 針對英特爾,博通、微軟、谷歌他們做了什么
針對英特爾,博通、微軟、谷歌他們做了什么
憑借其GPU的領先優勢,英偉達過去幾年炙手可熱,乘著ChatGPT熱潮,公司的市值從今年年初至今更是大漲了93.6%,過去五年的漲幅更是達到驚人的385%。雖然GPU是英偉達的最重要倚仗,但這絕不是美國芯片“當紅炸子雞”的唯一武器。
通過過去幾年的收購和自研,英偉達已經打造起了一個涵蓋DPU、CPU和Switch,甚至硅光在內的多產品線巨頭,其目的就是想在一個服務器甚至一個機架中做很多的生意。但和很多做GPGPU或者AI芯片的競爭對手想取替GPU一樣,英偉達的“取替”計劃似乎也不是不能一帆風順。
近日,三巨頭更是再次出手,想把英偉達拒之門外。
1/博通芯片,瞄準Infiniband
熟悉博通的讀者應該知道,面向Switch市場,美國芯片巨頭擁有三條高端產品線,分別是面向高帶寬需求的Tomahawk、面向更多功能的 Trident,以及雖然帶寬不高,但是卻擁有更深的Buffer和更高可編程性的Jericho。
昨日,他們帶來了Jericho系列最新的產品Jericho3-AI。在他們看來,這是比英偉達Infiniband更適合AI的一個新選擇。

據博通所說,大公司(甚至 NVIDIA) 都認為 AI 工作負載會受到網絡延遲和帶寬的限制,而Jericho3-AI 的存在則旨在減少 AI 訓練期間花在網絡上的時間。其結構的主要特性是負載平衡以保持鏈路不擁塞、結構調度、零影響故障轉移以及具有高以太網基數(radix)。
博通強調,AI 工作負載具有獨特的特征,例如少量的大型、長期流,所有這些都在 AI 計算周期完成后同時開始。Jericho3-AI 結構為這些工作負載提供最高性能,具有專為 AI 工作負載設計的獨特功能:
完美的負載均衡將流量均勻分布在結構的所有鏈路上,確保在最高網絡負載下實現最大網絡利用率。
端到端流量調度的無擁塞操作可確保無流量沖突和抖動。
超高基數獨特地允許 Jericho3-AI 結構將連接擴展到單個集群中的 32,000 個 GPU,每個 800Gbps。
零影響故障轉移功能可確保在 10 納秒內自動收斂路徑,從而不會影響作業完成時間。
利用這一獨特的功能,與 All-to-All 等關鍵 AI 基準測試的替代網絡解決方案相比,Jericho3-AI 結構的工作完成時間至少縮短了 10%。這種性能改進對降低運行 AI 工作負載的成本具有乘法效應,因為它意味著昂貴的 AI 加速器的使用效率提高了10%。此外,Jericho3-AI 結構提供每秒 26 PB 的以太網帶寬,幾乎是上一代帶寬的四倍,同時每千兆比特的功耗降低 40%。

