

自從ChatGPT出現之后,各種大語言模型是徹底被解封了,每天見到的模型都能不重樣,幾乎分不清這些模型是哪個機構發(fā)布的、有什么功能特點、以及這些模型的關系。比如 GPT-3.0 和 GPT 3.5 就有一系列的模型版本和索引,還有羊駝、小羊駝、駱駝 ...... 于是淺淺的調研了一下比較有名的大語言模型,主要是想混個臉熟,整理完之后就感覺清晰多了,又可以輕松逛知乎學習了。
一、Basic Language Model 基礎語言模型是指只在大規(guī)模文本語料中進行了預訓練的模型,未經過指令和下游任務微調、以及人類反饋等任何對齊優(yōu)化。
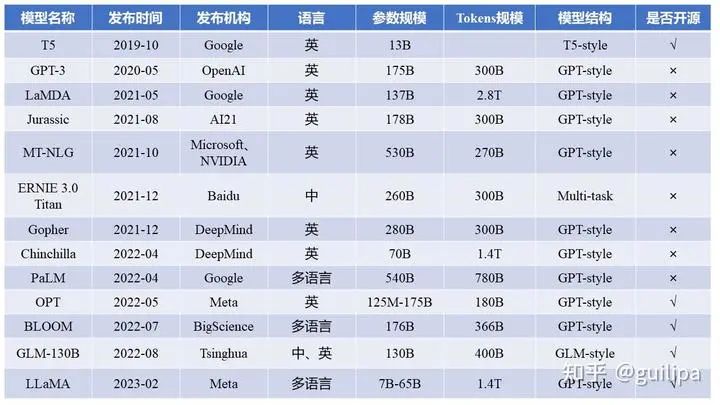
基礎 LLM 基本信息表,GPT-style 表示 decoder-only 的自回歸語言模型,T5-style 表示 encoder-decoder 的語言模型,GLM-style 表示 GLM 特殊的模型結構,Multi-task 是指 ERNIE 3.0 的模型結構
當前絕大部分的大語言模型都是 Decoder-only 的模型結構,原因請轉移這個問題:為什么現在的LLM都是Decoder only的架構[1];
大部分大語言模型都不開源,而 OPT、BLOOM、LLaMA 三個模型是主要面向開源促進研究和應用的,中文開源可用的是 GLM,后續(xù)很多工作都是在這些開源的基礎模型上進行微調優(yōu)化的。
T5T5 是谷歌提出了一個統一預訓練模型和框架,模型采用了谷歌最原始的 Encoder-Decoder Transformer結構。T5將每個文本處理問題都看成“Text-to-Text”問題,即將文本作為輸入,生成新的文本作為輸出。通過這種方式可以將不同的 NLP 任務統一在一個模型框架之下,充分進行遷移學習。 為了告知模型需要執(zhí)行的任務類型,在輸入的文本前添加任務特定的文本前綴 (task-specific prefifix ) 進行提示,這也就是最早的 Prompt。也就說可以用同樣的模型,同樣的損失函數,同樣的訓練過程,同樣的解碼過程來完成所有 NLP 任務。 T5 本身主要是針對英文訓練,谷歌還發(fā)布了支持 101 種語言的 T5 的多語言版本 mT5[3]。
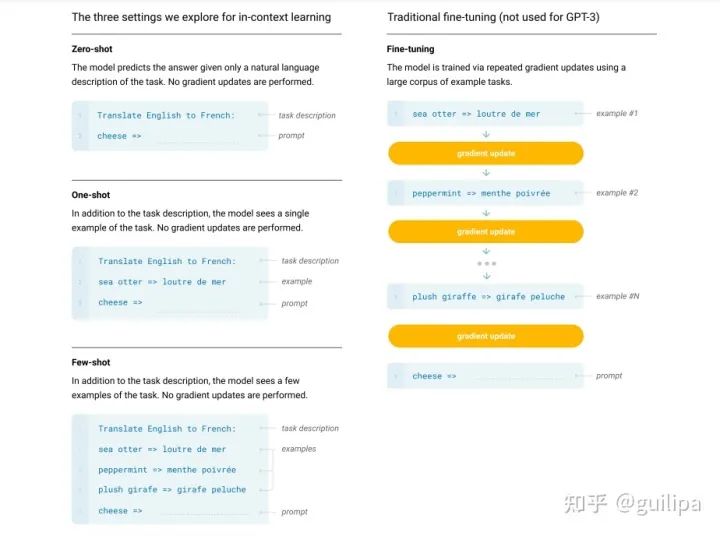
GPT-3大語言模型中最具代表和引領性的就是發(fā)布 ChatGPT 的 OpenAI 的 GPT 系列模型 (GPT-1、GPT-2、GPT-3、GPT-3.5、GPT-4),并且當前大部分大語言模型的結構都是 GPT-style ,文章生成式預訓練模型[5]中介紹了GPT-1/2/3, 且從 GPT-3 開始才是真正意義的大模型。 GPT-3 是 OpenAI 發(fā)布的 GPT 系列模型的一個,延續(xù)了 GPT-1/2 基于Transformer Decoder 的自回歸語言模型結構,但GPT-3 將模型參數規(guī)模擴大至 175B, 是 GPT-2 的 100 倍,從大規(guī)模數據中吸納更多的知識。 GPT-3不再追求 zero-shot 的設定,而是提出 In-Context Learning ,在下游任務中模型不需要任何額外的微調,利用 Prompts 給定少量標注的樣本讓模型學習再進行推理生成。就能夠在只有少量目標任務標注樣本的情況下進行很好的泛化,再次證明大力出擊奇跡,做大模型的必要性。 通過大量的實驗證明,在 zero-shot、one-shot 和 few-shot 設置下,GPT-3 在許多 NLP 任務和基準測試中表現出強大的性能,只有少量目標任務標注樣本的情況下進行很好的泛化,再次證明大力出擊奇跡,做大模型的必要性。
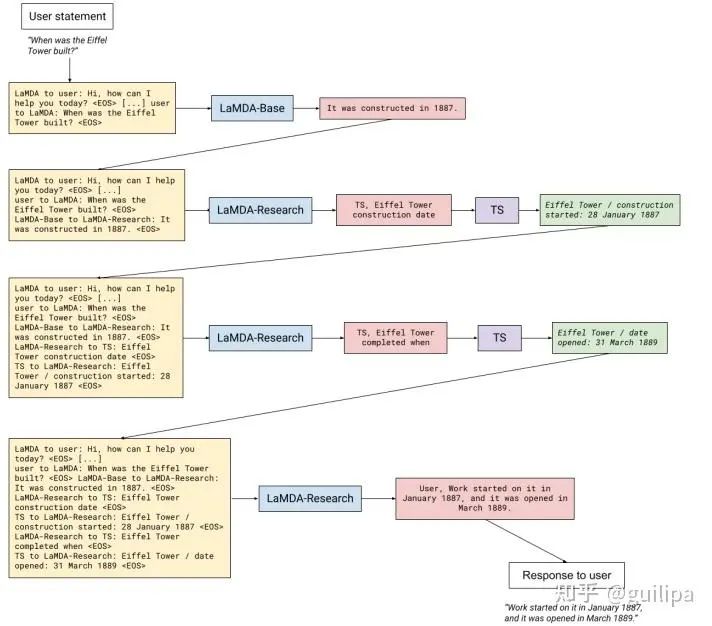
