") 簡(jiǎn)述FPGA的八大好處
簡(jiǎn)述FPGA的八大好處
引言
自從幾十年前首次推出FPGA 以來,每種新架構(gòu)都繼續(xù)在采用按位(bit-wise)的布線 結(jié)構(gòu)。雖然這種方法一直是成功的,但是隨著高速通信標(biāo)準(zhǔn)的興起,總是要求不斷增加片上總線位寬,以支持這些新的數(shù)據(jù)速率。這種限制的一個(gè)后果是,設(shè)計(jì)人員經(jīng)常花費(fèi)大量的開發(fā)時(shí)間來嘗試實(shí)現(xiàn)時(shí)序收斂,犧牲性能來為他們的設(shè)計(jì)布局布線。
傳統(tǒng)的FPGA布線基于整個(gè)FPGA中水平和垂直方向上運(yùn)行的多個(gè)獨(dú)立分段互連線(segment),在水平和垂直布線的交叉點(diǎn)處帶有開關(guān) 盒(switch box)以實(shí)現(xiàn)通路的連接。通過這些獨(dú)立段和開關(guān)盒可以在FPGA上構(gòu)建從任何源到任何目的地的通路。FPGA布線的這種統(tǒng)一結(jié)構(gòu)為實(shí)現(xiàn)任何邏輯功能提供了極大的靈活性,可用于FPGA邏輯陣列內(nèi)的任何數(shù)據(jù)路徑位寬。
盡管在FPGA中的按位來布線非常靈活,但其缺點(diǎn)是每個(gè)段都會(huì)給任何給定的信號(hào)通路增加延遲。需要在FPGA中進(jìn)行長(zhǎng)距離傳輸?shù)男盘?hào)會(huì)導(dǎo)致分段之間的連接延遲,從而降低了功能的性能。按位布線的另一個(gè)挑戰(zhàn)是擁塞,它要求信號(hào)路徑繞過擁塞,這會(huì)導(dǎo)致更多的延遲,并造成性能的進(jìn)一步降低。
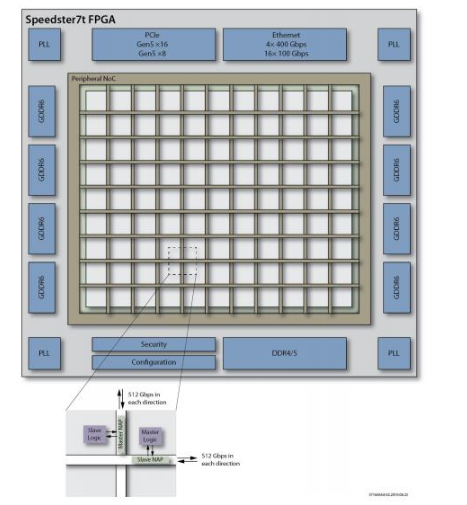
Achronix將此挑戰(zhàn)視為一個(gè)開發(fā)全新架構(gòu)的機(jī)會(huì),以消除傳統(tǒng)FPGA的設(shè)計(jì)挑戰(zhàn)并提高系統(tǒng)性能。Achronix的解決方案是在傳統(tǒng)分段式FPGA布線結(jié)構(gòu)之上,再為其全新的Speedste r7t FPGA系列器件創(chuàng)建一個(gè)革命性的二維(2D)高速片上網(wǎng)絡(luò)(NoC)。Speedster7t NoC連接到所有片上高速接口 :400G以太網(wǎng) 、PCIe Gen5、GDDR6和DDR4 / 5的多個(gè)端口。
NoC的內(nèi)部由一組行和列組成,它們?cè)谡麄€(gè)FPGA邏輯陣列中將網(wǎng)絡(luò)數(shù)據(jù)流量從水平和垂直方向上進(jìn)行分發(fā)。主NoC接入(NAP)點(diǎn)和從NoC接入點(diǎn)位于NoC的每一行和每一列交叉的位置。這些NAP可以是NoC和可編程邏輯陣列之間的源或目的地。
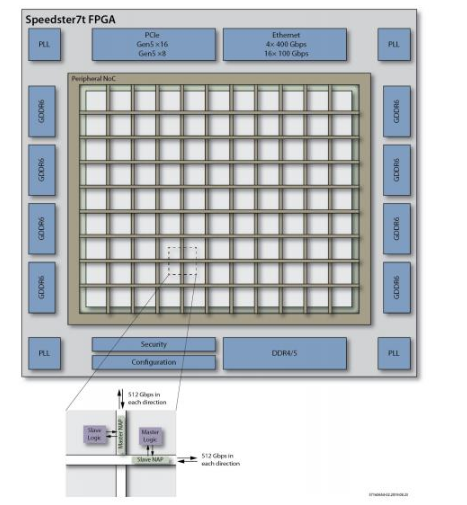
圖1:Speedster7t的片上網(wǎng)絡(luò)(NoC)和接口
Ethernet :以太網(wǎng)
Security:安全性
Configurati on:配置
each direcTI on:每個(gè)方向
