


本次主要介紹在旭日x3的BPU中部署yolov5。首先在ubuntu20.04安裝yolov5,并運行yolov5并使用pytoch的pt模型文件轉ONNX;
然后將ONNX模型轉換BPU模型;最后上板運行代碼測試,并利用Cypython封裝后處理代碼。
一. 安裝Anaconda
Anaconda 是一個用于科學計算的 Python 發行版,支持 Linux, Mac, Windows, 包含了眾多流行的科學計算、數據分析的 Python 包。
a. 先去官方地址下載好對應的安裝包
b.然后安裝anaconda
bash ~/Downloads/Anaconda3-2023.03-Linux-x86_64.sh (bash ~/安裝包位置/安裝包名稱)
全部選yes,anaconda會自動將環境變量添加到PATH里面,如果后面你發現輸出conda提示沒有該命令,那么你需要執行命令 source ~/.bashrc 更新環境變量,就可以正常使用了。
如果發現這樣還是沒用,那么需要添加環境變量。編輯~/.bashrc 文件,在最后面加上
export PATH=/home/
主機名稱/anaconda3/bin:$PATH
注意:路徑應改為自己機器上的路徑
保存退出后執行:source ~/.bashrc 再次輸入 conda list 測試看看,應該沒有問題。
c.添加Aanaconda國內鏡像配置
添加Aanaconda國內鏡
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/ conda config --set show_channel_urls yes像配置
二. 安裝pytorch,onnx
首先為pytorch創建一個anaconda虛擬環境,python=3.10,環境名字可自己確定,這里本人使用yolov5作為環境名:
conda create -n yolov5 python=3.10
進入創建的yolov5環境
conda activate yolov5
安裝關鍵包ONNX
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple onnx
安裝yolov5依賴的pytorch
pip install torch==1.11.0 torchvision==0.12.0 torchaudio==0.11.0
三. yolov5項目克隆和安裝
1.克隆yolov5項目
git clone -b (下載指定版本或下載最新把-b去掉即可)https://github.com/ultralytics/yolov5.git
2.使用清華源安裝所需庫
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
3.下載與訓練的權重文件
在https://pypi.tuna.tsinghua.edu.cn/simple 中找到下載版本的權重文件,并并放置在育yolov5文件夾下
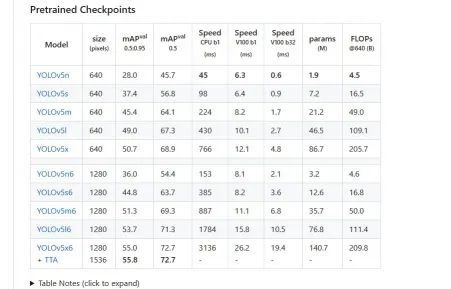
4.安裝測試
在yolov5路徑下執行:python detect.py
5.pytorch的pt模型文件轉onnx
BPU的工具鏈沒有支持onnx的所有版本的算子,即當前BPU支持onnx的opset版本為10和11,執行:
python export.py --weights yolov5s.pt --include onnx --opset 11
轉換成功后,控制臺顯示如下log信息,轉換模型造yolov5文件夾下
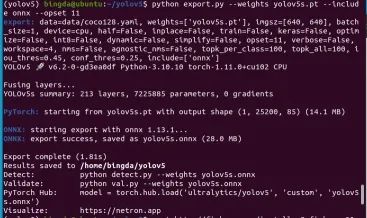
四. ONNX模型轉換
安裝docker
可以使用魚香ros一鍵安裝Docker,安裝完成之后輸入命令sudo docker pull
openexplorer/ai_toolchain_centos_7:v1.13.6,之后自動開始docker的安裝。 配置天工開物 OpenExplorer
OpenExplorer工具包的下載,需要wget支持,在ubuntu中安裝wget, sudo apt-get install wget ,
參考官網信息
https://developer.horizon.ai/forumDetail/136488103547258769,下載horizon_xj3_open_explorer
CPU Docker:
wget-c ftp://vrftp.horizon.ai/Open_Explorer_gcc_9.3.0/2.5.2/docker_openexplorer_ubuntu_20_xj3_cpu_v2.5.2_py38.tar.gz
啟動docker
這一部分文件我參考
https://blog.csdn.net/Zhaoxi_Li/article/details/125516265
天工開物OpenExplorer根目錄:
我的環境下是
"/home/bingda/dd/horizon_xj3_openexplorer_v2.5.2_py38_doc"記得加雙引號防止出現空格,該目錄要掛載在docker中/open_explorer的目錄下:
sudo docker run -it --rm -v "/home/bingda/dd/horizon_xj3_openexplorer_v2.5.2_py38_doc":/open_explorer -v "home/bingda/dd/Codes":/data/horizon_x3/codes openexplorer/ai_toolchain_centos_7:v1.13.6
已經成功通過Docker鏡像進入了完整的工具鏈開發環境。
