 502問題怎么排查?
502問題怎么排查?
剛工作那會,有一次,上游調用我服務的老哥說,你的服務報"502錯誤了,快去看看是為什么吧"。
當時那個服務里正好有個調用日志,平時會記錄各種200,4xx狀態碼的信息。于是我跑到服務日志里去搜索了一下502這個數字,毫無發現。于是跟老哥說,"服務日志里并沒有502的記錄,你是不是搞錯啦?"
現在想來,多少有些不好意思。
不知道有多少老哥是跟當時的我是一樣的,這篇文章,就來聊聊502錯誤是什么?
我們從狀態碼是什么開始聊起。
HTTP狀態碼
我們平時在瀏覽器里逛的某寶和某度,其實都是一個個前端網頁。
一般來說,前端并不存儲太多數據,大部分時候都需要從后端服務器那獲取數據。
于是前后端之間需要通過TCP協議去建立連接,然后在TCP的基礎上傳輸數據。
而TCP是基于數據流的協議,傳輸數據時,并不會為每個消息加入數據邊界,直接使用裸的TCP進行數據傳輸會有"粘包"問題。
因此需要用特地的協議格式去對數據進行解析。于是在此基礎上設計了HTTP協議。詳細的內容可以看我之前寫的《既然有HTTP協議,為什么還要有RPC》。
比如,我想要看某個商品的具體信息,其實就是前端發的HTTP請求中傳入商品的id,后端返回的HTTP響應中返回商品的價格,商店名,發貨地址的信息等。
通過id獲取商品詳情
這樣,表面上,我們是在刷著各種網頁,實際上背后正有多次HTTP消息在不斷進行收發。

用戶在網上瀏覽商品
但問題就來了,上面提到的都是正常情況,如果有異常情況呢,比如前端發的數據,根本就不是個商品id,而是一張圖片,這對于后端服務端來說是不可能給出正常響應的,于是就需要設計一套HTTP狀態碼,用來標識這次HTTP請求響應流程是否正常。通過這個可以影響瀏覽器的行為。
比方說一切正常,那服務端返回個200狀態碼,前端收到后,可以放心使用響應的數據。但如果服務端發現客戶端發的東西異常,就響應個4xx狀態碼,意思是這是個客戶端的錯誤,4xx里頭的xx可以根據錯誤的類型,再細分成各種碼,比如401是客戶端沒權限,404是客戶端請求了一個根本不存在的網頁。反過來,如果是服務器有問題,就返回5xx狀態碼。

4xx和5xx的區別
但問題就來了。
服務端都有問題了,搞嚴重點,服務器可能直接就崩潰了,那它還怎么給你返回狀態碼?
是的,這種情況,服務端是不可能給客戶端返回狀態碼的。所以說,一般情況下5xx的狀態碼其實并不是服務器返回給客戶端的。
它們是由網關返回的,常見的網關,比如nginx。
nginx的作用
