 形狀感知零樣本語義分割
形狀感知零樣本語義分割
一、簡介
由于大規模視覺語言預訓練取得了令人矚目的進展,最近的識別模型可以以驚人的高準確度對任意對象進行零樣本和開放式分類。然而,將這種成功轉化為語義分割并不容易,因為這種密集的預測任務不僅需要準確的語義理解,還需要良好的形狀描繪,而現有的視覺語言模型是通過圖像級別的語言描述進行訓練的。為了彌合這一差距,我們在本研究中追求具有形狀感知能力的零樣本語義分割。受圖像分割文獻中經典的譜方法的啟發,我們提出利用自監督像素級特征構建的拉普拉斯矩陣的特征向量來提升形狀感知分割性能。
盡管這種簡單而有效的算法完全不使用已知類別的掩模,但我們證明它的表現優于一種最先進的形狀感知范式,在訓練期間對齊地面實況和預測邊緣。我們還深入研究了在不同數據集上使用不同的骨干網絡所實現的性能提升,并得出了一些有趣且有結論性的觀察:形狀感知分割性能的提升與目標掩模的形狀緊密性和對應語言嵌入的分布都密切相關。
二、網絡架構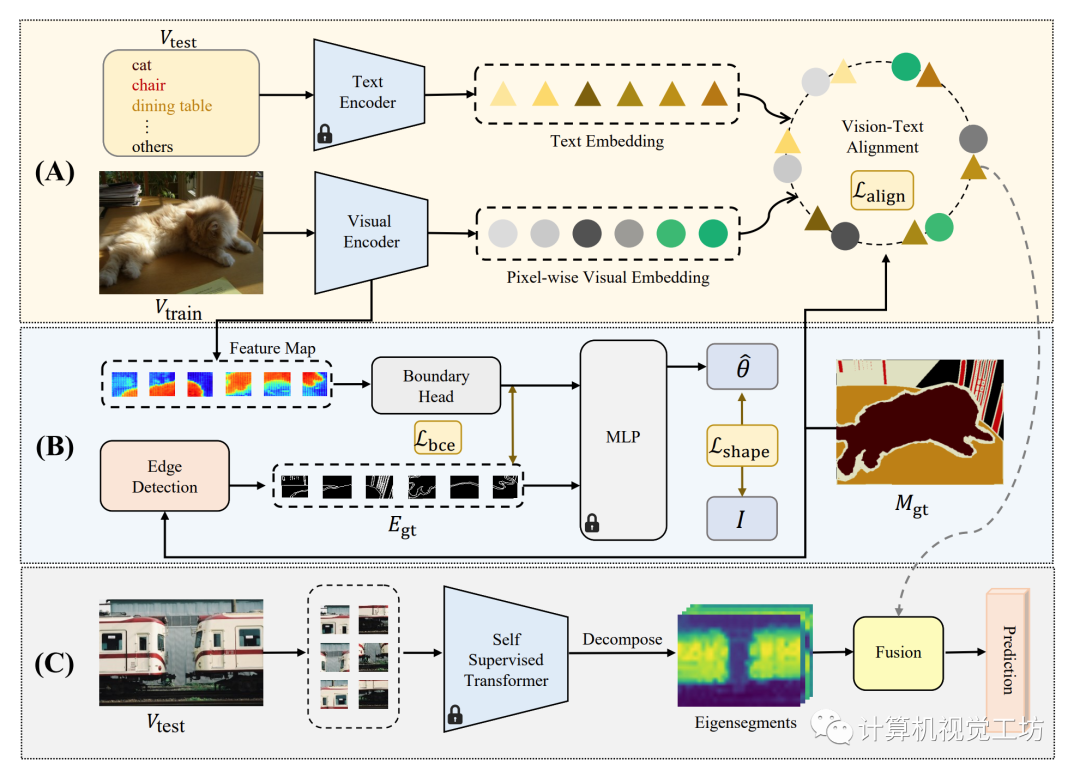
圖1 SAZS的總體框架
零樣本語義分割的目標是將語義分割任務擴展到訓練數據集中未出現的類別。引入額外的先驗信息的一種潛在方法是利用預訓練的視覺-語言模型,但是大多數這些模型都集中于圖像級別的預測,無法轉移到密集預測任務。為此,我們提出了一種名為“形狀感知零樣本語義分割(SAZS)”的新方法。
該方法利用了預訓練的CLIP[1]模型中包含的豐富的語言先驗信息,在訓練期間對齊地面實況和預測邊緣。同時,利用自監督像素級特征構建的拉普拉斯矩陣的特征向量來提升形狀感知分割性能,并將其與像素級別的預測相結合。 我們的方法的模型框架如圖1所示。
輸入圖像首先通過圖像編碼器轉換為像素級嵌入,然后與預訓練的CLIP[1]模型的文本編碼器獲得的預先計算的文本嵌入對齊(圖1中的A部分)。同時,圖像編碼器中的額外頭部用于在補丁中預測邊界,并針對分割地面真值中獲得的地面真值邊緣進行優化(圖1中的B部分)。此外,在推斷過程中,我們通過譜分析分解圖像并將輸出的特征向量與類別不可知的分割結果相結合(圖1中的C部分)。
我們將訓練集表示為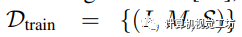 ,測試集表示為
,測試集表示為
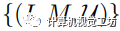 ,其中
,其中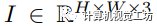 和
和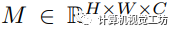 分別表示輸入圖像和相應的真實語義掩碼。S表示 I中的K個潛在標簽,而表示測試期間未見過的類別。
分別表示輸入圖像和相應的真實語義掩碼。S表示 I中的K個潛在標簽,而表示測試期間未見過的類別。
在我們的設置中,這兩個集合嚴格互斥(即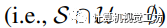 )。 在針對的
)。 在針對的 進行推斷之前,模型使用來自S的真實標簽在
