") AI安全發(fā)展概述
AI安全發(fā)展概述
AI安全發(fā)展概述
人工智能概述
人工智能基本概念
1956 年,在美國達(dá)特茅斯會議上,科學(xué)家麥卡錫首次提出“人工智能”:人工智能就是要讓機(jī)器的行為看起來更像人所表現(xiàn)出的智能行為一樣。在人工智能概念提出時(shí),科學(xué)家主要確定了智能的判別標(biāo)準(zhǔn)和研究目標(biāo),而沒有回答智能的具體內(nèi)涵。之后,包括美國的溫斯頓、尼爾遜和中國的鐘義信等知名學(xué)者都對人工智能內(nèi)涵提出了各自見解,反映人工智能的基本思想和基本內(nèi)容:研究如何應(yīng)用計(jì)算機(jī)模擬人類智能行為的基本理論、方法和技術(shù)。但是,由于人工智能概念不斷演進(jìn),目前未形成統(tǒng)一定義。?? 結(jié)合業(yè)界專家觀點(diǎn)認(rèn)為,人工智能是利用人為制造來實(shí)現(xiàn)智能機(jī)器或者機(jī)器上的智能系統(tǒng),模擬、延伸和擴(kuò)展人類智能,感知環(huán)境,獲取知識并使用知識獲得最佳結(jié)果的理論、方法和技術(shù)。
人工智能發(fā)展歷程
人工智能自 1956 年誕生至今已有六十多年的歷史,在其發(fā)展過程中,形成了符號主義、連接主義、行為主義等多個(gè)學(xué)派,取得了一些里程碑式研究成果。但是,受到各個(gè)階段科學(xué)認(rèn)知水平和信息處理能力限制,人工智能發(fā)展經(jīng)歷了多輪潮起潮落,曾多次陷入低谷。?? 進(jìn)入新世紀(jì)以來,隨著云計(jì)算和大數(shù)據(jù)技術(shù)的發(fā)展,為人工智能提供了超強(qiáng)算力和海量數(shù)據(jù),另外,以 2006 年深度學(xué)習(xí)模型的提出為標(biāo)志,人工智能核心算法取得重大突破并不斷優(yōu)化,與此同時(shí),移動(dòng)互聯(lián)網(wǎng)、物聯(lián)網(wǎng)的發(fā)展為人工智能技術(shù)落地提供了豐富應(yīng)用場景。算力、算法、數(shù)據(jù)和應(yīng)用場景的共同作用,激發(fā)了新一輪人工智能發(fā)展浪潮,人工智能技術(shù)與產(chǎn)業(yè)發(fā)展呈現(xiàn)加速態(tài)勢。?? 從整體發(fā)展階段看,人工智能可劃分為弱人工智能、強(qiáng)人工智能和超人工智能三個(gè)階段。弱人工智能擅長于在特定領(lǐng)域、有限規(guī)則內(nèi)模擬和延伸人的智能;強(qiáng)人工智能具有意識、自我和創(chuàng)新思維,能夠進(jìn)行思考、計(jì)劃、解決問題、抽象思維、理解復(fù)雜理念、快速學(xué)習(xí)和從經(jīng)驗(yàn)中學(xué)習(xí)等人類級別智能的工作;超人工智能是在所有領(lǐng)域都大幅超越人類智能的機(jī)器智能。雖然人工智能經(jīng)歷了多輪發(fā)展,但仍處于弱人工智能階段,只是處理特定領(lǐng)域問題的專用智能。對于何時(shí)能達(dá)到甚至是否能達(dá)到強(qiáng)人工智能,業(yè)界尚未形成共識。
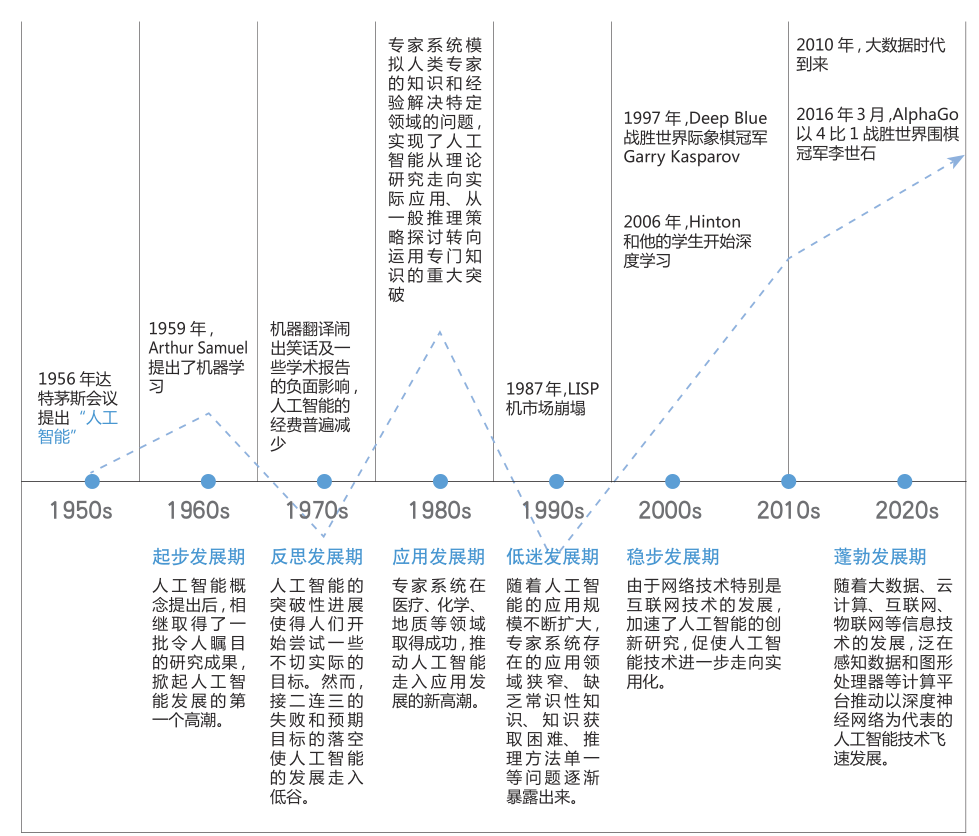
人工智能發(fā)展歷程圖
人工智能技術(shù)應(yīng)用
近年來,隨著大數(shù)據(jù)、云計(jì)算、互聯(lián)網(wǎng)、物聯(lián)網(wǎng)等信息技術(shù)的發(fā)展,泛在感知數(shù)據(jù)和圖形處理器等計(jì)算平臺推動(dòng)以深度神經(jīng)網(wǎng)絡(luò)為代表的人工智能技術(shù)飛速發(fā)展。人工智能在算法、算力和數(shù)據(jù)三大因素的共同驅(qū)動(dòng)下迎來了第三次發(fā)展浪潮,尤其是以深度學(xué)習(xí)為代表的機(jī)器學(xué)習(xí)算法及以語音識別、自然語言處理、圖像識別為代表的感知智能技術(shù)取得顯著進(jìn)步。專用人工智能即面向特定領(lǐng)域的人工智能,在計(jì)算機(jī)視覺、語音識別、機(jī)器翻譯、人機(jī)博弈等方面可以接近、甚至超越人類水平。與此同時(shí),機(jī)器學(xué)習(xí)、知識圖譜、自然語言處理等多種人工智能關(guān)鍵技術(shù)從實(shí)驗(yàn)室走向應(yīng)用市場。??