回到前后端交互數據的話題上,如果前端用戶少,那后端處理起請求來,游刃有余。但隨著用戶越來越多,后端服務器受資源限制,cpu或者內存都可能會嚴重不足,這時候解決方案也很簡單,多搞幾臺一樣的服務器,這樣就能將這些前端請求均攤給幾個服務器,從而提升處理能力。
但要實現這樣的效果,前端就得知道后端具體有哪些個服務器,并一一跟他們建立TCP連接。
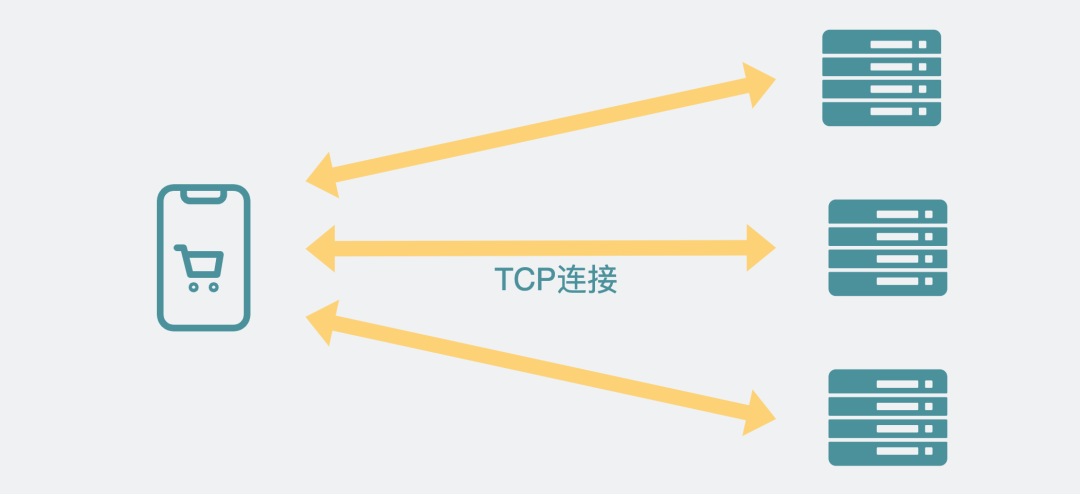
前端與多個服務器之間建立連接
也不是不行,但就是麻煩。
但這時候如果能有個中間層擋在它們中間就好了,這樣客戶端只需要跟中間層連接,中間層再和服務器建立連接。
于是,這個中間層就成了這幫服務器的一個代理人一樣,客戶端有啥事都找代理人,只管發出自己的請求,再由代理人去找某個服務器去完成響應。整個過程下來,客戶端只知道自己的請求被代理人幫忙搞定了,但代理人具體找了那個服務器去完成,客戶端并不知道,也不需要知道。
像這種,屏蔽掉具體有哪些服務器的代理方式就是所謂的反向代理。
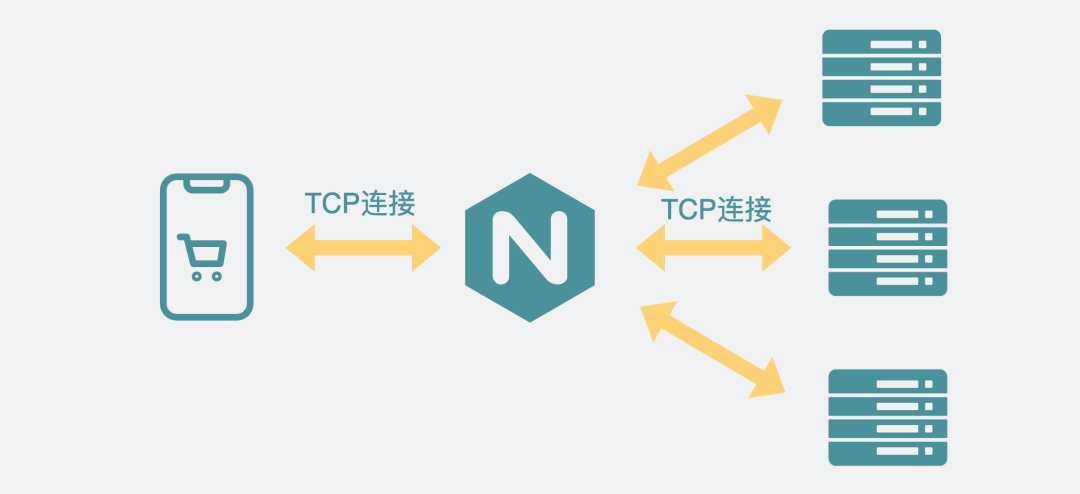
反向代理
反過來,屏蔽掉具體有哪些客戶端的代理方式,就是所謂的正向代理。
而這個中間層的角色,一般由nginx這類網關來充當。
另外,由于背后的服務器可能性能配置各不相同,有些4核8G,有些2核4G,nginx能為它們加上不同的訪問權重,權重高的多轉發點請求,通過這個方式實現不同的負載均衡策略。
nginx返回5xx狀態碼
有了nginx這一中間層后,客戶端從直連服務端,變成客戶端直連nginx,再由nginx直連服務端。從一個TCP連接變成兩個TCP連接。
于是,當服務器發生異常時,nginx發送給服務器的那條TCP連接就不能正常響應,nginx在得到這一信息后,就會返回5xx錯誤碼給客戶端,也就是說5xx的報錯,其實是由nginx識別出來,并返回給客戶端的,服務端本身,并不會有5xx的日志信息。所以才會出現文章開頭的一幕,上游收到了我服務的502報錯,但我在自己的服務日志里卻搜索不到這一信息。
產生502的常見原因
在rfc7231中有關于502錯誤碼的官方解釋是
502BadGateway The502(BadGateway)statuscodeindicatesthattheserver,whileactingasagatewayorproxy,receivedaninvalidresponsefromaninboundserveritaccessedwhileattemptingtofulfilltherequest.
