 ?高精地圖生成技術大揭秘
?高精地圖生成技術大揭秘
背景
目前學術界和工業界(尤其自動駕駛公司)均開始研究HD地圖生成,也有一些公開的學術數據集以及非常多的學術工作,此外各家自動駕駛公司也在AIDAY上公開分享技術方案。從這些公開信息來看,也觀察到了一些行業趨勢,例如在線建圖、圖像BEV感知、點圖融合以及車道線矢量拓撲建模等。本文將對相關的學術工作和自動駕駛公司的技術方案進行解讀,以及談談個人的一些思考。
學術數據集
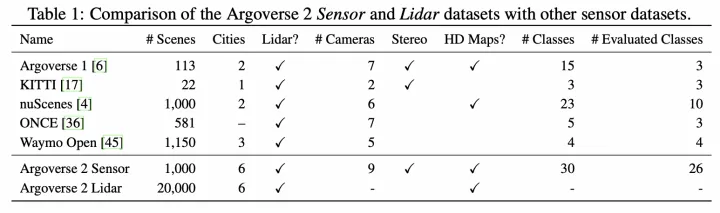
學術數據集對比
目前含HD地圖的學術數據集包括:nuScenes【1】以及Argoverse2【2】。著重介紹下Argoverse2數據集,該數據集包含信息非常豐富:
包括車道線、道路邊界、人行橫道、停止線等靜態地圖要素,其中幾何均用3D坐標表示,并且同時包含了實物車道線和虛擬車道線;
提供了密集的地面高度圖(30cm),通過地面高度可以僅保留地面的點云,便于處理地面上的地圖要素;
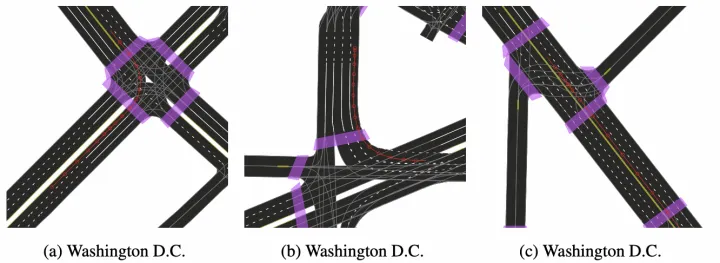
Argoverse2的HD地圖
學術工作
該領域目前是自動駕駛公司的關注重點,因此相關學術工作基本都來自高校和車企合作,目前已經公開的論文,包括理想、地平線和毫末智行等車企。
而這些學術工作的技術方案整體可以概括為兩部分:(1)BEV特征生成(2)地圖要素建模。
BEV特征生成
在BEV空間進行在線建圖,已經是目前學術界和業界的統一認識,其優勢主要包括:
減少車輛俯仰顛簸導致的內外八字抖動,適合車道線這種同時在道路中間以及兩邊存在的物體;
遠近檢測結果分布均勻,適合車道線這種細長物體;
便于多相機和時序融合,適合車道線這種可能在單幀遮擋看不見或單視角相機下拍攝不全的物體;
而在如何生成BEV特征上,不同論文的方法有些許區別。
HDMapNet【3】(來自清華和理想),采用了點圖融合方式生成BEV特征,其中點云分支使用PointPillar【4】+PointNet【5】方式提取特征,圖像分支則使用MLP方式實現PV2BEV轉換,即將PV空間到BEV空間的變換看作變換矩陣參數,并通過MLP去學習(擬合)該參數。
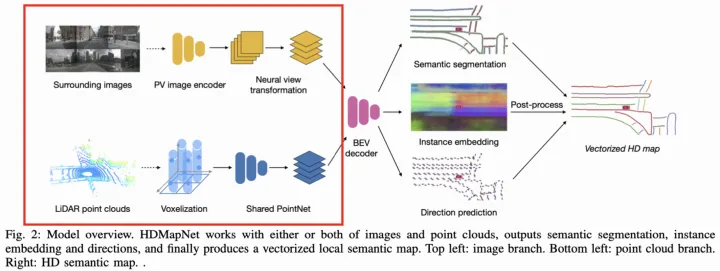
HDMapNet架構圖
其中環視圖像經過PV2BEV轉換,實現了不同視角相機的圖像特征融合。
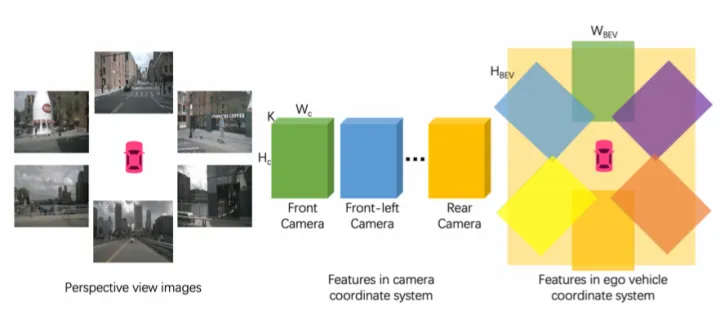
HDMapNet的環視相機特征融合