機(jī)器學(xué)習(xí)主要研究計(jì)算機(jī)等功能單元,是通過模擬人類學(xué)習(xí)方式獲取新知識或技能,或通過重組現(xiàn)有知識或技能來改善其性能的過程。深度學(xué)習(xí)作為機(jī)器學(xué)習(xí)研究中的一個(gè)新興領(lǐng)域,由Hinton等人于2006年提出。??
深度學(xué)習(xí)又稱為深度神經(jīng)網(wǎng)絡(luò)(層數(shù)超過3層的神經(jīng)網(wǎng)絡(luò)),是機(jī)器學(xué)習(xí)中一種基于對數(shù)據(jù)進(jìn)行表征學(xué)習(xí)的方法。在傳統(tǒng)機(jī)器學(xué)習(xí)中,手工設(shè)計(jì)特征對學(xué)習(xí)效果很重要,但是特征工程非常繁瑣,而深度學(xué)習(xí)基于多層次神經(jīng)網(wǎng)絡(luò),能夠從大數(shù)據(jù)中自動(dòng)學(xué)習(xí)特征,具有模型規(guī)模復(fù)雜、過程訓(xùn)練高效、結(jié)果訓(xùn)練準(zhǔn)確等特點(diǎn)。??
自然語言處理,研究能實(shí)現(xiàn)人與計(jì)算機(jī)之間用自然語言進(jìn)行有效通信的各種理論和方法。人機(jī)交互,主要研究人和計(jì)算機(jī)之間的信息交換,包括人到計(jì)算機(jī)和計(jì)算機(jī)到人的兩部分信息交換。計(jì)算機(jī)視覺,是使用計(jì)算機(jī)模仿人類視覺系統(tǒng)的科學(xué),讓計(jì)算機(jī)擁有類似人類提取、處理、理解和分析圖像以及圖像序列的能力。生物特征識別,是指通過個(gè)體生理特征或行為特征對個(gè)體身份進(jìn)行識別認(rèn)證的技術(shù)。智能語音,主要研究通過計(jì)算機(jī)等功能單元對人的語音所表示的信息進(jìn)行感知、分析和合成。
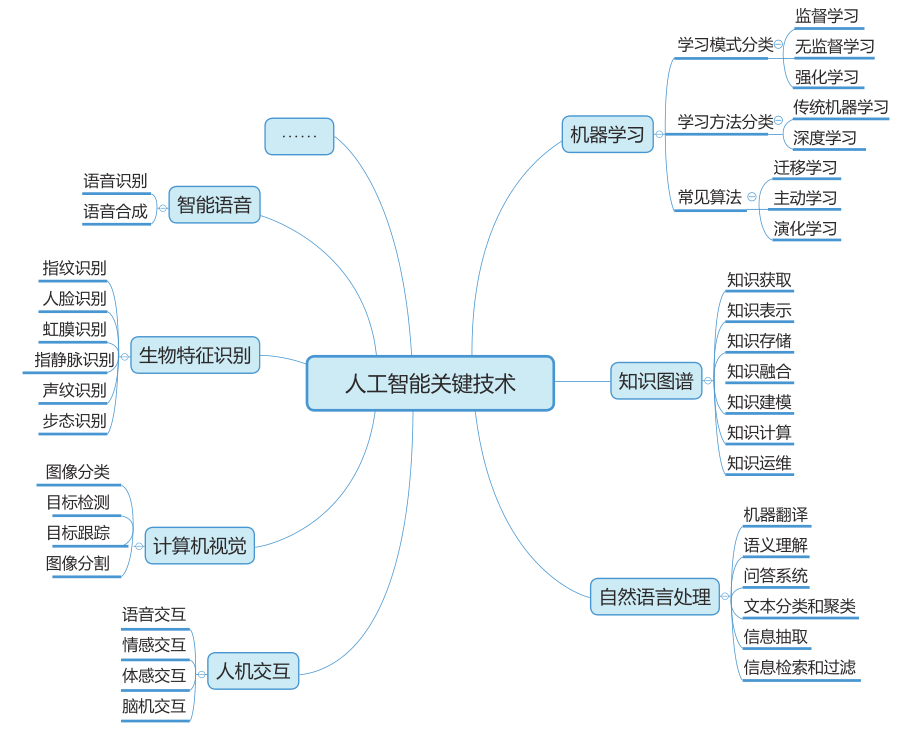
人工智能關(guān)鍵技術(shù)
人工智能產(chǎn)業(yè)結(jié)構(gòu)
當(dāng)前,全球人工智能產(chǎn)業(yè)鏈已初具規(guī)模,形成多層產(chǎn)業(yè)結(jié)構(gòu),其中基礎(chǔ)層是人工智能的基礎(chǔ)支撐,提供計(jì)算力、數(shù)據(jù)等基礎(chǔ)資源;技術(shù)層是人工智能的技術(shù)體系,提供算法開發(fā)的軟件框架、算法模型、關(guān)鍵技術(shù);應(yīng)用層實(shí)現(xiàn)人工智能應(yīng)用,提供人工智能產(chǎn)品、服務(wù)、行業(yè)應(yīng)用解決方案等。

人工智能產(chǎn)業(yè)結(jié)構(gòu)
人工智能安全法律法規(guī)和政策
國內(nèi)政策情況
我國已發(fā)布了一系列的人工智能相關(guān)政策法規(guī),圍繞促進(jìn)產(chǎn)業(yè)技術(shù)發(fā)展出臺了相關(guān)政策文件,包括《新一代人工智能發(fā)展規(guī)劃》(以下簡稱《發(fā)展規(guī)劃》)、《促進(jìn)新一代人工智能產(chǎn)業(yè)發(fā)展三年行動(dòng)計(jì)劃( 2018-2020年)》(以下簡稱《行動(dòng)計(jì)劃》)、《“互聯(lián)網(wǎng)+”人工智能三年行動(dòng)實(shí)施方案》、《關(guān)于促進(jìn)人工智能和實(shí)體經(jīng)濟(jì)深度融合的指導(dǎo)意見》和《國家新一代人工智能創(chuàng)新發(fā)展試驗(yàn)區(qū)建設(shè)工作指引》等。這些文件中均提出了人工智能安全和倫理等方面的要求,主要關(guān)注人工智能倫理道德、安全監(jiān)管、評估評價(jià)、監(jiān)測預(yù)警等方面,加強(qiáng)人工智能技術(shù)在網(wǎng)絡(luò)安全的深度應(yīng)用,《發(fā)展規(guī)劃》提出要“制定促進(jìn)人工智能發(fā)展的法律法規(guī)和倫理規(guī)范”。
國外政策情況
聯(lián)合國:
聚焦人身安全和倫理道德,自動(dòng)駕駛、機(jī)器人、人工智能犯罪等領(lǐng)域逐步深入。目前,聯(lián)合國對人工智能安全的研究主要聚焦于人身安全、倫理道德、潛在威脅和挑戰(zhàn)等方面,關(guān)注人工智能對人身安全、社會安全和經(jīng)濟(jì)發(fā)展的影響和挑戰(zhàn),目前已發(fā)布了自動(dòng)駕駛、智能機(jī)器人等領(lǐng)域的相關(guān)法律法規(guī)和研究成果,相關(guān)研究正逐步深入。?? 2016年,聯(lián)合國歐洲經(jīng)濟(jì)委員會通過修正案修改了《維也納道路交通公約》(以下簡稱“《公約》”)。?? 2017年9月,聯(lián)合國教科文組織與世界科學(xué)知識與技術(shù)倫理委員會聯(lián)合發(fā)布了《機(jī)器人倫理報(bào)告》,指出機(jī)器人的制造和使用促進(jìn)了人工智能的進(jìn)步,并討論了這些進(jìn)步所帶來的社會與倫理道德問題。?? 2017年,在荷蘭和海牙市政府的支持下,聯(lián)合國在荷蘭建立人工智能和機(jī)器人中心,以跟進(jìn)人工智能和機(jī)器人技術(shù)的最新發(fā)展。該辦事處也將聯(lián)合聯(lián)合國區(qū)域間犯罪和司法研究所(UNICRI)共同處理與犯罪相聯(lián)系的人工智能和機(jī)器人帶來的安全影響和風(fēng)險(xiǎn)。
美國:
關(guān)注人工智能設(shè)計(jì)安全,采用標(biāo)準(zhǔn)規(guī)范和驗(yàn)證評估減少惡意攻擊風(fēng)險(xiǎn)。
2019年2月,美國總統(tǒng)簽署行政令,啟動(dòng)“美國人工智能倡議”。該倡議提出應(yīng)在人工智能研發(fā)、數(shù)據(jù)資源共享、標(biāo)準(zhǔn)規(guī)范制定、人力資源培養(yǎng)和國際合作五個(gè)領(lǐng)域重點(diǎn)發(fā)力。其中,標(biāo)準(zhǔn)規(guī)范制定的目標(biāo)是確保技術(shù)標(biāo)準(zhǔn)最大限度減少惡意攻擊可利用的漏洞,促進(jìn)公眾對人工智能創(chuàng)新技術(shù)的信任。??