LaMDALaMDA 是谷歌在2021年開發(fā)者大會上公布的專用于對話的大語言模型,具有 137B 個參數。論文中提出三個指導模型更好訓練的指標:質量/Quality(合理性/Sensibleness、特異性/Specificity、趣味性/Interestingness,SSI)、安全性/Safety、真實性/Groundedness。 和其他大模型一樣,LaMDA分為預訓練和微調兩步,在微調階段,生成式任務(給定上下文生成響應)和判別式任務(評估模型生成響應的質量和安全性)應用于預訓練模型進行微調形成 LaMDA。對話期間,LaMDA 生成器在給定多輪對話上下文時生成幾個候選響應,然后 LaMDA 判別器預測每個候選響應的 SSI 和安全分數。安全分數低的候選響應首先被過濾掉,剩下的候選響應根據 SSI 分數重新排名,并選擇分數最高的作為最終響應。為提升 LaMDA 生成響應的真實可靠性,收集標注用戶與 LaMDA 間對話的數據集,并在適用的情況下使用檢索查詢和檢索結果進行注釋。然后,在這個數據集上微調 LaMDA,學習與用戶交互期間調用外部信息檢索系統,提升生成響應的真實可靠性。
Jurassic-1Jurassic-1 是以色列的 AI 公司 AI21 Labs 發(fā)布的一對自回歸語言模型,由 178B 參數模型 J1-Jumbo 和 7B 參數模型 J1-Large 組成,大致對應 GPT-3 175B 和 GPT-3 6.7B 兩個模型。 該模型主要對標 GPT-3,在數據補全、零樣本學習和少樣本學習方面對模型進行了評估,Jurassic-1 模型可以預測來自比 GPT-3 更廣泛的領域的文本(網絡、學術、法律、源代碼等),在零樣本條件中實現可比的性能,并且少樣本性能優(yōu)于 GPT-3,因為他們能夠將更多示例放入prompt中。MT-NLGMegatron-Turing NLG (MT-NLG) 是由 Microsoft 和 NVIDIA 共同研發(fā)的大語言模型,具有 530B 個參數,是 GPT-3 的三倍多,MT-NLG 在多個 benchmarks 中實現了非常好的零、一和少量樣本學習性能。 研究認為訓練如此大的語言模型有兩個挑戰(zhàn),
一是存儲高效性,將模型參數全部擬合到及時最大GPT的內存中已不再可能;
二是計算高效性,若不同時優(yōu)化算法、軟件和硬件堆棧,所需的大量計算操作可能會導致不切實際的長訓練時間;
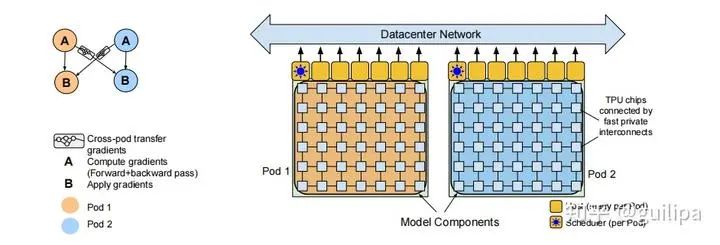
需要在內存和計算上都可擴展的高效并行技術,以充分發(fā)揮數千個 GPU 的潛力。對此,論文提出了結合了 DeepSpeed 的管道并行和數據并行性以及 Megatron 的張量切片并行的高效且可擴展的 3D 并行軟件系統。同時,還介紹了模型高效訓練的硬件基礎設施,提高訓練效率和穩(wěn)定性。GopherGopher 是 DeepMind 發(fā)布的大語言模型,擁有過 280B 規(guī)模的參數。在語言模型和開發(fā)過程中,DeepMind 訓練了 6 個不同參數規(guī)模的系列模型,參數量包括 44M、117M、417M、1.4B、7.1B、280B(Gopher)。這些模型在 152 項不同的任務上進行了評估,在大多數任務中都實現了最先進的性能。閱讀理解、事實核查和有毒語言識別等領域性能提升最大,但對于邏輯和數學推理等問題的性能提升較小。ChinchillaChinchilla(龍貓)是 DeepMind 發(fā)布的大語言模型,擁有 70B 的參數規(guī)模。Chinchilla 的研究主要關注在給定固定的 FLOPs 預算下,如何權衡模型規(guī)模大小和訓練tokens的數量規(guī)模的問題。 