") 8種主流數(shù)據(jù)遷移工具技術(shù)選型
8種主流數(shù)據(jù)遷移工具技術(shù)選型
前言
最近有些小伙伴問(wèn)我,ETL數(shù)據(jù)遷移工具該用哪些。
ETL(是Extract-Transform-Load的縮寫,即數(shù)據(jù)抽取、轉(zhuǎn)換、裝載的過(guò)程),對(duì)于企業(yè)應(yīng)用來(lái)說(shuō),我們經(jīng)常會(huì)遇到各種數(shù)據(jù)的處理、轉(zhuǎn)換、遷移的場(chǎng)景。
今天特地給大家匯總了一些目前市面上比較常用的ETL數(shù)據(jù)遷移工具,希望對(duì)你會(huì)有所幫助。
1.Kettle
Kettle是一款國(guó)外開源的ETL工具,純Java編寫,綠色無(wú)需安裝,數(shù)據(jù)抽取高效穩(wěn)定 (數(shù)據(jù)遷移工具)。
Kettle 中有兩種腳本文件,transformation 和 job,transformation 完成針對(duì)數(shù)據(jù)的基礎(chǔ)轉(zhuǎn)換,job 則完成整個(gè)工作流的控制。
Kettle 中文名稱叫水壺,該項(xiàng)目的主程序員 MATT 希望把各種數(shù)據(jù)放到一個(gè)壺里,然后以一種指定的格式流出。
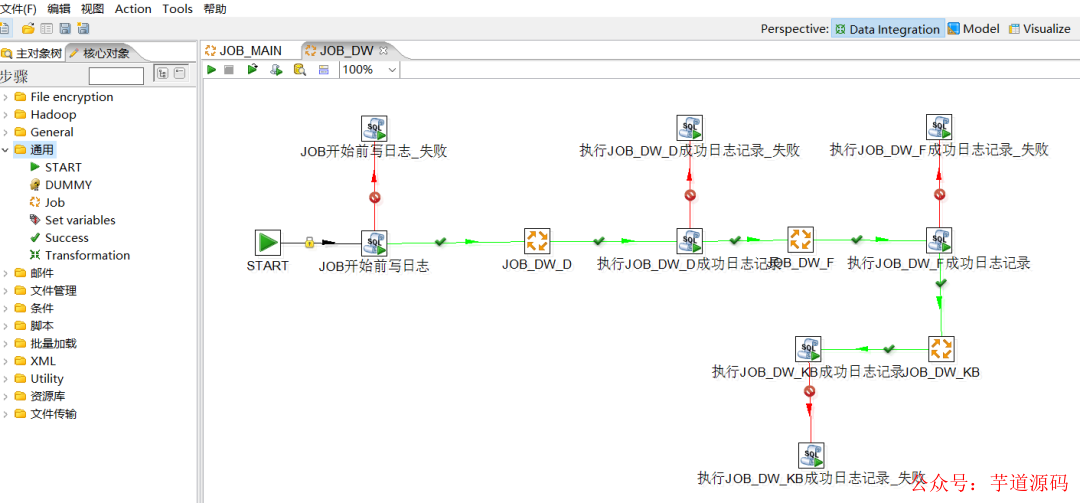
Kettle 這個(gè) ETL 工具集,它允許你管理來(lái)自不同數(shù)據(jù)庫(kù)的數(shù)據(jù),通過(guò)提供一個(gè)圖形化的用戶環(huán)境來(lái)描述你想做什么,而不是你想怎么做。
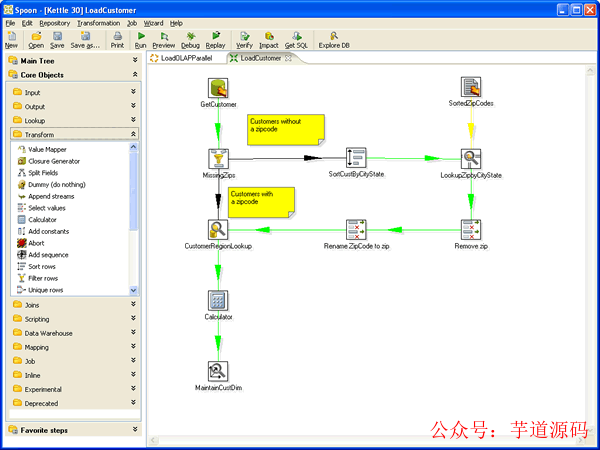
Kettle 家族目前包括 4 個(gè)產(chǎn)品:Spoon、Pan、CHEF、Kitchen。
SPOON:允許你通過(guò)圖形界面來(lái)設(shè)計(jì) ETL 轉(zhuǎn)換過(guò)程(Transformation)。
PAN:允許你批量運(yùn)行由 Spoon 設(shè)計(jì)的 ETL 轉(zhuǎn)換 (例如使用一個(gè)時(shí)間調(diào)度器)。Pan 是一個(gè)后臺(tái)執(zhí)行的程序,沒(méi)有圖形界面。
CHEF:允許你創(chuàng)建任務(wù)(Job)。任務(wù)通過(guò)允許每個(gè)轉(zhuǎn)換,任務(wù),腳本等等,更有利于自動(dòng)化更新數(shù)據(jù)倉(cāng)庫(kù)的復(fù)雜工作。任務(wù)通過(guò)允許每個(gè)轉(zhuǎn)換,任務(wù),腳本等等。任務(wù)將會(huì)被檢查,看看是否正確地運(yùn)行了。
KITCHEN:允許你批量使用由 Chef 設(shè)計(jì)的任務(wù) (例如使用一個(gè)時(shí)間調(diào)度器)。KITCHEN 也是一個(gè)后臺(tái)運(yùn)行的程序。
