 Kubernetes Operator最佳實踐介紹
Kubernetes Operator最佳實踐介紹
介紹
kubernetes operator是通過連接主API并watch時間的一組進程,一般會watch有限的資源類型。
當相關(所watch的)event觸發的時候,operator做出響應并執行具體的動作。這可能僅限于與主 API 交互,但通常會涉及在其他一些系統上執行某些操作(可以是集群中或集群外資源)。

Operators是控制器的集合,并且每個控制器watch了指定的資源類型。當被watched的資源時間觸發的時候,reconcile cycle(直譯:調諧循環,下文均使用reconcile cycle)也將隨之啟動。
在執行reconcile cycle期間,控制器有責任檢查當前狀態是否與被watched資源描述的期望狀態相匹配。有趣的是,根據設計,時間并不會傳遞到reconcile cycle中,這將會強制地讓你去考慮實例的整個狀態。這種方法被稱為基于水平觸發而不是基于邊緣觸發(level-based, as opposed to edge-based)。這源自于電子電路的設計,水平觸發是接收event(例如中斷)并對狀態做出反應的理念,而基于邊緣的觸發是接收event并對狀態變化做出反應的理念。
水平觸發雖說效率較低,因為它強制重新評估完整的狀態,而不是僅僅關注改變了什么,但在信號可能丟失或多次重復傳輸的復雜不可靠環境中,這種方式被認為是更適用的。
這種設計的選擇會影響我們編寫控制器代碼的方式。
與此討論相關的還有對 API 請求生命周期的理解。下圖提供了一個高層次的總結:
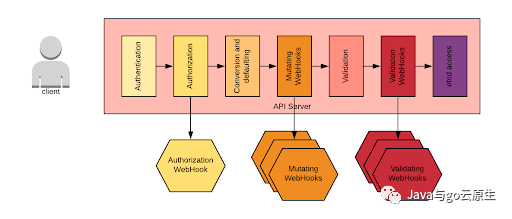
當向API服務器發送請求時,特別是對于創建和刪除請求,它們會經歷上圖所示的階段。需要注意的是,也可以指定webhook來執行請求的更改和驗證。如果operator引入了CRD(custom resource definition),我們可能還必須定義這些webhook。一般來說,operator進程會開放一個端口來來實現webhook endpoint。
本文介紹了一系列在使用Operator SDK來設計和開發Operator時需要牢記的最佳實踐。
如果你的operator引入了一個新的CRD,Operator SDK將會協助你來搭建。為確保您的 CRD 符合 Kubernetes 擴展 API 的最佳實踐,請遵循這些約定。
文中所提到的所有的最佳實踐都在operator-utils代碼庫中,并以可運行的例子體現。在你的operator項目中,也可以將operator-utils以library的方式導入,以此提供給你一些有用的工具。
最后,這組編寫operator的最佳實踐僅代表我的個人觀點,不應被視為Red Hat的官方最佳實踐。
創建 watches
正如我們所說,控制器watch著資源events。
watch是一種接收某種類型(核心類型或CRD)的機制。一般通過指定以下內容來創建watch機制:
想要watch的資源類型
handler。handler將被監視類型上的events映射到一個或多個調用協調周期的實例。監視類型和實例類型不必相同。
predicate。predicate是一組能夠過濾我們感興趣的events且可自定義的函數。
下圖記錄了以上提及的內容:
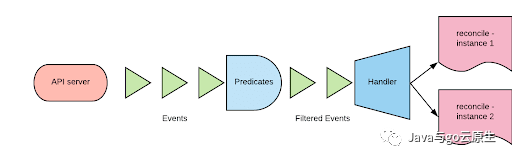
通常來說,同一類型(kind)開啟多個watch是可行的,因為watch是多路復用的。
你也應該盡可能多地嘗試過濾event。這邊有個predicate例子,用來過濾secret資源上的event。這里你只對類型為TLS的secret資源event感興趣:
isAnnotatedSecret:=predicate.Funcs{
UpdateFunc:func(eevent.UpdateEvent)bool{
oldSecret,ok:=e.ObjectOld.(*corev1.Secret)
if!ok{
returnfalse
}
newSecret,ok:=e.ObjectNew.(*corev1.Secret)
if!ok{
returnfalse
}
ifnewSecret.Type!=util.TLSSecret{
returnfalse
}
oldValue,_:=e.MetaOld.GetAnnotations()[certInfoAnnotation]
newValue,_:=e.MetaNew.GetAnnotations()[certInfoAnnotation]
old:=oldValue=="true"
