") NLP大模型必備-FudanNLP開源中文圖書集合CBook-150K
NLP大模型必備-FudanNLP開源中文圖書集合CBook-150K
為了助力大模型研究,復旦大學自然語言處理實驗室開源了中文圖書數(shù)據(jù)集合CBook-150K,包含15萬本中文圖書的下載和抽取方法,涵蓋人文、教育、科技、軍事、政治等眾多領(lǐng)域。
當前很多研究表明,高質(zhì)量數(shù)據(jù)對于訓練大規(guī)模語言模型具有至關(guān)重要的作用。圖書中的內(nèi)容在質(zhì)量、專業(yè)水準、可靠性等方面遠高于互聯(lián)網(wǎng)數(shù)據(jù)。OpenAI在訓練GPT 3時,也使用了大量圖書資源。但是目前還缺乏大規(guī)模的中文圖書開放集合。此外,由于絕大多數(shù)電子書籍的保存方式為PDF格式,從其中抽取文本內(nèi)容也需要分析工具支持。復旦大學自然語言處理實驗室結(jié)合此前自主開發(fā)的相關(guān)PDF分析工具,開源了中文語料圖書集合CBook-150K。
復旦大學自然語言處理實驗室,自2019年起,自研了PDF處理工具DocAI,針對非掃描件PDF,具有能夠處理復雜格式、高效、高準確率、可私有化部署等特點。DocAI在全CPU解決方案下,單核CPU處理100頁文檔僅需10秒。提取字符準確率100%,結(jié)構(gòu)分析準確率95%。DocAI智能文檔解析系統(tǒng)支持對DOC、PDF等常見電子文檔進行智能解析,對文檔中的標題、段落、表格等半結(jié)構(gòu)化數(shù)據(jù)進行結(jié)構(gòu)化分析還原。該應(yīng)用場景具有文件類型多,格式復雜,兼容性要求高等特點,特別是對于跨頁表格,多欄排版等復雜場景的支持。是目前支持段落、表格融合識別的為數(shù)不多的智能文檔解析工具之一。DodAI不依賴第三方資源,支持離線環(huán)境下的私有化部署和使用,確保文檔隱私與安全。
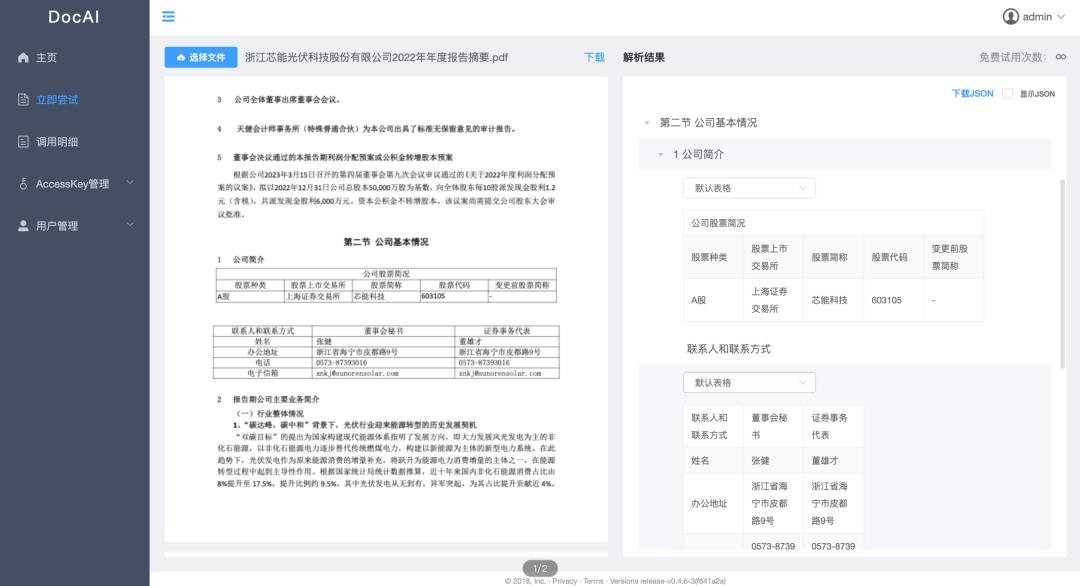

結(jié)合DocAI工具以及搜索引擎,復旦大學自然語言處理實驗室從互聯(lián)網(wǎng)中篩選了大量中文圖書資源鏈接,并構(gòu)造了內(nèi)容抽取算法,助力廣大學者NLP大模型研究,同時也在實踐與操作中不斷迭代更新,完善大型語料庫的部署。
下載鏈接:
https://github.com/FudanNLPLAB/CBook-150K
審核編輯 :李倩
-
開源
+關(guān)注
關(guān)注
3文章
3363瀏覽量
42544 -
自然語言處理
+關(guān)注
關(guān)注
1文章
618瀏覽量
13573 -
nlp
+關(guān)注
關(guān)注
1文章
489瀏覽量
22052
原文標題:NLP大模型必備-FudanNLP開源中文圖書集合CBook-150K
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
開源大模型在多個業(yè)務(wù)場景的應(yīng)用案例
阿里通義千問代碼模型全系列開源
科技云報到:假開源真噱頭?開源大模型和你想的不一樣!
Llama 3 與開源AI模型的關(guān)系
nlp邏輯層次模型的特點
nlp神經(jīng)語言和NLP自然語言的區(qū)別和聯(lián)系
nlp自然語言處理基本概念及關(guān)鍵技術(shù)
llm模型有哪些格式
nlp自然語言處理模型怎么做
nlp自然語言處理模型有哪些
NLP模型中RNN與CNN的選擇
通義千問推出1100億參數(shù)開源模型
大模型開源開放評測體系司南正式發(fā)布
機器人基于開源的多模態(tài)語言視覺大模型






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論