翻譯一下就是,502 (Bad Gateway) 狀態代碼表示服務器在充當網關或代理時,在嘗試滿足請求時從它訪問的入站服務器接收到無效響應。
汝聽,人言否?
這對于大部分編程小白來說,不僅沒解釋到問題,反而只會冒出更多的問號。比如,這上面提到的無效響應到底指的是什么?
我來解釋下,它其實是說,502其實是由網關代理(nginx)發出的,是因為網關代理把客戶端的請求轉發給了服務端,但服務端卻發出了無效響應,而這里的無效響應,一般是指TCP的RST報文或四次揮手的FIN報文。
四次揮手估計大家背的很熟了,所以略過,我們來重點說下RST報文是什么。
RST是什么?
我們都知道TCP正常情況下斷開連接是用四次揮手,那是正常時候的優雅做法。
但異常情況下,收發雙方都不一定正常,連揮手這件事本身都可能做不到,所以就需要一個機制去強行關閉連接。
RST就是用于這種情況,一般用來異常地關閉一個連接。它是TCP包頭中的一個標志位,在收到置這個標志位的數據包后,連接就會被關閉,此時接收到 RST的一方,在應用層會看到一個connection reset或 connection refused的報錯。
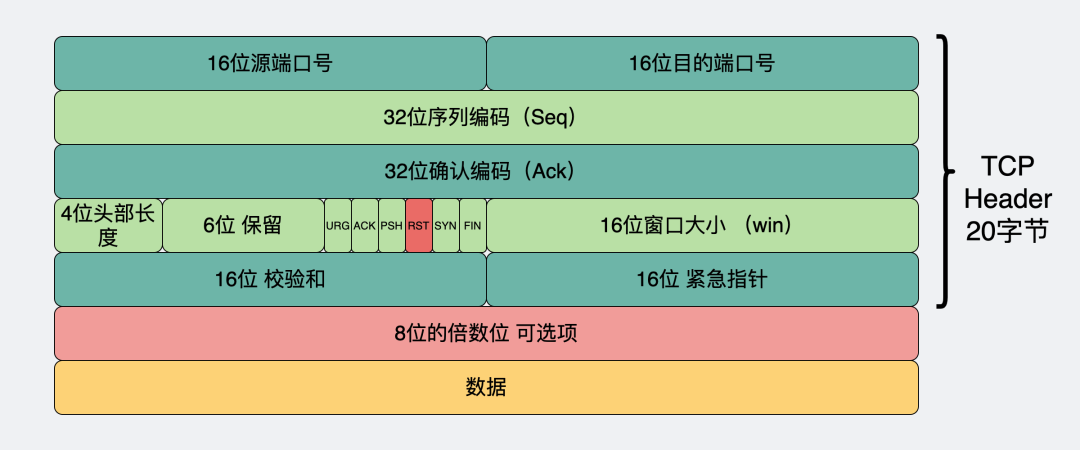
TCP報頭RST位
而之所以發出RST報文,一般有兩個常見原因。
服務端過早斷開連接
nginx與服務端之間有一條TCP連接,在nginx將客戶端請求轉發給服務端時,他兩之間按道理會一直保持這條連接,直到服務端將結果正常返回后,再斷開連接。
但如果服務端過早斷開連接,而nginx卻還繼續發消息過去,nginx就會收到服務端內核返回的RST報文或四次揮手的FIN報文,迫使nginx那邊的連接結束。
過早斷開連接的原因常見的有兩個。