new:=newValue=="true"
//ifthecontenthaschangedwetriggeriftheannotationisthere
if!reflect.DeepEqual(newSecret.Data[util.Cert],oldSecret.Data[util.Cert])||
!reflect.DeepEqual(newSecret.Data[util.CA],oldSecret.Data[util.CA]){
returnnew
}
//otherwisewetriggeriftheannotationhaschanged
returnold!=new
},
CreateFunc:func(eevent.CreateEvent)bool{
secret,ok:=e.Object.(*corev1.Secret)
if!ok{
returnfalse
}
ifsecret.Type!=util.TLSSecret{
returnfalse
}
value,_:=e.Meta.GetAnnotations()[certInfoAnnotation]
returnvalue=="true"
},
}
一個非常常見的模式是觀察我們創建(和我們擁有)資源上的events,并且定期在擁有這些資源的CR上執行reconcile cycle。為此,你可以使用EnqueueRequestForOwner handler,按照如下方式完成:
err=c.Watch(&source.Kind{Type:&examplev1alpha1.MyControlledType{}},&handler.EnqueueRequestForOwner{})
另一種不太常用的情況是將一個events傳播到多個資源上。考慮一種情況,一個控制器注入了TLS secret的路由。同一個命名空間中的多個路由可以指向同一個secret。如果secret發生了改變,我們需要更新所有路由。因此,我們需要在secret類型上創建一種watch機制,處理程序如下所示:
typeenqueueRequestForReferecingRoutesstruct{
client.Client
}
//triggerarouterreconcileeventforthoseroutesthatreferencethissecret
func(e*enqueueRequestForReferecingRoutes)Create(evtevent.CreateEvent,qworkqueue.RateLimitingInterface){
routes,_:=matchSecret(e.Client,types.NamespacedName{
Name:evt.Meta.GetName(),
Namespace:evt.Meta.GetNamespace(),
})
for_,route:=rangeroutes{
q.Add(reconcile.Request{NamespacedName:types.NamespacedName{
Namespace:route.GetNamespace(),
Name:route.GetName(),
}})
}
}
//UpdateimplementsEventHandler
//triggerarouterreconcileeventforthoseroutesthatreferencethissecret
func(e*enqueueRequestForReferecingRoutes)Update(evtevent.UpdateEvent,qworkqueue.RateLimitingInterface){
routes,_:=matchSecret(e.Client,types.NamespacedName{
Name:evt.MetaNew.GetName(),
Namespace:evt.MetaNew.GetNamespace(),
})
for_,route:=rangeroutes{
q.Add(reconcile.Request{NamespacedName:types.NamespacedName{
Namespace:route.GetNamespace(),
Name:route.GetName(),
}})
}
}
資源 Reconciliation Cycle
reconcile cycle是在被watch的event傳遞后框架將控制權轉交給我們地方。正如之前所解釋的,在該reconcile cycle中我們沒有獲得相關時間類型的信息,是因為我們是基于水平觸發的方式來工作。
