 從Cache驗證參考模型對比來談復雜度權衡
從Cache驗證參考模型對比來談復雜度權衡
一直以來對MTK北京團隊做的關于Cache一致性驗證的方案有深刻印象,2019年當時的一篇論文“An Enhanced Stimulus and Checking Mechanism on Cache Verification”(接下來該論文簡稱PP-MESH)采用的是MESH預測的方法,對cache的數據做好準確預測和檢查。
2022年的時候我們V3課程中的聯發科學員,還跟著我們一同回顧了這篇論文中涉及到的一些技術,給當時正在做cache一致性驗證的其他同學提供了思路。我們以往做的各個方向的技術分享和論文回顧,都有保存在V3課程視頻中。
這次我們要談的論文DVCon 2022 “CAMEL: A Flexible Cache Model for Cache Verification”(接下來該論文簡稱PP-CAMEL),其背景正是基于PP-MESH做的更新,我們也可以借此以了解對于一個復雜設計而言,如何考慮規劃其參考模型,在實際項目中有哪些需要權衡的地方。
總體而言,在驗證L1 cache system (L1SYS)的過程中,L1SYS的機構被拆分為多個模塊,包括shadow command buffer, store buffer, sram, line filling buffer, evinctionbuffer, prefetch buffer,而根據不同thread訪問數據時的cache hit/miss的情況和數據經過L1SYS各個模塊的流向,又將L1SYS的不同數據讀寫行為定義為了各種情況(例如in-order, out-of-order, with-losses, any-in-order, either-in-order, MISO, with-redundancy等)。