2019年6月美國對《國家人工智能研究與發(fā)展戰(zhàn)略計(jì)劃》進(jìn)行了更新,在2016年版本的基礎(chǔ)上提出長期投資人工智能研究、應(yīng)對倫理和法律社會影響、確保人工智能系統(tǒng)安全、開發(fā)共享的公共數(shù)據(jù)集和環(huán)境、通過標(biāo)準(zhǔn)評估技術(shù)等八個(gè)戰(zhàn)略重點(diǎn)。
歐盟:
重視人工智能倫理道德,對人工智能帶來挑戰(zhàn)。
2017年,歐洲議會曾通過一項(xiàng)立法決議,提出要制定“機(jī)器人憲章”,推動(dòng)人工智能和機(jī)器人民事立法。2018年4月,歐盟委員會發(fā)布《歐盟人工智能戰(zhàn)略》,通過提高技術(shù)和產(chǎn)業(yè)能力、應(yīng)對社會經(jīng)濟(jì)變革、建立適當(dāng)?shù)膫惱砗头煽蚣苋笾е瑏泶_立歐盟人工智能價(jià)值觀。 ??2019年4月8日,歐盟委員會發(fā)布了由人工智能高級專家組編制的《人工智能道德準(zhǔn)則》,列出了人工智能可信賴的七大原則,以確保人工智能應(yīng)用符合道德,技術(shù)足夠穩(wěn)健可靠,從而發(fā)揮其最大的優(yōu)勢并將風(fēng)險(xiǎn)降到最低。其中,可信賴人工智能有兩個(gè)組成部分:一是應(yīng)尊重基本人權(quán)、規(guī)章制度、核心原則及價(jià)值觀;二是應(yīng)在技術(shù)上安全可靠,避免因技術(shù)不足而造成無意的傷害。
人中智能安全問題
AI安全面臨的挑戰(zhàn)
AI有巨大的潛能改變?nèi)祟惷\(yùn),但同樣存在巨大的安全風(fēng)險(xiǎn)。這種安全風(fēng)險(xiǎn)存在的根本原因是AI算法設(shè)計(jì)之初普遍未 考慮相關(guān)的安全威脅,使得AI算法的判斷結(jié)果容易被惡意攻擊者影響,導(dǎo)致AI系統(tǒng)判斷失準(zhǔn)。?? 在工業(yè)、醫(yī)療、交通、 監(jiān)控等關(guān)鍵領(lǐng)域,安全危害尤為巨大;如果AI系統(tǒng)被惡意攻擊,輕則造成財(cái)產(chǎn)損失,重則威脅人身安全。AI安全風(fēng)險(xiǎn)不僅僅存在于理論分析,并且真實(shí)的存在于現(xiàn)今各種AI應(yīng)用中。例如攻擊者通過修改惡意文件繞開惡意文 件檢測或惡意流量檢測等基于AI的檢測工具;加入簡單的噪音,致使家中的語音控制系統(tǒng)成功調(diào)用惡意應(yīng)用;刻意修 改終端回傳的數(shù)據(jù)或刻意與聊天機(jī)器人進(jìn)行某些惡意對話,導(dǎo)致后端AI系統(tǒng)預(yù)測錯(cuò)誤;在交通指示牌或其他車輛上貼 上或涂上一些小標(biāo)記,致使自動(dòng)駕駛車輛的判斷錯(cuò)誤。應(yīng)對上述AI安全風(fēng)險(xiǎn),AI系統(tǒng)在設(shè)計(jì)上面臨五大安全挑戰(zhàn):
軟硬件的安全:
在軟件及硬件層面,包括應(yīng)用、模型、平臺和芯片,編碼都可能存在漏洞或后門;攻擊者能夠利 用這些漏洞或后門實(shí)施高級攻擊。在AI模型層面上,攻擊者同樣可能在模型中植入后門并實(shí)施高級攻擊;由于AI 模型的不可解釋性,在模型中植入的惡意后門難以被檢測。
數(shù)據(jù)完整性:
在數(shù)據(jù)層面,攻擊者能夠在訓(xùn)練階段摻入惡意數(shù)據(jù),影響AI模型推理能力;攻擊者同樣可以在判斷 階段對要判斷的樣本加入少量噪音,刻意改變判斷結(jié)果。
模型保密性:
在模型參數(shù)層面,服務(wù)提供者往往只希望提供模型查詢服務(wù),而不希望曝露自己訓(xùn)練的模型;但通 過多次查詢,攻擊者能夠構(gòu)建出一個(gè)相似的模型,進(jìn)而獲得模型的相關(guān)信息。
模型魯棒性:
訓(xùn)練模型時(shí)的樣本往往覆蓋性不足,使得模型魯棒性不強(qiáng);模型面對惡意樣本時(shí),無法給出正確的 判斷結(jié)果。
數(shù)據(jù)隱私:
在用戶提供訓(xùn)練數(shù)據(jù)的場景下,攻擊者能夠通過反復(fù)查詢訓(xùn)練好的模型獲得用戶的隱私信息。
AI安全典型攻擊方式
人工智能系統(tǒng)作為采用人工智能技術(shù)的信息系統(tǒng),除了會遭受拒絕服務(wù)等傳統(tǒng)網(wǎng)絡(luò)攻擊威脅外,也會面臨針對人工智能系統(tǒng)的一些特定攻擊,這些攻擊特別影響使用機(jī)器學(xué)習(xí)的系統(tǒng)。
對抗樣本攻擊
