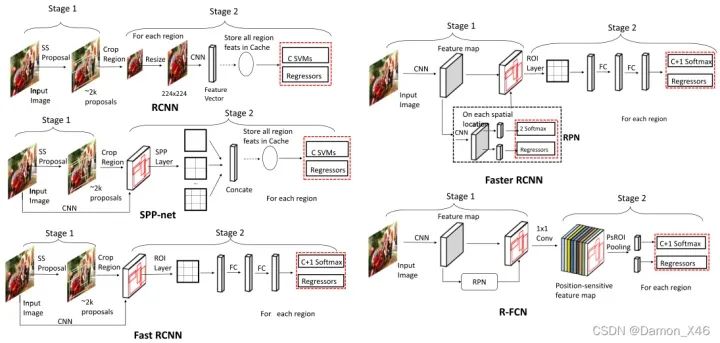
one stage:
不用RP,直接在網(wǎng)絡(luò)中提取特征來預(yù)測物體的分類和位置,速度非常快,適合做實(shí)時(shí)檢測任務(wù),但是效果不會(huì)太好
任務(wù)流程:特征提取—分類/定位回歸
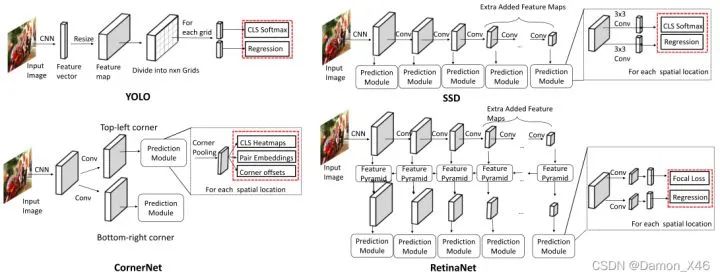
YOLO和SSD區(qū)別
YOLO將物體檢測這個(gè)問題定義為bounding box和分類置信度的回歸問題。
將整張圖像作為輸入,劃分成SxS grid,每個(gè)cell預(yù)測B個(gè)bounding box(x, y, w, h)及對應(yīng)的分類置信度(class-specific confidence score)。分類置信度是bounding box是物體的概率及其與真實(shí)值IOU相乘的結(jié)果。
SSD將物體檢測這個(gè)問題的解空間,抽象為一組預(yù)先設(shè)定好(尺度,長寬比,1,2,3,1/2,1/3)的bounding box。在每個(gè)bounding box,預(yù)測分類label,以及box offset來更好的框出物體。對一張圖片,結(jié)合多個(gè)大小不同的feature map的預(yù)測結(jié)果,能夠處理大小不同的物體。
區(qū)別:
YOLO在卷積層后接全連接層,即檢測時(shí)只利用了最高層Feature maps。而SSD采用金字塔結(jié)構(gòu),即利用了conv4-3/fc7/conv6-2/conv7-2/conv8_2/conv9_2這些大小不同的feature maps,在多個(gè)feature maps上同時(shí)進(jìn)行softmax分類和位置回歸
SSD還加入了Prior box(先驗(yàn)框)
前景背景樣本不均衡解決方案:Focal Loss,GHM與PISA
我們可以將前景背景類不平衡的解決方案分為四類:(i)硬采樣方法,(ii)軟抽樣方法( Soft Sampling Methods),(iii)無抽樣方法和(iv)生成方法。
1. 軟抽樣方法
軟采樣調(diào)整每個(gè)樣本在訓(xùn)練過程中迭代的權(quán)重(wi),這與硬采樣不同,沒有樣本被丟棄,整個(gè)數(shù)據(jù)集用于更新參數(shù)中。該方法同樣也可以應(yīng)用在分類任務(wù)中。
1.1 Focal Loss
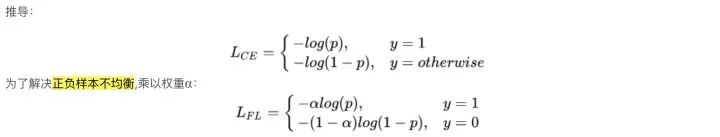
一般根據(jù)各類別數(shù)據(jù)占比,對 α 進(jìn)行取值,即當(dāng)class_1占比為30%時(shí), α = 0.3,但是這個(gè)并不能解決所有問題。因?yàn)楦鶕?jù)正負(fù)難易,樣本一共可以分為以下四類:

雖然 α 平衡了正負(fù)樣本,但對難易樣本的不平衡沒有任何幫助。其中易分樣本(即,置信度高的樣本)對模型的提升效果非常小,即模型無法從中學(xué)習(xí)大量的有效信息。所以模型應(yīng)該主要關(guān)注于那些難分樣本。(這個(gè)假設(shè)是有問題的,GHM對其進(jìn)行了改進(jìn))。
我們希望模型能更關(guān)注容易錯(cuò)分的數(shù)據(jù),反向思考,就是讓模型別那么關(guān)注容易分類的樣本。因此,F(xiàn)ocal Loss的思路就是,把高置信度的樣本損失降低