在 Chinchilla 之前的一系列大語言模型在擴展模型參數規(guī)模的同時保持訓練數據量不變,導致計算資源的浪費和大語言模型的訓練不足。對于計算成本最優(yōu)的訓練,模型規(guī)模大小和訓練 tokens 的數量應該同等比例地縮放,模型參數規(guī)模的加倍時,訓練 tokens 的數量也應該加倍。 基于上述假設訓練了計算優(yōu)化模型 Chinchilla,它與 Gopher 使用相同的計算預算,但具有 70B 的參數和 4 倍多的訓練數據。同時,Chinchilla 在大量下游評估任務上一致且顯著優(yōu)于 Gopher (280B)、GPT-3 (175B)、Jurassic-1 (178B) 和 Megatron-Turing NLG (530B)。Chinchilla 使用更少的計算來進行微調和推理,極大地促進了下游使用。PaLMPaLM 是谷歌2022年提出的 540B 參數規(guī)模的大語言模型,它采用的是 GPT-style 的 decoder-only 的單向自回歸模型結構,這種結構對于 few-shot 更有利。 PaLM 是使用谷歌提出的Pathways[12]系統(一種新的 ML 系統,可以跨多個 TPU Pod 進行高效訓練)在 6144 塊TPU v4 芯片上訓練完成的。 作者在 Pod 級別上跨兩個 Cloud TPU v4 Pods 使用數據并行對訓練進行擴展,與以前的大多數 LLM 相比,是一個顯著的規(guī)模增長。PaLM 實現了 57.8% 的硬件 FLOPs 利用率的訓練效率,是 LLM 在這個規(guī)模上實現的最高效率。PaLM 在數百種語言理解和生成 benchmarks 上實現最先進的few-shot 學習結果,證明了scaling 模型的好處。在其中的許多任務中,PaLM 540B 實現了突破性的性能,在一組多步推理任務上的表現優(yōu)于經過微調的 SOTA 模型。并且大量 BIG-bench 任務顯示了模型規(guī)模的擴大帶來性能的不連續(xù)提升,當模型擴展到最大規(guī)模,性能急劇提高。
U-PaLM由于擴大語言模型可以提高性能,但會帶來巨大的計算成本。谷歌提出 UL2R 方法,在幾乎可以忽略不計的額外計算成本和沒有新數據的情況下,使用原始的預訓練數據繼續(xù)訓練 PaLM 模型,能夠顯著改善大語言模型在下游指標上的擴展特性。 使用 UL2R 訓練 PaLM,引入了一組 8B、62B 和 540B 規(guī)模的新模型,稱為 U-PaLM。在 540B 規(guī)模下,實現了大約 2 倍的計算節(jié)省率,其中 U-PaLM 以大約一半的計算預算實現了與最終 PaLM 540B 模型相同的性能,并且在在許多小樣本條件上性能優(yōu)于 PaLM。 UL2[14]連接了生成語言模型和雙向語言模型,它提出了混合降噪器目標,在同一模型中混合前綴(非因果)語言建模和填充(跨度損壞),并利用模式提示(mode prompts)在下游任務期間切換模式。OPTOPT 是由 Meta AI 研究人員發(fā)布的一系列大規(guī)模預訓練語言模型,模型包括125M、350M、1.3B、2.7B、6.7B、13B、30B、66B、175B 9個不同的參數規(guī)模和版本,除了 175B 的版本需要填寫申請獲取外,其它規(guī)模版本的模型都完全開放下載,可以免費獲得。 OPT-175B 和 GPT-3 的性能相當,并且部署只需要損耗 GPT-3 1/7 的能量損耗。OPT 系列模型開源的目的是為促進學術研究和交流,因為絕大多數大語言模型訓練成本高昂,導致大部分研究人員都無法負擔大語言模型的訓練或使用;同時,各大企業(yè)發(fā)布的大語言預訓練模型由于商業(yè)目的也都無法完整訪問模型權重,只能通過 API 調用獲取結果,阻礙了學術的交流與研究。