是指在輸入樣本中添加細(xì)微的、通常無法識別的干擾,導(dǎo)致模型以高置信度給出一個(gè)錯(cuò)誤的輸出。研究表明深度學(xué)習(xí)系統(tǒng)容易受到精心設(shè)計(jì)的對抗樣本的影響,可能導(dǎo)致系統(tǒng)出現(xiàn)誤判或漏判等錯(cuò)誤結(jié)果。對抗樣本攻擊也可來自物理世界,通過精心構(gòu)造的交通標(biāo)志對自動(dòng)駕駛進(jìn)行攻擊。?? Eykholt等人的研究表明一個(gè)經(jīng)過稍加修改的實(shí)體停車標(biāo)志,能夠使得一個(gè)實(shí)時(shí)的目標(biāo)檢測系統(tǒng)將其誤識別為限速標(biāo)志,從而可能造成交通事故。?? 攻擊者利用精心構(gòu)造的對抗樣本,也可發(fā)起模仿攻擊、逃避攻擊等欺騙攻擊。模仿攻擊通過對受害者樣本的模仿,達(dá)到獲取受害者權(quán)限的目的,目前主要出現(xiàn)在基于機(jī)器學(xué)習(xí)的圖像識別系統(tǒng)和語音識別系統(tǒng)中。逃避攻擊是早期針對機(jī)器學(xué)習(xí)的攻擊形式,比如垃圾郵件檢測系統(tǒng)、PDF文件中的惡意程序檢測系統(tǒng)等。通過產(chǎn)生一些可以成功逃避安全系統(tǒng)檢測的對抗樣本,實(shí)現(xiàn)對系統(tǒng)的惡意攻擊。
數(shù)據(jù)投毒
主要是在訓(xùn)練數(shù)據(jù)中加入精心構(gòu)造的異常數(shù)據(jù),破壞原有的訓(xùn)練數(shù)據(jù)的概率分布,導(dǎo)致模型在某些條件會產(chǎn)生分類或聚類錯(cuò)誤。由于數(shù)據(jù)投毒攻擊需要攻擊者接觸訓(xùn)練數(shù)據(jù),通常針對在線學(xué)習(xí)場景(即模型利用在線數(shù)據(jù)不斷學(xué)習(xí)更新模型),或者需要定期重新訓(xùn)練進(jìn)行模型更新的系統(tǒng),這類攻擊比較有效,典型場景如推薦系統(tǒng)、自適應(yīng)生物識別系統(tǒng)、垃圾郵件檢測系統(tǒng)等。正確過濾訓(xùn)練數(shù)據(jù)可以幫助檢測和過濾異常數(shù)據(jù),從而最大程度地減少可能的數(shù)據(jù)投毒攻擊。
模型竊取
是指向目標(biāo)模型發(fā)送大量預(yù)測查詢,使用接收到的響應(yīng)來訓(xùn)練另一個(gè)功能相同或類似的模型,或采用逆向攻擊技術(shù)獲取模型的參數(shù)及訓(xùn)練數(shù)據(jù)。針對云模式部署的模型,攻擊者通常利用機(jī)器學(xué)習(xí)系統(tǒng)提供的一些應(yīng)用程序編程接口(API)來獲取系統(tǒng)模型的初步信息,進(jìn)而通過這些初步信息對模型進(jìn)行逆向分析,從而獲取模型內(nèi)部的訓(xùn)練數(shù)據(jù)和運(yùn)行時(shí)采集的數(shù)據(jù)。針對私有部署到用戶的移動(dòng)設(shè)備或數(shù)據(jù)中心的服務(wù)器上的模型,攻擊者通過逆向等傳統(tǒng)安全技術(shù),可以把模型文件直接還原出來使用。
人工智能攻擊
對機(jī)器學(xué)習(xí)系統(tǒng)的典型攻擊是影響數(shù)據(jù)機(jī)密性及數(shù)據(jù)和計(jì)算完整性的攻擊,還有其他攻擊形式導(dǎo)致拒絕服務(wù)、信息泄露或無效計(jì)算。例如,對機(jī)器學(xué)習(xí)系統(tǒng)的控制流攻擊可能會破壞或規(guī)避機(jī)器學(xué)習(xí)模型推斷或?qū)е聼o效的訓(xùn)練。機(jī)器學(xué)習(xí)系統(tǒng)使用的復(fù)雜設(shè)備模型(如硬件加速器)大多是半虛擬化或仿真的,可能遭受設(shè)備欺騙,運(yùn)行時(shí)內(nèi)存重新映射攻擊及中間人設(shè)備等攻擊。
AI安全常用的防御手段
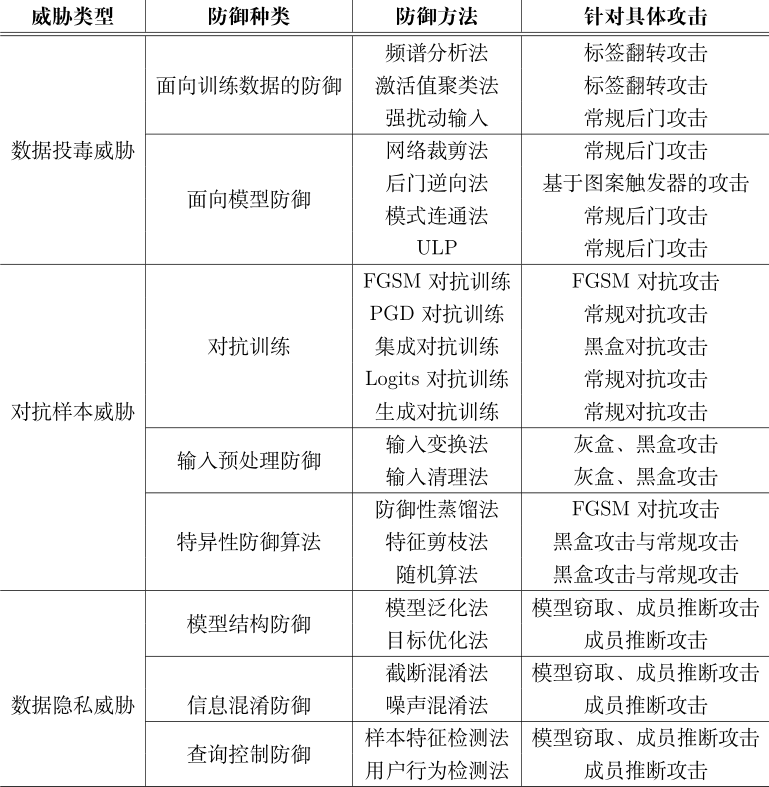
AI安全常用防御技術(shù)