下面是一個管理CRD控制器的常見reconcile cycle的模型。和其他任何一個模型一樣,它不會反映任何特定用例,但我希望它將有助于解決你在編寫operator時遇到的問題。
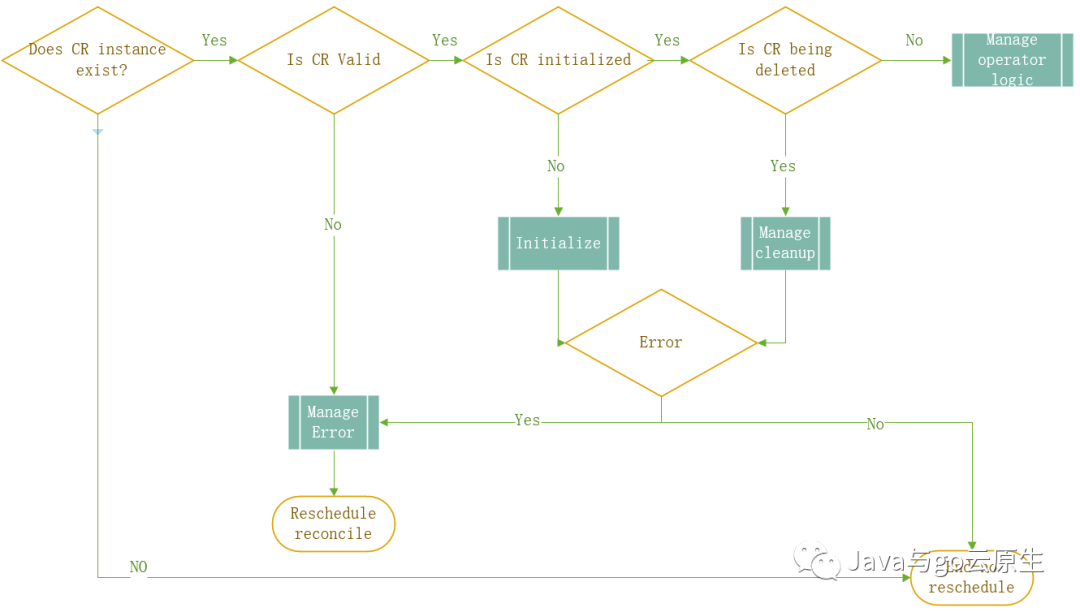
從圖中我們可以看到,主要步驟是:
檢索你感興趣的CR實例
確認實例的有效性。我們不會在不合法實例上做任何事情。
初始化實例。如果實例的某些值沒有被初始化,我們會在這一步進行處理。
判斷實例的deletion狀態。如果實例正在被刪除,我們也需要做一些特殊的清理。
管理控制器的業務邏輯。如果以上步驟均通過,我們最終可以管理和執行該實例的reconcile邏輯。這個邏輯每個控制器都不盡相同。
在本節的剩余部分,你可以找到有關每個步驟的更深入的注意事項。
資源驗證
這里存在兩種類型的校驗:語法校驗和語義校驗。
語法校驗:通過定義OpenAPI規則來驗證。
語義校驗:可以通過創建 ValidatingAdmissionConfiguration 來完成。
注意:在控制器中不能校驗CR合法性。一旦CR被APIServer接受了,它就會存在Etcd中。CR存在Etcd之后,管理該CR資源的控制器就無法拒絕它,如果這個CR是不合法的,控制器在嘗試使用或處理它的時候將會發生錯誤。
推薦:但是由于我們不能保證ValidatingAdmissionConfiguration被創建或正常工作,我們還是應該在控制器內部去驗證CR,如果CR不合法,應該避免創建無限錯誤循環。
語法校驗
可以按照這個鏈接的描述添加OpenAPI驗證規則
推薦:盡可能多地為你的自定義資源模型進行語法校驗。你應該盡量使用語法校驗,因為它相對簡單,并且可以防止格式錯誤的 CR 存儲在 etcd 中。
語義校驗
語義校驗是為了確保字段具有合理的值,從而使整個資源記錄是有意義的。語義驗證業務邏輯取決于 CR 所代表的概念,并且必須由operator的開發人員進行編碼實現。
如果給定的CR需要語義校驗,那么operator需要暴露一個webhook,作為operator deploymen的一部分,ValidatingAdmissionConfiguration也應該被創建。
以下是目前存在的局限性:
在OpenShift 3.11中,ValidatingAdmissionConfigurations還處于技術預覽階段(將從4.1開始支持)
Operator SDK不支持腳手架形式的webhook。可以使用kubebuilder來進行實現:
kubebuilderwebhook--groupcrew--versionv1--kindFirstMate--type=mutating--operations=create,update
驗證控制器中的資源
最好的方式是直接拒絕一個無效的CR,而不是接受并保存在Etcd中,然后對它進行錯誤條件處理。當然也有可能的情況是,ValidatingAdmissionConfiguration并沒有被部署或者根本不可用。所以我認為在控制器代碼中進行語義校驗仍然是一個很好的做法。你應該做到的是,可以在ValidatingAdmissionConfiguration和控制器之間共享這部分結構化的代碼。
控制器中調用驗證方法的代碼如下所示:
ifok,err:=r.IsValid(instance);!ok{
returnr.ManageError(instance,err)
}
請注意,如果驗證失敗,我們按照錯誤管理部分中的描述來管理這個錯誤。
IsValid函數如下:
func(r*ReconcileMyCRD)IsValid(objmetav1.Object)(bool,error){
mycrd,ok:=obj.(*examplev1alpha1.MyCRD)
//validationlogic
}
資源初始化
Kubernetes的一個很好的慣例是用戶只初始化他所需要的資源字段,其他的可以省略。以上是用戶的視點,但從編碼人員和調試者的角度來說,實際上最好將所有的字段都初始化。這允許在編碼的時候不必總是去校驗字段是否被定義了,并且可以輕松地排除錯誤情況。為了初始化資源,這里有兩個選項:
在控制器中定義初始化方法
定義一個 MutatingAdmissionConfiguration(類似于ValidatingAdmissionConfiguration的程序)
建議:在控制器中定義一個初始化方法。代碼應類似于此示例:
ifok:=r.IsInitialized(instance);!ok{
err:=r.GetClient().Update(context.TODO(),instance)
iferr!=nil{