VectorMapNet【6】是HDMapNet的后續工作(來自清華和理想),同樣采用了點圖融合方式生成BEV特征,區別在于對圖像分支采用IPM+高度插值方式實現PV2BEV轉換。IPM是傳統的PV2BEV轉換方法,但需要滿足地面高度平坦的假設。現實中,該假設通常較難滿足,因此該工作假設了4個不同地面高度下(-1m,0m,1m,2m)的BEV空間,分別將圖像特征經過IPM投影到這些BEV空間上,然后將這些特征concatenate起來得到最終的BEV特征。
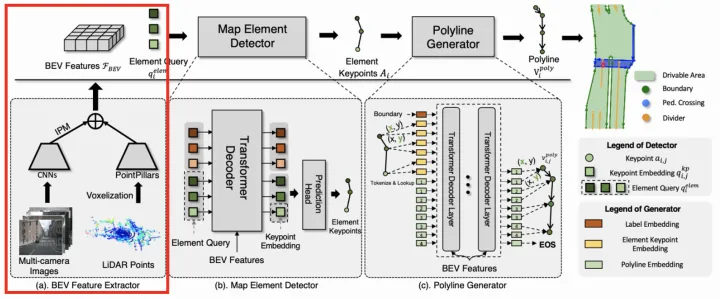
VectorMapNet架構圖
MapTR【7】(來自地平線)則是只采用了圖像分支生成BEV特征,利用他們之前提出的GKT【8】實現PV2BEV轉換。對于BEV Query,先通過相機內外參確定在圖像的先驗位置,并且提取附近的Kh×Kw核區域特征,然后和BEV Query做Cross-Attention得到BEV特征。
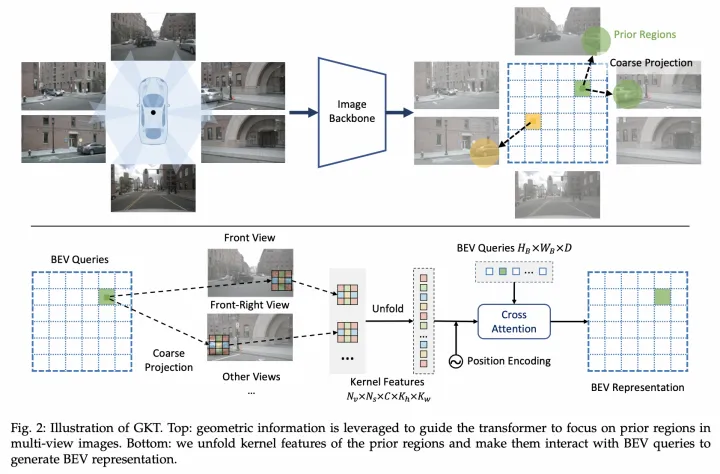
GKT架構圖
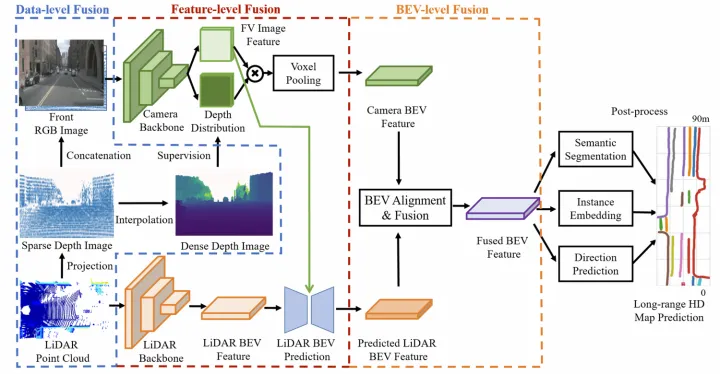
SuperFusion【9】(來自毫末智行)提出了長距離的車道拓撲生成方案,并且相應地采用多層級的點云和圖像特征融合來生成BEV特征(類似CaDDN【14】將深度圖分布和圖像特征外積得到視椎體特征,再通過voxel pooling方式生成BEV特征)。其中點云分支提取特征方式和HDMapNet一致,而圖像分支則基于深度估計實現PV2BEV轉換。
SuperFusion架構圖
其多層級的點圖特征融合,包括data-level,feature-level以及bev-level:
Data-level特征融合:將點云投影到圖像平面得到sparse深度圖,然后通過深度補全得到dense深度圖,再將sparse深度圖和原圖concatenate,并用dense深度圖進行監督訓練;
Feature-level特征融合:點云特征包含距離近,而圖像特征包含距離遠,提出了一種圖像引導的點云BEV特征生成方式,即將FV圖像特征作為K和V,將點云的BEV特征作為Q去和圖像特征做cross-attention得到新的BEV特征,并經過一系列卷積操作得到最終的點云BEV特征;
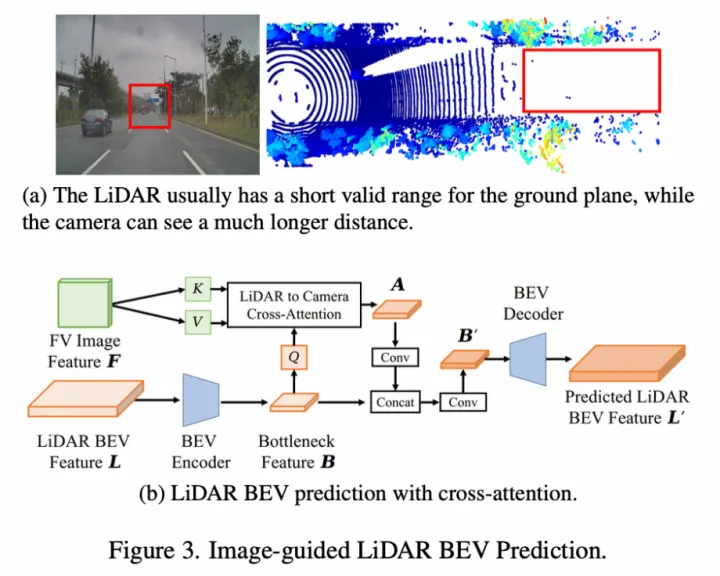
SuperFusion的Feature-level特征融合
BEV-level特征融合:由于深度估計誤差和相機內外參誤差,直接concatenate圖像和點云的BEV特征會存在特征不對齊問題。提出了一種BEV對齊方法,即將圖像和點云BEV特征先concat后學習flow field,然后將該flow field用于圖像BEV特征的warp(根據每個點的flow field進行雙線性插值),從而生成對齊后的圖像BEV特征;