進行推斷之前,模型使用來自S的真實標簽在 上進行訓練。 這意味著在訓練過程中從未看到測試集中的類別,使得任務在零樣本設置下進行。一旦模型訓練得當,它應該能夠泛化到未見過的類別,并在開放世界中實現高效的目標密集預測。
上進行訓練。 這意味著在訓練過程中從未看到測試集中的類別,使得任務在零樣本設置下進行。一旦模型訓練得當,它應該能夠泛化到未見過的類別,并在開放世界中實現高效的目標密集預測。
像素級別的視覺-語言對齊
我們采用擴張殘差網絡(DRN[2])和密集預測Transformer(DPT[3])來將圖像編碼為像素級嵌入向量。同時,我們采用預訓練的CLIP文本編碼器將來自S中K個類別的名稱映射到CLIP特征空間作為文本特征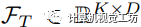 。其中,視覺特征
。其中,視覺特征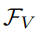 和文本特征具有相同的維度D。
和文本特征具有相同的維度D。
為了實現視覺-語言對齊,此前的工作[5]通過最小化像素和對應語義類別之間的距離,同時最大化像素和其他類別之間的距離來實現。在像素級視覺和語言特征被嵌入同一特征空間的假設下,我們利用余弦相似度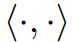 作為特征之間的量化距離度量,并提出對齊損失,它是所有像素上已見類別的交叉熵損失的總和:
作為特征之間的量化距離度量,并提出對齊損失,它是所有像素上已見類別的交叉熵損失的總和: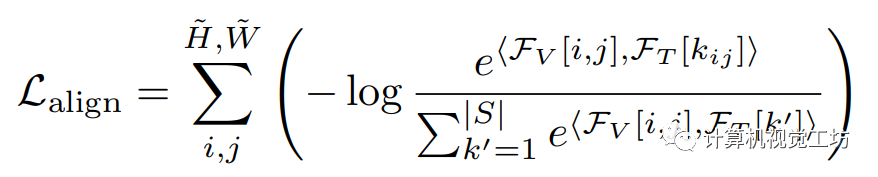 其中,
其中,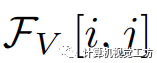 表示在位置
表示在位置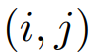 上的像素視覺特征,
上的像素視覺特征,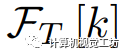 表示第k個文本特征,
表示第k個文本特征,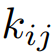 表示像素 的類別的索引。
表示像素 的類別的索引。
形狀約束
由于CLIP是在圖像級別任務上訓練的,僅僅利用CLIP特征空間中的先驗信息可能對密集預測任務不足夠。為了解決這個問題,我們引入邊界檢測作為一個約束任務。受到之前工作[6]的啟發,我們通過優化真實邊緣和特征圖中的邊緣之間的仿射變換,使其趨近于單位矩陣。
具體來說,如圖1所示,我們提取視覺編碼器的中間特征,并將其劃分成塊。首先采用Sobel算子獲得邊緣對應的真實標簽。之后將特征塊輸入邊界頭進行特征提取。我們利用訓練好的形狀網絡(圖 1中的MLP)計算第i個特征塊的變換矩陣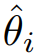 ,該矩陣用于將處理后的特征塊與邊緣的真實注釋之間進行仿射變換。我們使用形狀損失來優化仿射變換矩陣與單位矩陣之間的差異:
,該矩陣用于將處理后的特征塊與邊緣的真實注釋之間進行仿射變換。我們使用形狀損失來優化仿射變換矩陣與單位矩陣之間的差異: 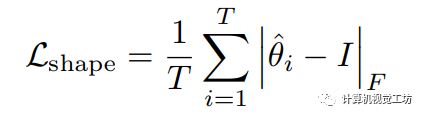 其中T表示特征塊數量,表示Frobenius范數。