此外,Broadcom 表示,因為它可以處理 800Gbps 的端口速度(對于 PCIe Gen6 服務器)等等,所以它是一個更好的選擇。對于將“AI”放在產品名稱中,Broadcom 并沒有做出過多解讀,甚至關于網絡 AI計算功能,他們也沒涉及,這著實讓人摸不著頭腦,因為這是英偉達Infiniband 架構的主要賣點。
盡管如此,Broadcom 表示其 Jericho3-AI 以太網在 NCCL 性能方面比 NVIDIA 的 Infiniband 好大約 10%。
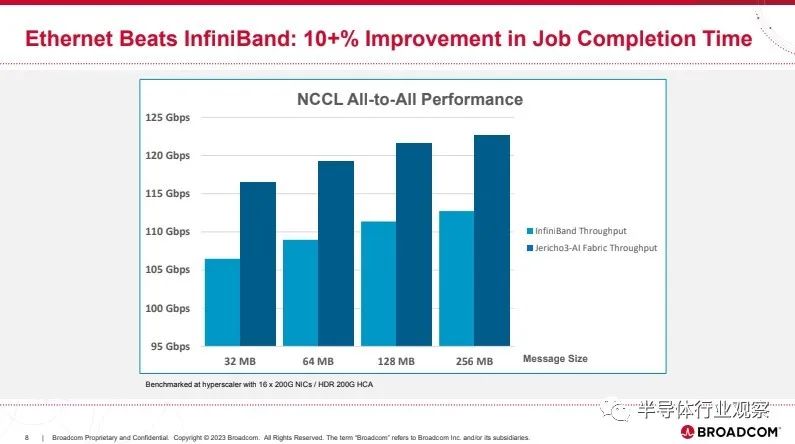
“Jericho3-AI 結構的一個獨特之處在于它提供了最高的性能,同時還實現了最低的總擁有成本。這是通過長距離 SerDes、分布式緩沖和高級遙測等屬性實現的,所有這些都使用行業標準以太網提供。這些因素為最大的硬件和軟件提供商生態系統提供了網絡架構和部署選項的高度靈活性。”博通強調。
2/微軟,自研芯片再曝進展
因為ChatGPT大火的企業除了英偉達外,作為ChatGPT投資人的微軟也備受關注。在半導體行業觀察日前發布的文章《英偉達H100市面價格飆升!Elon Musk:每個人都在買GPU》中我們也披露,為了發展ChatGPT,微軟已經搶購了不少GPU。隨著算力需求的增加,微軟在后續必須要更多的芯片支持。
如果一如既往地購買英偉達GPU,這對英偉達來說會是一筆昂貴的支出,他們也會為此不爽。于是,就恰如其分地,微軟的自研芯片有了更多信息曝光。
據路透社引述The Information 的報道,微軟公司正在開發自己的代號為“Athena”的人工智能芯片,該芯片將為 ChatGPT 等人工智能聊天機器人背后的技術提供支持。
根據該報告,這些芯片將用于訓練大型語言模型和支持推理——這兩者都是生成 AI 所需要的,例如 ChatGPT 中使用的 AI 來處理大量數據、識別模式并創建新的輸出來模仿人類對話。報告稱,微軟希望該芯片的性能優于目前從其他供應商處購買的芯片,從而為其昂貴的 AI 工作節省時間和金錢。
雖然目前尚不清楚微軟是否會向其 Azure 云客戶提供這些芯片,但據報道,這家軟件制造商計劃最早于明年在微軟和 OpenAI 內部更廣泛地提供其 AI 芯片。據報道,該芯片的初始版本計劃使用臺積電 (TSMC) 的 5 納米工藝,不過作為該項目的一部分,可能會有多代芯片,因為微軟已經制定了包括多個后代芯片的路線圖。
據報道,微軟認為自己的 AI 芯片并不能直接替代 Nvidia 的芯片,但隨著微軟繼續推動在Bing、Office 應用程序、GitHub和其他地方推出 AI 驅動的功能,內部的努力可能會大幅削減成本。研究公司 SemiAnalysis 的 Dylan Patel 也告訴The Information,“如果 Athena 具有競爭力,與 Nvidia 的產品相比,它可以將每芯片的成本降低三分之一。”