log.Error(err,"unabletoupdateinstance","instance",instance)
returnr.ManageError(instance,err)
}
returnreconcile.Result{},nil
}
注意,如果IsInitialized方法的結果返回true,我們更新instance并return。這將會立即出發另一個reconcile cycle。第二次調用IsInitialized方法將會返回false,代碼邏輯將會執行到下一部分。
資源 Finalization
如果資源不屬于您的操作員控制的 CR,但在刪除該 CR 時需要采取措施,您必須使用finalizer。
終結器提供了一種機制來通知 Kubernetes 控制平面,在執行標準 Kubernetes 垃圾收集邏輯之前需要執行一個操作。
資源可以有一個或多個finalizers。每一個控制器應該管理自己的finalizer并且忽略其他的。
這是管理finalizers的偽代碼算法:
如果需要,在初始化方法中添加finalizer。
當資源被刪除,檢查此控制器擁有的finalizer是否存在。
清理成功,移除finalizer并更新CR
如果失敗決定是重試還是放棄并可能留下垃圾(在某些情況下這是可以接受的)
如果不存在,直接return
如果存在,執行如下清理邏輯:
如果你的清理邏輯需要添加額外的資源,需要記住的是,無法在正在刪除的命名空間中創建其他資源。刪除命名空間將會觸發finalizer并刪除其下所有資源。
看如下的代碼例子:
ifutil.IsBeingDeleted(instance){
if!util.HasFinalizer(instance,controllerName){
returnreconcile.Result{},nil
}
err:=r.manageCleanUpLogic(instance)
iferr!=nil{
log.Error(err,"unabletodeleteinstance","instance",instance)
returnr.ManageError(instance,err)
}
util.RemoveFinalizer(instance,controllerName)
err=r.GetClient().Update(context.TODO(),instance)
iferr!=nil{
log.Error(err,"unabletoupdateinstance","instance",instance)
returnr.ManageError(instance,err)
}
returnreconcile.Result{},nil
}
資源所有權
資源所有權是Kubernetes中的原生概念,它決定了資源如何被刪除。默認情況下,當一個資源被刪除的時候,它的子資源也也會被刪除(你可以設置cascade=false來關閉這種行為)
這種行為有助于確保資源的正確垃圾收集,尤其是當資源控制多級層次結構中的其他資源時(deployment-> repilcaset->pod)
建議:如果你的控制器創建資源并且它的生命周期與其他資源(kubernetes核心資源或其他CR)有關聯,那么您應該將此資源設置為其他資源的所有者,如下所示:
controllerutil.SetControllerReference(owner,obj,r.GetScheme())
有關所有權的其他規則如下:
父子資源必須位于同一命名空間中
命名空間資源可以擁有集群資源。但我們必須小心處理。一個對象可以有一個所有者列表。如果多個命名空間對象擁有相同的集群資源,則每個對象都應聲明所有權,而不會覆蓋其他對象的所有權
集群資源不能擁有命名空間資源
集群資源可以擁有另外一個集群資源
狀態管理
Status是資源的一個標準部分。Status被用于報告資源的狀態。在本文檔中,我們將使用 status 報告最后一次執行協調循環的結果。你也可以在Status中添加更多的信息。
在正常情況下,如果我們每次執行reconcile cycle的時候都要更新資源,這將觸發更新時間,進而導致無限觸發reconcile cycle。
因此,正如上面描述的那樣,我們應該把Status作為子資源。
使用這種方法,我們能夠不增加ResourceGeneration元數據域的情況下更新資源的狀態。使用如下命令更新狀態:
err=r.Status().Update(context.Background(),instance)
現在我們需要為我們的watch機制寫一個predicate(有關這些概念的更多詳細信息,請參閱有關watches的部分)用來丟棄不增加ResourceGeneration的更新事件。可以使用GenerationChangePredicate來完成此功能。