第一個是,服務端設置的超時時間過短。不管是用的哪種編程語言,一般都有現成的HTTP庫,服務端一般都會有幾個timeout參數,比如golang的HTTP服務框架里有個寫超時(WriteTimeout),假設設置了2s,那它的含義就是,服務端在收到請求后需要在2s內處理完并將結果寫到響應中,如果等不到,就會將連接給斷掉。
比如你的接口處理時間是5s,而你的WriteTimeout卻只有2s,在沒等到響應寫完之前,HTTP框架就會主動將連接給斷開。nginx此時就有可能收到四次揮手的FIN報文(有些框架也可能發RST報文),然后斷開連接,于是客戶端就會收到一個502報錯。
遇到這種問題,將WriteTimeout的時間調大一些就好了。
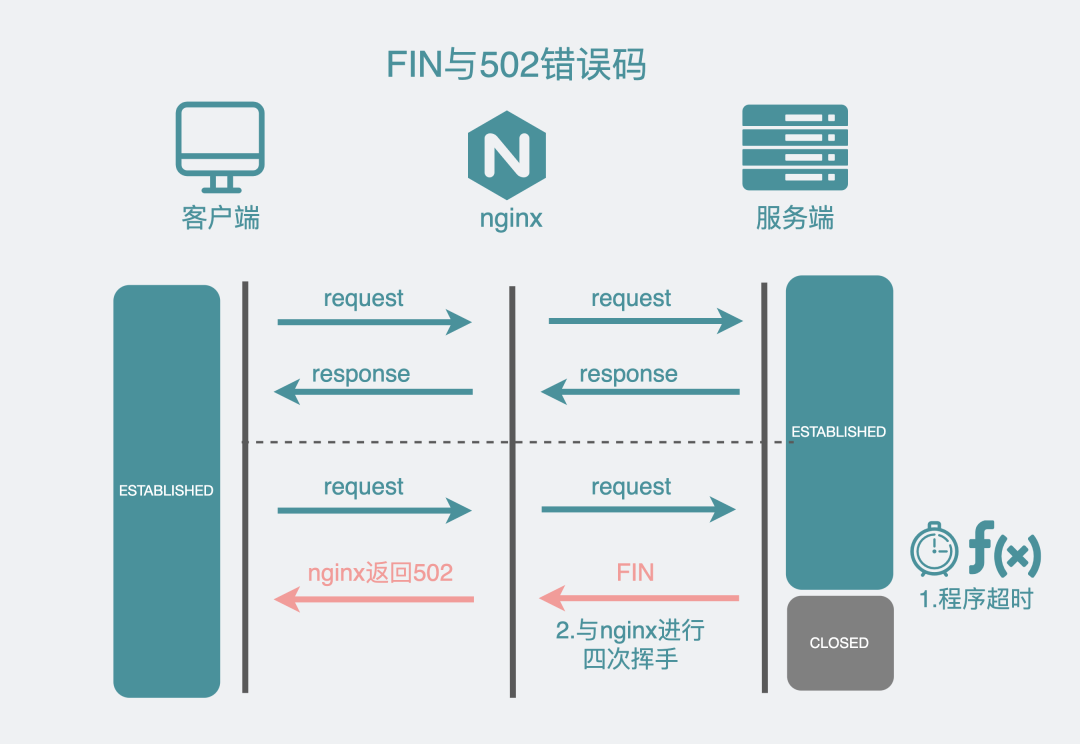
FIN與502的關系
第二個原因,也是造成502狀態碼最常見的原因,就是服務端應用進程崩了(crash)。
服務端崩了,也就是當前沒有一個進程在監聽服務器端口,而此時你卻嘗試向一個不存在的端口發數據,服務器的linux內核協議棧就會響應一個RST數據包。同樣,這時候nginx也會給客戶端一個502。
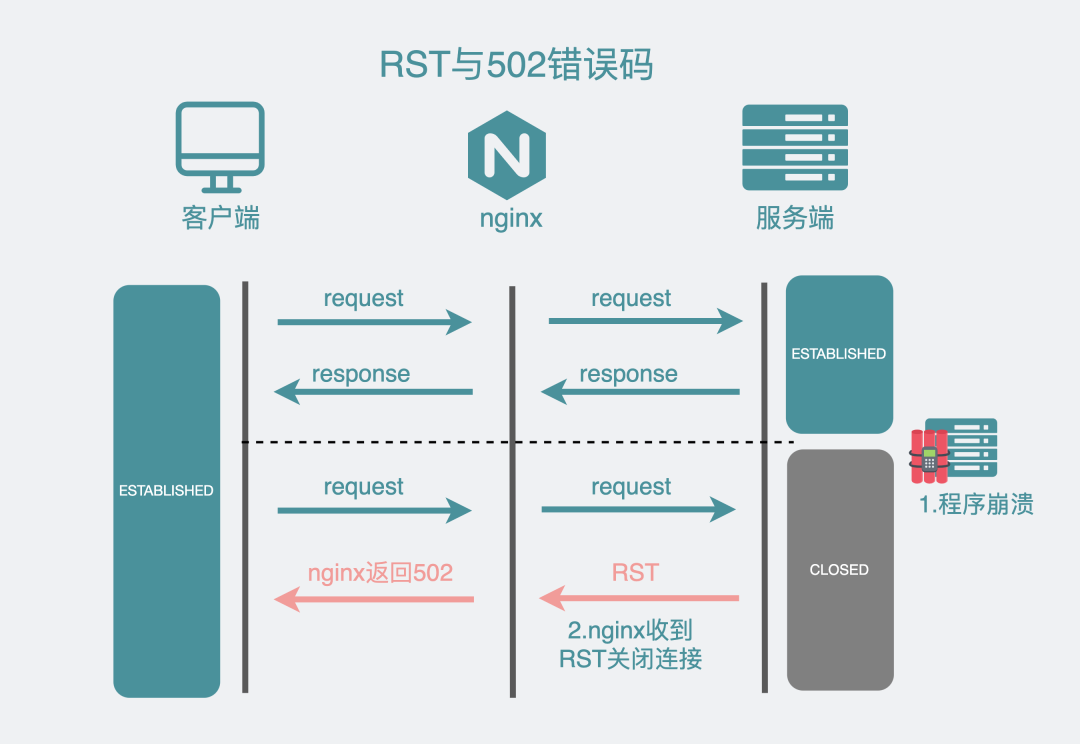
RST和502
在開發過程中,這種情況是最常見的。
現在我們大部分的服務器都會將掛掉的服務重啟,因此我們需要判斷下服務是否曾經崩潰過。
如果你有對服務端的cpu或者內存做過監控,可以看下CPU或內存的監控圖是否出現過斷崖式的突然下跌。如果有,十有八九百,就是你的服務端應用程序曾經崩潰過。
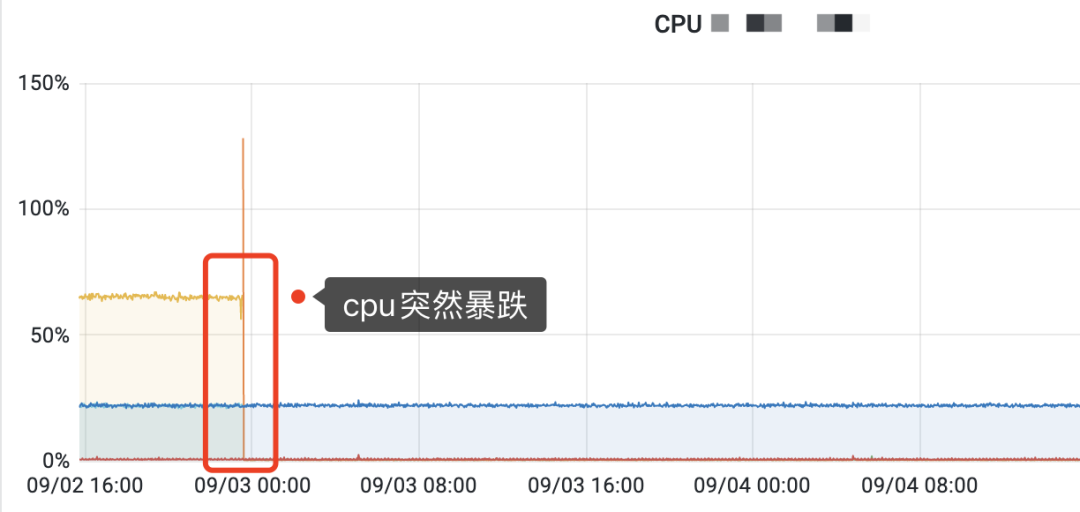