Speedster7t的NoC似乎只對(duì)FPGA內(nèi)部的布線總線有所幫助;但是,這種新型架構(gòu)可以顯著提高設(shè)計(jì)人員的工作效率,實(shí)現(xiàn)全新的設(shè)計(jì)功能,并提供了輕松實(shí)現(xiàn)密集型數(shù)據(jù)處理應(yīng)用的能力。下面列舉了在效率提高、設(shè)計(jì)變更和性能提升方面最顯著的八種應(yīng)用場(chǎng)景。
在整個(gè)FPGA的邏輯陣列中簡(jiǎn)化高速數(shù)據(jù)分發(fā)
在傳統(tǒng)的各種FPGA架構(gòu)中,對(duì)連接到FPGA的片外存儲(chǔ)器 以及與之相連的外部高速數(shù)據(jù)源進(jìn)行雙向的讀/寫操作,需要數(shù)據(jù)在FPGA邏輯架構(gòu)中經(jīng)過一條較長(zhǎng)且分段的路由路徑。這種制約不僅限制了帶寬,而且還會(huì)消耗在邏輯陣列中的用戶設(shè)計(jì)所需的布線資源,這給FPGA設(shè)計(jì)人員在時(shí)序收斂方面帶來了挑戰(zhàn),尤其是其他邏輯功能對(duì)器件利用率提高的時(shí)候。
使用Speedster7t的NoC將數(shù)據(jù)從外部源傳輸?shù)紽PGA和存儲(chǔ) 器,比使用傳統(tǒng)的FPGA架構(gòu)完成同樣的工作要容易得多。Speedster7t NoC增強(qiáng)了FPGA陣列中傳統(tǒng)的可編程互連,其中的NoC就像一個(gè)疊加在城市街道系統(tǒng)上的高速公路網(wǎng)絡(luò)。雖然Speedster7t FPGA中傳統(tǒng)的、可編程互連矩陣仍然適用于較慢的本地?cái)?shù)據(jù)流量,但NoC可以處理更具挑戰(zhàn)性的、高速的數(shù)據(jù)流。
NoC中的每一行或每一列都被實(shí)現(xiàn)為兩個(gè)256位的、以2Ghz固定時(shí)鐘 速率運(yùn)行的單向數(shù)據(jù)通道。行具有東/西通道,列具有北/南通道,從而允許每個(gè)NoC行或列可以同時(shí)處理每個(gè)方向上512 Gbps的數(shù)據(jù)流量。總而言之,這些通道可以通過編寫簡(jiǎn)單的Verilog 或VHDL代碼,在FPGA陣列中傳輸大量的數(shù)據(jù),這些代碼支持FPGA與NAP通信并連接到NoC高速公路網(wǎng)絡(luò)上。
下圖顯示了NoC中各個(gè)點(diǎn)之間的數(shù)據(jù)傳輸。點(diǎn)1和點(diǎn)2的邏輯分別實(shí)例化了一個(gè)水平NAP。NAP可以發(fā)送和接收數(shù)據(jù),但是每個(gè)單獨(dú)的數(shù)據(jù)流都只是朝向一個(gè)方向。類似地,點(diǎn)3和點(diǎn)4的邏輯實(shí)例化了一個(gè)垂直NAP,并且可以在彼此之間發(fā)送數(shù)據(jù)流。
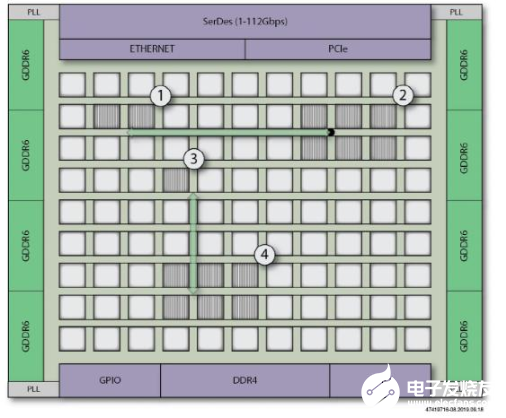
圖2:NoC上跨越器件邏輯陣列的數(shù)據(jù)流
自動(dòng)將PCIe接口連接到存儲(chǔ)器
在現(xiàn)在的FPGA中,設(shè)計(jì)人員在將高速接口連接至連有FPGA的存儲(chǔ)器件進(jìn)行讀寫時(shí),必須考慮在器件內(nèi)由于連接邏輯、進(jìn)行布線、以及輸入和輸出信號(hào)的位置而產(chǎn)生的延遲。為了實(shí)現(xiàn)基本的接口功能,在設(shè)計(jì)過程中構(gòu)建一個(gè)簡(jiǎn)單的存儲(chǔ)接口通常就要花費(fèi)大量的時(shí)間。
