

1. 動機介紹
對話中的情感分析已經成為自然語言處理(Natural Language Processing, NLP)界的一個新興話題。大多數現有的工作主要集中在對話情緒識別上(Emotion Recognition in Conversations, ERC),其目的是預測對話中每個話語的情緒標簽[1,2,3]。然而,情感推理任務,如識別對話中情緒背后的原因,還沒有被充分研究。最近,Poria等人[4]認為,在對話中識別情緒原因(RECCON)有利于提高情緒分析模型的可解釋性和性能。同時,它在一些領域有潛在的應用,如情緒支持系統[5]和共情對話系統[6]。因此,Poria等人[4]引入了一個名為RECCON的新任務,該任務有一個標注情緒原因的數據集。它包括兩個不同的子任務:原因跨度抽取(Causal Span Extraction, CSE)和情緒原因蘊含(Causal Emotion Entailment, CEE)。在本文中,我們重點關注CEE子任務,其目標是預測對話歷史中哪些特定的語句會引發目標語句中的非中性情緒。
在CEE任務中,有兩個主要的挑戰。首先,為了捕捉對話者之間相互交織的情感動態變化,有必要通過有效的語境模型來理解語境中的深層語義關聯。其次,要準確地將候選語句推理到目標情感上可能很困難,因為因果線索并不總是在語境中明確提及,而是應該通過基于推理來暗示,這就導致了候選語句和目標語句之間存在推理空缺。然而,Poria等人[4]簡單地將CEE表述為一個語句對分類問題,這是缺乏足夠的對話語境模型和有效的情感原因推理的。因此,為了應對這樣的兩個挑戰,我們將常識性知識(Commonsense Knowledge, CSK)[7]引入CEE。
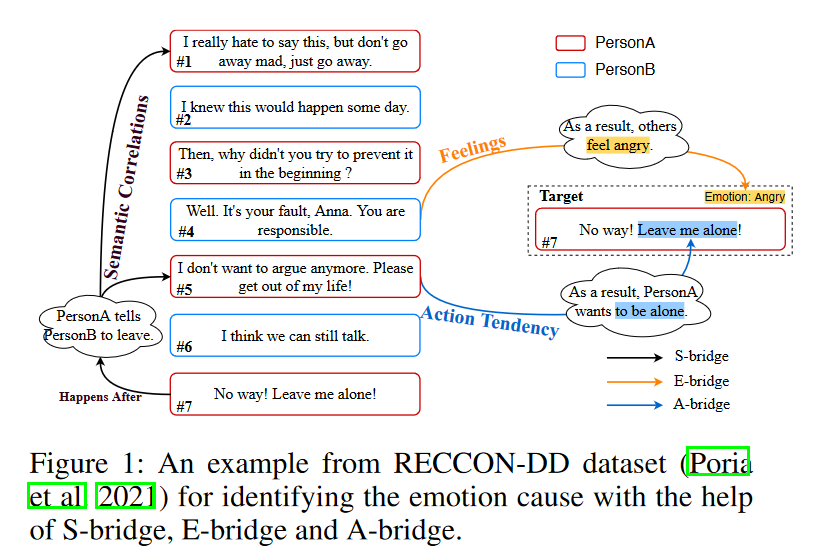
圖1: 數據集RECCON-DD示例
一方面,以事件為中心的CSK,對語句中提到的事件前后可能發生的事情進行揭示,可以被視為語義層面的橋梁(S-bridge),連接對話的發展,加強相關語句之間的語義依賴,從而深入理解對話的語境信息。如圖1左側所示,語句#7中PersonA想單獨離開的事件發生在PersonA告訴PersonB離開的事件之后,這與語句#1和#5相關。
另一方面,根據Moors等人[8],人類的感覺和行動傾向是情緒的兩個重要組成部分,并在很大程度上為目標情緒的產生提供了潛在的因果線索。為此,社會交互CSK被用作情緒層面的橋梁(E-bridge)和行動層面的橋梁(A-bridge),根據對話者的感覺和行動傾向所傳達的因果線索,將候選語詞與目標語詞連接起來。在圖1中,話語#4中PersonB的狡辯和批評使PersonA感到憤怒,這與目標語句#7所持有的情緒是一致的。此外,語句#5的內容暗示了PersonA的行動傾向是獨處,它直接導致了她在目標語句#7中表達的內容。
在本文中,我們提出了知識橋接因果交互網絡(Knowledge Bridged Causal Interaction Network, KBCIN),以有效地進行語境建模和情緒原因推理。具體來說,我們將一個對話抽象為一個對話圖,以建模對話中的語句間依賴關系。然后,我們引入了以事件為中心的CSKs,包括兩種類型isAfter和isBefore,并設計了知識增強的圖注意力模塊(CSK-Enhanced Graph Attention),將CSKs作為S-bridge在圖上進行消息傳遞。此外,為了填補候選語句和目標語句之間的推理空缺,我們利用社會交互CSKs,x(o)Want和x(o)React作為A-bridge和E-bridge。我們設計了情緒交互模塊和行動交互模塊,借助這兩個bridge所傳達的明確的因果線索,準確推理出目標情緒的原因。而上述三個模塊構成了知識橋接的因果交互(KBCI)模塊,它作為多個注意力頭的并列,充分地建模了對話語句之間的相互依賴關系,并將目標情緒與候選語篇精確地聯系起來。