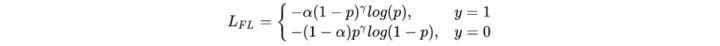
實(shí)驗(yàn)表明 γ 取2, α 取0.25的時(shí)候效果最佳。


1.2 Gradient Harmonizing Mechanism (GHM)
Focal Loss對容易分類的樣本進(jìn)行了損失衰減,讓模型更關(guān)注難分樣本,并通過 α alpha α和 γ gamma γ進(jìn)行調(diào)參。這樣相比CE loss 可以提高效果,但是也存在一些問題:
Focal loss有兩個(gè)超參數(shù)( α和 γ),調(diào)整起來十分費(fèi)力。
Focal loss 是個(gè)靜態(tài)loss,不會(huì)自適應(yīng)于數(shù)據(jù)的分布,在訓(xùn)練的過程中會(huì)一直的變化。
GHM認(rèn)為,類別不均衡可總結(jié)為難易分類樣本的不均衡,而這種難分樣本的不均衡又可視為梯度密度分布的不均衡。假設(shè)一個(gè)正樣本被正確分類,它就是正易樣本,損失不大,模型不能從中獲益。而一個(gè)錯(cuò)誤分類的樣本,更能促進(jìn)模型迭代。實(shí)際應(yīng)用中,大量的樣本都是屬于容易分類的類型,這種樣本一個(gè)起不了太大作用,但量級(jí)過大,在模型進(jìn)行梯度更新時(shí),起主要作用,使得模型朝這類數(shù)據(jù)更新
GHM中提到:有一部分難分樣本就是離群點(diǎn),不應(yīng)該給他太多關(guān)注;樣本不均衡的基本效果可以通過梯度密度直接統(tǒng)計(jì)得到,不需要調(diào)參。
簡而言之:Focal Loss是從置信度p來調(diào)整loss,GHM通過一定范圍置信度p的樣本數(shù)來調(diào)整loss。
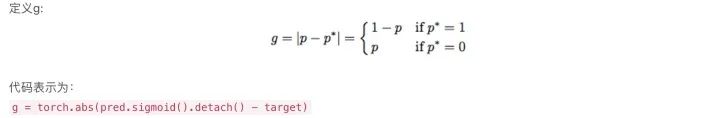
g的值表示樣本的屬性(easy/hard), 意味著對全局梯度的影響。盡管梯度的嚴(yán)格定義應(yīng)該是在整個(gè)參數(shù)空間,但是g是樣本梯度的成比例的norm,在這片論文中g(shù)被稱作gradient norm。
不同屬性的樣本(hard/easy,pos/neg)可以由 gradient norm的分布來表示。在圖1左中可以看出變化非常大。具有 小 gradient norm 的樣本具有很大的密度,它們對應(yīng)于大量的負(fù)樣本(背景)。由于大量的簡單負(fù)樣本,我們使用log軸來顯示樣本的分?jǐn)?shù),以演示具有不同屬性的樣本的方差的細(xì)節(jié)。盡管一個(gè)easy樣本在全局梯度上相比hard樣本具有更小的貢獻(xiàn),但是大量的easy樣本的全部貢獻(xiàn)會(huì)壓倒少數(shù)hard樣本的貢獻(xiàn),所以訓(xùn)練過程變得無效。除此之外,論文還發(fā)現(xiàn)具有非常 大gradient norm的樣本(very hard examples)的密度微大于中間樣本的密度。并且發(fā)現(xiàn)這些very hard樣本大多數(shù)是outliers,因?yàn)榧词鼓P褪諗克鼈兪冀K穩(wěn)定存在。如果收斂模型被強(qiáng)制學(xué)習(xí)分類這些outliers,對其他樣本的分類可能不會(huì)那么的準(zhǔn)確