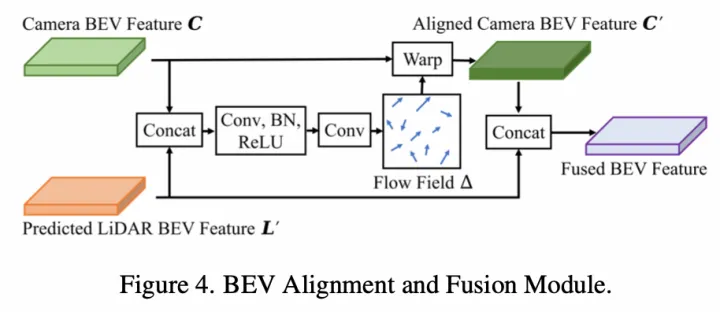
SuperFusion的BEV-level特征融合
地圖要素建模
關于地圖要素的建模方式,目前學術界趨勢是由像素到矢量點的逐漸轉變,主要考慮是有序矢量點集可以統一表達地圖要素以及拓撲連接關系。
HDMapNet采用像素方式建模車道線,引入語義分割、實例Embedding以及方向預測head分別學習車道線的語義像素位置、實例信息以及方向,并通過復雜的后處理(先采用DBSCAN對實例Embedding進行聚類,再采用NMS去除重復實例,最后通過預測的方向迭代地連接pixel),從而實現最終的車道線矢量化表達。

HDMapNet架構圖
VectorMapNet采用矢量點方式建模車道線,并拆解成Element檢測階段和Polyline生成階段。
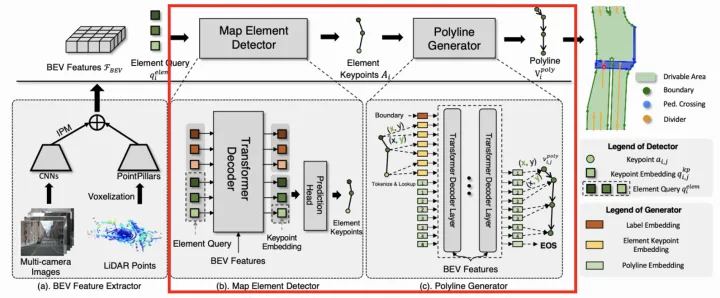
VectorMapNet架構圖
Element檢測階段的目標是檢測并分類全部的Map Element,采用了DETR【11】這種set prediction方式,即引入可學習的Element Query學習Map Element的關鍵點位置和類別。作者嘗試了多種定義關鍵點的方式,最終Bounding Box方式最優。

關鍵點表示方式
Polyline生成階段的目標是基于第一階段輸出的Map Element的類別和關鍵點,進一步生成Map Element的完整幾何形狀。將Polyline Generator建模成條件聯合概率分布,并轉換成一系列的頂點坐標的條件分布乘積,如下:
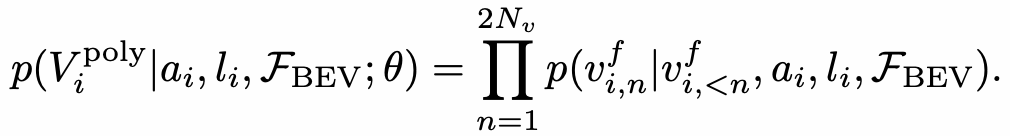
Polyline Generator建模
進而使用自回歸網絡對該分布進行建模,即在每個步驟都會預測下一個頂點坐標的分布參數,并預測End of Sequence token (EOS) 來終止序列生成。整個網絡結構采用普通的Transformer結構,每根線的關鍵點坐標和類標簽被token化,并作為Transformer解碼器的query輸入,然后將一系列頂點token迭代地輸入到Transformer解碼器中,并和BEV特征做cross-attention,從而解碼出線的多個頂點。