可以鍵入 hb_mapper --help命令驗證下是否可以正常得到幫助信息。其中hb_mapper --help是工具鏈的一個常用工具。
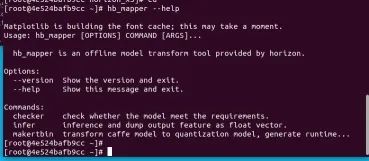
創建一個文件(我這里角yolo)中,,把前面轉好的yolov5s.onnx放進這個文件夾里,輸入:
sudo docker run -it --rm -v "/home/bingda/dd/yolo":/bpucodes openexplorer/ai_toolchain_centos_7:v1.13.6 在docker中,進入bpucodes
模型檢查
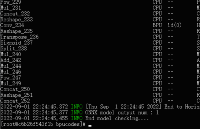
文件夾,開始我們的模型轉換。輸入指令hb_mapper checker --model-type onnx --march bernoulli2 --model yolov5s.onnx,
開始檢查模型,顯示如下內容表示模型檢查通過。
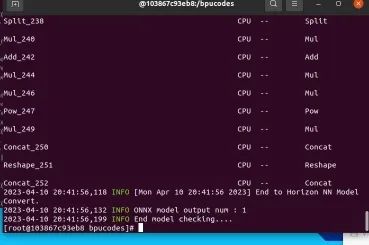
校準數據參考以下的yolov3校準代碼:
https://blog.csdn.net/Zhaoxi_Li/article/details/125516265
輸入prepare_calibration_data.py可以得到校準數據。
# 修改輸入圖像大小為640x640# img = imequalresize(img, (640, 640)) # 指定輸出的校準圖像根目錄 dst_root = '/data/horizon_x3/codes/yolov5/bpucodes/calibration_data
開始轉換BPU模型
輸入命令hb_mapper makertbin --config convert_yolov5s.yaml --model-type onnx
開始轉換我們的模型。校準過后會輸出每一層的量化損失,轉換成功后,得到model_output/yolov5s.bin,這個文件拿出來,拷貝到旭日X3派上使用,它也是我們上板運行所需要的模型文件。
五. 上板運行
文件準備
下載百度云的文件,拷貝到旭日X3派開發板中,其中yolov5s.bin就是我們轉換后的模型,coco_classes.names僅用在畫框的時候,如果用自己的數據集的話,參考coco_classes.names創建個新的名字文件即可。
輸入sudo apt-get install libopencv-dev安裝opencv庫,之后進入代碼根目錄,輸入python3 setup.py build_ext --inplace,編譯后處理代碼,得到lib/pyyolotools.cpython-38-aarch64-linux-gnu.so文件。
運行推理代碼
模型推理的代碼可參考https://blog.csdn.net/Zhaoxi_Li/article/details/126651890,其中yolotools.pypostprocess_yolov5為C++實現的后處理功能。
這里補充旭日x3通過opencv調用攝像頭,對每個圖像進行實時處理
import numpy as np
import cv2
import os
from hobot_dnn import pyeasy_dnn as dnn
from bputools.format_convert import imequalresize, bgr2nv12_opencv
import lib.pyyolotools as yolotools
def get_hw(pro):
if pro.layout == "NCHW":
return pro.shape[2], pro.shape[3]
else:
return pro.shape[1], pro.shape[2]
def format_yolov5(frame):
row, col, _ = frame.shape
_max = max(col, row)
result = np.zeros((_max, _max, 3), np.uint8)
result[0:row, 0:col] = frame
return result
# # img_path 圖像完整路徑
# img_path = '20220904134315.jpg'
# model_path 量化模型完整路徑
model_path = 'yolov5s.bin'
# 類別名文件
classes_name_path = 'coco_classes.names'
# 設置參數
thre_confidence = 0.4
thre_score = 0.25
thre_nms = 0.45
# 框顏色設置
colors = [(255, 255, 0), (0, 255, 0), (0, 255, 255), (255, 0, 0)]
#利用opencv讀取攝像頭,對每個圖像進行實時處理
cap = cv2.VideoCapture(0)
i = 0
while (1):
ret, imgOri = cap.read()
# 1. 加載模型,獲取所需輸出HW
models = dnn.load(model_path)
model_h, model_w = get_hw(models[0].inputs[0].properties)
print(model_h, model_w)
# 2 加載圖像,根據前面模型,轉換后的模型是以NV12作為輸入的
# 但在OE驗證的時候,需要將圖像再由NV12轉為YUV444
inputImage = format_yolov5(imgOri)
img = imequalresize(inputImage, (model_w, model_h))
nv12 = bgr2nv12_opencv(img)