在Speedster7t架構(gòu)中,將嵌入式PCIe Gen5接口連接到已連接的GDDR6或DDR4存儲(chǔ)器這項(xiàng)工作,可由外圍NoC自動(dòng)處理,不需要設(shè)計(jì)人員編寫任何RTL來建立這些連接。由于NoC連接到所有的外圍IP接口,因此設(shè)計(jì)人員在將PCIe連接到GDDR6或DDR4的任何一個(gè)存儲(chǔ)器接口時(shí),都具有極大的靈活性。在下面的示例中,NoC能夠提供足夠的帶寬,以持續(xù)支持PCIe Gen 5通信流連接到GDDR6內(nèi)存的任意兩個(gè)通道。這種高帶寬連接無需消耗任何FPGA邏輯陣列資源即可實(shí)現(xiàn),并且設(shè)計(jì)所需時(shí)間幾乎為零。用戶只需要啟用PCIe和GDDR6接口即可在NoC上發(fā)送事務(wù)。
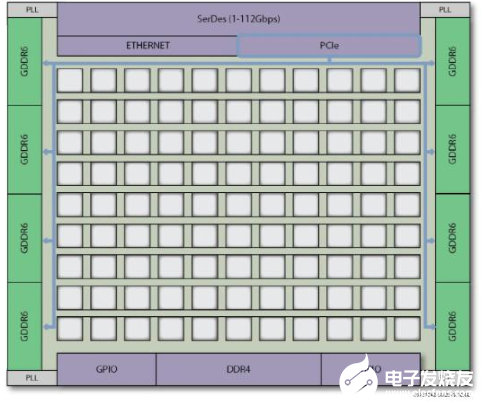
圖3:將PCIe直接連接到GDDR6接口
在獨(dú)立的FPGA邏輯陣列模塊上實(shí)現(xiàn)安全的局部重新配置
與其他基于靜態(tài)隨機(jī)存取存儲(chǔ)器(SRAM )的FPGA一樣,Speedster7t FPGA必須在通電時(shí)進(jìn)行配置。Speedster7t FPGA具有一個(gè)片上FPGA配置單元(FCU),用于管理FPGA的初始配置和任何后續(xù)的局部重新配置。FCU還被連接到NoC,從而在配置FPGA時(shí)提供了更高的靈活性。使用NoC將配置位流傳輸?shù)絊peedster7t FCU,可以使用以前不可用的新方法來對(duì)FPGA進(jìn)行配置。
在器件配置之前,Speedster7t NoC可用于某些讀/寫事務(wù):PCIe至GDDR6、PCIe至DDR4、最后是PCIe至FCU。一旦PCIe接口被設(shè)置好,F(xiàn)PGA就可以通過PCIe接口接收配置比特流(bitstream),并將其發(fā)送給FCU以配置器件的其余部分。一旦到達(dá)FCU,配置比特流被寫入FPGA可編程邏輯以配置器件。在器件被配置完成后,設(shè)計(jì)人員可以靈活地重新配置FPGA的某些部分(局部重新配置),以增加新的功能或提高加速性能,而無需關(guān)閉FPGA。
新的局部重新配置比特流可以通過PCIe接口發(fā)送到FCU,來重新配置器件的任何部分。當(dāng)部分器件被重新配置時(shí),通過在所需的區(qū)域中實(shí)例化一個(gè)NAP與NoC進(jìn)行通信,任何進(jìn)出新配置區(qū)域的數(shù)據(jù)都可以在Speedster7t1500器件中被輕松訪問。NoC消除了傳統(tǒng)FPGA局部重新配置的復(fù)雜性,因?yàn)橛脩舨槐負(fù)?dān)心圍繞現(xiàn)有邏輯功能進(jìn)行布線并影響性能,也不必?fù)?dān)心由于該區(qū)域中的現(xiàn)有邏輯而無法訪問某些器件的引腳。該功能節(jié)省了設(shè)計(jì)人員的時(shí)間,并在使用局部重新配置時(shí)提供了更大的靈活性。