MapTR同樣采用矢量點方式建模車道線,提出了等效排列建模方式來消除矢量點連接關系的歧義問題,并且相應地設計了Instance Query和Point Query進行分層二分圖匹配,用于靈活地編碼結構化的地圖信息,最終實現端到端車道線拓撲生成。
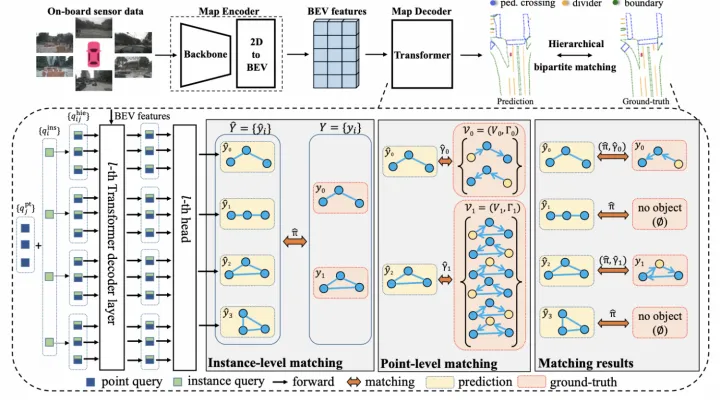
MapTR架構圖
等效排列建模就是將地圖要素的所有可能點集排列方式作為一組,模型在學習過程中可以任意匹配其中一種排列真值,從而避免了固定排列的點集強加給模型監督會導致和其他等效排列相矛盾,最終阻礙模型學習的問題。
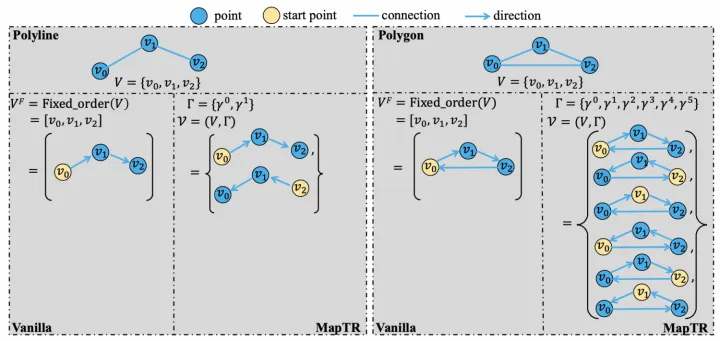
等效排列建模
分層二分圖匹配則同樣借鑒了DETR這種set prediction方式,同時引入了Instance Query預測地圖要素實例,以及Point Query預測矢量點,因此匹配過程也包括了Instance-level匹配和Point-level匹配。匹配代價中,位置匹配代價是關鍵,采用了Point2Point方式,即先找到最佳的點到點匹配,并將所有點對的Manhattan距離相加,作為兩個點集的位置匹配代價,該代價同時用在Instance-level和Point-level匹配上。此外,還引入了Cosine相似度來計算Edge Direction損失,用于學習矢量點的連接關系。
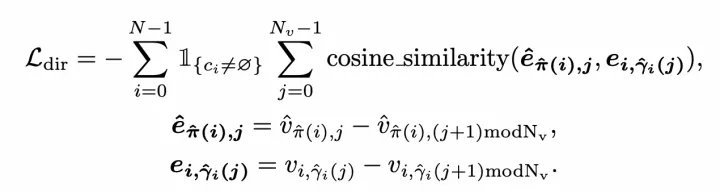
Edge Direction損失
SuperFusion則和HDMapNet一樣,采用像素方式建模車道線,方法完全一致。
實驗結果
目前實驗效果最好的是MapTR方法,僅通過圖像源即可超過其他方法的點圖融合效果,指標和可視化結果如下:
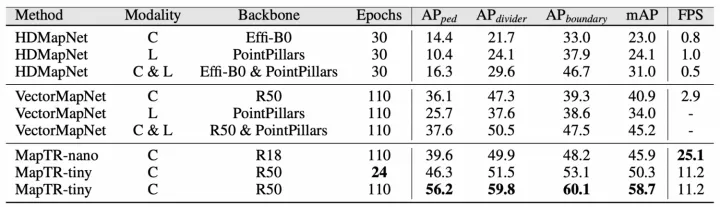
MapTR實驗結果

MapTR可視化
另外有趣的一個實驗是,VectorMapNet和SuperFusion均驗證了引入該車道線拓撲后對軌跡預測的影響,也說明了在線建圖的價值,如下:
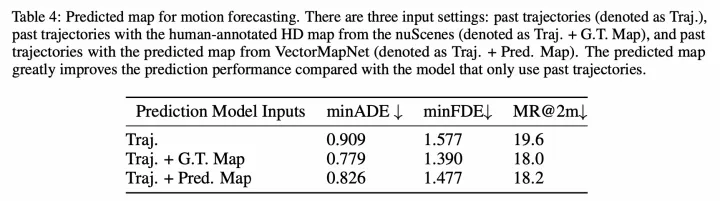
軌跡預測結果
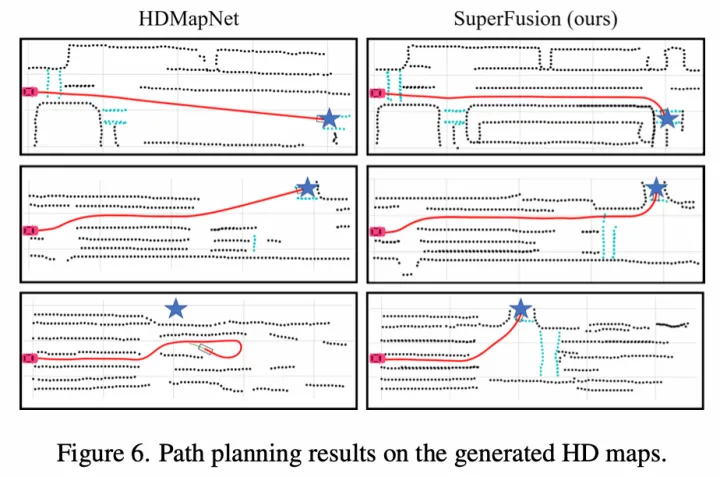
軌跡預測可視化
業界工作
特斯拉在AIDAY2022(https://www.youtube.com/watch?v=ODSJsviD_SU&t=10531s)中著重介紹了車道拓撲生成技術方案。借鑒語言模型中的Transformer decoder開發了Vector Lane模塊,通過序列的方式自回歸地輸出結果。整體思路是將車道線相關信息,包括車道線節點位置、車道線節點屬性(起點,中間點,終點等)、分叉點、匯合點、以及車道線樣條曲線幾何參數進行編碼,做成類似語言模型中單詞token的編碼,然后利用時序處理辦法進行處理,將這種表示看成“Language of Lanes”。