AI 模型自身在訓(xùn)練與測試階段遇到的安全威脅,包括投毒攻擊、對抗樣本攻擊和魯棒性缺乏威脅。為了應(yīng)對這些威脅,學(xué)術(shù)界與工業(yè)界已經(jīng)提出了許多有效的防御方法。這些防御方法從模型自身性質(zhì)出發(fā),針對性地增強(qiáng)了模型自身在真實(shí)場景下的魯棒性。AI 模型訓(xùn)練階段主要存在的威脅是數(shù)據(jù)投毒攻擊,它可以非常隱蔽地破壞模型的完整性。?? 近些年來,研究者們提出了多種針對數(shù)據(jù)投毒攻擊的防御方法。由于傳統(tǒng)意義上的有目標(biāo)的數(shù)據(jù)投毒攻擊可以看作是后門攻擊的一種特殊情況。根據(jù)防御技術(shù)的部署場景,這些方法可以分為兩類,分別是面向訓(xùn)練數(shù)據(jù)的防御和面向模型的防御。 ?? 面向訓(xùn)練數(shù)據(jù)的防御部署在模型訓(xùn)練數(shù)據(jù)集上,適用于訓(xùn)練數(shù)據(jù)的來源不被信任的場景; ?? 面向模型的防御主要應(yīng)用于檢測預(yù)訓(xùn)練模型是否被毒化,若被毒化則嘗試修復(fù)模型中被毒化的部分,這適用于模型中可能已經(jīng)存在投毒攻擊的場景。 ?? AI 模型在預(yù)測階段主要存在的威脅為對抗樣本攻擊。近些年來,研究者們提出了多種對抗樣本防御技術(shù),這些技術(shù)被稱為對抗防御 (Adversarial Defense)。對抗防御可以分為啟發(fā)式防御和可證明式防御兩類。啟發(fā)式防御算法對一些特定的對抗攻擊具有良好的防御性能,但其防御性能沒有理論性的保障,意味著啟發(fā)式防御技術(shù)在未來很有可能被擊破。 ?? 可證明式防御通過理論證明,計(jì)算出特定對抗攻擊下模型的最低準(zhǔn)確度,即在理論上保證模型面對攻擊時(shí)性能的下界。 ?? 根據(jù)防御算法的作用目標(biāo)不同分為三類:分別是對抗訓(xùn)練、輸入預(yù)處理以及特異性防御算法。 ?? 對抗訓(xùn)練通過將對抗樣本納入訓(xùn)練階段來提高深度學(xué)習(xí)網(wǎng)絡(luò)主動(dòng)防御對抗樣本的能力; ?? 輸入預(yù)處理技術(shù)通過對輸入數(shù)據(jù)進(jìn)行恰當(dāng)?shù)念A(yù)處理,消除輸入數(shù)據(jù)中可能的對抗性擾動(dòng),從而達(dá)到凈化輸入數(shù)據(jù)的功能; ?? 特異性防御算法通過修改現(xiàn)有的網(wǎng)絡(luò)結(jié)構(gòu)或算法來達(dá)到防御對抗攻擊的目的。 ?? 除了訓(xùn)練與預(yù)測階段存在的威脅,AI 模型還存在魯棒性缺乏風(fēng)險(xiǎn)。魯棒性缺乏是指模型在面對多變的真實(shí)場景時(shí)泛化能力有限,導(dǎo)致模型產(chǎn)生不可預(yù)測的誤判行為。為了增強(qiáng) AI 模型的魯棒性,提高模型的泛化能力,增強(qiáng)現(xiàn)實(shí)場景下模型應(yīng)對多變環(huán)境因素時(shí)模型的穩(wěn)定性,研究人員提出了數(shù)據(jù)增強(qiáng)和可解釋性增強(qiáng)技術(shù):數(shù)據(jù)增強(qiáng)技術(shù)的目標(biāo)是加強(qiáng)數(shù)據(jù)的收集力度并增強(qiáng)訓(xùn)練數(shù)據(jù)中環(huán)境因素的多樣性,使模型能夠盡可能多地學(xué)習(xí)到各種真實(shí)場景下的樣本特征,進(jìn)而增強(qiáng)模型對多變環(huán)境的適應(yīng)性;可解釋性增強(qiáng)技術(shù)的目標(biāo)是解釋模型是如何進(jìn)行決策的以及為何模型能夠擁有較好的性能。
面向訓(xùn)練數(shù)據(jù)的防御
Chen 等人提出基于激活值聚類(Activation Clustering)的方法來檢測含有后門的數(shù)據(jù)。他們認(rèn)為含有后門的任意類別樣本與不含后門的目標(biāo)類別樣本若能得到相同的分類結(jié)果,會在神經(jīng)網(wǎng)絡(luò)的激活值中體現(xiàn)出差異。在使用收集的數(shù)據(jù)訓(xùn)練得到模型后,他們將數(shù)據(jù)輸入到模型并提取模型最后一層的激活值,然后使用獨(dú)立成分分析(Independent Component Analysis, ICA)將激活值進(jìn)行降維,最后使用聚類算法來區(qū)分含有后門的數(shù)據(jù)和正常的數(shù)據(jù)。??
Gao 等人 提出 STRIP 算法來檢測輸入數(shù)據(jù)中是否含有后門。他們對輸入數(shù)據(jù)進(jìn)行有意圖的強(qiáng)擾動(dòng)(將輸入的數(shù)據(jù)進(jìn)行疊加),利用含有后門的任意輸入都會被分類為目標(biāo)類別的特點(diǎn)(若模型含有后門,含有后門的輸入數(shù)據(jù)在疊加后都會被分類為目標(biāo)類別,而正常數(shù)據(jù)疊加后的分類結(jié)果則相對隨機(jī)),通過判斷模型輸出分類結(jié)果的信息熵來區(qū)分含有后門的輸入數(shù)據(jù)。
面向模型的防御
面向模型的防御試圖檢測模型中是否含有后門,若含有則將后門消除。??