2.Datax
DataX是阿里云 DataWorks數(shù)據(jù)集成的開源版本,在阿里巴巴集團(tuán)內(nèi)被廣泛使用的離線數(shù)據(jù)同步工具/平臺(tái)。
DataX 是一個(gè)異構(gòu)數(shù)據(jù)源離線同步工具,致力于實(shí)現(xiàn)包括關(guān)系型數(shù)據(jù)庫(kù)(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各種異構(gòu)數(shù)據(jù)源之間穩(wěn)定高效的數(shù)據(jù)同步功能。
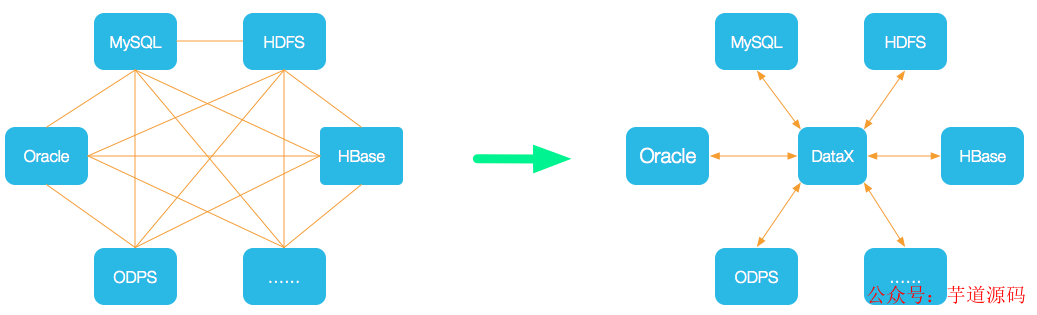
設(shè)計(jì)理念:為了解決異構(gòu)數(shù)據(jù)源同步問(wèn)題,DataX將復(fù)雜的網(wǎng)狀的同步鏈路變成了星型數(shù)據(jù)鏈路,DataX作為中間傳輸載體負(fù)責(zé)連接各種數(shù)據(jù)源。當(dāng)需要接入一個(gè)新的數(shù)據(jù)源的時(shí)候,只需要將此數(shù)據(jù)源對(duì)接到DataX,便能跟已有的數(shù)據(jù)源做到無(wú)縫數(shù)據(jù)同步。
當(dāng)前使用現(xiàn)狀:DataX在阿里巴巴集團(tuán)內(nèi)被廣泛使用,承擔(dān)了所有大數(shù)據(jù)的離線同步業(yè)務(wù),并已持續(xù)穩(wěn)定運(yùn)行了6年之久。目前每天完成同步8w多道作業(yè),每日傳輸數(shù)據(jù)量超過(guò)300TB。
DataX本身作為離線數(shù)據(jù)同步框架,采用Framework + plugin架構(gòu)構(gòu)建。將數(shù)據(jù)源讀取和寫入抽象成為Reader/Writer插件,納入到整個(gè)同步框架中。

DataX 3.0 開源版本支持單機(jī)多線程模式完成同步作業(yè)運(yùn)行,本小節(jié)按一個(gè)DataX作業(yè)生命周期的時(shí)序圖,從整體架構(gòu)設(shè)計(jì)非常簡(jiǎn)要說(shuō)明DataX各個(gè)模塊相互關(guān)系。
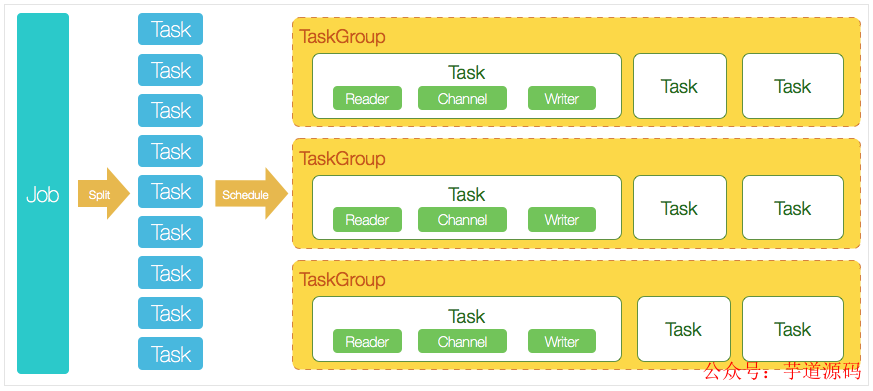
DataX 3.0六大核心優(yōu)勢(shì):
可靠的數(shù)據(jù)質(zhì)量監(jiān)控
豐富的數(shù)據(jù)轉(zhuǎn)換功能
精準(zhǔn)的速度控制
強(qiáng)勁的同步性能
健壯的容錯(cuò)機(jī)制
極簡(jiǎn)的使用體驗(yàn)
3.DataPipeline
DataPipeline采用基于日志的增量數(shù)據(jù)獲取技術(shù)( Log-based Change Data Capture ),支持異構(gòu)數(shù)據(jù)之間豐富、自動(dòng)化、準(zhǔn)確的語(yǔ)義映射構(gòu)建,同時(shí)滿足實(shí)時(shí)與批量的數(shù)據(jù)處理。