這種數據從點到點的流向,就構成了DVCon 2019的這篇論文中數據檢查思想的框架,即根據每一個data stream的不同特征,分別對input stream, output stream做數據流向的標注。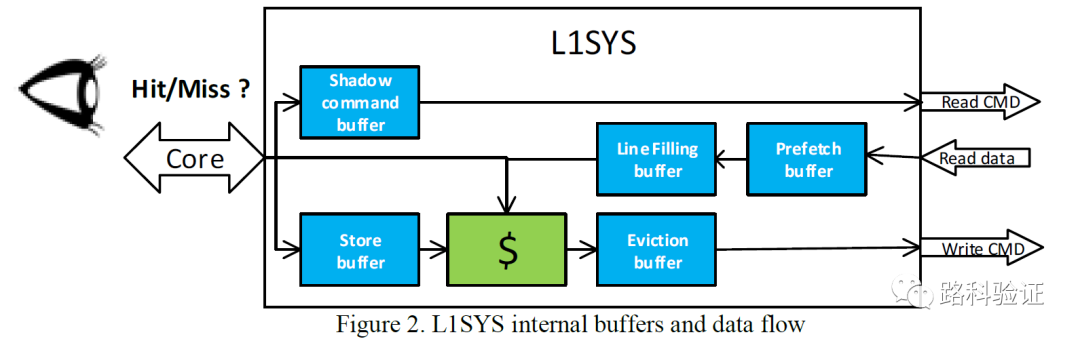
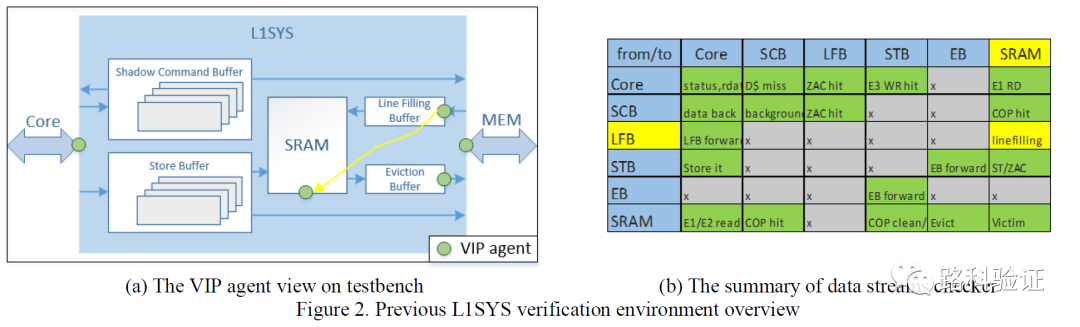
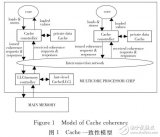
由于這種精細規劃和預測的方式,MESH檢查可以做到周期級的準確(cycle-accurate),從下面這個圖也可以看到,L1SYS模型中的每一部分(STB/EB/LFB/PB/SRAM等)都需要監測L1SYS設計外部和內部數據,從PP-CAMEL的回顧來看,MESH方案需要連接5個VIP monitor,而且從VIP monitor監測到的數據需要根據需要組合為stream,再按照MESH表格對這些stream進行獨立的處理和檢查。
PP-CAMEL對以前的這部分工作評價是,盡管可以做到cycle-accurate的細致檢查,但帶來的一個煩惱是由于MESH方案需要與設計行為深度耦合,而且對驗證人員提出較高的維護要求,如果設計發生變化,那么MESH方案作為一個整體都將需要花費較大人力去更新MESH驗證環境。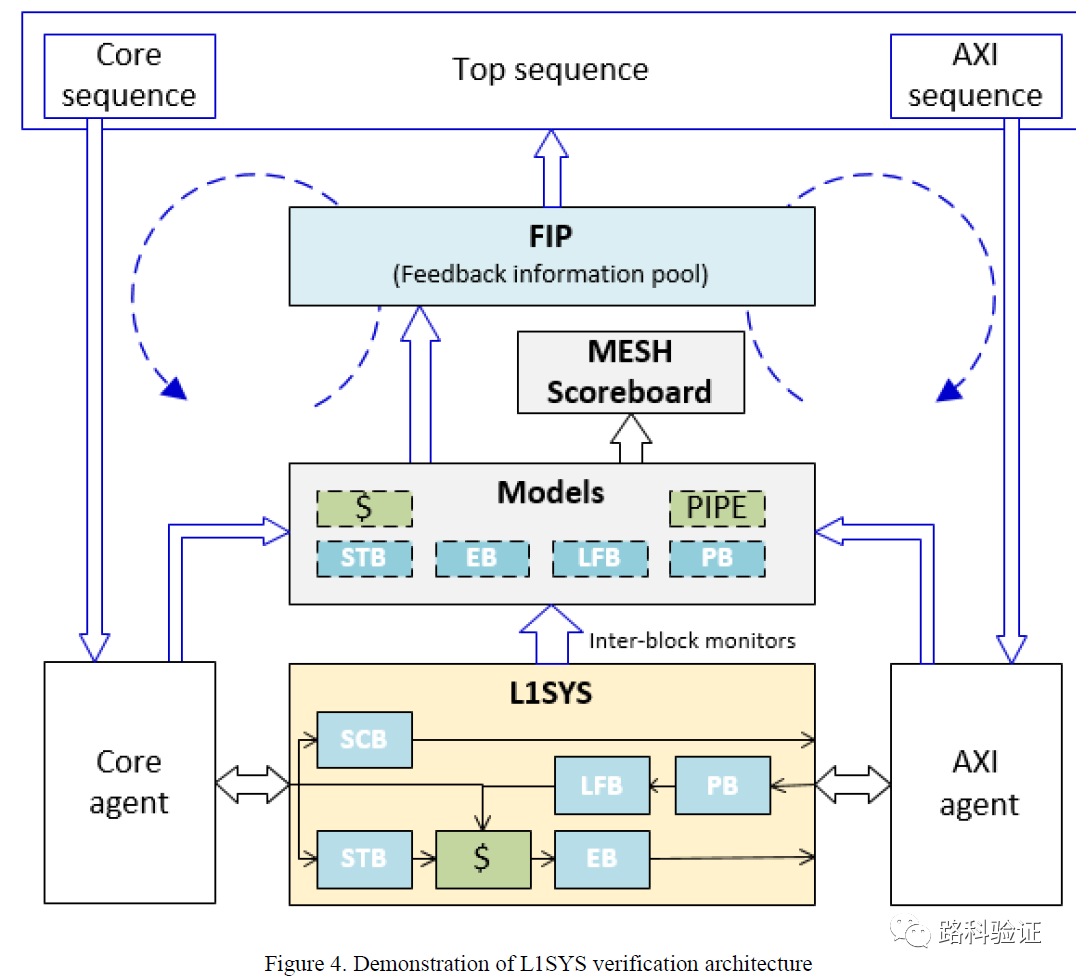
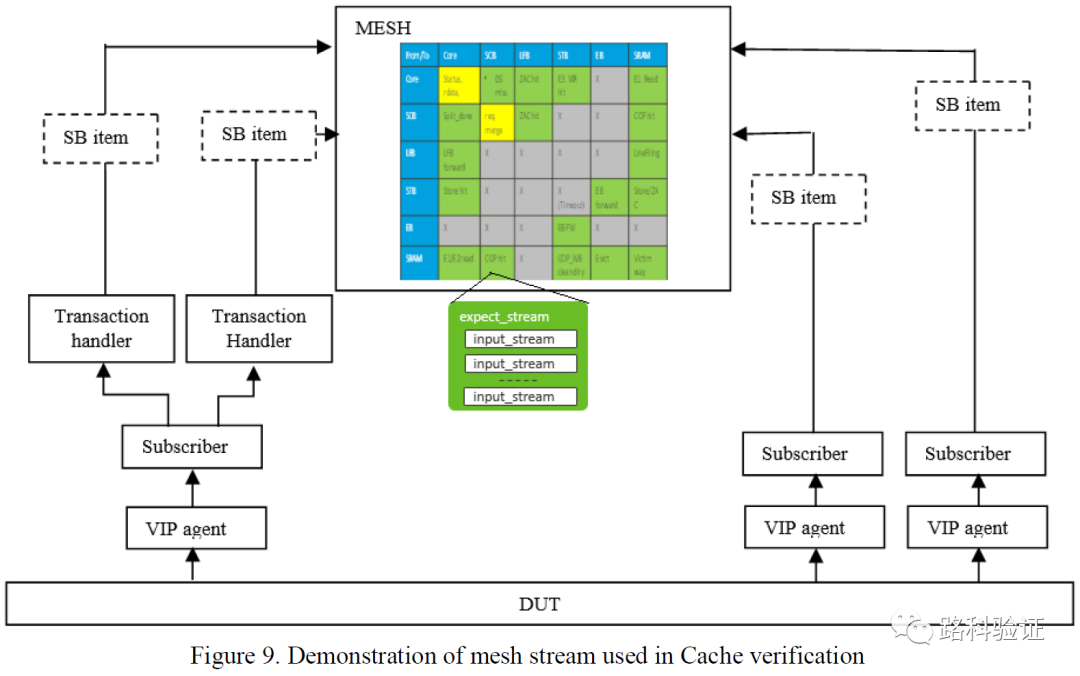