Liu 等人提出使用剪枝 (Pruning)、微調(diào) (Fine Tuning) 以及基于微調(diào)的剪枝 (FinePruning) 等三種方法來消除模型的后門。他們基于 Gu 等發(fā)現(xiàn)的后門觸發(fā)器會在模型的神經(jīng)元上產(chǎn)生較大的激活值使得模型誤分類的現(xiàn)象,提出通過剪枝的操作來刪除模型中與正常分類無關(guān)的神經(jīng)元的方法來防御后門攻擊。他們提取正常數(shù)據(jù)在模型神經(jīng)元上的激活值,根據(jù)從小到大的順序?qū)ι窠?jīng)網(wǎng)絡(luò)進(jìn)行剪枝,直到剪枝后的模型在數(shù)據(jù)集上的正確率不高于預(yù)先設(shè)定的閾值為止。然而,若攻擊者意識到防御者可能采取剪枝防御操作,將后門特征嵌入到與正常特征激活的相關(guān)神經(jīng)元上,這種防御策略將會失效。應(yīng)對這種攻擊,研究人員發(fā)現(xiàn)通過使用干凈數(shù)據(jù)集對模型進(jìn)行微調(diào)便可以有效地消除模型中的后門,因此結(jié)合剪枝和微調(diào)的防御方法能在多種場景下消除模型中的后門。?? Wang 等人提出 Neural Cleanse 來發(fā)現(xiàn)并消除模型中可能存在的后門。他們根據(jù)含有后門的任意輸入都會被分類為目標(biāo)類別的特點(diǎn),通過最小化使得所有輸入都被誤分類為目標(biāo)類別的擾動(dòng)來逆向模型中存在的后門。
對抗訓(xùn)練
對抗訓(xùn)練 (Adversarial Training) 是針對對抗攻擊的最為直觀防御方法,它使用對抗樣本和良性樣本同時(shí)作為訓(xùn)練數(shù)據(jù)對神經(jīng)網(wǎng)絡(luò)進(jìn)行對抗訓(xùn)練,訓(xùn)練獲得的 AI 模型可以主動(dòng)防御對抗攻擊。對抗訓(xùn)練過程可以被歸納為 MIN-MAX 過程表述為:
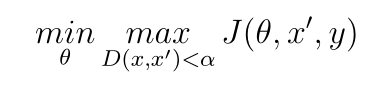
其中 J(θ, x′, y) 是對抗攻擊的損失函數(shù),θ 是模型參數(shù),x′ 是對抗樣本,y 是樣本 x的正確標(biāo)簽。內(nèi)部的最大化損失函數(shù)的目的是找出有效的對抗樣本,外部的最小化優(yōu)化問題目的是減小對抗樣本造成的損失函數(shù)升高。
輸入預(yù)處理防御
基于輸入預(yù)處理的對抗防御方法通過對輸入數(shù)據(jù)進(jìn)行恰當(dāng)?shù)念A(yù)處理,消除輸入數(shù)據(jù)中存在的對抗性擾動(dòng)。預(yù)處理后的輸入數(shù)據(jù)將代替原輸入樣本輸入網(wǎng)絡(luò)進(jìn)行分類,使模型獲得正確的分類結(jié)果。輸入預(yù)處理防御是一種簡單有效的防御方法,它可以很容易地集成到已有的 AI 系統(tǒng)中。?? 圖片分類系統(tǒng)中的預(yù)處理模塊與分類模型通常是解耦的,因此很容易將輸入預(yù)處理防御方法集成到預(yù)處理模塊中。一類數(shù)據(jù)預(yù)處理方法使用 JPEG 壓縮、濾波、圖像模糊、分辨率調(diào)整等方來對輸入圖像進(jìn)行預(yù)處理。?? Xie 等人提出一種將圖片壓縮到隨機(jī)大小,然后再將壓縮后的圖片固定到隨機(jī)位置并向周圍補(bǔ)零填充的預(yù)處理防御方法。他們的這種防御方式在 NIPS 2017 對抗防御比賽黑盒賽道中獲得了較好的成績,但在白盒攻擊情況下可被 EoT 算法攻擊成功。 Guo 等人 嘗試使用位深度減小、JPEG壓縮、總方差最小化和圖像縫合等操作對輸入樣本進(jìn)行輸入預(yù)處理,以減輕對抗性擾動(dòng)對模型分類結(jié)果的影響。這種方法可以抵抗多種主流攻擊方法生成的灰盒和黑盒對抗樣本,但是它仍易受 EoT 算法的攻擊。輸入預(yù)處理除了可以直接防御對抗攻擊,還可以實(shí)現(xiàn)對抗樣本的檢測。?? Xu 等人分別利用位深度減小和模糊圖像兩種壓縮方法對輸入圖像進(jìn)行預(yù)處理,以減少輸入樣本的自由度,從而消除對抗性擾動(dòng)。他們通過比較原始圖像和被壓縮圖像輸入模型后的預(yù)測結(jié)果的差異大小,辨別輸入數(shù)據(jù)是否為對抗樣本。如果兩種輸入的預(yù)測結(jié)果差異超過某一閾值,則將原始輸入判別為對抗樣本。另一類輸入預(yù)處理技術(shù)依賴于輸入清理 (Input Cleansing) 技術(shù)。與傳統(tǒng)的基于輸入變換的輸入預(yù)處理技術(shù)不同,輸入清理利用機(jī)器學(xué)習(xí)算法學(xué)習(xí)良性樣本的數(shù)據(jù)分布,利用良性樣本的數(shù)據(jù)分布精準(zhǔn)地去除輸入輸入樣本中的對抗性擾動(dòng)。研究人員首先嘗試基于生成對抗網(wǎng)絡(luò) (GAN) 學(xué)習(xí)良性樣本的數(shù)據(jù)分布,并使用 GAN 進(jìn)行輸入清理。?? Samangouei 等人 提出使用防御對抗生成網(wǎng)絡(luò) (Defense-GAN) 進(jìn)行輸入清理。他們訓(xùn)練了一個(gè)學(xué)習(xí)了良性樣本數(shù)據(jù)分布的生成器,輸入數(shù)據(jù)在輸入神經(jīng)網(wǎng)絡(luò)進(jìn)行分類前,會預(yù)先在 Defense-GAN 學(xué)習(xí)到的數(shù)據(jù)分布中搜索最接近于原輸入數(shù)據(jù)的良性樣本。該良性樣本將替代原樣本,輸入神經(jīng)網(wǎng)絡(luò)進(jìn)行預(yù)測,使模型輸出正確的預(yù)測結(jié)果。?? Shen 等人 [98] 提出使用擾動(dòng)消除對抗生成網(wǎng)絡(luò) (Adversarial PerturbationElimination GAN,APE-GAN) 進(jìn)行輸入清理,其生成器的輸入是可能為對抗樣本的源數(shù)據(jù),輸出是清除對抗性擾動(dòng)后的良性樣本。