其中T表示特征塊數量,表示Frobenius范數。
此外,我們還計算了整張特征圖的預測邊緣掩碼與相應的真實標注之間的二元交叉熵損失 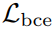 ,以進一步優化邊緣檢測的性能。經過邊緣檢測任務的聯合訓練,視覺編碼器能夠利用輸入圖像中的形狀先驗信息。后面的實驗結果表明,由
,以進一步優化邊緣檢測的性能。經過邊緣檢測任務的聯合訓練,視覺編碼器能夠利用輸入圖像中的形狀先驗信息。后面的實驗結果表明,由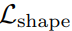 和引入的形狀感知帶來了顯著的性能提升。
和引入的形狀感知帶來了顯著的性能提升。
最終,在訓練過程中需要優化的總損失為: 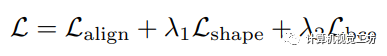 其中,和是損失權重。
其中,和是損失權重。
自監督譜分解
由于此前譜分解工作[7]的啟發,我們利用無監督譜分解的方式將輸入圖像的拉普拉斯矩陣分解為具有邊界信息的特征段,并在圖1中的融合模塊中將這些特征段與神經網絡的預測結果融合。 關聯矩陣的推導是譜分解的關鍵。首先提取預訓練的自監督Transformer(DINO[4])最后一層的注意力塊中的特征。像素,的關聯矩陣定義為: 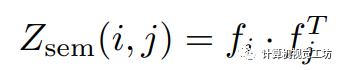 雖然從DINO特征中的關聯矩陣富含語義信息,但缺少包括顏色相似性和空間距離在內的低層次近鄰信息。
雖然從DINO特征中的關聯矩陣富含語義信息,但缺少包括顏色相似性和空間距離在內的低層次近鄰信息。
我們首先將輸入圖像轉換為HSV顏色空間: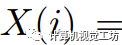
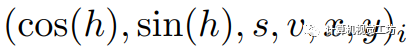 ,其中
,其中 是各自的HSV坐標,
是各自的HSV坐標,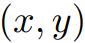 是像素i的空間坐標。然后,像素關聯矩陣被定義為:
是像素i的空間坐標。然后,像素關聯矩陣被定義為: 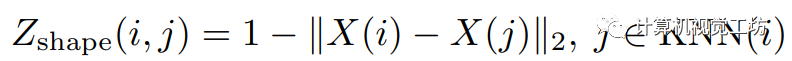 這里的
這里的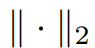 表示二范數。整體的關聯矩陣定義為這兩者的加權和:
表示二范數。整體的關聯矩陣定義為這兩者的加權和: 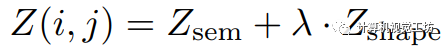
推理過程
在進行推理時,我們首先使用預訓練的CLIP文本編碼器對類別的進行編碼,并獲得包含C個類別的文本特征 ,其中每個類別都用一個D維嵌入表示。然后我們利用訓練好的視覺編碼器獲取視覺特征圖
,其中每個類別都用一個D維嵌入表示。然后我們利用訓練好的視覺編碼器獲取視覺特征圖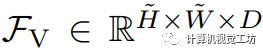 。最終的邏輯回歸值