此外,局部重新配置允許設(shè)計(jì)人員在工作負(fù)載變化時(shí)調(diào)整器件內(nèi)的邏輯。例如,如果FPGA正在對(duì)輸入的數(shù)據(jù)執(zhí)行壓縮算法,并且不再需要壓縮,則主機(jī)CPU 可以告訴FPGA重新配置,并加載經(jīng)過優(yōu)化的新設(shè)計(jì)以處理下一個(gè)工作負(fù)載。在器件仍處于運(yùn)行狀態(tài)時(shí),局部重新配置可以在邏輯陣列集群(cluster)級(jí)別上獨(dú)立完成。一個(gè)聰明的用例是開發(fā)一個(gè)具有自我感知的FPGA,該FPGA通過使用一個(gè)軟CPU來監(jiān)測(cè)器件操作以實(shí)時(shí)啟動(dòng)局部重新配置,來關(guān)閉邏輯從而節(jié)省功耗,或在FPGA架構(gòu)中添加更多加速器模塊,以臨時(shí)處理大量的輸入數(shù)據(jù)。這些功能為設(shè)計(jì)人員提供了前所未有的配置靈活性。
輕松支持硬件虛擬化
Speedster7t NoC通過利用NAP及其AXI接口,為設(shè)計(jì)人員提供了在單個(gè)FPGA中創(chuàng)建虛擬化安全硬件的獨(dú)特能力。將可編程邏輯設(shè)計(jì)直接連接到NoC只需要在邏輯設(shè)計(jì)中實(shí)例化一個(gè)NAP及其AXI4接口即可。每個(gè)NAP還具有一個(gè)相關(guān)的地址轉(zhuǎn)換表(ATT),該表將NAP上的邏輯地址轉(zhuǎn)換為NoC上的物理地址。NAP的ATT允許可編程邏輯模塊使用本地地址,同時(shí)將NoC定向事務(wù)映射到NoC全局存儲(chǔ)映射所分配的地址。此項(xiàng)重新映射功能可以以多種方式使用。例如,它可以用于允許加速引擎的所有相同副本使用基于零的虛擬尋址,同時(shí)將數(shù)據(jù)流量從每個(gè)加速引擎發(fā)送到不同的物理存儲(chǔ)位置。
每個(gè)ATT條目還包含一個(gè)訪問保護(hù)位,以防止該節(jié)點(diǎn)訪問被禁止的地址范圍。該功能提供了一種重要的進(jìn)程間安全機(jī)制,可防止同時(shí)在一個(gè)Speedster7t FPGA上運(yùn)行的多個(gè)應(yīng)用或多個(gè)任務(wù)干擾分配給其他應(yīng)用或任務(wù)的存儲(chǔ)模塊。這種安全機(jī)制還有助于防止由于意外、偶然甚至是故意的存儲(chǔ)地址沖突而導(dǎo)致系統(tǒng)崩潰。此外,設(shè)計(jì)人員可以使用此方案阻止邏輯功能訪問整個(gè)存儲(chǔ)設(shè)備。
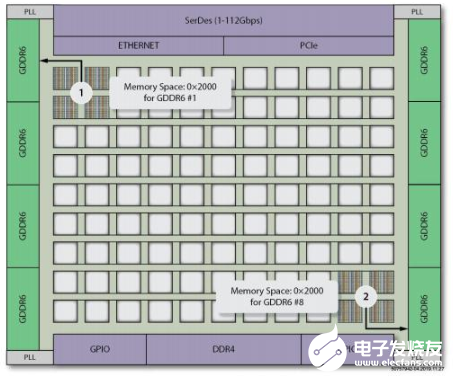
圖4:使用Speedster7t NoC實(shí)現(xiàn)硬件虛擬化
Memory Space:存儲(chǔ)空間
簡(jiǎn)化團(tuán)隊(duì)協(xié)同設(shè)計(jì)
基于團(tuán)隊(duì)的協(xié)同化FPGA設(shè)計(jì)并不是一個(gè)新的概念,但是底層架構(gòu)和布線依賴于FPGA的其他部分,從而使得實(shí)現(xiàn)這個(gè)簡(jiǎn)單概念非常具有挑戰(zhàn)性。一旦一個(gè)團(tuán)隊(duì)完成了設(shè)計(jì)的一部分,另一個(gè)設(shè)計(jì)其他部分的團(tuán)隊(duì)在嘗試訪問設(shè)備另一端的資源時(shí),通常會(huì)遇到挑戰(zhàn),因?yàn)樾枰谝呀?jīng)完成的設(shè)計(jì)部分進(jìn)行布線。同樣,對(duì)一部分已進(jìn)行設(shè)計(jì)布線的FPGA的區(qū)域或大小進(jìn)行更改,可能會(huì)對(duì)所有其他FPGA設(shè)計(jì)模塊產(chǎn)生連鎖 影響。