根據(jù)gradient norm分布的分析,GHM關(guān)注于不同樣本梯度貢獻(xiàn)的協(xié)調(diào)。大量由easy樣本產(chǎn)生的累積梯度可以被largely down-weighted并且outliers也可以被相對的down-weighted。最后,每種類型的樣本分布將會(huì)使平衡的訓(xùn)練會(huì)更加的穩(wěn)定和有效


1.3 PrIme Sample Attention (PISA)
PISA 方法和 Focal loss 和 GHM 出發(fā)點(diǎn)不一樣, Focal loss 和 GHM 是利用 loss 來度量樣本的難易分類程度,而本篇論文做者從mAP 出發(fā)來度量樣本的難易程度。
多標(biāo)簽圖像分類任務(wù)中圖片的標(biāo)簽不止一個(gè),因此評(píng)價(jià)不能用普通單標(biāo)簽圖像分類的標(biāo)準(zhǔn),即mean accuracy,該任務(wù)采用的是和信息檢索中類似的方法—mAP(mean Average Precision),雖然其字面意思和mean accuracy看起來差不多,但是計(jì)算方法要繁瑣得多。
該作者提出改論文的方法考慮了兩個(gè)方面:
樣本之間不該是相互獨(dú)立的或同等對待。基于區(qū)域的目標(biāo)檢測是從大量候選框中選取一小部分邊界框,以覆蓋圖像中的全部目標(biāo)。所以,不一樣樣本的選擇是相互競爭的,而不是獨(dú)立的。通常來講,檢測器更可取的作法是在確保全部感興趣的目標(biāo)都被充分覆蓋時(shí),在每一個(gè)目標(biāo)周圍的邊界框產(chǎn)生高分,而不是對全部正樣本產(chǎn)生高分。作者研究代表關(guān)注那些與gt目標(biāo)有最高IOU的樣本是實(shí)現(xiàn)這一目標(biāo)的有效方法。
目標(biāo)的分類和定位是有聯(lián)系的。定位目標(biāo)周圍的樣本很是重要,這一觀察具備深入的意義,即目標(biāo)的分類和定位密切相關(guān)。具體地,定位好的樣本須要具備高置信度好的分類。
PISA由兩個(gè)部分組成:
基于重要性的樣本重加權(quán)(ISR)
分類感知回歸損失(CARL)。
ISR(Importance-based Sample Reweighting)
ISR由正樣本重加權(quán)和負(fù)樣本重加權(quán)組成,分別表示為ISR-P和ISR-N。對于陽性樣本,我們采用IoU-HLR作為重要性度量;對于陰性樣本,我們采用Score-HLR。給定重要性度量,剩下的問題是如何將重要性映射到適當(dāng)?shù)膿p失權(quán)重。
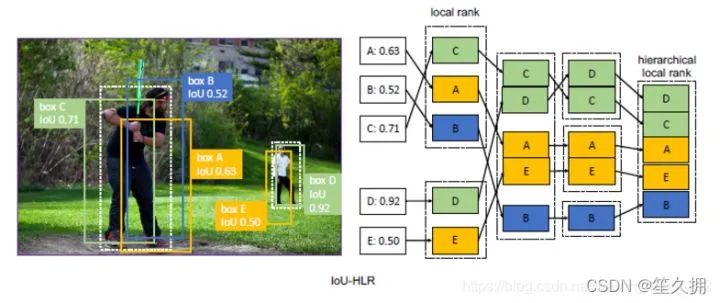
oU-HLR:
為了計(jì)算IoU-HLR,首先將所有樣本根據(jù)其最近的gt目標(biāo)劃分為不同的組。接下來,使用與gt的IoU降序?qū)γ總€(gè)組中的樣本進(jìn)行排序,并獲得IoU局部排名(IoU-LR)。隨后,以相同的IoU-LR采樣并按降序?qū)ζ溥M(jìn)行排序。具體來說,收集并分類所有top1 IoU-LR樣本,其次是top2,top3,依此類推。這兩個(gè)步驟將對所有樣本進(jìn)行排序