此外,自動(dòng)編碼器技術(shù)也被證明可用于輸入清理。?? Meng 等人使用良性樣本數(shù)據(jù)集訓(xùn)練具有良性樣本數(shù)據(jù)分布的自動(dòng)編碼器。該自動(dòng)編碼器將把可能作為對抗樣本的輸入進(jìn)行重構(gòu),輸出與之對應(yīng)的良性樣本。與上述工作僅從輸入層面進(jìn)行輸入清理不同。?? Liao 等人 嘗試從更深層次的深度學(xué)習(xí)網(wǎng)絡(luò)特征圖層面進(jìn)行輸入清理。為了使輸入樣本在特征層面上沒有對抗性擾動(dòng),他們提出了高階表征指導(dǎo)的去噪器 (High-level Representation GuidedDenoiser, HGD)。HGD 訓(xùn)練了采用特征級損失函數(shù)的用于降噪的 U-Net,最大程度地減少良性樣本和對抗樣本在高維特征中的差異,從而去除對抗擾動(dòng)。基于輸入預(yù)處理的防御把防御的重點(diǎn)放在樣本輸入網(wǎng)絡(luò)之前,通過輸入變換或輸入清理技術(shù)消除了對抗樣本中的對抗性擾動(dòng),處理后的樣本對模型的攻擊性將大幅減弱。輸入預(yù)處理防御可以有效地防御黑盒和灰盒攻擊,然而對于在算法和模型全部暴露給攻擊者的白盒攻擊設(shè)置下,這些算法并不能保證良好的防御性能。
特異性防御算法
除了對抗訓(xùn)練和輸入預(yù)處理,很多工作通過優(yōu)化深度學(xué)習(xí)模型的結(jié)構(gòu)或算法來防御對抗攻擊,我們將其稱之為特異性防御算法。進(jìn)年來,越來越多的啟發(fā)式特異性對抗防御算法被提出,我們選取其中一些具有代表性的算法歸納如下。蒸餾算法被證明可以一定程度提高深度學(xué)習(xí)模型的魯棒性。?? Hinton 等人最早提出蒸餾算法 (Distillation),該算法可以做到從復(fù)雜網(wǎng)絡(luò)到簡單網(wǎng)絡(luò)的知識遷移。Papernot 等人在此基礎(chǔ)上進(jìn)一步提出了防御性蒸餾算法,防御性蒸餾模型的訓(xùn)練數(shù)據(jù)沒有使用硬判別標(biāo)簽 (明確具體類別的獨(dú)熱編碼向量),而是使用代表各類別概率的向量作為標(biāo)簽,這些概率標(biāo)簽可由早期使用硬判別標(biāo)簽訓(xùn)練的網(wǎng)絡(luò)獲得。研究者發(fā)現(xiàn)防御性蒸餾模型的輸出結(jié)果比較平滑,基于優(yōu)化的對抗攻擊算法在攻擊這種模型較難獲取有效的梯度,因此防御性蒸餾網(wǎng)絡(luò)獲得了較好的對抗攻擊的魯棒性。實(shí)驗(yàn)結(jié)果顯示,防御性蒸餾算法可以有效地防御 FGSM對抗攻擊。
魯棒性增強(qiáng)
魯棒性增強(qiáng)是指在復(fù)雜的真實(shí)場景下,增強(qiáng) AI 模型面對環(huán)境干擾以及多樣輸入時(shí)的穩(wěn)健性。目前,AI 模型仍然缺乏魯棒性,當(dāng)處于復(fù)雜惡劣的環(huán)境條件或面對非正常輸入時(shí),性能會出現(xiàn)一定的損失,做出的不盡人意的決策。魯棒性增強(qiáng)就是為了使模型在上述情況下依然能夠維持其性能水平,減少意外的決策失誤,可靠地履行其功能。構(gòu)建高魯棒性的 AI 模型不僅有助于提升模型在實(shí)際使用過程中的可靠性,同時(shí)能夠從根本上完善模型攻防機(jī)理的理論研究,是 AI 模型安全研究中重要的一部分。為了增強(qiáng)模型的魯棒性,可以從數(shù)據(jù)增強(qiáng)和可解釋性增強(qiáng)兩個(gè)方面進(jìn)行深入探索。
可解釋性增強(qiáng)
可解釋性增強(qiáng)一方面從機(jī)器學(xué)習(xí)理論的角度出發(fā),在模型的訓(xùn)練階段,通過選取或設(shè)計(jì)本身具有可解釋性的模型,為模型提高性能、增強(qiáng)泛化能力和魯棒性保駕護(hù)航;另一方面要求研究人員能夠解釋模型有效性,即在不改變模型本身的情況下探索模型是如何根據(jù)樣本輸入進(jìn)行決策的。針對模型可解釋性增強(qiáng),目前國內(nèi)外研究主要分為兩種類型:集成解釋(Integrated Interpretability)和后期解釋 (Post Hoc Interpretability)。
四、對抗樣本攻擊
本節(jié)介紹對抗樣本攻擊的基本原理進(jìn)行介紹,然后對其攻擊技巧與攻擊思路進(jìn)行了解。
4.1 對抗樣本攻擊的基本原理
對抗樣本攻擊主要通過在干凈樣本中添加人民難以察覺的細(xì)微擾動(dòng),來使正常訓(xùn)練的深度學(xué)習(xí)模型輸出置信度很高的錯(cuò)誤預(yù)測。對抗樣本攻擊的核心在于如何構(gòu)造細(xì)微擾動(dòng)。深度學(xué)習(xí)模型的訓(xùn)練過程如圖4.1所示,假設(shè)模型F的輸入為x,預(yù)測結(jié)果為F(x),真實(shí)類別標(biāo)簽為y,由F(x)和y求出損失函數(shù)L,通過反響傳播算法求出梯度并對模型F進(jìn)行優(yōu)化,不斷減少損失函數(shù)的值,直到模型收斂。深度學(xué)習(xí)模型的預(yù)測過程如圖4.2所示。一般而言,對于一個(gè)訓(xùn)練好的模型F,輸入樣本x,輸出F(x)=y,如圖4.3所示。
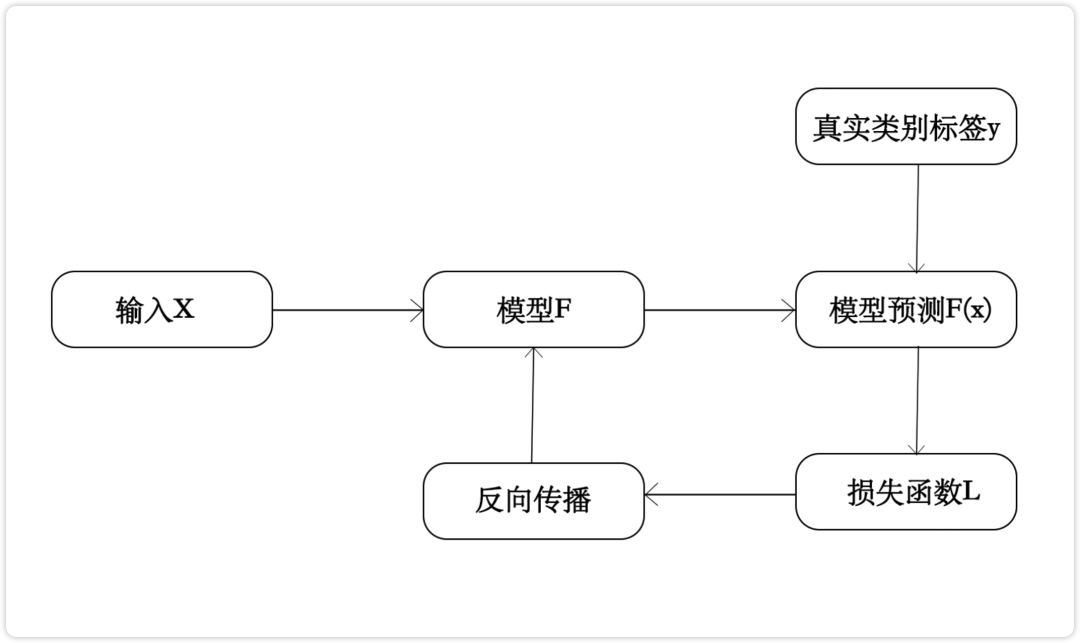
圖 4.1 深度學(xué)習(xí)模型的訓(xùn)練過程

圖4.2 深度學(xué)習(xí)模型的預(yù)測過程