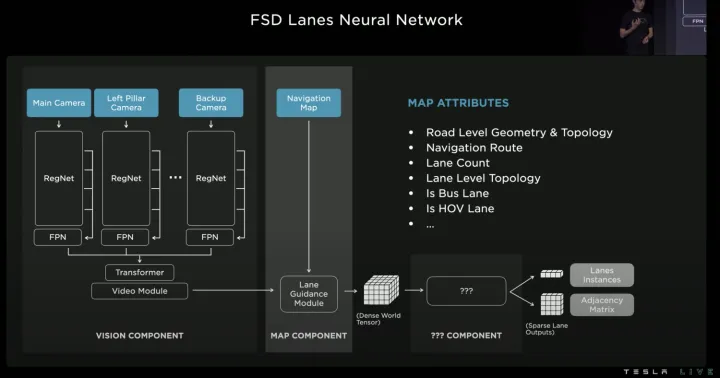
Vector Lane模塊
其中BEV特征(Dense World Tensor)不僅包括視覺圖像特征,還引入了低精度地圖中關于車道線幾何/拓撲關系的信息、車道線數量、寬度、以及特殊車道屬性等信息的編碼特征,這些信息提供了非常有用的先驗信息,在生成車道線幾何拓撲時很有幫助,尤其是生成無油漆區域的虛擬車道線。
自回歸方式生成車道線幾何拓撲的詳細過程如下:
先選取一個生成順序(如從左到右,從上到下)對空間進行離散化(tokenization),然后就可以用Vector Lane模塊預測一系列的離散token,即車道線節點。考慮到計算效率,采用了Coarse to Fine方式預測,即先預測一個節點的粗略位置的(index:18),然后再預測其精確位置(index:31),如下:

預測節點
接著再預測節點的語義信息,例如該節點是車道線起點,于是預測“Start”,因為是“Start”點,所以分叉/合并/曲率參數無需預測,輸出None。
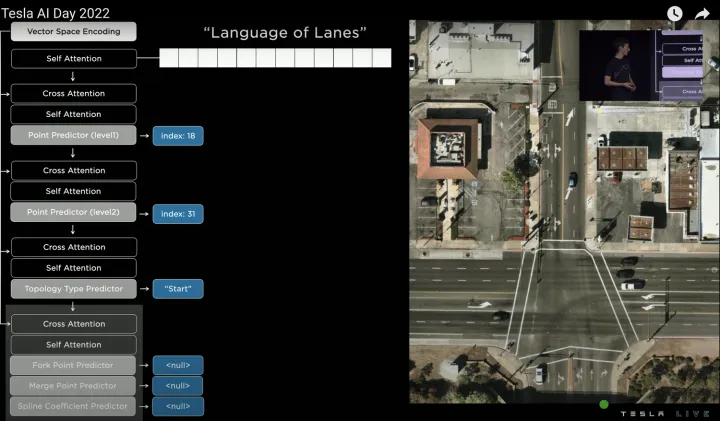
預測節點的語義信息
然后所有預測結果接MLP層輸出維度一致的Embedding,并將所有的Embedding相連得到車道線節點的最終特征,即輸出第一個word(綠色點),如下:
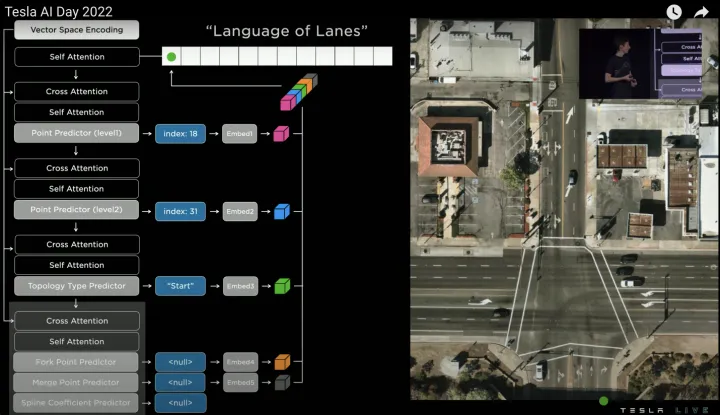
節點特征整合
接著將第一個word輸入給Self Attention模塊,得到新的Query,然后和Vector Space Encoding生成的Value和Key進行Cross Attention,預測第二個word(黃色點),整體過程和預測第一個word相同,只是第二個word的語義是“Continue”(代表延續點),分叉/合并預測結果仍為None,曲率參數則需要預測(根據不同曲線方程建模,例如三次多項式曲線或貝塞爾曲線等),如下:
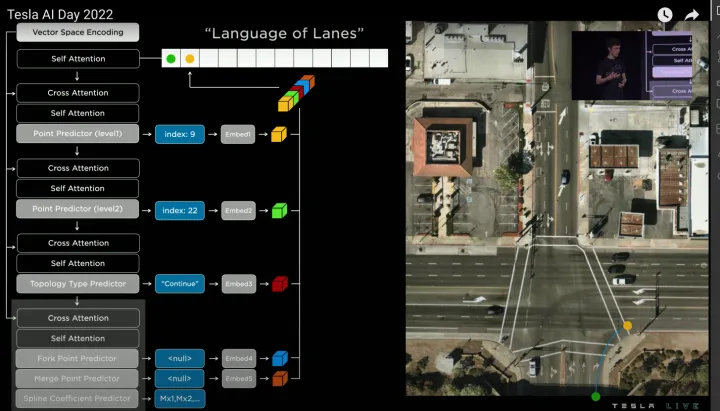
迭代預測第二個節點
接著同樣方式預測第三個word(紫色點),如下:
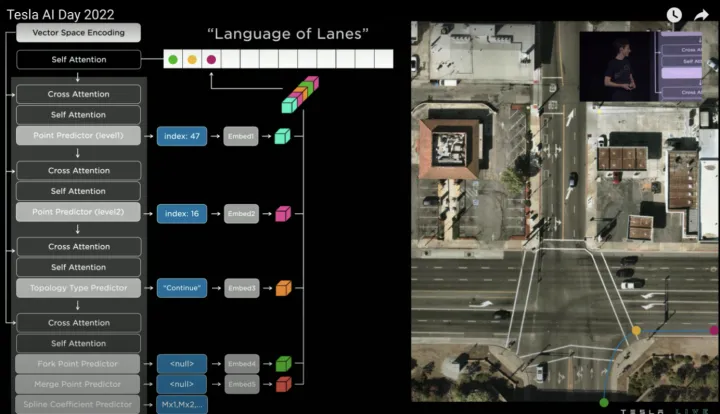
迭代預測第三個節點
然后回到起始點繼續預測,得到第四個word(藍色點),該word和也是和第一個word相連,所以語義預測為“Fork”(合并點),如下:
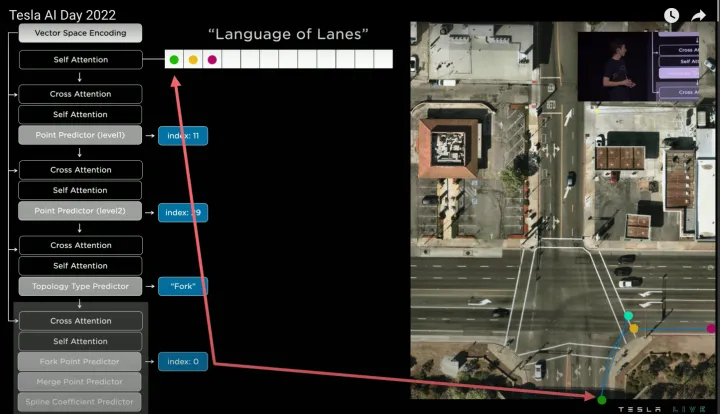
迭代預測第四個節點
進一步輸入前序所有word,預測第五個word,該word的語義預測為“End of sentence”(終止點),代表從最初的第一個word出發的所有車道線已經預測完成。
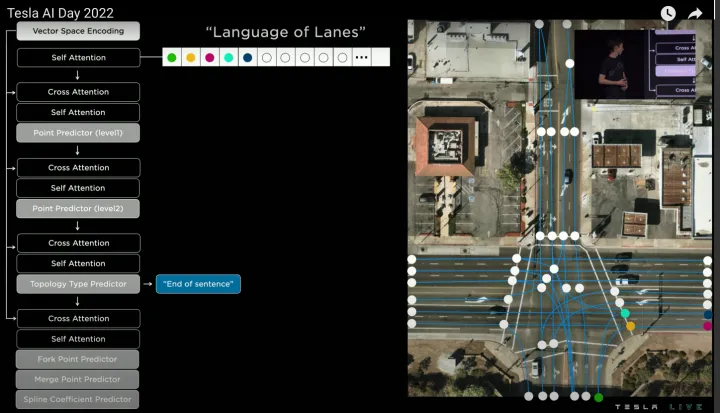
迭代預測第五個節點
由此遍歷所有起始點,即可生成完整的車道線拓撲,如下:
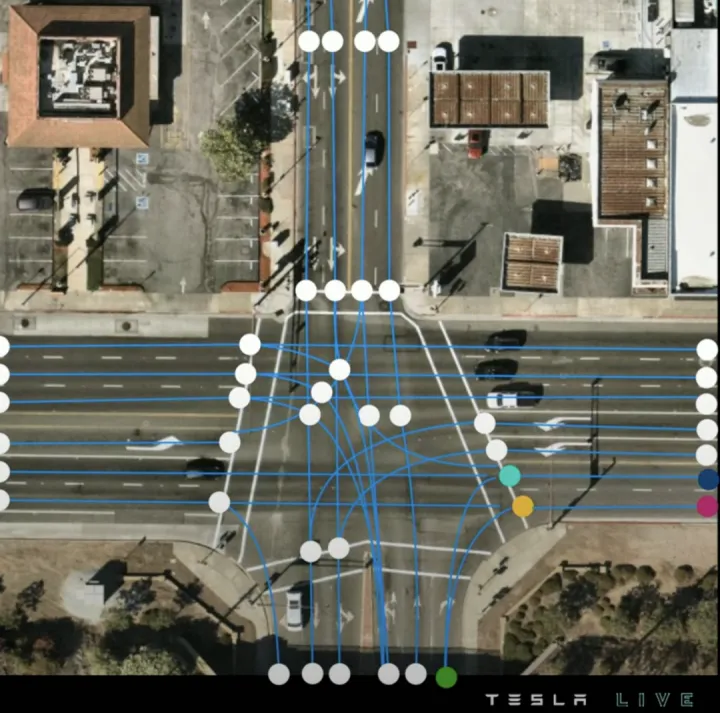
車道線拓撲

在線建圖可視化
百度
百度在ApolloDay2022(https://www.apollo.auto/apolloday/#video)上也介紹了生成在線地圖的技術方案,可以概述為以下幾點:
點圖融合,圖像分支基于Transformer實現PV2BEV空間轉換;
Query-based的set-prediction,引入Instance query、Point query以及Stuff query同時學習地圖要素實例、矢量點以及可行駛區域分割等;
高精地圖(精度)和眾源地圖(規模和鮮度)多源融合;
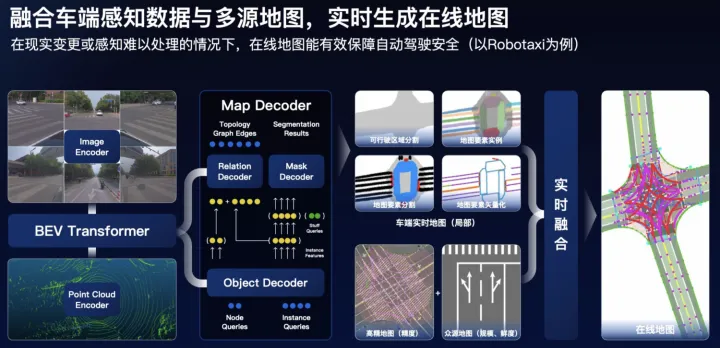
在線建圖架構圖
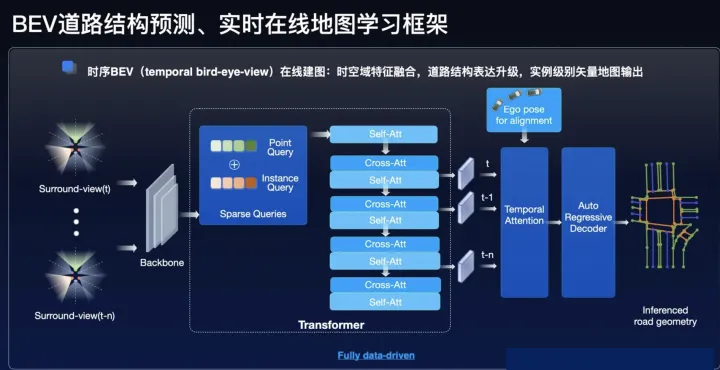
在線建圖架構圖
毫末智行
毫末智行是一家重感知輕地圖的公司,因此也在毫末智行AI DAY(https://mp.weixin.qq.com/s/bwdSkns_TP4xE1xg32Qb6g)上著重介紹了在線建圖方案,可以概述為以下幾點:
點圖融合,圖像分支基于Transformer實現PV2BEV空間轉換;
實物車道線檢測+虛擬車道線拓撲,實物車道線檢測的Head采用HDMapNet方式生成,虛擬車道線拓撲則是以SD地圖作為引導信息,結合BEV特征和實物車道線結果,使用自回歸編解碼網絡,解碼為結構化的拓撲點序列,實現車道拓撲預測;
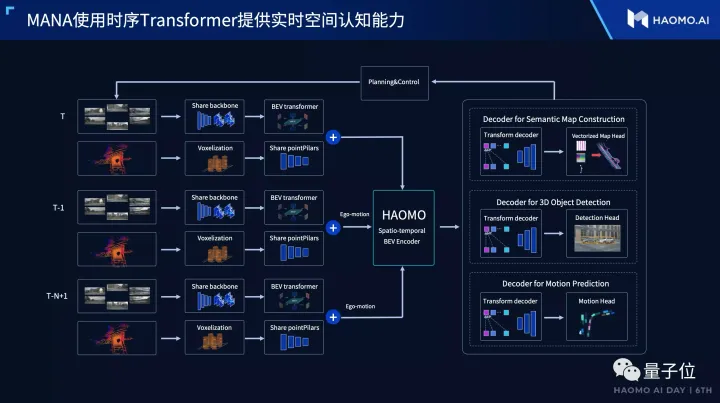
實物車道線檢測
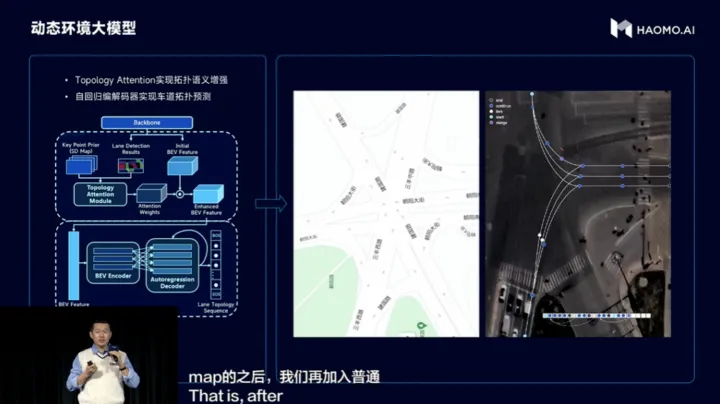
虛擬車道線拓撲生成
地平線
地平線也在分享(https://mp.weixin.qq.com/s/HrI6Nx7IefvRFULe_KUzJA)中也介紹了其在線建圖方案。
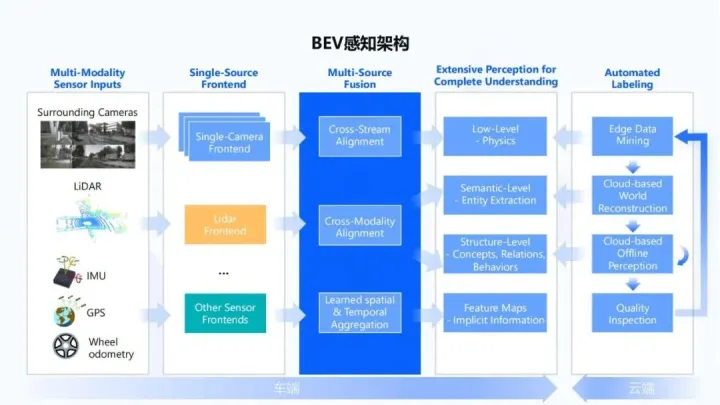
BEV感知架構