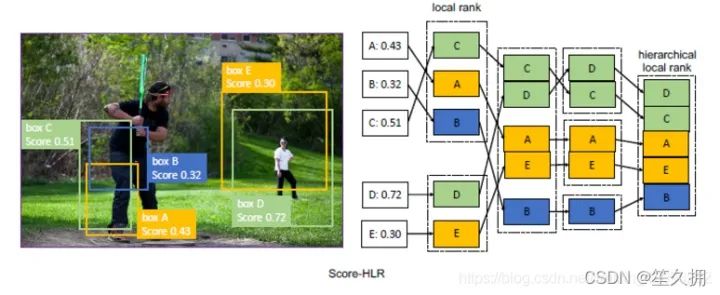
Score-HLR:
以類似于IoU-HLR的方式計(jì)算負(fù)樣本的Score-HLR。與由每個(gè)gt目標(biāo)自然分組的正樣本不同,負(fù)樣本也可能出現(xiàn)在背景區(qū)域,因此我們首先使用NMS將它們分組到不同的群集中。將所有前景類別中的最高分?jǐn)?shù)用作負(fù)樣本的得分,然后執(zhí)行與計(jì)算IoU-HLR相同的步驟。
如何解決訓(xùn)練數(shù)據(jù)樣本過少的問題
利用預(yù)訓(xùn)練模型進(jìn)行遷移微調(diào)(fine-tuning),預(yù)訓(xùn)練模型通常在特征上擁有很好的語義表達(dá)。此時(shí),只需將模型在小數(shù)據(jù)集上進(jìn)行微調(diào)就能取得不錯(cuò)的效果。這也是目前大部分小數(shù)據(jù)集常用的訓(xùn)練方式。視覺領(lǐng)域內(nèi),通常會(huì)ImageNet上訓(xùn)練完成的模型。自然語言處理領(lǐng)域,也有BERT模型等預(yù)訓(xùn)練模型可以使用。
單樣本或者少樣本學(xué)習(xí)(one-shot,few-shot learning),這種方式適用于樣本類別遠(yuǎn)遠(yuǎn)大于樣本數(shù)量的情況等極端數(shù)據(jù)集。例如有1000個(gè)類別,每個(gè)類別只提供1-5個(gè)樣本。少樣本學(xué)習(xí)同樣也需要借助預(yù)訓(xùn)練模型,但有別于微調(diào)的在于,微調(diào)通常仍然在學(xué)習(xí)不同類別的語義,而少樣本學(xué)習(xí)通常需要學(xué)習(xí)樣本之間的距離度量。例如孿生網(wǎng)絡(luò)(Siamese Neural Networks)就是通過訓(xùn)練兩個(gè)同種結(jié)構(gòu)的網(wǎng)絡(luò)來判別輸入的兩張圖片是否屬于同一類。3. 以上兩種是常用訓(xùn)練小樣本數(shù)據(jù)集的方式。此外,也有些常用的方式:數(shù)據(jù)集增強(qiáng)、正則或者半監(jiān)督學(xué)習(xí)等方式來解決小樣本數(shù)據(jù)集的訓(xùn)練問題。
如何解決類別不平衡的問題
機(jī)器學(xué)習(xí)中,解決樣本不均衡問題主要有2種思路:數(shù)據(jù)角度和算法角度。從數(shù)據(jù)角度出發(fā),有擴(kuò)大數(shù)據(jù)集、數(shù)據(jù)類別均衡采樣等方法。在算法層面,目標(biāo)檢測方法使用的方法主要有:
Faster RCNN、SSD等算法在正負(fù)樣本的篩選時(shí),根據(jù)樣本與真實(shí)物體的IoU大小,設(shè)置了3∶1的正負(fù)樣本比例,這一點(diǎn)緩解了正負(fù)樣本的不均衡,同時(shí)也對難易樣本不均衡起到了作用。
Faster RCNN在RPN模塊中,通過前景得分排序篩選出了2000個(gè)左右的候選框,這也會(huì)將大量的負(fù)樣本與簡單樣本過濾掉,緩解了前兩個(gè)不均衡問題。
權(quán)重懲罰:對于難易樣本與類別間的不均衡,可以增大難樣本與少類別的損失權(quán)重,從而增大模型對這些樣本的懲罰,緩解不均衡問題。