cpu突然暴跌
除此之外你還通過下面的命令,看下進程上次的啟動時間是什么時候。
ps-olstart{pid}
比如我要看的進程id是13515,命令就需要像下面這樣。
#ps-olstart13515 STARTED WedAug3114532022
可以看到它上次的啟動時間是8月31日,這個時間如果跟你印象中的操作時間有差距,那說明進程可能是崩了之后被重新拉起了。
遇到這種問題,最重要的是找出崩潰的原因,崩潰的原因就多種多樣了,比如,對未初始化的內存地址進行寫操作,或者內存訪問越界(數組arr長度明明只有2,代碼卻讀arr[3])。
這種情況幾乎都是程序有代碼邏輯問題,崩潰一般也會留下代碼堆棧,可以根據堆棧報錯去排查問題,修復之后就好了。比如下面這張圖是golang的報錯堆棧信息,其他語言的也類似。
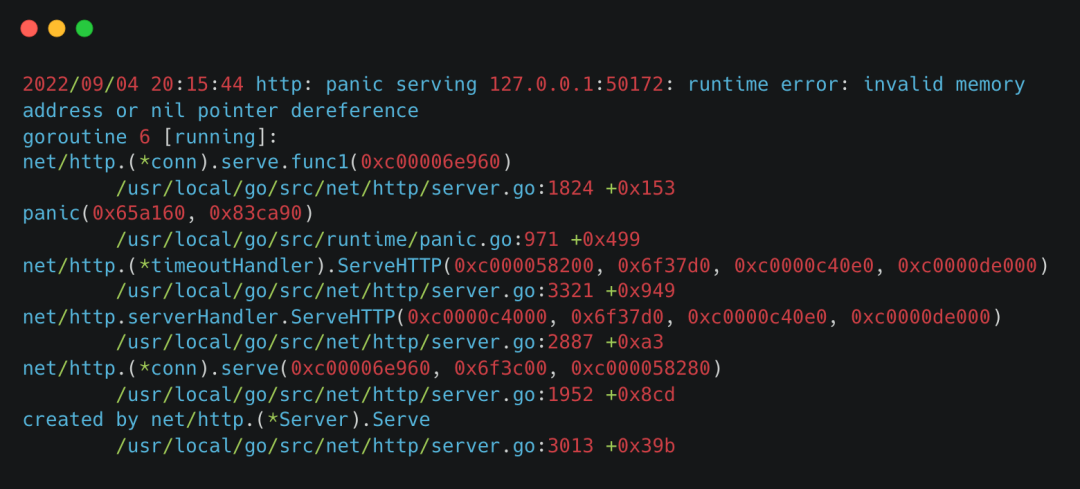
報錯堆棧
不打印堆棧的情況
但有一些情況,有時候根本不留下堆棧。
比如內存泄露導致進程占用內存越來越多,最后導致超過服務器的最大內存限制,觸發OOM(out of memory), 進程直接就被操作系統kill掉。
還有更隱蔽的,代碼邏輯里隱藏了主動退出進程的操作。比如golang的日志打印里有個方法叫log.Fatalln(),打印完日志還會順便執行os.Exit()直接退出進程,對源碼不了解的新手很容易犯這個錯。

打印完順便還退出進程
如果你很明確,你的服務沒有崩過。那繼續往下看。
網關將請求打到了一個不存在的IP上
nginx是通過配置的形式來代理多個服務器。這個配置一般是放在/etc/nginx/nginx.conf中。
打開它,你可能會看到類似下面這樣的信息。