如果你還記得的話,上文提到過,在使用finalizer的時候,應該在初始化的時候設置。如果finalizer是初始化的唯一項,由于它是元數據項的一部分,所以ResourceGeneration不會遞增。為了說明該用例,以下是predicate的修改版本:
typeresourceGenerationOrFinalizerChangedPredicatestruct{ predicate.Funcs } //UpdateimplementsdefaultUpdateEventfilterforvalidatingresourceversionchange func(resourceGenerationOrFinalizerChangedPredicate)Update(eevent.UpdateEvent)bool{ ife.MetaNew.GetGeneration()==e.MetaOld.GetGeneration()&&reflect.DeepEqual(e.MetaNew.GetFinalizers(),e.MetaOld.GetFinalizers()){ returnfalse } returntrue }
現在假設你的status如下所示:
typeMyCRStatusstruct{
//+kubebuilderEnum=Success,Failure
Statusstring`json:"status,omitempty"`
LastUpdatemetav1.Time`json:"lastUpdate,omitempty"`
Reasonstring`json:"reason,omitempty"`
}
你可以寫一個函數來管理并保證reconcile cycle成功執行:
func(r*ReconcilerBase)ManageSuccess(objmetav1.Object)(reconcile.Result,error){
runtimeObj,ok:=(obj).(runtime.Object)
if!ok{
log.Error(errors.New("notaruntime.Object"),"passedobjectwasnotaruntime.Object","object",obj)
returnreconcile.Result{},nil
}
ifreconcileStatusAware,updateStatus:=(obj).(apis.ReconcileStatusAware);updateStatus{
status:=apis.ReconcileStatus{
LastUpdate:metav1.Now(),
Reason:"",
Status:"Success",
}
reconcileStatusAware.SetReconcileStatus(status)
err:=r.GetClient().Status().Update(context.Background(),runtimeObj)
iferr!=nil{
log.Error(err,"unabletoupdatestatus")
returnreconcile.Result{
RequeueAfter:time.Second,
Requeue:true,
},nil
}
}else{
log.Info("objectisnotRecocileStatusAware,notsettingstatus")
}
returnreconcile.Result{},nil
}
錯誤管理
如果控制器進入了一個錯誤條件,并且在reconcile方法中返回了一個錯誤。operator將會打印錯誤日志到標準輸出,reconlie event將會立即再次調度(默認的調度器實際上應該檢測是否一遍又一遍地出現相同的錯誤,并增加相應的調度時間,但在我的經驗看來,這并沒有發生)。如果錯誤一直存在,那么也將永遠存在錯誤循環。而且,這個錯誤條件對用戶來說是不可見的。
有兩種方法可以通知用戶發生了錯誤,它們可以同時使用:
在對象的status字段中返回錯誤
生成一個event描述錯誤
此外,如果你認為錯誤能夠自解決,你應該在一段周期時間后重新調度reconcile cycle。通常來說,周期時間是呈指數增長的,因此在每次迭代中,reconcile event周期會越來越長(例如每次增長時間量的兩倍)。
我們現在構建狀態管理來處理錯誤條件:
func(r*ReconcilerBase)ManageError(objmetav1.Object,issueerror)(reconcile.Result,error){