數(shù)據(jù)增強(qiáng):從數(shù)據(jù)側(cè)入手,可以在當(dāng)前數(shù)據(jù)集上使用隨機(jī)生成和添加擾動(dòng)的方法,也可以利用網(wǎng)絡(luò)爬蟲數(shù)據(jù)等增加數(shù)據(jù)集的豐富性,從而緩解難易樣本和類別間樣本等不均衡問題,可以參考SSD的數(shù)據(jù)增強(qiáng)方法。
近年來,不少的研究者針對樣本不均衡問題進(jìn)行了深入研究,比較典型的有OHEM(在線困難樣本挖掘)、S-OHEM、Focal Loss、GHM(梯度均衡化)。
-
OHEM:在線難例挖掘
OHEM算法(online hard example miniing,發(fā)表于2016年的CVPR)主要是針對訓(xùn)練過程中的困難樣本自動(dòng)選擇,其核心思想是根據(jù)輸入樣本的損失進(jìn)行篩選,篩選出困難樣本(即對分類和檢測影響較大的樣本),然后將篩選得到的這些樣本應(yīng)用在隨機(jī)梯度下降中訓(xùn)練。 -
Focal loss:專注難樣本
為了解決一階網(wǎng)絡(luò)中樣本的不均衡問題,何凱明等人首先改善了分類過程中的交叉熵函數(shù),提出了可以動(dòng)態(tài)調(diào)整權(quán)重的Focal Loss。 - GHM:損失函數(shù)梯度均衡化機(jī)制
前面講到的OHEM算法和Focal loss各有利弊:
1、OHEM算法會(huì)丟棄loss比較低的樣本,使得這些樣本無法被學(xué)習(xí)到。
2、FocalLoss則是對正負(fù)樣本進(jìn)行加權(quán),使得全部的樣本可以得到學(xué)習(xí),容易分類的負(fù)樣本賦予低權(quán)值,hard examples賦予高權(quán)值。但是在所有的anchor examples中,出了大量的易分類的負(fù)樣本外,還存在很多的outlier,F(xiàn)ocalLoss對這些outlier并沒有相關(guān)策略處理。并且FocalLoss存在兩個(gè)超參,根據(jù)不同的數(shù)據(jù)集,調(diào)試兩個(gè)超參需要大量的實(shí)驗(yàn),一旦確定參數(shù)無法改變,不能根據(jù)數(shù)據(jù)的分布動(dòng)態(tài)的調(diào)整。
GHM主要思想:GHM做法則是從樣本的梯度范數(shù)出發(fā),通過梯度范數(shù)所占的樣本比例,對樣本進(jìn)行動(dòng)態(tài)的加權(quán),使得具有小梯度的容易分類的樣本降權(quán),具有中梯度的hard expamle升權(quán),具有大梯度的outlier降權(quán)。
手撕代碼IOU
import numpy as np
def ComputeIOU(boxA, boxB):
## 計(jì)算相交框的坐標(biāo)
## bboxA[0][1] 左上角坐標(biāo) bboxA[2][3] 右下角坐標(biāo)
x1 = np.max([boxA[0], boxB[0]])
y1 = np.max([boxA[1], boxB[1]])
x2 = np.min([boxA[2], boxB[2]])
y2 = np.min([boxA[3], boxB[3]])
## 計(jì)算交區(qū)域,并區(qū)域,及IOU
S_A = (boxA[2]-boxA[0]+1)*(boxA[3]-boxA[1]+1)