Github:metaseq/projects/OPT at main · facebookresearch/metaseq[16];
GitHub - facebookresearch/metaseq: Repo for external large-scale work[17]
LLaMALLaMA 是 Meta AI 發(fā)布的包含 7B、13B、33B 和 65B 四種參數規(guī)模的基礎語言模型集合,LLaMA-13B 僅以 1/10 規(guī)模的參數在多數的 benchmarks 上性能優(yōu)于 GPT-3(175B),LLaMA-65B 與業(yè)內最好的模型 Chinchilla-70B 和 PaLM-540B 比較也具有競爭力。 這項工作重點關注使用比通常更多的 tokens 訓練一系列語言模型,在不同的推理預算下實現最佳的性能,也就是說在相對較小的模型上使用大規(guī)模數據集訓練并達到較好性能。Chinchilla 論文中推薦在 200B 的 tokens 上訓練 10B 規(guī)模的模型,而 LLaMA 使用了 1.4T tokens 訓練 7B的模型,增大 tokens 規(guī)模,模型的性能仍在持續(xù)上升。
Github:https://github.com/facebookresearch/llama[19]
BLOOMBLOOM 是 BigScience(一個圍繞研究和創(chuàng)建超大型語言模型的開放協作研討會)中數百名研究人員合作設計和構建的 176B 參數開源大語言模型,同時,還開源了BLOOM-560M、BLOOM-1.1B、BLOOM-1.7B、BLOOM-3B、BLOOM-7.1B 其他五個參數規(guī)模相對較小的模型。 BLOOM 是一種 decoder-only 的 Transformer 語言模型,它是在 ROOTS 語料庫上訓練的,該數據集包含 46 種自然語言和 13 種編程語言(總共 59 種)的數百個數據來源。實驗證明 BLOOM 在各種基準測試中都取得了有競爭力的表現,在經過多任務提示微調后取得了更好的結果。BLOOM 的研究旨在針對當前大多數 LLM 由資源豐富的組織開發(fā)并且不向公眾公開的問題,研制開源 LLM 以促進未來使用 LLM 的研究和應用。
Transformers:https://huggingface.co/bigscience[21]
GLM-130BGLM-130B 是清華大學與智譜AI共同研制的一個開放的雙語(英漢)雙向密集預訓練語言模型,擁有 1300億個參數,使用通用語言模型(General Language Model, GLM[23])的算法進行預訓練。 2022年11月,斯坦福大學大模型中心對全球30個主流大模型進行了全方位的評測,GLM-130B 是亞洲唯一入選的大模型。GLM-130B 在廣泛流行的英文基準測試中性能明顯優(yōu)于 GPT-3 175B(davinci),而對 OPT-175B 和 BLOOM-176B 沒有觀察到性能優(yōu)勢,它還在相關基準測試中性能始終顯著優(yōu)于最大的中文語言模型 ERNIE 3.0 Titan 260B。GLM-130B 無需后期訓練即可達到 INT4 量化,且?guī)缀鯖]有性能損失;更重要的是,它能夠在 4×RTX 3090 (24G) 或 8×RTX 2080 Ti (11G) GPU 上有效推理,是使用 100B 級模型最實惠的 GPU 需求。

GLM 預訓練方式:自回歸的空白填充,并通過 GLM 通過添加 2D 位置編碼和打亂片段順序來改進空白填充預訓練
Github:https://github.com/THUDM/GLM-130B[24]