通過六個圖像傳感攝像頭的輸入,得到全局BEV語義感知結果,這更多是感知看得見的內容,如下圖所示:
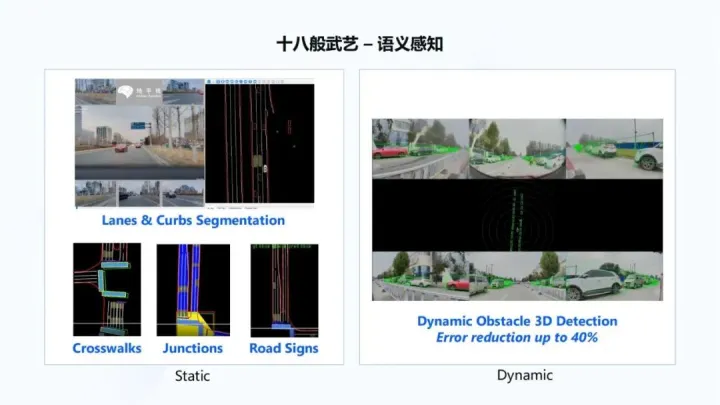
語義感知
再通過引入時序信息,將想象力引入到 BEV感知中,從而感知看不見的內容,如下右圖所示,感知逐漸擴展自己對于周邊車道線、道路以及連接關系的理解,這個過程一邊在做感知,一邊在做建圖,也叫做online maps。
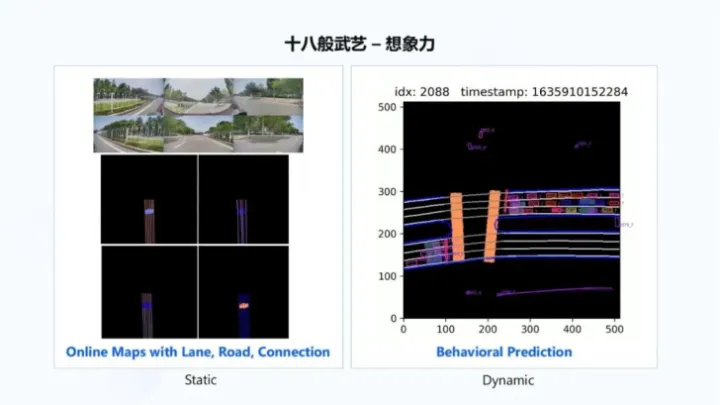
超視距感知
小鵬
小鵬汽車目前推出了全新一代的感知架構XNet(https://mp.weixin.qq.com/s/zOWoawMiaPPqF2SpOus5YQ),結合全車傳感器,對于靜態環境有了非常強的感知,可以實時生成“高精地圖”。核心是通過Transformer實現多傳感器、多相機、時序多幀的特征融合。
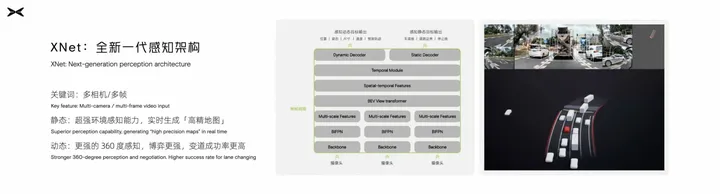
XNet架構圖
思考
拋開技術外,我還想聊聊對圖商的”離線高精地圖“和自動駕駛公司的”在線地圖“的認識。
地圖是自動駕駛的一個非常重要模塊,自動駕駛不能脫離地圖,因為自動駕駛是運行在規則約束的交通系統下,無法擺脫這套規則的約束,而地圖恰恰是這套規則系統表達的很好載體,一個完整的地圖不僅包括各種地圖要素,還包括各種交通規則,例如該車道能否掉頭、該紅綠燈作用在哪個車道等。因此,圖商憑借在SD地圖制作經驗(交通規則理解),均開展了”離線高精地圖“制作,包括高德地圖、百度地圖、騰訊地圖、四維圖新等。而圖商制作”離線高精地圖“的邏輯是,建立統一的、大而全的高精地圖標準,同時服務于市場上的多家自動駕駛公司。但不同的自動駕駛公司的自身自動駕駛能力差異非常大,對高精地圖的需求也不同,這就導致”離線高精地圖“越來越復雜,圖商的采集和制作成本也越來越高。正因為成本高,高精地圖的覆蓋率低和鮮度差的問題也始終未被解決,這是每個圖商都需要面對的緊迫問題。盡管也有一些眾包更新的解決方案,但實際得到大規模應用的并不多。
而自動駕駛又需要高覆蓋、高鮮度的高精地圖,于是自動駕駛公司開始研究如何“在線建圖”這個課題了。“在線建圖”的關鍵在于“圖”,在我看來,這個“圖”已經不是“離線高精地圖”的“圖”了,因為自動駕駛公司的“在線建圖”是根據自身的自動駕駛能力調整的,在“離線高精地圖”中的冗余信息都可以舍棄,甚至是常說的精度要求(“離線高精地圖”一般要求5cm精度)。而恰恰因為對“圖”進行了簡化,所以自動駕駛公司的”在線地圖“才有了可行性。通過”在線地圖“,在“離線高精地圖”覆蓋范圍內實現地圖更新,在“離線高精地圖”覆蓋范圍外生成自己可用的地圖,可能會有一些自動駕駛功能的降級,這個邊界仍在摸索中。