upstreamxiaobaidebug.top{ server10.14.12.19:9235weight=2; server10.14.16.13:8145weight=5; server10.14.12.133:9702weight=8; server10.14.11.15:7035weight=10; }
上面配置的含義是,如果客戶端訪問xiaobaidebug.top域名,nginx就會將客戶端的請求轉發到下面的4個服務器ip上,ip邊上還有個weight權重,權重越高,被轉發到的次數就越多。
可以看出,nginx具有相當豐富的配置能力。但要注意的是,這些個文件是需要自己手動配置的。對于服務器少,且不怎么變化的情況,這當然沒問題。
但現在已經是云原生時代了,很多公司內部都有自己的云產品,服務自然也會上云。一般來說每次更新服務,都可能會將服務部署到一臺新的機器上。而這個ip也會隨著改變,難道每發布一次服務,都需要手動去nginx上改配置嗎?這顯然不現實。
如果能在服務啟動時,讓服務主動將自己的ip告訴nginx,然后nginx自己生成這樣的一個配置并重新加載,那事情就簡單多了。
為了實現這樣一個服務注冊的功能,不少公司都會基于nginx進行二次開發。
但如果這個服務注冊功能有問題,比方說服務啟動后,新服務沒注冊上,但老服務已經被銷毀了。這時候nginx還將請求打到老服務的IP上,由于老服務所在的機器已經沒有這個服務了,所以服務器內核就會響應RST,nginx收到RST后回復502給客戶端。
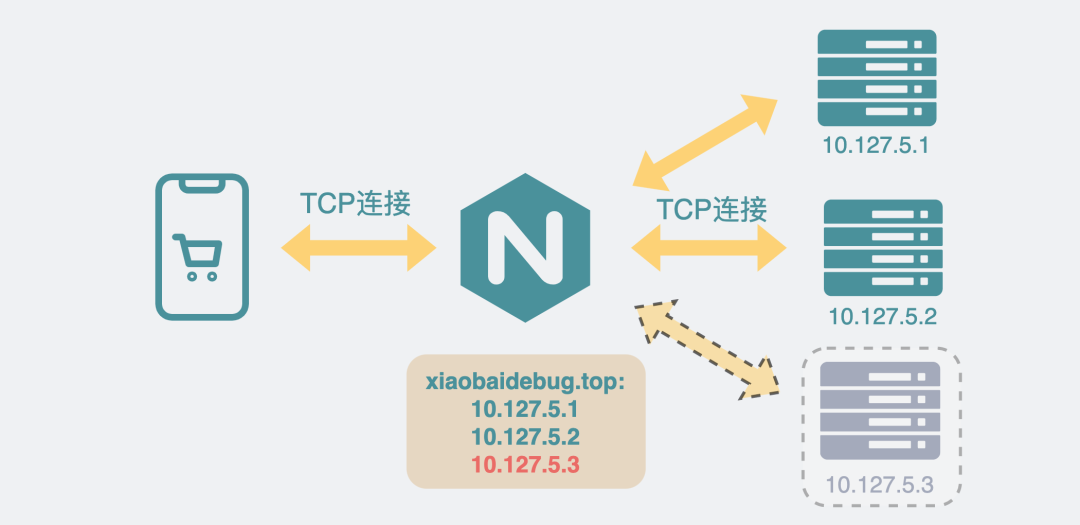
實例已經銷毀但配置沒刪IP
要排查這種問題也不難。
這個時候,你可以看下nginx側是否有打印相關的日志,看下轉發的IP端口是否符合預期。