ERNIE 3.0 TitanERNIE 3.0[26]是百度發(fā)布的知識增強的預訓練大模型,參數規(guī)模為 10B。ERNIE 實現了兼顧自然語言理解和自然語言生成的統一預訓練框架,使得經過訓練的模型可以通過零樣本學習、少樣本學習或微調輕松地針對自然語言理解和生成任務進行定制。
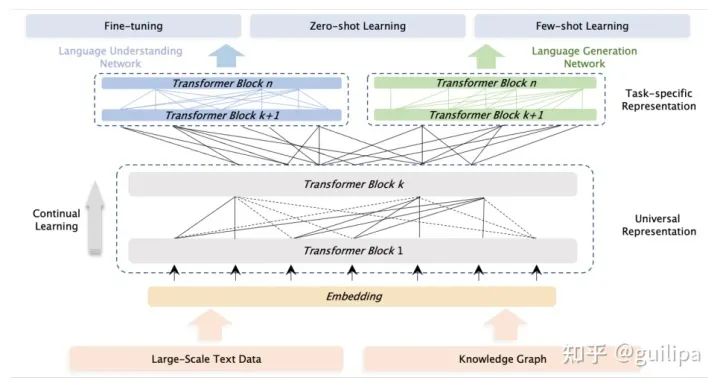
ERNIE 3.0 模型框架:模型包括統一表示模塊(Universal Representation Module) 和 兩個任務特定的表示模塊(Task-specific Representation Modules),即自然語言理解(NLU)表示模塊和自然語言生成表示模塊(NLG) ERNIE 3.0 Titan 是百度與鵬城實驗室發(fā)布的目前為止全球最大的中文單體模型,它是ERNIE 3.0的擴大和升級,模型參數規(guī)模達到 260B,相對GPT-3的參數量提升50%。 此外,在預訓練階段還設計了一個自監(jiān)督的對抗性損失和一個可控的語言建模損失,使 ERNIE 3.0 Titan 生成可信和可控的文本(Credible and Controllable Generations)。 為了減少計算開銷,ERNIE 3.0 Titan 提出了一個在線蒸餾框架,教師模型將同時教授學生模型和訓練自己以更高效地利用計算資源。ERNIE 3.0 Titan 在 68 個 NLP 數據集上的表現優(yōu)于最先進的模型。
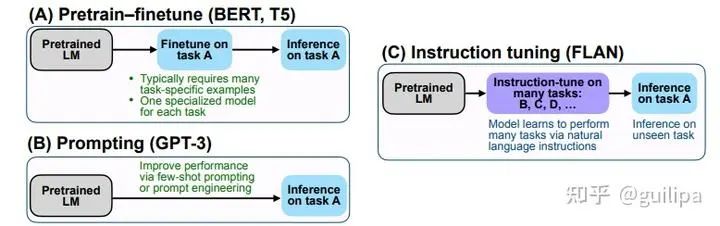
二、Instruction-Finetuned Language Model 這里的Instruction[27](指令)是指通過自然語言形式對任務進行描述。 如下圖所示,對于翻譯任務,在對需要翻譯的句子 "I Love You." 前加入任務指令 "Translate the given English utterance to French script." 告訴模型要執(zhí)行的任務和要求。這種方式符合模型生成的工作模型,最重要的是對于未知任務具有較好的 zero-shot 性能表現。通過將各種不同的任務轉化為指令數據形式,對語言模型進行進一步微調。
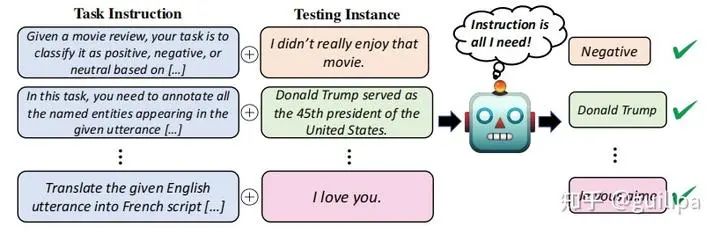
Instruction-tuning示例 下表為經過 Instruction 微調的大模型,他們幾乎都是在基礎語言模型基礎上進行指令微調、人類反饋、對齊等優(yōu)化操作。
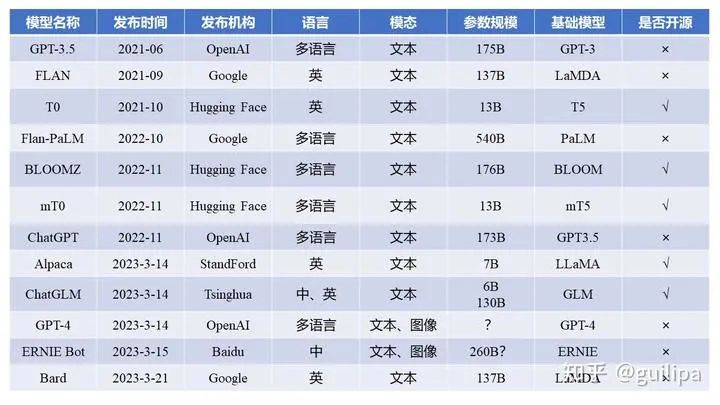
指令微調大模型基本信息
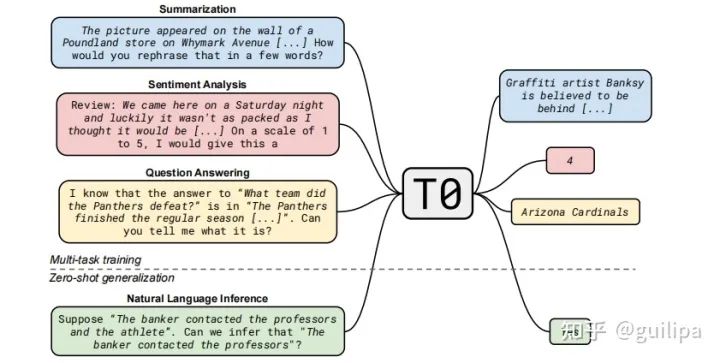
T0T0 是由 Hugging Face 牽頭聯合 42 位研究人員研發(fā)的一個基于 T5 模型在大規(guī)模多任務數據集上進行微調得到的模型。該研究的目的是在不需要大幅度擴大模型規(guī)模情況下引導模型更好地泛化到未知任務(zero-shot 性能),并且對 prompts 的措辭表達選擇與變化更加穩(wěn)健。 研究開發(fā)了一個可以將任何自然語言任務映射到人類可讀的 prompt 形式的系統, 并轉換了大量有監(jiān)督的數據集,每個數據集都有多個 prompt 和不同的措辭,在這個涵蓋各種任務的多任務數據上微調 encoder-decoder 結構的 T5 模型。T0 在多個標準數據集上 zero-shot 性能大幅度超越比其大 16 倍的 GPT-3 模型。