不過,測繪資質和法規變化可能會促使一種新的圖商和自動駕駛公司的高精地圖生產合作模式,即自動駕駛公司提供智能車數據 + 圖商提供高精地圖制作能力的生態閉環。2022年下半年,國家和地方密集出臺了一系列高精度地圖相關法律,例如:《關于促進智能網聯汽車發展維護測繪地理信息安全的通知》、《關于做好智能網聯汽車高精度地圖應用試點有關工作的通知》等。這些法律文件明確界定了智能網聯汽車和測繪的關系,即智能網聯汽車在運行過程中(包括賣出的車)對數據的操作即為測繪,并且自動駕駛公司是測繪活動的行為主體。從規定來看,自動駕駛公司的“在線地圖”是明確的測繪行為,而想要合法測繪,必須擁有導航電子地圖制作的甲級資質,而獲得資質的途徑可以是直接申請(太難申請,并且不是一勞永逸,可能在復審換證環節被撤銷企業資質)、間接收購(風險高)、以及與圖商合作。由此來看,自動駕駛公司和圖商合作的生態閉環可能是唯一解法。那么,自動駕駛公司的智能車數據提供給圖商進行地圖數據生產是否合法呢?在《上海市智能網聯汽車高精度地圖管理試點規定》中,明確規定“鼓勵具有導航電子地圖制作測繪資質的單位,在確保數據安全、處理好知識產權等關系的前提下,探索以眾源方式采集測繪地理信息數據,運用實時加密傳輸及實時安全審校等技術手段,制作和更新高精度地圖。” 目前,騰訊地圖已官宣與蔚來宣布達成深度合作,打造智能駕駛地圖、車載服務平臺等,當然這可能更多是投資關系促使。如何真正實現高精地圖生產的生態閉環,可能是圖商未來的破局關鍵。
審核編輯 :李倩
-
圖像
+關注
關注
2文章
1083瀏覽量
40449 -
數據集
+關注
關注
4文章
1208瀏覽量
24689 -
自動駕駛
+關注
關注
784文章
13784瀏覽量
166394
原文標題:?高精地圖生成技術大揭秘
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
高精3D地圖是自動駕駛技術的基石 測繪地圖技術的重要性何在

高精地圖在無人駕駛領域的作用,高精地圖與普通導航地圖的區別

高德和整車廠合作,拿下國內首個高精地圖訂單
Apollo定位、感知、規劃模塊的基礎-高精地圖
自動駕駛技術最新進展:自動駕駛系統與高精地圖關系

豐田展示一款路面高精地圖 將大幅降低高精地圖的構建和維護成本
隨著5G以及自動駕駛技術的進步,高精地圖技術也越發受到重視

為什么需要去除高精地圖?
國內首個L3級自動駕駛之城誕生,高精定位和高精地圖成為關鍵支撐

自動駕駛仿真測試實踐:高精地圖仿真






 工商網監
工商網監
評論