runtimeObj,ok:=(obj).(runtime.Object)
if!ok{
log.Error(errors.New("notaruntime.Object"),"passedobjectwasnotaruntime.Object","object",obj)
returnreconcile.Result{},nil
}
varretryIntervaltime.Duration
r.GetRecorder().Event(runtimeObj,"Warning","ProcessingError",issue.Error())
ifreconcileStatusAware,updateStatus:=(obj).(apis.ReconcileStatusAware);updateStatus{
lastUpdate:=reconcileStatusAware.GetReconcileStatus().LastUpdate.Time
lastStatus:=reconcileStatusAware.GetReconcileStatus().Status
status:=apis.ReconcileStatus{
LastUpdate:metav1.Now(),
Reason:issue.Error(),
Status:"Failure",
}
reconcileStatusAware.SetReconcileStatus(status)
err:=r.GetClient().Status().Update(context.Background(),runtimeObj)
iferr!=nil{
log.Error(err,"unabletoupdatestatus")
returnreconcile.Result{
RequeueAfter:time.Second,
Requeue:true,
},nil
}
iflastUpdate.IsZero()||lastStatus=="Success"{
retryInterval=time.Second
}else{
retryInterval=status.LastUpdate.Sub(lastUpdate).Round(time.Second)
}
}else{
log.Info("objectisnotRecocileStatusAware,notsettingstatus")
retryInterval=time.Second
}
returnreconcile.Result{
RequeueAfter:time.Duration(math.Min(float64(retryInterval.Nanoseconds()*2),float64(time.Hour.Nanoseconds()*6))),
Requeue:true,
},nil
}
注意,此函數會立即發送一個event,然后使用錯誤條件更新狀態。最后,計算何時重新安排下一次reconcile。該算法嘗試將每個循環的時間加倍,最多到六個小時為止。
六個小時是一個很好的上限時間,因為event大約持續6個小時,所以這應該確保始終有一個活動event描述當前的錯誤情況。
總結
本博客中介紹的實踐涉及Kubernetes Operator時最常見的問題,且讓你可以編寫一個有信心投入生產環境的operator。當然很有可能,這僅僅是一個開始,我們很容易預見將會有更多的框架和工具的出現來幫助你編寫operator。
審核編輯:劉清
-
控制器
+關注
關注
112文章
16332瀏覽量
177812 -
API接口
+關注
關注
1文章
84瀏覽量
10437 -
CRD
+關注
關注
0文章
14瀏覽量
4015 -
TLS
+關注
關注
0文章
44瀏覽量
4248
原文標題:Kubernetes Operator 最佳實踐
文章出處:【微信號:magedu-Linux,微信公眾號:馬哥Linux運維】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
leader選舉在kubernetes controller中是如何實現的
Kubernetes Ingress 高可靠部署最佳實踐
虛幻引擎的紋理最佳實踐
華為云在Kubernetes大規模場景下的Service性能優化實踐
阿里巴巴 Kubernetes 應用管理實踐中的經驗與教訓
教你們Kubernetes五層的安全的最佳實踐
最常用的11款Kubernetes工具
Kubernetes是什么,一文了解Kubernetes






 工商網監
工商網監
評論