FLANFLAN 是谷歌在 LaMDA 137B 模型基礎上進行進一步的指令微調(Instruction tuning)得到的模型,通過指令微調提高語言模型在未知任務上的 zero-shot 性能和泛化能力。zero-shot 實驗中 FLAN 在評估的 25 個數據集中的 20 個上超過了 GPT-3 175B。FLAN 在 ANLI、RTE、BoolQ、AI2-ARC、OpenbookQA 和 StoryCloze 上的表現甚至大大優(yōu)于 few-shot GPT-3。論文的消融實現表明,微調數據集的數量、模型規(guī)模和自然語言指令是指令微調成功的關鍵。
Flan-LMFlan-LM 是谷歌在其已有的 T5、PaLM、U-PaLM 基礎模型基礎上利用指令 (Instruction) 數據集微調的一系列語言模型,包括 Flan-T5 (11B)、Flan-PaLM (540B)、Flan-U-PaLM (540B),在指令數據集上微調語言模型可以提高模型性能以及對未知任務的泛化能力。該工作主要通過擴大模型規(guī)模和微調任務數量來研究指令微調 scaling 的效果, 通過整合 Muffiffiffin(80 tasks)、T0-SF(193 tasks)、NIV2(1554 tasks)、CoT (9 tasks) 四個之前的工作將指令微調任務擴大到 1,836 個,同時對 CoT 數據進行微調提升模型的邏輯推理能力。實驗證明,指令微調可以顯著提高預訓練語言模型性能和可用性的通用方法,以及各種提示設置(零樣本、少樣本、CoT)和評估基準性能,例如,在 1.8K 任務上微調的 Flan-PaLM 540B 指令大大優(yōu)于 PaLM 540B(平均 +9.4%),并在多個基準測試中實現了最先進的性能。
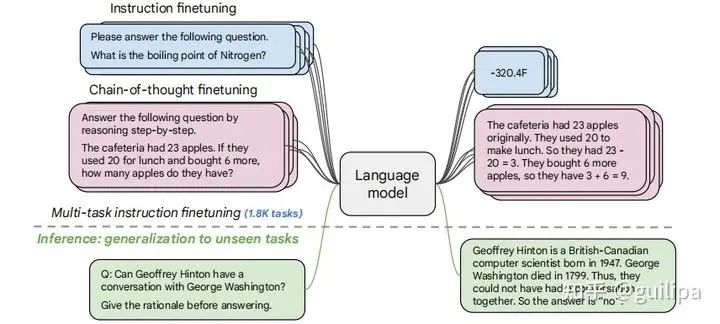
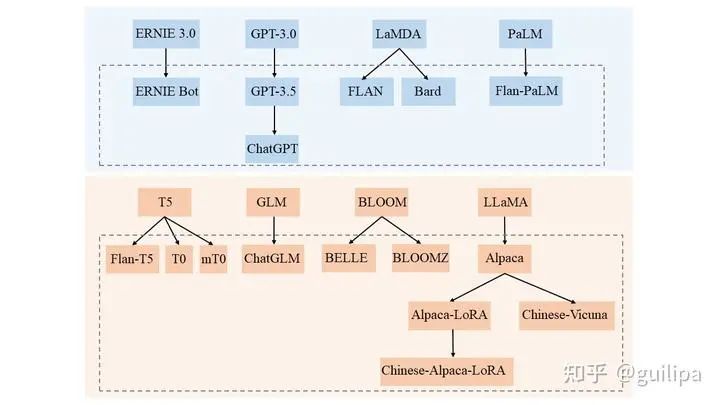
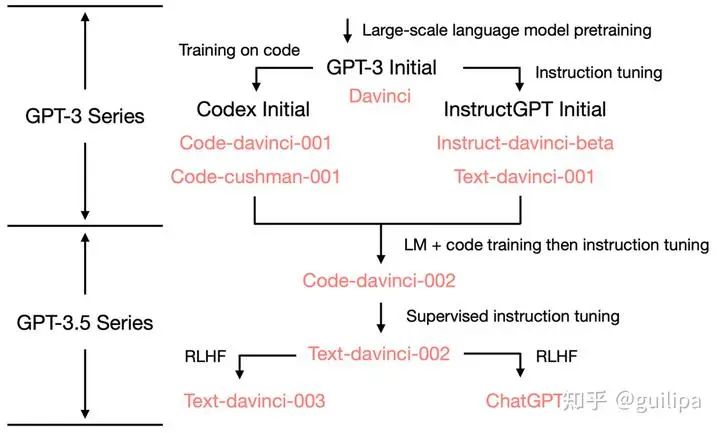
BLOOMZ &mT0上述 T0 和 FLAN 等指令微調模型證明了多任務提示微調 (MTF) 可以幫助大模型在 zero-shot 條件下泛化到新任務,并且對 MTF 的探索主要集中在英語數據和模型上。 Hugging Face將 MTF 應用于預訓練的多語言 BLOOM 和 mT5 模型系列,發(fā)布了稱為 BLOOMZ 和 mT0 的指令微調變體。研究實驗中發(fā)現在具有英語提示的英語任務上微調多語言大模型可以將任務泛化到僅出現在預訓練中的非英語任務;使用英語提示對多語言任務進行微調進一步提高了英語和非英語任務的性能,實現各種最先進的 zero-shot 結果;論文還研究了多語言任務的微調,這些任務使用從英語翻譯的提示來匹配每個數據集的語言,實驗發(fā)現翻譯的提示可以提高相應語言的人工提示的性能。實驗還發(fā)現模型能夠對它們從未見過的語言任務進行零樣本泛化,推測這些模型正在學習與任務和語言無關的更高級別的能力。GPT-3.5GPT-3.5 是從 GPT-3 演化來的一些列模型,如下圖所示,從初始的 GPT-3 到 GPT-3.5 再到 ChatGPT 是經過了一些列的優(yōu)化和演進。圖片來源:ChatGPT進化的秘密[33]和 拆解追溯 GPT-3.5 各項能力的起源[34],參考文章整理了以下 GPT-3.5 的演化過程。
2020年7月,發(fā)布GPT-3,最原始的 GPT-3 基礎模型主要有 davinci、curie、ada 和 babbage 四個不同版本,其中davinci 是功能最強大的,后續(xù)也都是基于它來優(yōu)化的;
2021年7月,發(fā)布Codex[35],在代碼數據上對 GPT-3 微調得到,對應著 code-davinci-001 和 code-cushman-001 兩個模型版本;
