 滑動窗口算法技巧
滑動窗口算法技巧
關于雙指針的快慢指針和左右指針的用法,可以參見前文 [雙指針技巧匯總],本文就解決一類最難掌握的雙指針技巧:滑動窗口技巧,并總結出一套框架,可以保你閉著眼直接套出答案。
說起滑動窗口算法,很多讀者都會頭疼。這個算法技巧的思路非常簡單,就是維護一個窗口,不斷滑動,然后更新答案么。LeetCode 上有起碼 10 道運用滑動窗口算法的題目,難度都是中等和困難。該算法的大致邏輯如下:
int left = 0, right = 0;
while (right < s.size()) {
// 增大窗口
window.add(s[right]);
right++;
while (window needs shrink) {
// 縮小窗口
window.remove(s[left]);
left++;
}
}
這個算法技巧的時間復雜度是 O(N),比一般的字符串暴力算法要高效得多。
其實困擾大家的,不是算法的思路,而是各種細節問題 。比如說如何向窗口中添加新元素,如何縮小窗口,在窗口滑動的哪個階段更新結果。即便你明白了這些細節,也容易出 bug,找 bug 還不知道怎么找,真的挺讓人心煩的。
所以今天我就寫一套滑動窗口算法的代碼框架,我連在哪里做輸出 debug 都給你寫好了,以后遇到相關的問題,你就默寫出來如下框架然后改三個地方就行,還不會出邊界問題 :
/* 滑動窗口算法框架 */
void slidingWindow(string s, string t) {
unordered_map<char, int> need, window;
for (char c : t) need[c]++;
int left = 0, right = 0;
int valid = 0;
while (right < s.size()) {
// c 是將移入窗口的字符
char c = s[right];
// 右移窗口
right++;
// 進行窗口內數據的一系列更新
...
/*** debug 輸出的位置 ***/
printf("window: [%d, %d)\\n", left, right);
/********************/
// 判斷左側窗口是否要收縮
while (window needs shrink) {
// d 是將移出窗口的字符
char d = s[left];
// 左移窗口
left++;
// 進行窗口內數據的一系列更新
...
}
}
}
其中兩處...表示的更新窗口數據的地方,到時候你直接往里面填就行了 。
而且,這兩個...處的操作分別是右移和左移窗口更新操作,等會你會發現它們操作是完全對稱的。
說句題外話,其實有很多人喜歡執著于表象,不喜歡探求問題的本質。 比如說有很多人評論我這個框架,說什么散列表速度慢,不如用數組代替散列表;還有很多人喜歡把代碼寫得特別短小,說我這樣代碼太多余,影響編譯速度,LeetCode 上速度不夠快。
我也是服了,算法看的是時間復雜度,你能確保自己的時間復雜度最優就行了。至于 LeetCode 所謂的運行速度,那個都是玄學,只要不是慢的離譜就沒啥問題,根本不值得你從編譯層面優化,不要舍本逐末……
labuladong 公眾號的重點在于算法思想,你把框架思維了然于心套出解法,然后隨你再魔改代碼好吧,你高興就好。
言歸正傳, 下面就直接上四道** LeetCode 原題來套這個框架** ,其中第一道題會詳細說明其原理,后面四道就直接閉眼睛秒殺了。
本文代碼為 C++ 實現,不會用到什么編程方面的奇技淫巧,但是還是簡單介紹一下一些用到的數據結構,以免有的讀者因為語言的細節問題阻礙對算法思想的理解:
unordered_map就是哈希表(字典),它的一個方法count(key)相當于 Java 的containsKey(key)可以判斷鍵 key 是否存在。
可以使用方括號訪問鍵對應的值map[key]。需要注意的是,如果該key不存在,C++ 會自動創建這個 key,并把map[key]賦值為 0。
所以代碼中多次出現的map[key]++相當于 Java 的map.put(key, map.getOrDefault(key, 0) + 1)。
一、最小覆蓋子串
LeetCode 76 題,Minimum Window Substring,難度 Hard ,我帶大家看看它到底有多 Hard :