上面來自PP-CAMEL的評價便于理解,這就像如果我們把設計的模型做成一個big synthesized model,那么設計的每一處更新都會使得讓我們去維護這個大模型,而大模型越來越大、復雜、乃至趨于臃腫的情況下,設計可能打補丁式的修改,也可能會讓參考模型去做類似的補丁式修改。
理想情況下,如果維護這個模型的人是同一個人(大公司里這種情況較多)那么還好一些,但是如果一旦人員發生變動,模型當時設定的好壞、代碼結構是否合理、模型是否方便維護這些問題就隨之而來了。 從PP-CAMEL最后的代碼對比來看,也能證實這個問題,CAMEL模型的代碼量大概只有MESH模型的1/3。
但這并不是簡單說明,CAMEL既輕量化,又能完成MESH模型可以做的cycle-accurate的細致檢查。熊掌與魚難以兼得,CAMEL模型是在將功能檢查做了分層、分類以后,才將MESH模型原來可以一股腦完成的事情解耦合成CAMEL模型和其它模型,并且CAMEL模型能做的事情,也是分為了多種任務的。
一句話,那就是CAMEL模型做了檢查任務的規劃,沒有一來就試圖去構建一個大而全的模型,而是一開始就打算將驗證分成了多個步驟,逐一將從基礎功能到高級功能再到邊界情況的檢查分為了多個任務去實現的。
那么,PP-CAMEL為什么不采用PP-MESH中的大模型呢?難道是不需要做準確預測了嗎?其實從論文一開始的背景闡述來看,即他們開始在做多核多線程的架構(RISC-V)。這意味他們盡管可以參考原來PP-MESH中的L1SYS設計,但同時要適配多核ACE協議和snoop memory 請求(對于L1SYS而言屬于新的外部請求/響應)。
我能猜想到的是,當時也應該是考慮過MESH方案復用的,但這意味著需要理解原有的方案,而且要修改MESH中的代碼。如果是同一位工程師修改維護他原來的方案,那么思路大概還能跟得上拍子,但如果是不同的工程師打算要做這件事情,那么他還會考慮另外一種可能,就是在原有MESH思路的基礎上,做一些檢查的優化。