2021年3月,發(fā)布 InstructGPT[36]論文,對 GPT-3 進行指令微調 (supervised fine-tuning on human demonstrations) 得到davinci-instruct-beta1模型;在指令數據和經過標注人員評分反饋的模型生成樣例數據上進行微調得到text-davinci-001,InstructGPT 論文中的原始模型對應著davinci-instruct-beta;
2021年6月,發(fā)布 code-davinci-002,是功能最強大的 Codex 型號,在文本和代碼數據上進行訓練,特別擅長將自然語言翻譯成代碼和補全代碼;
2021年6月,發(fā)布 text-davinci-002,它是在code-davinci-002 基礎上進行有監(jiān)督指令微調得到;
2021年11月,發(fā)布 text-davinci-003 和 ChatGPT[37], 它們都是在 text-davinci-002 基礎上利用人類反饋強化學習 RLHF 進一步微調優(yōu)化得到。
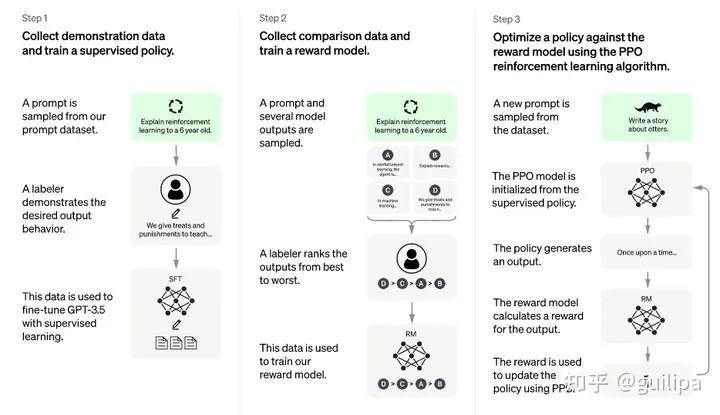
ChatGPTChatGPT 是在 GPT-3.5 基礎上進行微調得到的,微調時使用了從人類反饋中進行強化學習的方法(Reinforcement Learning from Human Feedback,RLHF)。這里的人類反饋其實就是人工標注數據,來不斷微調 LLM,主要目的是讓LLM學會理解人類的命令指令的含義(比如文生成類問題、知識回答類問題、頭腦風暴類問題等不同類型的命令),以及讓LLM學會判斷對于給定的prompt輸入指令(用戶的問題),什么樣的答案輸出是優(yōu)質的(富含信息、內容豐富、對用戶有幫助、無害、不包含歧視信息等多種標準)。 其實從 GPT-1到 GPT-3.5 可以發(fā)現更大的語言模型雖然有了更強的語言理解和生成的能力,但并不能從本質上使它們更好地遵循或理解用戶的指令意圖。例如,大型語言模型可能會生成不真實、有害或對用戶沒有幫助的輸出,原因在于這些語言模型預測下一個單詞的訓練目標與用戶目標意圖是不一致的。為了對齊語言模型于人類意圖,ChatGPT展示了一種途徑,可以引入人工標注和反饋,通過強化學習算法對大規(guī)模語言模型進行微調,在各種任務上使語言模型與用戶的意圖保持一致,輸出人類想要的內容。
GPT-4GPT-4 是 OpenAI 繼 ChatGPT 之后發(fā)布的一個大規(guī)模的多模態(tài)模型,之前的 GPT 系列模型都是只支持純文本輸入輸出的語言模型,而 GPT-4 可以接受圖像和文本作為輸入,并產生文本輸出。GPT-4 仍然是基于 Transformer 的自回歸結構的預訓練模型。OpenAI 的博客中表示在隨意的對話中,GPT-3.5 和 GPT-4 之間的區(qū)別可能很微妙,當任務的復雜性達到足夠的閾值時,差異就會出現,即 GPT-4 比 GPT-3.5 更可靠、更有創(chuàng)意,并且能夠處理更細微的指令。雖然在許多現實場景中的能力不如人類,但 GPT-4 在各種專業(yè)和學術基準測試中表現出人類水平的表現,包括通過模擬律師考試,得分在應試者的前 10% 左右。和 ChatGPT RLHF 的方法類似,alignment(對齊)訓練過程可以提高模型事實性和對期望行為遵循度的表現,具有強大的意圖理解能力,并且對 GPT-4 的安全性問題做了很大的優(yōu)化和提升。AlpacaAlpaca(羊駝)模型是斯坦福大學基于 Meta 開源的 LLaMA-7B 模型微調得到的指令遵循(instruction-following)的語言模型。在有學術預算限制情況下,訓練高質量的指令遵循模型主要面臨強大的預訓練語言模型和高質量的指令遵循數據兩個挑戰(zhàn),作者利用 OpenAI 的 text-davinci-003 模型以 self-instruct[41]方式生成 52K 的指令遵循樣本數據,利用這些數據訓練以有監(jiān)督的方式訓練 LLaMA-7B 得到 Alpaca 模型。在測試中,Alpaca 的很多行為表現都與 text-davinci-003 類似,且只有 7B 參數的輕量級模型 Alpaca 性能可與 GPT-3.5 這樣的超大規(guī)模語言模型性能媲美。