# 3 模型推理
t1 = cv2.getTickCount()
outputs = models[0].forward(nv12)
t2 = cv2.getTickCount()
outputs = outputs[0].buffer # 25200x85x1
print('time consumption {0} ms'.format((t2-t1)*1000/cv2.getTickFrequency()))
# 4 后處理
image_width, image_height, _ = inputImage.shape
fx, fy = image_width / model_w, image_height / model_h
t1 = cv2.getTickCount()
class_ids, confidences, boxes = yolotools.pypostprocess_yolov5(outputs[0][:, :, 0], fx, fy,
thre_confidence, thre_score, thre_nms)
t2 = cv2.getTickCount()
print('post consumption {0} ms'.format((t2-t1)*1000/cv2.getTickFrequency()))
# 5 繪制檢測框
with open(classes_name_path, "r") as f:
class_list = [cname.strip() for cname in f.readlines()]
t1 = cv2.getTickCount()
for (classid, confidence, box) in zip(class_ids, confidences, boxes):
color = colors[int(classid) % len(colors)]
cv2.rectangle(imgOri, box, color, 2)
cv2.rectangle(imgOri, (box[0], box[1] - 20), (box[0] + box[2], box[1]), color, -1)
cv2.putText(imgOri, class_list[classid], (box[0], box[1] - 10), cv2.FONT_HERSHEY_SIMPLEX, .5, (0,0,0))
t2 = cv2.getTickCount()
print('draw rect consumption {0} ms'.format((t2-t1)*1000/cv2.getTickFrequency()))
# print('draw rect consumption {0} inputImage = format_yolov5(imgOri)')
img = imequalresize(inputImage, (model_w, model_h))
nv12 = bgr2nv12_opencv(img)
k = cv2.waitKey(1)
if k == 27: # 按下ESC退出窗口
break
elif k == ord('s'): # 按下s保存圖片
cv2.imwrite('./' + str(i) + '.jpg', imgOri)
i += 1
cv2.imshow("capture", imgOri)
cap.release()
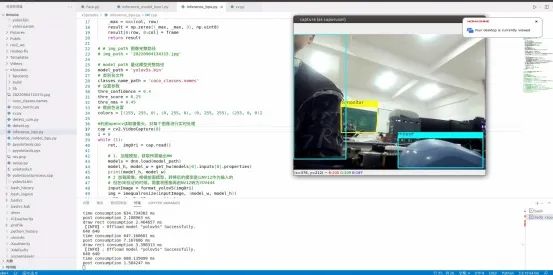
輸入sudo python3 inference_bpu.py,效果演示如下圖
六. 利用Cython封裝后處理代碼
①寫后處理的C++代碼
首先,創建頭文件yolotools.h,用來記錄函數聲明,方便其他代碼調用。
因為Cython調用時,調用C++的一些類并不方便,所以寫成C語言接口更方便調用。后處理的函數名為postprocess_yolov5,創建 yolov5postprocess.cpp來對后處理函數進行實現。
②寫Cython所需的Pyx文件
同級目錄下創建pyyolotools.pyx,切記文件名不要跟某個CPP重復了,因為cython會將pyyolotools.pyx轉為pyyolotools.cpp,如果有重復的話可能會導致文件被覆蓋掉。
③寫編譯Pyx所需的python代碼
創建setup.py文件,將下面代碼放進去,配置好opencv的頭文件目錄、庫目錄、以及所需的庫文件。
在Extension中配置封裝的函數所依賴的文件,然后在控制臺輸入python3 setup.py build_ext --inplace即 。
審核編輯:湯梓紅
-
Linux
+關注
關注
87文章
11515瀏覽量
213959 -
Ubuntu
+關注
關注
5文章
592瀏覽量
31326 -
模型
+關注
關注
1文章
3524瀏覽量
50474 -
python
+關注
關注
56文章
4827瀏覽量
86893 -
鏡像
+關注
關注
0文章
178瀏覽量
11260
原文標題:使用旭日X3派的BPU部署Yolov5
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
【地平線旭日X3派試用體驗】開箱篇硬件介紹
【 地平線旭日X3派試用體驗】01. X3派開箱及上手
#旭日X3派首百嘗鮮# 用solidworks畫了一個旭日X3派的模型
【 地平線旭日X3派試用體驗】地平線旭日X3派AGV智能車設計



旭日X3派首百嘗鮮 | 借助旭日X3派玩轉智能家居

旭日X3派BPU部署教程系列之帶你輕松走出模型部署新手村

旭日X3派BPU部署教程系列之手把手帶你成功部署YOLOv5

當旭日X3派遇上ChatGPT,我們能「chat」什么





 工商網監
工商網監

評論