為了評估所提出的模型的性能,我們在基準數據集[4]上進行了廣泛的實驗。我們與CEE、情緒原因抽取(ECE)和情感-原因對提取(ECPE)任務上的基線模型相比,取得了最先進的性能。
這項工作的主要貢獻總結如下:
我們將常識性知識引入到因果情感實體化任務中,以填補候選語句和目標語句之間的推理空白。
我們提出了一個新的模型KBCIN,以常識性知識為橋梁,進行全面的對話語境建模和準確的情感原因推理。
在基準數據集上對比大多數強基線的實驗結果證明了我們模型的優越性。
2. 模型方法
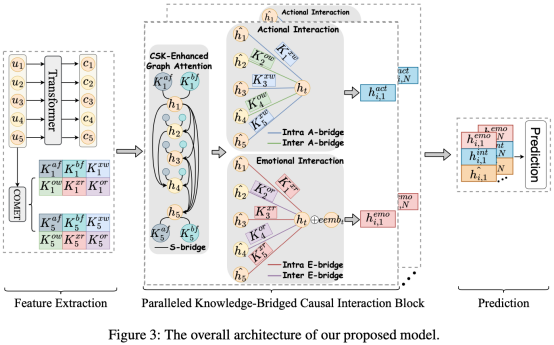
圖3: 整體模型架構圖
2.1 特征提取
語句級特征提取。Transformer encoder(Vaswani等人,2017)被作為語句encoder來提取語料級特征。具體來說,對于每條語句,一個特殊的標記[CLS]被拼接到語句的開頭。然后,我們將該序列送入語句編碼器,從最后一個隱藏層中得到的最大池化后的表示作為每條語句的語句級特征。
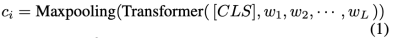
知識獲取。在這項工作中,我們使用ATOMIC- 2020[7]作為我們的常識性知識(CSK)基礎。它是一個常識知識圖,涵蓋日常推理知識的社會、物理和時間相關方面。
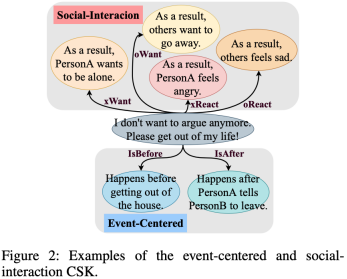
圖2: 常識知識圖事件中心CSK和社會交互CSK示例
為了充分理解對話中各語句之間的語義依賴關系,并填補候選語句與目標之間的推理空白,我們將CSK作為三座橋梁,分別命名為語義級橋梁(S-bridge)、情緒級橋梁(E-bridge)和動作級橋梁(A-bridge)。更具體地說,我們從ATOMIC-2020中探索了六種CSK,它們被歸類為以事件為中心的CSK和社會交互CSK。圖2中顯示了CSK的例子。一方面,根據事件中心CSK isAfter和isBefore所體現的對話發展的脈絡和因果關系,語句之間的深層語義依賴將由此來建立。因此,S-bridge的構建是為了對對話語境進行全面的了解。另一方面,另外兩座橋,E-bridge和A-bridge是由社會交互CSK xReact, oReact, xWant和oWant構建的。而x(o)Want是對自身(他人)在事件發生后可能想做什么的描述,而x(o)React體現了自身(他人)在事件發生后的情緒感受。它們從人的感覺和行動傾向的角度出發,填補了候選語詞和目標語詞之間的推理空白。
為了生成給定語句的CSK表示,我們采用了生成性常識模型COMET[9],該模型是在ATOMIC-2020上訓練的。更具體地說,我們使用基于BART[10]的COMET變體。給出對話中的每個語句,形成輸入格式,其中r是我們選擇的CSK類型,COMET會在關系r下生成推理內容的描述,而COMET最后一層的隱狀態表示被用作CSK代表。通過這種方式,對于每個語句,有六種CSK表示,用于對話語境建模和情緒原因推理。它們被表示為,分別是關系類型isAfter、isBefore、xReact、oReact、xWant和oWant的縮寫。
2.2 并行的知識橋接因果互動
受多頭注意力機制的啟發[11],我們提出了并行的知識橋接因果交互塊,其目的是為了充分理解對話語境,準確推理出目標語氣中的非中性情緒的原因。對于每個模塊,它由三個部分組成:CSK增強的圖形注意模塊,情感互動模塊和行為互動模塊。