就是說要在S(source) 中找到包含T(target) 中全部字母的一個子串,且這個子串一定是所有可能子串中最短的。
如果我們使用暴力解法,代碼大概是這樣的:
for (int i = 0; i < s.size(); i++)
for (int j = i + 1; j < s.size(); j++)
if s[i:j] 包含 t 的所有字母:
更新答案
思路很直接,但是顯然,這個算法的復雜度肯定大于 O(N^2) 了,不好。
滑動窗口算法的思路是這樣 :
***1、***我們在字符串S中使用雙指針中的左右指針技巧,初始化left = right = 0, 把索引左閉右開區間[left, right)稱為一個「窗口」 。
***2、***我們先不斷地增加right指針擴大窗口[left, right),直到窗口中的字符串符合要求(包含了T中的所有字符)。
3、 此時,我們停止增加right,轉而不斷增加left指針縮小窗口[left, right),直到窗口中的字符串不再符合要求(不包含T中的所有字符了)。同時,每次增加left,我們都要更新一輪結果。
***4、***重復第 2 和第 3 步,直到right到達字符串S的盡頭。
這個思路其實也不難, 第 2 步相當于在尋找一個「可行解」,然后第 3 步在優化這個「可行解」,最終找到最優解, 也就是最短的覆蓋子串。左右指針輪流前進,窗口大小增增減減,窗口不斷向右滑動,這就是「滑動窗口」這個名字的來歷。
下面畫圖理解一下,needs和window相當于計數器,分別記錄T中字符出現次數和「窗口」中的相應字符的出現次數。
初始狀態:
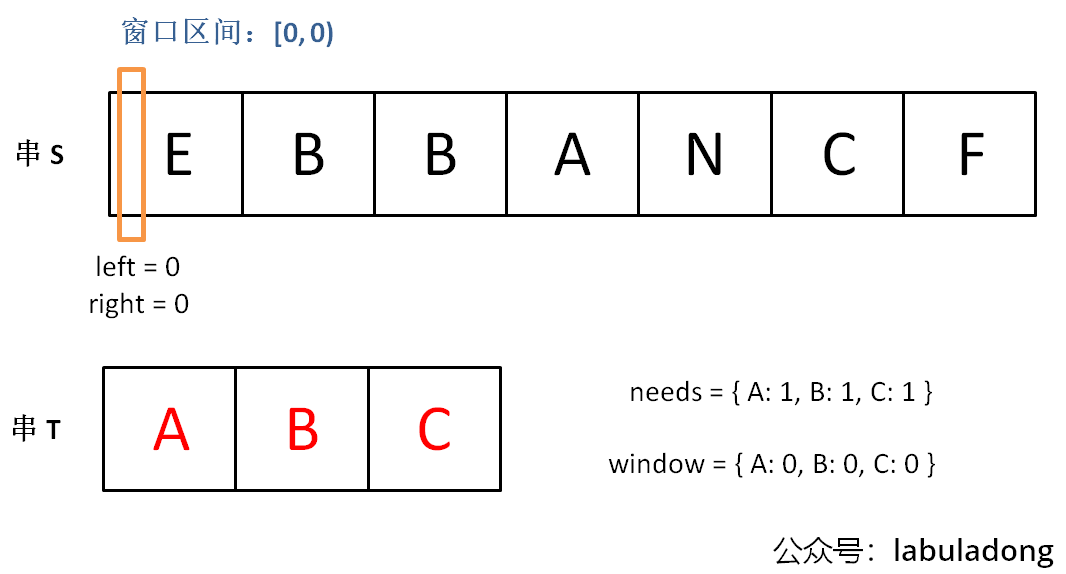
增加right,直到窗口[left, right)包含了T中所有字符:
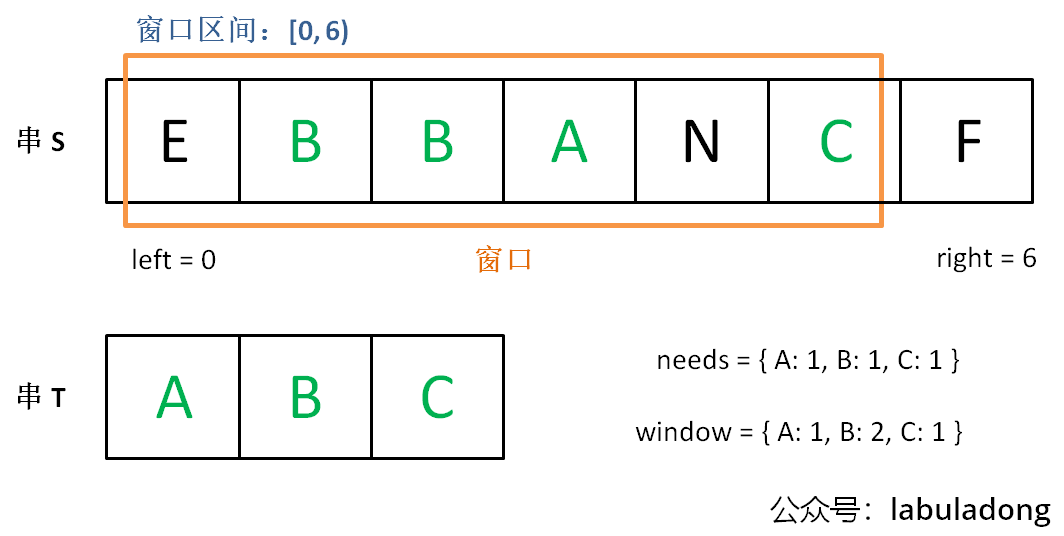
現在開始增加left,縮小窗口[left, right)。