值得注意的是,PP-CAMEL論文中提到了PP-MESH原本在數據激勵方面的layer層次規劃清晰、各個方法接口也很豐富,這些有關激勵部分思想和接口仍然可以復用下來。
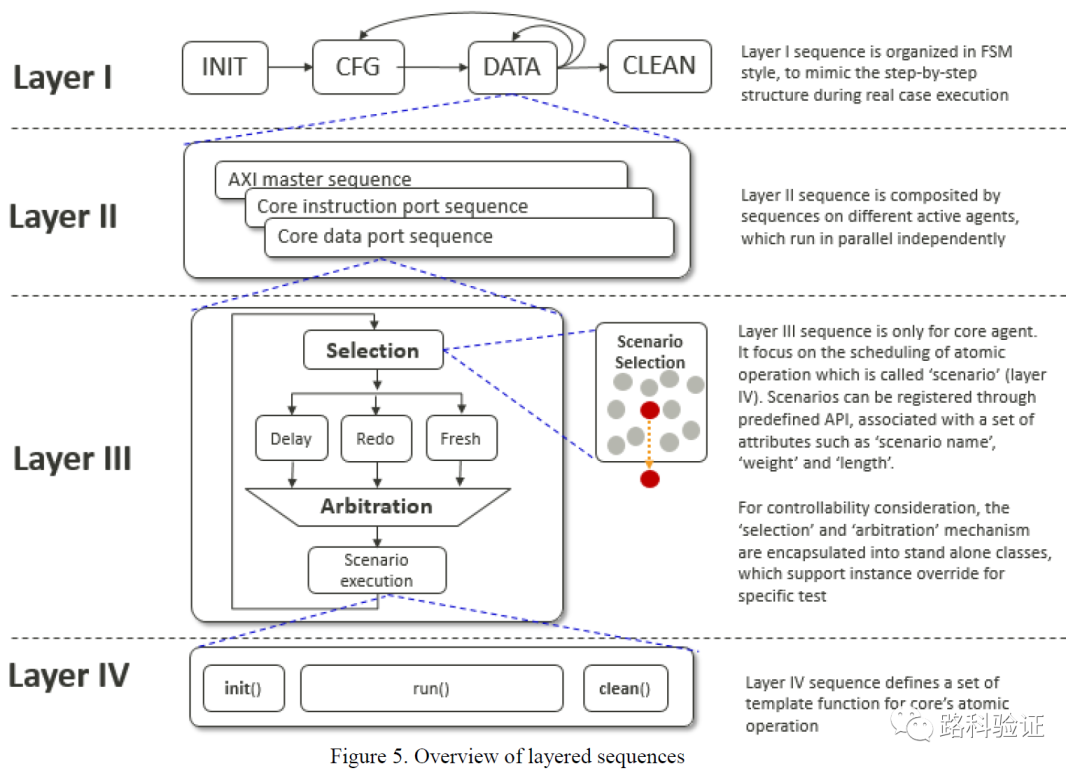
所以可能更符合當時實際情況的是,已經經歷過PP-MESH“高精度”模型帶來驗證環境與設計高度綁定以后的晃動帶來的痛苦之后,PP-CAMEL決定采取一個“循序漸進”的方案,即它的初衷是構建一個更為快速能夠對新的L1SYS設計進行檢查的驗證環境(如果能夠復用以前的一些激勵、測試序列那就更好)。
所以它一開始并沒有求全,而是把檢查的重心放在數據完整性上面,即data correctness check。這一點跟我們常規的數據流檢查類似,比如DMA數據搬遷或者數據打包解包操作等功能檢查,都是先完成數據完整性檢查,再去就設計的行為、時序做更為細致的檢查。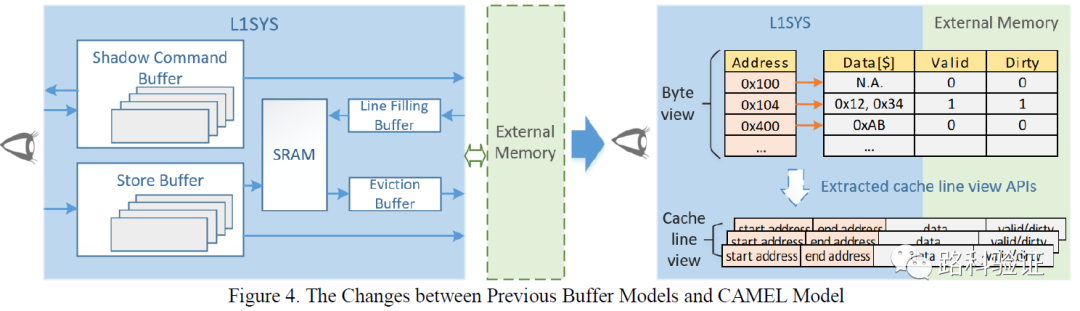

它的模型中的數據存放是較為模糊的,因為它不會準確預測數據,而是會存放所有可能從目標地址讀出去的數據(stores all possible values of the same address),這種方式仍然可以在設計早期階段幫助驗證做數據(模糊)檢查。它的優點在于更快部署、不依賴于具體的設計、時序,與設計可以解耦。
如果檢查方案里有配置按鈕(configuration knob),那么這種檢查方式可以給起個名字(rough level check)。 接下來PP-CAMEL也提到了,如果要進一步做到準確的數據預測檢查,那么就需要獲得額外的信息,比如對cache hit/miss check和rationality read/write command to external memory(對外部存儲讀寫請求的合理性檢查,關系到cache hit/miss的預測和模型準確度)。