使用Speedster7t NoC,可以將設(shè)計(jì)模塊映射到FPGA的任何部分,并且可以對(duì)資源分配進(jìn)行更改,而不會(huì)影響其他FPGA模塊的時(shí)序、布局或布線。由于器件中所有的NAP都支持每個(gè)設(shè)計(jì)模塊無限制地訪問NoC進(jìn)行通信,因此使得基于團(tuán)隊(duì)的設(shè)計(jì)成為可能。因此,如果一個(gè)設(shè)計(jì)的某個(gè)部分在規(guī)模上有所增大,只要有足夠的FPGA資源可用,數(shù)據(jù)流就會(huì)由NoC自動(dòng)管理,從而使設(shè)計(jì)人員不必?fù)?dān)心是否滿足時(shí)序,以及對(duì)其他團(tuán)隊(duì)成員正在進(jìn)行的設(shè)計(jì)的其他部分可能帶來的后續(xù)影響。
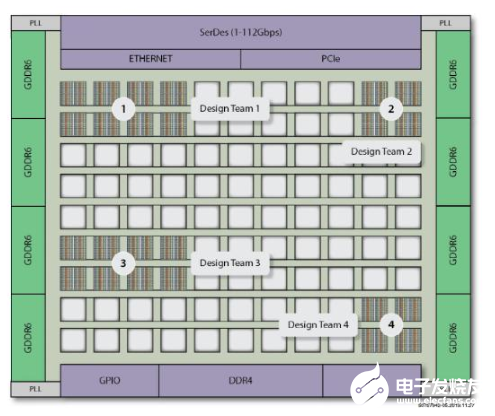
圖5:致力于開發(fā)同一個(gè)FPGA的多個(gè)設(shè)計(jì)團(tuán)隊(duì)
Design Team:設(shè)計(jì)團(tuán)隊(duì)
通過獨(dú)立的接口和邏輯驗(yàn)證加快設(shè)計(jì)速度
Speedster7t NoC的另一個(gè)獨(dú)特功能是支持設(shè)計(jì)人員獨(dú)立于用戶邏輯去配置和驗(yàn)證I/O 連接。例如,一個(gè)設(shè)計(jì)團(tuán)隊(duì)可以驗(yàn)證PCIe至GDDR6的接口,而另一個(gè)設(shè)計(jì)團(tuán)隊(duì)可以獨(dú)立地驗(yàn)證內(nèi)部邏輯功能。這種獨(dú)立操作之所以能夠?qū)崿F(xiàn),是因?yàn)镹oC的外圍部分連接了PCIe、GDDR6、DDR4和FCU,而不會(huì)消耗任何FPGA資源。這些連接可以在不使用任何HDL代碼的情況下進(jìn)行測(cè)試 ,從而可以同時(shí)獨(dú)立地驗(yàn)證接口和邏輯。該功能消除了驗(yàn)證步驟之間的依賴關(guān)系,并實(shí)現(xiàn)了比傳統(tǒng)FPGA架構(gòu)更快的總體驗(yàn)證速度。
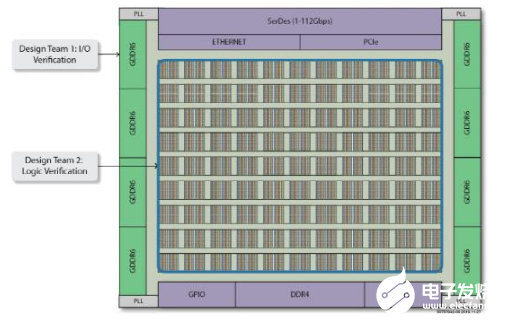
圖6:獨(dú)立的I/O和邏輯驗(yàn)證
Design Team 1:I/O Verif icaTI on:設(shè)計(jì)團(tuán)隊(duì)1:I/O驗(yàn)證
Design Team 2:Logic VerificaTI on:設(shè)計(jì)團(tuán)隊(duì)2:邏輯驗(yàn)證
采用分組模式(Packet Mode)簡(jiǎn)化400 Gbps以太網(wǎng)應(yīng)用