如果不符合預期,可以去找找做這個基礎組件的同事,進行一波友好的交流。
總結
HTTP狀態碼用來表示響應結果的狀態,其中200是正常響應,4xx是客戶端錯誤,5xx是服務端錯誤。
客戶端和服務端之間加入nginx,可以起到反向代理和負載均衡的作用,客戶端只管向nginx請求數據,并不關心這個請求具體由哪個服務器來處理。
后端服務端應用如果發生崩潰,nginx在訪問服務端時會收到服務端返回的RST報文,然后給客戶端返回502報錯。502并不是服務端應用發出的,而是nginx發出的。因此發生502時,后端服務端很可能沒有沒有相關的502日志,需要在nginx側才能看到這條502日志。
如果發現502,優先通過監控排查服務端應用是否發生過崩潰重啟,如果是的話,再看下是否留下過崩潰堆棧日志,如果沒有日志,看下是否可能是oom或者是其他原因導致進程主動退出。如果進程也沒崩潰過,去排查下nginx的日志,看下是否將請求打到了某個不知名IP端口上。
審核編輯 :李倩
-
HTTP
+關注
關注
0文章
505瀏覽量
31211 -
TCP
+關注
關注
8文章
1353瀏覽量
79064 -
服務端
+關注
關注
0文章
66瀏覽量
7007
原文標題:502問題怎么排查?
文章出處:【微信號:良許Linux,微信公眾號:良許Linux】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
可調電流低壓線性IC/NU502應用資料
Fluke 190-502 二通道手持示波表|福祿克示波表190-502|福祿克190-502

DC502A DC502A評估板
最大502 ADI







 工商網監
工商網監
評論