可實(shí)現(xiàn) Oracle、IBM DB2、MySQL、MS SQL Server、PostgreSQL、GoldenDB、TDSQL、OceanBase 等數(shù)據(jù)庫(kù)準(zhǔn)確的增量數(shù)據(jù)獲取。
平臺(tái)具備“數(shù)據(jù)全、傳輸快、強(qiáng)協(xié)同、更敏捷、極穩(wěn)定、易維護(hù)”六大特性。
在支持傳統(tǒng)關(guān)系型數(shù)據(jù)庫(kù)的基礎(chǔ)上,對(duì)大數(shù)據(jù)平臺(tái)、國(guó)產(chǎn)數(shù)據(jù)庫(kù)、云原生數(shù)據(jù)庫(kù)、API 及對(duì)象存儲(chǔ)也提供廣泛的支持,并在不斷擴(kuò)展。
DataPipeline 數(shù)據(jù)融合產(chǎn)品致力于為用戶提供企業(yè)級(jí)數(shù)據(jù)融合解決方案,為用戶提供統(tǒng)一平臺(tái)同時(shí)管理異構(gòu)數(shù)據(jù)節(jié)點(diǎn)實(shí)時(shí)同步與批量數(shù)據(jù)處理任務(wù),在未來(lái)還將提供對(duì)實(shí)時(shí)流計(jì)算的支持。
采用分布式集群化部署方式,可水平垂直線性擴(kuò)展的,保證數(shù)據(jù)流轉(zhuǎn)穩(wěn)定高效,讓客戶專注數(shù)據(jù)價(jià)值釋放。
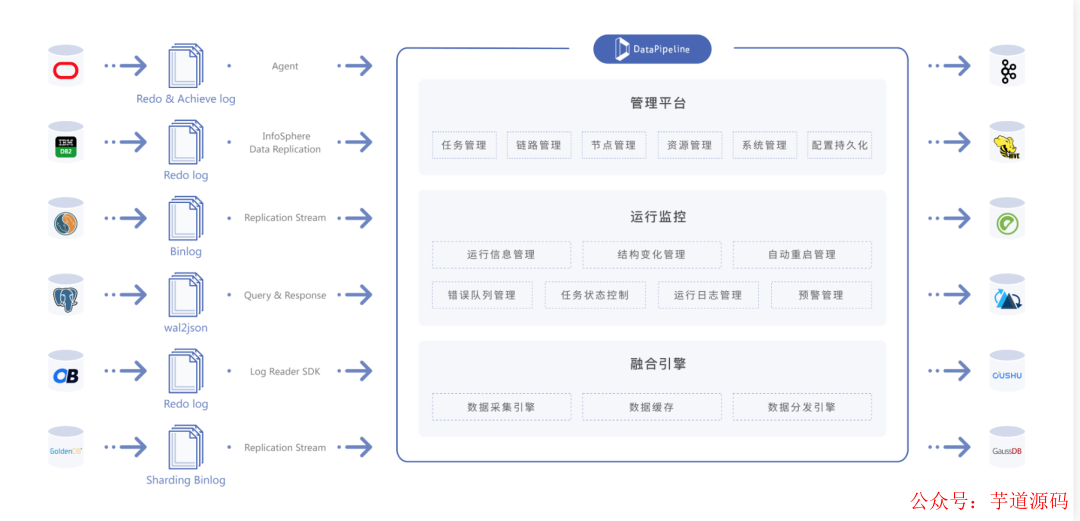
產(chǎn)品特點(diǎn):
全面的數(shù)據(jù)節(jié)點(diǎn)支持:支持關(guān)系型數(shù)據(jù)庫(kù)、NoSQL數(shù)據(jù)庫(kù)、國(guó)產(chǎn)數(shù)據(jù)庫(kù)、數(shù)據(jù)倉(cāng)庫(kù)、大數(shù)據(jù)平臺(tái)、云存儲(chǔ)、API等多種數(shù)據(jù)節(jié)點(diǎn)類型,可自定義數(shù)據(jù)節(jié)點(diǎn)。
高性能實(shí)時(shí)處理:針對(duì)不同數(shù)據(jù)節(jié)點(diǎn)類型提供TB級(jí)吞吐量、秒級(jí)低延遲的增量數(shù)據(jù)處理能力,加速企業(yè)各類場(chǎng)景的數(shù)據(jù)流轉(zhuǎn)。
分層管理降本增效:采用“數(shù)據(jù)節(jié)點(diǎn)注冊(cè)、數(shù)據(jù)鏈路配置、數(shù)據(jù)任務(wù)構(gòu)建、系統(tǒng)資源分配”的分層管理模式,企業(yè)級(jí)平臺(tái)的建設(shè)周期從三到六個(gè)月減少為一周。
無(wú)代碼敏捷管理:提供限制配置與策略配置兩大類十余種高級(jí)配置,包括靈活的數(shù)據(jù)對(duì)象映射關(guān)系,數(shù)據(jù)融合任務(wù)的研發(fā)交付時(shí)間從2周減少為5分鐘。