關于微軟造芯,最早可以追溯到2020年。據彭博社在當時的報道,微軟公司正在研究用于運行公司云服務的服務器計算機的內部處理器設計,以促進全行業減少對英特爾公司芯片技術依賴的努力。知情人士透露,這家全球最大的軟件制造商正在使用Arm的設計來生產將用于其數據中心的處理器。它還在探索使用另一種芯片來為其部分 Surface 系列個人電腦提供動力。
近年來,微軟加大了處理器工程師的招聘力度,在英特爾、超微、英偉達等芯片制造商的后院招聘。2022年,他們甚至還從蘋果公司挖走了一位經驗豐富的芯片設計師,以擴大自身的服務器芯片業務。據報道,這位名為Mike Filippo 的資深專家將在由 Rani Borkar 運營的微軟 Azure 集團內從事處理器方面的工作。微軟發言人證實了 Filippo 的聘用,他也曾在 Arm和英特爾公司工作過。
今年年初,微軟更是宣布收購了一家名為Fungible的DPU芯片公司。
微軟 Azure 核心部門的 CVP Girish Bablani 在一篇博文中寫道:“Fungible 的技術有助于實現具有可靠性和安全性的高性能、可擴展、分解、橫向擴展的數據中心基礎設施”。他進一步指出:“今天的公告進一步表明微軟致力于數據中心基礎設施進行長期差異化投資,這增強了公司的技術和產品范圍,包括卸載、改善延遲、增加數據中心服務器密度、優化能源效率和降低成本。”Fungible 在其網站上的一份聲明中寫道。“我們很自豪能成為一家擁有 Fungible 愿景的公司的一員,并將利用 Fungible DPU 和軟件來增強其存儲和網絡產品。”
由此我們可以看到微軟在芯片上做更多的發布也不足為奇。
3/谷歌TPU,已經第四代
在取代英偉達的這條路上,谷歌無疑是其中最堅定,且走得最遠的一個。
按照谷歌所說,公司谷歌早在 2006 年就考慮為神經網絡構建專用集成電路 (ASIC),但到 2013 年情況變得緊迫。那時他們意識到神經網絡快速增長的計算需求可能需要我們將數量 增加一倍我們運營的數據中心。從2015年開始,谷歌就將其TPU部署到了服務器中,并在后續的測試中獲得了不邵的反饋,以迭代其產品。
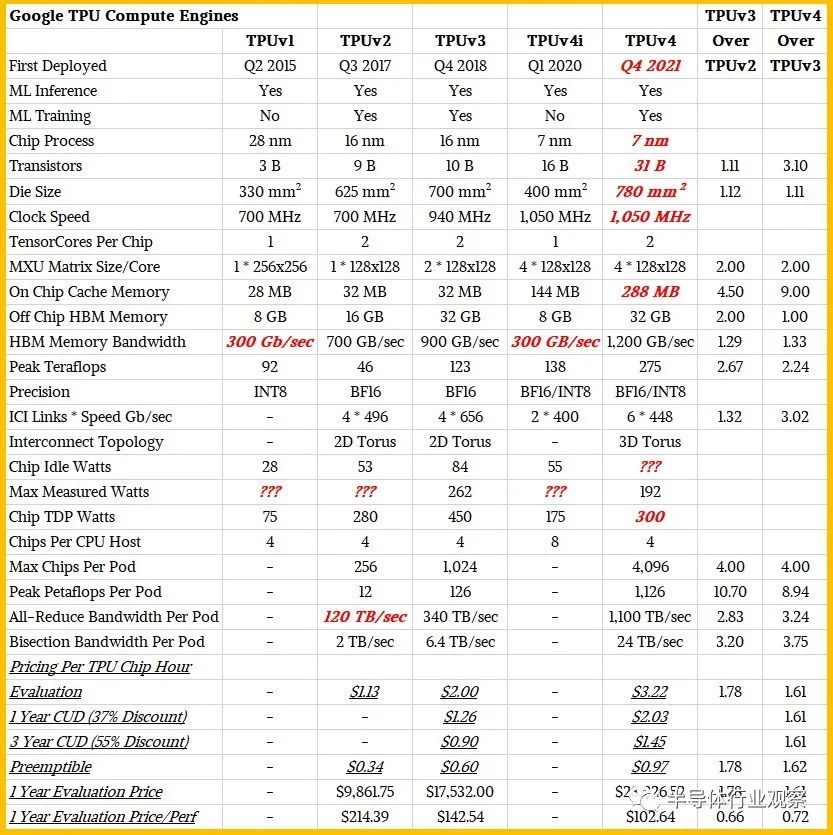
近日,谷歌對其TPUv4及其基于這個芯片的打造的超級計算系統進行了深度披露。
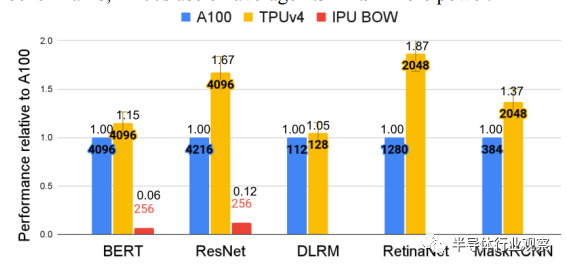
據他們在一篇博客中介紹,得益于互連技術和領域特定加速器 (DSA) 方面的關鍵創新,谷歌云 TPU v4 在擴展 ML 系統性能方面比 TPU v3 有了近 10 倍的飛躍;與當代 ML DSA 相比,提高能源效率約 2-3 倍。在與Nvidia A100 相比時,谷歌表示,TPU v4比前者快 1.2-1.7 倍,功耗低 1.3-1.9 倍。在與Graphcore的IPU BOW相比,谷歌表示,其芯片也擁有領先的優勢。