Alpaca訓練示意圖
博客:https://crfm.stanford.edu/2023/03/13/alpaca.html[42]
Github:https://github.com/tatsu-lab/stanford\_alpaca[43]
Alpaca-LoRA[44]使用 low-rank adaptation (LoRA)[45]重現 Alpaca 的結果,并且能夠以一塊消費級顯卡,在幾小時內完成 7B 模型的 fine-turning。 Alpaca 主要支持英文任務,因此許多工作在 Alpaca 基礎上進一步訓練其他語言的模型,比如,韓語羊 KoAlpaca[46],日語羊駝 Japanese-Alpaca-LoRA[47]。對于中文任務,國內開源了參考 Alpaca 訓練方式基于 LLaMA 的 Chinese-Vicuna (小羊駝)模型[48],以及 Luotuo(駱駝): Chinese-alpaca-lora[49]。

ChatGLMChatGLM 是清華大學知識工程(KEG)實驗室與其技術成果轉化的公司智譜AI基于此前開源的 GLM-130B[51]千億基座模型研制,是一個初具問答和對話功能的千億中英語言模型。ChatGLM 參考了 ChatGPT 的設計思路,在千億基座模型 GLM-130B 中注入了代碼預訓練,通過有監(jiān)督微調(Supervised Fine-Tuning)、反饋自助(Feedback Bootstrap)、人類反饋強化學習(Reinforcement Learning from Human Feedback) 等技術實現人類意圖對齊。 同時,開源了62 億參數的 ChatGLM-6B[52],結合模型量化技術,用戶可以在消費級的顯卡上進行本地部署(INT4 量化級別下最低只需 6GB 顯存),雖然規(guī)模不及千億模型,但大大降低了用戶部署的門檻,并且已經能生成相當符合人類偏好的回答。
博客地址:https://chatglm.cn/blog[53]
ERNIE BotERNIE Bot 就是百度的文心一言,基于 ERNIE 系列大模型構建的類 ChatGPT 的對話模型,具體細節(jié)不知道...BardBard 是谷歌基于 LaMDA 研制的對標 ChatGPT 的對話語言模型,目前應該只支持英文對話,限美國和英國用戶預約訪問,其他未知...
審核編輯 :李倩
-
模型
+關注
關注
1文章
3499瀏覽量
50047 -
語言模型
+關注
關注
0文章
558瀏覽量
10687 -
ChatGPT
+關注
關注
29文章
1588瀏覽量
8820
原文標題:總結從T5、GPT-3、Chinchilla、PaLM、LLaMA、Alpaca等近30個最新模型
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
【大語言模型:原理與工程實踐】揭開大語言模型的面紗
【大語言模型:原理與工程實踐】大語言模型的基礎技術
【大語言模型:原理與工程實踐】大語言模型的預訓練
【大語言模型:原理與工程實踐】大語言模型的評測
【大語言模型:原理與工程實踐】大語言模型的應用
大語言模型:原理與工程時間+小白初識大語言模型
FPGA加速器支撐ChatGPT類大語言模型創(chuàng)新





 工商網監(jiān)
工商網監(jiān)

評論