直到窗口中的字符串不再符合要求,left不再繼續移動。

之后重復上述過程,先移動right,再移動left…… 直到right指針到達字符串S的末端,算法結束。
如果你能夠理解上述過程,恭喜,你已經完全掌握了滑動窗口算法思想。 現在我們來看看這個滑動窗口代碼框架怎么用 :
首先,初始化window和need兩個哈希表,記錄窗口中的字符和需要湊齊的字符:
unordered_map<char, int> need, window;
for (char c : t) need[c]++;
然后,使用left和right變量初始化窗口的兩端,不要忘了,區間[left, right)是左閉右開的,所以初始情況下窗口沒有包含任何元素:
int left = 0, right = 0;
int valid = 0;
while (right < s.size()) {
// 開始滑動
}
其中valid變量表示窗口中滿足need條件的字符個數 ,如果valid和need.size的大小相同,則說明窗口已滿足條件,已經完全覆蓋了串T。
現在開始套模板,只需要思考以下四個問題 :
1、 當移動right擴大窗口,即加入字符時,應該更新哪些數據?
2、 什么條件下,窗口應該暫停擴大,開始移動left縮小窗口?
3、 當移動left縮小窗口,即移出字符時,應該更新哪些數據?
4、 我們要的結果應該在擴大窗口時還是縮小窗口時進行更新?
如果一個字符進入窗口,應該增加window計數器;如果一個字符將移出窗口的時候,應該減少window計數器;當valid滿足need時應該收縮窗口;應該在收縮窗口的時候更新最終結果。
下面是完整代碼:
string minWindow(string s, string t) {
unordered_map<char, int> need, window;
for (char c : t) need[c]++;
int left = 0, right = 0;
int valid = 0;
// 記錄最小覆蓋子串的起始索引及長度
int start = 0, len = INT_MAX;
while (right < s.size()) {
// c 是將移入窗口的字符
char c = s[right];
// 右移窗口
right++;
// 進行窗口內數據的一系列更新
if (need.count(c)) {
window[c]++;
if (window[c] == need[c])
valid++;
}
// 判斷左側窗口是否要收縮
while (valid == need.size()) {
// 在這里更新最小覆蓋子串
if (right - left < len) {
start = left;
len = right - left;
}
// d 是將移出窗口的字符
char d = s[left];
// 左移窗口
left++;
// 進行窗口內數據的一系列更新
if (need.count(d)) {
if (window[d] == need[d])
valid--;
window[d]--;
}
}
}
// 返回最小覆蓋子串
return len == INT_MAX ?
"" : s.substr(start, len);
}
需要注意的是,當我們發現某個字符在window的數量滿足了need的需要,就要更新valid,表示有一個字符已經滿足要求。而且,你能發現,兩次對窗口內數據的更新操作是完全對稱的。
當valid == need.size()時,說明T中所有字符已經被覆蓋,已經得到一個可行的覆蓋子串,現在應該開始收縮窗口了,以便得到「最小覆蓋子串」。
移動left收縮窗口時,窗口內的字符都是可行解,所以應該在收縮窗口的階段進行最小覆蓋子串的更新,以便從可行解中找到長度最短的最終結果。
至此,應該可以完全理解這套框架了,滑動窗口算法又不難,就是細節問題讓人煩得很。 以后遇到滑動窗口算法,你就按照這框架寫代碼,保準沒有 bug,還省事兒 。
下面就直接利用這套框架秒殺幾道題吧,你基本上一眼就能看出思路了。
二、字符串排列
LeetCode 567 題,Permutation in String,難度 Medium:

注意哦,輸入的s1是可以包含重復字符的,所以這個題難度不小。
這種題目,是明顯的滑動窗口算法, 相當給你一個S和一個T,請問你S中是否存在一個子串,包含T中所有字符且不包含其他字符 ?
首先,先復制粘貼之前的算法框架代碼,然后明確剛才提出的 4 個問題,即可寫出這道題的答案:
// 判斷 s 中是否存在 t 的排列
bool checkInclusion(string t, string s) {
unordered_map<char, int> need, window;
for (char c : t) need[c]++;
int left = 0, right = 0;
int valid = 0;
while (right < s.size()) {
char c = s[right];
right++;
// 進行窗口內數據的一系列更新
if (need.count(c)) {
window[c]++;
if (window[c] == need[c])
valid++;
}
// 判斷左側窗口是否要收縮
while (right - left >= t.size()) {
// 在這里判斷是否找到了合法的子串
if (valid == need.size())
return true;
char d = s[left];
left++;
// 進行窗口內數據的一系列更新
if (need.count(d)) {
if (window[d] == need[d])
valid--;
window[d]--;
}
}
}
// 未找到符合條件的子串
return false;
}
對于這道題的解法代碼,基本上和最小覆蓋子串一模一樣,只需要改變兩個地方:
1、 本題移動left縮小窗口的時機是窗口大小大于t.size()時,因為排列嘛,顯然長度應該是一樣的。
2、 當發現valid == need.size()時,就說明窗口中就是一個合法的排列,所以立即返回true。
至于如何處理窗口的擴大和縮小,和最小覆蓋子串完全相同。
三、找所有字母異位詞
這是 LeetCode 第 438 題,Find All Anagrams in a String,難度 Medium:

呵呵,這個所謂的字母異位詞,不就是排列嗎,搞個高端的說法就能糊弄人了嗎? 相當于,輸入一個串S,一個串T,找到S中所有T的排列,返回它們的起始索引 。
直接默寫一下框架,明確剛才講的 4 個問題,即可秒殺這道題:
vector<int> findAnagrams(string s, string t) {
unordered_map<char, int> need, window;
for (char c : t) need[c]++;
int left = 0, right = 0;
int valid = 0;
vector<int> res; // 記錄結果
while (right < s.size()) {
char c = s[right];
right++;
// 進行窗口內數據的一系列更新
if (need.count(c)) {
window[c]++;
if (window[c] == need[c])
valid++;
}
// 判斷左側窗口是否要收縮
while (right - left >= t.size()) {
// 當窗口符合條件時,把起始索引加入 res
if (valid == need.size())
res.push_back(left);
char d = s[left];
left++;
// 進行窗口內數據的一系列更新
if (need.count(d)) {
if (window[d] == need[d])
valid--;
window[d]--;
}
}
}
return res;
}
跟尋找字符串的排列一樣,只是找到一個合法異位詞(排列)之后將起始索引加入res即可。
四、最長無重復子串
這是 LeetCode 第 3 題,Longest Substring Without Repeating Characters,難度 Medium:

這個題終于有了點新意,不是一套框架就出答案,不過反而更簡單了,稍微改一改框架就行了:
int lengthOfLongestSubstring(string s) {
unordered_map<char, int> window;
int left = 0, right = 0;
int res = 0; // 記錄結果
while (right < s.size()) {
char c = s[right];
right++;
// 進行窗口內數據的一系列更新
window[c]++;
// 判斷左側窗口是否要收縮
while (window[c] > 1) {
char d = s[left];
left++;
// 進行窗口內數據的一系列更新
window[d]--;
}
// 在這里更新答案
res = max(res, right - left);
}
return res;
}
這就是變簡單了,連need和valid都不需要,而且更新窗口內數據也只需要簡單的更新計數器window即可。
當window[c]值大于 1 時,說明窗口中存在重復字符,不符合條件,就該移動left縮小窗口了嘛。
唯一需要注意的是,在哪里更新結果res呢?我們要的是最長無重復子串,哪一個階段可以保證窗口中的字符串是沒有重復的呢?
這里和之前不一樣, 要在收縮窗口完成后更新res ,因為窗口收縮的 while 條件是存在重復元素,換句話說收縮完成后一定保證窗口中沒有重復嘛。
五、最后總結
建議背誦并默寫這套框架,順便背誦一下文章開頭的那首詩。以后就再也不怕子串、子數組問題了。
我覺得吧,能夠看到這的都是高手,要么就是在成為高手的路上。有了框架,任他窗口怎么滑,東哥這波車開得依然穩如老狗,「在看」安排一下。
-
算法
+關注
關注
23文章
4607瀏覽量
92835 -
滑動窗口法
+關注
關注
0文章
5瀏覽量
2150 -
leetcode
+關注
關注
0文章
20瀏覽量
2318
發布評論請先 登錄
相關推薦
TCP協議擁塞控制的滑動窗口協議解析
3*3窗口生成模塊,用于生成濾波的滑動窗口,得到窗口內的所有元素數據
采用嵌入式處理器PXA270與ARM-Linux相結合的Web服務器構建
滑動窗口。
基于C6000的滑動窗口圖像處理算法存儲優化
滑動DFT算法在功率譜估計中的應用
基于滑動窗口的多核程序數據競爭硬件檢測算法
快慢指針、左右指針的常見算法
基于MBNS滑動窗口的多標量乘快速算法
基于滑動窗口的寬度優先搜索算法

語音芯片在口算訓練儀的應用
關于go語言實現的幾種限流算法介紹
滑動窗口算法解決子串問題教程






 工商網監
工商網監
評論