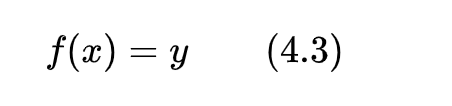
假設(shè)存在一個(gè)非常小的擾動(dòng)e,使得式(4.4)成立,即模型預(yù)測結(jié)果發(fā)生了改變,那么x+e就是一個(gè)對抗樣本,構(gòu)造e的方式就稱為對抗樣本攻擊。如圖4.5所示。
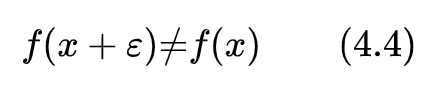
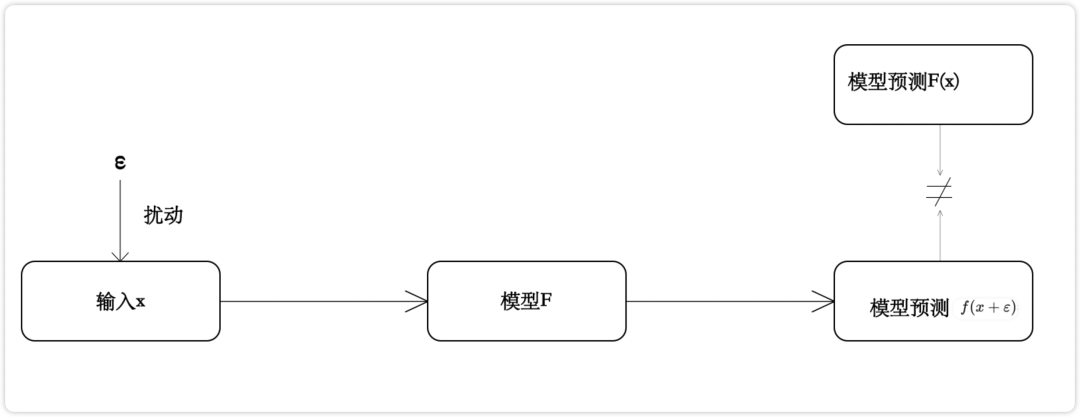
圖4.5 對抗樣本攻擊示意圖
對抗樣本攻擊常見的場景為圖像分類,通過在圖像上疊加精心構(gòu)造的變化量,在肉眼難以察覺的情況下,讓分類模型以較高的置信度產(chǎn)生錯(cuò)誤的預(yù)測。
4.2 對抗樣本攻擊的分類
對抗樣本攻擊按照攻擊后的效果可以分為定向攻擊(Targeted Attack)和非定向攻擊(Non-Targeted Attack)。
4.2.1 定向攻擊
定向攻擊是在將深度學(xué)習(xí)模型誤導(dǎo)至攻擊者指定的輸出,如在分類任務(wù)中指定將熊貓識別為牛。給出定向攻擊的目標(biāo)標(biāo)簽為牛,構(gòu)造相應(yīng)的擾動(dòng)e附加到輸入樣本熊貓x上,使得模型F的預(yù)測結(jié)果F(x+e)為牛。定向攻擊即要降低深度學(xué)習(xí)模型對輸入樣本真實(shí)標(biāo)簽的置信度,又要盡可能地提升攻擊者指定標(biāo)簽的置信度,因此攻擊難度較大。
4.2.2 非定向攻擊
非定向攻擊是在將深度學(xué)習(xí)模型誤導(dǎo)至錯(cuò)誤的類別,而不指定具體的類別,如在分類任務(wù)中將熊貓識別為非熊貓的任一類別即可。構(gòu)造擾動(dòng)e附加到輸入樣本熊貓x上,使得模型F的預(yù)測結(jié)果F(x+e)為非熊貓。非定向攻擊僅需要盡可能地降低深度學(xué)習(xí)模型對輸入樣本真實(shí)類別的置信度,因此攻擊難度相對較小。對抗樣本攻擊安裝攻擊環(huán)境可以分為白盒攻擊(White-Box Attack)和黑盒攻擊(Black-Bpx Attack)。按照攻擊環(huán)境,對抗樣本攻擊可以分為輸入可直接從存儲介質(zhì)中獲取的數(shù)字世界攻擊(Digital Attack)和輸入需要從物理世界中獲取的物理世界攻擊(Real-World Attack/Physical Attack)。
五、數(shù)據(jù)投毒攻擊
近些年來,隨著深度學(xué)習(xí)技術(shù)進(jìn)一步發(fā)展與應(yīng)用,對抗樣本相關(guān)技術(shù)即體現(xiàn)模型脆弱性一個(gè)十分重要的方面。和對抗樣本攻擊不同,數(shù)據(jù)投毒攻擊是另一種通過污染模型訓(xùn)練階段數(shù)據(jù)來實(shí)現(xiàn)攻擊目的的手段,其利用深度學(xué)習(xí)模型數(shù)據(jù)驅(qū)動(dòng)(Data-dreiven)的訓(xùn)練機(jī)制,通過構(gòu)造特定的樣本數(shù)據(jù)影響模型訓(xùn)練,從而實(shí)現(xiàn)部分控制模型表現(xiàn)的能力。
5.1數(shù)據(jù)投毒攻擊的基本原理
數(shù)據(jù)投毒主要在于通過無言訓(xùn)練數(shù)據(jù)影響模型訓(xùn)練,從而使模型有某種特定的表現(xiàn),如控制某些簡單的行為。數(shù)據(jù)投毒攻擊的核心為如何構(gòu)建可以實(shí)現(xiàn)特定目標(biāo)攻擊的數(shù)據(jù)投毒樣本。數(shù)據(jù)投毒攻擊可以被定義為一個(gè)雙層優(yōu)化問題,如式(5.1)所示。
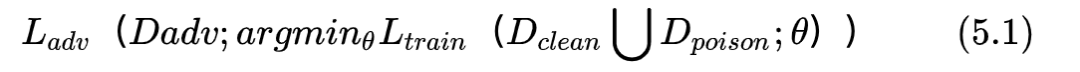
Ltrain可以為任意一個(gè)傳統(tǒng)任務(wù)的損失函數(shù),如垃圾郵件檢測、圖像分類等。基于原始干凈數(shù)據(jù)集Dclean和投毒數(shù)據(jù)集Dpoison,在給定損失函數(shù)Ltrain下進(jìn)行優(yōu)化可以獲得模型更新后的參數(shù)_Theta,Dadv是一個(gè)測試對抗樣本集合,Ladb是和投毒目標(biāo)相關(guān)的損失函數(shù),攻擊者希望通過數(shù)據(jù)投毒在訓(xùn)練號的參數(shù)Theta_和對抗樣本集合Dadv上獲得的損失Ladb最小(攻擊目標(biāo)最優(yōu))。為了姐姐雙層優(yōu)化問題,領(lǐng)域內(nèi)發(fā)展出了很多不同的解法,我將在以后進(jìn)行介紹。
5.2數(shù)據(jù)投毒攻擊的范圍與思路
在學(xué)習(xí)數(shù)據(jù)投毒攻擊中,書中共介紹了三個(gè)可能的數(shù)據(jù)投毒入口。
1、產(chǎn)品開放入口;
2、網(wǎng)絡(luò)公開數(shù)據(jù);
3、內(nèi)部人員。
總結(jié)
在本篇文章中,我們基本學(xué)習(xí)了介紹AI的框架組成,AI腳本攻擊中的對抗樣本攻擊和數(shù)據(jù)投毒攻擊的基本原理和分類,在下一篇文章繼續(xù)學(xué)習(xí)對抗樣本攻擊的使用方法,和使用范圍,對腳本進(jìn)行講解和使用。
審核編輯 :李倩
-
AI
+關(guān)注
關(guān)注
87文章
30996瀏覽量
269296 -
人工智能
+關(guān)注
關(guān)注
1791文章
47350瀏覽量
238759 -
大數(shù)據(jù)技術(shù)
+關(guān)注
關(guān)注
0文章
37瀏覽量
5134
原文標(biāo)題:總結(jié)
文章出處:【微信號:Tide安全團(tuán)隊(duì),微信公眾號:Tide安全團(tuán)隊(duì)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論