在FPGA中實(shí)現(xiàn)高速400 Gbps以太網(wǎng)數(shù)據(jù)通路所面臨的挑戰(zhàn)是找到一種能夠滿足FPGA性能要求的總線位寬。對(duì)于400G以太網(wǎng),全帶寬運(yùn)行的唯一可行選擇是運(yùn)行在724 MHz的1,024位總線,或運(yùn)行在642 MHz的2,048位總線。如此寬的總線難以布線,因?yàn)樗鼈冊(cè)贔PGA架構(gòu)內(nèi)消耗了大量的邏輯資源,即使在最先進(jìn)的FPGA中也會(huì)在這樣的速率要求下產(chǎn)生時(shí)序收斂挑戰(zhàn)。
但是,在Speedster7t架構(gòu)中,設(shè)計(jì)人員可以使用一種稱為分組模式(packetmode)的新型處理模式,其中傳入的以太網(wǎng)流被重新排列為四個(gè)較窄的32字節(jié)數(shù)據(jù)包,或者四條獨(dú)立的以506 MHz頻率運(yùn)行的256位總線。這種模式的優(yōu)點(diǎn)包括:當(dāng)數(shù)據(jù)包結(jié)束時(shí)減少了字節(jié)的浪費(fèi),并且可以并行傳輸數(shù)據(jù),而不必等到第一個(gè)數(shù)據(jù)包完成后才開始第二個(gè)數(shù)據(jù)包的傳輸。Speedster7t FPGA架構(gòu)的設(shè)計(jì)旨在通過將以太網(wǎng)MAC直接連接到特定的NoC列,然后使用用戶實(shí)例化的NAP從NoC列連接到邏輯陣列中,從而啟用分組模式。使用NoC列,數(shù)據(jù)可以沿著該列被發(fā)送到FPGA架構(gòu)中的任何位置,以便進(jìn)一步處理。使用ACE設(shè)計(jì)工具配置分組模式,可大大簡(jiǎn)化用戶設(shè)計(jì),并在處理400 Gbps以太網(wǎng)數(shù)據(jù)流時(shí)提高了效率。
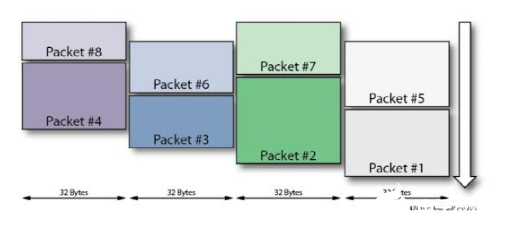
圖7:分組模式下的數(shù)據(jù)總線重排
Packet:數(shù)據(jù)包
Byte:字節(jié)
降低邏輯占用并提高整體FPGA性能
與以前的傳統(tǒng)FPGA相比,Speedster7t NoC具有更大的靈活性和更簡(jiǎn)單的設(shè)計(jì)方法。一個(gè)潛在的好處是NoC會(huì)自動(dòng)減少給定設(shè)計(jì)所需的邏輯量,設(shè)計(jì)可以使用NoC代替FPGA邏輯陣列來進(jìn)行模塊間布線。ACE設(shè)計(jì)工具自動(dòng)管理將設(shè)計(jì)單元連接到Speedster7t NoC的復(fù)雜性,因此設(shè)計(jì)人員無需編寫HDL代碼即可實(shí)現(xiàn)生產(chǎn)率。這種方法簡(jiǎn)化了實(shí)現(xiàn)時(shí)序收斂的耗時(shí)挑戰(zhàn),同時(shí)又不會(huì)由于FPGA邏輯陣列內(nèi)的布線擁塞而降低整體應(yīng)用性能。NoC還可以在不犧牲FPGA性能的情況下提高器件利用率,并且可以顯著增加可用于計(jì)算的查找表(LUT)數(shù)量。