。最終的邏輯回歸值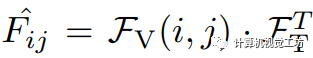 是視覺特征和文本特征之間余弦相似性的計算結果。同時,我們使用預訓練的DINO以無監督的方式提取語義特征,并計算出前K個譜特征區段
是視覺特征和文本特征之間余弦相似性的計算結果。同時,我們使用預訓練的DINO以無監督的方式提取語義特征,并計算出前K個譜特征區段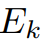 (我們的實現中
(我們的實現中 )。 最終的預測結果是由融合模塊生成的,該模塊根據和
)。 最終的預測結果是由融合模塊生成的,該模塊根據和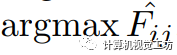 之間的最大IoU(表示為
之間的最大IoU(表示為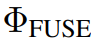 )從預測集中進行選擇:
)從預測集中進行選擇: 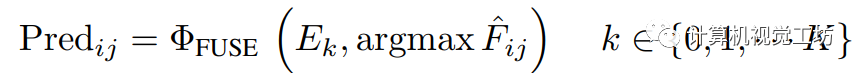
三、實驗結果
我們分別在語義分割數據集PASCAL-5i[8]和COCO-20i[9]上進行了定量和定性實驗,分別如下圖所示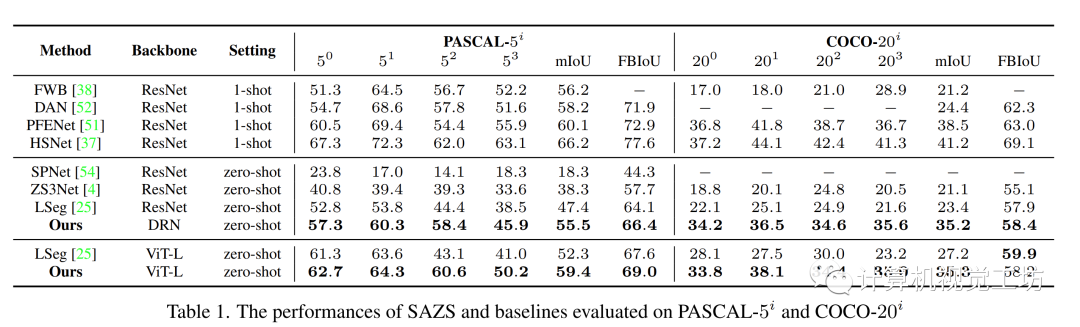
表1:SAZS在PASCAL-5i和COCO-20i上的定量結果
表2:SAZS跨數據零樣本分割的定量結果(在PASCAL-5i上測試)
SAZS在PASCAL-5i和COCO-20i上的定性結果分別如下圖所示。第一列和最后一列是不同類別的輸入圖像和相應的地面真實語義掩碼。第二列和第三列分別是 SAZS 沒有和有形狀感知的預測結果。*表示在訓練階段未曾出現的類別.

形狀感知分割驗證指標IoU與目標掩模的形狀緊密性和對應語言嵌入的分布關系如下圖所示。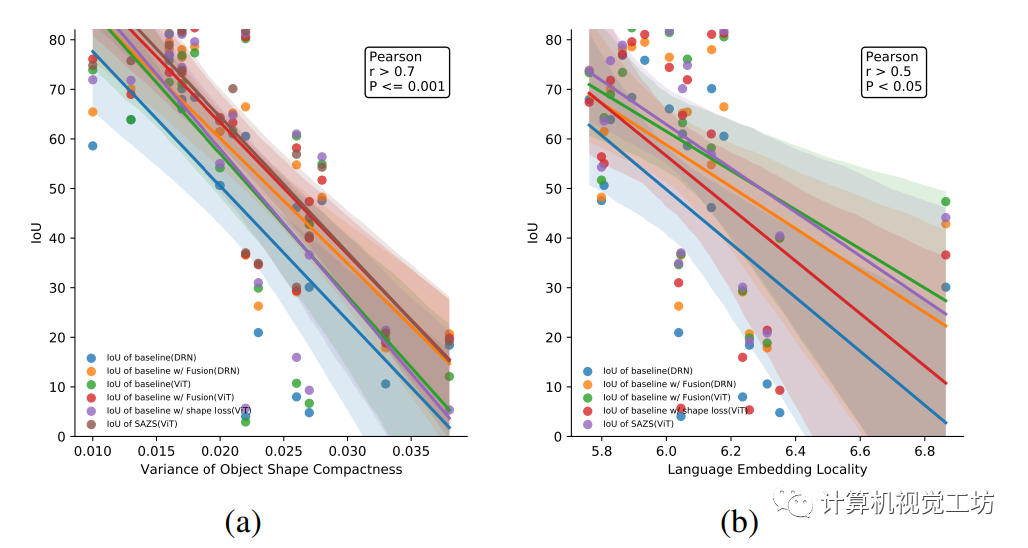
四、總結
本文提出了一種新穎的框架,用于實現形狀感知的零樣本語義分割(簡稱SAZS)。該框架利用大規模預訓練視覺語言模型的特征空間中包含的豐富先驗信息,同時通過在邊界檢測約束任務上進行聯合訓練。此外,采用自監督譜分解來獲取圖像的特征向量,將其與網絡預測融合增強模型感知形狀的能力。相關性分析進一步凸顯了形狀緊密度和語言嵌入分布對分割性能的影響。
審核編輯:劉清
-
編碼器
+關注
關注
45文章
3701瀏覽量
135690 -
DRNN
+關注
關注
0文章
2瀏覽量
6127 -
Clip
+關注
關注
0文章
32瀏覽量
6778 -
HSV
+關注
關注
0文章
10瀏覽量
2637
原文標題:CVPR2023 | 形狀感知零樣本語義分割
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
SparseViT:以非語義為中心、參數高效的稀疏化視覺Transformer

【「具身智能機器人系統」閱讀體驗】2.具身智能機器人的基礎模塊
利用VLM和MLLMs實現SLAM語義增強

手冊上新 |迅為RK3568開發板NPU例程測試
語義分割25種損失函數綜述和展望






 工商網監
工商網監
評論