CSK-增強的圖注意力模塊。我們沒有把CEE定義為一個沒有明確的語境交互建模的語句對分類問題,而是把對話中的語句抽象為一個對話圖,其中當前的語句只與對話歷史中的過去的語句相聯系。通過這種方式,我們確保語句的互動符合因果關系的性質,即原因只能從過去推理出來。每個節點的表示都是由相應的語句級特征初始化的。此外,我們計算目標語句和候選語句之間的相對距離,并利用相對位置信息來豐富語句的表示。由于每個語句的情緒標簽被證明在CEE中起著重要作用[4],我們也考慮到了這一點。因此,每個節點的最終表示是通過以下方式獲得的:
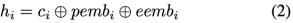
基于原始圖注意網絡[12],我們設計了CSK增強的圖注意力來傳播對話圖上的信息,并利用以事件為中心的CSK作為S-bridge來測量語句間的語義依賴:
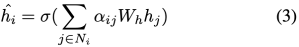
權重被用來衡量當前節點和其鄰居之間的相關性。我們將以事件為中心的CSK 和融入進入這個過程:
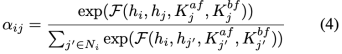
與原始的計算語句表示之間的注意力分數的注意力函數不同[12],我們利用以事件為中心的CSK 和作為S-bridge來衡量語句的依賴關系。
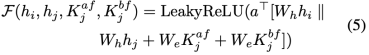
情緒交互模塊。在S-bridge的幫助下對對話語境進行了全面的建模后,我們用兩種社會交互 CSK、 和 或作為E-bridge來填補推理空白,并根據情緒因果線索來推理目標情緒。這個想法的靈感來自于這樣一個理論:感受是人類情感中最重要的組成部分[8]。因此,目標語句與相應的情緒對那些能夠產生與目標語句最相似的情緒或感覺的候選句來說更相關。此外,為了區分說話人內部的依賴性和說話人之間的依賴性,和分別作為說話人內部E-bridge和說話人之間E-bridge。情緒相似度得分可以通過以下方式獲得:
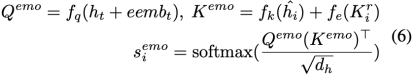
其中 都是線性變換。是目標語句的索引, 是對話歷史中的候選語句的索引。如果目標語句 與候選語句 是同一說話人,則,否則 。然后我們利用情緒相似度得分 來對候選語句的重要性進行加權,并用目標語句的表述來豐富它們:
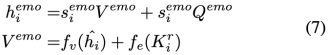
行動交互模塊。由于行動傾向是推理人類被引發的情緒的另一個重要組成部分,其他兩類社會交互CSK 和 作為A-bridge,使候選語詞與目標語句產生關聯,并暗示一致的行動傾向。此外,還形成了說話人內部A-bridge和說話人之間A-brige。行動相似性得分為:
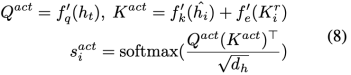
行動交互后的權重表示為:
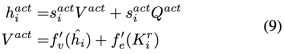
最后,在每個知識橋接的因果交互塊結束時,為了綜合推理過程中的結果,我們將對話表征 、情緒表征 和行動表征 加在一起,每個語句的最終表示為:
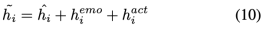
2.3 因果語句預測
在這里,將每個并行的KBCI頭的因果表征連接起來作為輸入,我們利用一個因果語句預測器來決定候選 是否是目標 的原因:
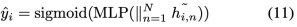
3. 實驗
3.1 數據集
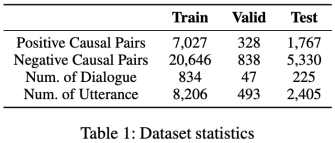