極穩(wěn)定高可靠:采用分布式架構(gòu),所有組件均支持高可用,提供豐富容錯(cuò)策略,應(yīng)對(duì)上下游的結(jié)構(gòu)變化、數(shù)據(jù)錯(cuò)誤、網(wǎng)絡(luò)故障等突發(fā)情況,可以保證系統(tǒng)業(yè)務(wù)連續(xù)性要求。
全鏈路數(shù)據(jù)可觀測(cè):配備容器、應(yīng)用、線程、業(yè)務(wù)四級(jí)監(jiān)控體系,全景駕駛艙守護(hù)任務(wù)穩(wěn)定運(yùn)行。自動(dòng)化運(yùn)維體系,靈活擴(kuò)縮容,合理管理和分配系統(tǒng)資源。
4.Talend
Talend (踏藍(lán)) 是第一家針對(duì)的數(shù)據(jù)集成工具市場(chǎng)的 ETL (數(shù)據(jù)的提取 Extract、傳輸 Transform、載入 Load) 開源軟件供應(yīng)商。
Talend 以它的技術(shù)和商業(yè)雙重模式為 ETL 服務(wù)提供了一個(gè)全新的遠(yuǎn)景。它打破了傳統(tǒng)的獨(dú)有封閉服務(wù),提供了一個(gè)針對(duì)所有規(guī)模的公司的公開的,創(chuàng)新的,強(qiáng)大的靈活的軟件解決方案。
5.DataStage
DataStage,即IBM WebSphere DataStage,是一套專門對(duì)多種操作數(shù)據(jù)源的數(shù)據(jù)抽取、轉(zhuǎn)換和維護(hù)過(guò)程進(jìn)行簡(jiǎn)化和自動(dòng)化,并將其輸入數(shù)據(jù)集市或數(shù)據(jù)倉(cāng)庫(kù)目標(biāo)數(shù)據(jù)庫(kù)的集成工具,可以從多個(gè)不同的業(yè)務(wù)系統(tǒng)中,從多個(gè)平臺(tái)的數(shù)據(jù)源中抽取數(shù)據(jù),完成轉(zhuǎn)換和清洗,裝載到各種系統(tǒng)里面。
其中每步都可以在圖形化工具里完成,同樣可以靈活地被外部系統(tǒng)調(diào)度,提供專門的設(shè)計(jì)工具來(lái)設(shè)計(jì)轉(zhuǎn)換規(guī)則和清洗規(guī)則等,實(shí)現(xiàn)了增量抽取、任務(wù)調(diào)度等多種復(fù)雜而實(shí)用的功能。其中簡(jiǎn)單的數(shù)據(jù)轉(zhuǎn)換可以通過(guò)在界面上拖拉操作和調(diào)用一些 DataStage 預(yù)定義轉(zhuǎn)換函數(shù)來(lái)實(shí)現(xiàn),復(fù)雜轉(zhuǎn)換可以通過(guò)編寫腳本或結(jié)合其他語(yǔ)言的擴(kuò)展來(lái)實(shí)現(xiàn),并且 DataStage 提供調(diào)試環(huán)境,可以極大提高開發(fā)和調(diào)試抽取、轉(zhuǎn)換程序的效率。
Datastage 操作界面