那么就需要添加諸如location/SCB data/SRAM data這樣的屬性。而這些屬性又當來自于各個VIP monitor。當從monitor獲得的信息越多,那么CAMEL模型也將越復雜,而用于做data correctness check, hit/miss check, rationality check of request to external memory等也將越準確。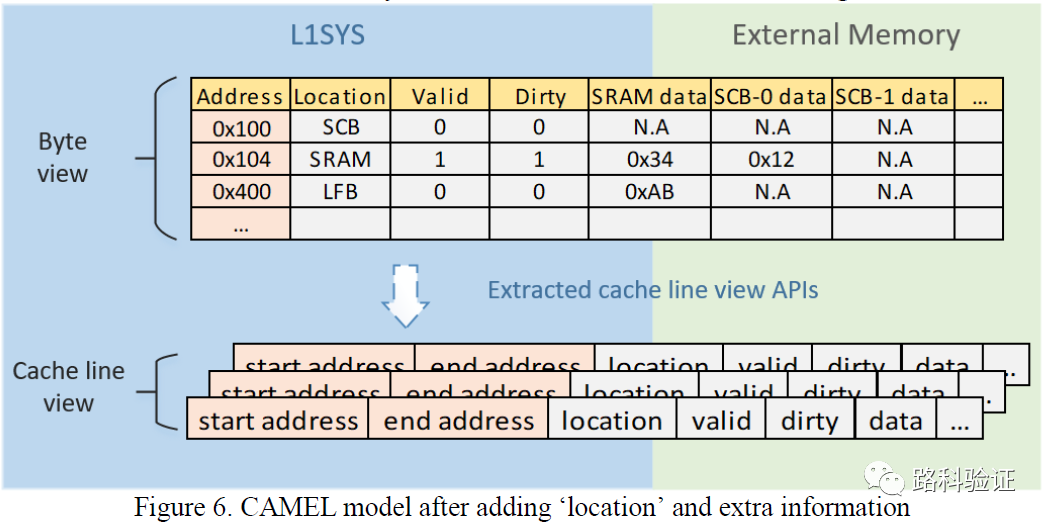
這個道理我們似乎都懂,但是PP-CAMEL恰恰給出了與原有PP-MESH不同的驗證環境實現步驟,下面這段話我認為是整篇論文中要著重表達的驗證工程思想。我們能夠理解,一個simple testbench不可能做到precise check,但我們能不能理解如果要設計一個complex testbench,是否有能力讓它做到simple check,或者做到different precision of check?對于MESH模型,PP-CAMEL給出的回顧似乎在說維護這樣一個大模型很耗神,尤其在PP-CAMEL背景中遇到一個新的L1SYS設計的時候,需要修改的內容恐怕很多,尤其是面對8000+行的MESH模型。
將模型先從簡單做起,有的時候也是一種妥協。這種妥協可能是來自于項目的壓力,可能是來自于對復雜設計邏輯和時序,也可能是為了將來以后便于維護。PP-CAMEL的模型核心是圍繞著地址和數據的,它本身不復雜,而在此基礎之上添加了一些必要的屬性,即能夠創造出條件做不同精確度的檢查。最終,檢查精度還會落回到模型復雜性上。