S_B = (boxB[2]-boxB[0]+1)*(boxB[3]-boxB[1]+1)
interArea = np.max([x2-x1+1, 0])*np.max([y2-y1+1,0])##一定要和0比較大小,如果是負(fù)數(shù)就說明壓根不相交
unionArea = S_A + S_B - interArea
iou = interArea/unionArea
return iou
boxA = [1,1,3,3]
boxB = [2,2,4,4]
IOU = ComputeIOU(boxA, boxB)
手撕代碼NMS
對整個(gè)bboxes排序的寫法
import numpy as np
def nms(dets, iou_thred, cfd_thred):
if len(dets)==0: return []
bboxes = np.array(dets)
## 對整個(gè)bboxes排序
bboxes = bboxes[np.argsort(bboxes[:,4])]
pick_bboxes = []
# print(bboxes)
while bboxes.shape[0] and bboxes[-1,-1] >= cfd_thred:
bbox = bboxes[-1]
x1 = np.maximum(bbox[0], bboxes[:-1,0])
y1 = np.maximum(bbox[1], bboxes[:-1,1])
x2 = np.minimum(bbox[2], bboxes[:-1,2])
y2 = np.minimum(bbox[3], bboxes[:-1,3])
inters = np.maximum(x2-x1+1, 0) * np.maximum(y2-y1+1, 0)
unions = (bbox[2]-bbox[0]+1)*(bbox[3]-bbox[1]+1) + (bboxes[:-1,2]-bboxes[:-1,0]+1)*(bboxes[:-1,3]-bboxes[:-1,1]+1) - inters
ious = inters/unions
keep_indices = np.where(ious
- 不改變bboxes,維護(hù)orders的寫法
始終維護(hù)orders,代表到原bboxes的映射(map) 優(yōu)化1:僅維護(hù)orders,不改變原bboxes 優(yōu)化2:提前計(jì)算好bboxes的面積,以免在循環(huán)中多次重復(fù)計(jì)算
import numpy as np
def nms(dets, iou_thred, cfd_thred):
if len(dets)==0: return []
bboxes = np.array(dets)
## 維護(hù)orders
orders = np.argsort(bboxes[:,4])
pick_bboxes = []
x1 = bboxes[:,0]
y1 = bboxes[:,1]
x2 = bboxes[:,2]
y2 = bboxes[:,3]
areas = (x2-x1+1)*(y2-y1+1) ## 提前計(jì)算好bboxes面積,防止在循環(huán)中重復(fù)計(jì)算
while orders.shape[0] and bboxes[orders[-1],-1] >= cfd_thred:
bbox = bboxes[orders[-1]]
xx1 = np.maximum(bbox[0], x1[orders[:-1]])
yy1 = np.maximum(bbox[1], y1[orders[:-1]])
xx2 = np.minimum(bbox[2], x2[orders[:-1]])
yy2 = np.minimum(bbox[3], y2[orders[:-1]])
inters = np.maximum(xx2-xx1+1, 0) * np.maximum(yy2-yy1+1, 0)
unions = areas[orders[-1]] + areas[orders[:-1]] - inters
ious = inters/unions
keep_indices = np.where(ious
NMS的改進(jìn)思路
- 根據(jù)手動(dòng)設(shè)置閾值的缺陷,通過自適應(yīng)的方法在目標(biāo)系數(shù)時(shí)使用小閾值,目標(biāo)稠密時(shí)使用大閾值。例如Adaptive NMS
- 將低于閾值的直接置為0的做法太hard,通過將其根據(jù)IoU大小來進(jìn)行懲罰衰減,則變得更加soft。例如Soft NMS,Softer NMS。
- 只能在CPU上運(yùn)行,速度太慢的改進(jìn)思路有三個(gè),一個(gè)是設(shè)計(jì)在GPU上的NMS,如CUDA NMS,一個(gè)是設(shè)計(jì)更快的NMS,如Fast NMS,最后一個(gè)是掀桌子,設(shè)計(jì)一個(gè)神經(jīng)網(wǎng)絡(luò)來實(shí)現(xiàn)NMS,如 ConvNMS。
- IoU的做法存在一定缺陷,改進(jìn)思路是將目標(biāo)尺度、距離引進(jìn)IoU的考慮中。如DIoU
IOU相關(guān)優(yōu)化(giou,diou,ciou)
GIOU
普通IOU是對兩個(gè)框的距離不敏感的,下面兩張圖中,左圖預(yù)測框的坐標(biāo)要比右圖預(yù)測框的坐標(biāo)更接近真實(shí)框。但兩者的IOU皆為0,如果直接把IOU當(dāng)作loss函數(shù)進(jìn)行優(yōu)化,則loss=0,沒有梯度回傳,所以無法進(jìn)行訓(xùn)練。


但是,GIOU也存在它的缺點(diǎn):當(dāng)兩個(gè)預(yù)測框高寬相同,且處于同一水平面時(shí),GIOU就退化為IOU。此外,GIOU和IOU還有兩個(gè)缺點(diǎn):收斂較慢、回歸不夠準(zhǔn)確。
DIOU
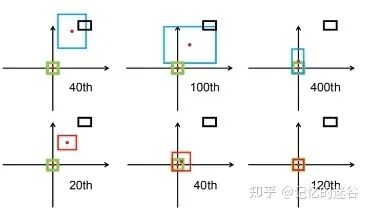
在介紹DIOU之前,先來介紹采用DIOU的效果:如圖,黑色代表anchor box, 藍(lán)色紅色代表default box,綠色代表真實(shí)目標(biāo)存在的框GT box的位置,期望紅藍(lán)框與綠框盡可能重合。第一行是使用GIOU訓(xùn)練網(wǎng)絡(luò),讓預(yù)測邊界框盡可能回歸到真實(shí)目標(biāo)邊界框中,迭代到400次后才勉強(qiáng)重合。第二行使用DIOU訓(xùn)練網(wǎng)絡(luò),到達(dá)120步時(shí),發(fā)現(xiàn)與目標(biāo)邊界框已經(jīng)完全重合。可以看出,相對于GIOU,DIOU的不僅收斂速度更快,準(zhǔn)確率也更高。