對(duì)元數(shù)據(jù)的支持:Datastage 是自己管理 Metadata,不依賴任何數(shù)據(jù)庫(kù)。
參數(shù)控制:Datastage 可以對(duì)每個(gè) job 設(shè)定參數(shù),并且可以 job 內(nèi)部引用這個(gè)參數(shù)名。
數(shù)據(jù)質(zhì)量:Datastage 有配套用的 ProfileStage 和 QualityStage 保證數(shù)據(jù)質(zhì)量。
定制開發(fā):提供抽取、轉(zhuǎn)換插件的定制,Datastage 內(nèi)嵌一種類 BASIC 語(yǔ)言,可以寫一段批處理程序來(lái)增加靈活性。
修改維護(hù):提供圖形化界面。這樣的好處是直觀、傻瓜式的;不好的地方就是改動(dòng)還是比較費(fèi)事(特別是批量化的修改)。
Datastage 包含四大部件:
Administrator:新建或者刪除項(xiàng)目,設(shè)置項(xiàng)目的公共屬性,比如權(quán)限。
Designer:連接到指定的項(xiàng)目上進(jìn)行 Job 的設(shè)計(jì);
Director:負(fù)責(zé) Job 的運(yùn)行,監(jiān)控等。例如設(shè)置設(shè)計(jì)好的 Job 的調(diào)度時(shí)間。
Manager:進(jìn)行 Job 的備份等 Job 的管理工作。
6.Sqoop
Sqoop 是 Cloudera 公司創(chuàng)造的一個(gè)數(shù)據(jù)同步工具,現(xiàn)在已經(jīng)完全開源了。
目前已經(jīng)是 hadoop 生態(tài)環(huán)境中數(shù)據(jù)遷移的首選 Sqoop 是一個(gè)用來(lái)將 Hadoop 和關(guān)系型數(shù)據(jù)庫(kù)中的數(shù)據(jù)相互轉(zhuǎn)移的工具,可以將一個(gè)關(guān)系型數(shù)據(jù)庫(kù)(例如 :MySQL ,Oracle ,Postgres 等)中的數(shù)據(jù)導(dǎo)入到 Hadoop 的 HDFS 中,也可以將 HDFS 的數(shù)據(jù)導(dǎo)入到關(guān)系型數(shù)據(jù)庫(kù)中。
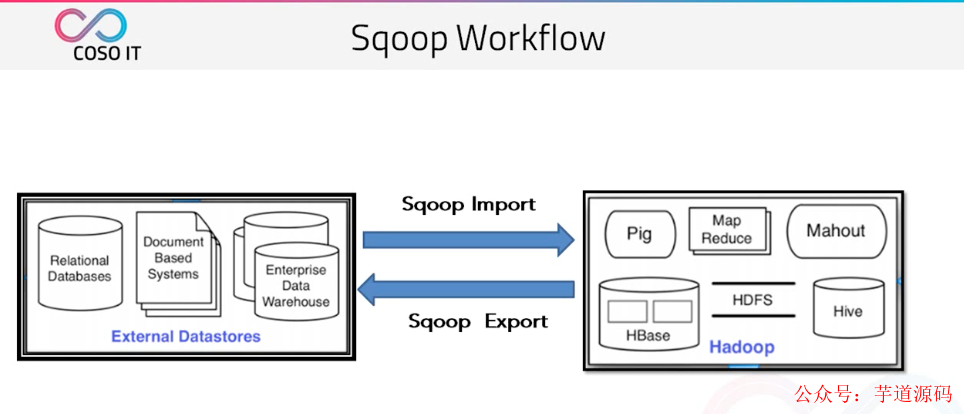
他將我們傳統(tǒng)的關(guān)系型數(shù)據(jù)庫(kù) | 文件型數(shù)據(jù)庫(kù) | 企業(yè)數(shù)據(jù)倉(cāng)庫(kù) 同步到我們的 hadoop 生態(tài)集群中。
同時(shí)也可以將 hadoop 生態(tài)集群中的數(shù)據(jù)導(dǎo)回到傳統(tǒng)的關(guān)系型數(shù)據(jù)庫(kù) | 文件型數(shù)據(jù)庫(kù) | 企業(yè)數(shù)據(jù)倉(cāng)庫(kù)中。
那么 Sqoop 如何抽取數(shù)據(jù)呢?