只不過,從trade-off來看,PP-CAMEL提出的思路,使得在驗證L1SYS過程中,得以找到一條從簡單到復雜的路,使得可以對L1SYS的各個功能逐一做從基礎到復雜的檢查。另外,在PP-CAMEL中可以看到,與PP-MESH的驗證思路聯系緊密,盡管模型的實現方式發生了較大變化,但激勵層次的組織和復用、以及原有的各個API的復用仍然帶來了幫助。
這種有歷史銜接的論文前后研究起來也很有收獲,而這兩篇論文也可以啟發我們在實現參考模型時,究竟是按照大模型來實現,還是按照分層(由易到難)模型來實現,需要考慮諸多工程因素。
審核編輯:劉清
-
sram
+關注
關注
6文章
767瀏覽量
114675 -
Cache
+關注
關注
0文章
129瀏覽量
28331 -
mesh技術
+關注
關注
0文章
14瀏覽量
8757 -
miso
+關注
關注
0文章
7瀏覽量
5421
原文標題:DVCon文賞-2023w18 從Cache驗證參考模型對比來談復雜度權衡
文章出處:【微信號:Rocker-IC,微信公眾號:路科驗證】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
業務復雜度治理方法論--十年系統設計經驗總結
PCB與PCBA工藝復雜度的量化評估與應用初探!
基于紋理復雜度的快速幀內預測算法
時間復雜度是指什么
各種排序算法的時間空間復雜度、穩定性
圖像復雜度對信息隱藏性能影響分析
一種基于貝葉斯網絡的隨機測試方法在Cache一致性驗證中的設計與實現
常見機器學習算法的計算復雜度
算法時空復雜度分析實用指南2
如何計算時間復雜度





 工商網監
工商網監
評論