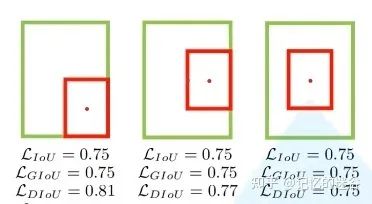
我們再看一組圖,圖中給出了3組目標(biāo)邊界框與目標(biāo)邊界框的重合關(guān)系,顯然他們的重合位置不相同的,我們期望第三種重合(兩個(gè)box中心位置盡可能重合。這三組計(jì)算的IOU loss和GIoU loss是一模一樣的,因此這兩種損失不能很好表達(dá)邊界框重合關(guān)系)。但是DIOU計(jì)算出的三種情況的損失是不一樣的,顯然DIOU更加合理。
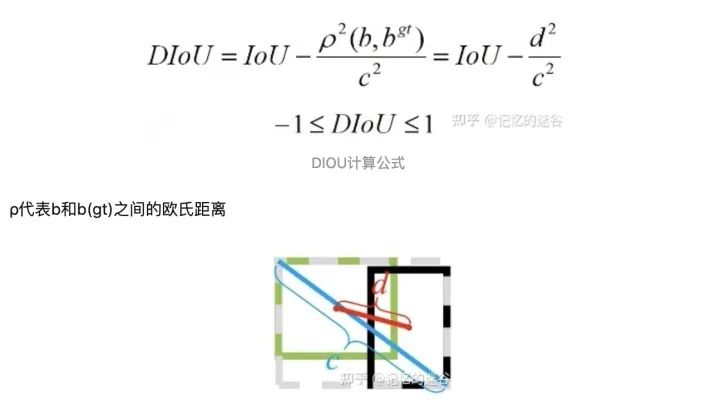
從公式和示意圖中,我們可以看到,DIoU有幾個(gè)優(yōu)點(diǎn):
DIoU的懲罰項(xiàng)是基于中心點(diǎn)的距離和對角線距離的比值,避免了像GIoU在兩框距離較遠(yuǎn)時(shí),產(chǎn)生較大的外包框,Loss值較大難以優(yōu)化(因?yàn)樗膽土P項(xiàng)是 A ∪ B 比上最小外包框的面積)。所以DIoU Loss收斂速度會(huì)比GIoU Loss快。
即使在一個(gè)框包含另一個(gè)框的情況下,c值不變,但d值也可以進(jìn)行有效度量。
CIOU LOSS:
論文中,作者表示一個(gè)優(yōu)秀的回歸定位損失應(yīng)該考慮三種幾何參數(shù):重疊面積、中心點(diǎn)距離、長寬比。CIoU就是在DIoU的基礎(chǔ)上增加了檢測框尺度的loss,增加了長和寬的loss,這樣預(yù)測框就會(huì)更加的符合真實(shí)框。

審核編輯 :李倩
-
算法
+關(guān)注
關(guān)注
23文章
4615瀏覽量
93000 -
檢測技術(shù)
+關(guān)注
關(guān)注
2文章
355瀏覽量
29088 -
目標(biāo)檢測
+關(guān)注
關(guān)注
0文章
209瀏覽量
15622
原文標(biāo)題:目錄
文章出處:【微信號(hào):vision263com,微信公眾號(hào):新機(jī)器視覺】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評(píng)論請先 登錄
相關(guān)推薦
有關(guān)VBA的一些編程總結(jié)
電力傳動(dòng)控制系統(tǒng)的基本組成和共性問題
C++面向?qū)ο箨P(guān)于MFC的一些簡單應(yīng)用和總結(jié)
一些關(guān)于iOS面試會(huì)問到的問題總結(jié)
C++的一些試題資料總結(jié)免費(fèi)下載

2019美西展一些總結(jié)分享
解析在目標(biāo)檢測中怎么解決小目標(biāo)的問題?
TensorFlow主題演講中涉及的一些更新總結(jié)
單片機(jī)學(xué)習(xí)之路一些常見的疑問也是我的個(gè)人學(xué)習(xí)總結(jié)

單片機(jī)學(xué)習(xí)之路一些常見的疑問也是我的個(gè)人學(xué)習(xí)總結(jié)
電路設(shè)計(jì)的一些經(jīng)驗(yàn)總結(jié)
多目標(biāo)跟蹤算法總結(jié)歸納





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論