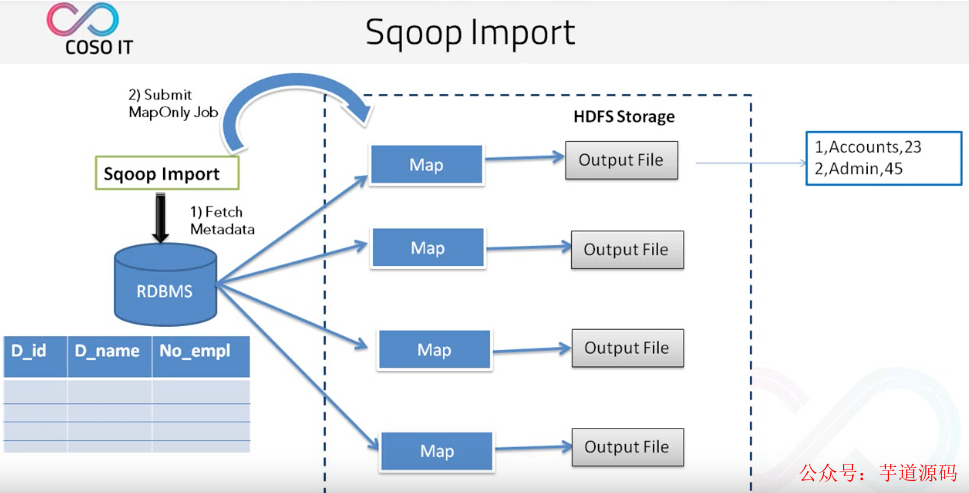
首先 Sqoop 去 rdbms 抽取元數(shù)據(jù)。
當(dāng)拿到元數(shù)據(jù)之后將任務(wù)切成多個(gè)任務(wù)分給多個(gè) map。
然后再由每個(gè) map 將自己的任務(wù)完成之后輸出到文件。
7.FineDataLink
FineDataLink是國(guó)內(nèi)做的比較好的ETL工具,F(xiàn)ineDataLink是一站式的數(shù)據(jù)處理平臺(tái),具備高效的數(shù)據(jù)同步功能,可以實(shí)現(xiàn)實(shí)時(shí)數(shù)據(jù)傳輸、數(shù)據(jù)調(diào)度、數(shù)據(jù)治理等各類復(fù)雜組合場(chǎng)景的能力,提供數(shù)據(jù)匯聚、研發(fā)、治理等功能。
FDL擁有低代碼優(yōu)勢(shì),通過(guò)簡(jiǎn)單的拖拽交互就能實(shí)現(xiàn)ETL全流程。
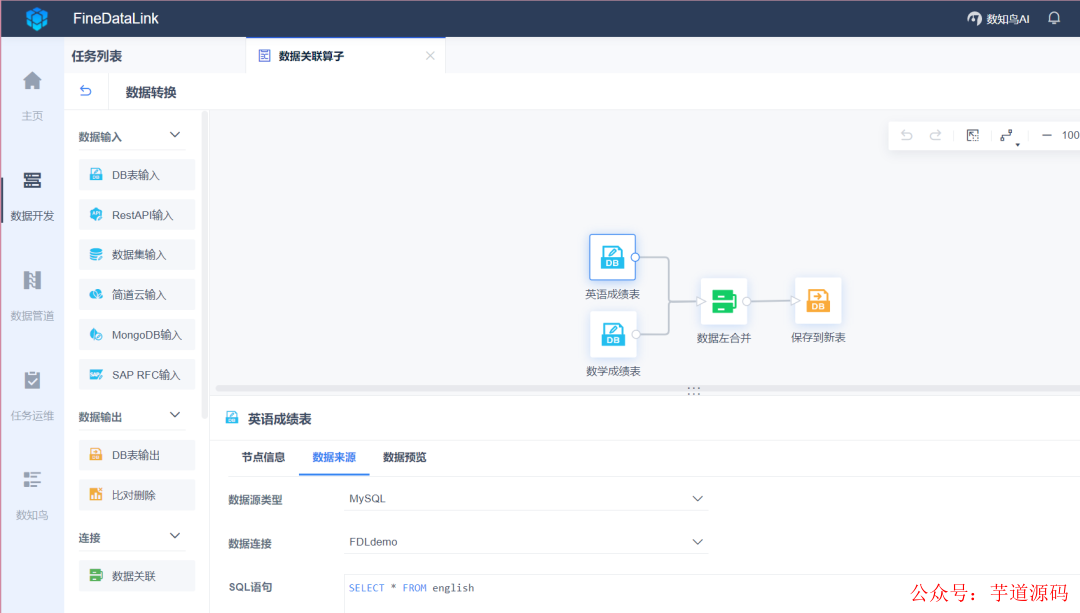
FineDataLink——中國(guó)領(lǐng)先的低代碼/高時(shí)效數(shù)據(jù)集成產(chǎn)品,能過(guò)為企業(yè)提供一站式的數(shù)據(jù)服務(wù),通過(guò)快速連接、高時(shí)效融合多種數(shù)據(jù),提供低代碼Data API敏捷發(fā)布平臺(tái),幫助企業(yè)解決數(shù)據(jù)孤島難題,有效提升企業(yè)數(shù)據(jù)價(jià)值。
8.canal
canal [k?'n?l],譯意為水道/管道/溝渠,主要用途是基于 MySQL 數(shù)據(jù)庫(kù)增量日志解析,提供增量數(shù)據(jù)訂閱和消費(fèi)。
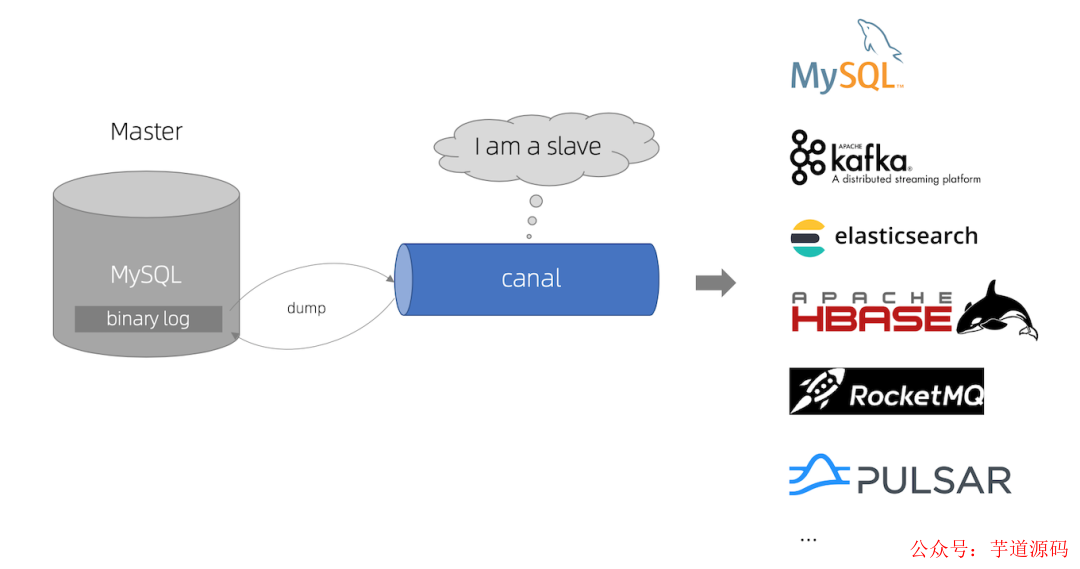