基于這個芯片,谷歌打造了一個擁有 4,096 個張量處理單元 (TPU)的TPU v4 超級計算機。谷歌表示,這些芯片由內部開發的行業領先的光電路開關 (OCS) 互連,OCS 互連硬件允許谷歌的 4K TPU 節點超級計算機與 1,000 個 CPU 主機一起運行,這些主機偶爾(0.1-1.0% 的時間)不可用而不會引起問題。
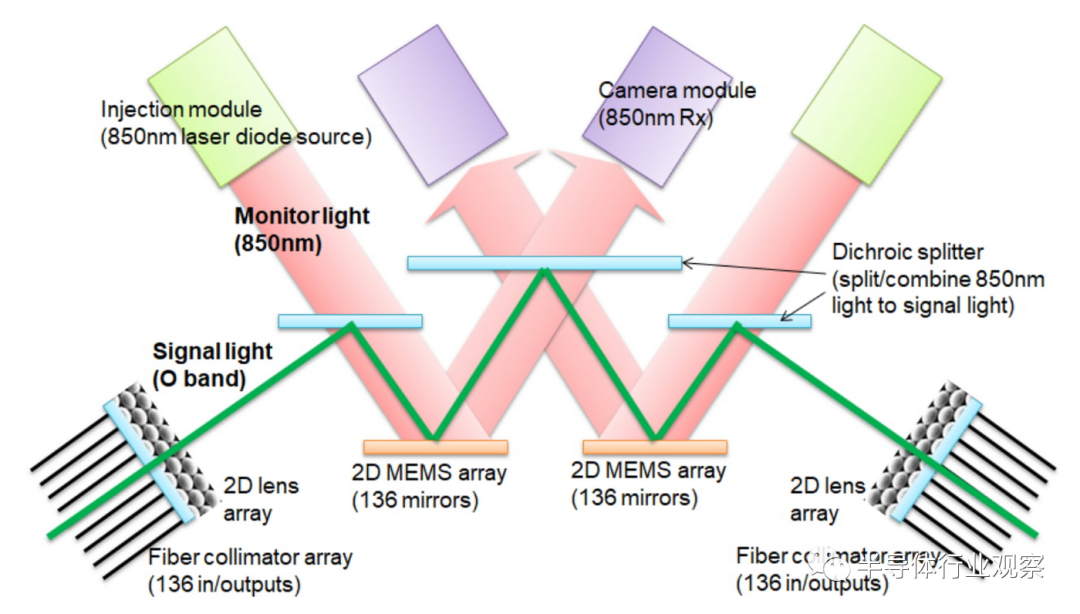
據谷歌介紹,OCS 動態重新配置其互連拓撲,以提高規模、可用性、利用率、模塊化、部署、安全性、功率和性能。與 Infiniband 相比,OCS 和底層光學組件更便宜、功耗更低且速度更快,不到 TPU v4 系統成本的 5% 和系統功耗的 5% 以下。下圖顯示了 OCS 如何使用兩個 MEM 陣列工作。不需要光到電到光的轉換或耗電的網絡分組交換機,從而節省了電力。
值得一提的是,TPU v4 超級計算機包括 SparseCores,這是一種更接近高帶寬內存的中間芯片,許多 AI 運算都發生在該芯片上。SparseCores 的概念支持 AMD、英特爾和高通等公司正在研究的新興計算架構,該架構依賴于計算更接近數據,以及數據進出內存之間的協調。
此外,谷歌還在算法-芯片協同方面做了更大的投入。如半導體行業觀察之前的文章《從谷歌TPU 看AI芯片的未來》中所說;“隨著摩爾定律未來越來越接近物理極限,預計未來人工智能芯片性能進一步提升會越來越倚賴算法-芯片協同設計,而另一方面,由于有算法-芯片協同設計,我們預計未來人工智能芯片的性能仍然將保持類似摩爾定律的接近指數級提升,因此人工智能芯片仍然將會是半導體行業未來幾年最為熱門的方向之一,也將會成為半導體行業未來繼續發展的重要引擎。”
寫在最后
綜合上述報道我們可以直言,對于英偉達而言,其面臨的挑戰是方方面面的,而不是僅僅局限于其GPU。其對手也不僅僅是芯片公司,因此如何在規模化優勢的情況下,保證其高性價比,是安然度過未來潛在挑戰的有效方法之一。
不過,可以肯定的是,圍繞著數據中心的創新遠未接近停止,甚至可以說因為大模型的流行,這場戰斗才剛剛開始。
-
英特爾
+關注
關注
61文章
9949瀏覽量
171694 -
cpu
+關注
關注
68文章
10854瀏覽量
211590 -
谷歌
+關注
關注
27文章
6161瀏覽量
105304 -
服務器
+關注
關注
12文章
9123瀏覽量
85331 -
DPU
+關注
關注
0文章
357瀏覽量
24169
發布評論請先 登錄
相關推薦
世紀大并購!傳高通有意整體收購英特爾,英特爾最新回應

英特爾或被道瓊斯指數除名
英特爾CEO:AI時代英特爾動力不減
英特爾、AMD等聯手推出UALink,希望用它取代Nvidia NVLink接口

英特爾與微軟合作在其AI PC及邊緣解決方案中支持多種Phi-3模型
微軟正在與英偉達、AMD和英特爾合作以改進PC游戲畫質技術


Cirrus Logic與英特爾和微軟在全新的PC參考設計上進行合作
英特爾拿下微軟芯片代工訂單

微軟將使用英特爾的18A技術生產芯片






 工商網監
工商網監
評論