為了強(qiáng)調(diào)這一優(yōu)勢(shì),我們創(chuàng)建了一個(gè)支持二維輸入圖像卷積的示例設(shè)計(jì)。每個(gè)模塊都使用Speedster7t機(jī)器學(xué)習(xí) 處理器(MLP)和BRAM模塊,每個(gè)MLP在一個(gè)周期內(nèi)執(zhí)行12次int8乘法。將40個(gè)二維卷積模塊鏈接在一起,以利用器件中幾乎所有可用的BRAM和MLP資源。總共有40個(gè)二維卷積示例設(shè)計(jì)實(shí)例并行運(yùn)行,使用了94%的MLP、97%的BRAM、但僅使用了8%的LUT。在總的可用LUT中,其余92%的LUT仍可被用于其他功能。
隨著更多的實(shí)例被內(nèi)置于器件中,單個(gè)單元模塊的最高頻率(FMAX)不會(huì)降低。該設(shè)計(jì)能夠保持性能,因?yàn)檫M(jìn)出每個(gè)二維卷積模塊的數(shù)據(jù)可以直接從連接到NoC的NAP訪問GDDR6內(nèi)存,而無需通過FPGA邏輯陣列進(jìn)行布線。
結(jié)論
Speedster7t NoC實(shí)現(xiàn)了FPGA設(shè)計(jì)過程的根本轉(zhuǎn)變。Achronix是第一家實(shí)現(xiàn)二維片上網(wǎng)絡(luò)(2D NoC)的FPGA公司,該2D NoC可以連接所有的系統(tǒng)接口和FPGA邏輯陣列。這種新型架構(gòu)使Achronix公司的FPGA特別適用于高帶寬應(yīng)用,同時(shí)顯著提高了設(shè)計(jì)人員的生產(chǎn)率。由于NoC管理了FPGA中設(shè)計(jì)的數(shù)據(jù)加速器和高速數(shù)據(jù)接口之間的所有網(wǎng)絡(luò)功能,因此設(shè)計(jì)人員只需要設(shè)計(jì)其數(shù)據(jù)加速器并將其連接到NAP原語即可。ACE和NoC負(fù)責(zé)其他所有事務(wù)。通過使用NoC,F(xiàn)PGA設(shè)計(jì)人員將受益于:
- 在整個(gè)FPGA邏輯陣列中簡(jiǎn)化高速數(shù)據(jù)分發(fā)
- 自動(dòng)將PCIe接口連接到存儲(chǔ)器
- 在獨(dú)立的FPGA邏輯陣列模塊上實(shí)現(xiàn)安全的局部重新配置
- 輕松支持硬件虛擬化
- 簡(jiǎn)化團(tuán)隊(duì)化設(shè)計(jì)
- 通過獨(dú)立的接口和邏輯驗(yàn)證加快設(shè)計(jì)速度
- 采用分組模式簡(jiǎn)化400 Gbps以太網(wǎng)應(yīng)用
- 降低邏輯占用并提高整體FPGA性能
-
FPGA
+關(guān)注
關(guān)注
1629文章
21729瀏覽量
602986 -
開關(guān)
+關(guān)注
關(guān)注
19文章
3136瀏覽量
93599 -
邏輯
+關(guān)注
關(guān)注
2文章
833瀏覽量
29464
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
使用帶有片上高速網(wǎng)絡(luò)的FPGA的八大好處
電源模塊的三大好處
解決傳導(dǎo)干擾的八大對(duì)策分享
CES八大技術(shù)趨勢(shì):平板電腦居首
數(shù)據(jù)結(jié)構(gòu)常見的八大排序算法
磷酸鐵鋰電池八大缺陷及八大優(yōu)勢(shì)分析
詳細(xì)putty串口使用教程與八大使用技巧分享

使用帶有片上高速網(wǎng)絡(luò)的FPGA的八大好處






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論