早期阿里巴巴因?yàn)楹贾莺兔绹?guó)雙機(jī)房部署,存在跨機(jī)房同步的業(yè)務(wù)需求,實(shí)現(xiàn)方式主要是基于業(yè)務(wù) trigger 獲取增量變更。從 2010 年開始,業(yè)務(wù)逐步嘗試數(shù)據(jù)庫(kù)日志解析獲取增量變更進(jìn)行同步,由此衍生出了大量的數(shù)據(jù)庫(kù)增量訂閱和消費(fèi)業(yè)務(wù)。
基于日志增量訂閱和消費(fèi)的業(yè)務(wù)包括:
數(shù)據(jù)庫(kù)鏡像
數(shù)據(jù)庫(kù)實(shí)時(shí)備份
索引構(gòu)建和實(shí)時(shí)維護(hù)(拆分異構(gòu)索引、倒排索引等)
業(yè)務(wù) cache 刷新
帶業(yè)務(wù)邏輯的增量數(shù)據(jù)處理
當(dāng)前的 canal 支持源端 MySQL 版本包括 5.1.x , 5.5.x , 5.6.x , 5.7.x , 8.0.x。
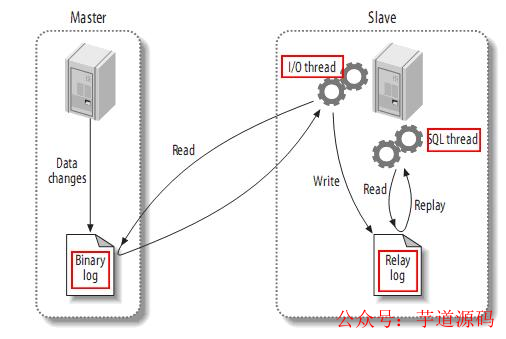
MySQL master 將數(shù)據(jù)變更寫入二進(jìn)制日志( binary log, 其中記錄叫做二進(jìn)制日志事件binary log events,可以通過(guò) show binlog events 進(jìn)行查看)。
MySQL slave 將 master 的 binary log events 拷貝到它的中繼日志(relay log)。
MySQL slave 重放 relay log 中事件,將數(shù)據(jù)變更反映它自己的數(shù)據(jù)。
canal 工作原理:
canal 模擬 MySQL slave 的交互協(xié)議,偽裝自己為 MySQL slave ,向 MySQL master 發(fā)送dump 協(xié)議
MySQL master 收到 dump 請(qǐng)求,開始推送 binary log 給 slave (即 canal )
canal 解析 binary log 對(duì)象(原始為 byte 流)