表1: 經處理的RECCON-DD的統計數據
我們在基準數據集RECCON-DD上進行了實驗。它是在數據集DailyDialog[13]的基礎上,標注了情緒原因標簽。我們只考慮對話歷史中的原因,重復的因果對被刪除。表1顯示了經過處理的RECCON-DD的統計數據。
3.2 主實驗結果及分析
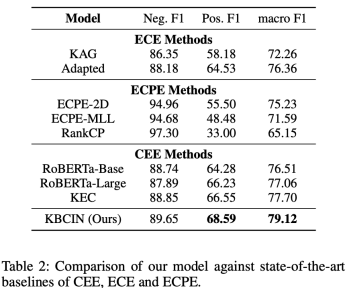
表2: 主實驗結果
如表2所示,我們提出的模型在REECON-DD數據集上取得了最好的結果。由于RoBERTa-Base/Large的結果和ECPE的方法是在與我們相同的數據集規模下實現的,我們直接參考了Poria等人[4]的結果,我們在相同的環境下重新實現了KEC和ECE任務下的方法。受益于通過S-bridge進行的有效對話語境建模和通過E-bridge和A-bridge進行的準確情緒原因推理,KBCIN取得了最先進的Pos. F1和macro F1分數,分別為68.59和79.12。
3.3 消融實驗
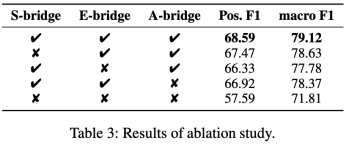
表3: 消融實驗結果
我們進行了消融實驗,以驗證我們模型中提出的不同模塊的有效性。從表3的結果可以看出,三個bridge均對情緒原因的推理起到正向的增強作用。
3.4 情緒信息的影響
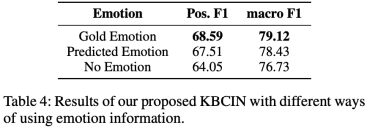
表4: 情緒信息影響分析
為了進一步研究對話歷史中每條語句的情緒信息的影響,我們要么刪除情緒信息,要么用情緒識別模型預測的標簽替換真實情感標簽。結果展示在表4中。我們之所以用預測的標簽來測試KBCIN的性能,是因為在實際應用的情況下,情緒識別是情緒原因提取的前置過程,這意味著在實際應用中的情緒原因抽取系統中,對話歷史中語句的這種真實情感標簽可能無法獲得。使用預測的情緒標簽導致的結果下降,提醒我們要嘗試在對話中聯合進行情緒識別和情緒原因提取,這樣可以在兩個任務之間共享相關的情緒信息,緩解兩階段使用情緒信息帶來的錯誤級聯傳播問題。
3.5 知識橋接塊的數量
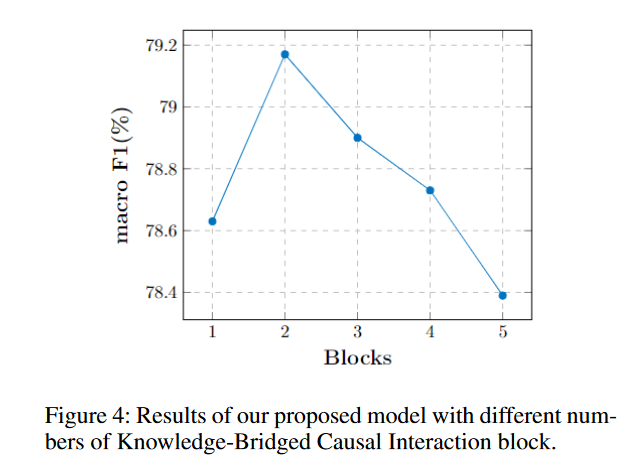
圖4: 知識橋接塊數量影響分析
由于KBCI是我們模型的創新和關鍵部分,用于有效的對話語境建模和準確的情緒原因推理,我們調整了不同數量的KBCI塊來深入分析性能。結果顯示在圖4中。隨著KBCI塊的數量從1到5的增加,配有2個KBCI塊的模型取得了最好的性能。
4. 結論
在本文中,我們提出了知識橋接的因果交互網絡(KBCIN),用于情緒原因的推理。常識知識(CSK)被用作三個橋梁來進行有效的對話語境建模和準確的情緒原因推理。具體來說,我們將對話抽象為一個對話圖,并利用以事件為中心的CSK作為語義層面的橋梁(S-bridge),通過CSK增強的圖注意力模塊在圖上進行消息傳遞,來增強深層次的語義間的依賴性。而社會交互CSK作為情緒級橋梁(E-bridge)和行動級橋梁(A-bridge),從人的感覺和行動傾向的角度為情緒交互模塊和行動交互模塊提供顯示的因果線索,填補了候選語句與目標語句之間的推理空白。基準數據集的實驗結果證明了我們提出的KBCIN的有效性。
審核編輯 :李倩
-
數據集
+關注
關注
4文章
1222瀏覽量
25245 -
自然語言處理
+關注
關注
1文章
625瀏覽量
13980 -
nlp
+關注
關注
1文章
490瀏覽量
22453
原文標題:參考文獻
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄






 工商網監
工商網監

評論