審核編輯:劉清
-
ETL
+關(guān)注
關(guān)注
0文章
21瀏覽量
9466 -
JAVA語(yǔ)言
+關(guān)注
關(guān)注
0文章
138瀏覽量
20274 -
HDFS
+關(guān)注
關(guān)注
1文章
30瀏覽量
9703 -
調(diào)度器
+關(guān)注
關(guān)注
0文章
98瀏覽量
5352
原文標(biāo)題:8 種主流數(shù)據(jù)遷移工具技術(shù)選型,yyds!
文章出處:【微信號(hào):芋道源碼,微信公眾號(hào):芋道源碼】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
hyper v遷移,hyper v遷移的教程,hyper-v批量管理工具的使用教程
HarmonyOS Next 應(yīng)用元服務(wù)開發(fā)-分布式數(shù)據(jù)對(duì)象遷移數(shù)據(jù)文件資產(chǎn)遷移
HarmonyOS Next 應(yīng)用元服務(wù)開發(fā)-分布式數(shù)據(jù)對(duì)象遷移數(shù)據(jù)權(quán)限與基礎(chǔ)數(shù)據(jù)
MySQL數(shù)據(jù)遷移的流程介紹
VCOP Kernel-C到C7000遷移工具用戶指南

emc數(shù)據(jù)遷移工具的使用指南
云計(jì)算遷移的步驟與注意事項(xiàng)
精準(zhǔn)選型,高效設(shè)計(jì) —— 賽盛LC濾波工具介紹

8位單片機(jī)選型五大要點(diǎn)你知多少?
將軟件從8位(字節(jié))可尋址CPU遷移至C28x CPU
米思米直線電機(jī)模組選型工具:如何引領(lǐng)設(shè)計(jì)效率的二次革命?
業(yè)界首個(gè)一云多芯遷移標(biāo)準(zhǔn) 中國(guó)信通院聯(lián)合浪潮云海發(fā)布






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論